LombardTTS
Synthesizing the Lombard Effect: Multi-Level Control of Speech Clarity and Vocal Effort in TTS
This paper presents a TTS system that independently controls vocal effort and articulation to simulate the Lombard effect, enhancing speech clarity and intelligibility in noisy conditions. It enables continuous multi-level and word-level control for nuanced, context-specific speech emphasis.
Links
Paper & demos
Abstract
Humans tend to speak louder and clearer in challenging environments, such as noisy conditions or when addressing hearingimpaired listeners, which is called Lombard effect. To simulate this behavior in speech synthesis systems, we introduce a flow-matching based text-to-speech (TTS) model trained with vocal effort and articulation pseudo-labels. The proposed model achieves continuous and disentangled control of vocal effort and articulation, while also enabling word-level emphasis for clarifying specific segments of an utterance. Experimental results show that these control mechanisms effectively improve clarityrelated acoustic features. Furthermore, speech-in-noise experiments demonstrate that our model successfully simulates the intelligibility gains of human clear speech in noisy conditions.
Introduction and problem setting
This paper addresses Lombard speech synthesis: generating speech that becomes louder, clearer, and more intelligible in adverse listening conditions, such as background noise or when speaking to a hearing-impaired listener. The core motivation is that human Lombard speech is not just louder; it also tends to exhibit coordinated changes in vocal effort, articulation, pitch, spectral tilt, and speaking rate. Those changes improve intelligibility, but they are difficult to reproduce in modern text-to-speech (TTS) systems, which are usually trained on neutral speech and therefore lack controllable, interpretable mechanisms for producing clear or projected speech styles.
The paper’s central claim is that Lombard-style synthesis should be controllable along multiple axes, rather than through a single global style knob. In particular, the authors argue that vocal effort and articulation are related but distinct dimensions: vocal effort primarily affects spectral energy distribution and audibility, while articulation primarily affects phonetic distinctiveness and intelligibility. Their system aims to control both independently and jointly, and to allow targeted word-level emphasis when only specific segments of an utterance need to be clarified.
The authors position their work against two major strands of prior work. Earlier Lombard synthesis approaches were mostly signal-processing based, using pitch, spectral tilt, energy, or speaking-rate manipulations. More recent neural methods often adapt pretrained TTS systems or control a single aggregate notion of "Lombardness," but they typically do not provide a clean factorization between articulation and vocal effort. The paper’s stated novelty is a dual-axis conditioning framework with multi-level control over both utterance-wide and word-level clarity.
Model overview
The system is built on Matcha-TTS, a flow-matching TTS model. The authors choose this base architecture because it combines good synthesis quality with efficient inference. Unlike iterative diffusion models, Matcha-TTS uses a deterministic flow-matching objective, which is well suited to smooth interpolation in acoustic space. This is important for the paper’s goal: gradual control of speech style, rather than only discrete style switching.
The decoder is an optimal transport-based flow-matching decoder, and duration learning is handled by Monotonic Alignment Search ($\mathrm{MAS}$), which learns phoneme-to-frame durations. That makes duration an explicit control channel, allowing the model to modulate speaking rate and phoneme stretching in addition to acoustic features. A Vocos vocoder reconstructs waveforms from the acoustic representation.
