S5-TTS
Streaming T5-based Text-to-Speech Synthesis with Limited Lookahead
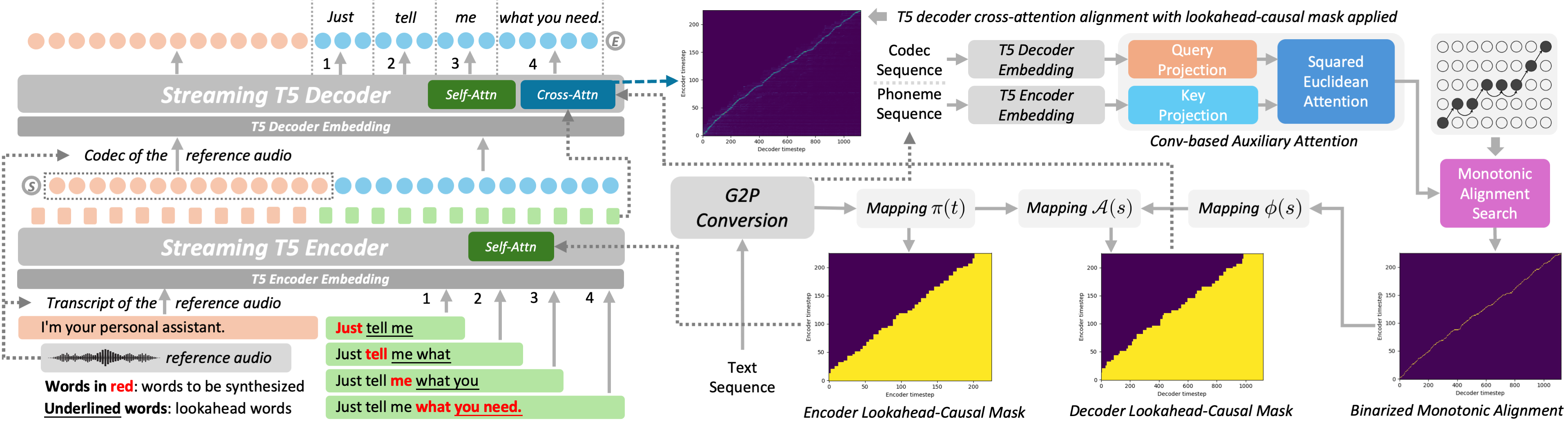
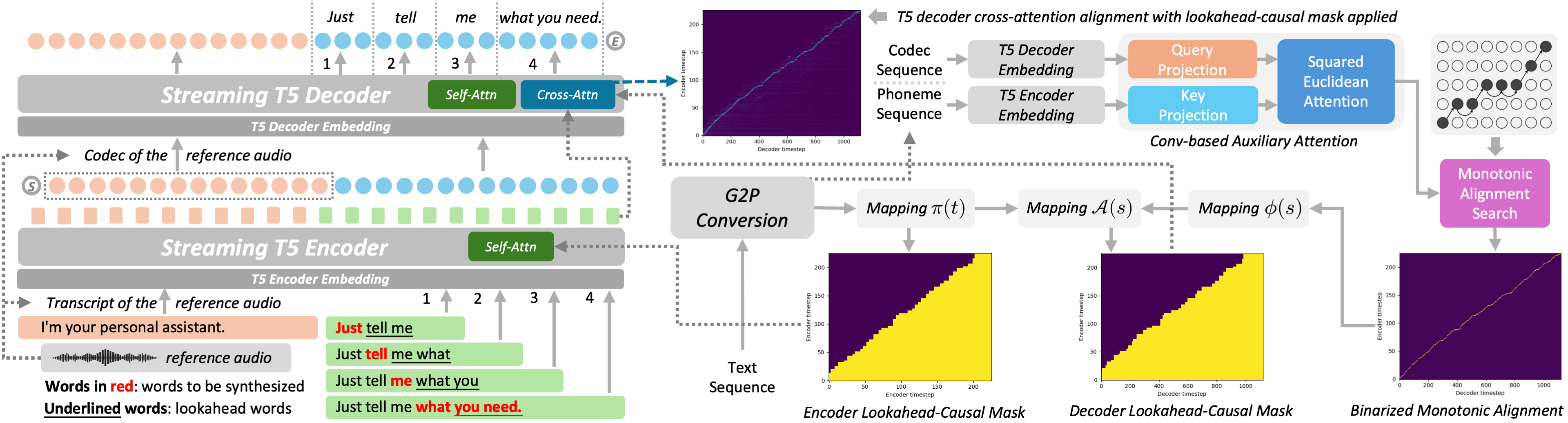
S5-TTS enables streaming, low-latency text-to-speech synthesis by generating speech word-by-word with limited lookahead. It preserves quality and speaker similarity using monotonic alignment and lookahead-causal masks, making it ideal for real-time conversational AI systems.
