FlowTTS-GRPO
FlowTTS-GRPO: Online Reinforcement Learning with Multi-Objective Reward Optimization for Flow-Matching Based Text-to-Speech
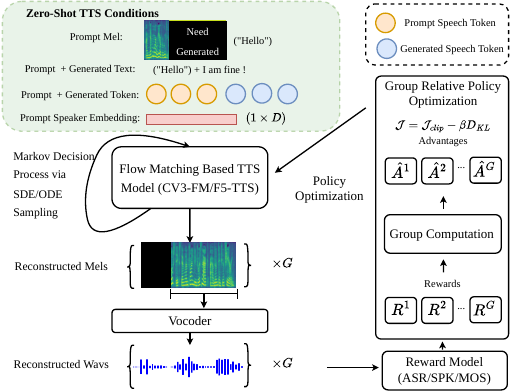
FlowTTS-GRPO uses online reinforcement learning to fine-tune flow-matching TTS models with multi-objective rewards for speaker similarity, quality, and intelligibility. It enables exploration via stochastic sampling without auxiliary models, improving voice cloning and cross-lingual transfer.
Links
Paper & demos
Abstract
Existing Reinforcement Learning (RL) research for Text-to-Speech (TTS) focuses on large language models (LLMs), leaving Flow-Matching (FM) under-explored. We present FlowTTS-GRPO, an online RL framework for FM-based TTS. By converting ordinary differential equation (ODE) trajectories into stochastic differential equation (SDE) paths, our method enables direct fine-tuning of open-source FM models without auxiliary models. We show that a weighted reward combination converges faster than a probabilistic scheme, and identify three practical optimizations: omitting classifier-free guidance (CFG) during training accelerates convergence; synthesizing hard cases improves robustness; and applying RL to the FM component enhances audio-detail metrics. Experiments on CosyVoice 3.0 and F5-TTS demonstrate objective and subjective preference gains in speaker similarity and perceptual quality, with F5-TTS also improving intelligibility.
1. Problem Setting and Core Idea
This paper studies online reinforcement learning for flow-matching-based text-to-speech (TTS), a setting that has been much less explored than RL for LLM-based TTS. The motivation is that modern hybrid TTS systems can produce high-quality speech, yet their outputs are not always aligned with human preferences for speaker similarity, perceptual quality, and, where applicable, intelligibility. The authors argue that the FM component in LLM+FM systems is a natural place to improve acoustic detail and perceptual quality, while the LM component more strongly governs linguistic correctness.
Their method, FlowTTS-GRPO, adapts Group Relative Policy Optimization to FM-based TTS by converting the deterministic FM sampling path from an ODE into a stochastic reverse-time SDE. This provides the exploration needed for RL without training a separate stochastic generator. The paper’s central claim is that this makes it possible to directly fine-tune open-source FM TTS models using reward signals computed on the synthesized audio, while avoiding auxiliary value networks, preference datasets, or token-to-reward models.
2. Models, Post-Training Scope, and Inference Setup
The paper fine-tunes two pretrained TTS systems:
- CosyVoice 3.0 (CV3), a hybrid model with a speech tokenizer, an LM, an FM acoustic model, and a vocoder.
- F5-TTS, an FM-only TTS model with an FM acoustic model and a vocoder.
The RL training objective is applied only to the FM component in both systems. For CosyVoice 3.0, the speech tokenizer, LM, and vocoder are frozen; for F5-TTS, the vocoder is frozen and only the FM is updated. The RL sample construction follows the actual inference pipeline: a training utterance is used as the prompt waveform and prompt text, a new target text is sampled, the model generates a speech output, and the resulting prompt/generated pair becomes the RL training sample.
This design matters because the paper is not training a synthetic proxy model on abstract token sequences; instead it fine-tunes the same component that is used at inference, which the authors frame as a more direct form of preference alignment for zero-shot voice cloning.
3. Formal RL Formulation
The FM decoder is cast as a Markov decision process with state $s_t = (c, t, x_t)$, where $c$ is the conditioning information such as text and speaker-related context, and $x_t$ is the latent at time $t$. The action is the predicted velocity $a_t = v_t = \phi_\theta(x_t, c)$. The latent evolves by a deterministic Euler update in the underlying FM sampler:
$$x_{t+\Delta t} = x_t + v_t\,\Delta t.$$
The terminal reward is assigned at the final time step $t=1$ as $r(x_1, c)$, while intermediate steps receive zero reward. To make policy optimization feasible, the paper introduces stochasticity by rewriting the ODE sampler as a reverse-time SDE. In the paper’s notation, the mean update becomes
$$x_{t,\mathrm{mean}} = x_t + \Big[v_\theta(x_t,t) + \frac{\sigma_t^2}{2(1-t)}\big(-x_t + t\,v_\theta(x_t,t)\big)\Big]\Delta t,$$
with added Gaussian noise $\epsilon \sim \mathcal{N}(0,\mathbf{I})$ and noise schedule $\sigma_t = a\sqrt{\frac{1-t}{t}}$, where $a$ is a hyperparameter controlling exploration. The actual sampled step is
$$x_{t+\Delta t} = x_{t,\mathrm{mean}} + \sigma_t\sqrt{\Delta t}\,\epsilon.$$
In practice, the authors use window training: only a subset of early denoising steps is made stochastic and optimized, while the remaining steps stay deterministic. This reduces training burden and accelerates convergence.
