CORTIS
CORTIS: Text-Only Adaptation of Spoken Language Models for Task-Oriented Voice Agents
CORTIS adapts spoken language models for task-oriented voice agents using text-only supervision, enabling direct speech-to-structured-output generation without paired speech-target data. It is more robust than ASR-LLM cascades under noise, especially in preserving high-level semantic understanding.
Links
Paper & demos
Abstract
Task-oriented voice agents need to map spoken user requests to structured outputs such as semantic frames, executable actions, and function calls. A common approach is to cascade ASR with a text-based LLM, but transcription errors can propagate to downstream structured output generation, especially under noisy conditions. Spoken language models (SLMs) offer a direct speech-based alternative, yet adapting them to new tasks typically requires paired speech-target annotations. Motivated by this gap, we present CORTIS, a text-only adaptation framework for task-oriented voice agents. CORTIS fine-tunes SLMs using text-form task supervision, enabling speech-based structured output generation at inference time without task-specific speech-target annotations during adaptation. We evaluate CORTIS on two Qwen2.5-Omni backbones and three task-oriented speech datasets, including an in-house product dataset, and compare it with matched ASR-LLM cascades trained with the same text-form task supervision. Results show that CORTIS performs competitively with matched cascades and offers clearer advantages under acoustic degradation, particularly in preserving high-level task semantics. These findings suggest that text-only fine-tuning of SLMs can serve as a practical adaptation strategy for voice agents when paired speech-target data are costly to collect.
1. Problem Setting and Core Idea
The paper studies task-oriented voice agents that must convert spoken user requests into structured outputs such as semantic frames, executable actions, or function calls. The central challenge is that most supervised structured-output systems are trained for text instructions, while production voice agents must operate on speech. The standard engineering solution is an ASR-LLM cascade: first transcribe the audio, then pass the transcript to a text-only language model. That architecture is modular, but it is brittle because ASR mistakes can propagate into the final structured output, especially under acoustic degradation.
The paper argues that spoken language models (SLMs) provide a direct speech-to-structure alternative, but adapting them to new downstream tasks usually needs paired speech-target annotations. Those annotations are expensive to collect because every target task requires speech examples aligned with task-specific labels or function calls. CORTIS is proposed as a cost-efficient alternative: it adapts an SLM using only text-form supervision while still performing speech-based inference at test time.
The key claim is not merely that text-only tuning can preserve general speech understanding, but that it can support structured output generation for voice agents without collecting task-specific speech-target pairs. The paper evaluates this claim against matched ASR-LLM cascades trained with the same text supervision and finds that CORTIS is especially robust when the audio becomes noisy.
- What CORTIS changes: fine-tunes the language-model side of an SLM on text instructions paired with structured outputs.
- What CORTIS does not need: task-specific speech-target annotations during adaptation.
- Main empirical question: can a text-only adapted SLM compete with an ASR-LLM cascade, and does it become more attractive under noisy speech?
2. Method: Text-Only Adaptation of an SLM
2.1 Task formulation
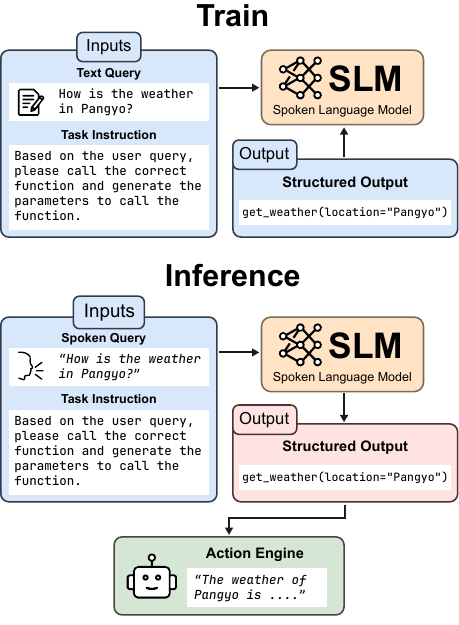
The task is formalized as mapping a spoken user request $a_i$ and its text form $x_i$ to a target structured output $y_i$. The target can be a semantic frame, an intent-plus-entity representation, or a function call with arguments. The output is serialized as text so that the same supervision format can train both text-only LLMs and SLMs.
