ProsoCodec
ProsoCodec: Prosody-Oriented Speech Codec for Voice Conversion
ProsoCodec is a prosody-oriented speech codec designed for voice conversion. By conditioning on text and speaker embeddings, it isolates and preserves residual prosody, improving prosody preservation and reducing source timbre leakage during voice conversion.
Links
Paper & demos
Abstract
Neural speech codecs efficiently compress speech and have become a foundation for speech generation, but they are typically learned as holistic representations that intertwine linguistic content, speaker identity, and prosody. While this design is effective for zero-shot voice cloning, it hinders downstream tasks that require prosody preservation or transfer, such as voice conversion. To address this, we introduce ProsoCodec, a prosody-oriented speech codec that models prosody as a conditional residual rather than as a disentangled stream. Specifically, by conditioning both the encoder and decoder on text and speaker embeddings as prefix tokens, the discrete bottleneck is encouraged to capture prosodic variation not explained by content and speaker. To further preserve prosody, we use the low-frequency mel band and train the model on paired same-speaker utterances. Experiments on voice conversion show improved prosody preservation and reduced source-timbre leakage.
Introduction and problem setting
The paper studies a mismatch between the way most neural speech codecs are trained and the needs of voice conversion. Standard codecs are optimized to reconstruct speech as faithfully as possible under a low bitrate, so their discrete latents typically entangle linguistic content, speaker identity, and prosody. That entanglement is acceptable for zero-shot voice cloning, where the goal is to reproduce the reference signal holistically, but it becomes a liability for voice conversion, where the desired output should preserve the source utterance's content and prosodic variation while adopting a different target speaker timbre.
The paper argues that prosody should not be treated as a fully disentangled, speaker-independent stream. Instead, prosody is context dependent: it varies with both the linguistic content and the speaker. Based on that observation, the authors propose ProsoCodec, a prosody-oriented codec that models prosody as a conditional residual. The core idea is to condition the codec on explicit text and speaker priors so that the discrete bottleneck is forced to represent what remains unexplained by those priors, namely prosodic variation such as intonation and rhythm.
The method is designed specifically for high-quality zero-shot voice conversion. It uses pretrained ASR and speaker-verification features, a discrete bottleneck based on binary spherical quantization, a diffusion-style decoder, low-frequency mel input biasing, and a dual-utterance training strategy to reduce prompt-style leakage. Across the reported experiments, these choices improve source prosody preservation and reduce source-timbre leakage while maintaining strong speaker similarity to the reference.
High-level contributions
- It introduces ProsoCodec, a generative speech codec that explicitly conditions on text and speaker identity so that the discrete code focuses on residual prosodic information rather than re-encoding content and timbre.
- It proposes a dual-utterance training strategy that pairs utterances from the same speaker but different utterance instances, making it harder for the model to copy prompt-level style directly and thereby improving prosody preservation in voice conversion.
- It adds low-frequency mel-band input biasing and a carefully tuned discrete bottleneck to trade off reconstruction fidelity against source-style preservation in conversion.
- It reports a broad evaluation covering objective metrics, MOS-style subjective evaluation, ablations on conditioning and training design, and bottleneck configuration sweeps.
