Audio-Image Alignment for Low-Resource ASR
Audio--Image Alignment as a Continued-Pretraining Stage Improves Low-Resource ASR
This paper proposes an intermediate pretraining step using audio-image pairs to adapt pretrained audio encoders without transcripts. This stage improves ASR performance in low-resource languages by enhancing representation robustness and transferability before supervised fine-tuning.
Links
Paper & demos
Abstract
Thousands of languages are spoken worldwide, yet many remain under-resourced for Automatic Speech Recognition (ASR) due to the limited availability of high-quality transcribed speech data. Collecting accurate transcriptions is often costly and labor-intensive, particularly for low-resource languages. In this work, we investigate the use of aligned audio-image pairs to adapt pretrained audio encoders without requiring transcription data before supervised fine-tuning. Our proposed representation alignment stage is introduced between large-scale pretraining and supervised ASR fine-tuning. Specifically, image representations extracted from pretrained vision encoders are aligned with audio representations to further adapt a pretrained audio encoder. For this alignment process, we utilize the Vaani dataset, in which images serve as prompts for speech collection, naturally providing paired audio-image data. We evaluate the proposed approach using multiple vision encoders and a pretrained FastConformer audio encoder. Experimental results demonstrate that models fine-tuned after representation alignment consistently achieve improved ASR performance compared to direct fine-tuning. These findings highlight the potential of audio-image representation alignment as an effective transcription-free adaptation strategy for enhancing ASR systems in low-resource language settings.
Overview
This paper studies a simple but nonstandard adaptation stage for low-resource ASR: instead of moving directly from self-supervised audio pretraining to supervised ASR fine-tuning, the authors insert an intermediate audio--image alignment stage. The key idea is to exploit aligned audio--image pairs that are cheaper to obtain than transcriptions, and use them to further adapt a pretrained audio encoder before any text supervision is introduced. The paper’s central claim is that this extra stage improves downstream multilingual ASR, especially in low-resource and cross-domain conditions, even though no new audio is added beyond what the SSL model has already seen.
The work is explicitly framed as continued pretraining rather than multimodal inference. The vision model is only used during the alignment stage to shape the audio encoder; at ASR fine-tuning and evaluation time, the system is audio-only and uses a hybrid CTC-TDT decoder.
Problem setting and motivation
The motivation is the standard low-resource ASR bottleneck: many languages have abundant unlabeled speech but very little high-quality transcription data. Conventional SSL-to-finetuning pipelines use unlabeled audio during pretraining and transcribed speech during fine-tuning, but ignore other low-cost supervision signals. The paper argues that image prompts naturally produce semantically aligned audio--image data in collection settings like Vaani, and that these pairs can act as a transcription-free adaptation signal.
The authors test whether aligning audio representations to image semantics can make the encoder more transferable before supervised ASR training. Their hypothesis is that the alignment stage encourages representations that are more robust and semantically structured, which should help especially when labeled ASR data is scarce.
Three-stage training pipeline
The overall pipeline has three stages:
- Pretraining of a 17-layer FastConformer audio encoder on Vaani speech.
- Audio--image alignment, where the audio encoder is further optimized against frozen image embeddings using aligned audio--image pairs.
- Supervised ASR fine-tuning with a hybrid CTC-TDT decoder and multilingual transcribed speech.
The paper emphasizes that the same pretrained audio encoder checkpoint is used for both the baseline and aligned systems. The baseline omits stage 2; the aligned models include it. This makes the comparison a clean test of whether the intermediate multimodal stage adds value.
Alignment method
During alignment, the image encoder is frozen and its embeddings are precomputed and cached. The audio encoder, by contrast, is fully trainable: all 17 FastConformer blocks are updated. Because the audio and image feature dimensions differ across backbone choices, the method includes an alignment head implemented as an MLP that maps audio representations into the image embedding space or into a token set suitable for late interaction.
The paper evaluates three alignment configurations, summarized below. In all cases, training uses the SigLIP sigmoid contrastive objective with learnable temperature and bias, and in-batch negatives gathered across all GPUs.
Alignment objectives and pair scoring
For the single-vector setup, the pair score is cosine similarity between the projected audio and image embeddings. For the token-based setups, the score is a late-interaction MaxSim-style function. In the paper’s notation, the loss is of the SigLIP form:
$$ \mathcal{L} = -\log \sigma\bigl(y_{ij}(t\,s_{ij} + b)\bigr), $$
where $s_{ij}$ is the audio--image pair score, $t$ is a learnable temperature, $b$ is a learnable bias, and $y_{ij}$ denotes the pair label used by the contrastive objective.