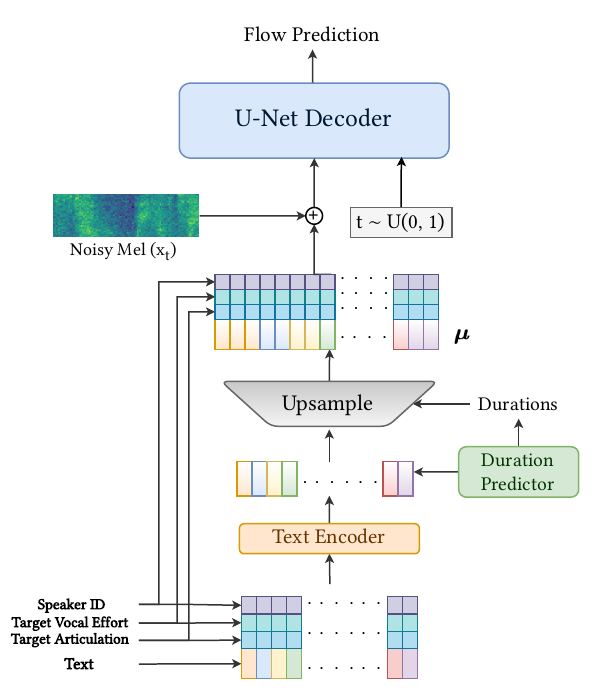
In the figure above, the key design idea is that style information is injected at two places: the text encoder side, to influence durations and temporal structure, and the decoder side, to influence acoustic realization. This dual injection is what enables the model to affect both temporal properties such as speaking rate and phoneme duration, and spectral-prosodic properties such as energy and spectral tilt.
Dual-axis style representation and conditioning
The paper uses the predefined style classes from the Expresso dataset to construct pseudo-labels for two style dimensions:
- Articulation, modeled along the fast–enunciated axis.
- Vocal effort, modeled along the default–projected axis.
Concretely, the style classes are treated as follows: fast corresponds to low articulation, neutral/default to mid articulation and baseline effort, enunciated to high articulation, and projected to high vocal effort. The paper maps each discrete label into a 32-dimensional continuous embedding space using learnable linear projection layers. The articulation and vocal-effort embeddings are concatenated into a joint style embedding. Speaker identity is represented by a separate discrete embedding of the same dimensionality and concatenated with the style embedding.
This factorized representation is intended to support three kinds of control:
- Independent control of articulation and vocal effort.
- Joint control where both dimensions are increased or decreased together.
- Localized control where different words or segments receive different articulation settings.
The embeddings are temporally broadcast across text tokens for the encoder and across mel frames for the decoder. This repeated conditioning allows the style signal to influence generation throughout the utterance, rather than being compressed into a single global token.
The paper emphasizes that the conditioning is deliberately reference-free: at inference time, the user can directly specify the desired vocal-effort and articulation levels without requiring a reference audio sample.
Inference-time control formulation
At inference, the two style dimensions are controlled with continuous scalars $\alpha$ and $\beta$, both in $[0, 1]$. Here, $\alpha$ controls vocal effort and $\beta$ controls articulation. The model interpolates within the learned embedding spaces, which lets it synthesize a continuum of styles rather than only a small set of discrete speaking modes.
The authors stress two practical consequences of this design. First, it supports smooth transitions between neutral and clear speech, which is important for conversational systems that need to adapt gradually to changing noise conditions. Second, it lets the user tune the two axes separately: articulation can be increased without necessarily increasing vocal effort, and vice versa.
For word-level control, the paper allows different $\beta$ values across the time axis. In other words, selected words can be assigned a larger articulation value than neighboring words, enabling targeted emphasis and local intelligibility repair.
Training data and pseudo-labels
The model is trained on a subset of Expresso containing the default, enunciated, fast, and projected speaking styles. This subset comprises approximately 11 hours of speech from four speakers (two female and two male). Because this amount of style-diverse data is limited for robust phonetic coverage, the authors augment training with LJ Speech, which is treated as a neutral speaker with mid-level articulation and baseline vocal effort.
The paper assigns the following pseudo-labels:
| Control dimension | Label | Value |
|---|---|---|
| Articulation | fast | 0.1 |
| Articulation | neutral | 0.5 |
| Articulation | enunciated | 0.9 |
| Vocal effort | neutral | 0.3 |
| Vocal effort | projected | 0.9 |
These pseudo-labels are the mechanism through which the authors create a continuous control space from a small number of observed style classes. The paper does not report a separate supervised classifier; rather, it uses the style labels as conditioning signals for the TTS model.
Evaluation protocol
The main objective evaluation uses the Harvard Sentences dataset, which is phonetically balanced and therefore appropriate for analyzing articulation and intelligibility. The first five lists, corresponding to 50 sentences per speaker, are synthesized under varying articulation $\beta$ and vocal-effort $\alpha$ settings.