Method overview
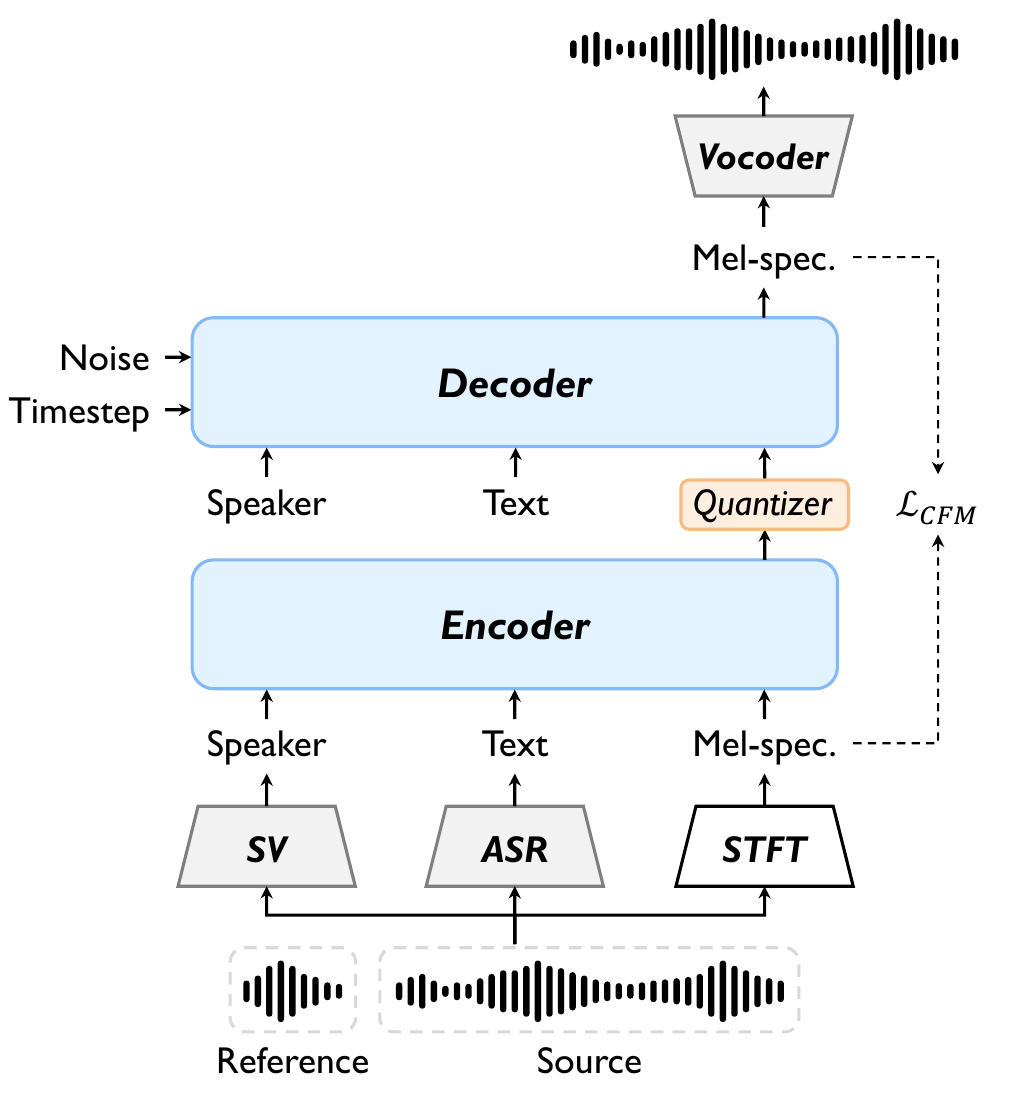
ProsoCodec follows an encode-quantize-decode pipeline built on top of a diffusion autoencoder style architecture. During training, the model receives two utterances from the same speaker. The source utterance is intended to provide the prosodic content to preserve; the reference utterance is used as a prompt to anchor the target timbre. During inference, the source and reference are from different speakers for voice conversion.
The model separately encodes the source and reference speech into discrete token sequences. The decoder then reconstructs the converted speech from the source tokens, while the reference prompt and its speaker embedding steer the output toward the target voice. The explicit text transcript and speaker embedding are injected as prefix tokens in both the encoder and decoder so that the token bottleneck can devote capacity to residual prosodic information.