Demos
These demos demonstrate S5-TTS, a streaming T5-based text-to-speech system that reduces latency by generating speech incrementally with limited lookahead. Evaluate how well it balances naturalness, intelligibility, and speaker similarity compared to full-context T5-TTS and ground truth. Note also the quality improvements achieved by knowledge distillation in the distilled S5-TTS variant.
Links
Paper & demos
Abstract
Streaming text-to-speech synthesis in cascaded LLM-TTS systems still faces latency challenges as most TTS models require full context before initiating generation. We present S5-TTS, a streaming variant of T5-TTS that enables low-latency, word-by-word incremental speech synthesis through encoder-decoder language modeling and monotonic alignment learning. S5-TTS begins generating speech immediately after receiving the first few words, substantially reducing end-to-end response latency. To maintain quality under limited lookahead, we introduce a lookahead-causal masking mechanism with Conv-based auxiliary attention that preserves intelligibility and speaker similarity, and employ interleaved multi-source distillation to further restore naturalness. Experiments show that S5-TTS achieves comparable quality to full-context T5-TTS, supports zero-shot synthesis with high speaker similarity, and significantly reduces end-to-end latency for practical conversational AI systems.
Introduction and problem setting
This paper addresses a specific latency bottleneck in cascaded LLM-to-TTS systems: even when the upstream language model can stream tokens, many text-to-speech models still wait for full-sentence context before starting synthesis. That behavior is a poor fit for conversational agents, where response time matters as much as audio quality. The authors position their work as a streaming extension of T5-TTS, called S5-TTS, that keeps the encoder-decoder T5-style formulation but changes inference and training so that speech can be generated incrementally, word by word, with only a small amount of lookahead.
The key modeling premise is that text-to-speech alignment is nearly monotonic: each region of speech mostly corresponds to a contiguous region of text. The paper leverages this property with monotonic alignment learning and with explicit lookahead-causal masks that restrict what the model may attend to during streaming. The result is meant to preserve the strengths of full-context T5-TTS—naturalness, robustness, and zero-shot speaker conditioning—while allowing the first speech chunk to start as soon as the first few words are available.
The authors also situate the work relative to earlier incremental TTS systems. Prior incremental models showed that limited future text can already recover much of the quality of full-context synthesis, but those systems were often restricted to single-speaker or few-speaker settings and did not reach the zero-shot flexibility of modern encoder-decoder TTS. S5-TTS is presented as a way to bring streaming behavior to a large, zero-shot, T5-based model without giving up much intelligibility or speaker similarity.
