Generative Relightable Avatars

Generative Relightable Avatars enable photorealistic free-view rendering and relighting of full-body humans by combining physics-based relighting with generative video refinement. This captures fine details and pose-dependent effects, producing temporally coherent avatars under diverse lighting.
Demos
These demos highlight Generative Relightable Avatars (GRA)'s photorealistic rendering and relighting of full-body humans. Observe its hybrid approach blending coarse relighting, texture refinement for pose-dependent effects, and video diffusion for fine details. Key evaluation points are visual quality, temporal coherence, and robustness to out-of-distribution lighting including OLAT and near-field cases without retraining.
Links
Paper & demos
Abstract
We present Generative Relightable Avatars (GRA), a person-specific method for photorealistic free-view rendering and environment-map relighting of full-body humans. We postulate that modeling fine-grained appearance details is inherently a one-to-many problem that can benefit from a generative formulation. In contrast to fully regressive relightable avatar methods, GRA follows a hybrid approach that combines controllable, physics-grounded relighting with probabilistic refinement. Starting from a tracked animated mesh, we optimize material parameters in UV-space and render a coarse relit appearance under a target HDR environment map. Next, we refine the textures with a feed-forward model to capture pose-dependent texture dynamics and illumination effects beyond simplified reflectance assumptions. Finally, a fine-tuned video-to-video diffusion model transforms the physically grounded renderings into temporally coherent, high-detail videos while preserving 3D control, with an error-recycling strategy for generating long videos. Experimental evaluations demonstrate our method's improved perceptual quality over prior relightable avatar baselines. Project Page: https://vcai.mpi-inf.mpg.de/projects/GRA/
Introduction
Generative Relightable Avatars (GRA) targets photorealistic free-view rendering and environment-map relighting of dynamic, full-body humans. The core claim of the paper is that fine-grained human appearance is not well modeled as a deterministic mapping from pose to pixels: details such as wrinkles, subtle shading changes, and specular responses are inherently ambiguous and can vary in a one-to-many fashion even for the same underlying motion. GRA therefore combines an explicit, physics-grounded relighting pipeline with a generative video refinement stage, rather than relying on a purely regressive avatar model.
The system takes skeletal motion, viewpoint, and illumination as input, and produces a temporally coherent relit video. It is explicitly designed to preserve 3D control while improving perceptual realism, especially under challenging lighting, novel viewpoints, and out-of-distribution illumination such as one-light-at-a-time (OLAT) setups. The overall design is coarse-to-fine: first a tracked mesh is relit using a microfacet BRDF in UV space, then a feed-forward network corrects pose- and illumination-dependent appearance effects, and finally a fine-tuned video diffusion model synthesizes high-frequency detail and temporal consistency.

The paper positions GRA between two existing families of methods. Deterministic relightable avatar methods are strong on 3D controllability but tend to over-smooth appearance because they must resolve pose-to-texture ambiguity with a single prediction. Image- or video-space relighting methods can produce convincing lighting changes but generally lack explicit geometry and view control. GRA bridges this gap by using explicit 3D intermediate renderings as an inductive bias and a generative video model for probabilistic refinement.
Method
Problem formulation
The method models the final appearance $z$ as a conditional distribution over motion $\theta$, camera viewpoint $\kappa$, and environment lighting $\mathbf{E}$:
$$p(\mathbf{z} \mid \theta, \kappa, \mathbf{E}).$$
Rather than learning this distribution directly, GRA decomposes the task into a deterministic intermediate rendering stage and a probabilistic refinement stage. The deterministic stage produces a coarse image-space rendering $\mathbf{z}' = q(\theta, \kappa, \mathbf{E})$, and the final stage models $p(\mathbf{z} \mid \mathbf{z}', \mathbf{E})$. This decomposition is central to the paper: physics-based rendering supplies correctness and 3D control, while the generative model accounts for the high-frequency ambiguity that a deterministic avatar would otherwise average away.
