Interleaved SLMs Latent Text
Interleaved Speech Language Models Latently Work In Text
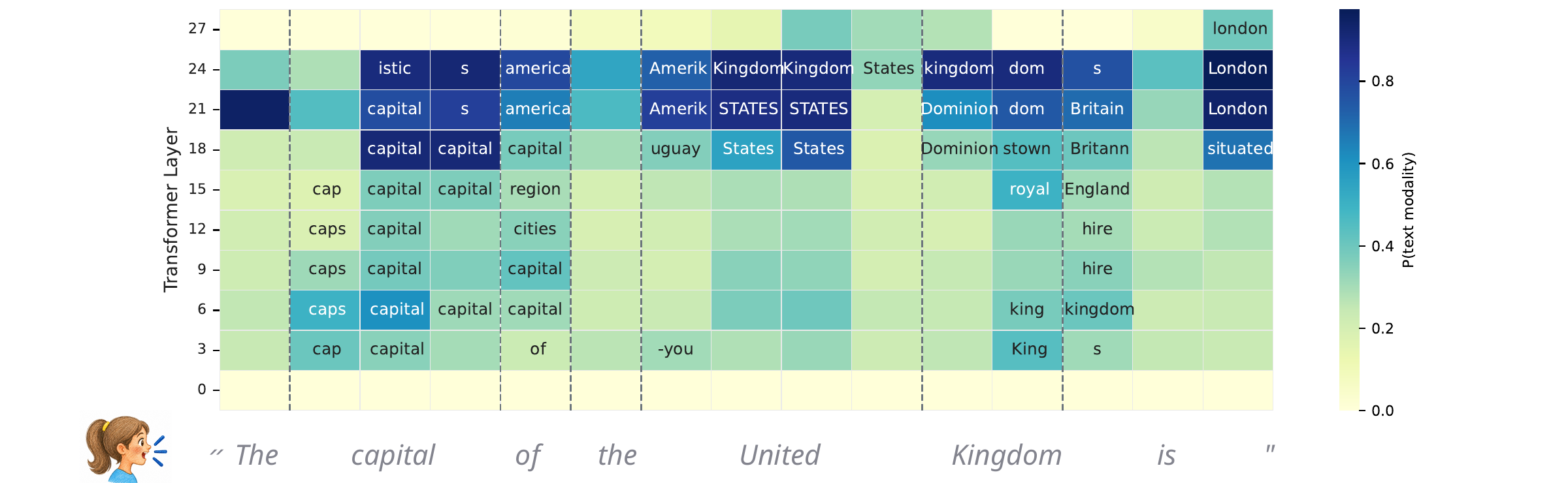
This paper shows that interleaved speech-text language models internally transcribe speech into text tokens within intermediate layers, without explicit transcription training. This latent transcription enables a unique interplay of speech and text modalities for improved model function.
Demos
The demos show how interleaved speech language models internally transcribe spoken words into text tokens in intermediate layers, even without explicit speech recognition training. When evaluating, watch how the model decodes speech into text and then predicts the next word, demonstrating the latent interaction between speech and text.
Links
Paper & demos
Code & resources
Abstract
Speech language models (SLMs) have been extensively studied, with the common paradigm incorporating text data and pre-trained text LMs. A leading approach is speech-text interleaving in which models are trained over sequences containing both speech and text tokens, aiming to boost even speech-only capabilities. Yet the way these two modalities interact in the model latent space remains unclear. In this work, we analyze interleaved speech-text LMs from different model families and sizes through the scope of the logit lens to provide such insight. We reveal that these models go through an implicit transcription phase in which the text token of the spoken word becomes decodable in intermediate layers, despite not being trained for speech recognition. The transcription of the word appears as one of the top candidate words for as much as 77\% of the data. Following this stage, the models proceed to predict the next word in the text space before transforming back to the speech domain. We finally analyze the role of interleaving data, and initializing from text LMs in eliciting this behavior, as well as seeing how this correlates with spoken knowledge abilities. Our analysis sheds light on the internal mechanisms underlying the relationship between speech and text modalities and could shape SLM optimization.
1. Problem, motivation, and main claim
This paper studies interleaved speech-text speech language models (SLMs): generative models trained on sequences that mix discrete speech units and text tokens in a single stream. The central question is not whether these models can use both modalities, but how they combine them internally. The authors ask whether speech inputs remain in a speech-token representation throughout computation, or whether the model passes through a textual latent workspace before producing speech again.
Their key finding is that interleaved SLMs often exhibit implicit latent transcription: when speech is fed into the model, intermediate layers become linearly decodable as the corresponding text transcription of the spoken word, even though the model is not trained with any explicit speech-recognition objective. The model then often transitions into predicting the next word in text space, and only later returns to the speech-token domain for generation. In the strongest cases, the correct transcription appears among the top candidate words for up to 77% of the data, and the authors argue that this behavior is positively associated with spoken factual-knowledge performance.
