Moshi-Face
Integrating Facial Generation into Full-Duplex Spoken Dialogue Systems
Moshi-Face extends full-duplex spoken dialogue by adding real-time facial motion generation synchronized with speech. It uses discrete tokens for 3D face motion, enabling natural low-latency audiovisual dialogue without losing semantic quality.
Links
Paper & demos
Code & resources
Abstract
Full-duplex spoken dialogue models, such as Moshi, enable natural, low-latency voice conversations. However, they remain limited to the audio modality, lacking the facial expressions that are integral to human communication. We present Moshi-Face, the first full-duplex dialogue model that jointly processes the user's audio and facial input while simultaneously generating speech and facial motion. We first construct a vector-quantized variational autoencoder (VQ-VAE) as a face codec that encodes 3D head meshes extracted from facial videos into compact discrete tokens, referred to as face tokens, and conversely reconstructs 3D meshes from these tokens. We then extend Moshi with a Face Transformer module that generates face tokens non-autoregressively, enabling Moshi-Face to produce synchronized audio and face tokens in real time. Experiments show that Moshi-Face achieves audiovisual alignment at low latency while preserving the dialogue quality of the original audio-only model.
Introduction and motivation
The paper addresses a gap between full-duplex spoken dialogue systems and the multimodal nature of human conversation. Existing full-duplex models such as Moshi support low-latency, simultaneous speech interaction, but they are limited to the audio channel. The authors argue that this leaves out facial behavior — lip motion, head motion, and facial expressions — that is central to face-to-face dialogue. In contrast to turn-based multimodal dialogue systems, a true full-duplex conversational agent must be able to consume and produce audio and facial motion concurrently.
The core contribution is Moshi-Face, which extends Moshi with a face generation pathway so the system can jointly process the user's audio and facial input while simultaneously generating the system's speech and facial motion in real time. The paper positions Moshi-Face as the first full-duplex dialogue model to do this jointly, using a discrete token representation for 3D facial motion that mirrors the audio-token interface already used by Moshi.
The high-level claim is not only that face generation is possible in a full-duplex setting, but that it can be added without collapsing the dialogue model's semantic quality. The experiments are designed to test two questions: whether the generated facial motion is synchronized with speech, and whether the original dialogue quality of Moshi is preserved after extending the model.
Overall architecture
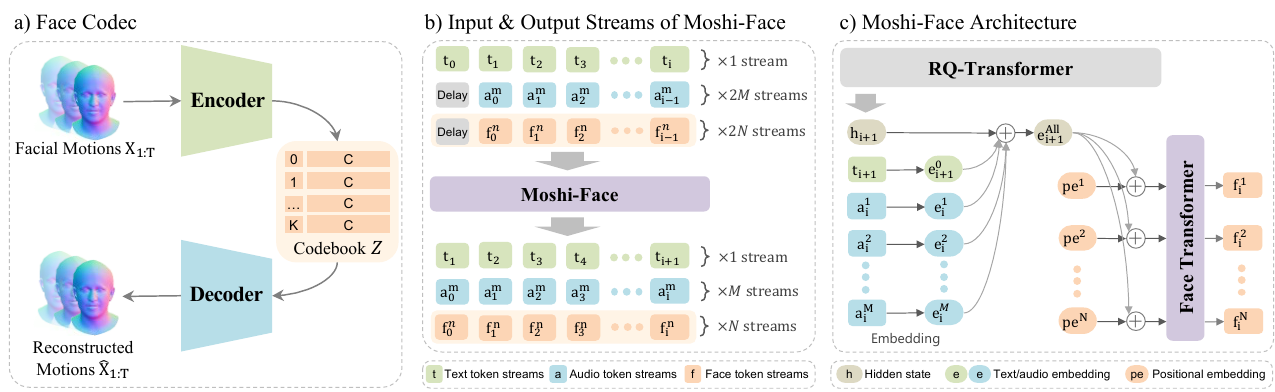
Moshi-Face is built by adding a face token stream to the existing Moshi text and audio token streams. At each timestep the system operates at 12.5 Hz, and the token interface is deliberately aligned across modalities so that face generation can happen in the same streaming regime as speech generation.