3.1 GRPO objective
For each prompt, the model samples a group of $G$ candidate outputs under the mixed ODE–SDE procedure. GRPO computes an intra-group advantage by normalizing each candidate’s reward against the group mean and standard deviation:
$$\hat A^i_t = \frac{R(\hat x_1^i,c) - \mathrm{mean}(\{R(\hat x_1^i,c)\}_{i=1}^G)}{\mathrm{std}(\{R(\hat x_1^i,c)\}_{i=1}^G)}.$$
The policy is updated with a clipped ratio objective plus a KL penalty to a reference policy. Conceptually, trajectories that receive higher terminal rewards are assigned higher probability under the updated velocity field. The paper emphasizes that this lets the model be optimized directly with off-the-shelf reward models rather than through preference pairs or a separately learned reward predictor.
4. Reward Design
The reward function is multi-objective and explicitly targets the dimensions that matter in zero-shot TTS:
- Speaker similarity reward $R_{\mathrm{SS}}$: cosine similarity between speaker embeddings extracted from the generated and reference waveforms using ERes2Net, mapped to $[0,1]$.
- ASR-based reward $R_{\mathrm{ASR}}$: for Chinese, $1-\mathrm{CER}$ using Paraformer; for English, $1-\mathrm{WER}$ using Whisper-v3.
- Perceptual quality reward $R_{\mathrm{MOS}}$: the P.835 DNSMOS OVRL score, computed after resampling waveforms to 16 kHz.
A key design choice is how to combine these signals. The paper observes reward conflicts and reward-scale mismatch, so it evaluates two fusion strategies:
- Probabilistic combination: each prompt is assigned to only one reward type, and the other rewards are zeroed out for that group.
- Weighted combination: each reward is normalized by its batch standard deviation and then combined with weights:
$$R = \lambda_1 \frac{R_{\mathrm{SS}}}{\mathrm{std}(R_{\mathrm{SS}})} + \lambda_2 \frac{R_{\mathrm{ASR}}}{\mathrm{std}(R_{\mathrm{ASR}})} + \lambda_3 \frac{R_{\mathrm{MOS}}}{\mathrm{std}(R_{\mathrm{MOS}})}.$$
The authors find that weighted combination with standard-deviation normalization converges faster and more stably than probabilistic assignment, because the reward variances are not naturally aligned.
5. Hard-Case Synthesis for Robustness
To improve robustness on difficult utterances, the paper adds a hard-case training set built from heuristic text augmentation on WenetSpeech4TTS. The authors create Chinese sentences that mimic common failure modes in TTS by applying three transformations: local word repetition, sparse multi-word repetition, and global sentence repetition. The purpose is to stress the model on repeated-text patterns and long-form stability issues similar to the HardZh subset in Seed-TTS-Eval.
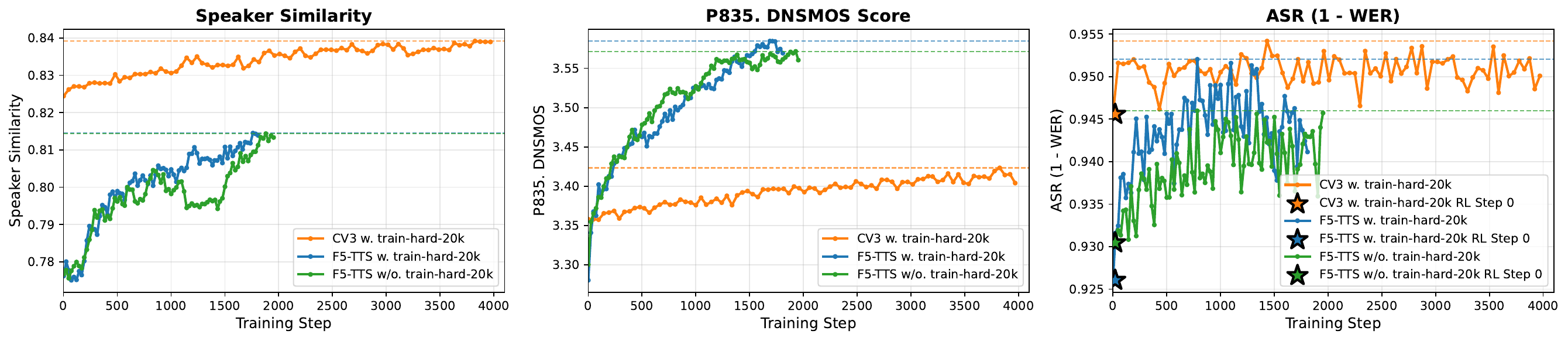
The main empirical finding is architecture-dependent: for CV3, adding hard cases brings only limited intelligibility benefit, which the paper interprets as evidence that semantics are primarily LM-driven in the hybrid architecture. For F5-TTS, however, hard cases help ASR reward growth and improve robustness more clearly, so the authors use both easy and hard training sets for that model.
6. Training and Evaluation Protocol
6.1 Data
Training uses WenetSpeech4TTS Premium for Chinese and LibriTTS-960 for English. The authors construct a balanced easy set of 40k samples, named train-easy-40k, with 20k Chinese and 20k English examples. They also construct an additional train-hard-20k Chinese hard-case set.
Validation uses two 200-utterance sets: dev-easy, sampled from Seed-TTS-Eval Chinese and English test data, and dev-hard, sampled from the repeated-text hard subset.