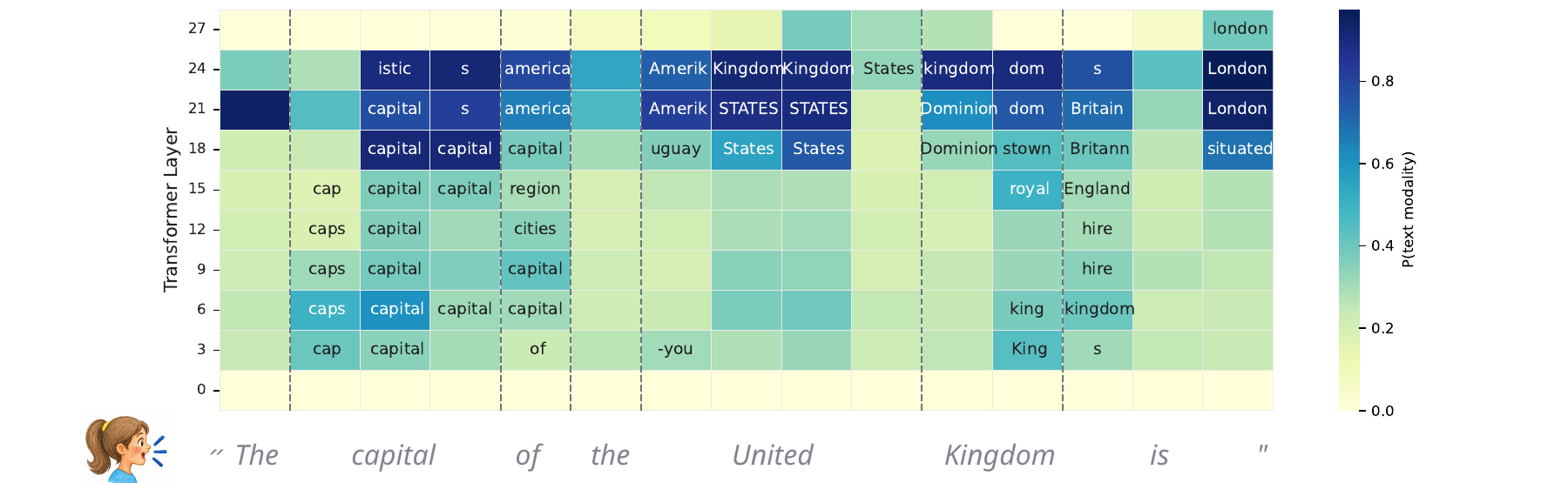
2. Background: interleaved speech-text models and the logit lens
The paper focuses on joint speech-text LMs that typically combine three pieces: a speech-to-unit frontend, a joint autoregressive LM, and a unit-to-speech back end. Speech is represented with discrete units rather than raw waveforms, and the joint model is trained on sequences that contain both speech units and text tokens. Interleaving follows the common code-switching setup in which aligned words are assigned either the speech or text modality, contiguous same-modality words are grouped into spans, and those spans are tokenized accordingly.
To inspect internal computation, the authors use the logit lens, which projects intermediate hidden states through the model’s output projection to obtain layer-wise token distributions. For a hidden state $h_i^{(j)}$ at position $i$ and layer $j$, they compute
$$P(x_{i+1} \mid h_i^{(j)}) = \operatorname{softmax}(W_{\mathrm{out}} h_i^{(j)}),$$
where $W_{\mathrm{out}}$ is the learned output projection. Because speech words correspond to variable-length spans of speech units, the paper aligns speech-token positions to word-level transcriptions and then aggregates logit-lens scores over each spoken word. The default aggregation is the maximum over positions in a span, which the authors motivate by observing that transcription-like information is often localized to one or two positions.
This aggregation is used for three related probes: whether the current spoken word is decodable, whether the next word is decodable, and whether the final factual answer is decodable from intermediate speech states.
3. Training setup, data, and evaluation protocol
The analysis is grounded in the official SIMS interleaved speech-text study and in controlled Llama-3.2-3B variants trained by the authors under the same optimization setup. The paper studies models built from Llama 3.2-3B and Qwen2.5 families, spanning different sizes and compute budgets. All models use next-token prediction with a sequence length of 2048, an effective batch size of 32, and 20K training steps. Training is implemented with SLAMKit.
