InteractiveAvatar
InteractiveAvatar: Real-Time Streaming Video Generation for Consistent and Intent-Aware Avatars
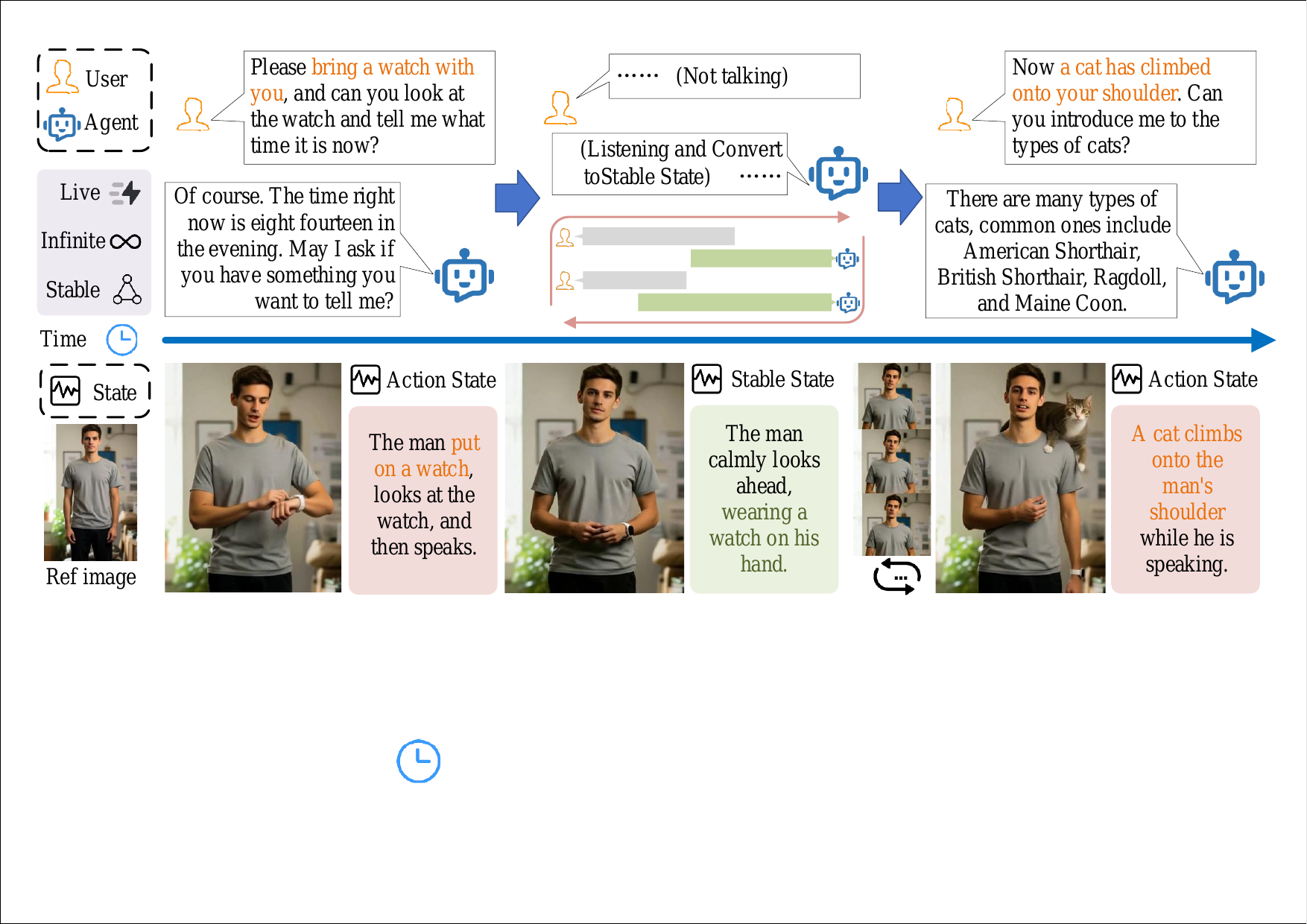
A real-time streaming avatar system that ensures long-term visual consistency and enables context-aware speech and actions by understanding user intent. It combines memory mechanisms for visual coherence with an intent reasoning module for interactive, natural avatar behavior beyond standard audio-driven models.