Evaluation is performed on Seed-TTS-Eval and CV3-Eval. Seed-TTS-Eval includes Chinese test-zh, English test-en, and a hard test-hard split. CV3-Eval is the multilingual voice-cloning subset with nine languages, plus extra hard-case test sets for Chinese and English.
6.2 Optimization details
The implementation uses LoRA for both FM models. For CV3, the LoRA rank is 32 with $\alpha=64$, corresponding to 10.09M trainable parameters or 2.78% of the FM model. The learning rate is $10^{-4}$ with linear decay to zero at 10k steps. Each iteration samples 16 prompt waveforms, generates 8 samples per prompt, discards groups with zero standard deviation, and performs 8 parameter updates per iteration. Training uses a 2-step denoising window with no CFG during training; inference uses 10 denoising steps.
For F5-TTS, LoRA is also rank 32 with $\alpha=64$, again about 10.09M trainable parameters or 2.80% of the FM model. The learning rate is $5\times10^{-5}$ with linear decay to zero at 10k steps. Each iteration samples 6 prompt waveforms, generates 10 samples per prompt, and also performs 8 updates per iteration. Training uses a 2-step denoising window without CFG; inference uses 16 denoising steps.
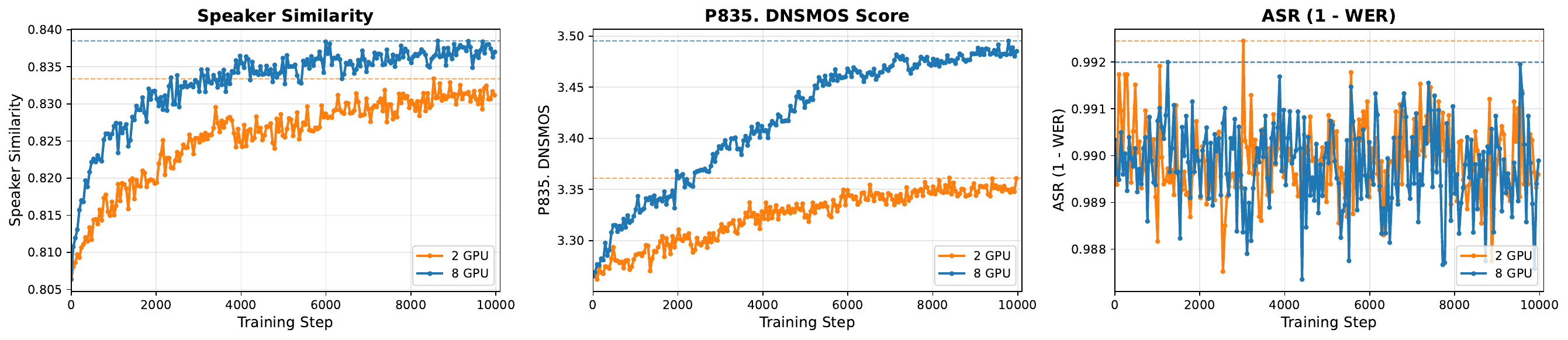
The paper notes that CV3 training is run with the 0.5B LM front-end used to pre-decode prompt and generated tokens, while F5-TTS is fine-tuned directly. All main runs use 8 GPUs, and the ablation section explicitly shows that more GPUs speed up reward growth by increasing the number of samples per update.
7. Main Results on Seed-TTS-Eval
The main quantitative results show that FlowTTS-GRPO improves speaker similarity and perceptual quality for both F5-TTS and CosyVoice 3.0. The paper also reports that on CV3, the RL-tuned FM reaches a new best speaker-similarity score on Seed-TTS-Eval-zh, surpassing the closed-source Seed-TTS baseline on SS1.
| Model | RL step | test-zh CER | test-zh SS1 | test-zh SS2 | test-en WER | test-en SS1 | test-en SS2 | test-hard CER | test-hard SS1 | test-hard SS2 |
|---|---|---|---|---|---|---|---|---|---|---|
| Human | – | 1.26 | 0.755 | 0.775 | 2.14 | 0.734 | 0.742 | – | – | – |
| F5-TTS | 0 | 1.56 | 0.741 | 0.794 | 1.83 | 0.647 | 0.742 | 8.67 | 0.713 | 0.762 |
| F5-TTS + FM-GRPO | 1289 | 1.55 | 0.777 | 0.827 | 1.73 | 0.705 | 0.790 | 7.86 | 0.741 | 0.791 |
| CosyVoice 3.0-0.5B-2512 | 0 | 1.20 | 0.777 | 0.830 | 2.42 | 0.701 | 0.770 | 7.32 | 0.757 | 0.808 |
| CosyVoice 3.0-0.5B-2512 + FM-GRPO | 9545 | 1.26 | 0.804 | 0.859 | 2.49 | 0.743 | 0.818 | 7.08 | 0.792 | 0.844 |
| CosyVoice 3.0-0.5B-2512 + LM w. RL | 0 | 0.87 | 0.776 | 0.831 | 1.70 | 0.693 | 0.770 | 6.01 | 0.756 | 0.803 |
| CosyVoice 3.0-0.5B-2512 + LM w. RL + FM-GRPO | 9545 | 0.85 | 0.803 | 0.858 | 1.83 | 0.737 | 0.817 | 5.89 | 0.790 | 0.841 |
The authors’ interpretation of these results is important:
- Speaker similarity improves strongly even though only the FM component is updated, including SS1, which is not a direct optimization target. They emphasize this as evidence against reward hacking.