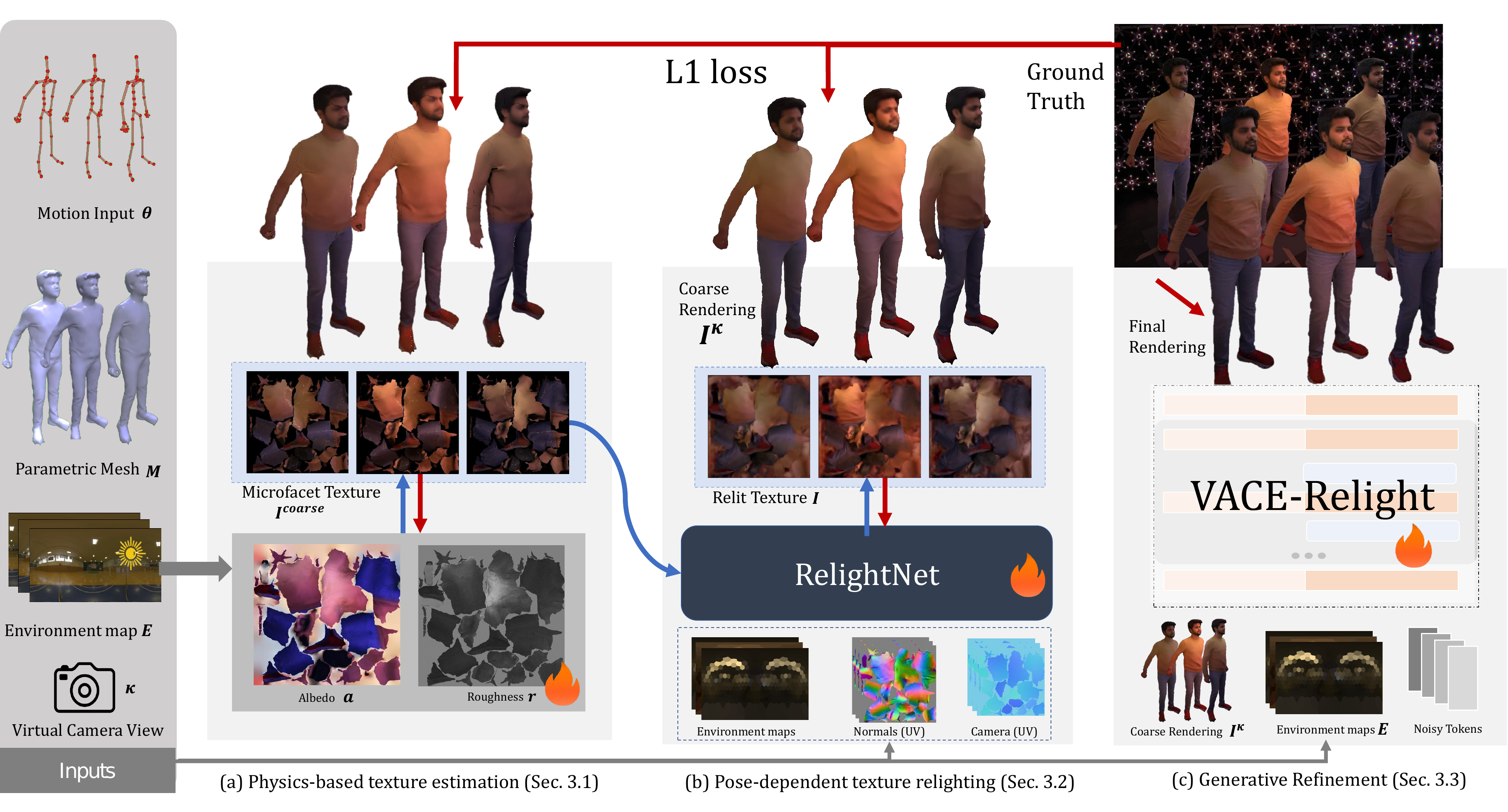
Step 1: Physics-based texture in UV space
The first stage uses a person-specific parametric avatar that predicts a temporally consistent animated mesh $M_t$ from skeletal motion. On top of this mesh, the authors optimize person-specific material parameters in UV space so that the avatar can be rendered under novel environment lighting. The outgoing radiance at a surface point is described by the rendering equation:
$$L_o(x, \omega_o) = \int f_r(x, \omega_i, \omega_o)\, L_i(x, \omega_i)\, V(x, \omega_i)\, \langle \omega_i, n \rangle\, d\omega_i,$$
where $f_r$ is the BRDF, $L_i$ is incoming illumination, $V$ is visibility, and $n$ is the surface normal. GRA approximates $f_r$ with a Cook--Torrance microfacet BRDF parameterized by spatially varying albedo $a(x)$ and roughness $r(x)$.
