Online Predictive Coding for Dual-Mode Speech
Online Predictive Coding for Dual-Mode Self-Supervised Speech Model
This paper introduces Online Predictive Coding (OPC) to improve dual-mode self-supervised speech models that handle streaming and offline modes using shared parameters. OPC regularizes online registers to predict future frames, reducing performance gaps and stabilizing training for low-latency speech recognition.
Links
Paper & demos
Abstract
Dual-mode self-supervised speech models are pre-trained to handle streaming and non-streaming conditions simultaneously. However, their attention is computed over different context ranges, which often makes optimization difficult. In previous work, we proposed online registers, additional tokens intended to compensate for missing future context in streaming mode, but the gains remained limited. To address these issues, we introduce two improvements for robust dual-mode pre-training: (1) Online Predictive Coding (OPC), which regularizes the registers through multi-step future prediction, and (2) Dual-mode Layer Normalization, which stabilizes optimization. We fine-tune the proposed dual-mode self-supervised speech models for speech recognition on LibriSpeech and WSJ. Results show that OPC consistently reduces the online-offline performance gap; at 160 ms latency on LibriSpeech, word error rates improve from 3.65% to 3.40% on test-clean and from 10.15% to 9.65% on test-other.
Introduction
This paper addresses a practical gap in self-supervised speech models (S3Ms): many strong encoders are pre-trained only in offline settings, but real-time applications require online or streaming inference where future context is unavailable. The paper focuses on dual-mode S3Ms that are intended to support both streaming and non-streaming inference with a single shared encoder. The central difficulty is that the same parameters must operate under very different attention visibility patterns, which makes optimization unstable and often leads to a measurable online–offline performance gap.
The authors build on their prior online registers idea: learnable tokens appended to each streaming chunk to compensate for missing future context. In this paper, they argue that registers alone are not sufficiently constrained to encode predictive information, so their gains remain limited. They introduce two changes to make dual-mode pre-training more robust:
- Online Predictive Coding (OPC), a multi-step future prediction objective that regularizes the online registers.
- Dual-mode Layer Normalization, which uses separate LayerNorm affine parameters for online and offline pathways to reduce mode-specific distribution mismatch.
The paper’s core claim is that these changes make dual-mode self-supervised pre-training more stable and reduce the streaming-vs.-offline discrepancy without increasing algorithmic latency.
Problem Setup and Motivation
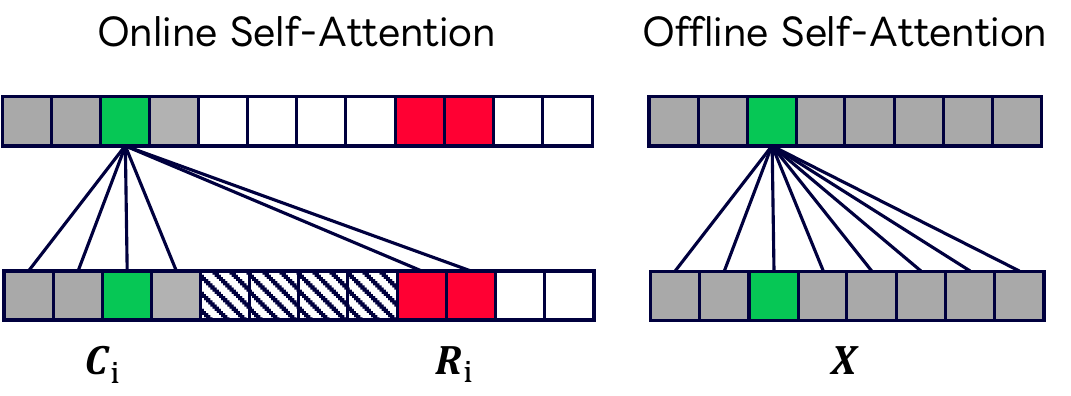
The paper starts from a standard wav2vec 2.0-style encoder. Let $X = (\mathbf{x}_1, \dots, \mathbf{x}_T)$ denote the latent acoustic feature sequence produced by a convolutional front end, where $T$ is the number of frames. In offline mode, the Transformer encoder can attend to all of $\mathbf{X}$. In online mode, the input is partitioned into chunks of size $N_c$, optionally with $N_l$ look-ahead frames, so each chunk only sees a restricted context window.