- Perceptual quality improves through P.835/P.808 gains, matching the intuition that FM is especially responsible for acoustic detail.
- Intelligibility gains are limited for CV3 because the LM dominates semantics in the hybrid pipeline, whereas F5-TTS, which is FM-only, also improves intelligibility more noticeably.
8. Generalization on CV3-Eval
The CV3-Eval experiments test multilingual voice cloning across nine languages. The paper’s main conclusion here is that FlowTTS-GRPO trained only on Chinese and English transfers surprisingly well to other languages, improving speaker similarity and perceptual metrics even in languages not seen in RL training. At the same time, the results reinforce the architectural split observed earlier: for LLM-FM systems, FM RL is better at improving timbre and audio detail than at large intelligibility gains.
| Model | Step | Metric | zh | en | hard-zh | hard-en | ja | ko | de | es | fr | it | ru |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F5-TTS | 0 | CER | 7.66 | 11.10 | 22.11 | 36.23 | – | – | – | – | – | – | – |
| F5-TTS + FM-GRPO | 1289 | CER | 5.44 | 7.07 | 17.46 | 25.63 | – | – | – | – | – | – | – |
| CV3 | 0 | CER | 3.72 | 5.09 | 9.04 | 8.11 | 6.54 | 5.92 | 6.48 | 3.58 | 10.66 | 5.43 | 7.84 |
| CV3 + FM-GRPO | 9545 | CER | 3.83 | 5.09 | 9.38 | 7.93 | 6.72 | 5.85 | 6.79 | 3.64 | 11.69 | 5.74 | 8.29 |
| CV3-LM-RL | 0 | CER | 3.26 | 4.10 | 8.39 | 7.30 | 5.77 | 6.28 | 4.72 | 3.15 | 8.63 | 3.36 | 4.39 |
| CV3-LM-RL + FM-GRPO | 9545 | CER | 3.28 | 4.31 | 8.26 | 7.29 | 5.91 | 6.10 | 4.69 | 3.40 | 8.52 | 3.75 | 4.67 |
| F5-TTS | 0 | SS1 | 0.729 | 0.605 | 0.688 | 0.559 | – | – | – | – | – | – | – |
| F5-TTS + FM-GRPO | 1289 | SS1 | 0.760 | 0.665 | 0.718 | 0.627 | – | – | – | – | – | – | – |