Links
Paper & demos
Abstract
Recent diffusion-based models have enabled realistic audio-driven avatar generation in real-time streaming. However, existing approaches struggle to maintain visual temporal consistency and fail to explicitly perceive user intent in complex interactive streaming scenarios. To address these challenges, we propose InteractiveAvatar, a real-time infinite-streaming video generation framework that supports visually consistent avatar video generation and intent-aware interactions. With autoregressive distillation, InteractiveAvatar achieves real-time str-eaming generation of human avatars over arbitrarily long durations. For visual consistency, we introduce a Long-Short Visual Memory (LSVM) mechanism that flexibly compresses historical visual information into compact tokens, preserving both short-range coherence and long-term consistency. To generate avatars with speeches and actions aligned with user intent, we propose a Reasoning-Reaction Module (RRM), which incorporates a State-Cycling strategy and a Cache-Switching mechanism. Extensive experimental results over diverse scenarios demonstrate that our method achieves state-of-the-art visual consistency in long-duration generation, while enabling complex user-avatar interaction in real time.
1. Problem Setting and Core Idea
InteractiveAvatar targets a setting that is more demanding than standard audio-driven talking-head synthesis: the model must generate real-time, infinite-streaming video of a human avatar that remains visually consistent over long durations while also reacting to user intent in interactive dialogue. The paper argues that current diffusion-based avatar systems are strong at lip sync and appearance quality, but still struggle with