AudioCALM
AudioCALM: Continuous Autoregressive Language Modeling for Universal Audio Generation
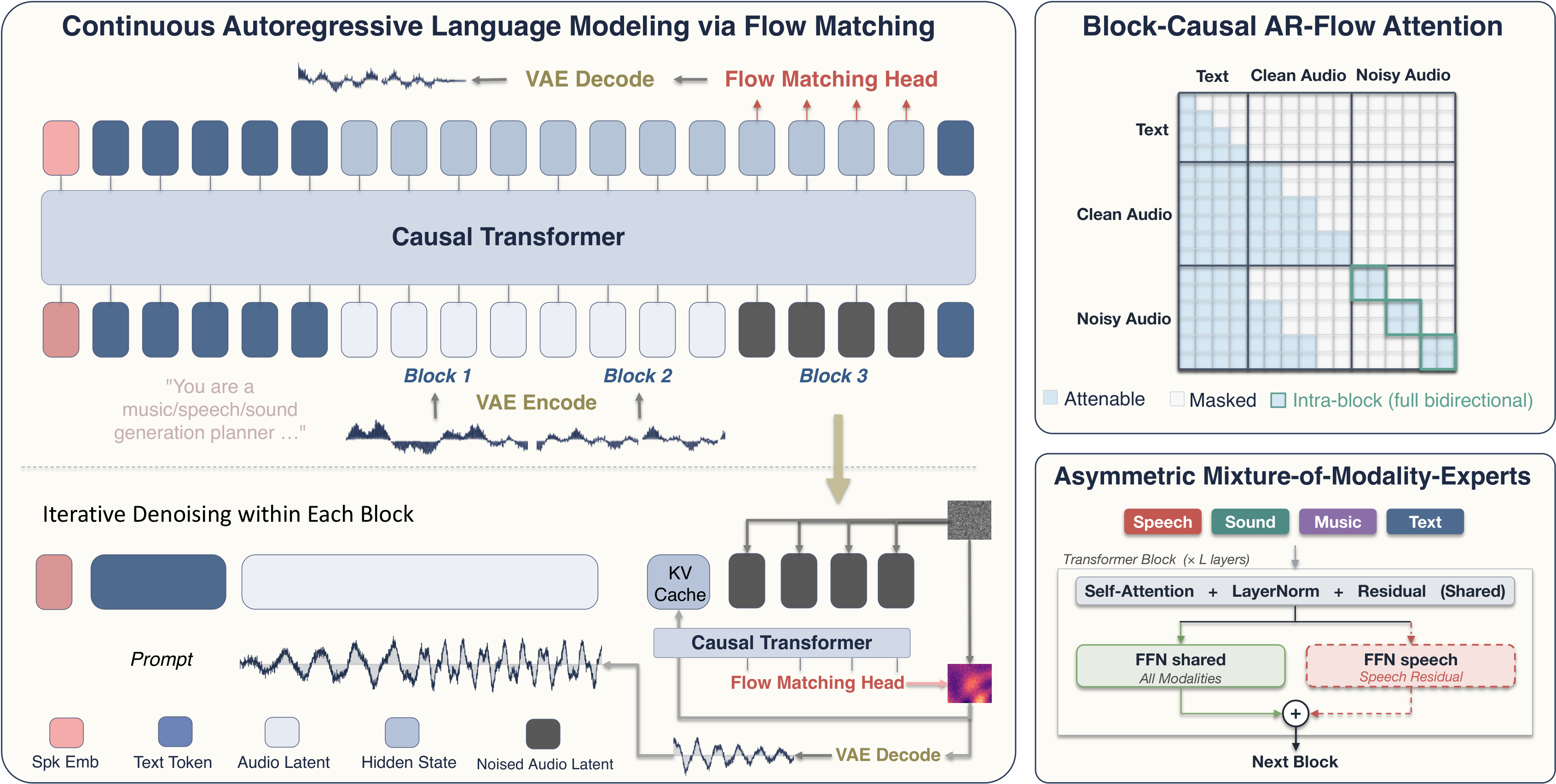
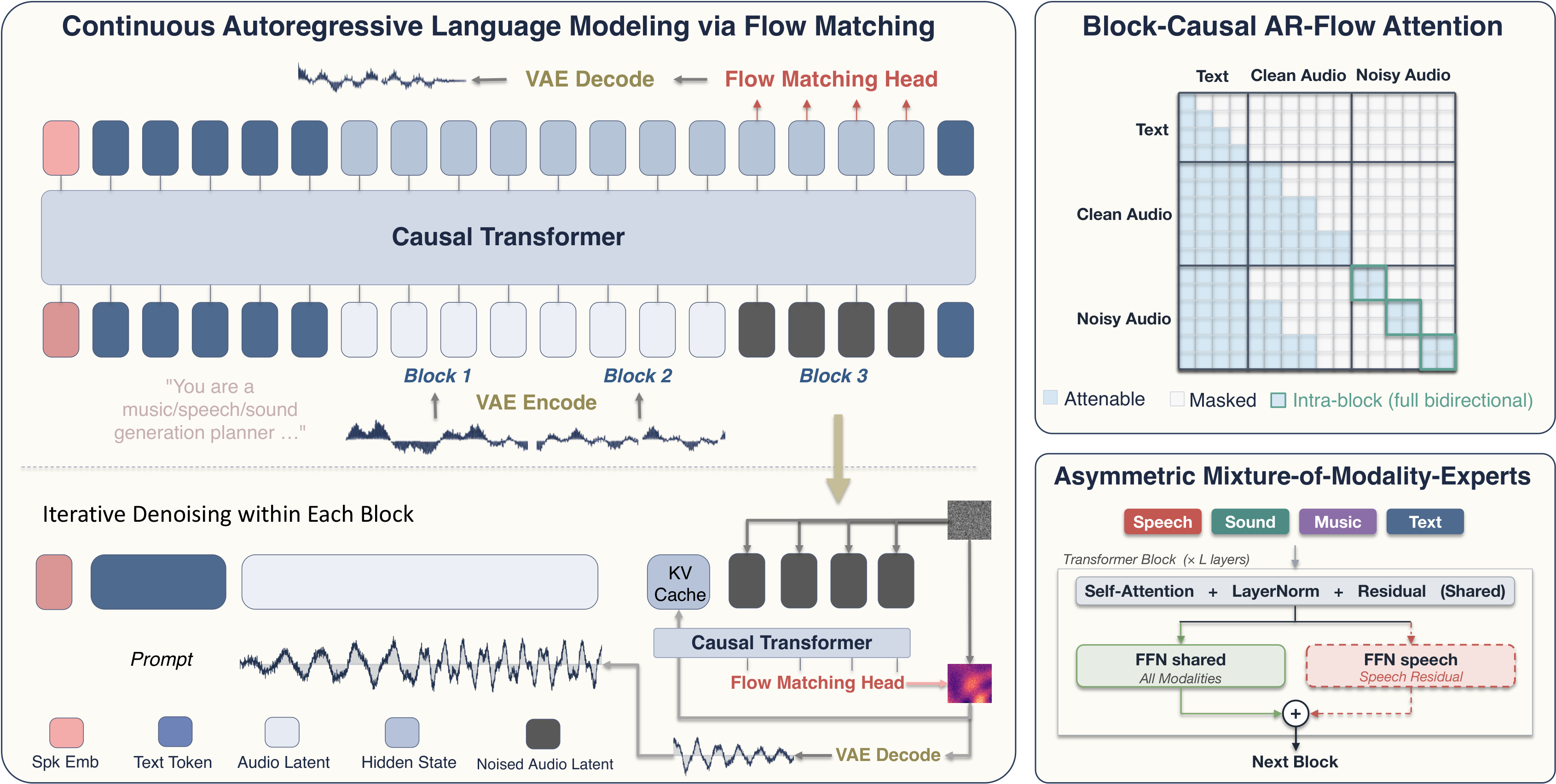
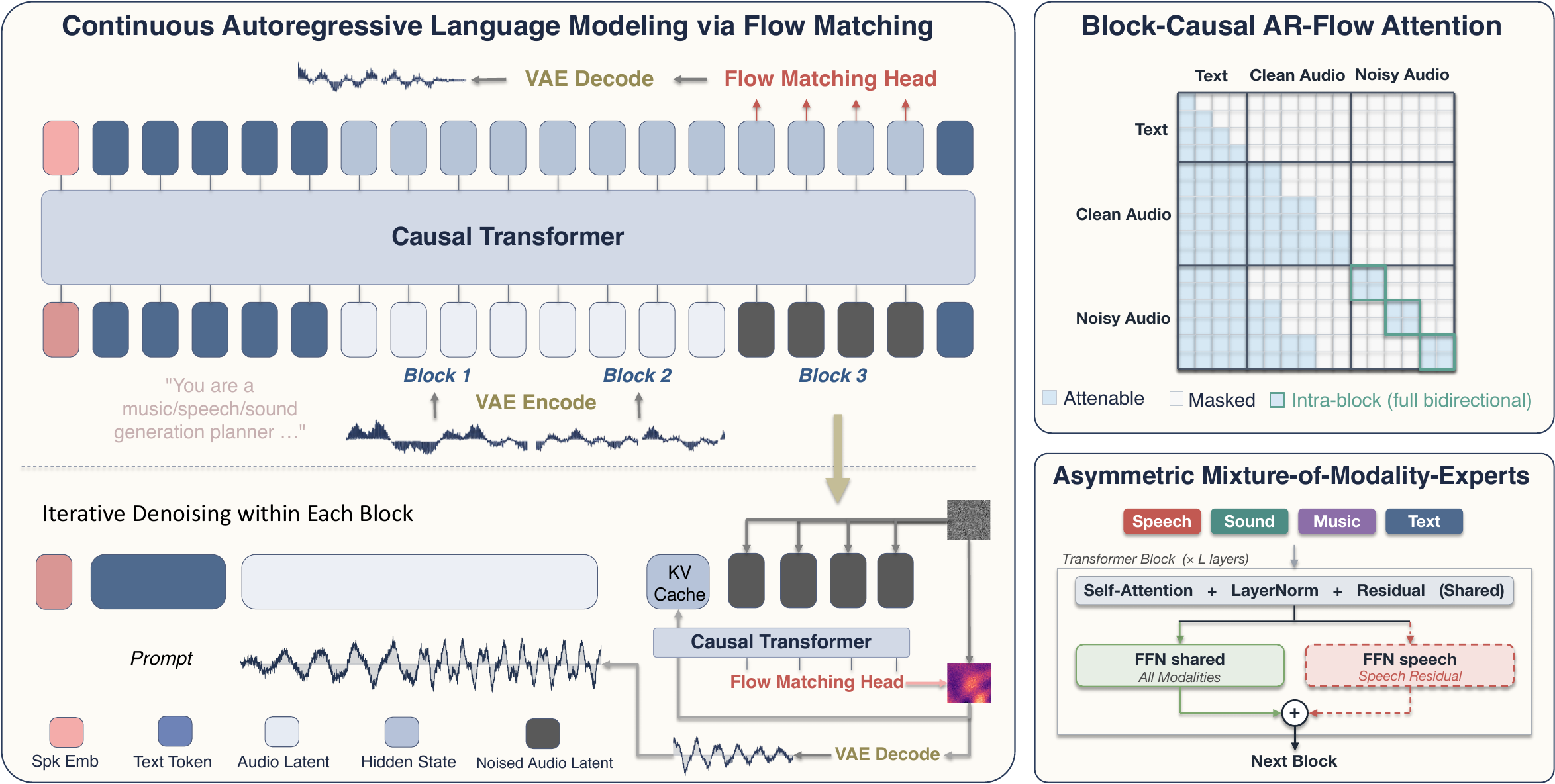
AudioCALM is a universal audio generation model that autoregressively predicts continuous audio latents to unify speech, sound, and music synthesis. It balances modality differences with asymmetric experts and descriptive conditioning for high-quality, variable-length, end-to-end audio generation.
Demos
These demos highlight AudioCALM's unified model generating high-fidelity speech, sound, and music from text prompts, demonstrating its continuous autoregressive approach with flow-matching and asymmetric experts. Evaluate its speech intelligibility, sound authenticity, and musical coherence, as well as smooth, variable-length streaming audio output.
Links
Paper & demos
Abstract
Unifying speech, sound, and music generation in one model is hindered by tradeoffs between fidelity, end-to-end training, in-context conditioning, and variable-length synthesis that no current paradigm fully resolves. To address this challenge, we present AudioCALM, a universal audio generation framework that extends autoregressive (AR) next-token prediction from discrete tokens to continuous audio latents: a thin flow-matching head replaces the softmax to predict rectified-flow velocities at each position, and a block-causal AR-Flow attention pattern produces arbitrary-length output. Joint training of multiple audio generation tasks faces an asymmetric text--audio mismatch: speech transcripts align to specific time spans and demand tight, time-aligned attention, whereas sound and music captions describe only overall semantics and rely on diffuse, holistic attention; mixing the two disproportionately degrades sound and music generation. We address this asymmetry at two levels: a data reformulation strategy that unifies all three tasks under a single description-style conditioning interface, and a novel architecture Asymmetric Mixture-of-Modality-Experts (A-MoME), which adds a dedicated residual expert for speech while sound and music share the backbone, incurring no inference overhead on non-speech inputs. Experimental results demonstrate that AudioCALM matches modality-specific state-of-the-art and outperforms prior unified baselines on speech, sound, and music generation benchmarks.