The authors emphasize that the main optimization problem is attention mismatch: the online pathway sees only past/current frames plus optional look-ahead, while the offline pathway sees the full utterance. Shared parameters therefore have to serve two different computational regimes. Online registers are introduced to partially fill this gap by giving the online pathway extra learnable slots that can carry information about unseen future context.
Method
Dual-mode Transformer with Online Registers
The encoder is based on wav2vec 2.0 and is trained in a dual-mode fashion. For the $i$-th chunk, the chunk content and look-ahead are defined as
$$ \mathbf{C}_i = \mathbf{X}_{(i-1)N_c+1:iN_c}, \qquad \mathbf{L}_i = \mathbf{X}_{iN_c+1:iN_c+N_l}. $$
For online processing, the model appends $N_r$ learnable online registers $\mathbf{R}_i = (\mathbf{r}_1, \dots, \mathbf{r}_{N_r})$ to each chunk. The register embeddings are shared across chunks. A Transformer encoder $f(\cdot)$ is then run in two modes:
$$ (\hat{\mathbf{C}}^{\text{on}}, \hat{\mathbf{L}}^{\text{on}}, \hat{\mathbf{R}}^{\text{on}}) = f\big((\mathbf{C}, \mathbf{L}, \mathbf{R}); \mathbf{M}\big), \qquad \hat{\mathbf{X}}^{\text{off}} = f(\mathbf{X}), $$
where $\mathbf{M}$ masks future context in online mode. At inference time, online representations are extracted chunk by chunk. The paper notes that registers add only marginal memory and compute overhead and do not affect algorithmic latency.
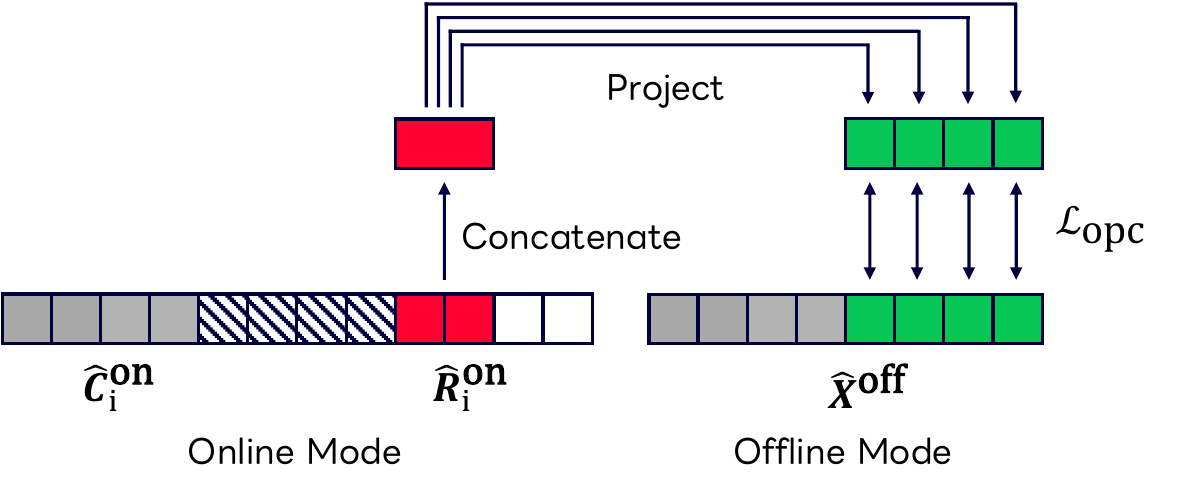
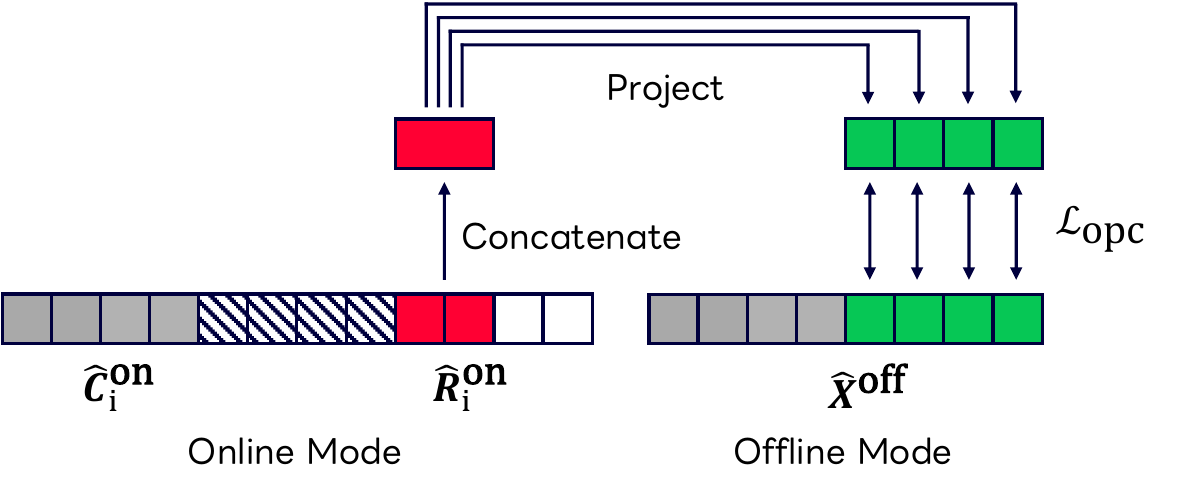
Online Predictive Coding
The main new objective is Online Predictive Coding (OPC). The intention is to force the online registers to be predictive of unseen future context, rather than merely serving as extra capacity. For each chunk $i$, the output register states $\hat{\mathbf{R}}_i^{\text{on}}$ are concatenated and linearly projected to predict multiple future offline representations:
$$ \hat{\mathbf{f}}_{i,j} = \mathbf{W}_j^\top \begin{bmatrix} \hat{\mathbf{r}}_{i,1} \\ \vdots \\ \hat{\mathbf{r}}_{i,N_r} \end{bmatrix}, \qquad \mathbf{f}_{i,j} = \hat{\mathbf{x}}^{\text{off}}_{iN_c + N_l + j}, \qquad j = 1, \dots, N_f. $$