For the multi-token variants, the score is computed with an asymmetric MaxSim rule:
$$ s_{ij} = \frac{1}{K_a} \sum_{a=1}^{K_a} \max_{v \in V_j} \langle q_{i,a}, v \rangle, $$
where $q_{i,a}$ are the audio query vectors, $V_j$ are the image tokens, and $K_a = 16$ for the multi-query variants.
Alignment variants
| Variant | Vision backbone | Image representation | Audio representation | Pair score |
|---|---|---|---|---|
| SigLIP | SigLIP2 base/256 | 1 pooled vector, $D=768$ | 1 pooled audio vector | Cosine similarity |
| SigLIP-MT | SigLIP2 large/384 | 16 top-$K$ patch tokens, $D=1024$ | 16 audio query vectors, $D=1024$ | MaxSim |
| Qwen-MT | Qwen3-VL visual stack | Up to 16 tokens via $2\times2$ spatial merge, $D=2048$ | 16 audio query vectors, $D=2048$ | MaxSim |
Across all three variants, the image encoder is frozen, the audio encoder is trainable, and the alignment stage runs for 200,000 steps. The paper also notes that the image embeddings are cached on disk to avoid recomputation.
Datasets and data splits
The main dataset is Vaani, a multilingual Indic speech corpus collected with picture prompts. The corpus contains approximately 31,255 hours of speech across 105 languages, with 1,894 hours transcribed. The alignment stage uses the picture-prompt structure to obtain naturally paired audio--image examples.
The paper makes an important control point: the 11,848,593 audio--image pairs used for alignment are drawn from the same Vaani pretraining corpus used to train the SSL model, excluding all audio from the evaluation sets. The authors explicitly state that no additional or unseen audio is introduced in alignment, so gains cannot be explained by more speech exposure alone.
Two supervised fine-tuning settings are used:
- Vaani fine-tuning: 1,894 hours of transcribed multilingual speech.
- FLEURS fine-tuning: 124.35 hours train, 16.44 hours development, and 36.88 hours test.
Evaluation is performed on the Vaani test set covering 48 languages and on the FLEURS South Asia test split covering 14 languages from the 8th Schedule, with 10,658 utterances.
The tokenizer is a BPE model with a 2,000-word vocabulary, trained separately for each fine-tuning setup using the corresponding training partition.
Optimization and training protocol
The alignment stage and the final ASR fine-tuning stage use different optimization settings, but both are carefully standardized.
Alignment training
- Batch size: 64
- Optimizer: AdamW with $\beta_1 = 0.9$ and $\beta_2 = 0.95$
- Weight decay: 0.01
- Gradient clipping: 1.0
- Precision: bfloat16
- Learning rates: newly initialized layers at $3 \times 10^{-4}$, pretrained encoder parameters at $0.05$ times that rate
- Schedule: 1,000-step warm-up, then decay to a minimum multiplier of 0.05
- Total steps: 200,000
Fine-tuning training
- Framework: NeMo
- Hardware: $8 \times$ H100 GPUs
- Optimizer: AdamW with Noam annealing
- Warm-up: 2,000 steps
- Batch size: 16 per GPU
- Learning rate: $1 \times 10^{-4}$
- Regularization/augmentation: SpecAugment
- Training cap: 30 epochs unless otherwise stated
The supervised ASR model uses a hybrid CTC-TDT decoder with TDT durations $\{0,1,2,3,4\}$, and the aligned checkpoint or unaligned SSL checkpoint initializes the encoder.
Evaluation metric and significance testing
The evaluation metric is Word Error Rate (WER). For all reported system comparisons, the authors use paired utterance-level bootstrap testing with 2,000 resamples and report 95% confidence intervals on $\Delta$WER along with $p$-values.
Main results
Across both downstream settings, all alignment variants improve the final ASR model over the direct fine-tuning baseline. The improvements are modest on in-domain Vaani, but substantially larger on the cross-domain FLEURS South Asia evaluation, suggesting that the alignment stage improves transferability and generalization.
