LLM-Based Japanese G2P Benchmark
Benchmarking Large Language Models for Grapheme-to-Phoneme Conversion: A Japanese Case Study

This work benchmarks over 30 large language models on Japanese grapheme-to-phoneme conversion, comparing novel prompting pipelines to traditional morphological analyzers, and shows that LLMs can outperform classical methods for text-to-speech pronunciation accuracy.
Links
Paper & demos
Code & resources
Abstract
Grapheme-to-phoneme (G2P) conversion is essential for controllable and robust text-to-speech, and large language models (LLMs), with broad linguistic knowledge, offer a promising approach. We benchmarked over 30 LLMs on Japanese G2P, comparing them with conventional morphological analyzers on 3000 manually annotated sentences. We evaluated two prompting strategies: a parse mode, where the LLM performs morphological analysis followed by rule-based kana conversion, and a direct mode, where the LLM directly predicts kana readings. The results show that model size, version, and Japanese-specialized training are key factors, with the best LLMs achieving kana character error rate below 0.52\% vs. the best conventional tool (1.03\%). Parse mode outperforms direct mode for most models, as rule-based post-processing relieves the LLM of handling complex pronunciation rules. We also show that feeding LLM-predicted kana into a kana-input TTS yields better pronunciation than end-to-end TTS.
Introduction
This paper studies grapheme-to-phoneme (G2P) conversion for Japanese as a benchmark task for large language models (LLMs), with an explicit focus on practical text-to-speech (TTS) use. The core motivation is that although end-to-end TTS systems can implicitly learn pronunciation from data, an explicit G2P stage remains valuable for controllability and robustness, especially for proper nouns, out-of-vocabulary words, and cases where pronunciation must be specified precisely.
Japanese is a particularly difficult G2P setting because text is written without spaces, kanji are often polyphonic, and pronunciation depends on a mixture of segmentation, lexical reading selection, and post-lexical phonological rules. The paper highlights several examples of this complexity: word boundary ambiguity, kanji with multiple readings, irregular numeral-counter pronunciations such as 1本 $\rightarrow$ ippon and 2人 $\rightarrow$ futari, and particle/long-vowel rules such as は, を, and へ being realized differently in context.
The main question is whether LLMs can serve as strong Japanese G2P systems, and if so, whether they can outperform conventional morphological-analyzer-based pipelines. The paper benchmarks more than 30 LLMs against standard Japanese tools on a manually annotated corpus, and then tests whether LLM-predicted kana can improve pronunciation in a kana-input TTS pipeline compared with end-to-end TTS.
Problem Formulation and Japanese G2P Challenges
The paper decomposes Japanese G2P into three interdependent subproblems:
- Word segmentation: Japanese has no explicit spaces, so the system must identify token boundaries and part-of-speech structure.
- Reading estimation: each token must be assigned an appropriate kana reading, which is straightforward for kana but highly context dependent for kanji compounds and polyphonic characters.
- Pronunciation rules: deterministic phonological changes must be applied, including particle conversion and long-vowel normalization, as well as irregular numeral-counter behavior.
The paper uses these properties to motivate a split between what should be handled by the LLM and what should be handled by rules. That distinction is the central design idea behind the two prompting strategies evaluated in the benchmark.
Method: Two LLM-based G2P Pipelines
The paper evaluates two prompting strategies for Japanese G2P: parse mode and direct mode. Both are inference-only approaches; the main benchmark does not fine-tune the LLMs. All results in the main table are obtained with reasoning disabled, i.e. with non-thinking mode or low reasoning effort.
Parse Mode

In parse mode, the LLM acts as a replacement for a conventional morphological analyzer in a Japanese G2P pipeline. Given a sentence, it outputs a sequence of tokens with surface form, kana reading, and part-of-speech information. The prompt instructs the model to produce a JSON array, and compound nouns and proper nouns should be grouped as single tokens. Few-shot examples are used to demonstrate the expected output format.
The model’s output is then passed through a rule-based post-processing stage that applies deterministic pronunciation rules, including particle conversion and long-vowel normalization. This is important because it removes a large portion of the burden from the LLM: the model only needs to perform segmentation and lexical reading selection, while the postprocessor handles rules such as は $\rightarrow$ wa and other context-sensitive kana transformations.
The paper’s main methodological claim is that parse mode is often easier for LLMs than asking them to directly emit a fully normalized phonetic string, because the model no longer has to internalize every pronunciation rule via prompting alone.
Direct Mode

In direct mode, the LLM maps the input sentence directly to its full kana reading in a single step. This avoids explicit morphological analysis, but it also means the model must solve segmentation, reading disambiguation, and pronunciation normalization all at once.