Here $N_f$ is the number of future steps predicted by OPC. The objective minimizes cosine distance between each predicted vector and a stop-gradient target from the offline pathway:
$$ \mathcal{L}_{\text{opc}} = \sum_{i=1}^{\lfloor T/N_c \rfloor + 1} \sum_{j=1}^{N_f} \left(1 - \cos\left(\hat{\mathbf{f}}_{i,j}, \operatorname{SG}(\mathbf{f}_{i,j})\right)\right). $$
The stop-gradient on the offline target prevents collapse of the offline branch. The paper’s interpretation is that minimizing this loss encourages the registers to encode information useful for reconstructing future offline representations, thereby making them better surrogates for missing future context.
OPC is optimized jointly with the wav2vec 2.0 objectives for online and offline modes and with the codebook diversity loss:
$$ \mathcal{L} = \frac{1}{2}\left(\mathcal{L}^{\text{on}} + \mathcal{L}^{\text{off}}\right) + w_d \mathcal{L}_d + w_{\text{opc}} \mathcal{L}_{\text{opc}}. $$
In the reported experiments, $w_d = 0.1$ and $w_{\text{opc}} = 0.1$.
Dual-mode Layer Normalization
The second proposed change is Dual-mode Layer Normalization. The paper argues that dual-mode training induces mode-dependent feature statistics, and that online registers can exacerbate this mismatch because their activations are explicitly shaped to compensate for missing future frames. To reduce interference, each LayerNorm keeps separate affine parameters for the two modes:
$$ (\mathbf{\gamma}, \mathbf{\beta}) = \begin{cases} (\mathbf{\gamma}^{\text{off}}, \mathbf{\beta}^{\text{off}}) & \text{for offline mode}, \\ (\mathbf{\gamma}^{\text{on}}, \mathbf{\beta}^{\text{on}}) & \text{for online mode}. \end{cases} $$
All other weights are shared. The stated goal is to stabilize optimization under the distribution shift between online and offline pathways.
Training and Experimental Setup
Pre-training data. The pre-training corpus is the 960-hour LibriSpeech dataset without transcriptions.
Fine-tuning data. The model is fine-tuned for ASR on LibriSpeech and evaluated on test-clean and test-other. For cross-domain evaluation, the paper also fine-tunes and evaluates on Wall Street Journal (WSJ), using train_si284 for training, test_dev92 for validation, and test_eval92 and test_eval93 for testing.
