CAAD
CAAD: Contrastive Audio-Aware Distillation for Efficient Speech Language Models
CAAD distills contrastive audio-aware decoding into a student model to improve speech language understanding with efficiency and stronger acoustic grounding. It uses synchronized teacher forcing and metadata-based pseudo-ground truths to distill contrastive reasoning without inference-time overhead.
Links
Paper & demos
Code & resources
Abstract
Speech Language Models achieve reasoning capabilities, but are often hindered by massive parameter counts and a tendency to prioritize linguistic priors over acoustic features. While contrastive decoding enhances grounding by contrasting audio-aware and text-only logits, it increases inference latency. We propose Contrastive Audio-Aware Distillation (CAAD), a framework that internalizes the teacher's contrastive reasoning into the student model's weights. To overcome the high computational training overhead in the dual-path token-by-token contrastive distillation process, we introduce a synchronized teacher-forcing strategy. Anchored by unified Pseudo-Ground Truths, this mechanism enables simultaneous full-sequence generation of the teacher's contrastive distributions, allowing student to distill the audio-aware signal efficiently. Overall, CAAD yields a ~8% relative gain over standard knowledge distillation on Dynamic-SUPERB and successfully reduces linguistic bias in MCR-BENCH.
Introduction
This paper addresses a practical tension in modern Speech Language Models (SLMs): large multimodal models can perform instruction following and cross-modal reasoning, but they are expensive to run and often over-rely on linguistic priors instead of the acoustic signal. The authors focus on the case where a model should answer from speech, yet standard decoding or standard knowledge distillation can make the student imitate the teacher's text bias rather than the desired audio grounding. The motivation is especially clear in settings where audio and text conflict, or where the answer depends on paralinguistic cues rather than transcript content.
The key idea is to distill the reasoning effect of contrastive decoding into the student weights. Instead of paying the inference-time cost of a dual-path method that requires both an audio-aware and a text-only forward pass at every token, the paper proposes Contrastive Audio-Aware Distillation (CAAD), a training framework that teaches a single-path student to approximate the same contrastive shift. The reported goals are twofold: improve efficiency at test time and reduce linguistic bias in favor of stronger acoustic grounding.
The paper evaluates the method in the DeSTA2 speech instruction-following setup on Dynamic-SUPERB and MCR-BENCH. The main empirical claims are that CAAD gives about an 8% relative gain over standard knowledge distillation on Dynamic-SUPERB and substantially lowers the bias score on MCR-BENCH. The results also show a tradeoff between maximizing average benchmark score and aggressively suppressing lexical bias, controlled by the contrastive weight $\alpha$.
Problem Setting and Core Motivation
The paper frames modality bias as the central challenge. SLMs have strong language priors, and under cross-modal conflict those priors can dominate the acoustic evidence. In the authors' view, standard KD is problematic because it transfers whatever distribution the teacher produces at the end of decoding, including the teacher's own tendency to ignore audio. By contrast, contrastive decoding can suppress those priors by contrasting two paths: an audio-aware path that conditions on both speech and text, and a text-only path that removes the audio input. This improves grounding but doubles the computational cost at inference time.
