MotionMAR
MotionMAR: Multi-scale Auto-Regressive Human Motion Reconstruction from Sparse Observations
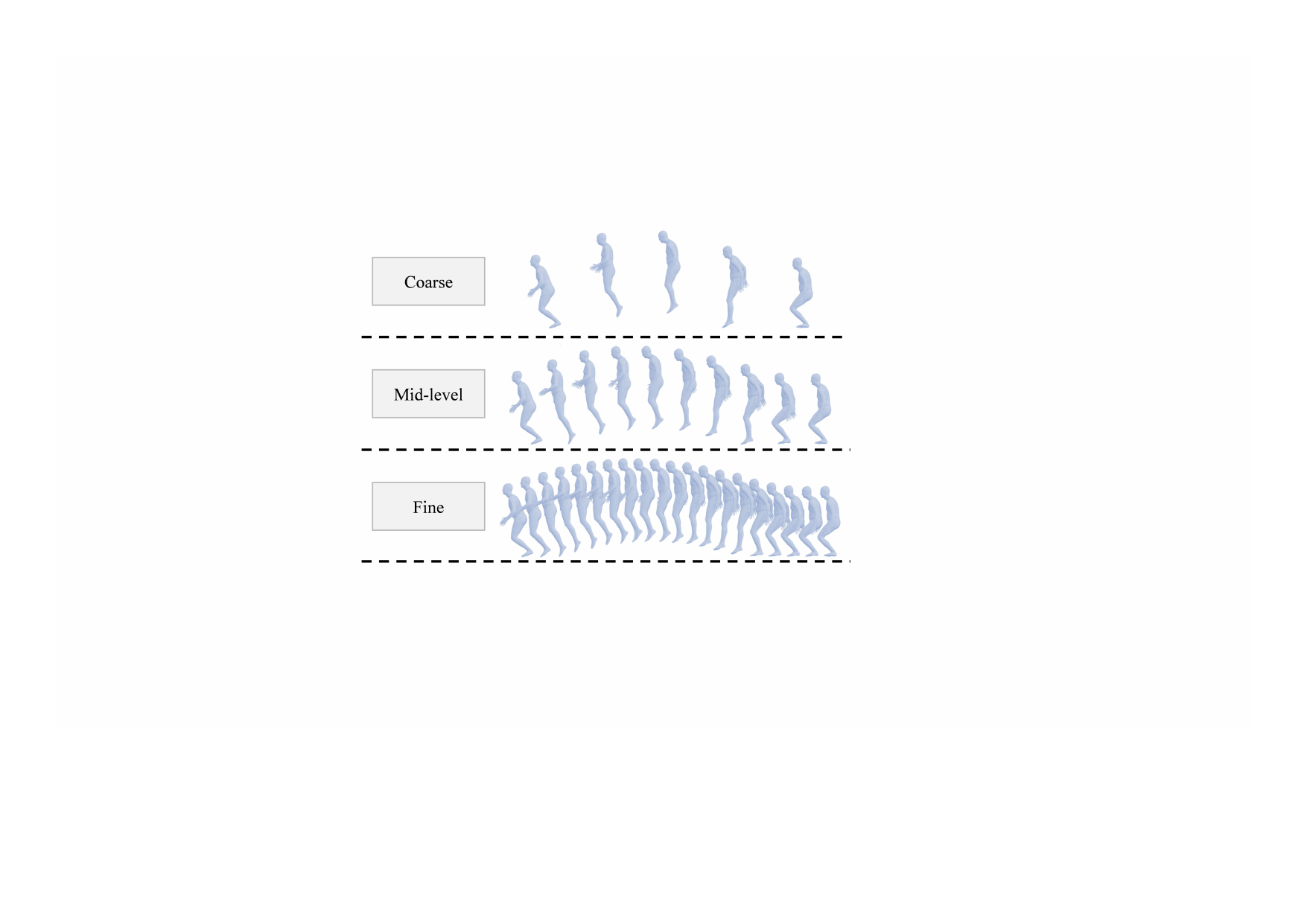
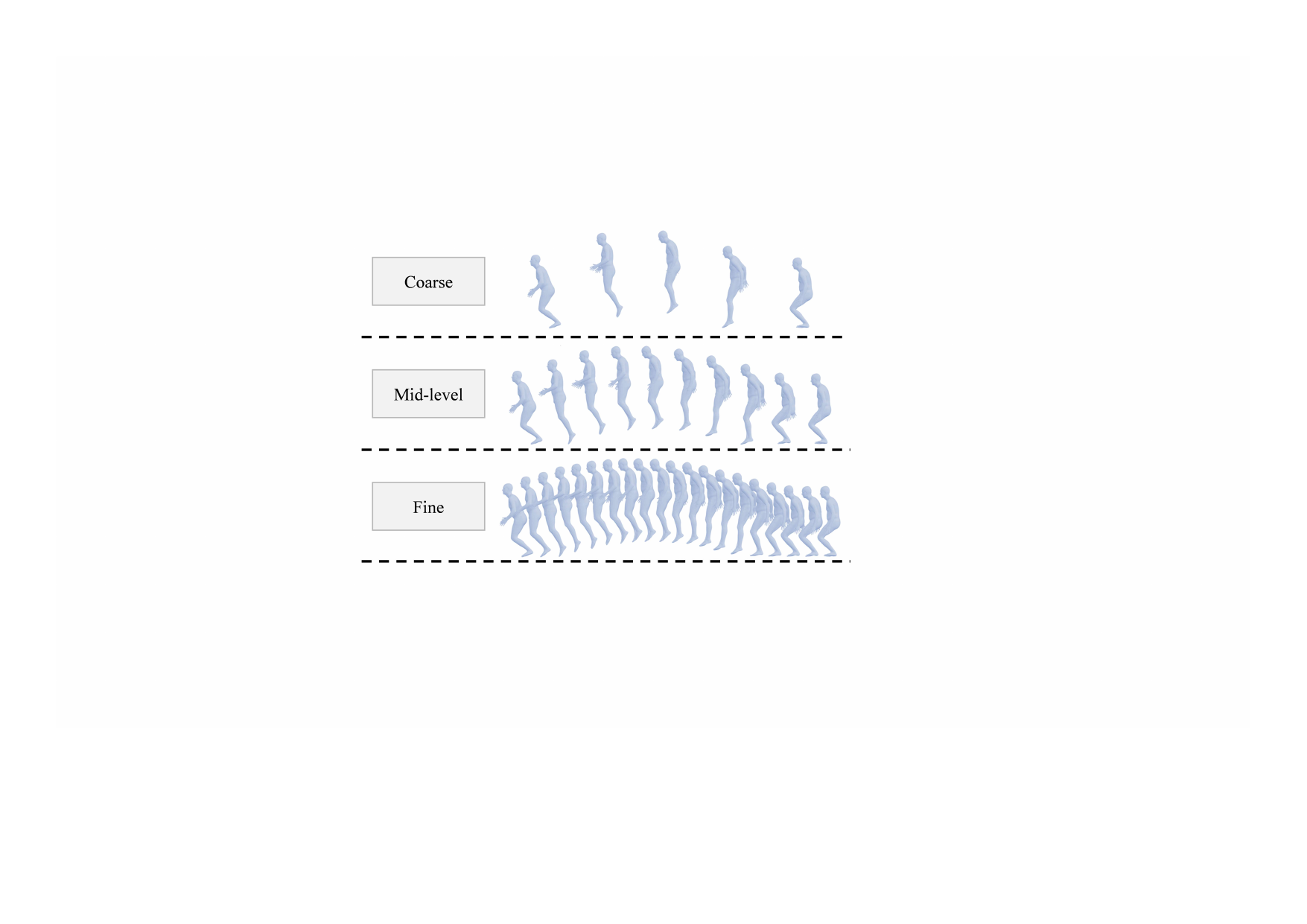
MotionMAR reconstructs full-body human motion from sparse VR sensor data using a multi-scale autoregressive framework, capturing global trajectories to fine details. Its coarse-to-fine tokenization and scale-aware control provide accurate, jitter-free human motion respecting temporal hierarchy.