The prompt for direct mode is correspondingly more detailed. It specifies katakana conversion rules, particle pronunciation changes, long-vowel normalization rules for different vowel classes, and exceptions where lengthening must not apply, such as certain inflectional contexts and particle boundaries. Few-shot examples are also included. The paper reports that, in practice, this makes direct mode harder for most models, particularly smaller ones.
Dataset, Annotation, and Evaluation Protocol
The benchmark uses 3,000 sentences from the nonpara30 subset of the JVS corpus (Japanese versatile speech). The chosen sentences cover diverse phenomena such as onomatopoeia and loanwords, which are often out-of-vocabulary for dictionary-based systems. The paper also reports that, under UniDic-based automatic analysis, proper nouns written in kanji appear in 181 sentences (6.0%), proper nouns written in katakana appear in 256 sentences (8.5%), and numeral expressions appear in 14.2% of the sentences.
All 3,000 sentences were manually annotated with reference kana readings. The metric is kana character error rate (CER), computed between predicted and reference kana sequences. Because Japanese kana have near one-to-one correspondence with phonemes, kana CER is treated as essentially equivalent to phoneme error rate. Before scoring, punctuation is removed and long vowels are normalized so that acceptable kana variation does not inflate the error rate.
The evaluation is designed to isolate the analysis step. For conventional morphological analyzers, the paper applies the same rule-based post-processing used in parse mode, so the comparison between LLMs and classical tools reflects the quality of morphological analysis and reading estimation, not differences in the final deterministic normalization stage.
Models Compared
The benchmark covers three groups:
- Proprietary LLMs: Claude Opus 4.6, Claude Sonnet 4.6, Gemini 2.5 Flash, Gemini 3 Flash, Gemini 3.1 Pro, and GPT-5.2.
- Open-weight LLMs: models from Gemma, Qwen, Llama, GLM, gpt-oss, Kimi, CALM3, and llm-jp families, spanning 2B to 1T parameters. Some variants are Japanese-specialized via continual pretraining and labeled Swallow.
- Conventional morphological analyzers: OpenJTalk, MeCab+IPAdic, MeCab+UniDic, KyTea, KWJA, Sudachi, and Vaporetto.
Most open-weight models were run locally. A few large models were accessed through provider APIs and are denoted with a dagger in the original table: GLM-4.7, GLM-5, Kimi K2.5, and Qwen3.5-397B. All main-benchmark LLM results were obtained with reasoning disabled.
Main Benchmark Results
The headline result is that the best LLMs outperform the best conventional Japanese G2P tool. The strongest proprietary models achieve sub-0.6% kana CER, and the best open-weight local model is substantially better than the best conventional analyzer. The paper also shows that model size, model version, and Japanese-specialized pretraining all matter strongly.