In the controlled experiments, two axes are varied:
- Initialization: pretrained text-LM initialization versus random initialization.
- Data composition: speech-only, balanced speech+text, and speech+text plus interleaved sequences.
For the interleaved regime, the paper defines variants in which interleaved examples account for $1/3$, $2/3$, or $5/6$ of the training tokens, while the non-interleaved speech and text portions remain balanced. The authors denote these settings with prefixes indicating pretrained or random initialization and the presence or absence of interleaved data.
The appendix specifies the broader data recipe. Speech training data follows the SIMS setup and includes LibriSpeech, LibriLight, VoxPopuli, TED-LIUM, People’s Speech, SWC, and synthetic sTinyStories. Text-only data is drawn from RedPajama and filtered with Gopher rules. Speech is tokenized into HuBERT-style units by quantizing mHuBERT features with a 500-unit k-means codebook. Interleaved examples are created from aligned speech-text spans using Whisper large-v3-turbo alignments. For interleaving, speech-segment lengths are sampled from a Poisson distribution with $\lambda = 10$ until speech spans cover $\eta = 0.3$ of the words.
To test whether speech-side factual knowledge is accessible from text priors, the authors also construct a small manually curated commonsense completion benchmark with 282 examples across categories such as colors, days and months, object functions, common-sense facts, languages, family relations, numerical facts, opposites, professions, capital cities, simple arithmetic, and number sequences. Prompts are synthesized into speech using Kokoro-82M and time-aligned with Whisper large-v3. Each true fact is paired with a counterfactual completion from the same category, and a model is scored correct if
$$\log p(\text{fact}) > \log p(\text{counterfactual fact}).$$