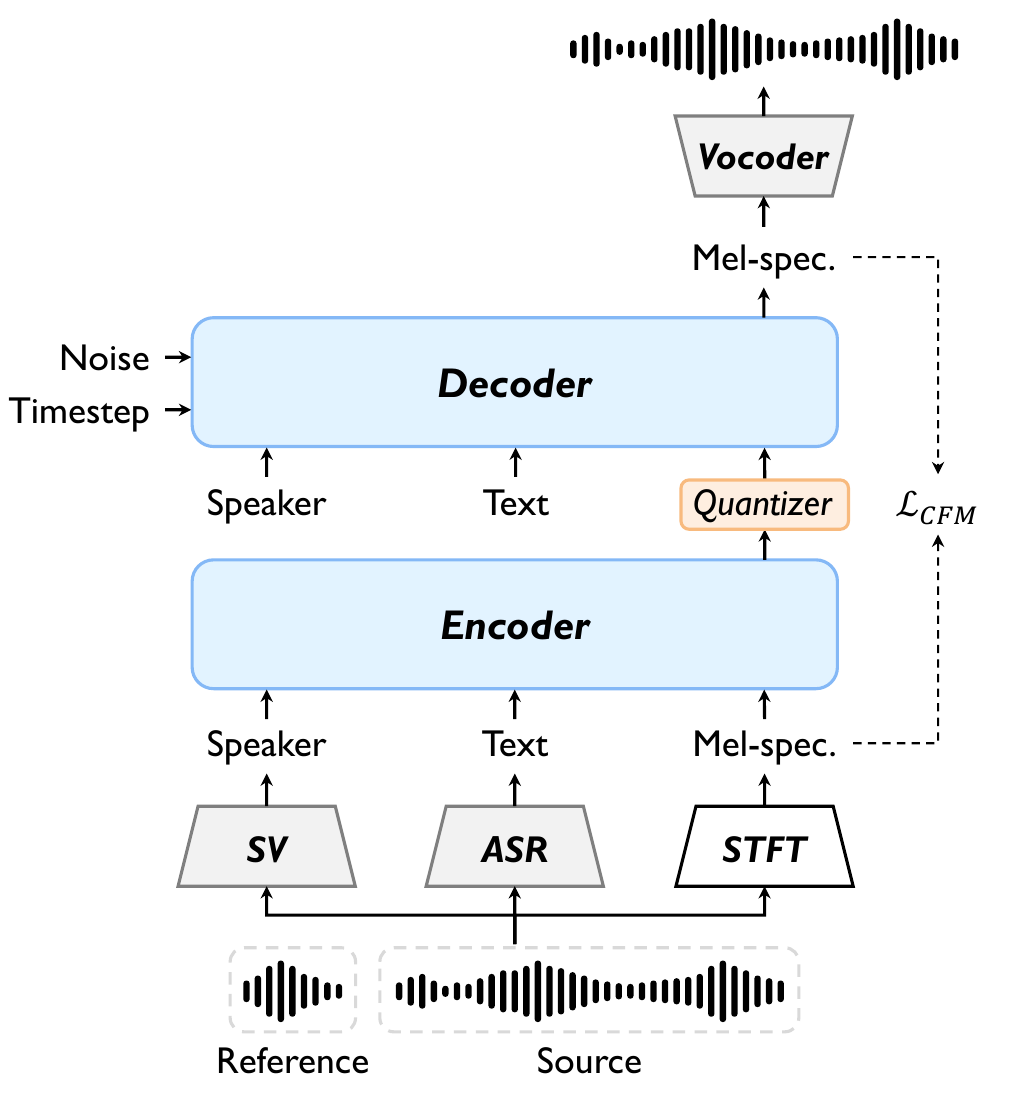
Text and speaker priors
The authors rely on pretrained external systems to provide robust priors. Transcripts are obtained from a pretrained ASR model, tokenized into subwords, embedded, and passed through an MLP-based text encoder to produce a sequence of text embeddings $ \mathbf{e}_{\text{txt}} \in \mathbb{R}^{L \times D}$, where $L$ is transcript length and $D$ is the model dimension. Speaker identity is extracted from a pretrained speaker-verification model and projected through an MLP-based speaker encoder to produce an utterance-level embedding $\mathbf{e}_{\text{spk}} \in \mathbb{R}^{1 \times D}$.
These priors are not used as the target representation themselves. Instead, they are used to strip away predictable content and identity information from the codec bottleneck, pushing the latent tokens toward the residual component that remains after accounting for text and speaker.