| Model | Size | Parse | Direct |
|---|---|---|---|
| Proprietary LLMs | |||
| Claude Opus 4.6 | -- | 0.52 | 0.74 |
| Claude Sonnet 4.6 | -- | 0.82 | 1.28 |
| Gemini 2.5 Flash | -- | 1.08 | 1.17 |
| Gemini 3 Flash | -- | 0.94 | 1.61 |
| Gemini 3.1 Pro | -- | 0.62 | 0.53 |
| OpenAI GPT-5.2 | -- | 1.64 | 1.05 |
| Open-weight LLMs | |||
| CALM3-22B | 22B | 14.30 | 22.81 |
| Gemma3-4B | 4B | 34.82 | 56.69 |
| Gemma2-27B | 27B | 10.33 | 24.56 |
| Gemma2-Swallow-27B | 27B | 5.74 | 17.53 |
| Gemma3-12B | 12B | 14.15 | 28.77 |
| Gemma3-27B | 27B | 5.75 | 15.16 |
| GLM4-9B | 9B | 26.89 | 57.56 |
| GLM4-32B | 32B | 16.82 | 35.62 |
| GLM4.7† | 355B | 3.70 | 5.87 |
| GLM5† | 744B | 1.44 | 4.96 |
| gpt-oss-20b | 20B | 7.95 | 14.71 |
| gpt-oss-120b | 120B | 3.03 | 3.45 |
| Kimi K2.5† | 1T | 1.35 | 4.91 |
| Llama3.1-Swallow-8B | 8B | 9.34 | 22.47 |
| Llama3.3-70B | 70B | 6.58 | 23.48 |
| Llama3.3-Swallow-70B | 70B | 2.85 | 11.78 |
| llm-jp-3.1-13b | 13B | 15.36 | 86.02 |
| Qwen2.5-7B | 7B | 43.27 | 79.39 |
| Qwen2.5-32B | 32B | 16.54 | 35.48 |
| Qwen3-4B | 4B | 35.77 | 57.72 |
| Qwen3-8B | 8B | 28.13 | 100.15 |
| Qwen3-14B | 14B | 17.13 | 32.11 |
| Qwen3-32B | 32B | 17.07 | 32.46 |
| Qwen3-Swallow-32B | 32B | 9.30 | 21.59 |
| Qwen3.5-2B | 2B | 41.87 | 87.30 |
| Qwen3.5-4B | 4B | 23.00 | 43.98 |
| Qwen3.5-9B | 9B | 14.17 | 27.47 |
| Qwen3.5-27B | 27B | 6.27 | 14.61 |
| Qwen3.5-35B-A3B | 35B | 6.12 | 26.93 |
| Qwen3.5-122B-A10B† | 122B | 7.57 | 16.80 |
| Qwen3.5-397B† | 397B | 1.96 | 6.20 |
| Conventional morphological analyzers | |||
| KWJA | -- | 2.52 | -- |
| KyTea | -- | 1.42 | -- |
| MeCab+IPAdic | -- | 1.78 | -- |
| MeCab+UniDic | -- | 1.54 | -- |
| OpenJTalk | -- | 1.03 | -- |
| Sudachi | -- | 1.83 | -- |
| Vaporetto | -- | 1.86 | -- |
Effect of Model Size
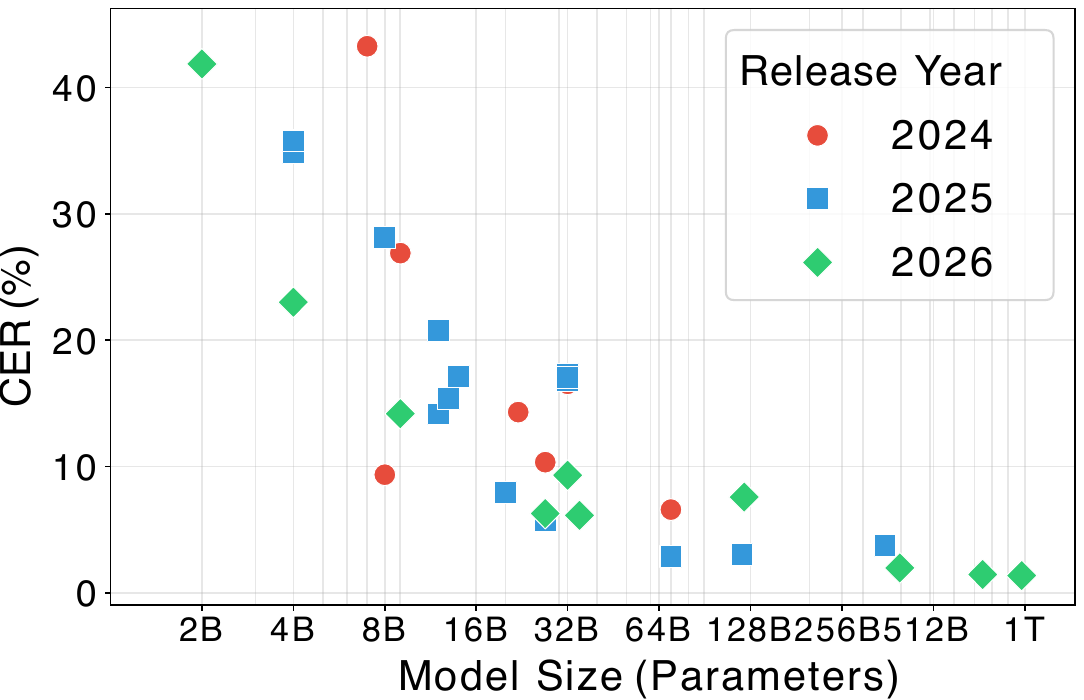
The size sweep shows a clear scaling trend: larger models consistently achieve lower CER within the same model family. The paper highlights several monotonic improvements in parse mode:
- Gemma3: 34.82% (4B) $\rightarrow$ 14.15% (12B) $\rightarrow$ 5.75% (27B)
- Qwen2.5: 43.27% (7B) $\rightarrow$ 16.54% (32B)
- Qwen3.5: 41.87% (2B) $\rightarrow$ 23.00% (4B) $\rightarrow$ 14.17% (9B) $\rightarrow$ 6.27% (27B)
This behavior is interpreted as evidence that scaling laws remain relevant for G2P: the larger the model, the better it can preserve readings, segmentation, and formatting fidelity. The paper also reports qualitative failure modes typical of smaller models, including:
- substituting unrelated words rather than emitting faithful readings,
- misreading kanji compounds, and
- even corrupting kana that should have been copied unchanged.