The paper optimizes these maps by differentiable rendering in UV space under a single-bounce assumption. Concretely, it minimizes an $\ell_1$ reconstruction loss between rendered images and ground-truth relit frames:
$$\mathcal{L}_{\mathrm{mf}} = \sum_{\kappa,t} \left\| \mathcal{P}(M_t, \kappa, \mathbf{E}; a, r) - I^{\mathrm{gt}}_{t,\kappa} \right\|_1,$$
where $\mathcal{P}$ denotes differentiable microfacet rendering. In the supplementary details, the authors note that this stage is computed in a $512\times512$ UV atlas, with per-texel visibility evaluated using an OptiX ray tracer and calibrated lightstage LED positions mapped to environment-map directions. The optimized coarse render is physically meaningful but still visually limited by the simplified reflectance model and by imperfect tracking.
Step 2: RelightNet for learned UV-space refinement
The second stage, RelightNet, is a feed-forward neural model that refines the coarse physically based result. Its purpose is to capture pose-dependent texture dynamics and illumination effects that exceed the microfacet approximation, such as local texture changes induced by motion, more complex global illumination, and residual errors due to the static UV representation on a deforming mesh.
RelightNet maps the target environment map, the coarse relit texture, a short history of normal maps, and a view-direction encoding to a refined UV texture:
$$I_t = \mathcal{R}(E_t, I^{\mathrm{coarse}}_t, N_{t-k:t}, C_t).$$
The refined texture is projected back onto the mesh and rasterized into the target camera view. Architecturally, RelightNet is a UNet-like model operating entirely in UV space. The paper states that it uses convolutional layers at higher resolutions for efficiency, and interleaves convolution, self-attention, and cross-attention at lower resolutions. The environment map is injected through cross-attention, and the model is trained with an $\ell_1$ image reconstruction loss. In the supplementary implementation details, the model input has 15 channels, attention uses 4 heads, and the final output is a 3-channel texture.
This stage is deterministic, which makes it strong for coarse shading and structural alignment but still insufficient for the stochastic high-frequency details that matter perceptually. The paper repeatedly emphasizes that deterministic regression tends to regress toward the mean for wrinkles and similar appearance cues.
Step 3: Generative refinement with a video model
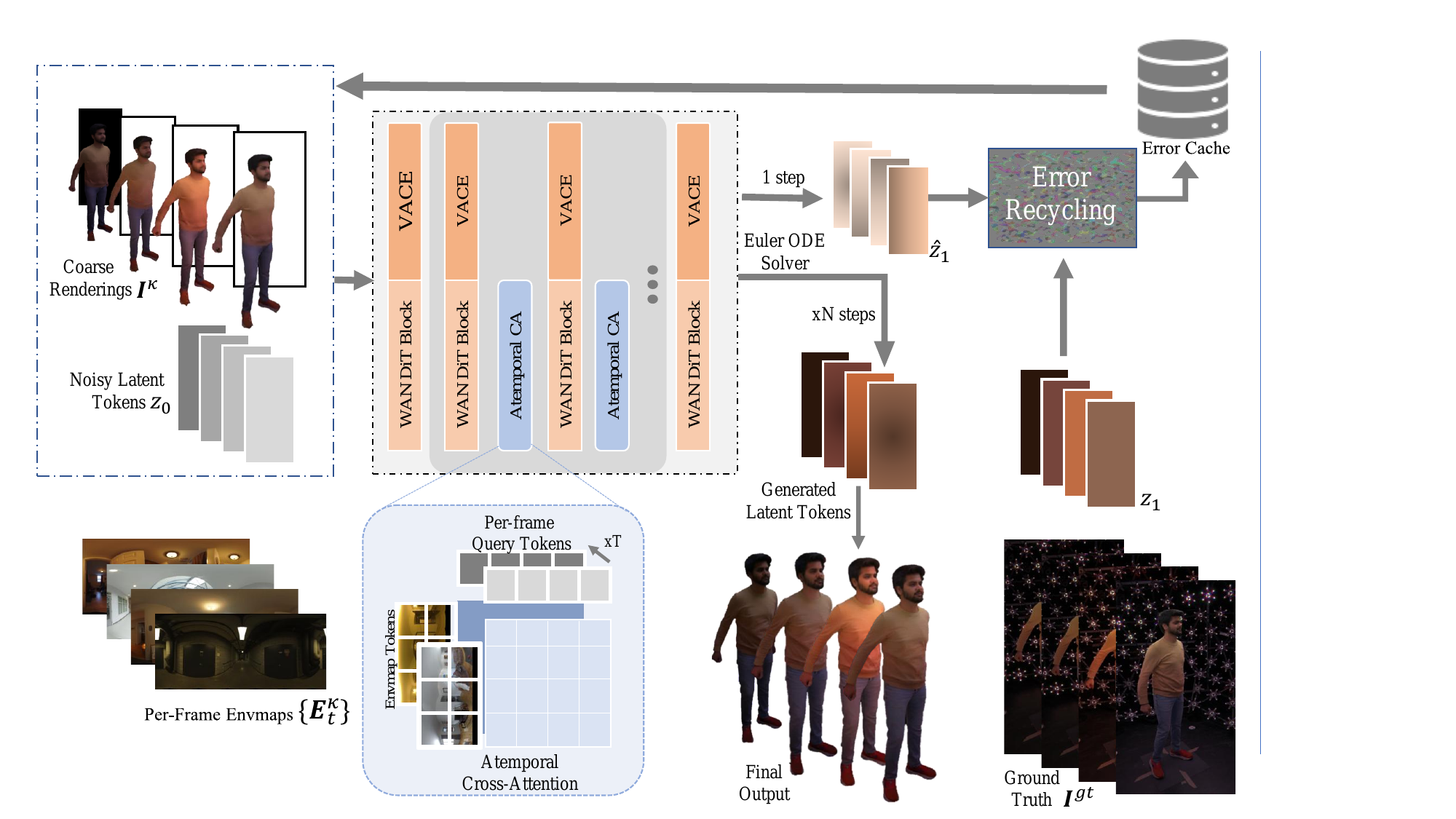