- Text stream: $1$ input stream and $1$ output stream. The text token $t_i$ corresponds to the system's inner-monologue content to be spoken.
- Audio streams: $2M$ input streams and $M$ output streams, with $M = 8$. Each speaker is represented by eight audio tokens, encoded from waveforms by Mimi and decoded back into audio by its decoder.
- Face streams: $2N$ input streams and $N$ output streams, with $N = 8$. Each speaker is represented by eight face tokens, encoded from 3D facial motion and decoded back into mesh motion by the face codec.
Following Moshi, the audio and face streams are delayed by one timestep relative to the text stream to improve generation stability. This creates a streaming setup in which the dialogue model can condition on prior user and system context while generating the next system response.
Face codec: discrete tokens for 3D facial motion
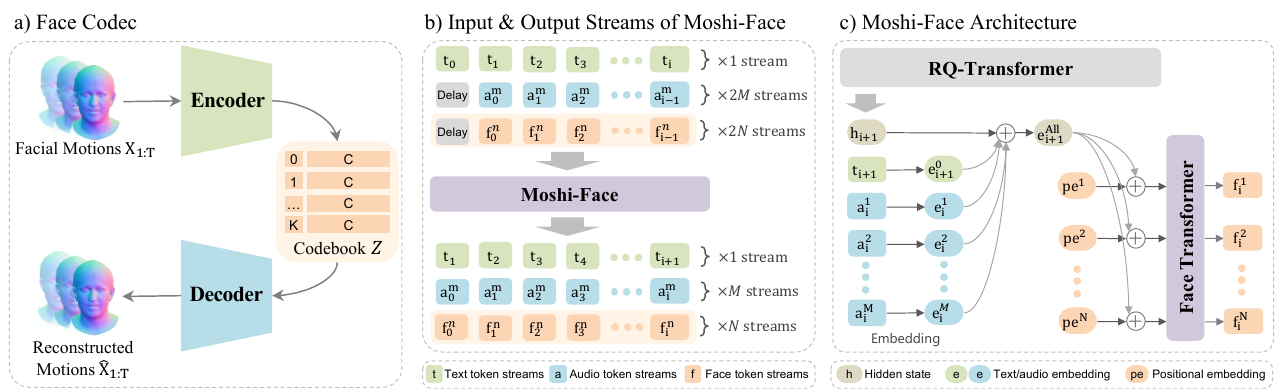
To represent facial motion in the same discrete-token style as speech, the authors train a vector-quantized variational autoencoder (VQ-VAE) as a face codec. The input is a sequence of 3D head meshes, $$ \mathbf{X}_{1:T} \in \mathbb{R}^{T \times V \times 3}, $$ where $T$ is the number of frames, $V$ is the number of FLAME facial vertices, and the three coordinates are $x$, $y$, and $z$. Each frame is represented as a displacement from a neutral facial expression.
The encoder consists of a downsampling 1-D convolution followed by a transformer layer. It reduces the temporal length by a factor of $r = T/T'$ and outputs $N$ latent vectors per downsampled frame: $$ \mathbf{Z} = E(\mathbf{X}_{1:T}) \in \mathbb{R}^{T' N \times C}. $$ Each latent vector is independently quantized to the nearest codebook entry in $\mathcal{Z} \in \mathbb{R}^{K \times C}$, producing $N$ discrete indices per frame. These indices are called face tokens. The paper uses $N = 8$ in all experiments.