two specific failure modes in streaming use cases: (1) temporal drift over long horizons, because causal streaming systems only look back over a small recent window, and (2) weak intent modeling, because many systems treat the user mainly as an audio source rather than as a person expressing actions and goals.
The proposed solution combines three pieces: autoregressive distillation for efficient real-time generation, a Long-Short Visual Memory (LSVM) mechanism for long-range visual consistency, and a Reasoning-Reaction Module (RRM) for intent-aware action and speech planning. In the authors’ framing, LSVM addresses what the avatar should visually remember, while RRM addresses how the avatar should respond.
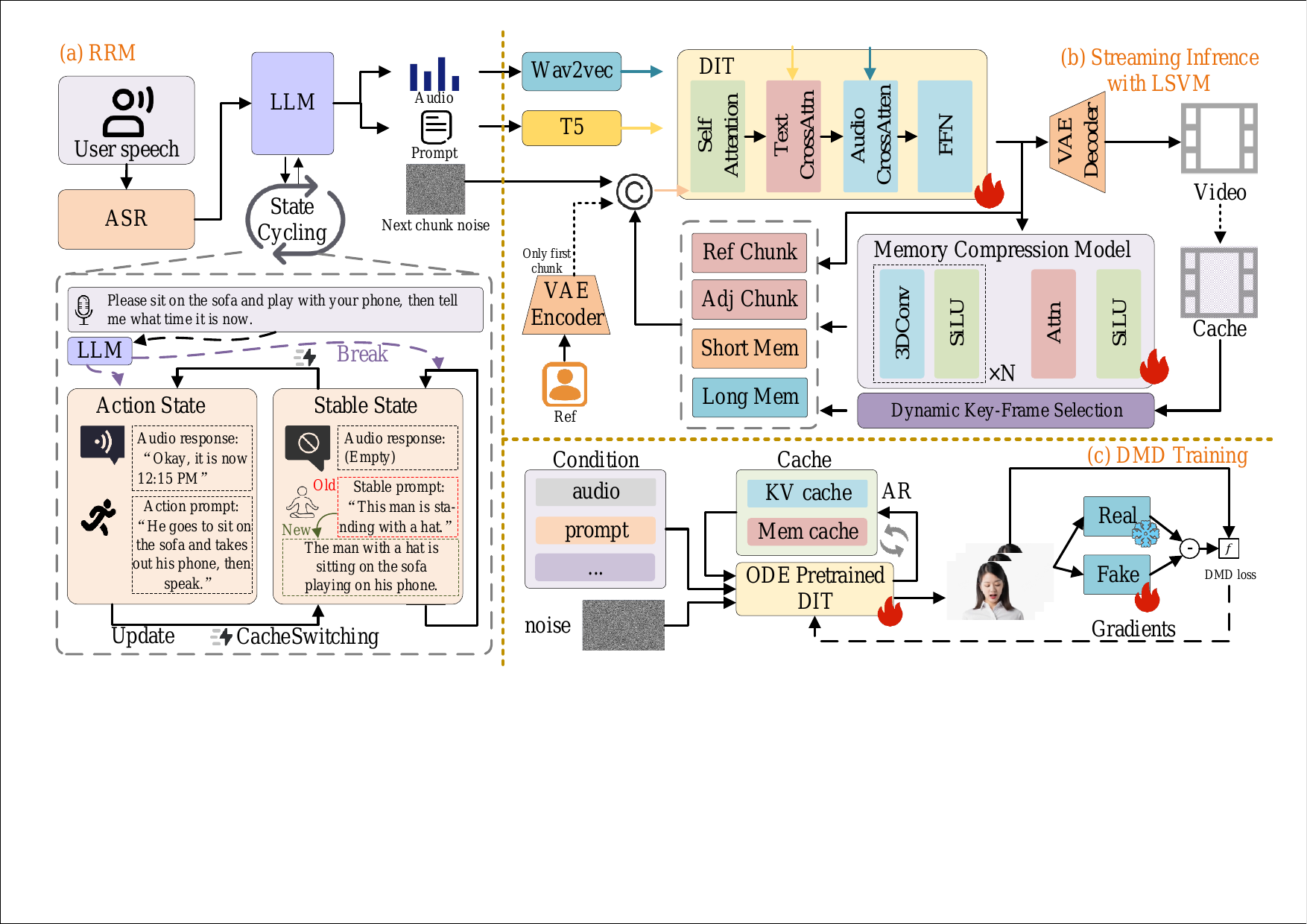
2. Overall Architecture
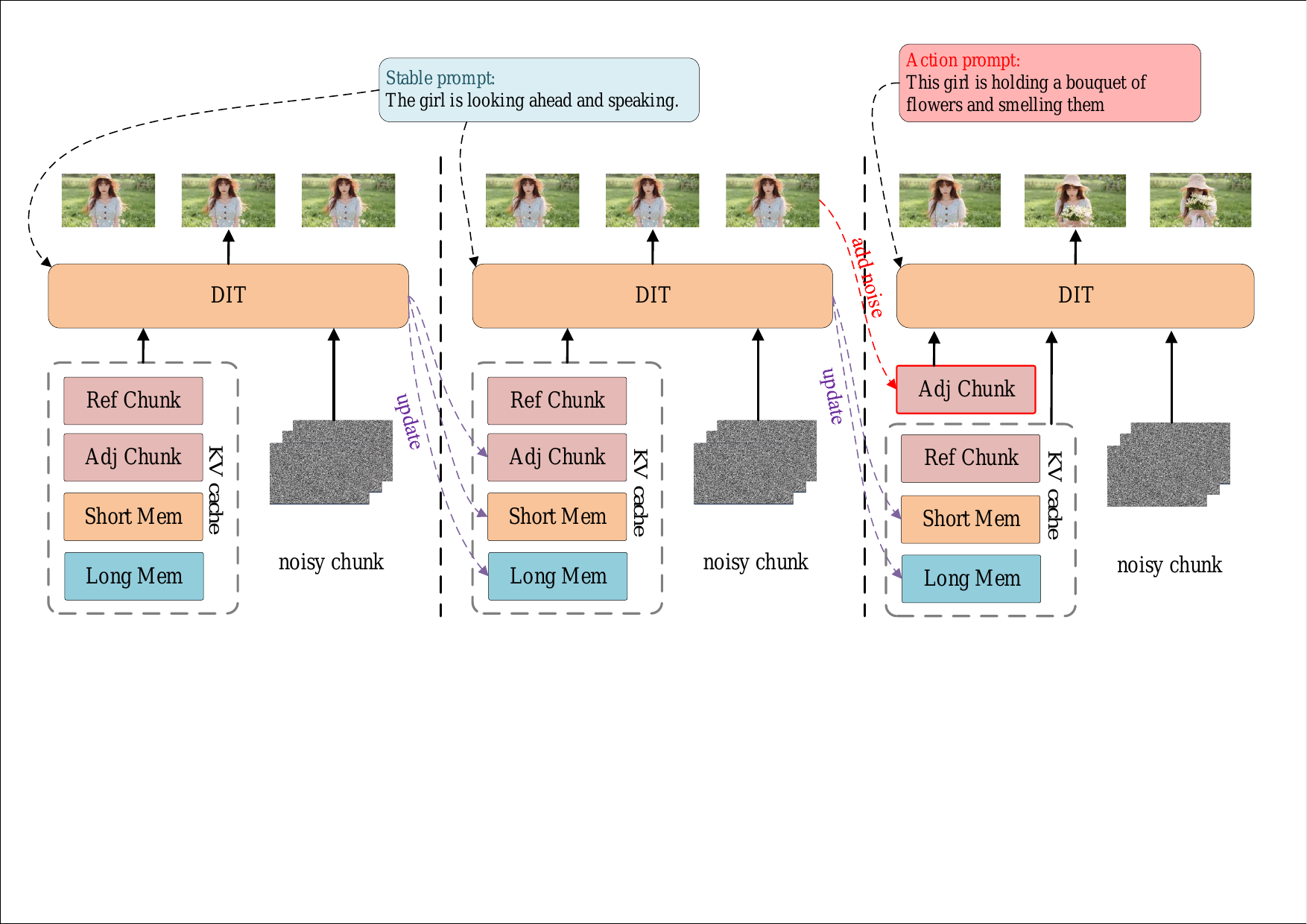
The system takes an avatar reference image and user speech as input. Speech is first transcribed into text by ASR. The text is then passed to the RRM, which uses an LLM to infer the user’s intent and produce two kinds of outputs: an action state containing an action prompt $p^{\mathrm{act}}$ and response audio $a^{\mathrm{resp}}$, and a stable state containing a prompt $p^{\mathrm{stable}}$ that describes the avatar after the action finishes. The streaming video generator is then conditioned on these outputs, with LSVM supplying compressed visual history so that frames remain coherent across chunks.
The paper’s headline design goal is to support an interactive cycle of listen → reason → act → stabilize without losing identity, object appearance, or local motion coherence. This is implemented on top of a Wan2.2 5B diffusion backbone and distilled into a few-step autoregressive generator for real-time inference.