| CV3 | 0 | SS2 | 0.804 | 0.745 | 0.780 | 0.747 | 0.777 | 0.800 | 0.785 | 0.796 | 0.772 | 0.772 | 0.775 |
| CV3 + FM-GRPO | 9545 | SS2 | 0.836 | 0.798 | 0.817 | 0.804 | 0.816 | 0.834 | 0.827 | 0.838 | 0.816 | 0.820 | 0.820 |
Across this table, the improvement pattern is consistent in similarity and quality metrics. The authors highlight that even though training is limited to Chinese and English, the FM-tuned model transfers to the multilingual voice-cloning subset, suggesting that the learned acoustic refinement is not language-specific. In several cases, however, CER does not improve and can even worsen slightly for CV3, which the paper uses to support the claim that FM RL is not the main lever for intelligibility in hybrid systems.
9. Ablation Findings
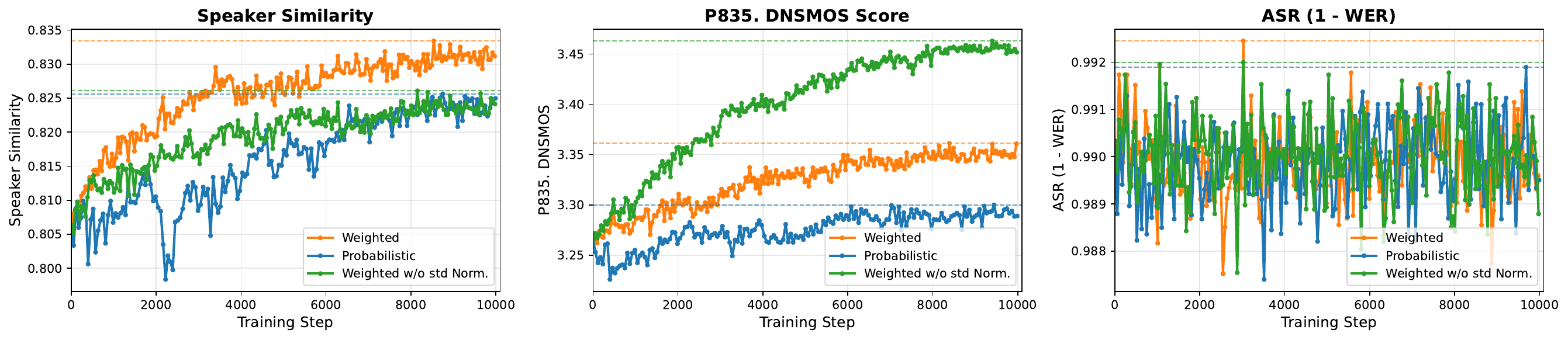
9.1 Weighted reward fusion versus probabilistic assignment
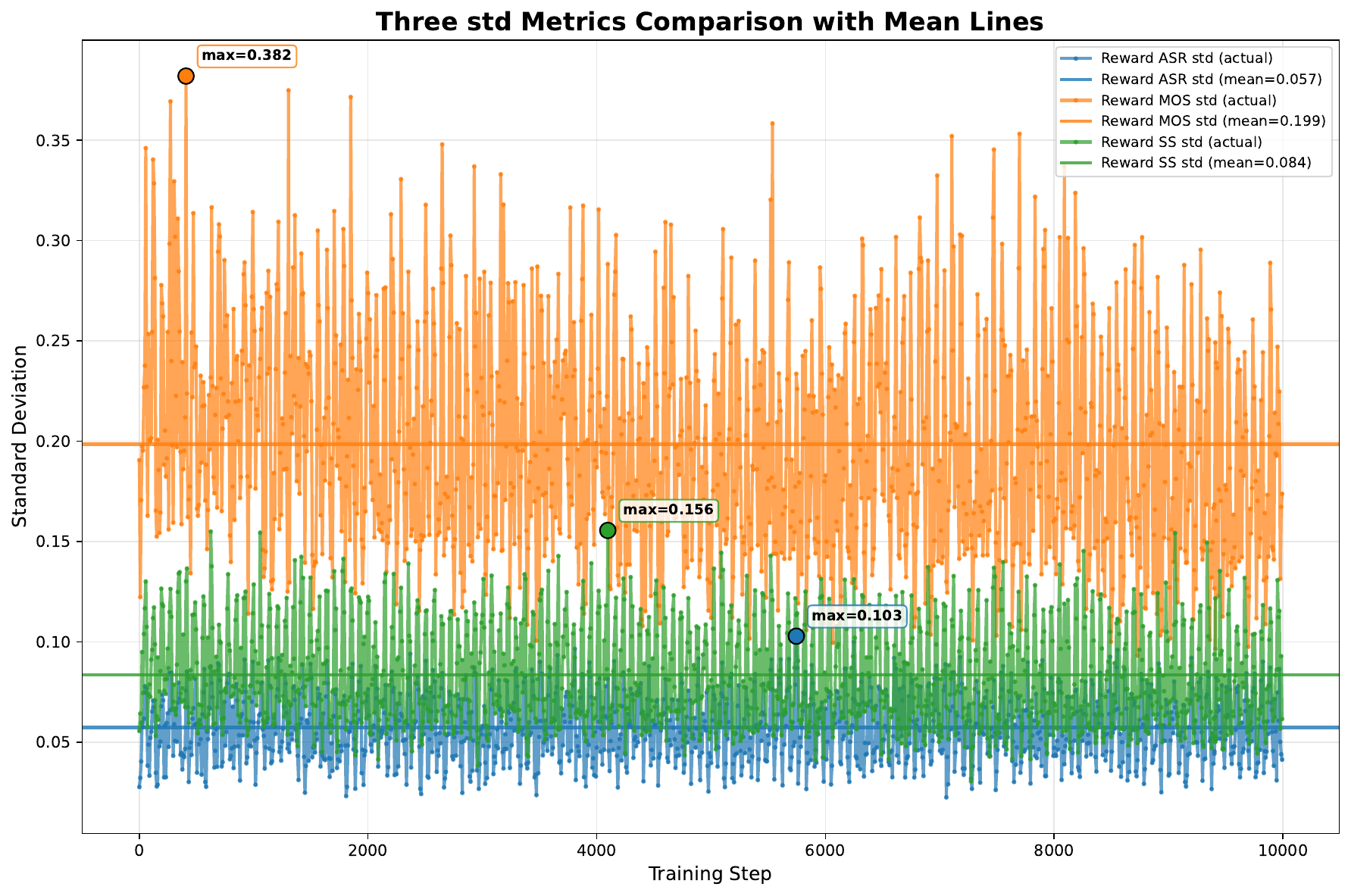
The paper’s ablation on reward fusion shows that probabilistic per-prompt assignment leads to early oscillations because each mini-group can be driven by a different objective. Weighted combination is both faster and more stable. Standard-deviation normalization is critical: without it, the natural variance of each reward would distort the intended weights and make the effective reward contributions hard to control.
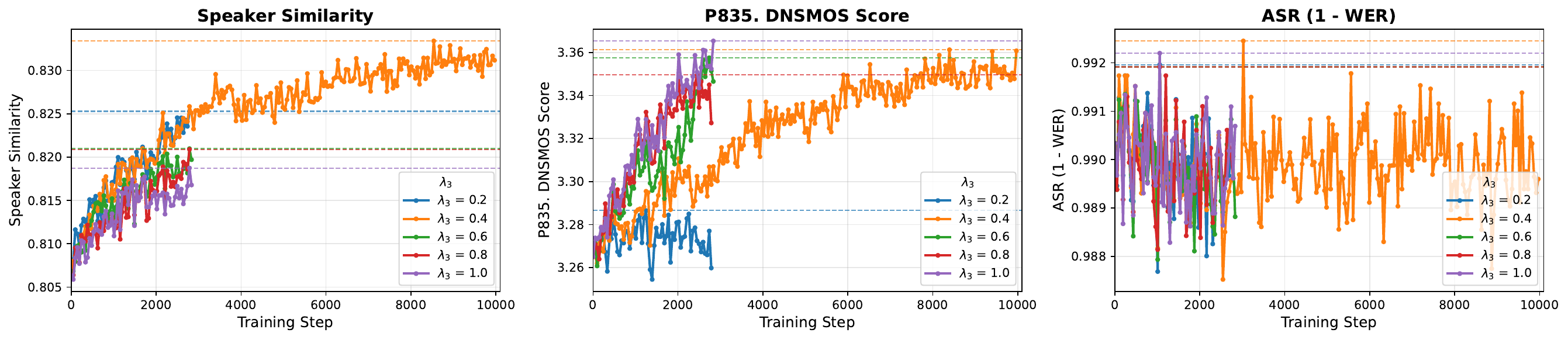
The authors also vary the DNSMOS weight $\lambda_3$. Increasing $\lambda_3$ from 0.2 to 1.0 speeds up DNSMOS gains but slows speaker-similarity growth, showing an explicit trade-off between perceptual quality and timbre preservation. The chosen setting is $\lambda_1 = \lambda_2 = 1.0$ and $\lambda_3 = 0.4$, which the paper presents as a balanced compromise.