Prior-guided encoder
The encoder first computes a mel-spectrogram from the waveform, then linearly projects it into the model dimension as $\mathbf{e}_{\text{mel}} \in \mathbb{R}^{T \times D}$, with $T$ denoting temporal length. The speaker and text embeddings are prepended as prefix tokens and concatenated with the mel sequence:
$$\mathbf{e} = [\mathbf{e}_{\text{spk}}; \mathbf{e}_{\text{txt}}; \mathbf{e}_{\text{mel}}], \quad \mathbf{e} \in \mathbb{R}^{(1 + L + T) \times D}.$$
A Transformer encoder with bidirectional self-attention processes the concatenated sequence. The output corresponding to the mel portion is sliced out as the guided acoustic representation:
$$\mathbf{h} = \operatorname{Encoder}(\mathbf{e}), \quad \mathbf{h}' = \mathbf{h}_{1+L:1+L+T}.$$
The use of prefix tokens is central to the design: the model can interpret the acoustic frames in light of the transcript and speaker identity rather than having to infer them implicitly from the waveform alone.
Discrete bottleneck and binary spherical quantization
To force the representation to discard redundant information, the paper inserts a strict discrete bottleneck. The continuous guided representation $\mathbf{h}'$ is first temporally interpolated to control the token rate and then quantized with binary spherical quantization (BSQ). The quantizer projects features to an $\ell_2$-normalized hypersphere and binarizes them, yielding a discrete code sequence $\mathbf{h}_q \in \{-1,1\}^{T' \times d}$ after interpolation, where $T'$ is the quantized sequence length and $d$ is the projected dimension.
The authors emphasize that the bottleneck is not meant to preserve all acoustic detail. Instead, it should store the structural prosodic information that is not already explained by text and speaker priors. In this framing, the bottleneck becomes a residual prosody carrier.
Diffusion-based decoder
Reconstruction is handled by a diffusion decoder based on a Diffusion Transformer (DiT). The decoder receives the noisy mel input, the quantized latent representation, and the same text and speaker prefixes used by the encoder. A diffusion timestep embedding is injected into every layer through adaptive layer normalization, allowing the network to model the denoising process at different noise levels.
The paper defines the diffusion training input by sampling Gaussian noise $\boldsymbol{\epsilon}$ and interpolating between clean mel-spectrogram $\mathbf{x}$ and noise:
$$\mathbf{x}_t = t\mathbf{x} + (1-t)\boldsymbol{\epsilon}, \quad t \sim \mathcal{U}(0,1).$$
To match the inference setting, where a reference prompt is available, the model also applies random span masking $\mathbf{m} \in \{0,1\}^T$ and forms a masked noisy input:
$$\tilde{\mathbf{x}}_t = \mathbf{m} \odot \mathbf{x}_t + (1-\mathbf{m}) \odot \mathbf{x}.$$
The quantized codes are projected and interpolated to the mel length, then combined with the noisy mel features before being passed to the decoder as prefix-conditioned input:
$$\mathbf{e} = [\mathbf{e}_{\text{spk}}; \mathbf{e}_{\text{txt}}; \mathbf{e}_{\text{noisy}} + \mathbf{e}_q].$$
The decoder output is projected to predict the diffusion velocity field, and training uses a flow-matching objective to align the predicted field with the target $\mathbf{x} - \boldsymbol{\epsilon}$.
Training objective
The encoder, quantizer, and decoder are trained end-to-end with conditional flow matching:
$$\mathcal{L}_{\mathrm{CFM}} = \mathbb{E}_t \left\| v_t(\mathbf{x}_t \mid \mathbf{e}, \theta) - u_t(\mathbf{x}_t) \right\|^2,$$
where $\theta$ denotes the DiT decoder parameters, $v_t$ is the predicted vector field, and $u_t$ is the target vector field. The paper frames this as a way to reconstruct high-fidelity mel-spectrograms while keeping the discrete representation focused on the remaining prosodic variation.