3. Base Diffusion Formulation and Distillation
The method is built on a standard diffusion objective in latent space. A VAE encodes input data $x$ into latents $z = E(x)$, and forward diffusion produces noisy states $z_t = \sqrt{\alpha_t} z + \sqrt{1 - \alpha_t}\, \epsilon$. The DiT backbone predicts the injected noise via $\epsilon_\theta(z_t, t, c)$ conditioned on text and other signals. The training objective is the usual mean-squared error between predicted and true noise:
$$ \mathcal{L} = \mathbb{E}_{t, z_t, c, \epsilon} \left[\left\| \epsilon_\theta(z_t, t, c) - \epsilon \right\|_2^2\right]. $$
To make diffusion practical for streaming, the paper adopts Distribution Matching Distillation / Self-Forcing DMD, which distills a pretrained teacher into a few-step student generator. The distillation objective aligns the noisy distributions produced by student and teacher, written as a reverse-KL matching over diffusion timesteps:
$$ \mathcal{L}_{\mathrm{DMD}} = \mathbb{E}_t \left[ D_{\mathrm{KL}}\big(p_{\theta,t} \| p_{\mathrm{data},t}\big) \right]. $$
The paper states that this is essential for real-time performance: without DMD, inference speed collapses dramatically, while the full model can run at 26.68 FPS in the reported setup.
4. Long-Short Visual Memory (LSVM)
LSVM is the main mechanism for long-horizon visual consistency. The paper’s central claim is that keeping only a short causal window is insufficient for arbitrarily long streaming generation, because the model gradually forgets the avatar’s stable visual attributes and important scene state. LSVM therefore splits the history into two buffers: a short-term memory $\mathcal{M}_s$ for recent chunks and a long-term memory $\mathcal{M}_l$ for compact global key frames.