Effect of Model Version and Japanese-specialized Training
Newer versions of the same family generally perform better. Examples include Gemma3-27B (5.75%) versus Gemma2-27B (10.33%), and Qwen3.5-27B (6.27%) versus Qwen2.5-32B (16.54%) and Qwen3-32B (17.07%). This indicates that improvements in model generation and instruction following translate into better G2P performance.
Japanese-specialized continual pretraining, marked as Swallow, also has a strong effect. The paper reports consistent gains for all matched pairs:
- Llama3.3-Swallow-70B: 2.85% versus Llama3.3-70B: 6.58%
- Qwen3-Swallow-32B: 9.30% versus Qwen3-32B: 17.07%
- Gemma2-Swallow-27B: 5.74% versus Gemma2-27B: 10.33%
Among locally deployed models, Llama3.3-Swallow-70B is the best reported system at 2.85% parse-mode CER.
Parse Mode versus Direct Mode
For nearly all local LLMs, parse mode outperforms direct mode, often by a wide margin. The effect is strongest for smaller models, where direct mode can be dramatically worse because the model must internalize all pronunciation rules. A representative example is Gemma3-4B, which improves from 56.69% in direct mode to 34.82% in parse mode.
The paper explains that direct mode is especially brittle for particle conversion and long-vowel normalization. If the model fails to convert particles or normalize vowel sequences correctly, the output accumulates systematic errors. This is illustrated by an example sentence where direct mode leaves particles unconverted and mishandles long vowels, while parse mode succeeds because the rule-based stage applies the deterministic transformations.
There are, however, two notable exceptions: Gemini 3.1 Pro and GPT-5.2. For these models, direct mode is slightly better than parse mode. The paper attributes this to strong prompt following and fewer normalization errors in direct mode, whereas parse mode can introduce segmentation mistakes, especially around numeral-counter expressions.
A specific parse-mode weakness is that morphological analysis can split numeral-counter compounds incorrectly, such as segmenting 2人 into separate pieces and producing an incorrect reading like ni-nin instead of the correct compound reading futari. Direct mode can avoid this kind of segmentation-induced error because it processes the full string without explicit tokenization.
Comparison with Conventional Tools
The best conventional analyzer is OpenJTalk at 1.03% parse-mode CER. The best LLMs outperform it decisively: Claude Opus 4.6 reaches 0.52% in parse mode, and Gemini 3.1 Pro reaches 0.62% in parse mode and 0.53% in direct mode. This is one of the paper’s main empirical claims: strong LLMs can beat long-established rule-based or morphological-analyzer-based Japanese G2P systems.
The paper also explains why. Conventional tools tend to fail on out-of-vocabulary words and rare lexical items, producing misreadings on items such as unfamiliar compounds and domain-specific terms. In contrast, LLMs benefit from pretrained linguistic knowledge and can often infer plausible readings for unseen words. On the other hand, because LLMs are probabilistic, they may still emit implausible readings for common words in some cases, so their superiority is not absolute.
Effect of Reasoning / Thinking Mode
The paper includes a small ablation on reasoning-enabled versus reasoning-disabled inference for three models in parse mode. The results are mixed:
- Qwen3-32B: 17.07% non-thinking versus 17.32% thinking
- gpt-oss-20b: 7.95% non-thinking versus 7.91% thinking
- Gemini 3 Flash: 0.94% non-thinking versus 0.54% thinking
For two models the difference is negligible, but Gemini 3 Flash shows a clear gain from reasoning. The paper’s interpretation is that thinking mode can improve word segmentation, which then helps downstream long-vowel normalization because vowel lengthening should not cross word boundaries. This suggests that reasoning may help high-performing models more than weaker ones, at least on this task.
Discussion: G2P-Based TTS versus End-to-End TTS
To test practical value beyond offline G2P accuracy, the paper evaluates whether LLM-predicted kana can improve pronunciation in a TTS pipeline. The experiment fine-tunes CosyVoice 2 with LoRA on the Corpus of Spontaneous Japanese (CSJ) so that it can accept kana input. LLM-predicted kana are then fed into this kana-input TTS system. This is compared with end-to-end TTS systems that consume raw text directly: CosyVoice 2, Gemini 2.5 Flash TTS, Qwen 3 TTS, and ElevenLabs v2.