Training strategies for prosody preservation
A key practical issue is prompt-style leakage: if the prompt and source are the same utterance, the decoder can simply copy prompt-level style, which undermines the goal of preserving source prosody. To mitigate this, the authors introduce a dual-utterance training strategy. During training, they sample paired utterances from the same speaker, using one as the prompt and the other as the source. This makes it harder for the model to rely on exact utterance-level copying and encourages it to preserve the source prosodic pattern at inference time. The paper alternates this strategy with random span masking during training.
The other major biasing choice is to feed only the low-frequency mel band to the encoder. The rationale is that prosodic cues live largely in lower-frequency regions, while the full-band mel input can tempt the bottleneck to encode more fine-grained spectral detail. In contrast, the decoder prompt uses the full-band mel-spectrogram to better provide speaker characteristics.
Inference procedure
At inference time for voice conversion, the source and reference speech are encoded separately into discrete token sequences. The decoder then synthesizes the output conditioned on the source transcript, the source tokens, and the reference speaker embedding. The reference speech, along with its transcript and tokens, is used as a prompt to support in-context consistency and target timbre adoption.
The paper’s framing is that the codec should preserve the source prosodic contour while the prompt should supply only the target timbre. The figure and the analysis show that the training setup is designed to reduce the tendency of prompt-based generation to overwrite source prosody.
Experimental setup
Datasets and evaluation protocol
Training is performed on LibriTTS, a 585-hour, 24 kHz read-speech corpus containing 2,456 speakers. Evaluation uses the LibriTTS test-clean and test-other splits, plus VCTK to test out-of-domain generalization. From each evaluation set, the authors randomly sample 1,000 utterances with durations between 2 and 8 seconds.
For each sample, they choose a same-speaker reference prompt for speech resynthesis and a different-speaker reference prompt for zero-shot voice conversion. This allows them to evaluate both reconstruction-style behavior and speaker conversion behavior under matched test conditions.
Implementation details
Speech is converted to a mel-spectrogram with 128 mel filter banks, an 80 ms window, and a 20 ms hop, corresponding to a 50 Hz frame rate. The paper uses pretrained Qwen3-ASR for transcripts and CAM++ for speaker embeddings. ProsoCodec is built from a Transformer encoder and a DiT decoder, both initialized from TaDiCodec for efficient training.
The encoder has 8 layers and the decoder has 16 layers. Both use hidden size 1024, intermediate size 4096, and 16 attention heads. Optimization uses AdamW with learning rate $2 \times 10^{-5}$, $\beta_1 = 0.9$, $\beta_2 = 0.999$, and weight decay $0.01$. The learning rate is linearly warmed up for 10k updates, and training runs for 150k updates with a global batch size of 160 seconds.
At inference, the model generates mel-spectrograms using 32 Euler ODE sampling steps and converts them to 24 kHz waveforms with a Vocos vocoder.
Evaluation metrics
The paper reports both subjective and objective metrics. Subjective evaluation is based on MOS tests collected from 15 listeners per subset, with 10 randomly sampled utterances rated on a 5-point Likert scale. Three MOS-style criteria are used:
- S-MOS: speaker similarity to the reference.
- P-MOS: prosody similarity to the source.
- N-MOS: overall naturalness.
Objective evaluation includes WER computed from Whisper-large-v3 transcripts, SIMr as cosine similarity between reference and synthesized speaker embeddings using WavLM-Large, SIMs as source-versus-converted speaker similarity where lower is better, RMSE over log-scaled $f_0$ extracted by Harvest, and UTMOS as an automatic naturalness predictor.
Main results
The principal comparison is against several open-source voice conversion systems: DDDM-VC, HierSpeech++, FACodec, Seed-VC, UniAudio, and Vevo. The reported table is evaluated on a merged set containing LibriTTS test-clean, test-other, and VCTK. The broad conclusion is that ProsoCodec achieves the best overall balance between content preservation, target speaker similarity, source-prosody retention, and low source-timbre leakage.