The text-only supervision set is $$ \mathcal{D}_{\text{text}} = \{(x_i, y_i)\}_{i=1}^{N}. $$ During adaptation, CORTIS does not use task-specific speech-target pairs $(a_i, y_i)$. At inference time, the fine-tuned model receives speech instead of text in the same prompt slot.
2.2 Prompt-based fine-tuning objective
Each example is wrapped in a task-specific instruction template $T(\cdot)$. The text query is inserted into the prompt during training, and the model is optimized with standard next-token prediction: $$ \mathcal{L}_{\text{text}}(\theta) = - \sum_{i=1}^{N} \log p_{\theta}(y_i \mid T(x_i)). $$ Here $\theta$ denotes the trainable parameters of the SLM’s language-model component.
At inference time, the spoken query replaces the text query in the same prompt slot, and decoding is performed directly from speech-conditioned representations: $$ \hat{y}_i = \operatorname{Decode}(p_{\theta}(\cdot \mid T(a_i))). $$ The paper’s core design principle is therefore prompt and schema consistency: the instruction, query position, and structured-output format are kept identical between text-only training and speech-based inference.
2.3 Implementation choices that make text-only transfer work
The authors explicitly adopt two implementation choices to preserve transfer from text-only adaptation to speech inference.
- Freeze speech-related modules. The speech encoder and modality adapter are kept fixed during adaptation. This avoids updating the parts of the SLM that are not directly supervised by the text-only objective.
- Keep the prompt structure fixed. The same prompt template is used for training and inference. At test time, the spoken query occupies the exact slot that the text query used during fine-tuning.
The paper’s prompt-format figure illustrates this in a ChatML-style setup for FSC, where the user query is followed by an instruction that asks the model to extract structured fields and return a single-line JSON object.

3. Experimental Setup
3.1 Compared systems
The main comparison is between CORTIS-tuned SLMs and matched ASR-LLM cascades. In the cascade, audio is first transcribed by ASR and the transcript is then passed to a text-tuned LLM. In CORTIS, the same speech signal is processed directly by the SLM, which has been adapted only through text-form supervision.
To keep the comparison fair, each CORTIS configuration is paired with a scale-matched cascade from the same backbone family:
- 3B setting: Qwen2.5-Omni-3B for CORTIS versus Whisper large-v3 + Qwen2.5-3B-Instruct for the cascade.
- 7B setting: Qwen2.5-Omni-7B for CORTIS versus Whisper large-v3 + Qwen2.5-7B-Instruct for the cascade.
The paper also reports an oracle-text condition, where the adapted text model receives the gold transcript at inference time. This provides an upper bound that isolates structured-output generation from ASR errors.
3.2 Datasets and output formats
The study evaluates three task-oriented speech datasets. The first two are public benchmarks, and the third is an internal product-oriented dataset for smart-home voice-agent commands.
| Dataset | Target format | Metric | Train | Dev | Test |
|---|---|---|---|---|---|
| FSC | {action, object, location} | Exact match | 23132 | 3118 | 3793 |
| SLURP | {scenario, action, entities} | Intent Acc., Entity F1, SLU-F1 | 11514 | 2033 | 13078 |
| In-house | Function call with arguments | Exact match | 21397 | 891 | 591 |
FSC is evaluated with exact match over the full semantic frame. SLURP is evaluated with intent accuracy, entity F1, and SLU-F1 under the standard SLURP protocol. The in-house dataset is evaluated with exact match over the generated function call and its arguments. The in-house dataset uses 42 predefined target functions, but the prompt does not include special function tokens or function descriptions.
A subtle but important detail is that the train and development splits are used only as text-form supervision. For SLURP, train and development instances are constructed at the sentence level, while the test set corresponds to audio-level utterances.