Overall architecture
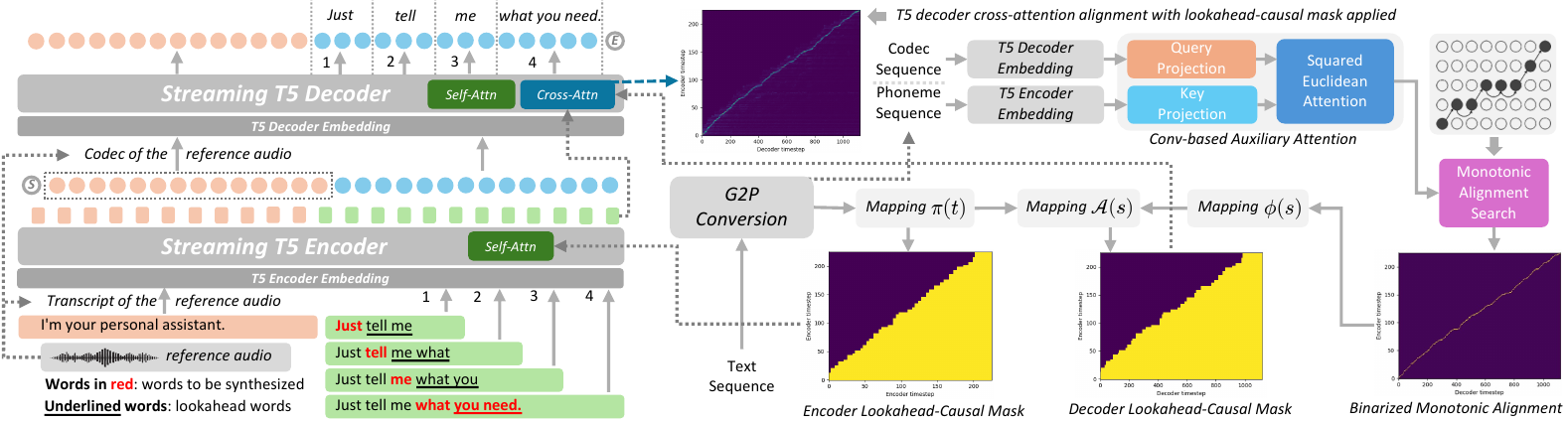
S5-TTS uses a T5-like encoder-decoder architecture. The encoder is a parallel Transformer over phoneme tokens, where text is first converted with G2P and represented in IPA. The decoder is autoregressive over codec tokens from an FSQ audio codec. At each decoding step, the decoder consumes the sum of the embeddings of the previously predicted codec tokens and predicts the next chunk of codec tokens, one token per codebook. In the reported setup, the codec has 8 codebooks and is based on the NeMo pretrained FSQ Mel codec model.
A central design detail is that S5-TTS is conditioned on reference audio during synthesis. The transcript of the reference audio is concatenated with the target text on the encoder side, while the corresponding codec frames are provided as a prompt to the decoder. This lets the model do zero-shot synthesis in the same spirit as T5-TTS: it can imitate speaker characteristics from a reference utterance while generating new content.
The paper reports the model size and codec characteristics used in experiments: S5-TTS has 4 encoder layers, 8 decoder layers, 8 attention heads in each stack, 768-dimensional embeddings, a feed-forward hidden size of 4096, dropout of 0.1, and about 160 million parameters. The audio codec works at 22.05 kHz, produces 86.1 tokens per second, uses 80 bits per token, and corresponds to a bitrate of 6.9 kbps.
Streaming decoding and word-boundary handling
Unlike the full-context baseline, S5-TTS is meant to synthesize in a word-level streaming manner. For each word to be spoken, the encoder processes the current word plus all previous words and a small number of future words, denoted by the lookahead window $k$. The decoder then autoregressively emits the codec chunk associated with that word. The same lookahead setting is also applied to G2P conversion so that the text representation seen by the model is consistent between training and incremental inference.
A practical issue in streaming synthesis is deciding when a word has been fully generated so that decoding can move on to the next word. The paper uses the decoder’s cross-attention as a boundary signal: it monitors the average cross-attention weights across heads at each decoding step and checks whether the most attended encoder position has moved into the lookahead region. When that happens, the current word is treated as complete.
Formally, if $\alpha_s$ is the decoder cross-attention weight vector over encoder steps at decoding step $s$, and $W_j$ is the number of encoder steps associated with word $j$, the paper defines a completion indicator for word $i$ at step $s$ as:
$$c_s^i = \operatorname{argmax}(\alpha_s) > \left(\sum_{j=1}^{i} W_j - 1\right).$$
Once the final target word enters the lookahead window, the model stops using word-completion flags and continues decoding until the final stop token is produced. To stitch the word-level waveform chunks into a continuous waveform, the authors overlap two codec frames and apply crossfading with Hanning-window coefficients.