| Model | $WER\downarrow$ | $SIM_r\uparrow$ | $SIM_s\downarrow$ | $S$-MOS$\uparrow$ | $RMSE\downarrow$ | $P$-MOS$\uparrow$ | $UTMOS\uparrow$ | $N$-MOS$\uparrow$ |
|---|---|---|---|---|---|---|---|---|
| Source Speech | 3.668 | 0.090 | 1.000 | - | 0.000 | - | 3.897 | 4.253 ± 0.136 |
| DDDM-VC | 9.186 | 0.297 | 0.296 | 3.309 ± 0.139 | 0.472 | 3.012 ± 0.174 | 3.624 | 2.006 ± 0.152 |
| UniAudio | 9.076 | 0.276 | 0.178 | 2.809 ± 0.175 | 0.470 | 2.475 ± 0.163 | 3.631 | 3.006 ± 0.174 |
| HierSpeech++ | 7.568 | 0.381 | 0.312 | 3.494 ± 0.148 | 0.461 | 3.389 ± 0.170 | 3.869 | 2.679 ± 0.167 |
| FACodec | 5.454 | 0.354 | 0.347 | 3.247 ± 0.169 | 0.455 | 3.364 ± 0.193 | 3.544 | 2.302 ± 0.172 |
| Seed-VC | 5.078 | 0.531 | 0.239 | 4.210 ± 0.124 | 0.473 | 3.463 ± 0.156 | 3.712 | 3.611 ± 0.163 |
| Vevo | 4.826 | 0.478 | 0.243 | 4.130 ± 0.139 | 0.464 | 3.506 ± 0.155 | 3.800 | 4.056 ± 0.144 |
| ProsoCodec | 4.451 | 0.565 | 0.167 | 4.167 ± 0.134 | 0.428 | 3.852 | 3.853 | 4.000 ± 0.148 |
The reported numbers show several important patterns. ProsoCodec achieves the best WER, indicating that source linguistic content is preserved more reliably than in the compared methods. It also obtains the highest $SIM_r$ and the lowest $SIM_s$, suggesting stronger target-speaker adoption with less leakage from the source speaker. For prosody, it achieves the best RMSE and the best P-MOS, showing that its residual prosody modeling is effective. Subjectively, its S-MOS is near the top, and its naturalness is competitive, though not the absolute best on every subjective metric.
In the discussion of the table, the authors attribute these gains to the combination of explicit text and speaker conditioning, prompt-based conversion with dual-utterance training, and low-frequency input biasing.
Ablation studies
Component ablation
The first ablation study incrementally removes key design components on LibriTTS test-clean. The results support the paper's central claims: each component helps steer the bottleneck toward prosody while maintaining conversion quality.
| Method | $WER\downarrow$ | $SIM_r\uparrow$ | $SIM_s\downarrow$ | $RMSE\downarrow$ | $UTMOS\uparrow$ |
|---|---|---|---|---|---|
| Source Speech | 3.921 | 0.081 | 1.000 | 0.000 | 4.091 |
| ProsoCodec | 4.684 | 0.608 | 0.168 | 0.376 | 3.978 |
| minus low-frequency mel | 4.810 | 0.585 | 0.192 | 0.386 | 4.004 |
| minus dual-utterance training | 5.630 | 0.634 | 0.166 | 0.421 | 3.884 |
| minus speaker conditioning | 6.793 | 0.600 | 0.186 | 0.397 | 3.891 |
| minus text conditioning | 86.601 | 0.569 | 0.108 | 0.434 | 3.569 |
The ablations indicate the following:
- Low-frequency mel input matters: using the full-band mel-spectrogram degrades WER, speaker similarity, source-speaker leakage, and RMSE relative to the baseline, consistent with the claim that low-frequency input biases the bottleneck toward prosody rather than detailed spectral reconstruction.
- Dual-utterance training matters: removing it yields noticeably worse RMSE and WER, supporting the paper's argument that same-speaker paired training prevents the model from simply copying prompt style.
- Speaker conditioning matters: without explicit speaker priors, target timbre adoption degrades and source leakage rises.
- Text conditioning is critical: removing transcript conditioning causes WER to explode to 86.601, showing that the codec depends on explicit linguistic guidance to maintain content under the discrete bottleneck.