A lightweight compressor $\mathcal{C}(\cdot)$ maps video latents to compact memory tokens $m_t = \mathcal{C}(z_t)$. The temporal compression ratio is set to 1, so time is not downsampled; the compression happens mainly in spatial/token form. In training, the short-term window covers the last 5 seconds, while the long-term buffer is populated by randomly sampled frames from earlier history.
The memory buffers are formalized as a FIFO short-term queue of size $K$ and a long-term buffer of fixed capacity $N$:
$$ \mathcal{M}_s = \{m_{t-K+1}, \dots, m_t\}, \qquad \mathcal{M}_l = \{\tilde{m}_1, \dots, \tilde{m}_N\}. $$
During training, the model reconstructs selected target frames from both the short-term and long-term parts of a sampled video segment $H$ under a noise-as-mask strategy. The paper’s training objective encourages the generator to recover targets anywhere in the history conditioned on the concatenated memory representation $\Phi(H) = \operatorname{Concat}(\mathcal{M}_l, \mathcal{M}_s)$. The intent is to force the student model to preserve both fine-grained recent dynamics and semantically important older content.
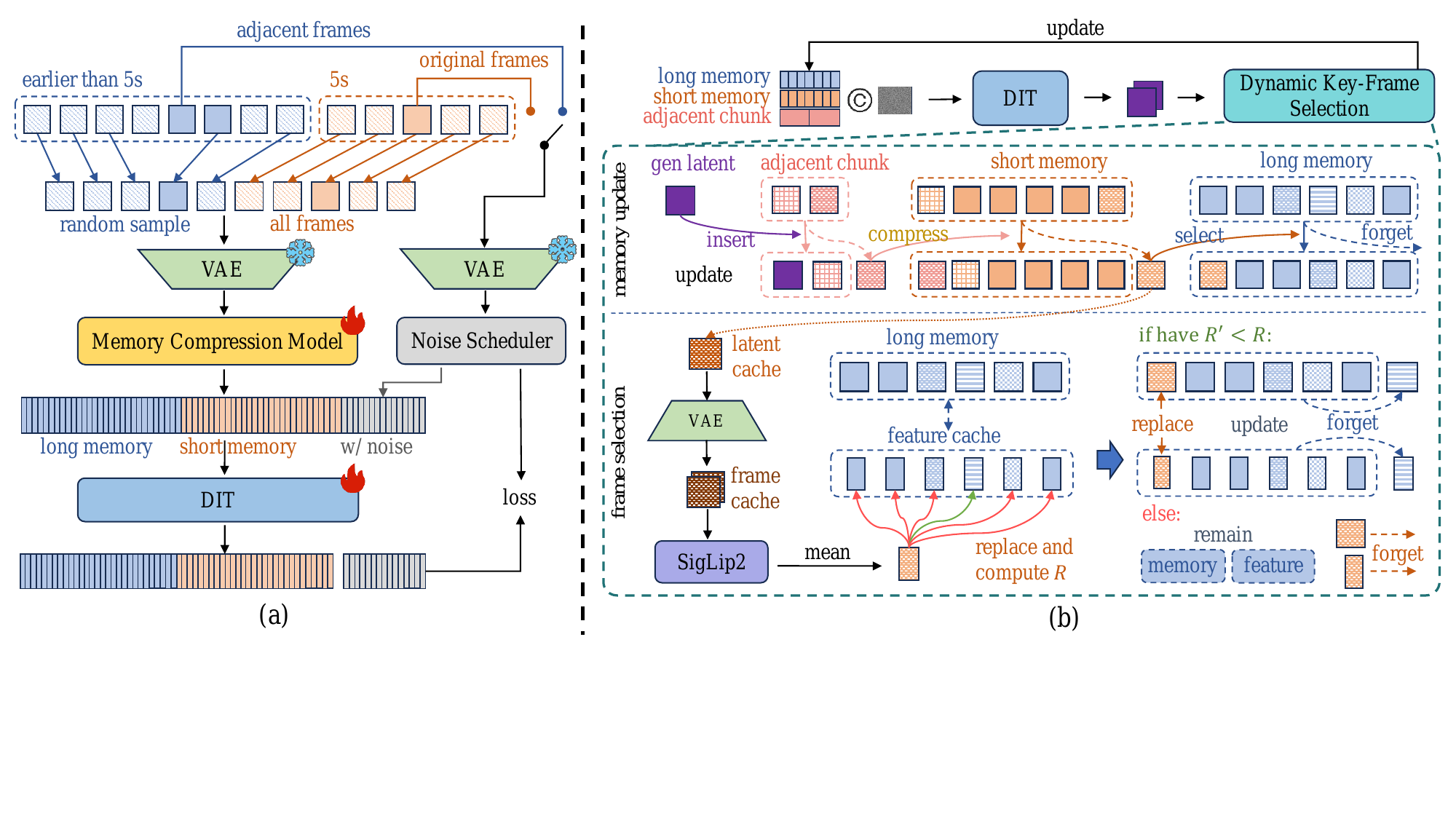
4.1 Dynamic Key-Frame Selection
At inference time, LSVM uses Dynamic Key-Frame Selection (DKFS) to decide which popped short-term frames should be promoted into long-term memory. This is not a naive uniform subsampling rule. Instead, the paper uses semantic features extracted by SigLIP2 from the corresponding real image frames of a candidate, averages them into a descriptor $\mathbf{s}_{\mathrm{cand}}$, and evaluates whether the candidate increases semantic diversity in the long-term buffer.
For the current long-term semantic set $\{\mathbf{s}_1, \dots, \mathbf{s}_N\}$, the paper defines an average pairwise cosine redundancy score:
$$ \bar{\rho}_i = \frac{1}{N-1} \sum_{j \neq i} \operatorname{cos}(\mathbf{s}_i, \mathbf{s}_j), \qquad R = \frac{1}{N} \sum_{i=1}^{N} \bar{\rho}_i. $$
A candidate is kept if replacing a slot with the candidate reduces redundancy, i.e. if $R' < R$. The stated effect is that the long-term memory becomes a semantically diverse set of key frames rather than a uniformly spaced history buffer. This should help preserve identity, scene state, and visually salient objects over long interactive sessions.