Lookahead-causal masking
The core streaming mechanism is implemented with lookahead-causal masks in both the encoder and decoder. The main purpose of these masks is to force the model to train under the same information constraints that will exist at inference time. Without such consistency, the model would be accustomed to full context during training and would degrade sharply when only limited future text is available online.
The encoder mask $M^{\mathrm{enc}}$ is applied to self-attention in all encoder layers. For an encoder step $t$ belonging to word $\pi(t)$, the mask allows attention only to the current word, all previous words, and the next $k$ words. In symbolic form:
$$M^{\mathrm{enc}}_{t,t'} = 1 \quad \text{if} \quad t' \in \Bigl(\bigcup_{q=1}^{\pi(t)} W_q\Bigr) \cup \Bigl(\bigcup_{q=\pi(t)+1}^{\min(\pi(t)+k,\,N)} W_q\Bigr),$$
and zero otherwise. Here $N$ is the number of words in the input text. In plain terms, each encoder position can see the current word and a small lookahead band, but not the rest of the sentence.
The decoder mask $M^{\mathrm{dec}}$ is applied to cross-attention in all decoder layers. For a decoder step $s$ associated with word $\mathcal{A}(s)$, the decoder may attend only to encoder positions corresponding to the current word, earlier words, and the same number of lookahead words:
$$M^{\mathrm{dec}}_{s,t} = 1 \quad \text{if} \quad t \in \Bigl(\bigcup_{q=1}^{\mathcal{A}(s)} W_q\Bigr) \cup \Bigl(\bigcup_{q=\mathcal{A}(s)+1}^{\min(\mathcal{A}(s)+k,\,N)} W_q\Bigr).$$
The mapping from decoder step to word index, $\mathcal{A}(s)$, is obtained through an auxiliary alignment predictor described next. The important architectural point is that both encoder and decoder are constrained by the same limited-lookahead policy during both training and inference, which is what makes streaming behavior feasible without a severe train-test mismatch.
Conv-based auxiliary attention and alignment prediction
The decoder-side mask needs a mapping from decoder steps to encoder positions before the actual streaming generation begins. To obtain this mapping, the paper introduces a Conv-based auxiliary attention module. It takes the decoder embedded codec frames $Q$ and encoder embedded phonemes $K$, projects both into a common attention space of dimension $C$, and then computes an alignment score using a scaled negative squared Euclidean distance.
The projections are implemented with a $3 \times 3$ convolution followed by ReLU and then a $1 \times 1$ convolution. After projection, the attention weights are computed as:
$$e_{s,t} = \operatorname{softmax}\!\left(-\delta \sum_{c=1}^{C} \bigl(Q'_{c,s} - K'_{c,t}\bigr)^2\right),$$
where $\delta$ is a scaling factor set empirically to $5 \times 10^{-5}$. The attention matrix is then converted into a binarized monotonic alignment with Monotonic Alignment Search (MAS):
$$\hat{A}_{s,t} = \operatorname{MAS}\!\left(\log e_{s,t}\right).$$
Using the binarized alignment, the paper defines $\phi(s)$, the encoder step aligned to decoder step $s$, and then composes it with the word-to-phoneme mapping $\pi$ to get the word index $\mathcal{A}(s) = \pi(\phi(s))$. During training, the auxiliary attention is jointly optimized with a CTC objective over the target monotonic path $\omega$:
$$\mathcal{L}_{\text{aux}} = \operatorname{CTCLoss}(e, \omega).$$
During inference, this auxiliary module is used once to align the reference audio. After that, the generation-time word progression can be tracked through completion flags, so the model does not need to repeatedly re-estimate the same reference alignment.