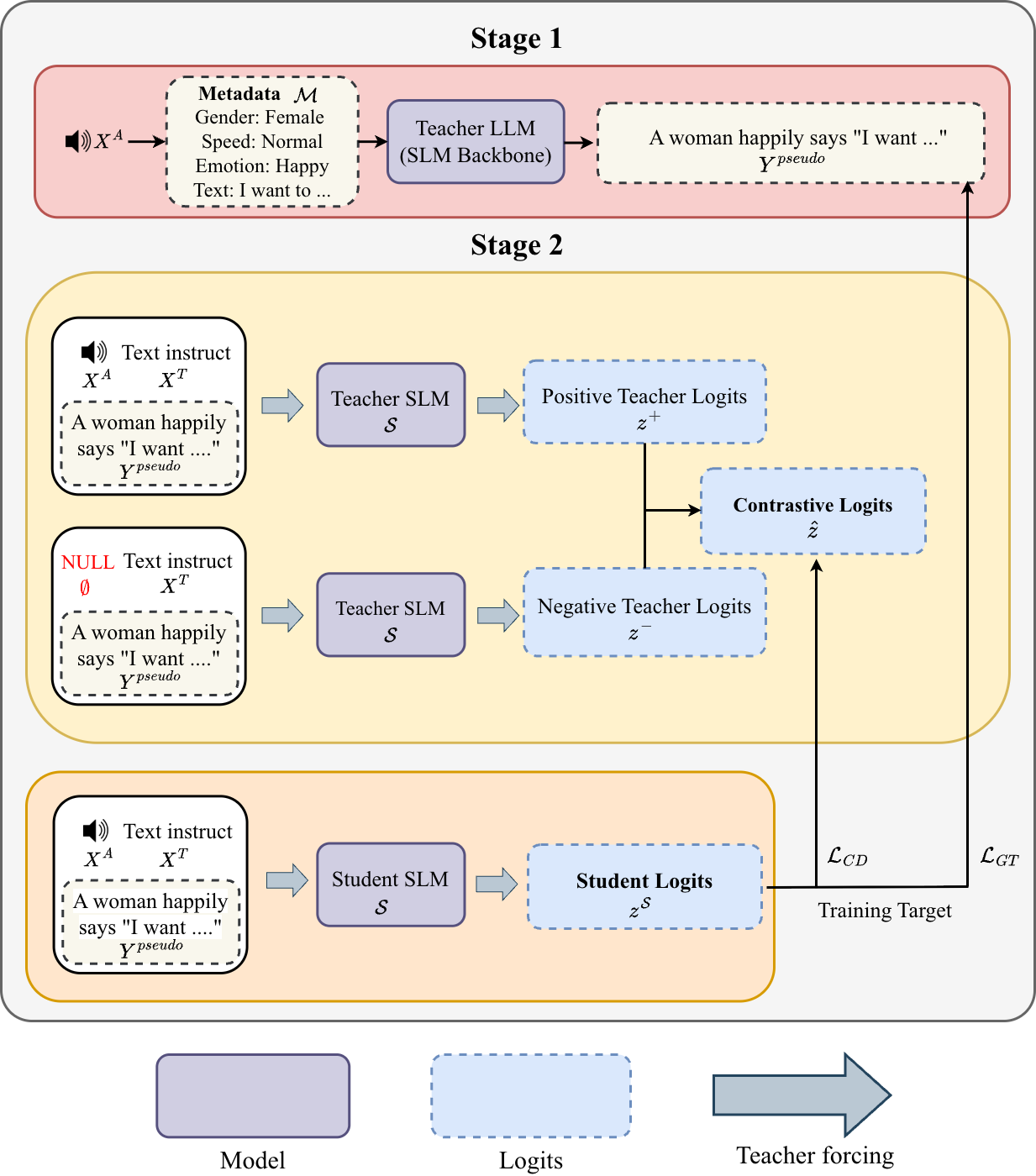
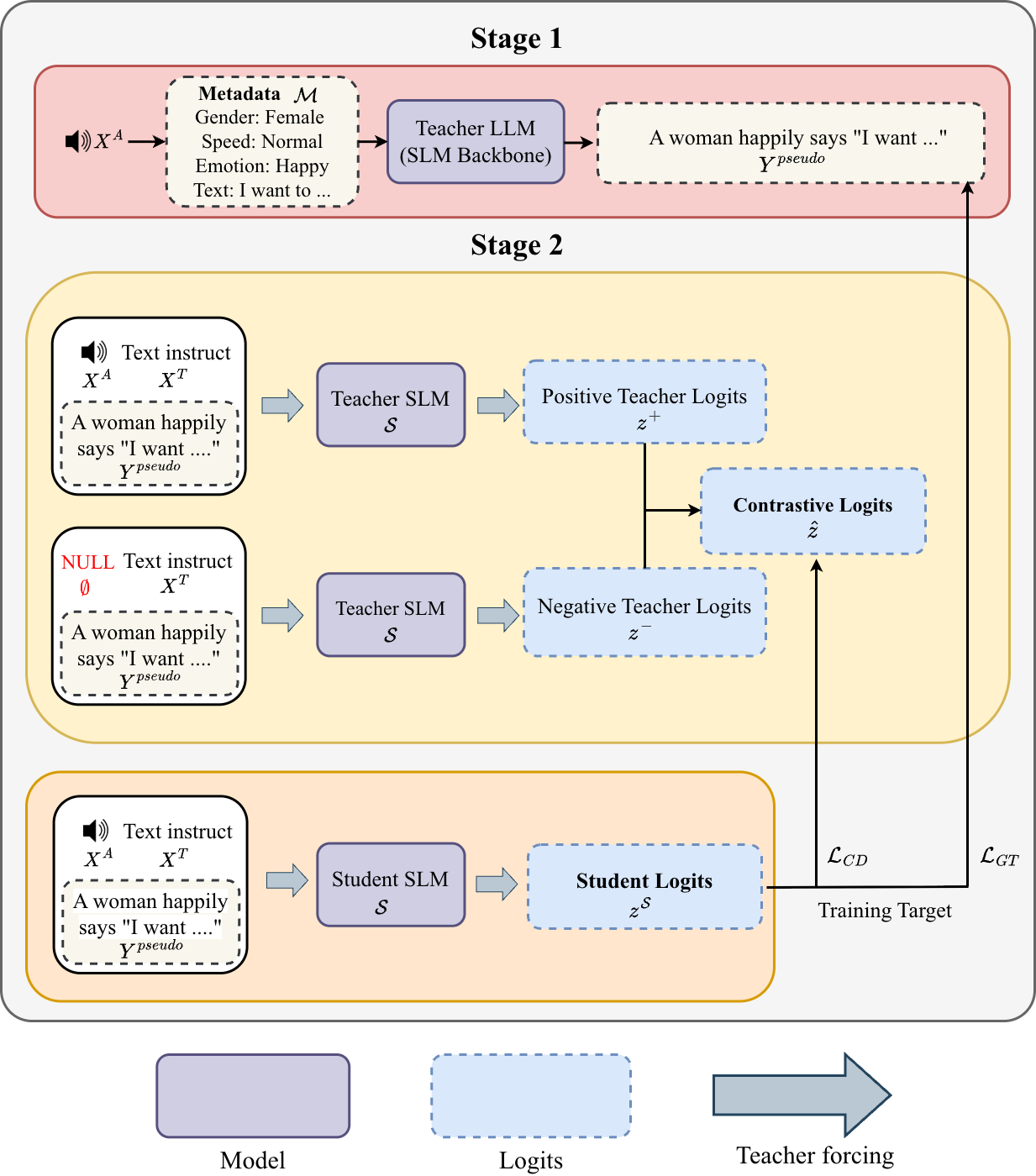
The proposed solution is to internalize the contrastive effect during training so that the student does not need dual-path decoding at test time. The difficulty is that standard contrastive distillation is autoregressive and token-by-token, which breaks the usual parallelism of teacher forcing. CAAD solves this by introducing a unified anchor sequence, called the Pseudo-Ground Truth or Pseudo-GT, that synchronizes the teacher's positive and negative distributions across the full sequence.
Methodology
CAAD is organized into two stages. The first stage constructs a Pseudo-GT sequence from metadata associated with the input audio. The second stage uses synchronized teacher forcing to generate the teacher's audio-aware and text-only logits in parallel over that same anchor sequence, and then distills the contrastive difference into the student.
Stage 1: Pseudo-GT generation via metadata anchor
In Stage 1, the method uses text metadata extracted from the audio to build a fixed anchor sequence $Y^{\text{pseudo}} = \{y_1, y_2, \dots, y_L\}$. The paper says this metadata can include attributes such as gender, emotion, acoustic environment, and similar descriptors. Following the DeSTA framework, the authors generate a structurally dense textual Pseudo-GT conditioned on this metadata. They also study an alternative anchor generated directly from continuous audio, but the experiments show that the metadata-based anchor is more effective.
The main reason for using metadata is that it provides a stable and structured teacher-forcing target. Rather than trying to synchronize two autoregressive paths over a sequence generated from the audio itself, CAAD uses the metadata-conditioned sequence as a common scaffold for both positive and negative teacher passes. This preserves full-sequence parallelization during training.