Dataset composition
| Category | Examples | Representative prompt |
|---|---|---|
| Colors | 16 | The color of grass is → green |
| Days of the week | 7 | The day that comes after Sunday is → Monday |
| Months of the year | 14 | The month that comes after January is → February |
| Object functions | 21 | People use eyes to → see |
| Common-sense facts | 13 | Water freezes into → ice |
| Country languages | 10 | The official language of France is → French |
| Family relations | 18 | The mother of mother is called → grandmother |
| Numerical facts | 27 | The number of seconds in a minute is → 60 |
| Opposites | 35 | The opposite of hot is → cold |
| Baby animals and professions | 10 | A baby dog is called a → puppy |
| Capital cities | 30 | The capital of France is → Paris |
| Simple arithmetic | 58 | One plus one equals → 2 |
| Number sequences | 23 | The number after one is → two |
| Total | 282 | — |
4. Main result: speech inputs pass through text-like latent states
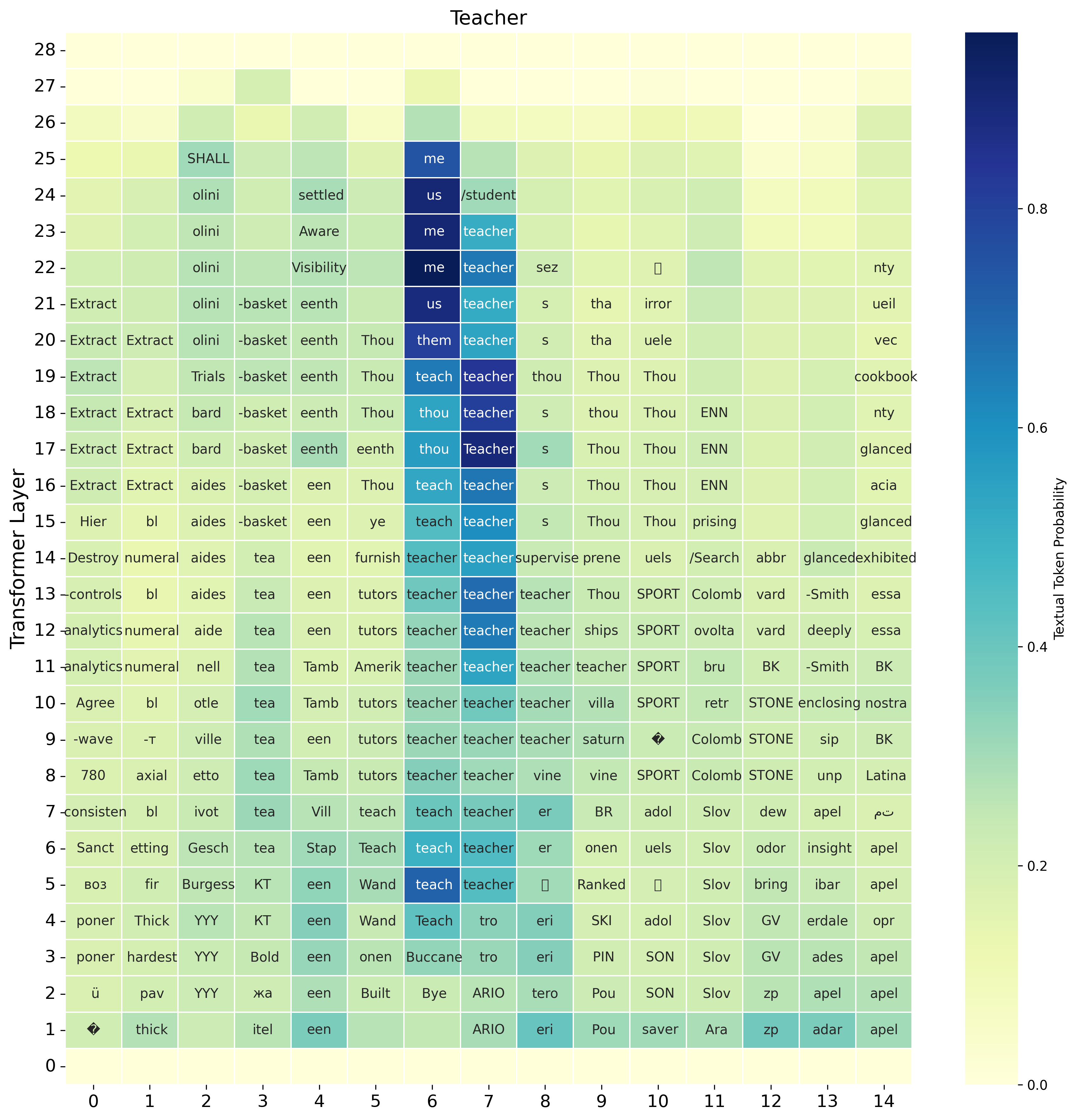
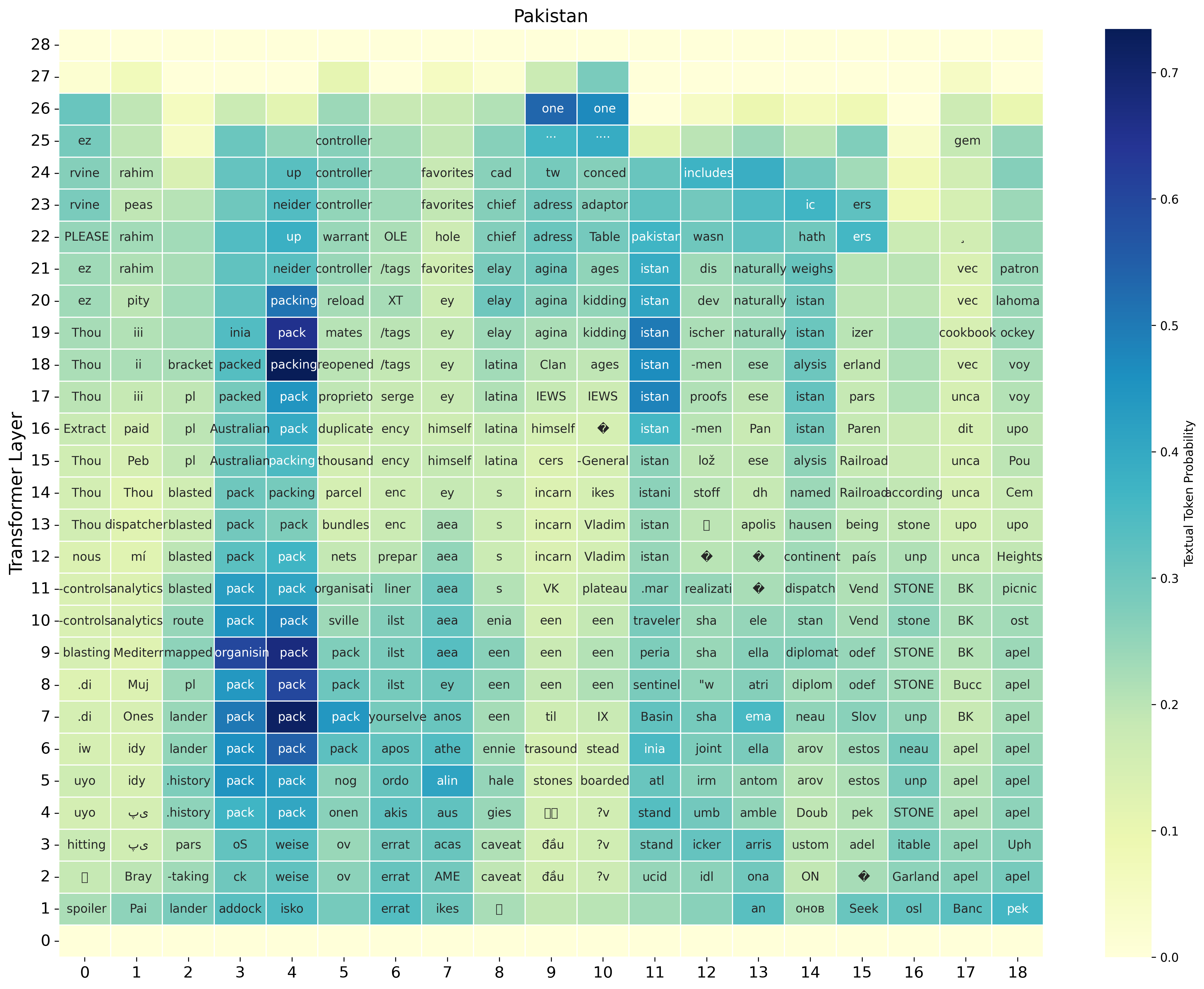
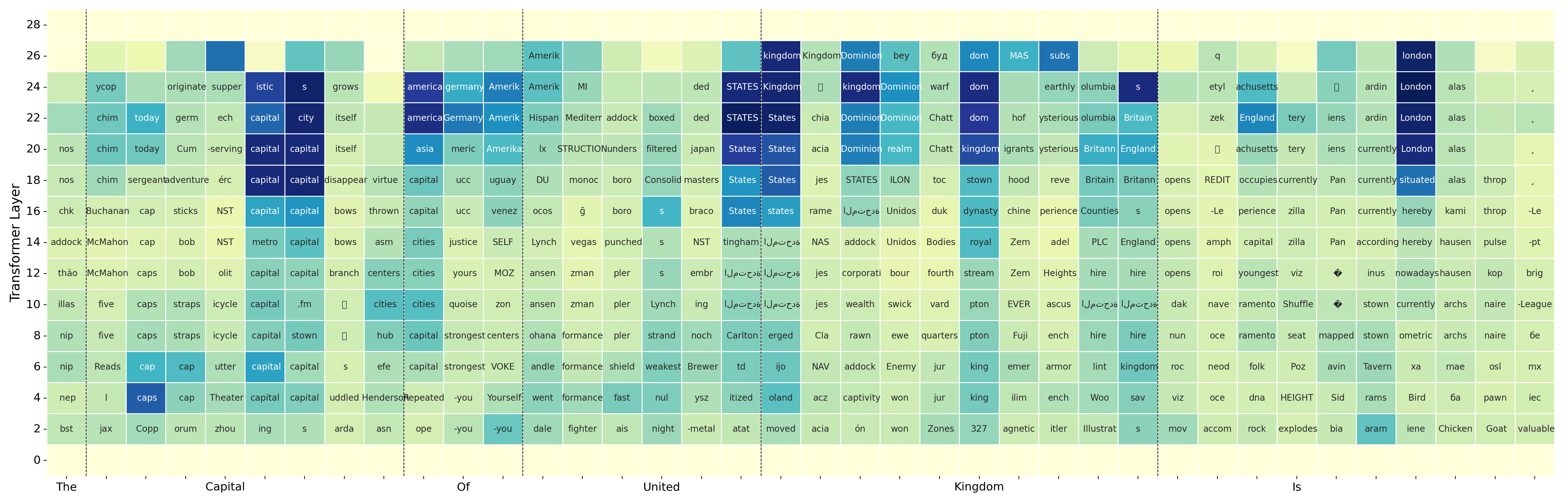
The first major result is a clear speech-text-speech pattern in the layer-wise token distribution. For the illustrated SIMS-Llama-3.2-3B model, early layers are dominated by speech-token predictions, middle layers shift toward text-token predictions, and late layers move back toward speech tokens before generation. This behavior is specific to speech inputs: when the same analysis is applied to text prompts, the logit-lens distribution stays concentrated on text tokens throughout. The paper also checks the top-200 token slice to rule out a vocabulary-size artifact; the same trend remains visible.
The authors interpret this as evidence that speech inputs are not processed wholly inside a speech-token manifold. Instead, the model appears to enter a text-like latent regime in the middle of the computation, then map the representation back to the speech domain for autoregressive generation.