Introduction
AudioCALM proposes a single model for text-to-speech, text-to-sound, and text-to-music generation that tries to avoid the usual tradeoffs between fidelity, end-to-end optimization, in-context conditioning, and variable-length synthesis. The paper frames the core challenge as a mismatch between what current audio generation paradigms are good at and what a universal model needs: discrete-token autoregressive systems preserve the language-model interface but are limited by codec bottlenecks; cascaded language-model-then-generator systems improve fidelity but break end-to-end training; and non-autoregressive flow-matching systems generate high-quality continuous audio but lose autoregressive in-context behavior and typically require external duration control.
The central idea is to extend autoregressive next-token prediction from discrete tokens to continuous audio latents. Instead of a softmax over a vocabulary, the model uses a thin flow-matching head that predicts rectified-flow velocities in latent space. A new attention pattern called AR-Flow keeps generation autoregressive across blocks while allowing bidirectional access within each active denoising block, so the model can produce arbitrary-length outputs without an external duration predictor. The paper argues that this combination retains the best properties of language models and continuous generators in one framework.
The other major problem is that joint training over speech, sound, and music is asymmetric: speech transcripts are tightly aligned to the waveform, while captions for sounds and music are globally descriptive. The paper finds that mixing speech with non-speech audio causes a directional interference pattern, where speech can crowd out the diffuse attention needed by sound and music more than the reverse. To address this, the authors propose a data reformulation into a shared description-style conditioning interface and an architectural specialization called Asymmetric Mixture-of-Modality-Experts (A-MoME), which adds a speech-only residual feed-forward expert while leaving sound and music on the shared backbone.
Problem Setting and High-Level Claims
The paper defines a universal audio generator as a single model that can condition on text, optionally plus a reference audio prompt for voice cloning, and generate speech, sound, or music. It positions AudioCALM against three established families: discrete-token autoregressive models, cascaded LM-then-generator systems, and non-autoregressive flow/diffusion models. The key claim is that no single existing paradigm fully satisfies four desiderata at once: fidelity, end-to-end optimization, in-context understanding, and natural variable-length generation. AudioCALM is designed explicitly around those four requirements.
The paper also makes a more specific claim about multi-task training. Speech is not just another audio domain: transcript-to-audio conditioning is locally aligned in time, while sound and music captions are semantically global. This asymmetry means that uniform sharing across all modalities is suboptimal. The authors argue that universal models need both a unified text interface and asymmetric capacity allocation, rather than symmetric modality-specific branching.
Method
Continuous Autoregressive Language Modeling
AudioCALM models audio as a sequence of continuous latent tokens $x = (x_1, \ldots, x_L)$ produced by a frozen variational autoencoder. Given text condition $c$, the model factorizes the distribution autoregressively as
$$p(x \mid c) = \prod_i p(x_i \mid x_{
Each audio latent is embedded with a learned input projection $\phi_{\text{in}}$, a position embedding, and a sinusoidal timestep embedding $\tau(t)$. For a noised latent $x_i^{(t)}$, the embedding is
$$e_i^{(t)} = \phi_{\text{in}}(x_i^{(t)}) + p_i + \tau(t).$$
The backbone is a pretrained text LLM, specifically initialized from Qwen3-1.7B in the main experiments, and the same transformer processes interleaved text and audio tokens. Instead of predicting discrete logits, the model applies a linear flow-matching head $\phi_{\text{out}}$ to each audio-position hidden state $h_i$ to produce a velocity vector in the latent space:
$$v_\theta(h_i) = \phi_{\text{out}}(h_i).$$
Training follows rectified flow. For each audio latent, the model samples a timestep $t$ from a logit-normal schedule, draws Gaussian noise $\epsilon_i$, interpolates between the clean latent and noise,
$$x_i^{(t)} = (1 - t)x_i + t\epsilon_i,$$
and predicts the target velocity
$$v_i^{\star} = \epsilon_i - x_i.$$
The loss is mean-squared error on the noisy audio positions:
$$\mathcal{L}_{\text{FM}}(\theta) = \mathbb{E}\left[\frac{1}{|\mathcal{N}|} \sum_{i \in \mathcal{N}} \|v_\theta(h_i) - v_i^{\star}\|_2^2\right].$$
The authors zero-initialize the output projection so the new head starts as a no-op and does not destabilize the LLM early in training. They also note that clean latents and $t=0$ latents share the same input projection, which reduces train-test mismatch when a fully denoised block is written back into the cache.