3.3 Noisy evaluation setup
Robustness is tested by adding synthetic babble noise derived from the speech subset of the MUSAN corpus. The paper follows a Kaldi-style augmentation recipe: three to seven randomly selected speech segments are mixed to form the babble background, which is then added to each test utterance at SNR levels of 15, 10, 5, 2.5, and 0 dB.
3.4 Training details
The training recipe is deliberately simple. All trainable LLM or SLM components are fine-tuned for three epochs with AdamW in bfloat16 precision, using four NVIDIA A100 GPUs, a per-device batch size of 2, gradient accumulation of 8, a learning rate of $5.0 \times 10^{-6}$, and a warmup ratio of 0.04. The paper largely follows the training setup of prior text-only adaptation work and does not introduce a more complex multi-stage training scheme.
4. Main Empirical Findings
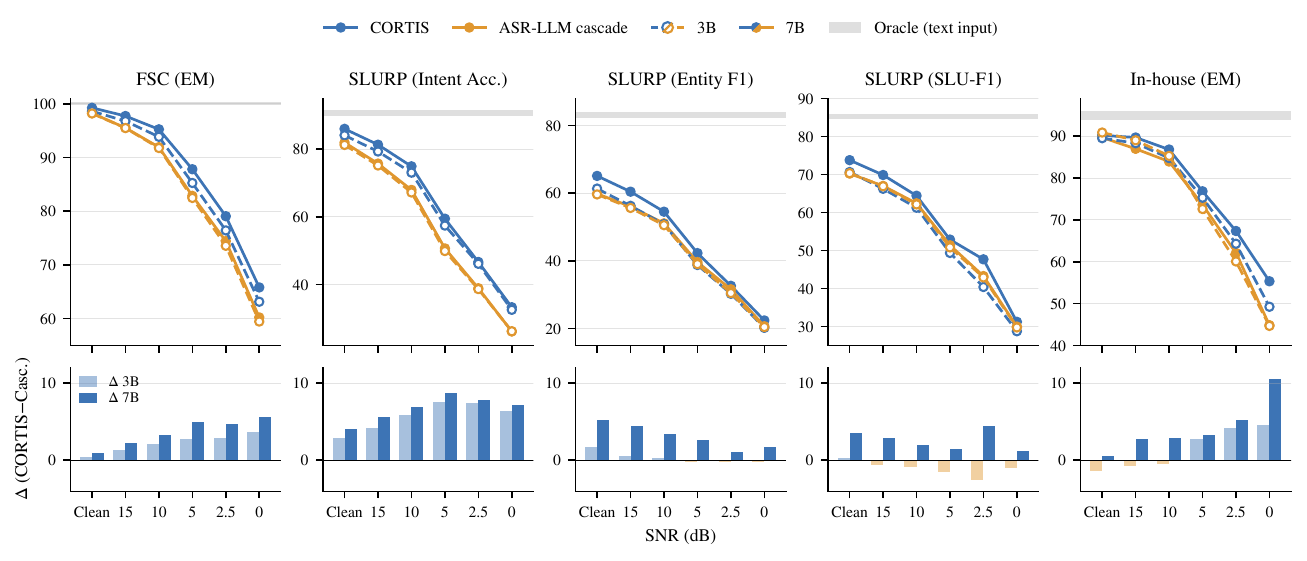
The headline result is that CORTIS is competitive with matched ASR-LLM cascades on clean speech and becomes particularly attractive under acoustic degradation. The benefits are strongest for higher-level semantic prediction: command intent, task scenario, and function-call correctness. The paper repeatedly emphasizes that this advantage is not universal at the slot-level, where exact lexical grounding can still be a challenge.