Links
Paper & demos
Abstract
Human motion follows a temporal hierarchical structure, transitioning from low-frequency global trajectories to high-frequency details. Inspired by the success of multi-level autoregressive models in computer vision, we propose MotionMAR, a coarse-to-fine framework for motion reconstruction from sparse observations. It first estimates the global trajectory of human motion and then gradually refines the temporal details. This architecture consists of four integrated components. The Temporal Multi-scale Tokenization (TMT) VQ-VAE encodes the data at multiple temporal resolutions, separating semantic motion from minor jitters. The Motion Autoregressive Network (MAN) operates in this latent space, predicting motion across scales. It first establishes the global structure through coarse indices and then generates finer indices to recover specific details. Meanwhile, the Scale-Aware Control (SAC) module integrates sparse tracking data to ensure the generated output aligns with actual observations. The Motion Refinement Network (MRN) subsequently smooths consecutive poses and eliminates quantization artifacts. Experiments show that MotionMAR achieves state-of-the-art accuracy on the AMASS dataset, providing a reliable and structure-aware approach for motion reconstruction. The source code is publicly available at http://www.lidarhumanmotion.net/motionmar/.
Introduction
MotionMAR addresses human motion reconstruction from sparse observations, where the input is limited to head, left hand, and right hand 6-DoF tracking from consumer VR/AR devices. The core challenge is that full-body motion is highly ambiguous under such sparse control signals: many different lower-body and torso configurations can be consistent with the same head/hand trajectories. The paper argues that a strong reconstruction system should respect the temporal hierarchy of motion, where broad, low-frequency trajectories determine the overall intent and higher-frequency details fill in local kinematic nuance.
Existing regression, diffusion, and single-scale autoregressive methods often treat motion as a flat sequence of frames or tokens. The authors argue that this misses the natural coarse-to-fine structure of motion and can lead to jitter, floating artifacts, and weak long-horizon coherence. MotionMAR reframes reconstruction as multi-scale autoregressive generation over time, borrowing the next-scale idea from visual autoregressive modeling and adapting it to temporal motion rather than 2D image patches.
The paper’s main claimed contributions are: (1) a temporal coarse-to-fine autoregressive framework for sparse human motion reconstruction; (2) a Temporal Multi-scale Tokenization VQ-VAE that separates semantic motion from small jitters; (3) a Scale-aware Control module that aligns sparse tracker inputs to each temporal scale; and (4) a Motion Refinement Network that smooths decoded poses and reduces quantization artifacts. The reported experiments show state-of-the-art performance on AMASS and competitive results on the GORP motion-controller subset.
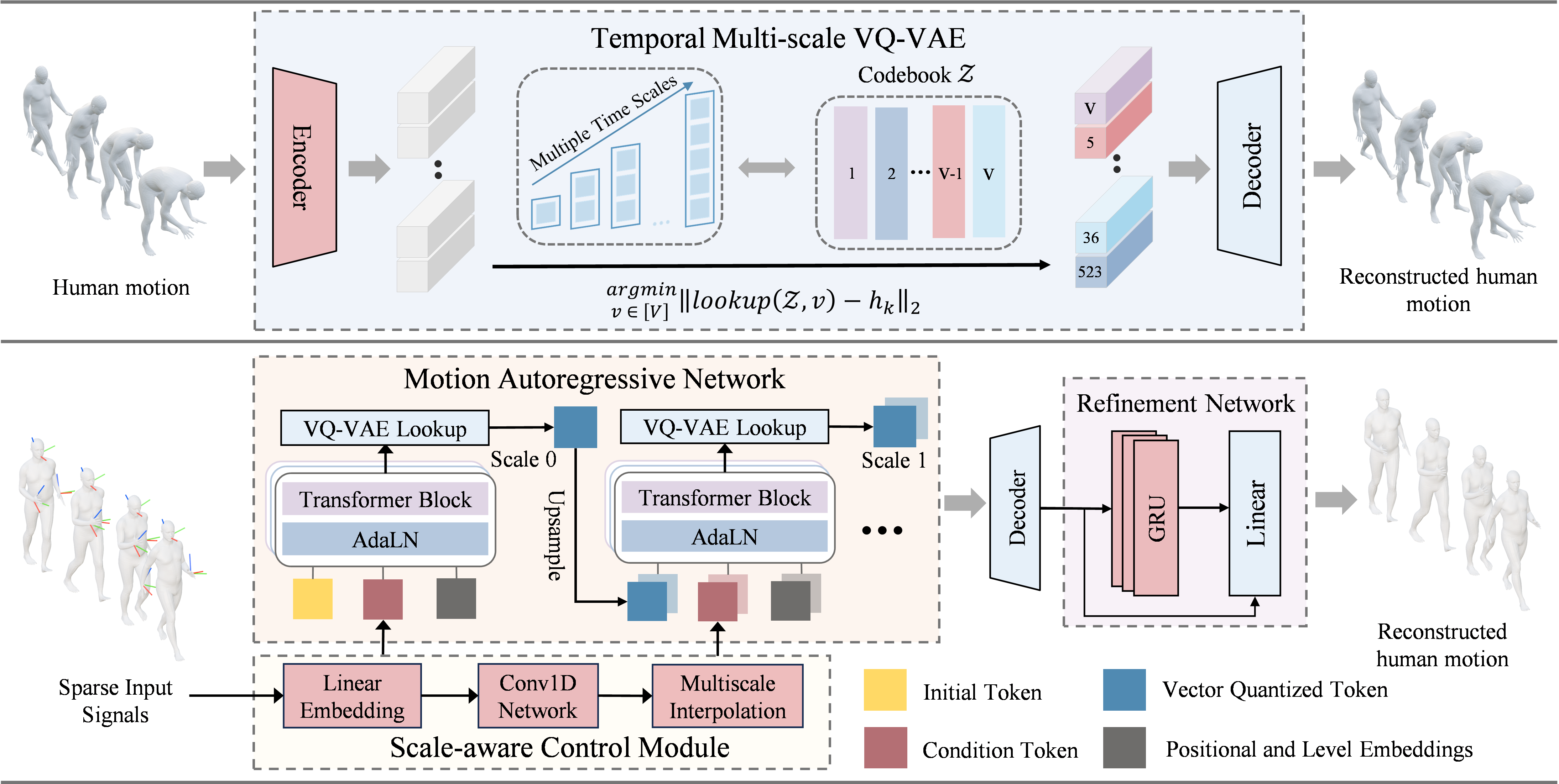
Problem setup and representation
The input is a sparse observation sequence $X_{raw}(t) = (X_h(t), X_l(t), X_r(t))$, corresponding to head, left hand, and right hand trackers. Each tracker is expanded into an 18-dimensional feature vector that includes 6-DoF pose plus linear and angular velocities, yielding an augmented observation matrix $X \in \mathbb{R}^{T \times 3 \times 18}$. The target output is full-body motion represented with the continuous 6D rotation parameterization over 22 joints: $\theta \in \mathbb{R}^{T \times 22 \times 6}$.