The key difficulty in combining autoregression with flow matching is that AR wants causal attention, while flow matching wants bidirectional context among the latents being denoised together. AR-Flow resolves this with a block-causal mask: attention is causal across blocks, but fully bidirectional within the currently active noisy block.
In the packed input at generation time, the model sees a text prefix, the committed clean audio latents, and one contiguous noisy block. The block attends to the entire text condition and to all committed prefix latents, but not to future noisy blocks. This makes variable-length generation a property of the attention mask rather than a fixed duration hyperparameter.
The paper further shows how to train this efficiently in a single forward pass. Instead of running one pass per block, it packs a clean prefix and noisy copies of the whole utterance into a single extended sequence. The training mask is constructed to exactly match the inference mask: each noisy position attends only to the text, the clean prefix strictly before its own block, and other noisy positions within the same block. The clean half is only there to populate the KV cache; the flow-matching loss is computed on the noisy half.
The paper emphasizes that this gives standard LM training cost while avoiding teacher-forcing/inference mismatch in the attention pattern itself.
The conditioning side is handled with a description-style interface. For every training clip, the authors store both a short variant and a long-form variant. The short variant is the original transcript for speech or original caption for sound and music. The long-form variant is generated offline by an audio-conditioned multimodal LLM and expands modality-relevant attributes in natural language: speaker timbre, prosody, and recording acoustics for speech; acoustic events and scene structure for sound; genre, instrumentation, tempo, mood, motifs, and production character for music.
For speech, the long-form description additionally wraps the verbatim transcript in explicit delimiters $\langle\text{spoken}\rangle \ldots \langle/\text{spoken}\rangle$ so the model can access both diffuse descriptive context and exact local textual content. The paper treats these delimiter tokens as special tokens in the tokenizer so they correspond to single embedding entries.
The architecture-level fix is A-MoME. Unlike a symmetric expert design that would allocate separate experts for every modality, A-MoME keeps self-attention, layer normalization, residual paths, and the main feed-forward network shared across all tokens, and adds only one extra residual feed-forward expert for speech positions. Formally,
$$\mathrm{FFN}_{\text{A-MoME}}(h) =
\begin{cases}
\mathrm{FFN}_{\text{shared}}(h) + \mathrm{FFN}_{\text{speech}}(h), & m(h)=\text{speech},\\
\mathrm{FFN}_{\text{shared}}(h), & \text{otherwise}.
\end{cases}$$
The authors stress that this is asymmetric by design: speech gets specialized capacity because it is the modality with the tighter local alignment problem, while sound and music continue to share the backbone unchanged. The speech-only branch is zero-initialized, and non-speech inference has no extra cost because those inputs never activate the additional expert.
The total objective combines the rectified-flow loss with a stop-head binary cross-entropy. The stop head is a linear layer followed by a sigmoid applied on clean hidden states, trained with targets that ramp from $0$ to $1$ over the final $K_{\text{stop}}=10$ tokens of each clip. At inference, the stop head is queried on each new block, and generation terminates when the predicted stop probability exceeds a threshold.
To reduce train-test drift from iterative autoregressive commitment, the paper adds two regularizers. First, per-block clean-prefix noise perturbs the input embeddings of the clean prefix with Gaussian noise whose scale ramps up across blocks. Second, exposure-bias perturbation adds a small Gaussian perturbation to the clean target latent itself, so the model learns to recover from slightly noisy committed prefixes.
Inference uses Euler integration of the learned velocity field with $K_{\text{flow}}=24$ steps per block. The default AR-Flow block size is $B=1.0$ seconds, corresponding to about $11$ latent tokens at the VAE’s $\approx 10.75$ Hz bottleneck rate. The model also uses classifier-free guidance at scale $w=3.0$.
The audio backend is not a standard codec tokenizer. The authors train their own continuous variational autoencoder on $44.1$ kHz stereo waveforms. It is a CNN-GAN family model inspired by Stable Audio Open / DAC, with three notable changes: an iSTFT synthesis head at the decoder output, self-attention inserted at the lowest-resolution encoder and decoder stages, and a learned patch-with-$[\text{CLS}]$ aggregator at the bottleneck to reduce the latent rate.
The encoder reduces the waveform through strided residual blocks to a $21.5$ Hz feature sequence, then groups frames into patches of size $P=2$ and mixes them with a small attention aggregator. The resulting latent posterior is Gaussian, and the aggregated bottleneck rate becomes $21.5/P \approx 10.75$ Hz. The decoder mirrors this process and reconstructs stereo audio through an iSTFT head with hop size $2048$ and FFT size $8192$.