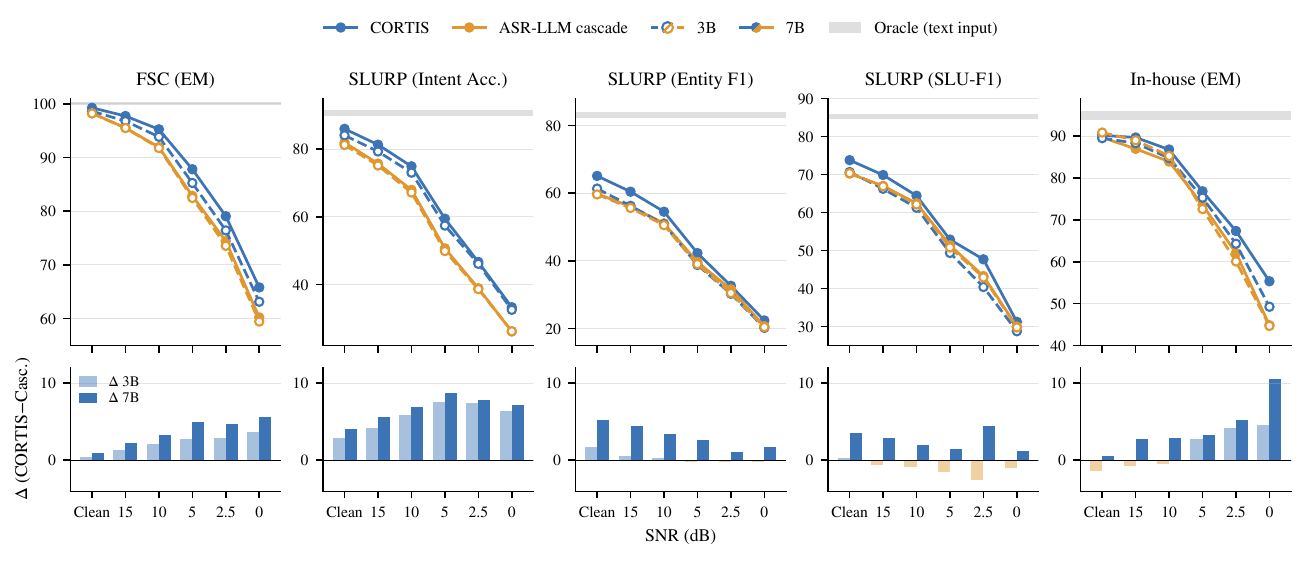
4.1 Selected quantitative results
The table below condenses the paper’s primary metric for each dataset. For SLURP, the table reports intent accuracy, which is the metric where CORTIS shows the clearest and most consistent gains.
| Dataset | Scale | System | Oracle | Clean | 5 dB | 0 dB |
|---|---|---|---|---|---|---|
| FSC | 3B | CORTIS | 100.00 | 98.63 | 85.26 | 63.14 |
| FSC | 3B | ASR-LLM cascade | 100.00 | 98.21 | 82.47 | 59.45 |
| FSC | 7B | CORTIS | 100.00 | 99.26 | 87.82 | 65.81 |
| FSC | 7B | ASR-LLM cascade | 100.00 | 98.26 | 82.86 | 60.22 |
| SLURP intent acc. | 3B | CORTIS | 90.71 | 84.11 | 57.43 | 32.53 |
| SLURP intent acc. | 3B | ASR-LLM cascade | 89.88 | 81.27 | 49.90 | 26.19 |
| SLURP intent acc. | 7B | CORTIS | 91.57 | 86.02 | 59.47 | 33.29 |
| SLURP intent acc. | 7B | ASR-LLM cascade | 91.21 | 81.97 | 50.69 | 26.14 |
| In-house EM | 3B | CORTIS | 95.94 | 89.51 | 75.30 | 49.24 |
| In-house EM | 3B | ASR-LLM cascade | 95.43 | 90.86 | 72.59 | 44.67 |
| In-house EM | 7B | CORTIS | 94.42 | 90.19 | 76.82 | 55.33 |
| In-house EM | 7B | ASR-LLM cascade | 93.91 | 89.68 | 73.60 | 44.84 |
4.2 FSC: consistent gains on full semantic-frame exact match
FSC is the cleanest success case for CORTIS. The paper reports that CORTIS outperforms the cascade across all speech conditions and both model scales. With the 7B backbone, the absolute EM gain of CORTIS grows from 1.00 under clean speech to 5.59 at 0 dB. The 3B model shows the same pattern, with gains widening as the signal becomes noisier.