The decoder mirrors the encoder and upsamples the quantized latent sequence back to a reconstructed mesh sequence $\hat{\mathbf{X}}_{1:T}$. The training objective combines three terms: $$ \mathcal{L}_{\mathrm{vq}} = \mathcal{L}_{\mathrm{rec}} + \lambda_{\mathrm{q}} \mathcal{L}_{\mathrm{q}} + \lambda_{\mathrm{vel}} \mathcal{L}_{\mathrm{vel}}, $$ where $\mathcal{L}_{\mathrm{rec}}$ is the $L_1$ reconstruction loss, $\mathcal{L}_{\mathrm{q}}$ is the quantization loss, and $\mathcal{L}_{\mathrm{vel}}$ is a velocity loss that encourages realistic motion dynamics.
A key design choice is that the $N$ quantized components within a frame are treated as independent, which later enables the face tokens to be generated non-autoregressively in parallel.
Moshi-Face generation model
The generation stack has two main parts: the existing Moshi RQ-Transformer and a new Face Transformer.
RQ-Transformer
The RQ-Transformer is described as a 7B-parameter decoder-only Transformer with a smaller Depth Transformer. It autoregressively predicts the next hidden state, next text token, and next system audio tokens conditioned on the history of text, audio, and face tokens: $$ \mathbf{h}_{i+1},\, \mathbf{t}_{i+1},\, \mathbf{a}_i^{1:M} = \mathcal{T}_{\mathrm{RQ}}\big(\mathbf{t}_{(\le i)},\, \mathbf{a}_{(< i)}^{1:M},\, \mathbf{f}_{(< i)}^{1:N}\big). $$ Here, the model consumes the past context and emits the internal representation $\mathbf{h}_{i+1}$ plus the next language and audio outputs. That hidden state then conditions face generation.
Face Transformer
The Face Transformer is a non-causal module that predicts the $N$ face tokens at each timestep in parallel. It takes a unified conditioning vector built from the RQ-Transformer hidden state and the text and audio embeddings: $$ \mathbf{e}^{\mathrm{All}}_{i+1} = \mathbf{h}_{i+1} + \mathbf{e}^{0}_{i+1} + \sum_{m=1}^{M} \mathbf{e}^{m}_{i}. $$ The vector is projected and combined with a learnable positional embedding $\mathbf{pe}^n$ to form query vectors $$ \mathbf{q}^n = \mathrm{Proj}(\mathbf{e}^{\mathrm{All}}_{i+1}) + \mathbf{pe}^n, $$ for each of the $N$ output positions. A transformer with non-causal self-attention across the $N$ positions then predicts the face token set: $$ \mathbf{f}_i^{1:N} = \mathcal{T}_{\mathrm{Face}}\big(\{\mathbf{q}^n\}_{n=1}^{N}\big). $$
The non-autoregressive design matches the face codec, where the $N$ codebook indices in a frame are quantized independently. This is an important architectural point: the model does not impose an arbitrary ordering on the within-frame face tokens, yet it still maintains timewise dependency across frames through the timestep-level conditioning. In training, the authors also use teacher forcing by embedding the ground-truth face tokens from timestep $i-1$ and adding them to the queries at timestep $i$.
The total Moshi-Face objective combines the original Moshi text and audio losses with a face-token cross-entropy term: $$ \mathcal{L}_{\mathrm{Moshi\text{-}Face}} = \mathcal{L}_{\mathrm{text}} + \mathcal{L}_{\mathrm{audio}} + \lambda\, \mathcal{L}_{\mathrm{face}}. $$ The paper sets $\lambda = 1$ in joint fine-tuning.
Dataset and training setup
The model is trained on a conversational audiovisual corpus derived from Meta's Seamless Interaction dataset. Because existing 3D audiovisual datasets such as VOCASET and BIWI are non-conversational and too small, the authors randomly download approximately 180 hours of dialogue data, corresponding to about 3,400 dialogues. Each dialogue includes time-aligned speech transcriptions, separate-channel audio, and single-speaker videos for both participants.