To isolate the benefit of learned control, the paper compares against a naive signal-processing baseline. In this baseline, vocal effort is approximated by RMS matching between neutral and higher-effort samples, and speaking-rate reduction is approximated by linear time-stretching. The paper’s discussion uses this baseline to show that simple amplitude and rate manipulations do not reproduce the full intelligibility gains of learned Lombard synthesis.
The reported objective metrics are:
- Word Error Rate ($\mathrm{WER}$), computed using Whisper-medium as a proxy for intelligibility.
- Spectral tilt, defined as the ratio of spectral energy between 5 kHz and 1 kHz to the energy below 1 kHz; higher values indicate a shift toward higher-frequency energy.
- Mean vowel dispersion ($\mathrm{MVD}$), defined as the Euclidean distance of /i/, /a/, and /u/ formants to the vowel centroid in $F_1$-$F_2$ space.
- Phoneme rate, measured as phonemes per second.
- Speech Intelligibility Index ($\mathrm{SII}$), reported as the percentage of speech information audible to a listener under noise.
The paper also includes a human study. A comparative Mean Opinion Score style test was run with 10 participants, who answered 9 naturalness questions and 18 intelligibility questions. The ratings used a $[-3, +3]$ scale, where negative values favored the baseline and positive values favored the authors’ method. For intelligibility, participants compared neutral speech with Lombard-style speech under noisy conditions, and they were not told which sample corresponded to which condition.
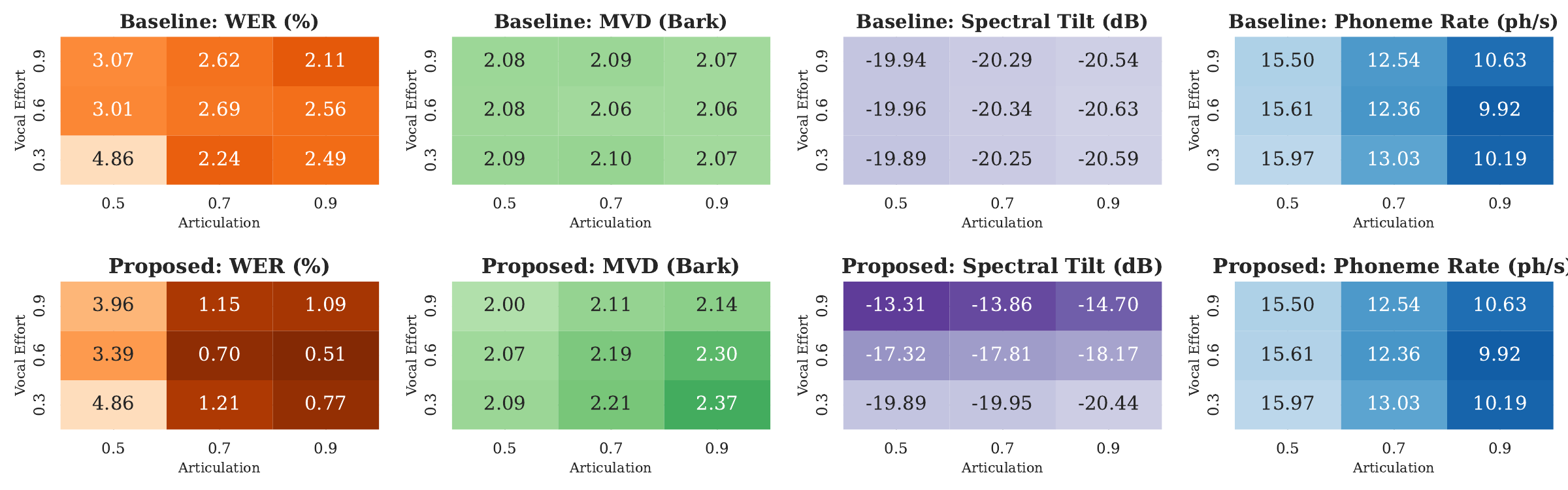
Objective results: clarity, spectral shift, and speaking-rate changes
The paper’s main objective analysis compares the proposed multi-dimensional control system against the naive baseline across $\mathrm{WER}$, $\mathrm{MVD}$, spectral tilt, and phoneme rate. The corresponding figure shows the trends across different vocal-effort $\alpha$ and articulation $\beta$ settings.