5. Reasoning-Reaction Module (RRM)
RRM is the paper’s intent-aware control module. It uses an LLM to convert the user’s transcribed text and current stable state into explicit action and response plans. The module is designed to bridge high-level natural language intent and low-level streaming video generation, so the avatar does not merely “talk back” but can also perform semantically appropriate actions.
5.1 State-Cycling Strategy
Under State-Cycling, the LLM receives the current user text $x_t$ and the previous stable-state prompt $p^{\mathrm{stable}}_{t-1}$, and outputs $(p^{\mathrm{act}}_t, a^{\mathrm{resp}}_t, p^{\mathrm{stable}}_t)$. The action prompt describes the motion to be executed, the response audio carries the spoken reply, and the stable prompt describes the static scene after the action completes.
The stream then follows a two-phase conditioning pattern: while response audio is active, generation is conditioned on the action prompt and the reply audio; once the response finishes, the system switches to the stable prompt only. This cycling is intended to avoid leaving the model stuck in a perpetual action state and to keep the avatar visually stable between user turns.
The paper emphasizes that this design is important for realistic dialogue, because many interactions are not pure speech synchronization events but require a sequence of distinct visual states such as listening, acting, then returning to a calm posture.
5.2 Cache-Switching Mechanism
To reduce latency when prompts change, the method introduces Cache-Switching for the prompt-conditioned key-value cache. If the action prompt changes from $p^{\mathrm{act}}_{t-1}$ to $p^{\mathrm{act}}_t$, the cached key-value tensors associated with affected neighboring chunks are recomputed under the new prompt, instead of starting from scratch. In compact notation, the paper writes the update as $\mathcal{K} \leftarrow \operatorname{Replace}(\mathcal{K}_{\mathrm{old}}, \mathcal{K}_{\mathrm{new}})$.
The appendix clarifies that the implementation re-noises already generated neighboring latents to the appropriate diffusion noise level before recomputing their KV representations. This is meant to quickly realign the streaming model with the new action instruction while preserving temporal continuity.