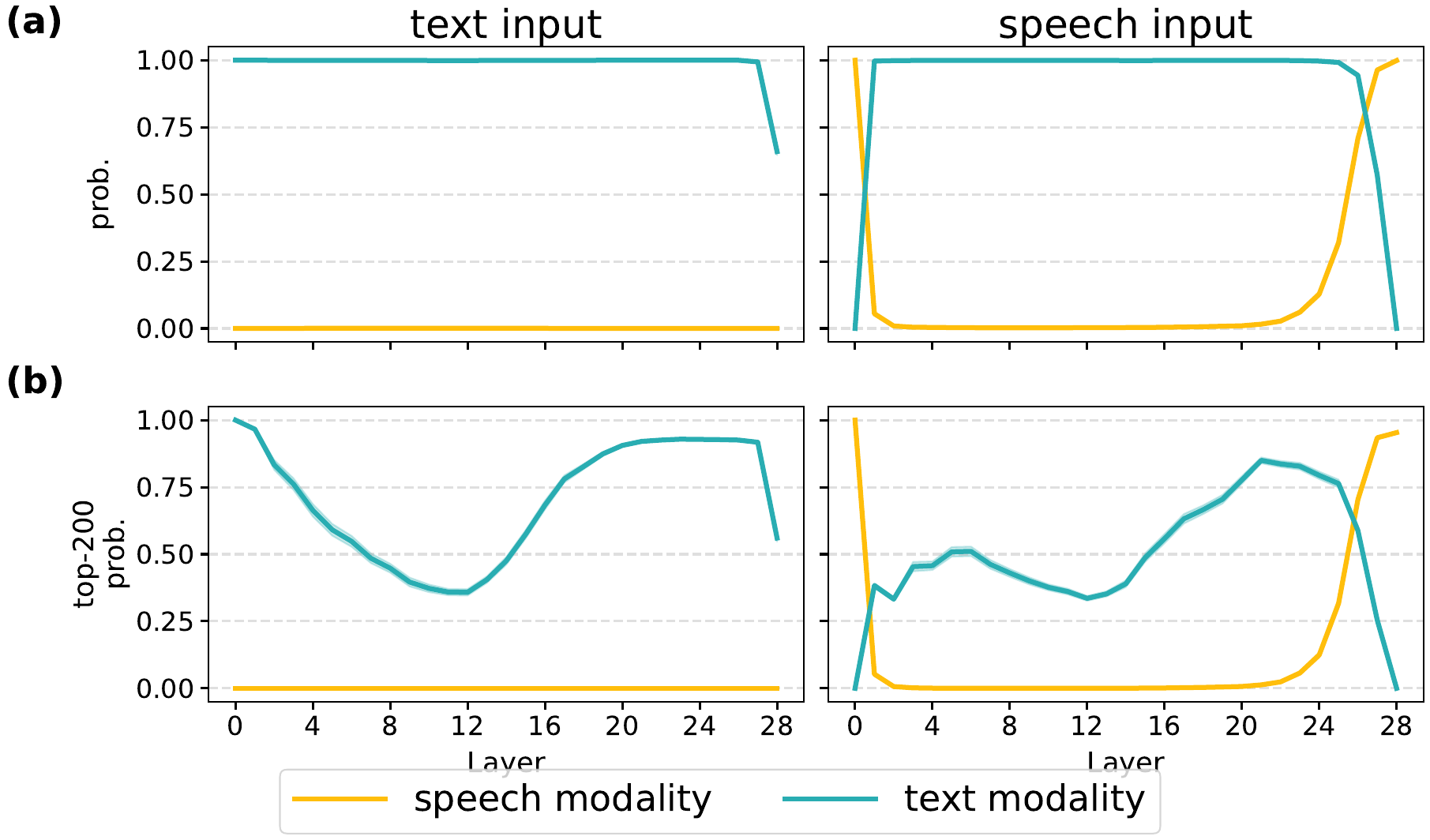
Current-word transcription is decodable in intermediate layers
The paper next tests whether the text-like phase contains meaningful lexical content about the spoken input. Using cumulative Recall@k over layers, the authors ask whether the gold transcription of each spoken word appears among the top-k logit-lens predictions from any aligned speech token up to a given layer. Across interleaved models from Llama and Qwen families, the correct transcription emerges in intermediate layers far above chance, while a random-token baseline remains near zero.
In the main figure, the SIMS-Llama-3.2-PI-1/3 variant reaches nearly 40% cumulative Recall@1 for current-word transcription by layer 23 and nearly 80% cumulative Recall@50. The paper notes that transcription often becomes visible before the final layers and then saturates as the model transitions back toward the speech-token domain for generation.
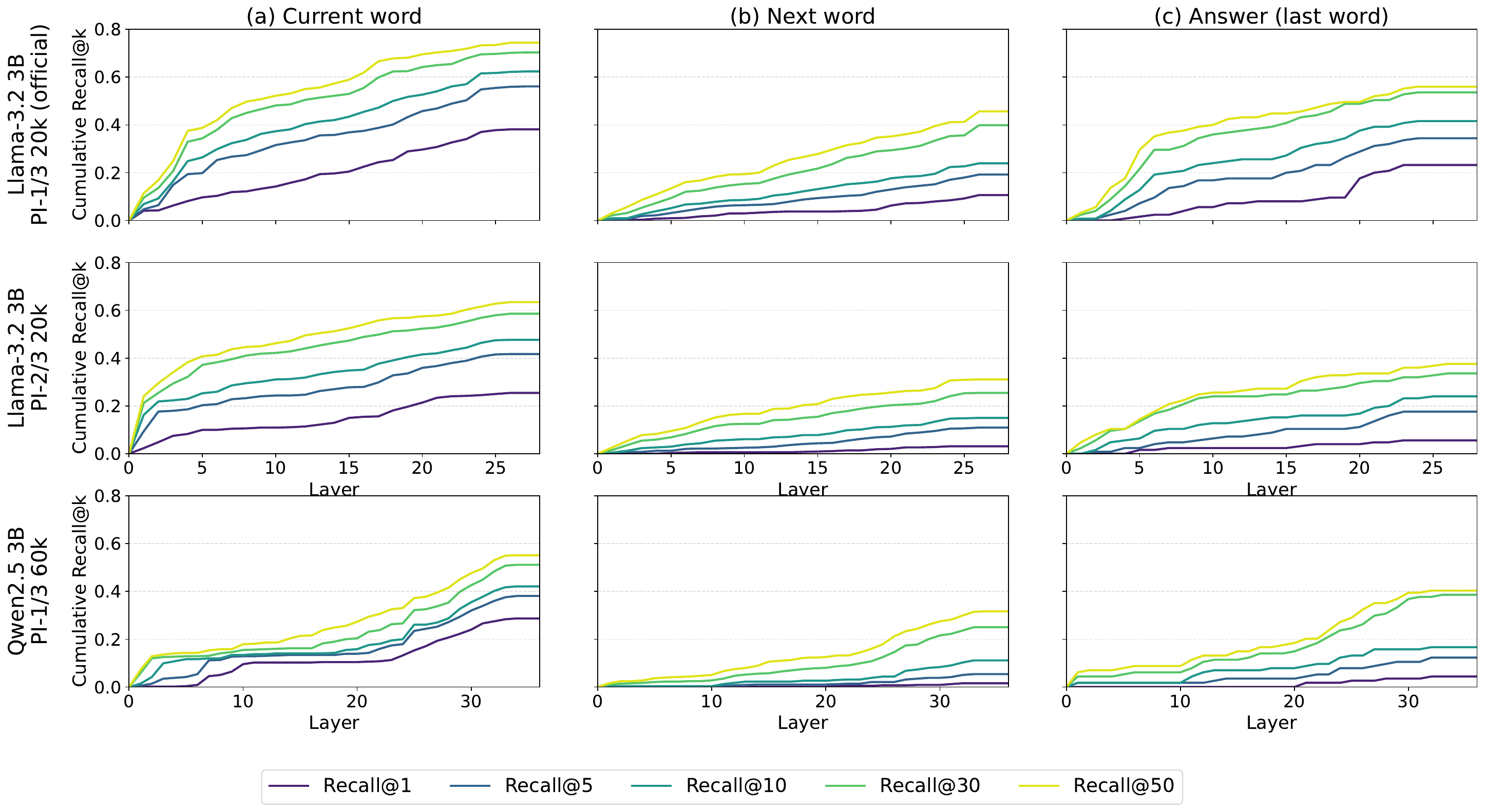
The paper explicitly calls this behavior implicit latent transcription. It is not direct ASR supervision: the models are never trained to output transcripts from speech, yet the corresponding text token becomes recoverable from intermediate hidden states. The effect is robust across several interleaved SLMs, including Llama-3.2-3B and Qwen2.5-3B variants.