The reported qualitative findings are as follows:
- Increasing articulation consistently reduces $\mathrm{WER}$, showing that hyper-articulation improves intelligibility.
- The naive baseline achieves only marginal $\mathrm{WER}$ gains, indicating that slowing speech with linear time-stretching is not enough to produce the benefits of learned clear speech.
- Mean vowel dispersion increases with $\beta$, which matches the intuition that hyper-articulated speech separates vowel formants more strongly.
- Across the vocal-effort axis, $\mathrm{MVD}$ remains relatively stable, supporting the paper’s claim that articulation and effort are at least partially disentangled.
- Spectral tilt changes most strongly with $\alpha$, reflecting the redistribution of energy toward higher frequencies under greater vocal effort.
- The baseline, which uses RMS gain, does not create the same frequency-dependent spectral change because it amplifies energy more uniformly.
The authors note one important caveat: at very high vocal effort, specifically around $\alpha = 0.9$, performance can drop slightly because ASR systems become sensitive to distribution mismatch. The paper interprets this as an evaluation artifact rather than a failure of the synthesis model itself.
Speech-in-noise experiments
The paper evaluates intelligibility under clean and noisy conditions using three signal-to-noise ratios: $10$, $5$, and $1$ dB. Three noise types are used: restaurant babble, overlapping speech, and white noise. Noise is mixed so that all styles are compared at fixed RMS-normalized SNR, ensuring that performance differences arise from the synthesized speaking style rather than trivial loudness changes.
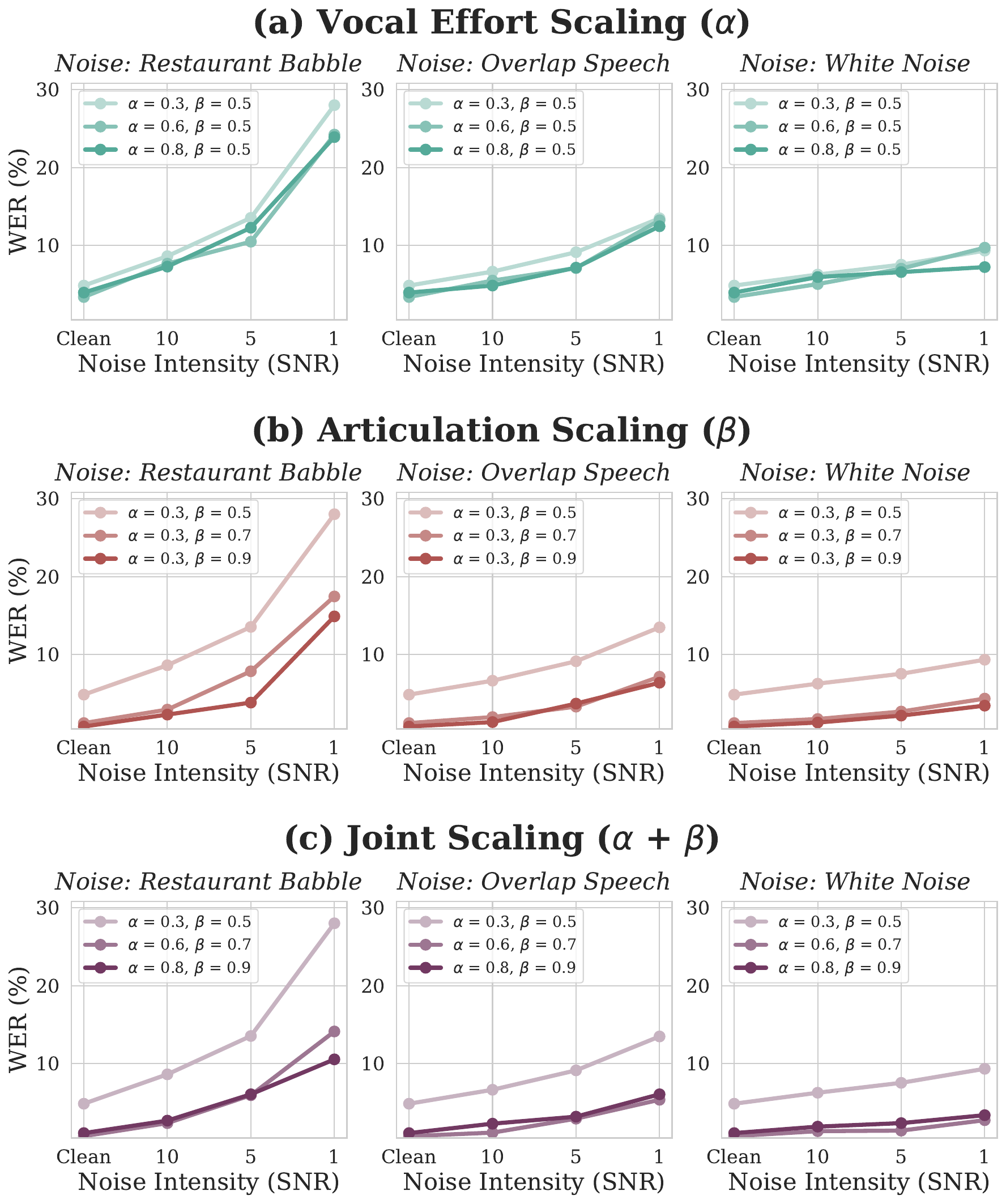
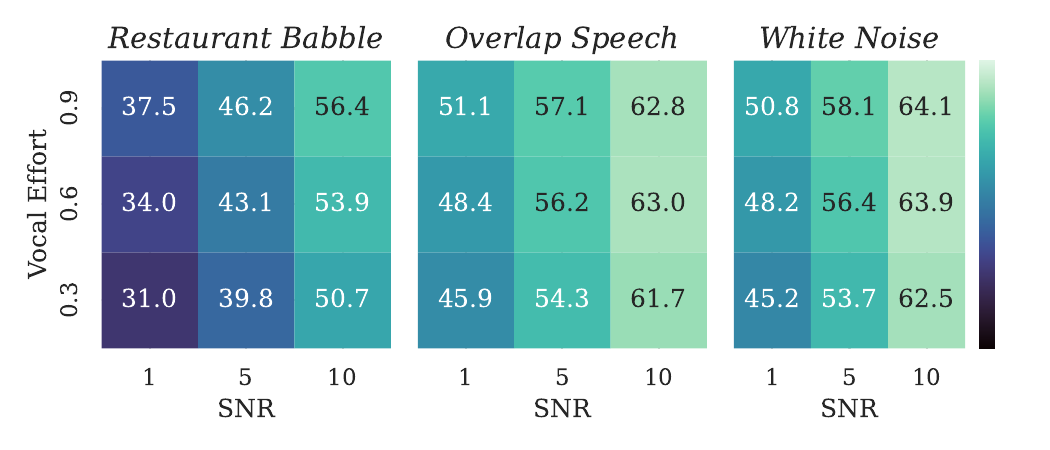
The reported trends are consistent with the paper’s interpretation of the two style axes:
- Articulation reduces $\mathrm{WER}$ across noise types, with especially strong gains in mid-level noise.
- The benefit of articulation tends to saturate at higher control values.
- Vocal effort provides smaller $\mathrm{WER}$ gains when evaluated under RMS-normalized conditions, because its main effect is spectral redistribution rather than raw amplitude increase.
- Nevertheless, vocal effort still improves intelligibility in more difficult settings, especially in restaurant babble and white noise.