6. Training Pipeline and System Configuration
The paper uses a four-stage training pipeline. Stage 1 initializes audio-driven generation on the Wan2.2 5B backbone, with speech features extracted by a Wav2Vec encoder and injected through cross-attention; only cross-attention parameters are trained while the backbone stays frozen. Stage 2 trains the memory compression module on video reconstruction with short-term and long-term memory splits. Stage 3 performs ODE-based student initialization using block-wise causal attention to approximate teacher trajectories. Stage 4 applies Self-Forcing DMD distillation to produce a stable few-step autoregressive generator.
The main paper reports training at 576p resolution with 3 latents per chunk, using 64 NVIDIA H100 GPUs and FSDP with hybrid sharding. The reported learning rates are $10^{-5}$ for the student branch and $2 \times 10^{-6}$ for the fake score branch. The appendix adds that the final system distills to 3 diffusion steps, and that an attempted 2-step version degraded visual quality, especially identity consistency.
For inference, the system uses KV caching and pipeline parallelism across the DiT and VAE components on separate GPUs, with the appendix describing deployment on two H100 GPUs connected by NVLink and streamed to the client through WebSocket. The authors also state that chunk size, number of referenced chunks, and memory capacity were chosen as a practical balance between context richness and real-time speed.
7. Data and Task Construction
The dataset is described as a large-scale audio-visual corpus of approximately 3 million high-quality clips after filtering. It combines three sources: speech-driven talking-head datasets such as HDTF, VFHQ, VoxCeleb2, CelebV-Text, and AVSpeech; movie and TV data from OpenHumanVid for complex scenes and long-range dynamics; and a proprietary conversational dataset containing long-duration speech segments with rich body motion and head-shoulder dynamics.
The appendix provides the filtering and annotation pipeline: videos are filtered by aesthetic score, shot boundary detection, face detection, and lip-sync verification. Gemini is used during captioning to detect action-related events, assign action prompts at event beginnings, and assign stable prompts at the end of each event. In other words, the training data is not just video/audio pairs; it is converted into temporally aligned prompt sequences that supervise the action-stable switching behavior of the RRM.
8. Evaluation Protocol and Metrics
The paper evaluates both video quality and streaming consistency. Quality is measured with IQA (Q-align), ASE, FID, and FVD. Consistency and control are measured with SynC and SynD for audio-visual synchronization, OBJ for object-level temporal consistency, ID for identity preservation, and TV for text-video alignment. In addition, FPS is reported to capture real-time performance.
The test set used for quantitative comparison contains 500 videos and covers both short and long interactive scenarios, including designated action switches.
9. Main Quantitative Results
The paper compares InteractiveAvatar against StableAvatar, OmniAvatar, HYAvatar, Hallo3, EchoMimicV3, WanS2V, and LiveAvatar. The main takeaway is that InteractiveAvatar does not claim the very best perceptual quality on every metric, but it does deliver the strongest combination of long-horizon consistency, intent alignment, and runtime speed among the compared systems.
| Model | IQA ↑ | ASE ↑ | FID ↓ | FVD ↓ | SynC ↑ | SynD ↓ | OBJ ↑ | ID ↑ | TV ↑ | FPS ↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| StableAvatar | 3.91 | 3.82 | 79.7 | 654.1 | 3.57 | 10.27 | 79.5 | 4.41 | 25.34 | 0.69 |
| OmniAvatar | 3.77 | 3.87 | 94.1 | 831.9 | 4.94 | 7.87 | 82.8 | 4.38 | 24.57 | 0.17 |
| HYAvatar | 3.81 | 3.93 | 76.5 | 632.6 | 4.78 | 8.11 | 78.9 | 4.46 | 25.61 | 0.09 |
| Hallo3 | 3.57 | 3.29 | 112.5 | 1127.6 | 4.21 | 9.74 | 75.1 | 4.31 | 24.92 | 0.28 |
| EchoMimicV3 | 3.96 | 3.89 | 85.2 | 773.9 | 3.89 | 10.09 | 80.3 | 4.45 | 25.56 | 0.81 |
| WanS2V | 3.76 | 3.68 | 88.4 | 793.5 | 4.54 | 8.95 | 82.6 | 4.49 | 25.14 | 0.26 |
| LiveAvatar | 3.94 | 3.91 | 83.9 | 672.7 | 4.91 | 8.17 | 76.9 | 4.53 | 25.78 | 21.94 |
| Ours | 3.87 | 3.89 | 80.2 | 701.4 | 4.86 | 7.91 | 85.2 | 4.51 | 25.93 | 26.68 |
The reported pattern is important: InteractiveAvatar is competitive on perceptual quality while excelling in the consistency and control metrics that matter most for streaming interaction. It achieves the best OBJ and TV scores, a very strong FPS, and competitive synchronization and identity preservation. The authors explicitly note that the system’s visual quality is reasonable, but its main advantage is that it maintains coherent, instruction-following behavior over long sequences.