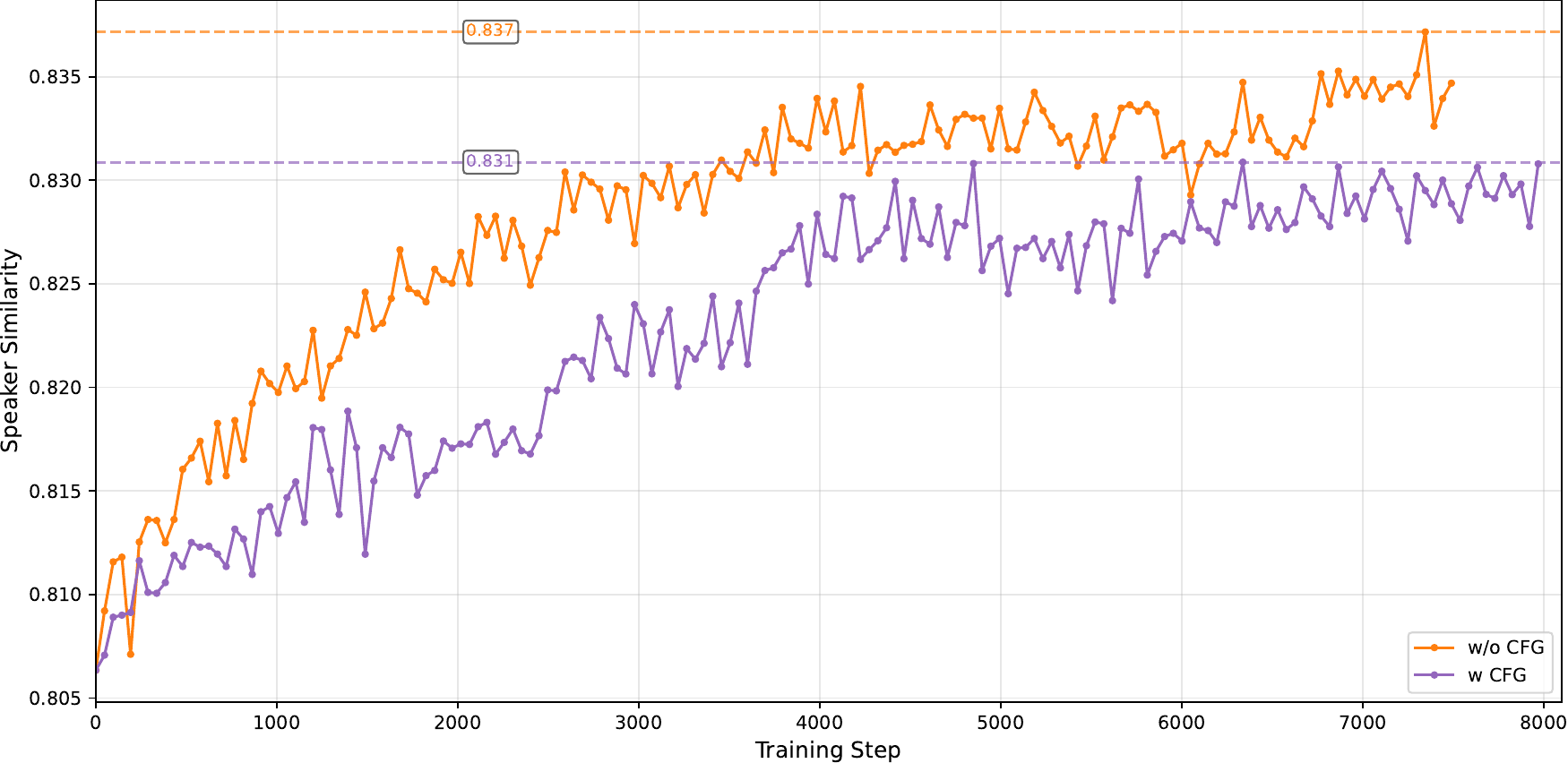
9.2 Omitting classifier-free guidance during training
Another ablation shows that removing CFG during RL training improves exploration and leads to faster reward growth. The key observation is that the model can still be trained effectively on the conditional velocity field, even when CFG is used later during inference. The authors therefore omit CFG in training for convergence speed.