The sequence length used throughout the implementation is $T=20$. The paper emphasizes that the 6D representation is preferred over Euler angles or quaternions because it is continuous and easier to optimize for neural reconstruction.
Method
MotionMAR is built around a coarse-to-fine temporal pyramid. The system first infers a broad global trajectory and then progressively fills in mid-level dynamics and high-frequency details. The generation process is not performed in one flat pass; instead, each scale is predicted in turn, with coarse tokens guiding finer tokens.
Temporal Multi-scale VQ-VAE
The first component is a Transformer-based VQ-VAE that converts continuous motion into a discrete multi-scale latent hierarchy. Rather than quantizing motion at a single temporal resolution, the model uses $K=3$ temporal scales with resolutions $t_k \in \{T/4, T/2, T\}$; in the implementation section these are set to $5$, $10$, and $20$ frames. A shared codebook of size $V=1024$ is used across scales. The latent at each scale is obtained by residual quantization: the model downsamples the current residual, matches it to the nearest codebook entry, upsamples the selected embedding back to full length, smooths it with a 1D residual convolution block, and subtracts it from the residual before moving to the next finer scale.
For scale $k$, the discrete assignment is computed by nearest-neighbor lookup in the codebook, using cosine-style matching after $L_2$ normalization. The quantized index $q_k$ is then mapped to an embedding $z_k$, and the collection of multi-scale tokens forms a temporal token pyramid.
The VQ-VAE is trained with a weighted sum of reconstruction and auxiliary losses:
$$\mathcal{L}_{all} = \lambda_1 \mathcal{L}_{rec} + \lambda_2 \mathcal{L}_{vq} + \lambda_3 \mathcal{L}_{loc} + \lambda_4 \mathcal{L}_{h}.$$
Here $\mathcal{L}_{rec}$ is Smooth-$L_1$ pose reconstruction loss on SMPL parameters, $\mathcal{L}_{vq}$ is the vector-quantization commitment/codebook loss summed across scales, $\mathcal{L}_{loc}$ is a Smooth-$L_1$ joint loss in local coordinates, and $\mathcal{L}_{h}$ is a global-coordinate loss for hand poses to better anchor the sparse observations. The implementation table reports loss weights of $1.0$ for reconstruction, $0.25$ for VQ loss, and $5.0$ each for local joint and hand losses.
Motion Autoregressive Network
The generative core is the Motion Autoregressive Network (MAN), a GPT-2-style Transformer that predicts token indices across scales. Conditioned on the sparse observations, MAN samples coarse indices first, then uses those predictions to condition the next finer scale. The paper explicitly frames this as next-scale prediction rather than next-token prediction, since the generation unit is the full temporal scale.
During training, the authors use teacher forcing: the prediction at scale $k$ is conditioned on the ground-truth tokens from all coarser scales, which stabilizes optimization and prevents error accumulation. The MAN objective is a summed cross-entropy over scales:
$$\mathcal{L}_{MAN} = \sum_{k=1}^{K} \mathrm{CE}(\hat{q}_k, q_k^{gt}).$$
The implementation table describes the MAN as a causal Transformer with Adaptive LayerNorm conditioning, cross-scale causal masking, 16 attention heads, hidden width 1024, and 8/16-layer settings across scales. Sparse observation features are fused through both local and global conditioning pathways.
Scale-aware Control Module
The Scale-aware Control module injects sparse tracking into the autoregressive process at the right temporal granularity. Instead of using the same conditioning vector at every scale, the module encodes the flattened sparse signals, extracts continuous temporal features with 1D convolutions, and then linearly interpolates those features to match each temporal resolution $t_k$. This produces a pyramid of aligned control features $\{C_1, C_2, \ldots, C_K\}$.
These aligned features are used in two ways: (1) they are added to the token embeddings at the corresponding scale to provide frame-aligned guidance, and (2) a globally pooled context vector modulates AdaLN parameters throughout the Transformer blocks. The result is that coarse scales remain anchored to the global body trajectory while finer scales still respect the observed controls.
Motion Refinement Network
After MAN predicts discrete indices, the VQ-VAE decoder reconstructs a continuous motion sequence. To reduce the quantization artifacts and temporal jitter introduced by discrete decoding, MotionMAR applies a post-processing Motion Refinement Network (MRN). MRN is a multi-layer bidirectional GRU that predicts a residual correction $\Delta \theta$ over the decoded motion $\hat{\theta}$, and outputs $\hat{\theta}_{final} = \hat{\theta} + \Delta \theta$.
The refinement loss combines a rotation term and a multi-stride velocity term. The rotation loss is computed in axis-angle space using an $L_1$ error wrapped to $[-\pi, \pi]$, and the velocity loss penalizes frame-to-frame and short-horizon differences using strides of 1 and 3 frames:
$$\mathcal{L}_{vel} = \| (\theta_{gt,t} - \theta_{gt,t-1}) - (\hat{\theta}_{final,t} - \hat{\theta}_{final,t-1}) \|_1 + \| (\theta_{gt,t} - \theta_{gt,t-3}) - (\hat{\theta}_{final,t} - \hat{\theta}_{final,t-3}) \|_1.$$
The paper also reports an ablation where the bidirectional GRU is replaced with a causal GRU; this improves FPS but slightly worsens motion quality, supporting the bidirectional design for offline reconstruction quality.
Training and implementation
The paper states that the Temporal Multi-scale VQ-VAE is pretrained and then frozen while training MAN and MRN. The MAN and MRN are optimized in separate phases. MAN is trained with teacher forcing and cross-entropy on discrete token indices extracted from the frozen VQ-VAE. MRN is trained on decoded sequences with geometric and kinematic losses.