Pre-training recipe. The authors follow the official Fairseq wav2vec 2.0 BASE configuration and modify it only as needed for the proposed dual-mode setup. Streaming behavior is simulated with chunk-based attention masks and Dynamic Chunk Training (DCT), where the chunk size and look-ahead are sampled as $N_c \sim \mathcal{U}(2, 32)$ and $N_l \sim \mathcal{U}(0, N_c)$. The number of registers is fixed to $N_r = 1$.
Pre-training runs for 100k steps on 16 NVIDIA H200 GPUs. The learning rate is warmed up linearly to $10^{-4}$ over the first 8k steps and then decayed linearly to zero. The batch size corresponds to 350 seconds of audio per GPU. All parameters, including register embeddings, are optimized with Adam.
The model removes relative positional encodings and uses sinusoidal positional encodings instead, following wav2vec-S. Initialization starts from the official checkpoint trained on LibriSpeech 960h, and the Dual-mode LayerNorm parameters are initialized from that checkpoint for both modes.
Fine-tuning and decoding. Fine-tuning follows the official Fairseq wav2vec 2.0 BASE 960h configuration for LibriSpeech, and the Fairseq LibriSpeech 100h setup for WSJ. The pre-training projection head is replaced by a linear layer, and the model is optimized with the average CTC loss over online and offline modes. DCT is also used during fine-tuning so the model supports arbitrary chunk sizes. Fine-tuning lasts 320k steps on 8 NVIDIA H200 GPUs, with 200 seconds of audio per GPU.
For LibriSpeech decoding, the paper uses the Flashlight beam-search decoder with the released 4-gram language model and beam size 50. For WSJ, the same decoding framework is used with a 4-gram language model trained on WSJ text.
Main Results
The main result is that OPC consistently reduces the online-offline gap, with the largest gains appearing at low latency. The paper reports that at 160 ms latency ($N_c = 8$, $N_l = 0$) on LibriSpeech, online WER improves from 3.65% to 3.40% on test-clean and from 10.15% to 9.65% on test-other. Offline WER also improves, from 2.73% to 2.64% on test-clean and from 6.63% to 6.41% on test-other.
| Pre-train method | test-clean | test-other | eval92 | eval93 | ||||
|---|---|---|---|---|---|---|---|---|
| Offline | Online | Offline | Online | Offline | Online | Offline | Online | |
| Dual-mode only | 2.73 | 3.65 | 6.63 | 10.15 | 7.24 | 8.99 | 10.08 | 8.12 |
| w/ online registers | 2.70 | 3.50 | 6.52 | 9.80 | 7.14 | 8.65 | 10.05 | 7.60 |
| w/ Online Predictive Coding | 2.64 | 3.40 | 6.41 | 9.65 | 6.94 | 8.13 | 10.20 | 7.86 |
On LibriSpeech, the progression is consistent: dual-mode only → online registers → OPC. The online registers reduce the mismatch somewhat, and OPC gives the largest gains. On WSJ, OPC improves eval92 in both offline and online modes, but the paper notes that eval93 shows a more mixed outcome: offline WER becomes slightly worse than the register-only variant, suggesting that the auxiliary predictive task can introduce domain-specific bias when the target domain differs from pre-training data.
The authors also compare against a lower-latency 640 ms setting to situate their approach relative to prior work.
| Method | test-clean | test-other | ||
|---|---|---|---|---|
| Offline | Online | Offline | Online | |
| wav2vec 2.0 | 2.6 | — | 6.1 | — |
| UFO2 | 3.0 | 3.8 | 7.1 | 9.4 |
| Ours | 2.6 | 3.1 | 6.4 | 8.3 |
At this 640 ms setting, the paper reports that the proposed method achieves offline performance comparable to wav2vec 2.0 and lower online WER than UFO2 on both LibriSpeech test sets.
Latency versus Accuracy
The paper analyzes how recognition quality changes as the online latency budget varies. It evaluates LibriSpeech test-clean in two ways: (1) varying chunk size with no look-ahead, and (2) varying look-ahead with a fixed 160 ms chunk size. The main conclusion is that OPC is especially helpful in the smallest-latency regime, where missing future context is most severe.