Textual continuation is also encoded
The authors then ask whether the same text workspace supports prediction of the next textual word, not just the current spoken word. Using the same cumulative Recall@k protocol but changing the target, they find that next-word information is indeed decodable, though it is weaker than current-word transcription. For the fine-tuned Llama variants, Recall@50 for next-word prediction reaches nearly 40%, while the Qwen-based model reaches roughly 30%. For the final answer word in the prompt, all models exceed 40% cumulative Recall@50, and the official SIMS-Llama-3.2-PI-1/3 model recovers the correct answer for nearly 60% of prompts at some layer.
The paper highlights that next-word prediction can be ambiguous for intermediate positions, so lower recall does not necessarily mean the information is absent. Some examples suggest a transcription-then-prediction trajectory, but the authors do not claim a strict ordering across all examples; transcription and continuation may overlap in time.
Concrete recall numbers for transcription and continuation
| Model | Text pre-trained | Text | Interleaved | Interleaved fraction | Cur @10 | Next @10 | Ans @10 |
|---|---|---|---|---|---|---|---|
| SIMS Llama-3.2 PI-1/3 (official) | yes | yes | yes | 1/3 | 61.88 | 23.91 | 41.60 |
| Llama-3.2 PI-1/3 (ours) | yes | yes | yes | 1/3 | 48.75 | 15.31 | 26.40 |
| Llama-3.2 PI-2/3 | yes | yes | yes | 2/3 | 49.06 | 15.78 | 24.00 |
| Llama-3.2 PI-5/6 | yes | yes | yes | 5/6 | 2.66 | 1.72 | 4.00 |
| Llama-3.2 PST | yes | yes | no | — | 3.75 | 3.28 | 0.00 |
| Llama-3.2 PS | yes | no | no | — | 0.16 | 0.00 | 0.00 |
| Llama-3.2 RST | no | yes | no | — | 5.78 | 6.72 | 4.80 |
| Llama-3.2 RI-1/3 | no | yes | yes | 1/3 | 2.19 | 5.78 | 7.20 |
These are the Recall@10 values reported in the main ablation table. The same qualitative pattern holds at Recall@1, Recall@5, and Recall@30: text-pretrained models with interleaved training are strongest, while models without interleaving or without a pretrained textual prior are much weaker. The paper emphasizes that this is a robust pattern, not a single-metric artifact.
5. What training factors matter?
The ablations are designed to isolate the causes of implicit transcription. The conclusion is that neither text exposure alone nor interleaving alone is sufficient. The strongest transcription appears when a model starts from a pretrained text LM and then receives enough speech-text interleaved supervision to align speech-unit representations with textual ones.
The fraction of interleaved training data matters as well, but not monotonically. The strongest signals appear at moderate interleaving ratios such as $1/3$ and $2/3$. The $5/6$ interleaving variant is substantially weaker, suggesting that too much interleaving may reduce exposure to pure modality-specific contexts or otherwise distort the training distribution.
This leads to a concrete interpretation: the text LM prior provides a strong textual latent scaffold, while interleaved speech-text examples teach the model how to map speech units onto that scaffold. Speech-only training or random initialization does not reproduce the same phenomenon.
6. Relationship to spoken factual knowledge
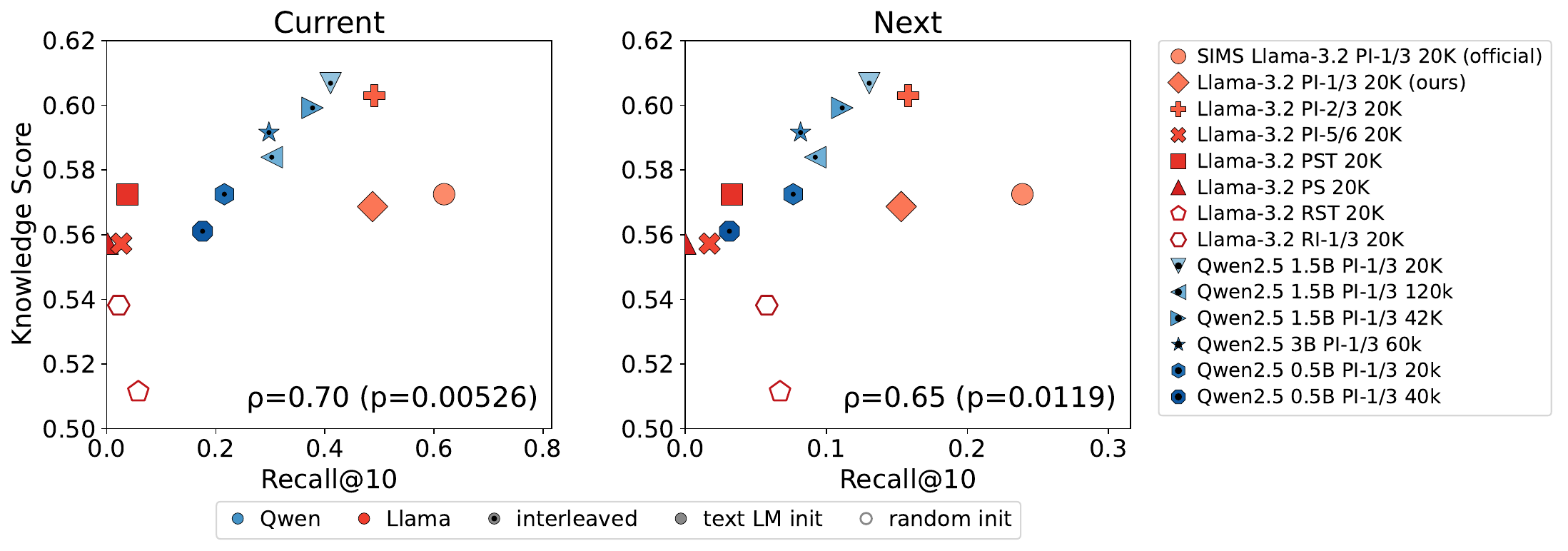
The paper’s second empirical question is whether implicit transcription is related to access to factual knowledge from speech. Using all the models above, the authors correlate each model’s transcription score with its accuracy on the commonsense speech benchmark. They report positive Spearman correlations for both current-word and next-word transcription:
- Current-word transcription vs. knowledge: $\rho = 0.70$, $p = 0.00526$.