Bottleneck configuration sweep
The second ablation varies the token frame rate, codebook size, and bitrate. The key takeaway is that stronger reconstruction does not automatically yield better voice conversion. More bitrate improves resynthesis, but it also encourages the bottleneck to retain more acoustic detail and thus increases source-timbre leakage.
| FR (Hz) | CS | BR (bps) | Resynthesis | Voice Conversion | |||||
|---|---|---|---|---|---|---|---|---|---|
| $WER\downarrow$ | $SIM\uparrow$ | $RMSE\downarrow$ | $WER\downarrow$ | $SIM_r\uparrow$ | $SIM_s\downarrow$ | $RMSE\downarrow$ | |||
| 25 | 4096 | 300 | 4.28 | 0.72 | 0.21 | 4.49 | 0.56 | 0.20 | 0.36 |
| 12.5 | 16384 | 175 | 4.54 | 0.71 | 0.22 | 4.71 | 0.60 | 0.18 | 0.37 |
| 12.5 | 4096 | 150 | 4.30 | 0.71 | 0.22 | 4.68 | 0.61 | 0.17 | 0.38 |
| 12.5 | 1024 | 125 | 4.57 | 0.70 | 0.22 | 4.91 | 0.62 | 0.16 | 0.38 |
| 6.25 | 4096 | 75 | 4.85 | 0.69 | 0.23 | 6.17 | 0.64 | 0.14 | 0.41 |
| Zero-Shot TTS | 5.85 | 0.67 | 0.29 | 6.04 | 0.68 | 0.11 | 0.48 | ||
The authors choose the $12.5$ Hz, $4096$ codebook, $150$ bps setting because it offers a good compromise between reconstruction and conversion. Higher-rate settings improve resynthesis but do not translate into better voice conversion. Very low-rate settings reduce source leakage but damage overall quality. The zero-shot TTS-style baseline without codec tokens illustrates the opposite extreme: it can follow the prompt speaker well, but it does not reproduce source prosody faithfully.
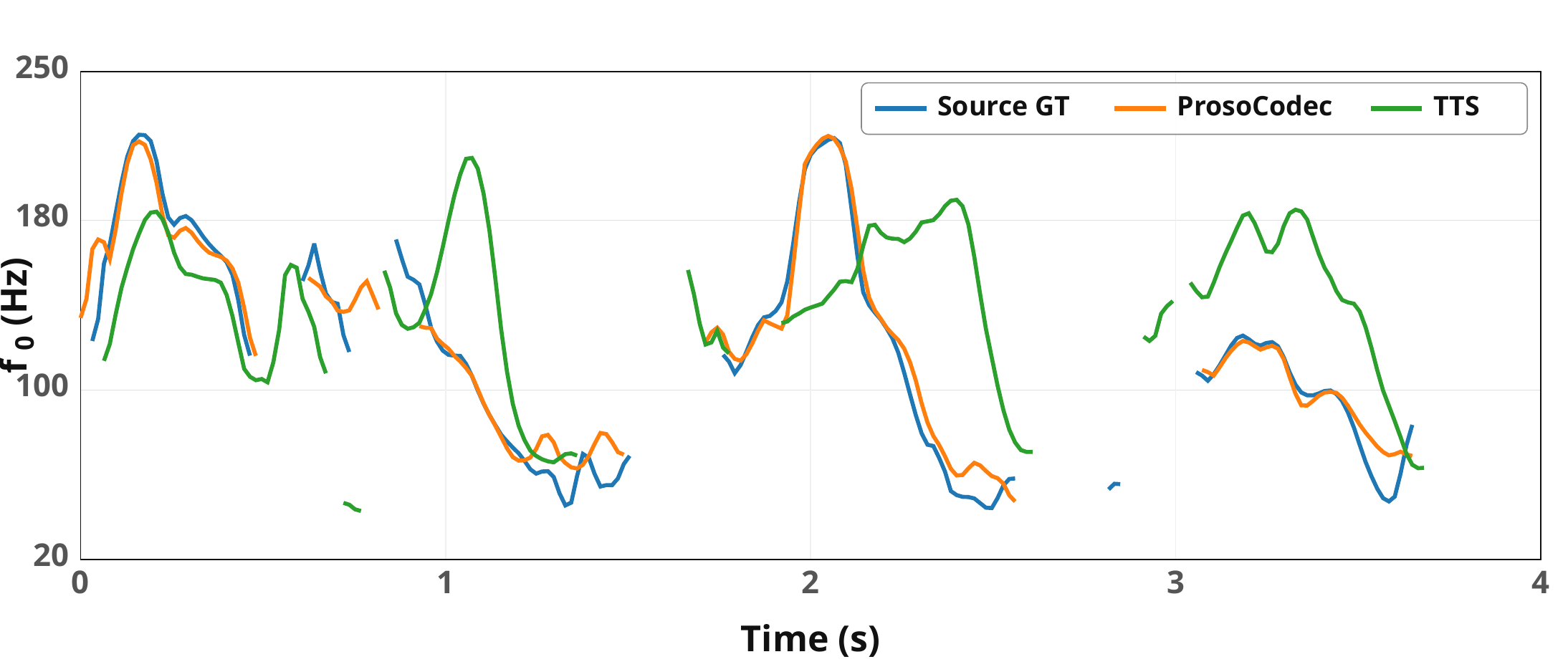
Analysis of prosody behavior
The paper includes a pitch-contour comparison that highlights the difference between ProsoCodec and a codec-free zero-shot TTS-style baseline. ProsoCodec closely matches the source $f_0$ trajectory in resynthesis, whereas the model without codec tokens tends to follow prompt-driven or generic text-driven prosody instead of the source's fine-grained intonation. This qualitative result is used to support the claim that ProsoCodec is modeling prosody as a residual carried by the discrete bottleneck, rather than leaving it to the prompt alone.
What the paper claims is novel
The paper's novelty is not a new speech codec objective in the abstract, but a specific reframing of codec learning for voice conversion. Rather than attempting fully disentangled prosody extraction, it uses explicit, reliable side information—text and speaker embeddings—to subtract away what is already known, leaving the codec to encode a residual prosodic signal. This is implemented with a prefix-conditioned Transformer encoder, a BSQ bottleneck, and a diffusion decoder trained with flow matching.