To obtain 3D facial supervision, they use VHAP to extract 3D facial meshes from monocular video. The motion is extracted at 25 fps and represented using the FLAME topology with 5,143 vertices. The resulting face motion is then tokenized by the face codec and aligned with the text/audio token streams.
Training proceeds in two stages. First, the face codec is trained on 70 hours of the extracted 3D mesh data, split into train/validation/test sets with an $8{:}1{:}1$ ratio. The trained codec is then used to tokenize the full 180-hour corpus. Second, Moshi-Face is trained on the tokenized text, audio, and face data. For the dialogue-model stage, the authors reserve 100 dialogues that were unseen during face-codec training as the test set, and split the remaining 3,300 dialogues into train and validation sets with a $9{:}1$ ratio.
The face codec uses $N = 8$ face components, codebook size $K = 256$, and embedding dimension $C = 128$. Since the target token rate matches Moshi's $12.5$ Hz stream, the codec downsamples the $25$ fps face motion by $r = 2$.
- Face codec training: 70 epochs, AdamW, learning rate $10^{-4}$, batch size 4.
- Moshi-Face step 1: initialize the RQ-Transformer from the pretrained Moshi checkpoint, freeze the RQ-Transformer, and train only the Face Transformer for 500 steps with learning rate $5 \times 10^{-4}$ and batch size 32.
- Moshi-Face step 2: jointly fine-tune all components for 1,200 steps with batch size 16 and learning rates $2 \times 10^{-6}$ for the Temporal Transformer, $4 \times 10^{-6}$ for the Depth Transformer, and $10^{-5}$ for the Face Transformer.
The paper emphasizes that the two-step optimization is important: the first stage isolates face generation learning, while the second stage adapts the full model to the multimodal objective.
Evaluation protocols and metrics
The paper evaluates two distinct aspects: the quality of the face codec itself and the end-to-end behavior of Moshi-Face.
Face codec metrics
The codec is evaluated using reconstruction quality and codebook utilization. Reconstruction is measured by Mean Vertex Error (MVE) and Lip Vertex Error (LVE), both reported in units of $\times 10^{-3}$ and lower-is-better. Codebook utilization is measured by Perplexity, normalized by codebook size, where higher is better and $1.0$ would indicate perfectly uniform use of the codebook.
End-to-end system metrics
Moshi-Face is evaluated under two settings:
- Teacher-forced: ground-truth audio tokens from the 100 test dialogues are provided as input, isolating the face-generation component.
- Free-run: two identical Moshi-Face models interact as system and user, with each model's output feeding the other at each timestep.
Audiovisual synchronization is measured with LSE-D and LSE-C using a pretrained SyncNet, after decoding the audio tokens with Mimi and rendering the decoded face meshes into 2D video. Speech naturalness is measured by UTMOS. Semantic quality is measured using LLM-as-a-Judge on ASR transcripts from Whisper-large-v3, with GPT-5-mini as the evaluator. The LLMAJ scores are reported on a $1$--$5$ scale for coherence, naturalness, relevance, and overall quality. Each sample is evaluated three times and averaged.
The authors note an important methodological constraint: there is no established metric that directly scores synchronization between audio tokens and face tokens, so they use an indirect rendering-based protocol for evaluation.
Face codec results
Table 1 shows that increasing the codebook size from $128$ to $256$ consistently improves reconstruction quality, and that $C = 128$ gives the best codebook utilization at the larger size. The selected configuration, $K = 256$ and $C = 128$, is used for all later experiments.
| Codebook size $K$ | Embedding dim. $C$ | Perplexity $\uparrow$ | MVE $\downarrow$ | LVE $\downarrow$ |
|---|---|---|---|---|
| 128 | 64 | 0.66 | 11.20 | 12.79 |
| 128 | 128 | 0.67 | 11.79 | 13.95 |
| 256 | 64 | 0.57 | 9.85 | 12.40 |
| 256 | 128 | 0.66 | 9.90 | 11.77 |
The trend is straightforward: larger codebooks better capture fine facial detail, while the higher-dimensional embedding helps keep codebook usage more uniform. The paper reads this as evidence that the face-token vocabulary is expressive enough to support downstream dialogue generation.