10. Ablation Studies
The ablation table isolates the contributions of LSVM, RRM, and DMD. The overall message is that each component affects a different bottleneck: LSVM mainly controls long-range appearance stability, RRM governs action compliance and prompt responsiveness, and DMD is what makes the whole system fast enough for real-time use.
| Method | OBJ ↑ | ID ↑ | TV ↑ | FPS ↑ |
|---|---|---|---|---|
| w/o LongMem | 82.6 | 4.43 | 25.91 | 28.92 |
| w/o DKFS | 83.1 | 4.45 | 25.85 | 26.83 |
| w/o LSVM | 78.4 | 4.38 | 25.87 | 30.04 |
| w/o StateCycling | 84.1 | 4.46 | 25.42 | 26.68 |
| w/o CacheSwitching | 84.5 | 4.47 | 25.76 | 26.75 |
| w/o RRM | 83.8 | 4.46 | 24.89 | 26.75 |
| w/o DMD | - | - | - | 1.27 |
| Ours | 85.2 | 4.51 | 25.93 | 26.68 |
The LSVM ablations show that removing long-term memory hurts object and identity consistency, while replacing DKFS with random sampling degrades the preservation of salient objects such as a watch. Removing LSVM entirely gives the fastest speed among the tested variants, but at a clear cost in consistency.
For RRM, removing State-Cycling makes the model repeat a single action, disabling Cache-Switching slows the response to prompt changes, and removing RRM altogether leaves the avatar with only verbal responses and no explicit action understanding. The DMD ablation is the strongest evidence that distillation is not a minor efficiency tweak: without it, reported speed falls from 26.68 FPS to 1.27 FPS.

11. Additional Qualitative Evidence
The appendix supplies more examples of user-intent understanding and avatar interaction. These examples reinforce the paper’s claim that the RRM can transform a conversational prompt into a temporally coherent sequence of state changes, rather than just a synced talking head animation.


12. What the Paper Claims as Contributions
- A real-time streaming avatar generation framework that can operate over arbitrarily long durations.
- LSVM, which compresses historical visual information into compact tokens and keeps both short-range coherence and long-term identity/scene consistency.
- RRM, which couples LLM-based reasoning with state cycling and cache switching to support intent-aware actions and lower-latency prompt updates.
- A four-stage training recipe that combines audio-driven initialization, memory training, student initialization, and self-forcing DMD distillation.
13. Practical Takeaways and Limitations Reflected by the Results
The paper’s results suggest a clear engineering trade-off: stronger streaming consistency and intent-awareness come from adding memory, reasoning, and distillation machinery, but each of those components also introduces design complexity. The authors do not provide a separate limitations section, so the safest limitations to infer are the ones directly visible in the reported experiments.
- The model is not best-in-class on every perceptual quality metric; several baselines exceed it on IQA, ASE, FID, or FVD.
- Real-time performance depends heavily on DMD distillation and caching; without those, speed is much worse.
- The interaction quality depends on prompt/state planning quality from the LLM, since the avatar’s behavior is mediated through action and stable prompts.
- The memory mechanism is tuned around a fixed chunking and a 5-second short-term window, so its behavior is tied to the chosen streaming granularity.
In short, InteractiveAvatar is presented as a system paper: the key contribution is not a single new generative backbone, but a carefully engineered combination of streaming diffusion, compact memory, and language-mediated state control that makes long-duration interactive avatars feasible in real time.