The interpretation is straightforward: when ASR errors distort a short command, the cascade can map a corrupted transcript to the wrong action or object. Direct speech-based inference is more resilient because it does not force the signal through a potentially error-prone intermediate transcript.
4.3 SLURP: strongest improvements on intent-level semantics, mixed behavior on slot-level details
SLURP is more demanding than FSC because it contains broader linguistic and semantic variation. Here, CORTIS’s clearest advantage is on intent accuracy. For the 7B backbone, the paper reports gains of 4.05 points under clean speech, 8.78 points at 5 dB, and 7.15 points at 0 dB. This is the most explicit evidence in the paper that direct speech-based inference helps preserve the high-level task interpretation even when acoustics deteriorate.
The finer-grained metrics are more mixed. In the 3B setting, CORTIS is better on intent accuracy and entity F1 in clean speech, but the cascade is slightly better on entity F1 and SLU-F1 at some noisy conditions. In the 7B setting, CORTIS is generally stronger on intent accuracy and entity F1, while SLU-F1 remains close between the two systems and can still favor the cascade at some noise levels. The paper’s conclusion from these patterns is careful: CORTIS is especially reliable for high-level semantic prediction, but exact entity grounding is still a weaker point than for transcript-based pipelines.
Concretely, the appendix table shows that for the 7B setting, CORTIS reaches 86.02 intent accuracy on clean speech and 33.29 at 0 dB, compared with 81.97 and 26.14 for the cascade. On entity F1 and SLU-F1, the two systems are closer, with some conditions favoring the cascade. This nuance is important because it shows that the value of CORTIS is not uniform across all SLU metrics.
4.4 In-house product dataset: robustness under acoustic degradation
The in-house product dataset is the paper’s most application-relevant evaluation because it targets function calls in a product-oriented voice-agent setting. Here, CORTIS again shows a robustness advantage under degradation. In the 3B setting, the cascade is slightly better under clean and mild-noise conditions, but CORTIS becomes better at 5 dB and below, reaching a 49.24 EM at 0 dB versus 44.67 for the cascade. In the 7B setting, CORTIS is better across all speech conditions, including clean speech and every noisy setting down to 0 dB.
The paper highlights the 0 dB 7B result in particular: CORTIS improves from 44.84 EM for the cascade to 55.33 EM. That is a substantial gain in a realistic voice-agent task where the model must directly generate the function name and argument values.
4.5 Summary of the main quantitative message
- FSC: CORTIS is consistently better than the cascade at both 3B and 7B, especially as noise increases.
- SLURP: CORTIS is most clearly better on intent accuracy; slot-level metrics are mixed.
- In-house: CORTIS is competitive in clean conditions and increasingly better under noise, especially at 7B.
- Overall: direct speech-based structured-output generation is most compelling when the goal is preserving task semantics under acoustic corruption.
5. Qualitative Analysis
The paper includes qualitative examples that clarify why the two pipelines differ. The recurring failure mode of the cascade is that an ASR error changes a key lexical item and the downstream LLM faithfully reasons over the wrong transcript. CORTIS can sometimes recover the intended command even when the transcript would be misleading.
- FSC example: “Heat down” is transcribed as “Feet down.” The cascade predicts an incorrect action/object pair, while CORTIS recovers the intended command and outputs the correct semantic frame.
- SLURP example: “is it going to rain on monday” becomes “Is it going straight on Monday?” The cascade predicts a transport-related scenario, whereas CORTIS correctly returns the weather scenario with the rain descriptor and date.
- In-house example: “Turn off the screen brightness.” is misrecognized as “turn off this room privately.” The cascade produces the wrong function call, but CORTIS returns the correct brightness-setting call.