Training objective
The main S5-TTS objective combines three terms: a codec-token cross-entropy loss, a CTC loss on the decoder cross-attention matrix to encourage monotonic alignments, and the auxiliary attention loss described above. Using the paper’s notation, the total loss is:
$$\mathcal{L} = \operatorname{CE}\bigl(\operatorname{softmax}(z), y\bigr) + \operatorname{CTCLoss}(\alpha, \omega) + \mathcal{L}_{\text{aux}}.$$
Here $z \in \mathbb{R}^{S \times Q \times V}$ are the decoder logits, $y$ are the ground-truth codec frames, $V$ is the codec vocabulary size, and $\omega$ is the ideal monotonic alignment path. The paper’s design makes the alignment objective explicit rather than relying on cross-attention alone, which is especially important when the model is only allowed to look ahead by one or two words.
Interleaved multi-source distillation
Limited lookahead makes it harder for the student model to preserve naturalness, especially in the earliest generated chunks. To recover quality, the authors use a distillation strategy called Interleaved Multi-Source Distillation, or IMSD. In this setup, T5-TTS serves as teacher and the pretrained S5-TTS becomes the student.
IMSD combines two supervision sources: a paired text-audio dataset $\mathcal{D}_{\text{audio}} = \{(\textit{text}_i, \textit{audio}_i)\}$ and a text-only dataset $\mathcal{D}_{\text{text}} = \{\textit{text}_j\}$. For paired data, the teacher produces soft labels using decoder-side teacher forcing. For text-only data, the teacher decodes autoregressively with sampling. Because text-only teacher outputs can be noisy, the decoded utterances are passed through an ASR filter and only examples with zero WER are retained.
A distinctive detail is that mini-batches from the two sources are interleaved within each gradient accumulation cycle, so their gradients are aggregated before each update. This is the “interleaved” part of IMSD and is meant to make use of both high-quality paired supervision and a larger pool of synthetic speech targets while keeping the supervision reliable.
The distillation loss combines hidden-state matching, logit matching, and a cross-entropy term:
$$\mathcal{L}_{\mathrm{distill}} = \lambda_h\,\operatorname{MSE}\bigl(h^{\mathrm{stu}}, h^{\mathrm{tea}}\bigr) + \lambda_z\,\operatorname{KL}\bigl(z^{\mathrm{stu}} \Vert z^{\mathrm{tea}}\bigr) + \operatorname{CE}\bigl(\operatorname{softmax}(z^{\mathrm{stu}}), y\bigr).$$
The paper uses $\lambda_h = 10.0$ and $\lambda_z = 1.0$. For the synthetic text-only examples, $y$ is the teacher-decoded codec sequence after ASR filtering.
Experimental setup
The main training corpora are the full training splits of LibriTTS and HiFiTTS, totaling 845.04 hours from 2,319 speakers. For distillation, the same speech datasets are combined with conversational text sampled from UltraChat-200k. These text-only sentences are synthesized by the T5-TTS teacher using randomly selected reference audio from the LibriTTS and HiFiTTS training sets, then filtered using the Parakeet-TDT 0.6B ASR model. The resulting distillation set contains 1.3 million utterances and 3,827.50 hours of synthetic speech.
The model is trained on 4 NVIDIA B200 GPUs with batch size 32 and gradient accumulation factor 4, for an effective batch size of 128. Pretraining runs for 250,000 steps with AdamW, a linear warmup to $2 \times 10^{-4}$ over the first 10,000 steps, and cosine decay to $1 \times 10^{-4}$. The distillation fine-tuning stage uses a fixed learning rate of $1 \times 10^{-4}$ for 100,000 steps. The paper states that training is performed in a purely language-modeling manner without reference audio.
At inference time, the model uses multinomial top-$k$ sampling with $k = 80$ and temperature $0.85$. The authors compare S5-TTS mainly against T5-TTS because the two share the same encoder-decoder paradigm and both support zero-shot synthesis, making the comparison more direct than comparisons with earlier incremental systems that were limited to fewer speakers.
Human evaluation is done on Prolific with 20 native English speakers. The authors report MOS, preference tests, and several objective metrics including WER, CER, speaker similarity as reported in the paper, UTMOS, STOI, PESQ, real-time factor, first-chunk latency, and end-to-end latency in a cascaded LLM-TTS pipeline.