End-to-end Moshi-Face results
The main comparison includes the original Moshi, a fine-tuned audio-only version Moshi-ft, a Reconstructed face upper bound, a Random face lower bound, and several ablations of Moshi-Face. The headline result is that Moshi-Face reaches strong audiovisual alignment while keeping dialogue quality close to the original audio model.
| Model | Streaming | Teacher-forced AV sync | Free-run AV sync | UTMOS $\uparrow$ | LLMAJ score $\uparrow$ | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| LSE-D $\downarrow$ | LSE-C $\uparrow$ | LSE-D $\downarrow$ | LSE-C $\uparrow$ | Coherence | Naturalness | Relevance | Overall | |||
| Moshi | Yes | -- | -- | -- | -- | 3.08 | 3.76 | 3.73 | 4.26 | 3.85 |
| Moshi-ft | Yes | -- | -- | -- | -- | 1.69 | 3.59 | 4.28 | 3.95 | 3.55 |
| Reconstructed face | No | 8.53 | 0.12 | -- | -- | -- | -- | |||
| Random face | No | 11.7 | 0.13 | 11.8 | 0.11 | -- | -- | |||
| Moshi-Face (ours) | Yes | 8.76 | 0.14 | 11.0 | 0.16 | 1.75 | 3.79 | 4.52 | 4.24 | 3.76 |
| w/o Face Transformer pre-training | Yes | 9.53 | 0.13 | 10.4 | 0.14 | 1.71 | 3.78 | 4.53 | 4.25 | 3.76 |
| w/o full fine-tuning | Yes | 11.8 | 0.16 | 11.1 | 0.20 | 2.42 | 3.24 | 3.94 | 3.89 | 3.23 |
| w/o $t-1$ face token input | Yes | 11.3 | 0.15 | 10.1 | 0.09 | 1.45 | 3.65 | 4.51 | 3.89 | 3.50 |
Audiovisual synchronization
In teacher-forced evaluation, Moshi-Face obtains an LSE-D of 8.76 and an LSE-C of 0.14, coming close to the reconstructed-face upper bound of $8.53 / 0.12$ and clearly outperforming the random-face lower bound of $11.7 / 0.13$. In free-run mode, it retains reasonable synchronization at $11.0 / 0.16$, showing that the model can sustain alignment in a fully interactive duplex setting rather than only under teacher forcing.
The paper treats this as evidence that the face-token interface is capable of representing timing-sensitive audiovisual cues, even though the generation process remains low-latency and streaming.
Speech quality and semantic quality
Moshi-Face's speech naturalness drops relative to the original Moshi baseline, with UTMOS decreasing from 3.08 to 1.75. The fine-tuned audio-only variant Moshi-ft also drops to 1.69. The authors interpret this as a consequence of adapting to a smaller domain-specific dataset.
On the semantic side, however, Moshi-Face performs well: it achieves the best coherence score in the table at 3.79, the second-highest naturalness score at 4.52, relevance of 4.24, and overall quality of 3.76, which is close to the original Moshi's 3.85. This is the paper's main evidence that adding face tokens does not harm dialogue competence and may even preserve useful multimodal context.

The qualitative example reinforces the quantitative findings: the generated motion is not limited to mouth articulation, but also includes natural head dynamics. The paper uses this example to illustrate that the system can produce synchronized multimodal behavior in an interactive dialogue loop.
Ablation analysis
The ablations probe three design choices: pre-training the Face Transformer separately, performing full joint fine-tuning, and feeding the previous timestep's face tokens into the model. The results show that all three matter, but in different ways.
- Without Face Transformer pre-training: teacher-forced LSE-D worsens from $8.76$ to $9.53$, showing that isolated pre-training provides a better initialization for face prediction.