The implementation details reported in the appendix are:
- TMT VQ-VAE: 4-layer Transformer encoder/decoder, hidden dimension 512, 4 attention heads, dropout 0.1, 2-layer MLP projection, AdamW with learning rate $10^{-4}$, weight decay $10^{-4}$, batch size 512, trained for 60 epochs.
- MAN: causal Transformer with AdaLNSelfAttn and cross-scale causal masking, hidden dimension 1024, 16 heads, AdamW with learning rate $10^{-4}$, weight decay $10^{-4}$, batch size 512, trained for 500 epochs, condition dropout 0.1, AdaLN-$\gamma$ initialized at $10^{-3}$.
- MRN: 2-layer BiGRU with hidden dimension 512, dropout 0.1, batch size 1, AdamW with learning rate $10^{-4}$, weight decay $10^{-4}$, trained for 200 epochs.
All experiments were run on a single NVIDIA RTX 4090 GPU.
Datasets and evaluation protocol
The main benchmark is AMASS, which the paper describes as a large-scale archive of motion-capture data standardized to SMPL format. Following prior sparse-motion reconstruction protocols, the authors evaluate three settings based on AMASS subsets:
- S1: CMU, BMLrub, and HDM05, randomly split 90%/10%, with head and both hands as inputs.
- S2: The same split as S1, but with an additional root joint tracker, giving a 4-tracker setup.
- S3: A larger mixed dataset consisting of CMU, MPI Limits, TotalCapture, Eyes Japan, KIT, BioMotionLab, BMLmovi, EKUT, ACCAD, MPI Mosh, SFU, and HDM05, split 90%/10%.
The appendix also evaluates on the GORP motion-controller subset, which the authors position as a more practical VR gameplay benchmark with real tracking noise and interaction patterns.
Metrics are inherited from SAGE and cover accuracy, consistency, and smoothness. The paper reports mean per-joint rotation error ($\mathrm{MPJRE}$), mean per-joint position error ($\mathrm{MPJPE}$), mean per-joint velocity error ($\mathrm{MPJVE}$), specialized position errors for the upper body, lower body, root, and hands, and a jitter metric based on acceleration changes. Lower values are better for all metrics.
Quantitative results
Across the main AMASS benchmark, MotionMAR is reported to outperform a wide range of baselines spanning optimization, matching, MLP regression, VAE-based reconstruction, Transformers, diffusion, and autoregressive designs. The main comparison in S1 includes Final IK, LoBSTr, VAE-HMD, AvatarPoser, AvatarJLM, AGRoL, SAGE, MAGE, HiPART, and RPM.
| Method | MPJRE ↓ | MPJPE ↓ | MPJVE ↓ | Hand PE ↓ | Upper PE ↓ | Lower PE ↓ | Root PE ↓ | Jitter ↓ |
|---|---|---|---|---|---|---|---|---|
| Final IK | 16.77 | 18.09 | 59.24 | - | - | - | - | - |
| LoBSTr | 10.69 | 9.02 | 44.97 | - | - | - | - | - |
| VAE-HMD | 4.11 | 6.83 | 37.99 | - | - | - | - | - |
| AvatarPoser | 3.08 | 4.18 | 27.70 | 2.12 | 1.81 | 7.59 | 3.34 | 14.49 |
| AvatarJLM | 2.90 | 3.35 | 20.79 | 1.24 | 1.42 | 6.14 | 2.94 | 8.39 |
| AGRoL (Online) | 2.96 | 4.26 | 79.12 | 1.51 | 1.73 | 7.91 | 3.78 | 84.79 |
| AGRoL (Offline) | 2.66 | 3.71 | 18.59 | 1.31 | 1.55 | 6.84 | 3.36 | 7.26 |
| SAGE | 2.53 | 3.28 | 20.62 | 1.18 | 1.39 | 6.01 | 2.95 | 6.55 |
| MAGE | 2.89 | 3.83 | 64.91 | 1.40 | 1.69 | 8.94 | 3.36 | 53.42 |
| HiPART | 2.75 | 3.71 | 98.19 | 1.74 | 1.93 | 8.54 | 3.16 | 107.1 |
| RPM | 3.25 | 4.08 | 19.29 | 3.61 | 2.17 | 6.83 | 3.47 | 4.20 |
| MotionMAR | 2.39 | 2.82 | 16.23 | 0.83 | 1.22 | 5.13 | 2.58 | 5.17 |
On S1, MotionMAR reports the best or tied-best reconstruction quality on nearly all core metrics, including the lowest MPJRE, MPJPE, MPJVE, hand error, upper-body error, lower-body error, and root error. The only metric where RPM is lower is jitter, though MotionMAR remains close while improving structural reconstruction substantially. The paper highlights that the method is especially strong on hands and lower body, which are typically difficult to infer from sparse upper-body controls.
| Method | MPJRE ↓ | MPJPE ↓ | MPJVE ↓ |
|---|---|---|---|
| Final IK | 12.39 | 9.54 | 36.73 |
| CoolMoves | 4.58 | 5.55 | 65.28 |
| LoBSTr | 8.09 | 5.56 | 30.12 |
| VAE-HMD | 3.12 | 3.51 | 28.23 |
| AvatarPoser | 2.59 | 2.61 | 22.16 |
| AvatarJLM | 2.40 | 2.09 | 17.82 |
| AGRoL | 2.25 | 2.17 | 16.26 |
| SAGE | 2.10 | 1.88 | 14.79 |
| RPM | 2.53 | 2.19 | 17.34 |
| MotionMAR | 1.98 | 1.71 | 13.20 |
| Method | MPJRE ↓ | MPJPE ↓ | MPJVE ↓ | Hand PE ↓ | Upper PE ↓ | Lower PE ↓ | Root PE ↓ | Jitter ↓ |
|---|---|---|---|---|---|---|---|---|
| AGRoL | 2.83 | 3.80 | 17.76 | 1.62 | 1.66 | 6.90 | 3.53 | 10.08 |
| AvatarJLM | 3.14 | 3.39 | 15.75 | 0.69 | 1.48 | 6.13 | 3.04 | 5.33 |
| AvatarPoser | 2.72 | 3.37 | 21.00 | 2.12 | 1.63 | 5.87 | 2.90 | 10.24 |
| SAGE | 2.41 | 2.95 | 16.94 | 1.15 | 1.28 | 5.37 | 2.74 | 5.27 |
| RPM | 3.01 | 3.23 | 15.53 | 2.53 | 2.09 | 5.73 | 2.97 | 3.67 |
| MotionMAR | 2.20 | 2.57 | 14.21 | 0.81 | 1.13 | 4.58 | 2.46 | 4.14 |
The paper also reports an additional evaluation on the GORP motion-controller subset.
| Method | MPJPE ↓ | MPJVE ↓ |
|---|---|---|
| AvatarPoser | 6.49 | 14.72 |
| AGRoL | 6.14 | 39.14 |
| EgoPoser | 7.21 | 15.00 |
| SAGE | 6.49 | 17.84 |
| AvatarJLM | 6.07 | 10.79 |
| HMD-Poser | 6.84 | 15.13 |
| RPM | 6.83 | 10.93 |
| MotionMAR | 5.98 | 10.54 |
According to the paper’s discussion, MotionMAR remains competitive on GORP and preserves an advantage in both position and velocity error, suggesting that the temporal hierarchy is useful beyond AMASS-style data.