Stage 2: contrastive audio-aware distillation
In Stage 2, the frozen teacher $\mathcal{T}$ is run twice under synchronized teacher forcing. The positive path conditions on audio and text, while the negative path masks audio and keeps only text instructions:
$$z_t^+ = \mathcal{T}(X^A, X^T, y_{
$$z_t^- = \mathcal{T}(\emptyset, X^T, y_{
Here $X^A$ is the audio input and $X^T$ is the text instruction. The paper defines the audio-aware target by moving away from the negative-path logits:
$$\hat{z}_t = (1 + \alpha) z_t^+ - \alpha z_t^-$$
The scalar $\alpha \ge 0$ controls how strongly the negative path is subtracted. Intuitively, the term $z_t^- $ captures the teacher's linguistic priors, while $z_t^+$ contains the desired audio-grounded distribution. The extrapolated target $\hat{z}_t$ rewards tokens uniquely supported by the audio-aware path and penalizes tokens mainly explained by text priors.
The student model $\mathcal{S}$ is optimized with a hybrid loss that balances contrastive distillation and ordinary supervision on the Pseudo-GT tokens. The contrastive loss is a KL divergence between the student's distribution and the sharpened audio-aware teacher target:
$$\mathcal{L}_{\text{CD}} = \frac{1}{L} \sum_{t=1}^{L} \tau^2 \, \mathrm{KL}\!\left( \operatorname{softmax}(\hat{z}_t / \tau) \parallel \operatorname{softmax}(z_t^{\mathcal{S}} / \tau) \right)$$
where $\tau$ is the temperature and $z_t^{\mathcal{S}}$ are the student logits. The paper additionally uses a standard cross-entropy loss on the Pseudo-GT sequence:
$$\mathcal{L}_{\text{GT}} = \frac{1}{L} \sum_{t=1}^{L} \mathrm{CrossEntropy}(z_t^{\mathcal{S}}, y_t^{\text{pseudo}})$$
The final objective is a weighted sum:
$$\mathcal{L}_{\text{total}} = \lambda \mathcal{L}_{\text{CD}} + (1-\lambda) \mathcal{L}_{\text{GT}}$$
This design is important because the cross-entropy term preserves fluency and keeps the student from drifting into degenerate regions of the logit space, while the contrastive term focuses the student on the audio-aware correction relative to the text-only baseline.
The experiments are run in the DeSTA2 framework. The teacher uses a standard DeSTA2 architecture with a Llama-3.2-8B foundation, and the student replaces the backbone with Llama-3.2-3B. The paper emphasizes that the core LLM parameters are frozen during distillation; only the Q-Former modality adapter is trained to project acoustic features into the LLM embedding space. This keeps the trainable parameter count low, at about 32M parameters.
Optimization uses FusedAdam with learning rate $1 \times 10^{-4}$ and a cosine schedule. The reported hyperparameters are $\lambda = 0.7$ for the combined loss and $\tau = 2.0$ for the contrastive KL term. Training was carried out on a single RTX A6000 GPU and took roughly 70 hours.
For Pseudo-GT generation, the paper says that Llama3-8B-Instruct serves as the stage-1 teacher for the DeSTA 3B student, with temperature and top-$p$ both set to $1$ in the described setup. The paper also notes that the Pseudo-GT generation protocol follows DeSTA and is based on metadata rather than raw audio in the main method.
The training corpus is the expressive speech instruction-following dataset established by DeSTA2. It consolidates multiple sources: AccentDB, DailyTalk, IEMOCAP, PromptTTS, VCTK, and VoxCeleb. Beyond the original labels, specialized pretrained models extract paralinguistic and environmental attributes such as gender, emotion state, pitch, speaking rate, signal-to-noise ratio, and C50. The paper states that the combined corpus contains 12 distinct attributes covering speaker identity, prosody, and acoustic environment.
Evaluation is performed on two complementary benchmarks. Dynamic-SUPERB measures generalization on unseen tasks and is broken into five categories: Content (CON), Semantic (SEM), Paralinguistic (PAR), Degradation (DEG), and Speaker (SPK). The paper treats CON and SEM as categories that can often be solved with language priors, while PAR, DEG, and SPK require acoustic perception.