- Without full fine-tuning: performance degrades most severely, with teacher-forced LSE-D reaching $11.8$, free-run LSE-D reaching $11.1$, and LLMAJ scores dropping notably. This indicates that the joint optimization stage is essential.
- Without $t-1$ face token input: free-run LSE-D improves slightly to $10.1$, but LSE-C and UTMOS worsen, suggesting a trade-off between robustness to error accumulation and output quality.
The ablations support the paper's broader architectural argument: the Face Transformer should be introduced carefully, first in isolation and then jointly with the full duplex system, and temporal face-token conditioning helps preserve naturalness even if it can amplify exposure-bias-like effects in some settings.
What the paper contributes
- A full-duplex multimodal dialogue framework that handles speech and 3D facial motion together, rather than treating facial generation as an offline post-processing step.
- A discrete face-token codec based on VQ-VAE, operating at the same frame rate as Moshi's audio/text token streams.
- A non-autoregressive Face Transformer that predicts multiple face tokens in parallel within each timestep, conditioned on the dialogue model's hidden state and speech/text context.
- A large conversational audiovisual dataset derived from Seamless Interaction and processed with VHAP to obtain 3D facial meshes.
- Empirical evidence that the proposed extension preserves dialogue quality while enabling synchronized audiovisual generation.
Limitations and future work stated by the authors
The paper is explicit about two limitations. First, the current face codec is non-causal, which means the visual representation is not yet fully streaming in the same sense as the rest of the system. The authors say they plan to replace it with a causal, streaming codec so that both visual input and output can be fully real time.
Second, the evaluation is entirely automated. The authors state that they intend to conduct human evaluations in future work to assess perceptual quality and real-world deployment readiness. They also note that the system is a step toward more natural conversational agents rather than a complete end-point.
A practical limitation of the evaluation protocol is that audiovisual synchronization is measured indirectly via rendered video and SyncNet-based metrics, because there is no standard metric directly operating on audio tokens and face tokens. The paper uses this workaround consistently, but it is still a proxy rather than a direct multimodal token-level measure.
Conclusion
Moshi-Face extends a state-of-the-art full-duplex dialogue model beyond audio by adding a learned discrete face representation and a parallel face-token generation module. On a large conversational audiovisual dataset, the system achieves low-latency audiovisual synchronization and preserves the underlying dialogue quality of Moshi. The work's main significance is architectural: it demonstrates that synchronized facial motion can be integrated into a streaming duplex dialogue stack without redesigning the entire language model from scratch.
In short, the paper shows that full-duplex spoken dialogue systems can be made multimodal in both understanding and generation, moving conversational AI closer to the simultaneous speech-plus-face behavior of human interaction.
Code & Implementation
The moshi repository contains the full codebase for the Moshi model, a speech-text foundation model and full-duplex spoken dialogue framework. The repository supports three main implementations of the Moshi inference stack:
- PyTorch Implementation (in
moshi/): Intended for research and tinkering, this contains the PyTorch code for Moshi and Mimi, the streaming neural audio codec used by Moshi. - MLX Implementation (in
moshi_mlx/): Designed for on-device inference on macOS and iPhone. - Rust Implementation (in
rust/): Production-grade implementation including Rust bindings for Mimi.
The model jointly processes two audio streams (user and Moshi's own speech) as well as textual tokens representing Moshi's inner monologue to enhance generation quality. Mimi is a key component that encodes and decodes 24 kHz audio to a compressed representation in a streaming manner, enabling low latency.
The PyTorch code includes scripts for serving the model in a streaming interactive mode with a web UI client accessible on localhost, and also offers a programmatic API for streaming encoding/decoding and model inference.
This codebase directly supports the methods described in the paper by providing the end-to-end architecture combining the speech codec (Mimi) and the dialogue LM (Moshi). It enables real-time, low-latency spoken dialogue as well as potential extensions to incorporate facial generation as described in the paper.