Ablations and analysis
The ablation study isolates the three major design choices: Temporal Multi-scale Tokenization (TMT), Scale-aware Control (SAC), and Motion Refinement Network (MRN). The complete model is strongest overall, but each module contributes in a specific way.
| Method | MPJRE ↓ | MPJPE ↓ | MPJVE ↓ | Hand PE ↓ | Upper PE ↓ | Lower PE ↓ | Root PE ↓ | Jitter ↓ |
|---|---|---|---|---|---|---|---|---|
| MotionMAR w/o MRN | 2.47 | 3.04 | 43.9 | 0.84 | 1.32 | 6.02 | 2.70 | 42.85 |
| MotionMAR w/o SAC | 2.59 | 3.30 | 17.30 | 1.21 | 1.41 | 7.47 | 3.22 | 5.93 |
| MotionMAR w/o TMT | 2.75 | 3.41 | 19.20 | 1.09 | 1.55 | 7.93 | 3.01 | 6.27 |
| MotionMAR | 2.39 | 2.82 | 16.23 | 0.83 | 1.22 | 5.13 | 2.58 | 5.17 |
The ablation indicates that MRN has the largest effect on temporal smoothness: removing it increases MPJVE from $16.23$ to $43.9$ and Jitter from $5.17$ to $42.85$. SAC primarily improves the root and hand errors by better aligning the sparse inputs with each generation scale. TMT yields the largest gains in overall reconstruction error, especially MPJPE, upper-body error, and lower-body error, supporting the claim that a temporal hierarchy is important for motion structure.
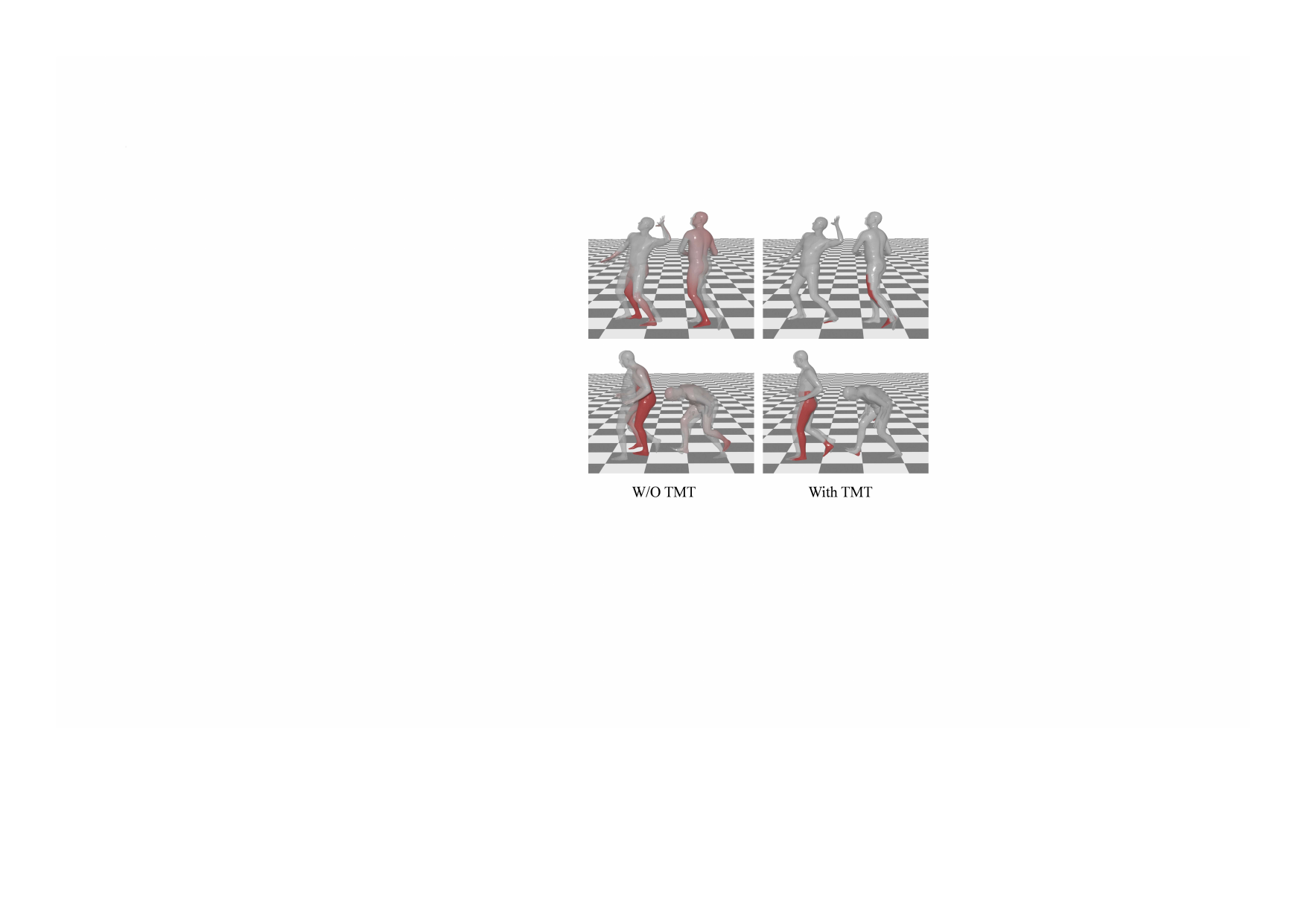
The authors also test whether TMT helps SAGE if inserted into that pipeline. The resulting SAGE(TMT) improves over plain SAGE, but still trails MotionMAR. This supports the paper’s broader claim that TMT is helpful, yet the full architecture matters: the combination of temporal tokenization, scale-aware control, and refinement is stronger than tokenization alone.
| Method | MPJRE ↓ | MPJPE ↓ | MPJVE ↓ | Hand PE ↓ | Upper PE ↓ | Lower PE ↓ | Root PE ↓ | Jitter ↓ |
|---|---|---|---|---|---|---|---|---|
| SAGE | 2.53 | 3.28 | 20.62 | 1.18 | 1.39 | 6.01 | 2.95 | 6.55 |
| SAGE (TMT) | 2.39 | 2.83 | 16.36 | 0.84 | 1.22 | 5.14 | 2.58 | 5.36 |
| MotionMAR | 2.39 | 2.82 | 16.23 | 0.83 | 1.22 | 5.13 | 2.58 | 5.17 |
The appendix further ablates a geodesic $SO(3)$ rotation loss and finds that the paper’s axis-angle $L_1$ variant performs slightly better, so the authors keep the simpler loss. A causal GRU variant of MRN is faster, but loses some reconstruction quality and smoothness. Directly sampling raw sparse signals at multiple scales also underperforms latent interpolation, confirming the design choice used in SAC.