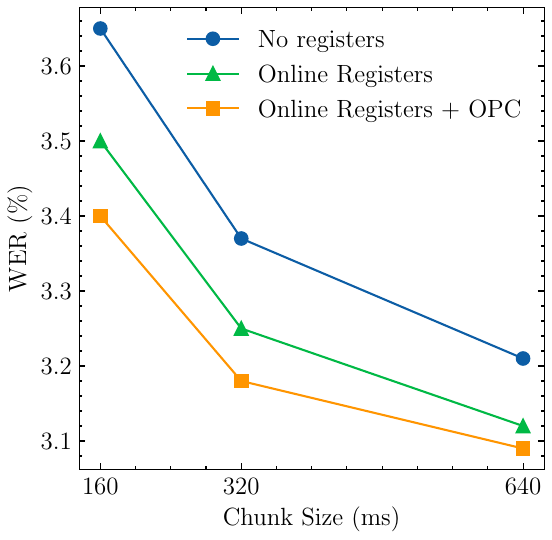
When the look-ahead is fixed at $N_l = 0$ and the chunk size varies, the accuracy gains are strongest at small chunks, particularly at 160 ms latency ($N_c = 8$). The paper highlights that the combination of online registers and OPC can match the baseline at a longer-latency operating point, effectively trading predictive regularization for lower latency.
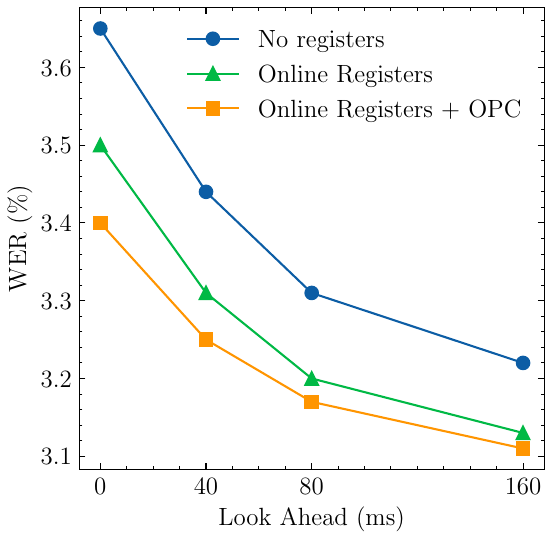
When the chunk size is fixed at $N_c = 8$ and look-ahead is varied, the model maintains high accuracy even with zero look-ahead. The paper interprets this as evidence that OPC makes the online registers a better approximation of missing future context, reducing the need for explicit look-ahead.
Ablation on the Number of Predicted Future Frames
OPC predicts $N_f$ future offline representations per chunk. The paper explores whether predicting more steps helps the registers encode richer context or simply makes the auxiliary objective too hard.
| $N_f$ | test-clean | test-other | ||
|---|---|---|---|---|
| Offline | Online | Offline | Online | |
| 2 | 2.68 | 3.49 | 6.48 | 9.83 |
| 4 | 2.64 | 3.40 | 6.41 | 9.65 |
| 6 | 2.65 | 3.43 | 6.39 | 9.72 |
| 8 | 2.65 | 3.47 | 6.42 | 9.78 |
The best overall setting is $N_f = 4$, which is the value used for the main results. The paper reports that too few future steps ($N_f = 2$) underutilize the predictive objective, while too many ($N_f = 8$) make the task harder and can hurt optimization. The authors interpret this as a trade-off between auxiliary-task difficulty and the amount of predictive information injected into the registers.
Interpretation and Stated Limitations
The paper’s interpretation is straightforward: online registers alone partially reduce the online-offline mismatch, but OPC makes them explicitly predictive and therefore more effective as surrogates for missing future context. Dual-mode LayerNorm complements this by separating the statistical normalization parameters for the two operating modes. Together, these changes improve both online and offline ASR performance, especially at low latency.
- The gains are strongest at small latency, where the online pathway is most constrained.
- The choice of $N_f$ matters; performance is not monotonic in the number of predicted future frames.
- On WSJ eval93, OPC slightly worsens offline WER relative to the register-only model, which the paper attributes to possible domain-specific bias from the auxiliary predictive task.
- The comparison to UFO2 is explicitly noted as not strictly controlled because the decoding setups differ.
The paper does not claim that OPC removes the online-offline gap entirely; rather, it narrows it while preserving the ability to operate in both streaming and non-streaming settings without increasing algorithmic latency.
Conclusion
The paper proposes Online Predictive Coding as a way to make dual-mode self-supervised speech models more robust under streaming constraints. By forcing online registers to predict multiple future offline representations and by separating LayerNorm parameters across modes, the model learns more stable representations that better align online and offline attention behavior. The reported experiments on LibriSpeech and WSJ show consistent improvements over the dual-mode baseline, with particularly strong gains at low latency.