- $\mathrm{SII}$ increases with vocal effort across noise types, showing that effort mainly helps audibility.
- The strongest overall gains under severe noise come from jointly increasing articulation and vocal effort, especially at $1$ dB SNR and in restaurant babble.
The authors’ interpretation is that articulation and vocal effort are complementary rather than redundant. Articulation improves phonetic distinctiveness, while vocal effort improves spectral audibility under energetic masking. That complementarity is the main justification for the paper’s dual-axis control design.
Human evaluation
The human study is reported as a comparative CMOS-style evaluation. The authors state that participants preferred the synthesized Lombard-style speech over the baseline in both naturalness and intelligibility. The numeric results are summarized below.
| Task | CMOS on $[-3, +3]$ |
|---|---|
| Naturalness | $1.97 \pm 0.32$ |
| Intelligibility | $1.13 \pm 0.24$ |
The paper’s discussion highlights a notable qualitative result: simple time-stretched speech is judged unnatural, which supports the claim that Lombard synthesis requires more than just slower timing. The human ratings are used to reinforce the objective finding that learned clear-speech control yields more perceptually convincing speech than a naive signal-processing baseline.
Word-level emphasis and targeted intelligibility repair
A distinguishing feature of this paper is word-level control. Rather than only controlling the whole utterance, the model can increase articulation for selected words while keeping surrounding words near baseline. The paper implements this by assigning a higher articulation index to the emphasized word and a lower articulation index to neighboring tokens, so that the target region stands out perceptually.
The paper’s specific setup uses $\beta = 1.5$ for the emphasized word and $\beta = 0.1$ for surrounding tokens. This creates a local articulation peak while preserving near-baseline rhythm outside the target region. The authors also note that emphasis labels add acoustic stress to the emphasized words.
They further report that the baseline phoneme rate is about 15.8 ph/s, while the emphasized word is slowed to about 10.5 ph/s, showing that the effect is localized rather than global.
To evaluate this capability, the authors first identify sentences where neutral baseline synthesis is recognized incorrectly by ASR, then resynthesize those cases with increased articulation. They compare four conditions: neutral baseline, hyper-articulation only, emphasis only, and both combined.
| Condition | WER (%) |
|---|---|
| Baseline (neutral) | 17.61 |
| Hyper-articulation only | 6.81 |
| Emphasis only | 9.15 |
| Both combined | 3.90 |
These results show that hyper-articulation is more effective than emphasis alone, but the combination of both produces the largest intelligibility gain. The paper uses this experiment to support its broader claim that the model can perform localized repair for specific difficult words, not just global style conversion.
Contributions and interpretation
The paper’s contributions can be summarized as follows:
- A dual-axis conditioning framework for independent and joint control of vocal effort and articulation.
- A factorized injection strategy that conditions both duration prediction and acoustic decoding.
- Multi-level control spanning utterance-wide style changes and word-level emphasis.
- Evidence that articulation and vocal effort contribute differently to Lombard speech: articulation primarily improves intelligibility, while vocal effort mainly improves spectral clarity and audibility.
- Demonstration that the system can reproduce clear-speech gains in noise better than naive rate-and-amplitude manipulation.
Conceptually, the paper frames Lombard synthesis as a control problem over interacting speech attributes. A single global style value is insufficient because the relevant perceptual effects are distributed across time and frequency. By disentangling the axes, the model can be steered toward clearer speech in a more interpretable way, and the experiments suggest that this leads to better performance under both clean and noisy conditions.
Limitations and future work
The authors explicitly mention two limitations. First, the evaluation relies heavily on ASR-based intelligibility, which may underestimate the benefit of extreme vocal effort because ASR systems are sensitive to distribution mismatch. Second, token-level control can leak into neighboring words, so the localized emphasis mechanism could be refined further.
The paper proposes several directions for future work: more robust evaluation metrics, improved fine-grained control to reduce leakage, and real-time adaptation to changing acoustic conditions. The overall conclusion is that the presented system is a practical step toward context-aware TTS that can produce human-like Lombard strategies on demand.