- Next-word transcription vs. knowledge: $\rho = 0.65$, $p = 0.0119$.
The interpretation is nuanced. Better implicit transcription tends to accompany better factual retrieval from speech, but the relationship is not exact. The correlation does not explain all cross-model variation, and the paper explicitly notes that random models can show some non-zero transcription-like token overlap while still performing poorly on factual retrieval. Thus, the authors present correlation as evidence of an association, not a causal mechanism.
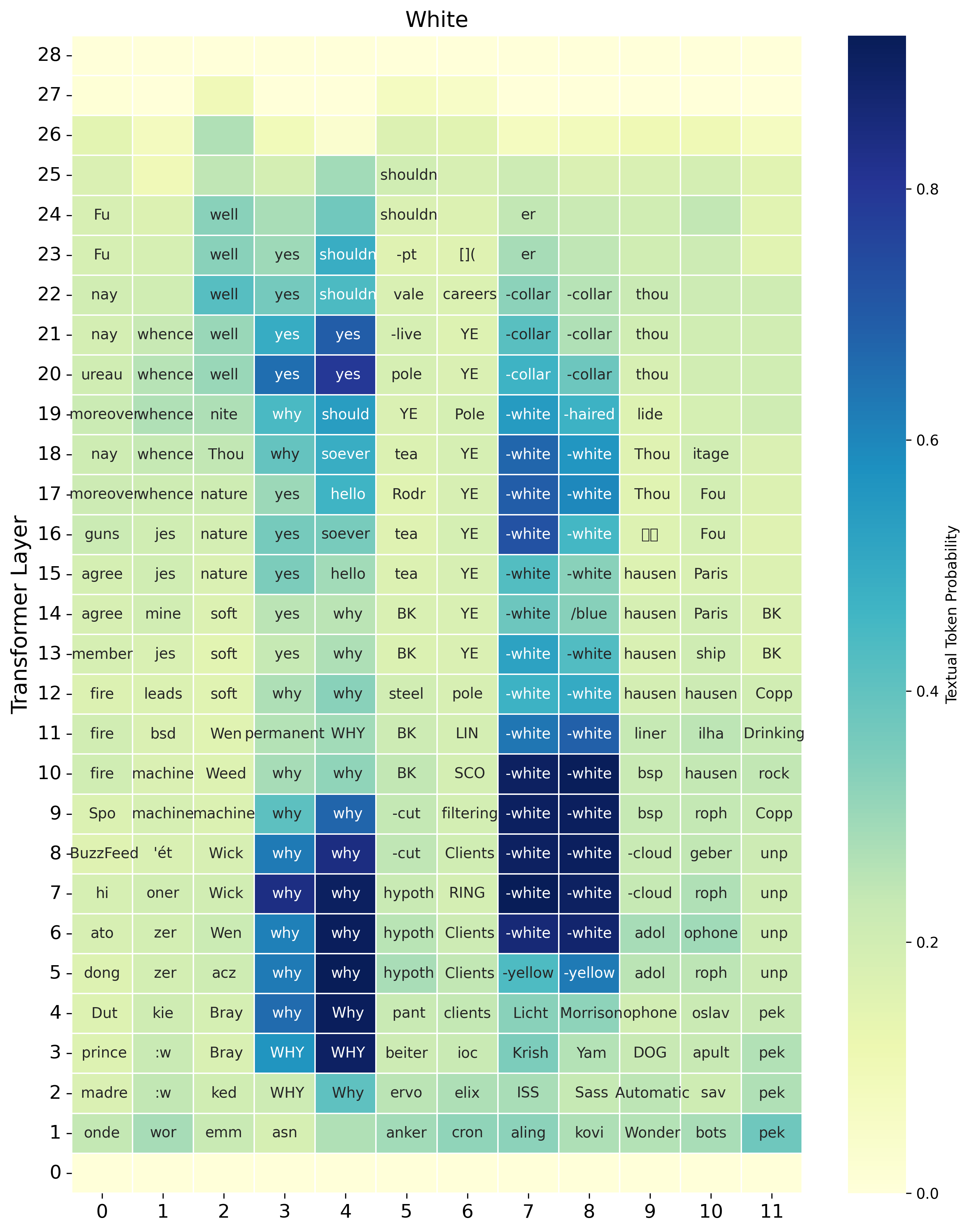
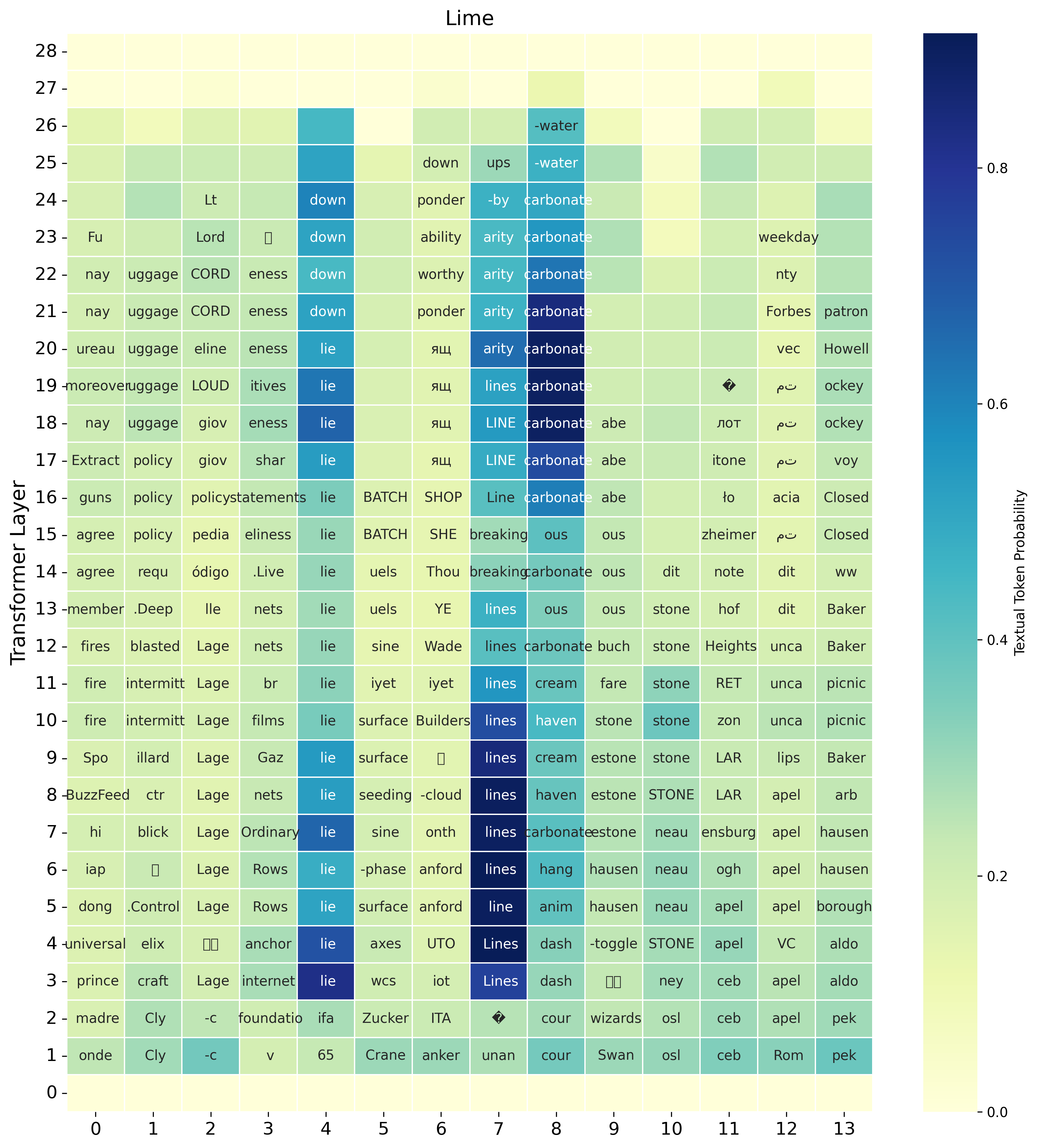
7. Qualitative examples of gradual and imperfect transcription
The qualitative analysis shows that implicit transcription can build up over time rather than appear all at once. The paper gives examples in which the model first predicts partial prefixes or acoustically related words and only later converges to the full transcription. This supports the view that the model is constructing a text hypothesis from partial acoustic evidence as the spoken word unfolds.
The authors also note transcription errors: the intermediate textual guess can be acoustically plausible but incorrect. These errors suggest that the text workspace is not perfectly aligned with speech and may itself be a source of ambiguity.
8. Limitations, interpretation, and broader implications
The paper is careful about what it does not establish. First, it does not identify the exact mechanism responsible for implicit transcription, such as the specific heads, layers, or pathways that carry it. Second, although transcription-like signals are positively associated with factual knowledge retrieval, the correlation is only moderate to strong, not explanatory of all model differences. Third, the study does not causally test whether increasing implicit transcription would improve knowledge performance.
