Bagpiper-TTS
Bagpiper-TTS: Natural Language Guided Universal Speech Synthesis

Bagpiper-TTS is a universal speech synthesis system using natural language to guide speech generation with rich details. It replaces rigid metadata inputs and supports diverse tasks like multi-talker dialogue, intent-to-speech, role-play, and singing voice synthesis in a single unified model.
Links
Paper & demos
Abstract
Classical TTS systems typically rely on rigid input formats and predefined metadata slots, limiting their ability to fulfill flexible user requirements. This paper introduces Bagpiper-TTS, a universal speech synthesis system that deals with diverse natural language user requests. Given a natural language prompt, Bagpiper-TTS first reasons over the users' intent to derive a rich caption, i.e., a comprehensive textual blueprint encompassing both transcription and nuanced metadata. Subsequently, this caption guides the synthesis of the target speech. Our model inherently supports a broad spectrum of tasks besides classical TTS applications, including multi-talker, intent-to-speech, role-play synthesis, singing voice synthesis, and more. Experimental results demonstrate that Bagpiper-TTS achieves an 1.7% Word Error Rate (WER) on the Seed-TTS-Eval benchmark and match the performance of dedicated models in both LLM-as-a-judge and human subjective evaluations across multiple applications.
Introduction
Bagpiper-TTS is presented as a universal speech synthesis system that replaces rigid, slot-based TTS inputs with a natural language interface. The paper argues that classical TTS pipelines are ill-suited to real user requests because they typically require predefined metadata fields such as speaker identity, emotion, language, or prosody. In contrast, Bagpiper-TTS is designed to accept free-form instructions and interpret them through a reasoning-and-planning stage before generating speech.
The central idea is to translate a user prompt into a rich caption: a dense textual blueprint that captures both transcription content and nuanced speech metadata. This rich caption then directly conditions speech synthesis. The system is intended to handle not only standard text-to-speech, but also tasks such as multi-talker dialogue, intent-to-speech, role-play synthesis, and singing voice synthesis, using the same natural language entry point.
The paper positions this as a step toward more human-centric speech generation: users do not need to understand a model’s internal control vocabulary, because they can express instructions in ordinary language. The model is built on top of an audio foundation model, Bagpiper-Base, and is fine-tuned with simulated instruction-following data that links user requests, an internal planning trace, and rich captions.
Core Architecture and System Design
Bagpiper-TTS is built on Bagpiper-Base, described as an audio-centric foundation model for cross-modal understanding and synthesis. The base model uses a Qwen3-8B-Base decoder-only language model as the backbone and represents audio using the multi-stream X-Codec tokenizer operating at 50 Hz with 8 discrete codes per frame as the generation target.
According to the paper, Bagpiper-Base was pretrained on 600 billion tokens spanning caption-to-audio synthesis, audio-to-caption understanding, and pure text modeling. The pretraining mixture includes speech, music, and environmental sounds. The authors emphasize that this large-scale caption-aligned pretraining is what makes the downstream free-form instruction setting viable: the model already has strong alignment between detailed textual descriptions and acoustic realizations, while retaining text reasoning capability.
The Bagpiper-TTS workflow is described as a three-stage hierarchy executed end-to-end within one unified model:
- Textual planning: infer user intent and outline the structure of the desired output.
- Rich caption synthesis: produce a comprehensive textual blueprint containing transcription plus paralinguistic and acoustic details.
- Speech generation: synthesize audio conditioned on the rich caption.
The paper frames this as a Planning-Caption-Generation pipeline. The key novelty is not a separate modular system with explicit interfaces, but a single model that internalizes the translation from natural language request to speech blueprint to audio.
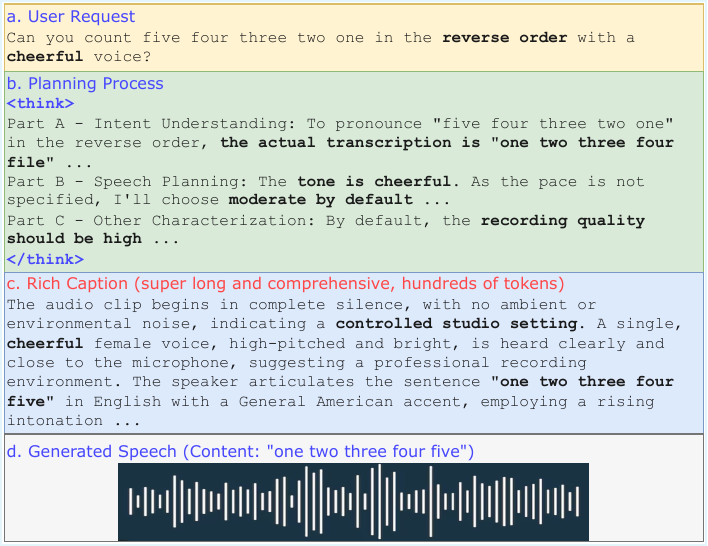
Natural Language as a Universal Interface
The paper’s main conceptual claim is that natural language becomes the universal control interface for speech synthesis. Instead of forcing the user to populate rigid metadata slots, Bagpiper-TTS accepts requests that may interleave transcription, speaker cues, prosody, style, context, and even non-speech scene details in arbitrary order and style.