The final stage treats relighting as a video-to-video generation problem. Instead of refining individual frames independently, GRA fine-tunes a pretrained video generation backbone based on latent flow matching in the latent space of a 3D VAE. The conditioning set consists of the RelightNet output in image space and the target illumination.
The latent flow matching objective is written as:
$$\mathcal{L}_{\mathrm{FM}} = \mathbb{E}_{s \sim \mathcal{U}[0,1]} \left\| v(z_s, s, c) - (z_1 - z_0) \right\|^2,$$
with the interpolation path $z_s = (1-s) z_0 + s z_1$, where $z_0$ is Gaussian noise, $z_1$ is the encoded clean latent, and $c$ is the conditioning signal. At inference time, the model integrates an ODE from noise to data space and then decodes the resulting latent video.
The paper’s backbone choice is WAN2.1-VACE, a video-to-video model that provides spatio-temporal control through a reference-video conditioning path. GRA adapts this backbone rather than training a new video generator from scratch, and the ablation results show that this pretrained prior is crucial for convergence and quality.
VACE control and concept decoupling
To control the denoising process, the authors use VACE-style concept decoupling. The coarse RelightNet renderings are split into reactive frames and inactive frames using a binary mask $M$:
$$F_{\mathrm{reac}} = I^{\kappa} \odot M, \qquad F_{\mathrm{inac}} = I^{\kappa} \odot (1-M).$$
Reactive frames are the ones the model is asked to refine, while inactive frames act as temporal anchors that reduce drift. Both streams, together with the mask, are encoded through the VACE control unit and fused into the diffusion backbone. The paper also adds a reference image under neutral illumination, which helps preserve identity-specific appearance independently of the target lighting.
During training, the first five frames of the conditioning sequence are sometimes replaced with ground-truth frames. This happens with probability 40%, and those frames are marked as inactive. The goal is to teach the model to continue a sequence from a short seed, which is later important for long-form rollout at inference time.
Atemporal lighting conditioning
Because the RHC dataset captures a distinct environment map in every frame, GRA injects illumination explicitly on a per-frame basis. The environment maps are transformed to camera space, encoded with the VAE encoder, and then attached to the DiT features using atemporal cross-attention. The key design choice is that each video frame attends only to its own environment-map latent, rather than using temporal cross-attention across all lighting tokens.