Pronunciation accuracy is measured by recognizing synthesized speech with a kana-output ASR model: Whisper fine-tuned for kana output. The paper reports that this ASR system achieves 2.22% CER on the CSJ test set, making it suitable for this evaluation. Speech naturalness is estimated with UTMOS.
| System | Input | CER | UTMOS |
|---|---|---|---|
| G2P + kana-input TTS (fine-tuned CosyVoice 2) | |||
| True kana (oracle) | Kana | 2.10 | 3.81 |
| Gemini 3.1 Pro (direct) | Kana | 2.38 | 3.82 |
| Claude Opus 4.6 (parse) | Kana | 2.69 | 3.82 |
| E2E TTS | |||
| Gemini 2.5 Flash TTS | Text | 3.96 | 3.75 |
| Qwen 3 TTS (1.7B) | Text | 4.31 | 4.00 |
| CosyVoice 2 | Text | 12.08 | 3.45 |
| ElevenLabs v2 | Text | 13.96 | 3.36 |
The conclusion from the TTS study is straightforward: explicit G2P helps pronunciation. G2P-based synthesis with Gemini 3.1 Pro direct mode reaches 2.38% CER, which is close to the oracle condition using true kana (2.10%) and substantially better than all evaluated E2E TTS systems. Even the best E2E system in this comparison, Gemini 2.5 Flash TTS, remains at 3.96% CER, clearly worse than the kana-input pipeline.
Importantly, naturalness does not appear to be sacrificed. UTMOS scores for G2P-based systems are 3.82, essentially comparable to or slightly above the E2E systems in this table. The paper therefore argues that a separate G2P stage provides a practical benefit: it improves pronunciation accuracy while maintaining naturalness at a competitive level.
Interpretation and Key Takeaways
- LLMs can be strong Japanese G2P systems, not merely a curiosity: the best models beat the strongest conventional analyzer.
- Model scale matters: performance improves steadily with size within a family, consistent with scaling behavior.
- Japanese-specialized pretraining matters: Swallow variants consistently outperform their base models.
- Parse mode is the default winner: offloading deterministic pronunciation rules to post-processing helps most models substantially.
- Direct mode can work very well for top-tier models: Gemini 3.1 Pro and GPT-5.2 slightly favor direct mode, showing that high-end models can sometimes absorb the full task.
- Explicit G2P remains practically relevant for TTS: kana-based synthesis improved pronunciation without hurting estimated naturalness.
Limitations and Future Work
The paper does not present a separate formal limitations section, but it does identify several avenues for improvement. First, some remaining errors come from the prompt design itself; tuning prompts based on observed output patterns could reduce them. Second, combining multiple models may improve robustness. Third, the deterministic post-processing rules could potentially be replaced by LLM-based post-processing, which may better capture irregular contexts. Fourth, proper nouns remain an especially important and challenging error source in practical TTS, so evaluating and optimizing on proper-noun-heavy data is a priority.
The paper also suggests that in-context learning could allow end users to specify their preferred readings directly through prompting, which would be a distinctive advantage over traditional G2P tools. This is framed as a practical benefit of LLM-based G2P: the system can be adapted at inference time without retraining.
Conclusions
This work is a large-scale benchmark of Japanese G2P using LLMs, and it establishes three main conclusions. First, the best LLMs achieve sub-0.6% kana CER and outperform conventional morphological analyzers. Second, parse mode is generally more reliable than direct mode because rule-based post-processing reduces the burden on the LLM. Third, feeding LLM-predicted kana into a kana-input TTS system yields better pronunciation than end-to-end TTS while maintaining comparable naturalness.
Overall, the paper positions Japanese G2P as a useful benchmark for evaluating linguistic competence in LLMs and as a practically relevant component for conversational and speech systems that need controllable, accurate pronunciation.
Code & Implementation
This repository provides the JVS-nonpara-kana dataset used in the paper for benchmarking large language models on Japanese grapheme-to-phoneme (G2P) conversion. It includes jvs_nonpara_kana.csv, containing 3,000 manually annotated katakana readings aligned to utterances from the JVS corpus, supporting evaluation of G2P predictions.
Additionally, the repo contains eval_cer.py, a Python script to compute the Character Error Rate (CER) of predicted katakana readings against the ground truth annotations. This script follows the evaluation protocol described in the paper and handles orthographic normalization of long vowel marks to avoid penalizing variant forms.
The repository does not include model training or inference code for LLMs but focuses on the curated dataset and a standard evaluation script that enables benchmarking results replication. Users can provide model predictions in the required input format (one .txt file per utterance) and run eval_cer.py to obtain CER results, aligning with the paper's comparative evaluation methodology.