This is especially important for the paper’s target scenarios, where the user may provide indirect or incomplete specifications. For example, in intent-to-speech, the transcription is not explicitly requested but must be inferred from context. In role-play synthesis, character descriptions imply acoustic properties. In singing voice synthesis, the prompt may need to preserve melodic content and background music cues. The authors argue that treating these as separate specialized pipelines is brittle, whereas a natural language interface allows one model to unify them.
The paper also notes that the model is intended to operate without a system prompt that specifies the task; the application is inferred from the user request itself. This is important because the training and evaluation setup aim to test whether the model can infer the appropriate speech-generation behavior from the request alone.
Fine-Tuning Data Simulation Pipeline
Since direct instruction-following speech data is scarce, the paper constructs a large synthetic fine-tuning corpus through a six-step simulation pipeline. The goal is to produce triplets of user request, planning process, and rich caption that are logically coherent and aligned with actual speech examples.
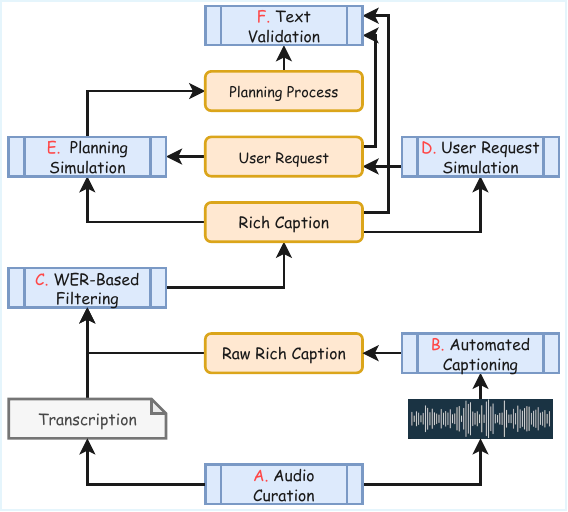
Step-by-step pipeline
- Step A: Speech curation. The team first selects speech clips for each target application. Ground-truth transcriptions are used when available; if they are missing, pseudo-transcriptions are generated with Qwen3-ASR.
- Step B: Automated captioning. The speech clips are passed through Qwen-30B-A3B-Captioner to generate detailed rich captions. The paper explicitly acknowledges that these captions may hallucinate some acoustic or linguistic attributes.
- Step C: WER-based filtering. The transcription extracted from the rich caption is compared to the ground-truth transcription using Word Error Rate. Samples above a threshold are removed. For most tasks, the threshold is set to enforce exact match. The paper also mentions optional caption refinement by the LLM to improve retention while preserving transcription accuracy.
- Step D: User request simulation. The text LLM reverse-engineers diverse user requests from the rich captions. The prompt is designed to vary request length, linguistic style, and metadata ordering.
- Step E: Planning-process simulation. The LLM generates an internal textual planning trace that bridges the request and the caption, covering intent interpretation, speech-specific attributes, and non-speech context.
- Step F: Textual consistency validation. An LLM-as-a-judge scores the logical coherence of the triplet on 1–5 scales across task-specific criteria. Only samples with an average score above 3.5 and no individual score below 3 are retained.
The paper states that Qwen3-235B-A22B-Instruct-FP8 is the primary text LLM used in the data processing pipeline, and that Gemini-3-Flash can additionally be used as a multimodal validator to check consistency between the synthesized caption and ground-truth speech.