The VAE is trained with multi-resolution STFT reconstruction, KL regularization with free bits, and adversarial losses from a multi-period discriminator and a multi-resolution complex-spectrogram discriminator. It is then frozen for AudioCALM training.
Training uses three modality groups. For speech, the corpus mix is LibriTTS plus the English subset of Emilia. For general sound, the mix includes VGGSound, AudioCaps, and WavCaps. For music, the mix includes FMA and MTG-Jamendo. Only official training splits are used. The paper explicitly holds out LibriTTS test-clean, the AudioCaps and Song-Describer evaluation sets, and SeedTTS-eval to avoid contamination.
All audio is resampled to $44.1$ kHz and converted to stereo; mono sources are duplicated to two channels. The long-form descriptions are generated offline using Gemini 3 Pro, with a modality-specific prompt template that enforces audio-grounded descriptions and, for speech, exact transcript preservation inside the delimiters. The prompt templates are carefully constrained: they forbid hallucinated attributes, named entities for sound, and exact BPM or artist names for music. A $5\%$ sample of generated captions is manually reviewed, rejected items are regenerated, and clips that fail repeatedly are removed. The data loader then randomly chooses between the short and long variant with equal probability per example.
The main model is initialized from Qwen3-1.7B, trained for $300{,}000$ steps on $8$ A800 GPUs with FSDP HYBRID-SHARD, AdamW, a constant learning rate of $10^{-4}$ after $2{,}000$ warmup steps, gradient clipping at $1.0$, and a global batch of roughly $64$k tokens. The sequence packing length is $4096$ tokens. The training mixture ratio at the example level is speech $0.4$, sound $0.3$, music $0.3$. Caption dropout for classifier-free guidance is $10\%$.
The paper also reports a size sweep with Qwen3-0.6B, 1.7B, and 4B backbones, a classifier-free guidance sweep over $w \in \{1,2,3,4,5\}$, an AR-Flow block-size sweep over $B \in \{0.25, 0.5, 1.0, 2.0, 4.0\}$ seconds, and an inference-step sweep. The appendix figure shows that quality improves sharply up to roughly 20 to 30 flow steps and then saturates, which is why 24 steps is used as the default.
AudioCALM is evaluated on zero-shot speech synthesis, text-to-sound, and text-to-music. Speech uses LibriTTS test-clean and SeedTTS-eval (English), with word error rate, speaker similarity, and MOS. Sound uses AudioCaps, and music uses Song-Describer, with Fréchet Audio Distance, CLAP similarity, and subjective MOS-quality and MOS-text scores.
The headline result is that one set of weights matches or beats the best modality-specific system in each domain, and clearly outperforms previous unified baselines. The paper also emphasizes that AudioCALM streams natively without an external duration predictor, unlike non-autoregressive baselines.
AudioCALM obtains the best WER and MOS on both speech benchmarks. It trails only CosyVoice 3.0 on SIM, which the paper interprets as unsurprising because CosyVoice 3.0 is a much larger speech-specific system trained on an English-only speech corpus with a dedicated speaker-fidelity objective. The unified model still posts the lowest WER on both sets: $0.020$ on LibriTTS test-clean and $0.011$ on SeedTTS-eval.
On AudioCaps, AudioCALM lowers FAD from the best sound specialist, TangoFlux, from $2.70$ to $1.95$, while raising CLAP slightly from $0.36$ to $0.37$. On Song-Describer, it reaches the best FAD and the best CLAP among all compared methods, with $2.02$ FAD and $0.36$ CLAP. The subjective ratings also place AudioCALM first on both sound and music. The paper highlights that it is the only method to rank first or second on every reported column across all three domains.
The ablation study is especially important because it isolates the effect of the continuous latent head, the description-style conditioning, and A-MoME. The paper reports both single-modality specialists and cumulative joint-training variants, all using the same Qwen3-1.7B backbone except where otherwise noted.
The ablation reveals several clear trends. First, the continuous flow-matching head is the single biggest jump over discrete-token autoregression: compared with variant (a), variant (b) sharply improves every metric across speech, sound, and music, confirming that codec discretization is the main fidelity bottleneck. Second, description-style reframing helps non-speech audio a lot more than speech, suggesting that harmonizing captions and transcripts into a shared long-form conditioning surface reduces the local-vs-global mismatch. Third, A-MoME outperforms a symmetric three-expert MoME while using less extra capacity and zero added inference cost on non-speech inputs.