The second benchmark is MCR-BENCH, used to probe modality conflict resolution. The paper evaluates the Speech Emotion Recognition subset derived from MELD and reports four accuracy settings: Neutral ($Acc_{\text{neu}}$), Faithful ($Acc_{\text{fth}}$), Adversarial ($Acc_{\text{adv}}$), and Irrelevant ($Acc_{\text{irr}}$). It also defines a Shift metric, where lower values indicate greater robustness to misleading text. The formula used is:
$$\text{Shift} = \frac{\Delta_{c \to i}}{N_{\text{neu}}}$$
where $\Delta_{c \to i}$ is the number of examples that were correct in the Neutral setting but incorrect in the Adversarial setting, and $N_{\text{neu}}$ is the number of correct predictions in the Neutral setting.
The paper compares CAAD against three baselines: vanilla greedy decoding, test-time contrastive decoding (CD), and standard KD. The comparison is useful because it separates three effects: raw model capability, explicit inference-time contrastive grounding, and conventional logit matching. The central outcome is that CAAD consistently improves over standard KD and the student's greedy baseline, while also greatly reducing the shift induced by conflicting text on MCR-BENCH.
On Dynamic-SUPERB, the CAAD student reaches an overall score of 54.44. Relative to standard KD's 50.40, this is the paper's main gain. CAAD is particularly strong on CON ($73.86$), SEM ($60.57$), and PAR ($51.35$), with the semantic and paralinguistic results exceeding the teacher's greedy decode baseline. The model does not surpass the teacher's CD decoding, but the point of CAAD is to capture some of that contrastive benefit in a single-pass student rather than require inference-time CD.
On MCR-BENCH, CAAD improves the student's ability to resist misleading text. It reaches $Acc_{\text{neu}} = 45.90$, $Acc_{\text{fth}} = 82.80$, $Acc_{\text{adv}} = 11.80$, $Acc_{\text{irr}} = 45.50$, and Shift = 79.03. The especially notable gain is the reduction in shift compared with standard KD's $100.00$, which the authors interpret as evidence that CAAD is less likely to flip from correct to incorrect when exposed to adversarial text. In the paper's framing, this indicates stronger reliance on acoustic evidence and weaker dependence on language priors.
The ablations focus on two design choices: the contrastive weight $\alpha$ and the source of the Pseudo-GT anchor. These studies are important because they show that CAAD is not just "more loss terms," but a specific balance between contrastive sharpening and sequence anchoring.
The paper reports that $\alpha = 0$ corresponds to standard KD. Any positive contrastive weight improves over that baseline. The main pattern is a tradeoff: moderate contrastive weight gives the best average benchmark score, while larger $\alpha$ values more aggressively reduce linguistic bias.
The best Dynamic-SUPERB average is obtained at $\alpha = 1.0$ with an ALL score of 55.00, while the strongest de-biasing on MCR-BENCH occurs at $\alpha = 2.0$ with Shift = 79.03. The authors interpret this as evidence that stronger contrastive subtraction better suppresses linguistic priors, even if the average task score does not always continue to rise. This is a useful design signal for practitioners: if the application prioritizes acoustic grounding and conflict robustness, a larger $\alpha$ may be preferable.
The second ablation compares Pseudo-GT generated from audio directly versus Pseudo-GT generated from metadata. The authors find that both synchronization strategies outperform the corresponding standard KD baseline, but metadata-based anchoring is better.
The paper's conclusion from this table is that metadata provides a higher-fidelity and more stable anchor than raw audio for synchronized teacher forcing. Under CAAD, metadata synchronization improves the ALL score from 49.83 to 54.44 and lowers Shift from 94.46 to 79.03. This supports the claim that the anchor quality matters materially for the success of contrastive distillation.
The strongest conceptual result is that CAAD shifts the benefit of contrastive decoding from test-time inference into model parameters. In other words, the student learns to imitate the teacher's contrastive logic, not just its final token probabilities. This distinction matters because standard KD can faithfully transfer the teacher's bias, while CAAD specifically targets the teacher's audio-aware residual over the text-only path.