| Method | Params | FLOPs | FPS |
|---|---|---|---|
| AvatarJLM | 63.81M | 0.52G | 12.91 |
| AvatarPoser | 4.12M | 0.33G | 12.40 |
| AGRoL | 7.48M | 1.00G | 54.64 |
| SAGE | 137.35M | 4.11G | 13.81 |
| RPM | 9.89M | 0.09G | 233 |
| MotionMAR | 42.36M | 1.47G | 61.76 |
In terms of efficiency, MotionMAR is positioned as a practical middle ground: it is much lighter than SAGE, far more accurate than RPM, and still fast enough for real-time VR/AR deployment. The paper reports 61.76 FPS, which meets the typical 30- or 60-FPS real-time threshold.
| Method | MPJRE ↓ | MPJPE ↓ | MPJVE ↓ | Hand PE ↓ | Upper PE ↓ | Lower PE ↓ | Root PE ↓ | Jitter ↓ | FPS ↑ |
|---|---|---|---|---|---|---|---|---|---|
| MotionMAR (Two Scales) | 2.47 | 2.93 | 17.07 | 0.87 | 1.26 | 5.33 | 2.70 | 5.51 | 91.27 |
| MotionMAR | 2.39 | 2.82 | 16.23 | 0.83 | 1.22 | 5.13 | 2.58 | 5.17 | 61.76 |
| MotionMAR (Four Scales) | 2.36 | 2.79 | 16.01 | 0.81 | 1.19 | 5.08 | 2.53 | 5.09 | 50.88 |
The temporal-scale ablation suggests that four scales give slightly better accuracy, but three scales are chosen as the best trade-off between quality and throughput. The two-scale model is fastest, but loses detail. This supports the paper’s design choice of a three-level coarse-to-fine hierarchy.
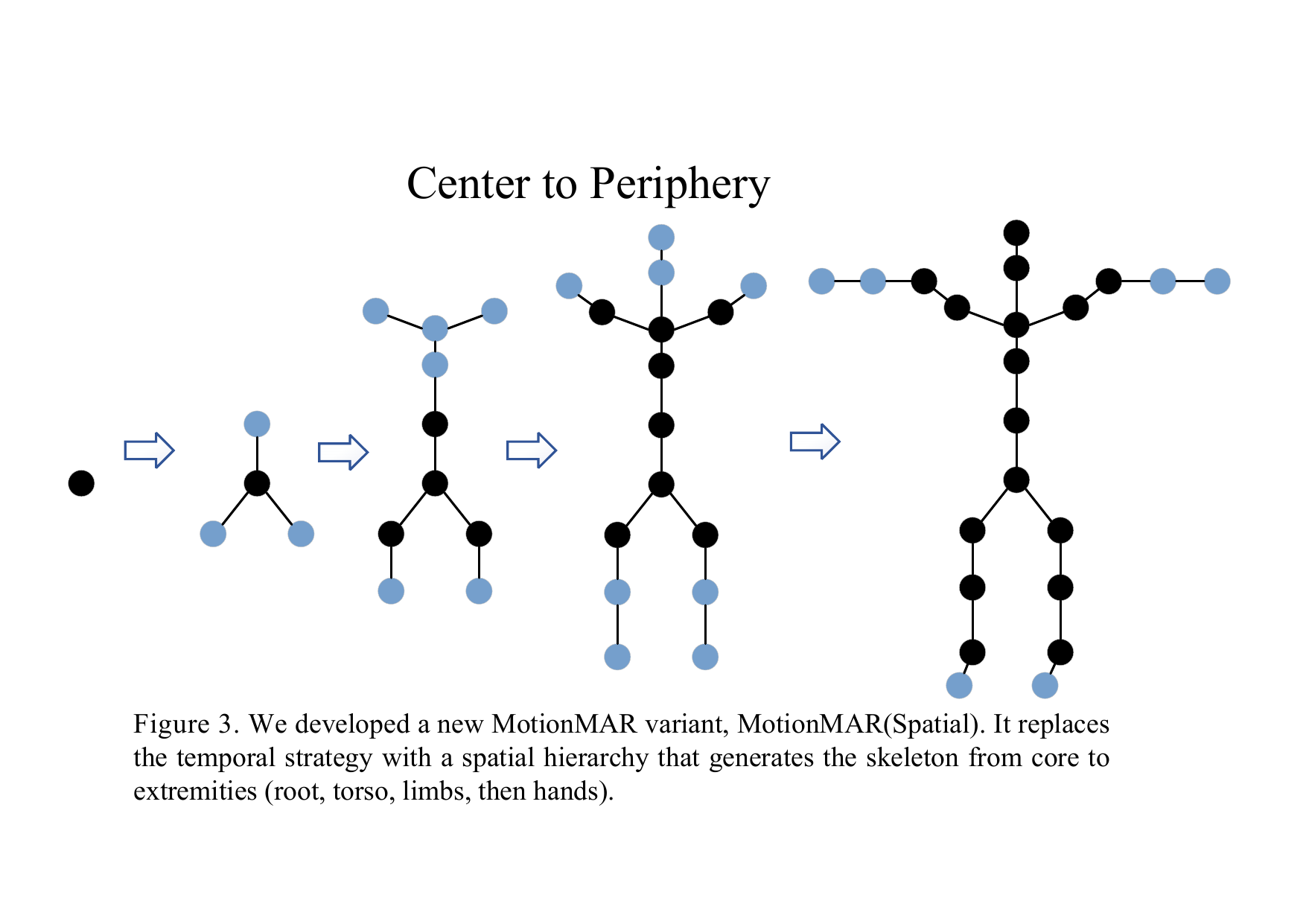
The appendix also evaluates a spatial multi-scale variant, MotionMAR(Spatial), that generates the skeleton from root to torso to limbs to hands. The paper finds that spatial hierarchy alone is inferior to the proposed temporal hierarchy, especially in jitter and global coherence, and it notes that fully decoupling both temporal and spatial structure would cause a prohibitive computational increase. The authors estimate that a naive joint spatio-temporal design would scale like $O(T^2 J^2 d)$ and be roughly $369\times$ more expensive at the finest scale for $J=22$ joints.
| Method | MPJRE ↓ | MPJPE ↓ | MPJVE ↓ | Hand PE ↓ | Upper PE ↓ | Lower PE ↓ | Root PE ↓ | Jitter ↓ |
|---|---|---|---|---|---|---|---|---|
| HiPART | 2.75 | 3.71 | 98.19 | 1.74 | 1.93 | 8.54 | 3.16 | 107.7 |
| MotionMAR (Spatial) | 2.39 | 3.02 | 19.56 | 1.01 | 1.58 | 6.91 | 2.83 | 23.98 |
| MotionMAR | 2.39 | 2.82 | 16.23 | 0.83 | 1.22 | 5.13 | 2.58 | 5.17 |
Finally, the paper argues that the discrete token formulation is important for multimodality. It notes that the autoregressive decoder models a probability distribution over tokens rather than a single point estimate, which allows different plausible lower-body reconstructions under the same sparse upper-body observation. A continuous variant that replaces VQ-VAE with a continuous autoencoder performs substantially worse, especially on velocity and jitter.