Application-specific data construction
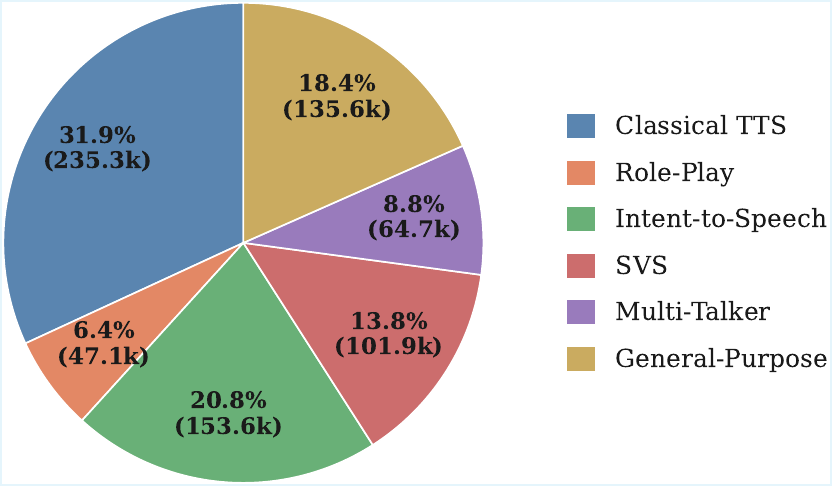
The authors curate fine-tuning data for several applications, plus a general-purpose subset for out-of-definition requests. The full synthetic corpus contains 738k examples.
- Classical TTS. Built from LibriTTS-R for neutral, prosodically consistent speech, and from Genshin and Starrail for expressive, spontaneous speech. Requests vary in how much metadata is explicitly specified.
- Multi-talker TTS. Constructed from long-form recordings in Gigaspeech and SSSD, with VibeVoice-ASR used to capture multi-speaker intersections. The focus is on speaker identity and temporal interleaving.
- Intent-to-speech. The transcription is intentionally absent from the request and must be inferred from context, while training examples are selected for high communicative value.
- Role-play TTS. Character descriptions are mapped to inferred acoustic characteristics. The paper gives the example of a “senior mathematics professor” implying a deep, authoritative voice.
- Singing voice synthesis. Singing samples from the base pretraining set are used. Pseudo-transcriptions are generated with Qwen3-ASR, and the transcription WER threshold is relaxed to 10% to allow for melodic variation. Background accompaniment cues are included explicitly.
- General-purpose TTS. Two million speech samples from the base pretraining data are randomly selected to form a general-purpose subset. Claude 4.6 Opus is used to generate 40 application scenarios, and the system selects applicable ones during simulation.
The paper emphasizes that the resulting training data does not include a system prompt, so the model must learn to infer the application from the request itself.

Evaluation Protocol
The paper evaluates Bagpiper-TTS at three levels:
- Classical benchmarks: Seed-TTS-Eval (English).
- Specialized applications: multi-talker, intent-to-speech, role-play, and singing voice synthesis.
- General-purpose flexibility: qualitative testing on hand-written out-of-definition requests.
For the specialized applications, the authors generate 300 unique user requests per application using GPT-OSS-120B, with strict isolation from the training-data simulation process. They report:
- WER as an objective intelligibility metric.
- Task fulfillment (TF) scored by Gemini-3-Flash on a 1–5 scale as an LLM-as-a-judge metric.
- Human subjective evaluation on Amazon Mechanical Turk, with 10 examples per application rated by at least three annotators on a 1–5 scale, where 3 is acceptable.
The paper explicitly states that it does not evaluate speaker similarity on the classical benchmark, because the system does not accept reference-audio prompts. That is treated as a limitation rather than a missing experimental detail.
Experimental Setup
Bagpiper-TTS is trained by supervised fine-tuning on the curated simulation datasets for 2 epochs. The optimization setup uses a global batch size of 160k tokens and a constant learning rate of $1 \times 10^{-5}$. Training completes in 16 hours on 8 NVIDIA H100 GPUs.
At inference time, the model uses decoupled Top-$k$ sampling for text and speech modalities, and classifier-free guidance for speech generation with guidance scale $\lambda = 3$. The paper refers readers to the Bagpiper-Base work for the exact sampling details.
Results on Classical TTS
On Seed-TTS-Eval (English), Bagpiper-TTS achieves a WER of 1.7%. The paper compares this with several frontier models and reports that the system remains competitive despite accepting free-form natural language prompts rather than rigid metadata slots.
| Model | WER |
|---|---|
| CosyVoice 2 | 2.6 |
| VibeVoice | 3.0 |
| Qwen3-TTS | 1.5 |
| Bagpiper-TTS | 1.7 |
The authors present this as evidence that the natural-language interface does not significantly degrade standard TTS intelligibility.