The paper also shows that the method is not simply a generic regularizer. The improvement on MCR-BENCH is tied to the subtraction of the negative path and the synchronized anchor. If the contrastive term is removed, the student behaves like ordinary KD and the shift remains maximal at $100.00$. If the anchor is weak, the gain is smaller. So the gains appear to come from the interaction between the contrastive target and the metadata-based synchronization scheme.
At the same time, the results reveal a limitation of the approach: CAAD does not fully recover the performance of the larger teacher with test-time CD. The teacher's CD decoding still performs better on overall Dynamic-SUPERB and some MCR-BENCH metrics. The paper therefore positions CAAD as a practical compromise: it is more efficient than inference-time CD and more acoustically grounded than standard KD, but it is not a perfect substitute for the teacher's dual-path reasoning.
The paper explicitly notes that distillation gains depend on the quality gap between teacher and student. If the student is already highly optimized, such as a strong small model, the room for improvement through distillation may be limited. This is a meaningful caveat because CAAD relies on the teacher providing a better contrastive signal than the student can already produce on its own.
A second practical limitation is that the method still requires the teacher's dual-path contrastive generation during training. CAAD reduces inference-time cost and improves training efficiency through synchronized teacher forcing, but it does not eliminate the need to run the contrastive teacher inside the distillation pipeline. The contribution is therefore efficiency relative to token-by-token contrastive distillation, not free training.
Overall, the paper argues that CAAD is a useful recipe for building smaller speech language models that are still responsive to acoustic evidence. Its central message is that contrastive decoding need not remain a test-time crutch; with an appropriate anchor and loss design, its grounding behavior can be absorbed into a compact student model.
This repository implements the Contrastive Audio-Aware Distillation (CAAD) framework primarily within the The While the README notes that full usage instructions will be updated soon, the existing codebase suggests an organization supporting training and evaluation of speech models with audio-aware distillation strategies as described in the paper.Optimization objective
Training Setup and Model Configuration
Training Data and Benchmarking
Main Results
Model / decoding or distillation
CON
SEM
PAR
DEG
SPK
ALL
Acc_neu
Acc_fth
Acc_adv
Acc_irr
Shift
Teacher (8B), greedy decode
79.41
59.42
43.14
51.63
42.50
56.78
3.90
98.60
1.10
41.20
97.37
Teacher (8B), CD
81.72
62.92
52.14
59.73
44.57
61.79
11.20
51.40
15.00
41.80
83.96
Student (3B), greedy decode
54.45
49.42
32.78
39.84
22.92
41.02
1.40
97.40
1.00
34.00
90.65
Student (3B), CD
40.13
43.57
29.42
38.52
20.21
35.80
1.00
56.60
7.40
26.90
87.50
Student (3B), standard KD
65.72
58.42
43.35
46.42
36.14
50.40
41.00
96.90
0.50
40.90
100.00
Student (3B), CAAD
73.86
60.57
51.35
49.23
35.00
54.44
45.90
82.80
11.80
45.50
79.03
Ablation Studies
Effect of the contrastive weight $\alpha$
Config
Dynamic-SUPERB (ALL)
MCR-BENCH (Shift)
$\alpha = 0.0$ (standard KD)
50.40
100.00
$\alpha = 0.5$
53.63
98.51
$\alpha = 1.0$
55.00
93.78
$\alpha = 2.0$
54.44
79.03
Effect of the Pseudo-GT anchor source
Synchronization strategy
Method
Dynamic-SUPERB (ALL)
MCR-BENCH (Shift)
Audio sync.
Standard KD
46.80
99.45
Audio sync.
CAAD
49.83
94.46
Metadata sync. (proposed)
Standard KD
50.40
100.00
Metadata sync. (proposed)
CAAD
54.44
79.03
Interpretation of the Results
Limitations
Contributions and Takeaways
Code & Implementation
desta/ directory. Key components include modules for task processing and utility functions supporting data handling and logging. The desta/tasks/ submodule contains scripts related to task execution such as ASR (Automatic Speech Recognition) and potentially distillation-related workflows.desta/cli/ directory offers command-line tools for model and audio resource management, such as downloading model snapshots.