The authors also point out open questions for future work. If speech models internally “think in text,” why does a modality gap remain at all? Possible explanations include transcription errors, compute spent on an intermediate text hypothesis, or a mismatch between speech timing and the text-like reasoning process. They further note that making implicit transcription more explicit could help optimization, but might also harm acoustic modeling abilities, which are a key reason to model speech directly.
Overall, the paper argues that interleaved SLMs do not merely align speech and text at the input-output level; they appear to use text as an internal working space during speech processing. This mechanism may be central to why interleaving helps semantic and knowledge performance, but the causal and circuit-level picture remains open.
Code & Implementation
This repository provides SlamKit, an open-source toolkit for training and evaluating Speech Language Models (SLMs), including speech-only pre-training, preference alignment, and speech-text interleaving techniques discussed in the paper. The implementation is modular and config-driven, leveraging four main CLI scripts: extract_features.py for converting audio to discrete tokens using pretrained speech tokenizers; prepare_tokens.py for preparing training tokens with various tokenization regimes including interleaved speech-text; train.py for model training with HuggingFace Trainer integration; and eval.py for evaluation and generation with pretrained models.
The repo structure contains key components under slamkit/ such as tokenizers, models, trainers, and utilities that collectively realize the interleaved speech-text modeling and analysis presented in the paper. The toolkit supports detailed configuration via Hydra, enabling flexible control over datasets, model architectures, and training regimes.
Users can replicate the core experiments by following documented CLI commands that chain feature extraction, token preparation, and model training stages on example datasets, with support for integration to logging services like Weights & Biases. This design aligns closely with the paper methodology of analyzing intermediate model states and multimodal token interleaving.