Vaani multilingual results
| Model | WER | Reported $\Delta$WER vs. baseline | Relative change | 95% CI on $\Delta$WER |
|---|---|---|---|---|
| Baseline (no alignment) | 0.2809 | -- | -- | -- |
| Qwen3-VL (multi-image) | 0.2768 | +0.0041 | +1.47% | [+0.0033, +0.0049] |
| SigLIP2-base (single-image) | 0.2771 | +0.0038 | +1.35% | [+0.0030, +0.0046] |
| SigLIP2-large (multi-image) | 0.2740 | +0.0069 | +2.47% | [+0.0062, +0.0078] |
On the 48-language Vaani test set, the aligned models improve the baseline in a majority of languages. The SigLIP2-base and SigLIP2-large variants both improve 37 out of 48 languages; SigLIP2-large yields the best overall WER. The paper reports no statistically significant degradation for the SigLIP-based variants, while Qwen3-VL shows some regressions, including one statistically significant regression.
| Variant | Improved | Statistically significant improvements | Regressed | Statistically significant regressions |
|---|---|---|---|---|
| Qwen3-VL | 33/48 | 15/48 | 14/48 | 1/48 |
| SigLIP2-base | 37/48 | 14/48 | 11/48 | 0/48 |
| SigLIP2-large | 37/48 | 20/48 | 10/48 | 0/48 |
FLEURS South Asia results
| Model | WER | Improved languages | Significant improvements | Regressed languages | Significant regressions |
|---|---|---|---|---|---|
| Baseline (SSL only) | 0.6778 | -- | -- | -- | -- |
| Qwen3-VL (multi-image) | 0.5683 | 12/14 | 10/14 | 2/14 | 2/14 |
| SigLIP2-large (multi-image) | 0.5358 | 13/14 | 13/14 | 1/14 | 1/14 |
| SigLIP2-base (single-image) | 0.5338 | 13/14 | 13/14 | 1/14 | 0/14 |
The FLEURS gains are much larger than the Vaani gains. The best system, SigLIP2-base, reduces WER from 0.6778 to 0.5338 overall, and is statistically significant in 13 of 14 languages with no statistically significant regression. This pattern supports the authors’ interpretation that audio--image alignment especially helps when labeled fine-tuning data is limited or the evaluation domain differs from the alignment/pretraining setup.
Per-language outcomes on FLEURS
The paper provides a language-by-language breakdown for the best model, SigLIP2-base. Most languages improve strongly, including especially large relative gains on Malayalam, Kannada, Marathi, and Sindhi. Urdu is the only language where the aligned system does not improve over baseline; the difference is not statistically significant.
| Language | N | WER baseline | WER aligned | Absolute $\Delta$ | Relative change | 95% CI on $\Delta$ | $p$ |
|---|---|---|---|---|---|---|---|
| Marathi | 1,015 | 0.7571 | 0.5188 | +0.2383 | +31.48% | [+0.2280, +0.2489] | <10-4 |
| Gujarati | 1,000 | 0.4855 | 0.4433 | +0.0422 | +8.69% | [+0.0334, +0.0510] | <10-4 |
| Assamese | 984 | 0.5853 | 0.5319 | +0.0534 | +9.13% | [+0.0459, +0.0606] | <10-4 |
| Sindhi | 980 | 0.7735 | 0.5413 | +0.2322 | +30.02% | [+0.2145, +0.2505] | <10-4 |
| Malayalam | 958 | 0.9733 | 0.5428 | +0.4305 | +44.23% | [+0.4134, +0.4466] | <10-4 |
| Bengali | 920 | 0.4348 | 0.4121 | +0.0227 | +5.22% | [+0.0157, +0.0299] | <10-4 |
| Oriya | 883 | 0.8172 | 0.6234 | +0.1939 | +23.72% | [+0.1784, +0.2084] | <10-4 |
| Kannada | 838 | 0.7231 | 0.4984 | +0.2247 | +31.07% | [+0.2067, +0.2434] | <10-4 |
| Nepali | 726 | 0.6390 | 0.5459 | +0.0931 | +14.57% | [+0.0816, +0.1048] | <10-4 |
| Tamil | 591 | 0.7346 | 0.6526 | +0.0820 | +11.17% | [+0.0671, +0.0965] | <10-4 |
| Punjabi | 574 | 0.5864 | 0.4837 | +0.1027 | +17.52% | [+0.0864, +0.1200] | <10-4 |
| Telugu | 472 | 0.6215 | 0.5678 | +0.0537 | +8.64% | [+0.0398, +0.0674] | <10-4 |
| Hindi | 418 | 0.4743 | 0.3520 | +0.1223 | +25.79% | [+0.1011, +0.1442] | <10-4 |
| Urdu | 299 | 1.0005 | 1.0021 | -0.0017 | -0.17% | [-0.0069, +0.0035] | 0.523 |
| Overall | 10,658 | 0.6778 | 0.5338 | +0.1441 | +21.26% | [+0.1396, +0.1482] | <10-4 |
Interpretation and analysis
The paper’s results support three main conclusions. First, aligned audio--image continued pretraining improves ASR over direct fine-tuning on the same SSL checkpoint. Second, the gains are much larger when the supervised signal is limited or the evaluation domain differs from the training domain, as seen in FLEURS. Third, the improvements are not attributable to extra audio exposure, since the alignment stage reuses audio from the pretraining corpus and a control experiment shows negligible differences between adjacent SSL checkpoints.