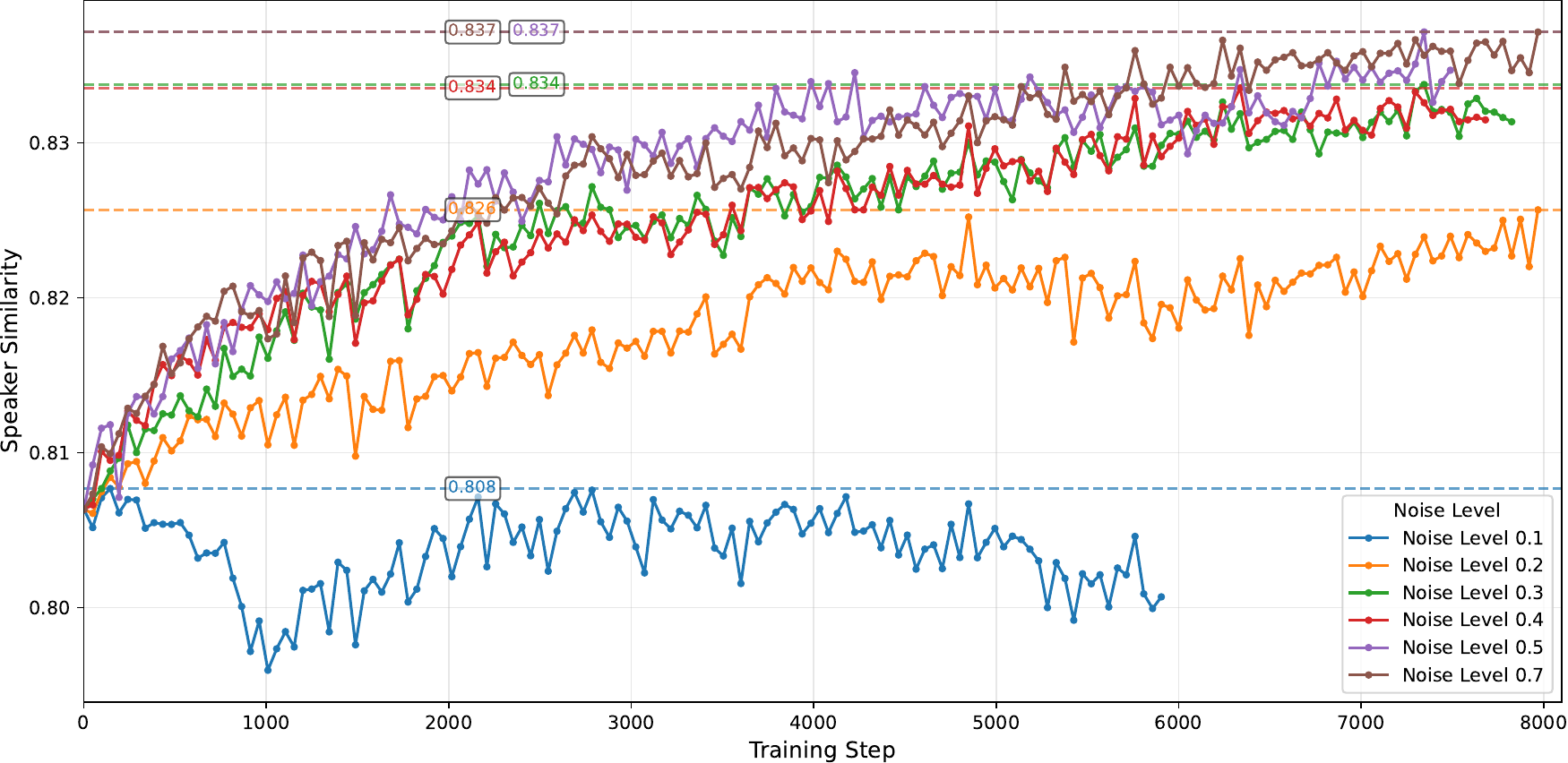
9.3 Noise level
The noise level hyperparameter also matters. Lower noise values can cause oscillatory or weak learning, while higher noise levels expand the exploration range. The paper reports that $\text{noise\_level}=0.5$ reaches the saturation point and is selected because it balances exploration and training stability.
9.4 GPU scaling
The GPU-scaling figure shows that a larger number of GPUs increases the sample throughput per update and speeds reward growth. The paper interprets this as evidence that RL training benefits from larger per-update groups and higher data throughput, not just more optimization steps.