The paper argues that this is an inductive bias aligned with the data: if lighting changes every frame, forcing the model to learn a full temporal attention matrix is both less efficient and more computationally expensive. The ablations support this claim: temporal lighting conditioning performs slightly worse than the proposed atemporal version, and removing lighting conditioning entirely leads to more visible shading errors.
Error recycling for long-form generation
To support long sequences, GRA adopts error recycling. The motivation is that even if a model performs well on short clips, self-generated outputs at inference time drift away from the ground-truth distribution seen during training. Error recycling injects reconstruction residuals from previous generations as perturbations during training, teaching the model to recover from its own mistakes.
The paper defines perturbed latents $\tilde{z}_0$ and $\tilde{z}_1$, constructs the noisy path
$$\tilde{z}_s = (1-s)\tilde{z}_0 + s\tilde{z}_1,$$
and trains with the loss
$$\mathcal{L}_{\mathrm{ER}} = \mathbb{E}_s \left\| v(\tilde{z}_s, s, c) - (z_1 - \tilde{z}_0) \right\|^2.$$
In effect, the model learns to map corrupted trajectories back to clean outputs. The supplementary ablation on long clips shows that this stabilizes metrics as clip length grows, whereas removing error recycling causes a consistent degradation over longer rollouts.
Training and implementation details
The paper trains the system per subject. The main dataset is the Relightable Holoported Characters (RHC) dataset, which contains 40 synchronized camera views of five subjects performing diverse motions, with interleaved uniformly lit and relit frames. Training uses 1,015 HDR environment maps from the Laval Indoor dataset, while testing uses 8 unseen environments. Each subject has 28,420 training and 14,336 testing frames per camera, captured at 60 Hz. The experiments evaluate four subjects, use 37 cameras for training, and hold out 3 cameras for novel-view testing.
Input images are downsampled from the captured resolution of $4096\times2160$ to $1024\times540$ for processing. Test sequences consist of 128 consecutive relit frames under a fixed environment. The reported metrics are averaged over every 10th frame on held-out views, and for video quality the paper reports Fréchet Video Distance on 17-frame clips sampled every 200 frames.
The character animation module is trained first using multi-view sequences under uniform lighting plus 3D supervision from Neus2 reconstructions, following the Deep Dynamic Characters training protocol. This yields the tracked mesh sequence used by the downstream relighting stages.
For microfacet optimization, the authors minimize the same $\ell_1$ loss over all cameras and time steps using Adam with learning rate $10^{-5}$ for 13K iterations on a single A40 GPU, batch size 1, and 8 gradient accumulation steps. RelightNet is trained with Adam at learning rate $10^{-4}$ for 50K iterations on 4 A40 GPUs, batch size 1 per GPU, and 2 gradient accumulation steps.
The generative refinement stage is initialized from pretrained WAN2.1-VACE and fine-tuned on 17-frame clips at resolution $1024\times544$; since the source images are $1024\times540$, the paper pads them to meet the model’s resolution requirement. The DiT backbone is adapted with LoRA of rank 32, the VACE adapter is fully fine-tuned, and the atemporal lighting-conditioning layers are trained from scratch. Training takes 4K iterations on four H100 GPUs with batch size 1 per GPU and two gradient accumulation steps.
To diversify the mostly static-camera dataset, the authors use synthetic augmentations: with 10% probability they repeat a single frame for a clip, and with 90% probability for such static clips they simulate camera motion via image-space translation and scaling. For dynamic clips, synthetic camera motion is applied with 5% probability.
Experiments
Evaluation setup
The paper evaluates photorealistic rendering under novel poses, viewpoints, and lighting, including settings that were not seen during training. Because the method is grounded in explicit relighting physics, it can generalize to one-light-at-a-time illumination even though such lighting is not observed in the training distribution.
Metrics are reported as PSNR, SSIM, LPIPS, and FVD. The authors explicitly note that PSNR and SSIM are imperfect for relighting because they tend to reward blurry, deterministic outputs, while LPIPS and FVD better capture the perceptual benefits of a generative approach.
Main comparison against relightable avatar baselines
GRA is compared with Relighting4D (R4D), IntrinsicAvatar (IA), MeshAvatar (MA), and DNF-Avatar (DNFA). For fairness, R4D is extended to a motion-driven setting using multi-view supervision and ground-truth environment maps, and its SMPL mesh is replaced by the higher-quality DDC-tracked mesh. IA, MA, and DNFA are trained with multi-view supervision and ground-truth environment maps in their standard SMPL-based formulations.