Another important design choice is the move from conventional same-utterance prompting to a dual-utterance same-speaker setup. The authors argue that this makes prompt style harder to copy and forces the model to generalize the target timbre without overwriting source prosody. Together with the low-frequency mel restriction, this gives the codec a strong inductive bias toward prosodic content.
Limitations and scope, as reflected in the paper
The paper does not include a dedicated limitations section, but its experiments make the main trade-off explicit: there is a tension between reconstruction fidelity and voice conversion behavior. Increasing bitrate helps resynthesis, but can worsen source-timbre leakage and reduce conversion quality. Conversely, overly aggressive compression hurts both content fidelity and prosody preservation. The selected operating point reflects this balance rather than an absolute optimum on every metric.
A second scope limitation is that the method depends on strong external priors: it uses pretrained ASR for transcripts and pretrained speaker verification for speaker embeddings. The paper positions this as a practical advantage, since those features are now readily available and more reliable than learning them implicitly inside the codec, but it also means the method assumes access to those auxiliary models.
Finally, the evaluation is centered on read-speech corpora and zero-shot conversion settings over LibriTTS and VCTK. The paper does not report broader stress tests beyond these datasets, nor does it provide a separate failure-analysis section. What it does establish is that, within this evaluation regime, the method improves prosody preservation and reduces source-timbre leakage relative to the compared baselines.
Conclusion
ProsoCodec is presented as a prosody-oriented speech codec for voice conversion. Its central insight is to treat prosody as a residual signal conditioned on text and speaker identity, rather than as a fully independent factor. By combining prefix conditioning, binary quantization, low-frequency mel biasing, and dual-utterance training, the model is trained to place prosodic variation into the discrete bottleneck while suppressing redundant content and speaker information. The reported experiments show that this design yields strong content preservation, improved target speaker matching, lower source leakage, and better prosody retention than the compared baselines.