The paper also uses the specialist rows to quantify asymmetric crowd-out. When non-speech data is added to a speech-only run, speech metrics stay within noise. But when speech is added to a non-speech-only run, sound and music suffer a much larger degradation. This directional effect motivates the asymmetry in both the data interface and the parameter specialization.
Two additional appendix sweeps are worth noting. Scaling the backbone from 0.6B to 1.7B to 4B steadily improves all metrics, with 4B giving the best reported numbers in that sweep. The CFG sweep finds $w=3.0$ to be the best overall balance. The AR-Flow block-size sweep shows the tradeoff between streaming granularity and quality: smaller blocks help latency and larger blocks approach the non-autoregressive regime, while the default $B=1.0$ second gives the best overall quality among the tested settings.
The paper’s main technical contribution is not simply “use flow matching with an LM.” It is the combination of three design levels that are aligned with one another: a continuous latent head that preserves the autoregressive LM interface, a blockwise attention scheme that makes streaming generation possible without giving up within-block denoising context, and a modality-asymmetric conditioning/specialization strategy that targets the actual source of cross-task interference. The authors argue that if any one of these pieces is removed, the universal model degrades toward one of the known tradeoff corners.
The data reformulation is especially central. By converting short transcripts and captions into description-style prompts, the model no longer sees speech, sound, and music as three incompatible prompt styles. This makes the shared backbone’s job easier and, in the ablation, directly improves non-speech generation. A-MoME then allocates extra capacity only where alignment is intrinsically tighter, rather than paying the cost of symmetric expert duplication.
The paper states three limitations. First, the training mixture covers only English speech and publicly available sound and music corpora, so it does not cover non-English speech, singing voice, or some narrower audio-event domains. The authors explicitly mention future work on incorporating singing so that the same backbone can support song generation. Second, the backbone-scale study only goes up to 4B parameters, so the behavior at larger scale remains unknown. Third, although the model can generate arbitrarily long outputs by construction, the paper does not deeply study long-form coherence and termination, and leaves that for future work.
The paper identifies both positive and negative applications. On the positive side, a universal speech/sound/music generator could support accessibility, creative audio production, and data augmentation. On the risk side, the model can be used for zero-shot voice cloning, impersonation, and fabrication of plausible synthetic audio events. To mitigate this, the authors say they will release the model under a research-use license that prohibits non-consensual cloning, impersonation, surveillance, harassment, and fraud workflows, and they emphasize that provenance and synthetic-audio detection remain necessary complements.