Lookahead trade-off: intelligibility, speaker similarity, and naturalness
The first major analysis varies the lookahead window $k$ and measures how much future context is enough to preserve quality. The authors train three S5-TTS variants with $k = 1$, $2$, and $3$, and compare them to full-context T5-TTS and ground truth on unseen speakers from LibriTTS and VCTK. Objective intelligibility is measured with ASR-derived WER and CER; speaker similarity is measured with cosine similarity between WavLM embeddings; and naturalness is approximated by UTMOS.
The main empirical takeaway is that one or two lookahead words are enough to get close to full-context quality, while too much lookahead can actually make things worse. The paper notes that $k = 1$ can even outperform T5-TTS on some intelligibility metrics, likely because the stronger focus on the current word reduces distractions from future context. By contrast, $k = 3$ degrades alignment and yields much higher error rates. Based on both objective metrics and a small preference test, the authors choose $k = 2$ as the default operating point.
| Eval set | Model | k | CER ↓ | WER ↓ | SSIM ↑ | UTMOS ↑ |
|---|---|---|---|---|---|---|
| LibriTTS (unseen) | Ground truth | – | 0.91% | 2.02% | 1.0000 | 3.79 |
| T5-TTS | – | 2.05% | 3.20% | 0.9356 | 3.77 | |
| S5-TTS | 1 | 1.68% | 3.03% | 0.9376 | 3.63 | |
| S5-TTS | 2 | 2.12% | 3.49% | 0.9328 | 3.66 | |
| S5-TTS | 3 | 4.90% | 7.27% | 0.9335 | 3.58 | |
| S5-TTS w/ IMSD | 2 | 1.47% | 2.65% | 0.9340 | 3.72 | |
| VCTK (unseen) | Ground truth | – | 0.56% | 1.82% | 1.0000 | 3.91 |
| T5-TTS | – | 1.27% | 1.63% | 0.9379 | 3.99 | |
| S5-TTS | 1 | 0.98% | 1.51% | 0.9350 | 3.88 | |
| S5-TTS | 2 | 1.09% | 1.80% | 0.9378 | 3.91 | |
| S5-TTS | 3 | 4.02% | 5.70% | 0.9291 | 3.86 | |
| S5-TTS w/ IMSD | 2 | 0.70% | 1.11% | 0.9362 | 3.93 | |
| UltraChat (unseen) | T5-TTS | – | 0.75% | 1.06% | 0.9776 | 4.28 |
| S5-TTS | 2 | 0.29% | 0.97% | 0.9798 | 4.13 | |
| S5-TTS w/ IMSD | 2 | 0.27% | 0.83% | 0.9791 | 4.17 | |
On LibriTTS, the naive S5-TTS with $k = 2$ is close to T5-TTS in CER/WER and speaker similarity, but slightly behind in UTMOS. On VCTK, the same pattern holds: S5-TTS remains very close to the full-context model, and the distilled version improves intelligibility further. On UltraChat, S5-TTS with $k = 2$ slightly beats T5-TTS on CER, WER, and the reported similarity metric, while remaining somewhat lower on UTMOS. After distillation, the model improves again and narrows the naturalness gap.
The paper also reports a human preference test between $k = 1$ and $k = 2$ on 50 paired LibriTTS examples rated by 20 evaluators. The $k = 2$ variant is preferred in 65.9% of comparisons, which is why the authors adopt it for distillation and later evaluation.
Ablation: why the lookahead-causal masks matter
The ablation study on the lookahead-causal masks is especially informative because it exposes the training-test consistency issue directly. Removing both masks causes a major degradation in intelligibility, showing that the streaming constraints are not merely an inference-time hack; the model must be trained under the same partial-context condition to remain stable. Removing only the encoder mask is even worse than removing both masks, because the decoder has been trained to rely on a full-sequence encoder and then encounters missing future context at inference time. Removing only the decoder mask hurts less than removing the encoder mask, but still raises WER and insertion errors.