The paper also shows a failure mode for CORTIS: when the transcript is already correct, the cascade can still outperform it on a fine-grained slot value. In one SLURP example, both systems recognize the musical-play intent, but CORTIS predicts the wrong genre value (“rock” instead of “rap”). This supports the broader conclusion that CORTIS is strong on semantic abstraction but can still be weaker on exact lexical grounding.
| Gold transcript | ASR hypothesis | ASR-LLM cascade | CORTIS |
|---|---|---|---|
| Heat down | Feet down. | wrong action/object | correct semantic frame |
| is it going to rain on monday | Is it going straight on Monday? | transport scenario | weather scenario with rain and date |
| Turn off the screen brightness. | turn off this room privately. | wrong privacy-mode function | correct brightness-setting function |
| i would like to hear some rap music | I would like to hear some rap music. | correct genre | incorrect genre |
6. Additional Backbone Check: Qwen2-Audio
The appendix includes an additional experiment with Qwen2-Audio-7B using the same text-only adaptation procedure. The main purpose is to test whether the CORTIS idea transfers beyond Qwen2.5-Omni. The reported result is mixed: CORTIS remains competitive with the cascade on FSC and SLURP, but it performs worse on the in-house dataset.
The paper suggests that the weaker in-house performance may reflect a mismatch between Qwen2-Audio and the product-processed audio used by the internal dataset. This is not framed as a definitive diagnosis, but rather as evidence that the success of text-only adaptation depends on the underlying SLM family and its audio interface.
In other words, the method is promising, but not architecture-agnostic. The backbone choice matters.
| Condition | FSC CORTIS | FSC Cascade | In-house CORTIS | In-house Cascade |
|---|---|---|---|---|
| Oracle | 100.00 | 100.00 | 94.92 | 95.94 |
| Clean | 98.44 | 98.08 | 87.82 | 91.54 |
| 0 dB | 62.30 | 59.50 | 39.76 | 44.67 |
This appendix result is useful because it shows that the method can still work with another backbone, but performance may degrade substantially depending on how well the model’s audio pathway matches the domain’s acoustics.
7. Limitations and Scope
The paper is explicit about several limitations, and these matter for interpreting the results.
- Potential benchmark contamination: FSC and SLURP are public datasets, so some utterances or annotations may already have appeared in pretraining data for existing models. The in-house dataset is included partly to reduce this concern.
- Backbone dependence: the main experiments focus on Qwen2.5-Omni backbones. Preliminary Qwen2-Audio results are weaker on the in-house dataset, suggesting that text-only adaptation may not transfer equally well across SLM families.
- Synthetic noise only: robustness is evaluated with babble noise from MUSAN. The paper does not cover reverberation, far-field speech, microphone mismatch, or other real-world acoustic disturbances.
- No mixed adaptation strategy: the paper does not combine text-only tuning with text denoising or a small amount of paired speech data, both of which are plausible future directions.
The ethical note is also straightforward: the in-house dataset was collected internally for product development, does not contain personally identifiable information, and is not released.
8. Bottom-Line Technical Takeaway
CORTIS is a pragmatic adaptation recipe for building spoken voice agents when paired speech-target annotations are expensive. Its main technical contribution is not a new speech encoder or a new structured-decoding algorithm, but a simple training rule: keep the speech stack fixed, fine-tune the language model on text-form task supervision, and rely on pretrained speech-text alignment to transfer the learned task mapping to speech at inference time.
Empirically, this strategy is competitive with a strong ASR-LLM cascade and often better under noisy conditions. The most convincing gains are on command semantics and intent-level understanding, which is exactly the part of the pipeline that matters most for many task-oriented assistants. The main remaining weakness is fine-grained entity grounding, where transcript-based pipelines can still have an edge when ASR is accurate.
For a talking-head or conversational-AI team, the paper’s practical message is clear: if paired speech-target supervision is scarce, text-only adaptation of an SLM is a viable and often robust alternative for structured-output voice agents, especially when the deployment environment includes noisy speech.