The main quantitative finding is that GRA is strongest on perceptual quality and temporal realism, especially LPIPS and FVD. It is competitive on PSNR and SSIM, but the paper stresses that these pixelwise metrics are not ideal for relighting. In the detailed per-subject table below, GRA achieves the best LPIPS and FVD on every subject, while PSNR/SSIM can still favor deterministic baselines on some sequences.
| Method | S1 PSNR | S1 LPIPS | S1 SSIM | S1 FVD | S2 PSNR | S2 LPIPS | S2 SSIM | S2 FVD | S3 PSNR | S3 LPIPS | S3 SSIM | S3 FVD | S4 PSNR | S4 LPIPS | S4 SSIM | S4 FVD |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R4D | 29.89 | 10.31 | 87.15 | 247 | 31.13 | 8.04 | 87.08 | 161 | 29.32 | 10.62 | 87.67 | 186 | 31.98 | 10.07 | 87.90 | 168 |
| IA | 27.25 | 18.25 | 81.39 | 408 | 28.87 | 15.43 | 82.07 | 345 | 26.14 | 22.52 | 79.07 | 621 | 29.50 | 18.46 | 82.91 | 354 |
| MA | 29.71 | 9.09 | 84.69 | 77 | 30.36 | 8.03 | 84.99 | 74 | 28.35 | 10.16 | 84.60 | 64 | 31.13 | 8.50 | 84.59 | 73 |
| DNFA | 26.32 | 11.57 | 82.50 | 212 | 28.57 | 9.40 | 82.92 | 131 | 26.37 | 12.04 | 82.26 | 150 | 29.31 | 10.82 | 84.12 | 124 |
| Ours | 30.49 | 6.42 | 87.52 | 49 | 31.15 | 5.64 | 87.50 | 48 | 29.11 | 7.40 | 87.16 | 52 | 32.09 | 6.55 | 87.35 | 63 |
Qualitatively, the paper reports that R4D tends to over-smooth, IA suffers from tracking inaccuracies, MA is sharper but still limited by pose-only conditioning and restrictive reflectance assumptions, and DNFA is sharper than IA but can exhibit visible high-frequency artifacts. GRA is described as producing sharper wrinkles and more plausible relighting while preserving temporal coherence.


Ablation studies
The ablation analysis is particularly informative because it shows how each stage contributes to the final result. Microfacet rendering alone achieves reasonable PSNR due to correct low-frequency shading, but it lacks fine-scale detail and has visible transport artifacts. Adding RelightNet improves PSNR and SSIM by learning pose-correlated appearance and more complete illumination effects. Adding the generative refinement stage substantially improves LPIPS and FVD, which the paper interprets as recovering stochastic high-frequency detail and improving temporal coherence.
| Method | PSNR | LPIPS | SSIM | FVD |
|---|---|---|---|---|
| Microfacet Rendering | 29.34 | 12.26 | 86.85 | 178.42 |
| + RelightNet | 30.90 | 8.92 | 89.25 | 118.24 |
| + Generative Refinement (Ours) | 30.49 | 6.42 | 87.52 | 48.79 |
| Ours w/ Temporal Lighting Conditioning | 30.78 | 6.53 | 88.00 | 58.18 |
| Ours w/o Atemporal Lighting Conditioning | 30.53 | 6.48 | 87.76 | 58.21 |
| Ours w/o VACE | 30.35 | 6.93 | 87.12 | 61.84 |
| Ours w/o RelightNet | 29.56 | 6.66 | 87.26 | 63.81 |
| Ours w/o VACE Finetuning | 24.92 | 22.43 | 70.76 | 230.94 |
| Ours w/o Prior | 30.02 | 9.60 | 86.67 | 394.91 |
| Ours w/ Neural Gaffer | 29.33 | 9.25 | 86.62 | 102.10 |
| Ours w/ Few-shot Adaptation | 29.82 | 7.01 | 87.30 | 65.25 |
These numbers support several important conclusions. First, the generative refinement stage is the main source of improvement in LPIPS and FVD. Second, atemporal lighting conditioning is preferable to temporal cross-attention, indicating that per-frame illumination alignment is easier to learn when it is built into the architecture as an inductive bias. Third, VACE is not just a convenience wrapper: removing it increases both perceptual error and temporal instability. Fourth, task-specific fine-tuning of the video prior matters substantially; without it, the model fails to treat the coarse renderings as a shading target and the output becomes physically implausible.