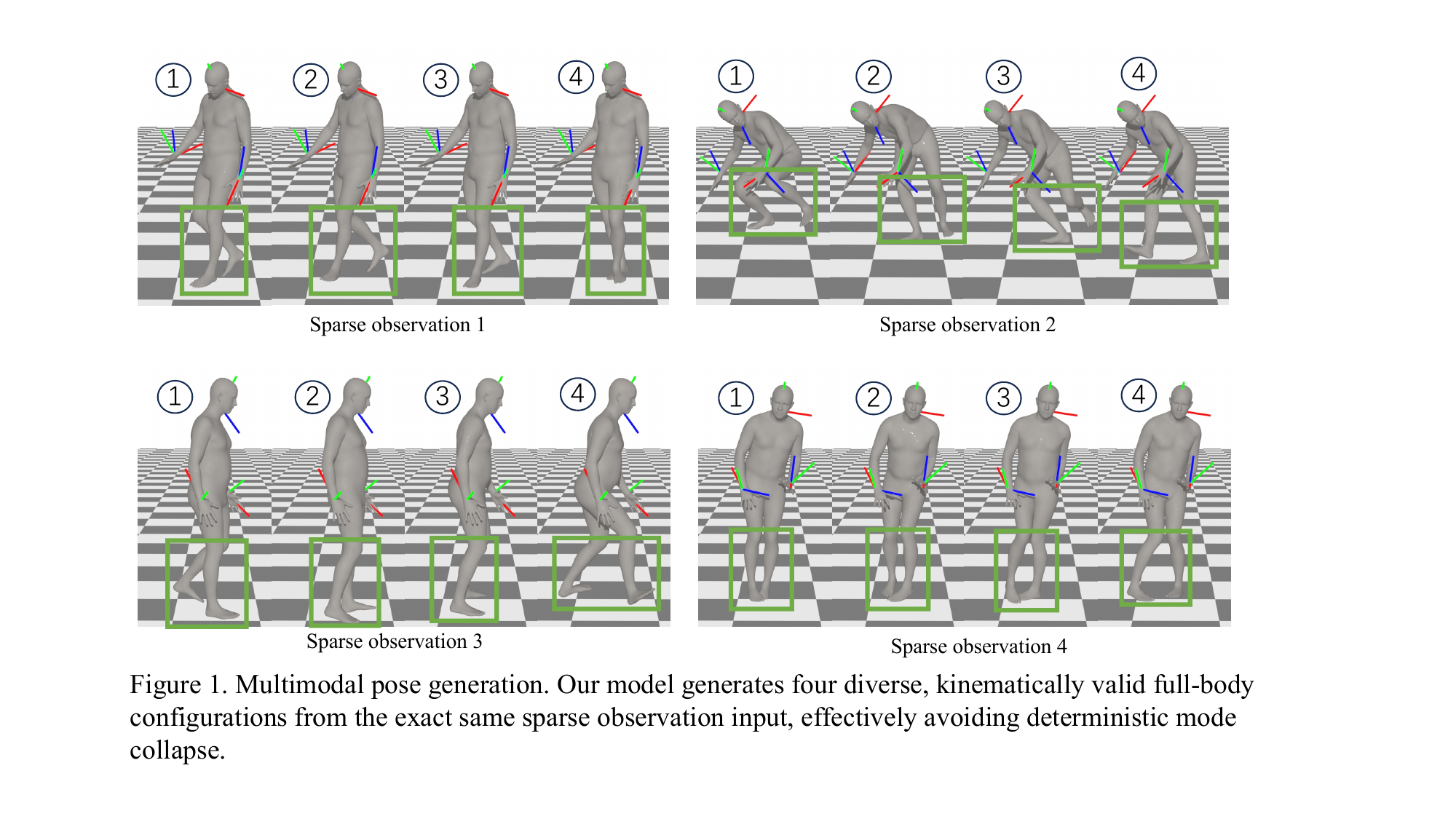
Qualitative results
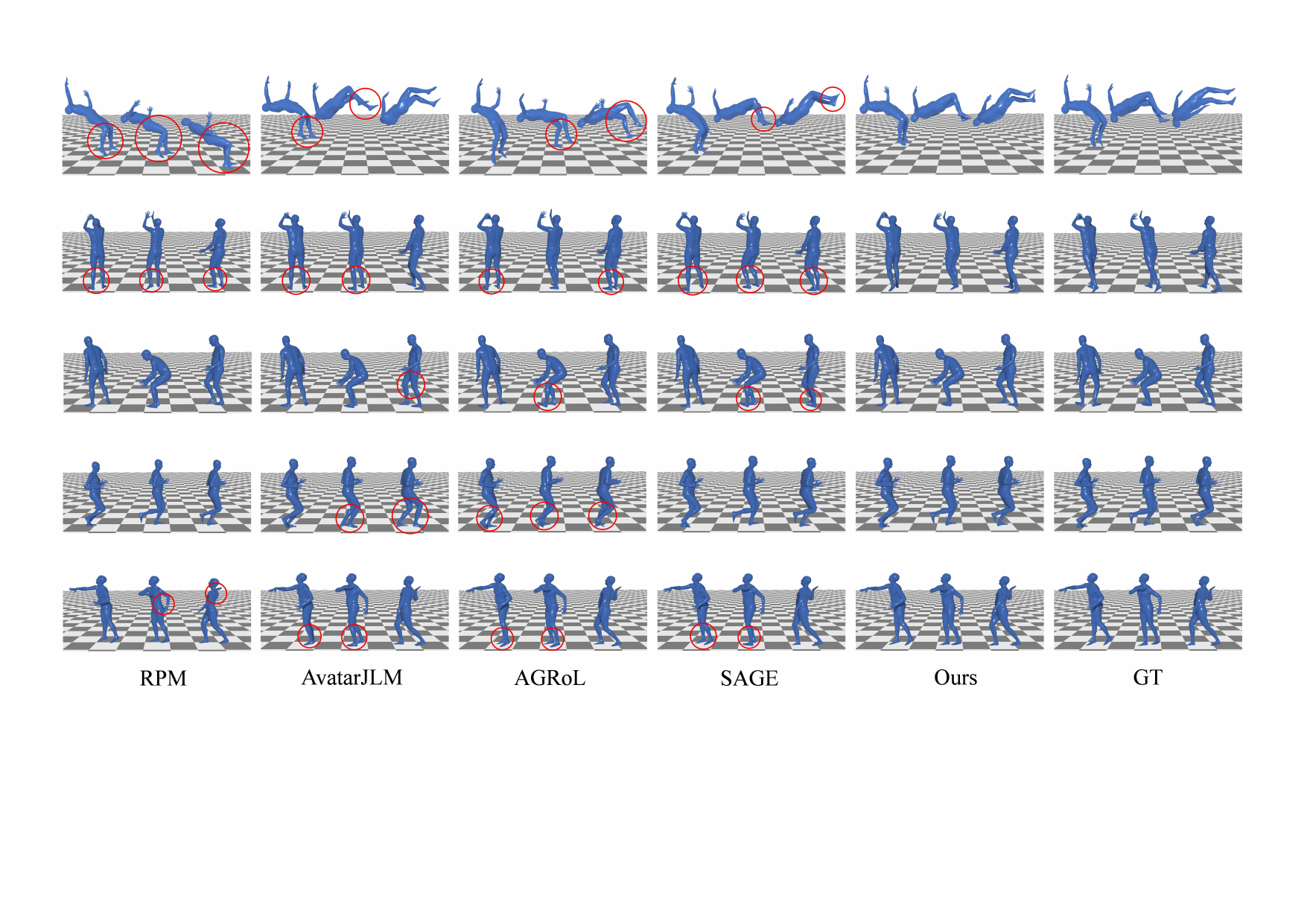
The paper includes qualitative comparisons on S1 and real captured data. The S1 visualization shows MotionMAR producing cleaner limb trajectories and less drift than prior methods, while the real-data evaluation indicates better alignment to the ground truth in the hand and leg regions. These visual results match the numerical findings: MotionMAR is especially effective at maintaining structure under sparse control, and the refinement stage helps suppress obvious artifacts.