The paper also clarifies that the reference voices used for similarity evaluation come from public benchmark datasets only, and the human listening study did not collect any participant voice recordings.
AudioCALM presents a coherent universal-audio recipe: continuous latent autoregression instead of discrete token prediction, block-causal flow-matching attention for streaming variable-length generation, unified description-style conditioning, and asymmetric specialization through A-MoME. Across speech, sound, and music, the model matches or exceeds modality-specific baselines and clearly surpasses previous unified baselines on the reported benchmarks. The paper’s broader message is that a universal model for audio should not force all modalities into a symmetric design; it should preserve a single backbone while adapting to the different alignment structure of speech versus non-speech audio.
AR-Flow: Block-Causal Attention for Streaming Variable-Length Generation
Modality-Asymmetric Conditioning and A-MoME
Training Objectives, Regularization, and Inference
Audio VAE and Latent Representation
Data, Preprocessing, and Captioning Pipeline
Experimental Setup
Main Results
Speech Results
Model
LibriTTS WER
LibriTTS SIM
LibriTTS MOS
SeedTTS WER
SeedTTS SIM
SeedTTS MOS
F5-TTS 0.033 0.616 3.85 ± 0.08 0.018 0.648 3.78 ± 0.09 CosyVoice 3.0 0.022 0.697 3.96 ± 0.07 0.015 0.695 3.88 ± 0.08 UniAudio 0.120 0.265 3.30 ± 0.11 0.113 0.363 3.22 ± 0.12 UniMoE-Audio 0.078 0.361 3.52 ± 0.09 0.019 0.573 3.72 ± 0.08 UniFlow-Audio 0.032 0.570 3.50 ± 0.10 0.058 0.573 3.45 ± 0.10 Ming-omni-TTS 0.025 0.553 3.82 ± 0.08 0.013 0.633 3.80 ± 0.07 AudioCALM 0.020 0.668 4.02 ± 0.06 0.011 0.672 3.95 ± 0.07 Sound and Music Results
Model
AudioCaps FAD
AudioCaps CLAP
AudioCaps MOS-Q
AudioCaps MOS-T
Song-Describer FAD
Song-Describer CLAP
Song-Describer MOS-Q
Song-Describer MOS-T
AudioLDM 2-Large 5.36 0.22 3.25 ± 0.10 3.10 ± 0.11 -- -- -- -- TangoFlux 2.70 0.36 3.82 ± 0.07 3.85 ± 0.08 -- -- -- -- Stable Audio Open 4.13 0.25 3.65 ± 0.08 3.45 ± 0.09 2.23 0.32 3.95 ± 0.07 3.85 ± 0.08 MusicGen-Large -- -- -- -- 5.28 0.19 3.65 ± 0.08 3.45 ± 0.10 UniAudio 6.64 0.13 3.20 ± 0.11 2.95 ± 0.13 11.25 0.06 2.80 ± 0.14 2.65 ± 0.15 UniMoE-Audio -- -- -- -- 3.71 0.22 3.80 ± 0.08 3.60 ± 0.09 UniFlow-Audio 4.22 0.35 3.62 ± 0.08 3.80 ± 0.08 6.39 0.15 3.45 ± 0.10 3.25 ± 0.11 Ming-omni 2.46 0.27 3.85 ± 0.07 3.60 ± 0.09 7.98 0.07 3.25 ± 0.11 2.92 ± 0.13 AudioCALM 1.95 0.37 3.98 ± 0.06 3.95 ± 0.07 2.02 0.36 3.99 ± 0.06 3.92 ± 0.07 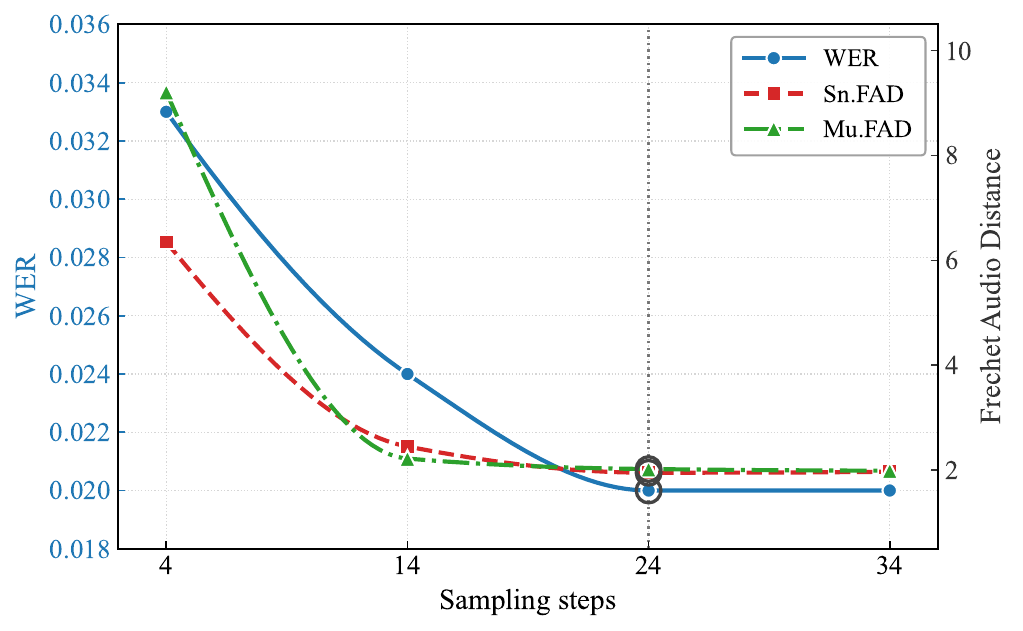
Ablation Studies
Variant
Speech WER
Speech SIM
Sound FAD
Sound CLAP
Music FAD
Music CLAP
Speech-only training 0.022 0.628 -- -- -- -- Non-speech-only training -- -- 2.45 0.34 2.55 0.30 (a) Discrete-token AR baseline 0.040 0.560 4.50 0.22 4.80 0.20 (b) Continuous AR + flow head, raw transcripts 0.024 0.620 3.30 0.30 3.45 0.26 (c) (b) + description-style reframing 0.023 0.625 2.70 0.33 2.85 0.29 (d) (c) + symmetric MoME with three modality experts 0.022 0.660 2.30 0.35 2.40 0.33 (e) (c) + A-MoME speech residual only 0.020 0.668 1.95 0.37 2.02 0.36 Interpretation of the Main Design Choices
Limitations
Broader Impact and Safety Notes
Conclusion