Results on Specialized Applications
For the advanced tasks, the paper reports results for multi-talker TTS, intent-to-speech, role-play TTS, and singing voice synthesis. Bagpiper-TTS is evaluated as a single universal model across all of them.
| Application | Model | WER | TF | MOS |
|---|---|---|---|---|
| Multi-talker | VibeVoice-1.5B | 4.6 | 3.32 | 3.77 |
| Multi-talker | Bagpiper-TTS | 4.2 | 4.23 | 3.60 |
| Intent-to-speech | Bagpiper-TTS | — | 3.80 | 3.57 |
| Role-play TTS | Bagpiper-TTS | 2.0 | 3.72 | 3.93 |
| Singing voice synthesis | YuE | 11.0 | 3.75 | 3.73 |
| Singing voice synthesis | Bagpiper-TTS | 7.2 | 4.60 | 3.67 |
The paper also reports aggregate human and judge-based scores across the four advanced applications. Bagpiper-TTS reaches a mean LLM-as-a-judge task fulfillment score of 4.09 and an average human subjective score of 3.69. The discussion notes that specialized baselines may outperform Bagpiper-TTS on some subjective dimensions, but the authors emphasize that those baselines are narrower, application-specific systems whereas Bagpiper-TTS is a generalist model spanning multiple tasks.
Interpretation of the Results
The reported numbers support the paper’s claim that a single natural-language-guided model can cover a broad range of speech generation tasks while remaining competitive on standard intelligibility metrics. Several points stand out:
- On classical TTS, the model stays close to frontier systems in WER despite not requiring structured metadata input.
- On multi-talker dialogue, Bagpiper-TTS improves both WER and task fulfillment relative to the cited VibeVoice baseline, though the human MOS is slightly lower.
- On role-play TTS, the model shows strong intelligibility and high MOS, indicating that the inferred character-to-voice mapping is useful in practice.
- On singing voice synthesis, Bagpiper-TTS improves WER and task fulfillment over YuE, while human MOS remains comparable.
The paper frames these findings as evidence that the rich-caption bottleneck is effective: the model first turns the prompt into a structured internal textual plan, then uses that plan to drive synthesis. The judge scores suggest that this internal reasoning helps fulfill the request even when the prompt is ambiguous, indirect, or non-standard.
Qualitative Behavior
The qualitative section highlights several behaviors that illustrate the intended flexibility of the approach. The paper reports that the model can correctly handle prompts such as “count from one to five” or “read five four three two one in reverse order,” producing the logically appropriate spoken output “one two three four five”. This suggests the model is not merely copying the request text but is able to reason over the instruction.
Another example concerns a prompt like “gentle criticism.” The model is said to adapt both the wording and the acoustic delivery so that the criticism remains polite and restrained. The paper also notes that the model can generate internal justifications in its planning stage, such as reasoning that content intended for children should be delivered warmly. The authors use this to argue that Bagpiper-TTS performs a form of latent judgment beyond static slot filling.
Limitations
The paper is explicit about two limitations. First, hallucinations persist in the simulation pipeline and during inference, especially in rich captions produced by the automated captioner. Even with filtering and validation, the authors do not claim that hallucination is eliminated.
Second, the approach focuses on textual natural language as the universal interface, but the authors acknowledge that some attributes are better grounded by acoustic prompts. In particular, they point out that speaker identity or voice characteristics can be more effectively specified with a reference audio clip. Because the system does not accept reference audio prompts, speaker similarity is not evaluated on the classical benchmark.
What the Paper Contributes
In technical terms, the main contributions are:
- A natural-language-guided TTS framework that treats free-form requests as the primary interface.
- A rich-caption intermediary representation that compresses transcription, metadata, and contextual constraints into a single generation blueprint.
- A synthetic data simulation pipeline for creating instruction-following speech data at scale.
- A single universal model that spans classical TTS, multi-talker dialogue, intent-to-speech, role-play synthesis, and singing voice synthesis.
- Evidence that the approach achieves competitive WER and strong task-fulfillment scores on both judge-based and human evaluation.
The paper’s broader message is that flexible speech synthesis should be modeled as a reasoning problem over language, not just a constrained acoustic generation problem. The rich-caption formulation is the key mechanism used to bridge user intent and speech realization.
Conclusion
Bagpiper-TTS proposes a practical route toward universal speech synthesis by combining a strong audio foundation model with a natural-language instruction interface and an intermediate rich-caption planning stage. The method is trained entirely through simulated triplets, and the experiments show that it can cover several demanding speech-generation tasks while preserving strong intelligibility.
The paper’s strongest technical claim is that a single model can interpret diverse user requests, reason through them in text, and synthesize speech that fulfills the request across multiple task types. Its strongest limitation is that the system still depends on caption quality and does not yet ground all attributes acoustically. Even so, the reported results suggest that rich-caption-mediated instruction following is a promising design for conversational AI and talking-head systems that need flexible speech generation behavior.