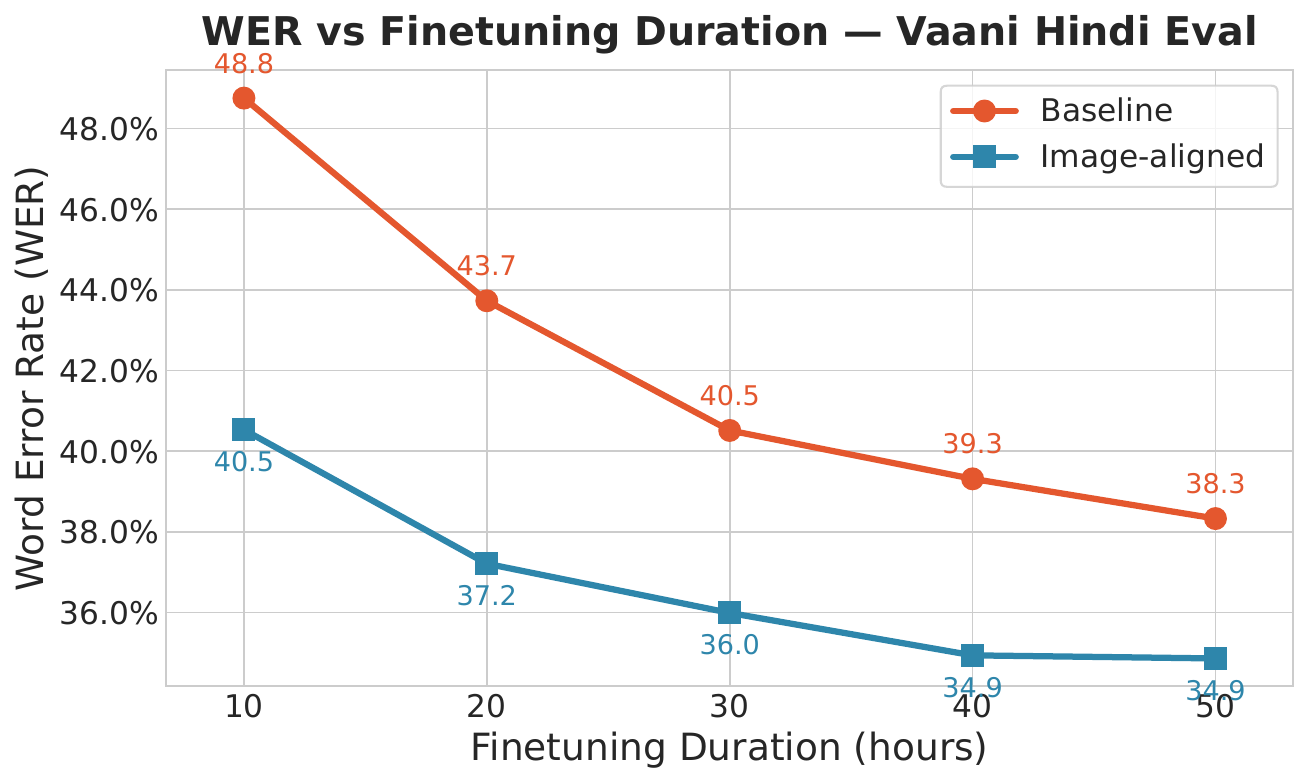
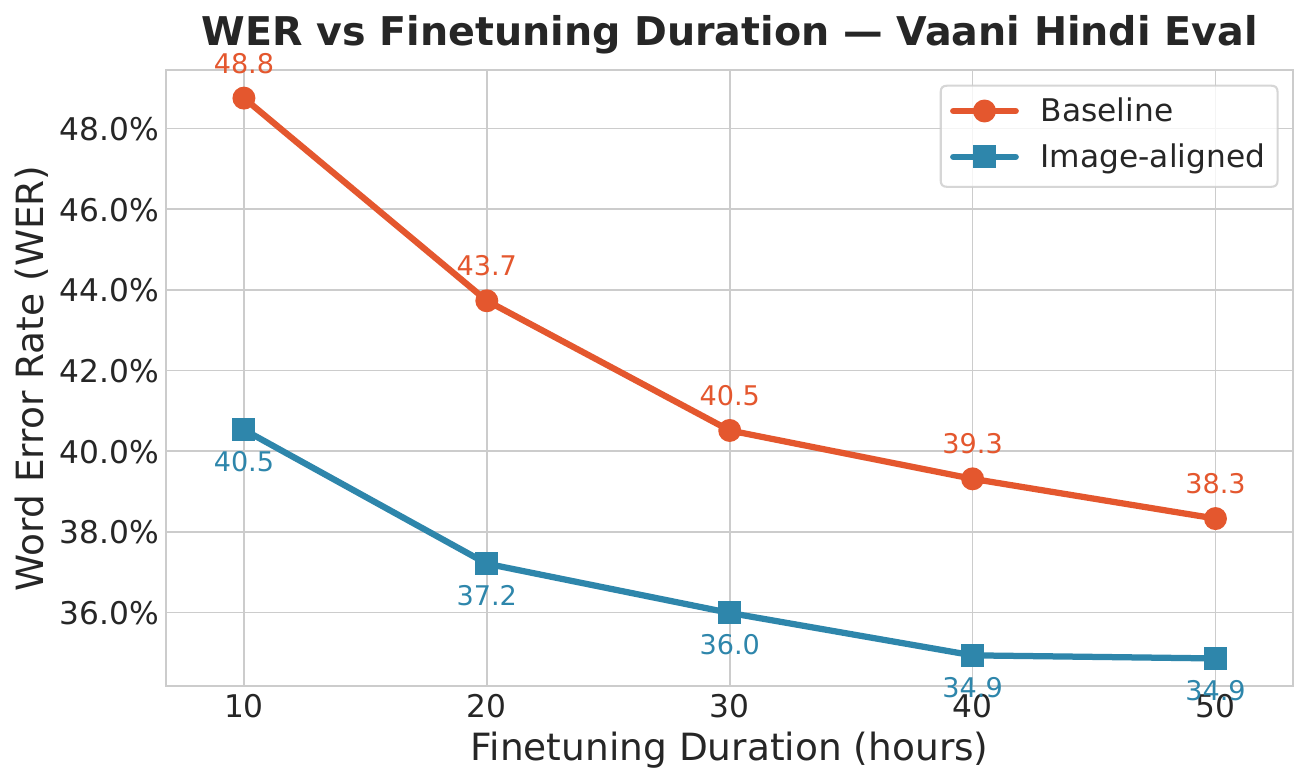
The authors also analyze how the benefit changes with the amount of labeled fine-tuning data. The figure above shows that the WER gap between the baseline and aligned systems shrinks as transcription duration increases from 10 to 50 hours. This suggests that audio--image alignment is most useful in the lowest-resource regime, where it can compensate for the lack of transcribed speech.
To rule out the possibility that more SSL pretraining alone explains the gains, the authors fine-tuned three neighboring checkpoints on 10 hours of Hindi data and evaluated on the Vaani Hindi test set. The reported WERs were 48.70, 48.98, and 48.75, which the authors interpret as negligible differences. This sanity check strengthens the claim that the alignment stage, not extra audio-only training, drives the observed improvements.
What is novel in this paper
- The multimodal signal is used before ASR fine-tuning, not during inference.
- The paper treats image prompts as a form of semantically aligned, transcription-free supervision for adapting an audio encoder.
- The alignment stage is inserted as a distinct continued-pretraining phase between SSL pretraining and supervised ASR.
- The authors compare single-vector and multi-token alignment formulations, showing that several image encoder choices are viable.
- The approach is evaluated on both in-domain multilingual Vaani and cross-domain FLEURS, with consistent gains in both settings.
Scope and caveats reported by the paper
The paper does not present a separate limitations section, but the reported evidence makes the practical scope clear. The gains are relatively small on the in-domain Vaani benchmark and become less pronounced as more labeled fine-tuning data is available. The method is also only evaluated in two multilingual fine-tuning settings, both tied to the Vaani/FLEURS experimental setup. Finally, the alignment stage relies on the availability of paired audio--image data and on a frozen pretrained vision encoder, so its usefulness depends on having that kind of multimodal collection process.
Bottom line
The paper shows that inserting an audio--image alignment phase between self-supervised audio pretraining and supervised ASR fine-tuning can improve multilingual ASR without any transcription during the intermediate stage. The strongest reported result is on FLEURS South Asia, where SigLIP2-base reduces WER from 0.6778 to 0.5338. The broader takeaway is that semantically aligned images can serve as an effective adaptation signal for speech encoders, especially when labeled speech data is scarce.