10. Subjective Evaluation
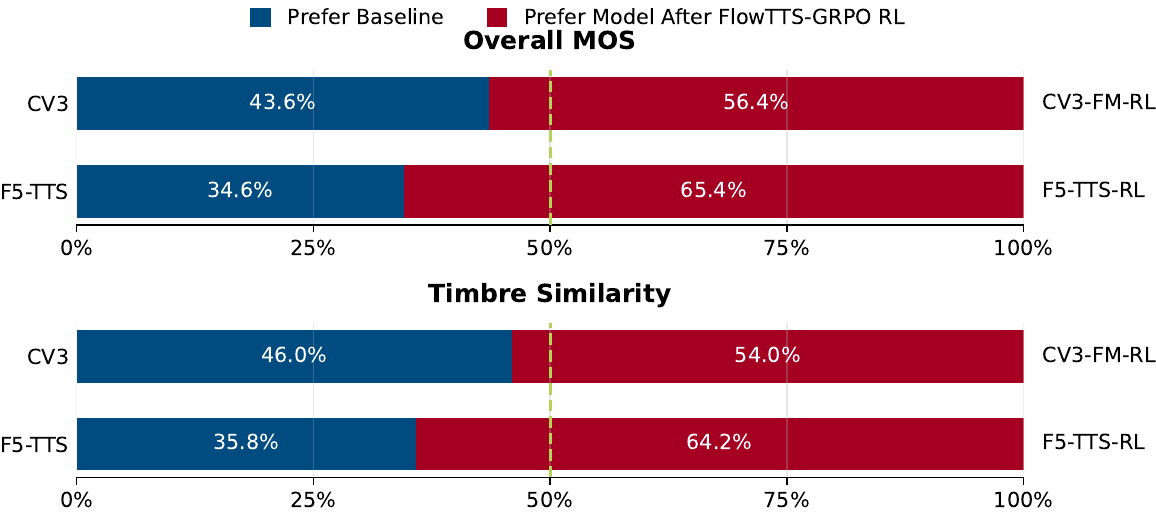
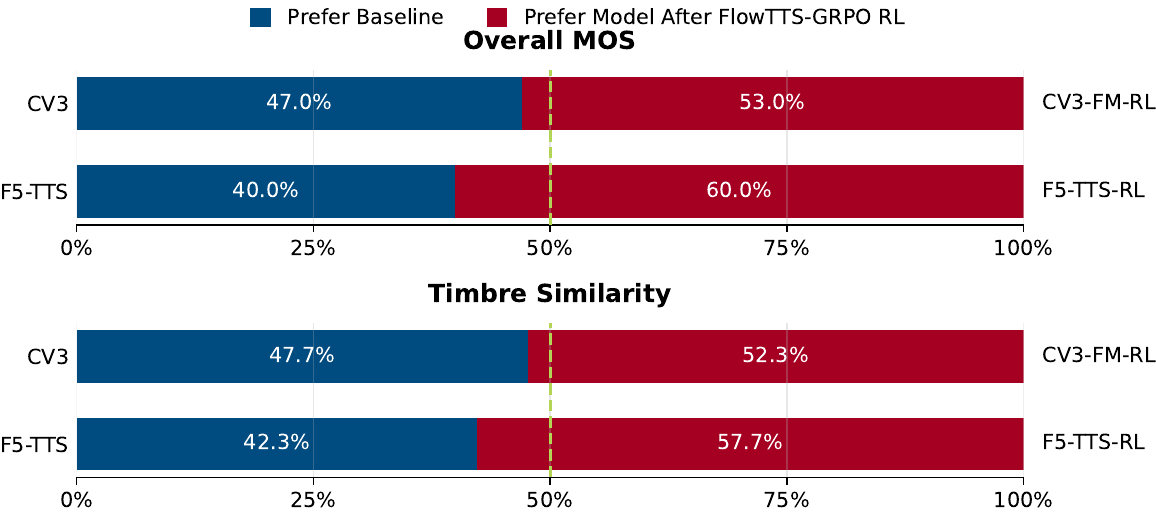
To check whether objective gains translate into human perception, the authors run A/B preference tests on English and Chinese subjective evaluation sets. They sample 30 utterances per language and recruit 10 native speakers to compare baseline outputs against FlowTTS-GRPO outputs.
The reported outcome is that the RL-finetuned models are consistently preferred over their baselines on both language sets, with the strongest gains in overall naturalness and timbre similarity. The paper uses this to argue that the proxy rewards are aligned with human judgments rather than merely exploiting the reward models.
11. What the Paper Claims as the Main Contributions
- The first application of Flow-GRPO-style online RL to TTS.
- A direct way to fine-tune open-source FM-based TTS models by converting ODE trajectories into stochastic SDE paths.
- A simplified RL setup that avoids auxiliary value networks, preference pairs, and token-to-reward models.
- Evidence that weighted multi-objective reward fusion with std normalization is better behaved than probabilistic reward assignment.
- Three practical training findings: omitting CFG helps convergence, hard-case synthesis improves robustness, and RL on FM mainly improves acoustic detail while LM RL mainly improves intelligibility in hybrid systems.
- Empirical gains on both speaker similarity and perceptual quality, plus improved intelligibility for F5-TTS, along with cross-lingual generalization on CV3-Eval.
12. Limitations and Scope Boundaries Stated by the Paper
- Intelligibility gains are architecture-dependent. For CosyVoice 3.0, the paper repeatedly observes that semantics are largely LM-driven, so FM RL mainly improves audio detail rather than CER/WER.
- Training data is not fully multilingual. The RL training data are Chinese and English; cross-lingual gains on CV3-Eval are a transfer result, and the authors explicitly say they plan to extend to multilingual data in future work.
- Resource cost differs by model. F5-TTS required substantially more training time than CV3-FM, and the authors note that resource limits constrained those runs.
- Reward design still requires manual balancing. Even with std normalization, the relative weights of speaker similarity, ASR, and DNSMOS must be tuned, and the ablation shows explicit trade-offs between them.
- The method depends on external proxy evaluators. The training loop uses off-the-shelf speaker verification, ASR, and DNSMOS models, so the quality of alignment is tied to those reward models and their domains.
13. Bottom-Line Technical Takeaway
The paper’s practical message is that online RL can be made to work for FM-based TTS if the sampler is made stochastic and the reward is carefully structured. In this setup, FM tuning is especially effective for speaker identity and acoustic detail, while the LM is still the main lever for semantic accuracy in hybrid models. The strongest evidence in the paper is that the method improves both objective metrics and human preference, and that the improvements are robust enough to transfer across reward models, languages, and model variants.