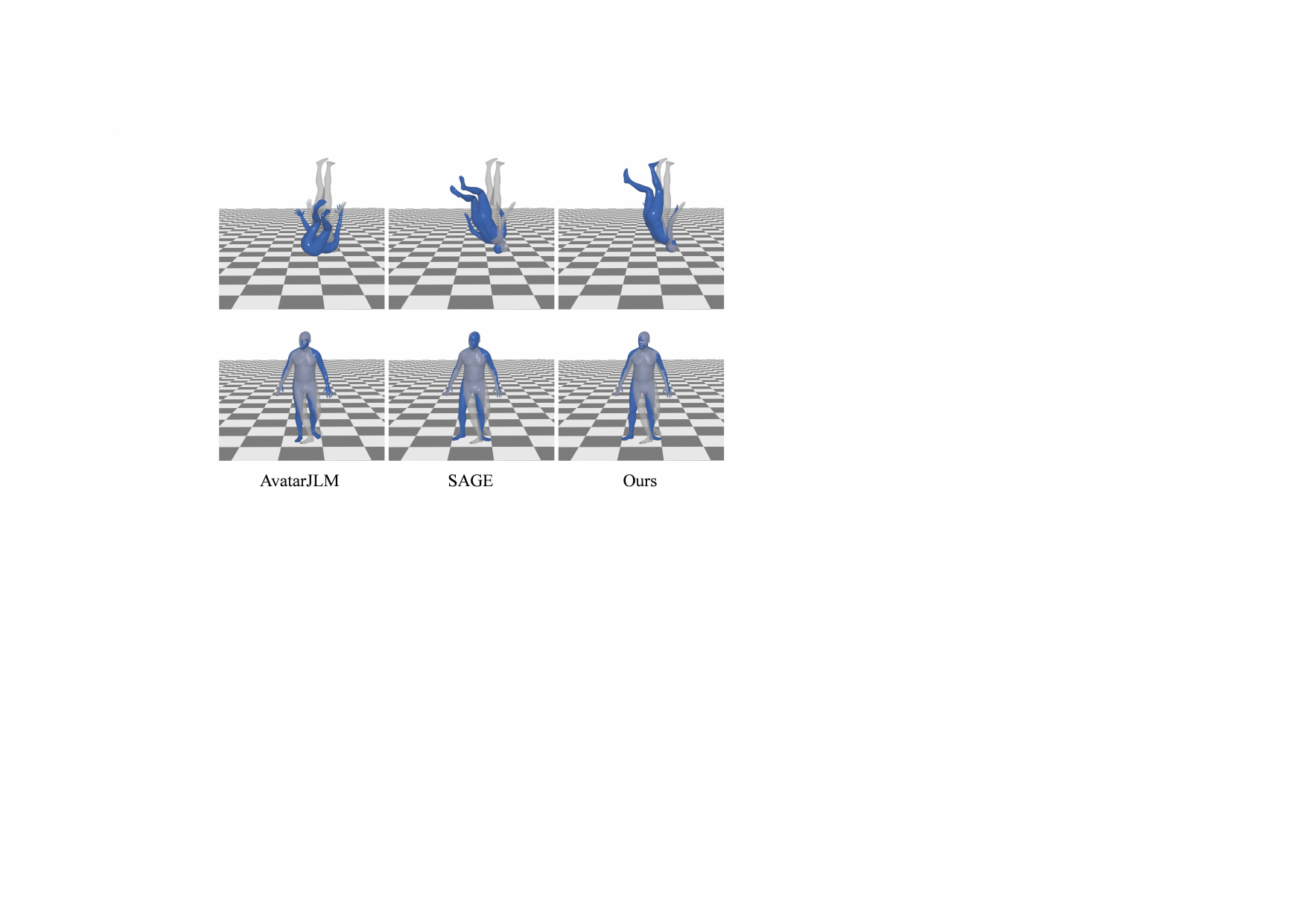
Limitations
The appendix is explicit about failure cases. MotionMAR, like the baselines, struggles in two particularly hard situations: unconventional movements such as a backflip with the head downward and legs upward, and minimal hand motion cases where arm-crossing configurations become ambiguous. These are settings where sparse controls provide too little evidence to disambiguate the full pose.
The authors also stress that the Motion Refinement Network should not be interpreted as a physical simulator. It improves plausibility through residual smoothing and geometric/kinematic losses, but those constraints are still data-driven regularizers rather than explicit physics. As a result, rare motions and highly ambiguous poses remain challenging, and stronger physics-based priors are identified as a direction for future work.
On the benchmark side, the paper centers AMASS and adds GORP, but notes that other datasets such as EgoBody and GIMO would be valuable for future investigation. The reason given is not a methodological limitation but rather dataset access and evaluation-protocol constraints.
Conclusion
MotionMAR’s central idea is that human motion reconstruction should be generated in temporal scales, not as a single flat sequence. By combining a temporal multi-scale VQ-VAE, scale-aligned sparse control, autoregressive next-scale generation, and a bidirectional refinement stage, the method explicitly targets the hierarchy of human motion from global trajectory to local detail. The reported results show strong gains in reconstruction error, temporal consistency, and runtime efficiency, making the approach well aligned with real-time VR/AR motion reconstruction scenarios.