The supplementary material also includes an error-recycling study on long clips. The reported trend is that error recycling keeps metrics more stable as clip length grows, while the non-recycled variant degrades consistently. This is important because long-form temporal drift is one of the major failure modes of video generators in avatar settings.

Tracking robustness
Because the avatar pipeline depends on tracked meshes, the paper also analyzes robustness to tracking quality. Using fewer views for tracking degrades all metrics, but the outputs remain coherent in many cases. This shows that the system is sensitive to geometry quality, as expected, but not catastrophically so.
| Method | PSNR | LPIPS | SSIM | FVD |
|---|---|---|---|---|
| 2-view tracking | 26.25 | 11.23 | 81.85 | 73.49 |
| 4-view tracking | 29.53 | 7.12 | 86.28 | 52.69 |
| Ours | 30.49 | 6.42 | 87.52 | 48.79 |

Comparison to sparse-view Gaussian relighting
The supplementary section compares GRA to Relightable Holoported Characters (RHC), a sparse-view Gaussian avatar method that requires image inputs at test time. GRA is pose-driven and does not require image conditioning at inference. On Subject 1, the paper reports that GRA has better LPIPS and FVD than both the 4-view and 0-view RHC variants, while remaining competitive on PSNR and SSIM.
| Method | PSNR | LPIPS | SSIM | FVD |
|---|---|---|---|---|
| RHC (4 views) | 31.38 | 7.01 | 90.00 | 54.57 |
| RHC (0 views) | 30.75 | 7.84 | 88.32 | 85.75 |
| Ours (0 views) | 30.49 | 6.42 | 87.52 | 48.79 |

The paper also reports a few-shot adaptation experiment. Starting from a checkpoint from one subject, the authors fine-tune the video model on only 170 frames, or equivalently ten 17-frame clips in the supplementary description, and observe that the adapted model can produce temporally consistent relighting for a new identity. The main takeaway is that the generative prior can transfer, although shading can become less precise than in the fully subject-specific setup.

Runtime
The paper includes a runtime breakdown on H100 GPUs, averaged over 100 runs of 17-frame generation. The video model is the largest bottleneck, and microfacet rendering is also relatively expensive because of visibility computation. The authors explicitly note that both components are candidates for distillation or speedups.
| Stage | ms |
|---|---|
| Microfacet | 404.6 |
| RelightNet | 25.4 |
| VAE env. | 140.2 |
| Video model | 840.3 |
| VAE dec. | 145.6 |
| Total | 1556.2 |
Discussion, applications, and limitations
Beyond the core relighting benchmark, the paper argues that the explicit physical intermediate representation enables additional applications. The model generalizes to OLAT lighting without retraining, supports near-field relighting by using the w/o RelightNet variant with a point light source, and permits relightable texture editing by directly modifying the optimized UV albedo map and re-rendering. These examples are presented as evidence that physics-grounded intermediate control is useful even when the final appearance is produced by a generative model.

The supplementary discussion also emphasizes that the method can be adapted to few-shot identity transfer, showing that the pretrained video prior retains broader motion and illumination knowledge. However, the final quality is still tied to the quality of the tracked mesh and the conditioning signal.
The paper’s stated limitations are straightforward and practical. First, error recycling can introduce minor temporal color jitter because shading changes may be partly interpreted as residual error during long rollouts. Second, the runtime remains far from interactive, with the authors reporting roughly 2 seconds per frame and suggesting that distillation would be needed for real-time use. Third, the current system does not explicitly model high-resolution facial expressions or hand articulation; the authors propose integrating dedicated face and hand models in future work. They also mention that future versions could incorporate more explicit near-field relighting.
Conclusion
GRA is best understood as a hybrid relightable-avatar system: an explicit 3D avatar supplies physically grounded control, RelightNet fills in pose- and lighting-dependent texture effects, and a fine-tuned video diffusion model restores high-frequency detail and temporal realism. The experimental results support the paper’s main thesis that relighting humans is better framed as a generative problem once the coarse physics is handled explicitly. The method is strongest where deterministic baselines struggle most: perceptual quality, temporal consistency, and robustness to challenging or unseen illumination.