| Model variant | CER ↓ | WER ↓ | Ins. ↓ | Del. ↓ | Sub. ↓ | SSIM ↑ |
|---|---|---|---|---|---|---|
| S5-TTS | 2.12% | 3.49% | 0.66% | 1.01% | 0.46% | 0.9328 |
| w/o both LCMs | 12.53% | 14.20% | 10.20% | 1.00% | 1.33% | 0.9310 |
| w/o encoder LCM | 33.04% | 40.15% | 26.54% | 2.55% | 3.96% | 0.9281 |
| w/o decoder LCM | 3.41% | 4.92% | 2.32% | 0.36% | 0.73% | 0.9323 |
The most striking outcome is that dropping the encoder mask alone leads to very large WER, substantially worse than removing both masks. The authors explain this as a train-test mismatch: without the encoder LCM, the decoder learns to depend on complete context during training, but that context disappears in streaming inference. This ablation strongly supports the claim that S5-TTS’s streaming behavior is not just a matter of running a full-context model chunk by chunk; the architecture must be explicitly adapted for streaming.
Distillation effects
IMSD is intended to restore the naturalness that is typically lost when a model is constrained by limited lookahead. The reported numbers show that this is indeed the case. On LibriTTS, adding IMSD to the $k = 2$ model reduces WER from 3.49% to 2.65% and raises UTMOS from 3.66 to 3.72. On VCTK, WER improves from 1.80% to 1.11% and UTMOS rises from 3.91 to 3.93. On UltraChat, the distilled model also achieves the best intelligibility among the S5-TTS variants.
The paper notes that SSIM changes little after distillation, suggesting that IMSD primarily improves naturalness and intelligibility rather than dramatically changing speaker similarity. This is consistent with the objective: the teacher supplies better sequence-level supervision, but the student is still constrained to use only limited lookahead at inference time.
Comparison with other TTS systems
The authors also compare the distilled S5-TTS against several representative autoregressive and non-autoregressive TTS systems using the same LibriTTS test utterances. This comparison should be read carefully: the baselines are trained with much more data than S5-TTS, so the point is not to claim a universal state of the art on every metric, but to show that a compact, streaming, zero-shot encoder-decoder model can be competitive.
| Model | Params | Data (h) | WER ↓ | UTMOS ↑ | STOI ↑ | PESQ ↑ | SSIM ↑ |
|---|---|---|---|---|---|---|---|
| S5-TTS w/ IMSD | 160M | 4.67K | 2.65% | 3.72 | 0.179 | 1.075 | 0.9340 |
| E2-TTS | 335M | 100K | 2.82% | 3.65 | 0.137 | 1.071 | 0.9487 |
| FireRedTTS | 400M | 248K | 4.70% | 3.82 | 0.157 | 1.074 | 0.9229 |
| MaskGCT | 315M | 100K | 2.31% | 3.74 | 0.156 | 1.071 | 0.9495 |
| CosyVoice | 300M | 170K | 2.46% | 3.95 | 0.152 | 1.060 | 0.9117 |
The distilled S5-TTS has far fewer parameters and much less training data than the comparison systems, yet it achieves the best STOI and PESQ among the listed models and is competitive on WER and UTMOS. It beats E2-TTS and FireRedTTS on WER, and it is close to MaskGCT on WER while exceeding it on STOI and PESQ. Against CosyVoice it trails on UTMOS but remains competitive on intelligibility. The authors’ framing is therefore practical rather than absolute: the value of S5-TTS is not only in raw synthesis quality, but in getting strong quality with streaming and zero-shot capabilities in a compact architecture.
Subjective quality and latency
MOS and timing results are where the streaming story becomes clearest. The authors evaluate both standalone TTS speed and end-to-end latency in a cascaded system that combines a Llama 3.3 70B LLM running through Ollama at INT4 precision with the TTS back end. For fairness, T5-TTS is also run in a streaming-like way with a fixed chunk size of 30 decoding steps, approximately matching the average step count of S5-TTS on UltraChat, which is 30.2.
The main result is that S5-TTS substantially reduces first-chunk latency and end-to-end latency relative to T5-TTS, while the distilled version recovers much of the subjective quality lost by the naive streaming model. The paper attributes the lower first-chunk latency of the distilled model partly to improved naturalness, which reduces the number of codec frames needed for the initial word.
| Eval set | Model | MOS ↑ | RTF ↓ | FCL ↓ | E2E ↓ |
|---|---|---|---|---|---|
| LibriTTS (unseen) | Ground truth | 3.81 ± 0.065 | – | – | – |
| T5-TTS | 3.75 ± 0.064 | 0.728 | 0.262 | 0.728 | |
| S5-TTS | 3.64 ± 0.067 | 0.616 | 0.181 | 0.354 | |
| S5-TTS w/ IMSD | 3.71 ± 0.062 | 0.609 | 0.169 | 0.343 | |
| UltraChat (unseen) | T5-TTS | 4.21 ± 0.051 | 0.722 | 0.263 | 0.868 |
| S5-TTS | 3.99 ± 0.058 | 0.615 | 0.186 | 0.365 | |
| S5-TTS w/ IMSD | 4.12 ± 0.054 | 0.618 | 0.176 | 0.356 |
On LibriTTS, the MOS gap between T5-TTS and the distilled S5-TTS is only 0.04, and on UltraChat it is 0.09. That is a small subjective penalty for a large latency reduction. The standalone TTS real-time factor also improves, with S5-TTS and S5-TTS plus IMSD both faster than T5-TTS. Most importantly for conversational systems, the end-to-end latency drops from 0.728 to 0.343 seconds on LibriTTS and from 0.868 to 0.356 seconds on UltraChat when moving from T5-TTS to S5-TTS with IMSD.
The paper reports that, in the cascaded setup, S5-TTS with $k = 2$ can begin synthesis after receiving the third word from the LLM, whereas T5-TTS has to wait for the full sentence. That difference is exactly what streaming TTS is supposed to buy: lower perceived response latency, not just faster frame generation once synthesis has already started.
What the paper claims as its main contributions
- S5-TTS adapts a T5-style encoder-decoder TTS model to a true streaming setting, starting speech synthesis after only a few words rather than waiting for the full sentence.
- It introduces lookahead-causal masking in both encoder and decoder, plus a Conv-based auxiliary attention module, to preserve alignment quality under limited future context.
- It uses IMSD, an interleaved multi-source distillation procedure that combines paired speech data and filtered text-only synthetic data, to recover naturalness under streaming constraints.
- It shows that a small lookahead of $k = 2$ is a good operating point: quality remains close to T5-TTS, while end-to-end latency drops substantially.
- It demonstrates competitive zero-shot synthesis on unseen speakers, including LibriTTS, VCTK, and UltraChat evaluation settings.
Reported limitations and trade-offs
The paper does not include a dedicated limitations section, but the reported experiments make the trade-offs clear. First, lookahead is a real tuning knob: too little context can hurt naturalness, while too much future context can worsen intelligibility and alignment. Second, the streaming model’s quality is sensitive to the consistency between training and inference, which is why the lookahead-causal masks are essential. Third, although IMSD largely recovers MOS and intelligibility, the distilled S5-TTS still does not always match T5-TTS on every perceptual metric, and on some datasets the full-context model retains a subjective quality advantage.
A second practical limitation is that the model depends on auxiliary alignment machinery and on word-level streaming assumptions. In other words, the system is not just a drop-in replacement for arbitrary token-streaming text; it relies on G2P, word segmentation, and monotonic alignment behavior that are natural for TTS but still need to hold in practice. Finally, the evaluation is centered on English speech datasets and a small human-evaluation panel, so the paper does not claim broad multilingual coverage or exhaustive robustness analysis beyond the reported test sets.
Conclusion
The paper’s main message is that streaming, low-latency TTS does not require abandoning strong encoder-decoder LLM-style modeling. By enforcing lookahead-causal attention, using monotonic alignment supervision, and applying multi-source distillation, S5-TTS brings T5-based zero-shot synthesis into a streaming regime with much lower latency and only modest quality loss. The reported results show that $k = 2$ is enough to get close to full-context performance, while the distilled model further narrows the gap in MOS and improves efficiency. For conversational AI systems that need to speak promptly as text arrives, this is a practical and well-supported design direction.