InterAligner
Progressive Alignment Objectives for Aligner-Encoder based ASR
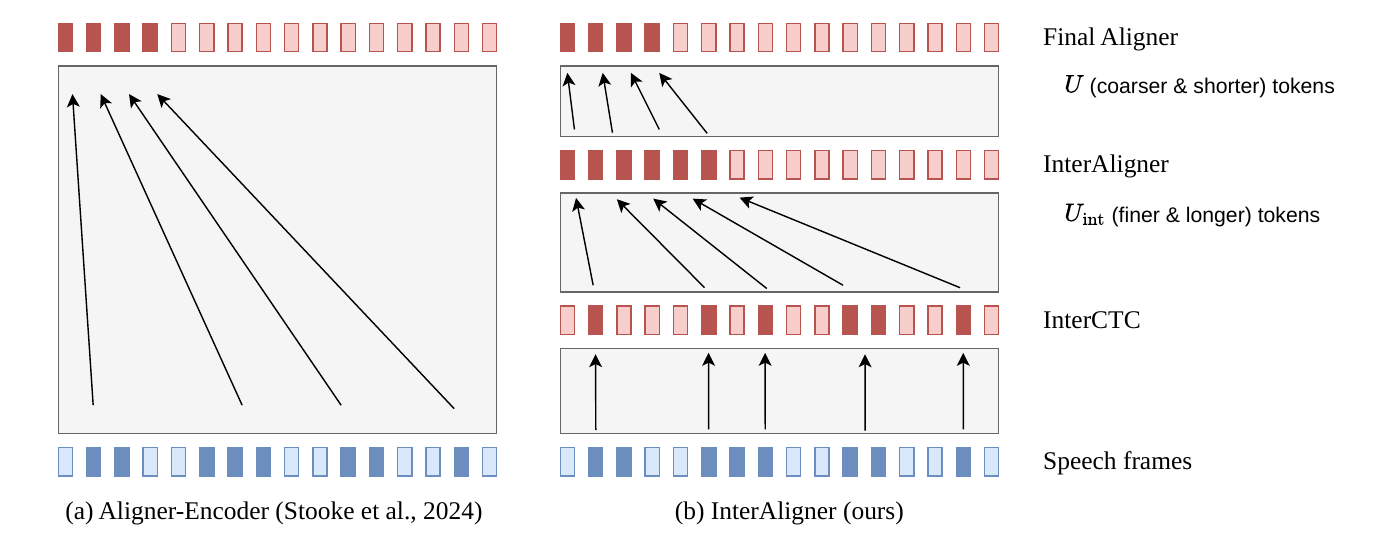
InterAligner enhances Aligner-Encoder ASR by adding progressive alignment objectives at intermediate layers, guiding the encoder to form monotonic alignment gradually. This approach stabilizes training and improves recognition, especially on long utterances, outperforming methods using only final-layer alignment.
Links
Paper & demos
Abstract
Aligner-Encoders are recently proposed seq2seq end-to-end ASR models that replace decoder attention by predicting the uth token directly from the u-th encoder position, so the encoder must learn the alignment internally without cross-attention or a transducer lattice. In practice, this alignment often forms abruptly in the upper layers, making training sensitive and brittle on long utterances. We propose InterAligner, which adds an intermediate Aligner objective so alignment can form progressively across depth, together with an intermediate CTC loss (InterCTC) to stabilize optimization. On LibriSpeech with a 17-layer Conformer, a final-only Aligner reaches 5.0/7.8 WER (test-clean/other). InterCTC improves to 3.4/6.0, and InterAligner further reduces WER to 3.1/5.6 with the largest gains on long utterances.
Introduction
This paper studies a particular weakness of Aligner-Encoders for end-to-end automatic speech recognition (ASR): although they eliminate decoder cross-attention and avoid an RNN-T style lattice, they still need the encoder itself to discover a monotonic audio-text alignment internally. The model predicts the $u$-th token directly from the $u$-th encoder position, so the alignment problem is pushed into encoder self-attention rather than handled by a separate decoder attention mechanism.
The authors observe that, in practice, this alignment often appears abruptly in only the upper layers of a deep encoder. That creates a late-layer bottleneck: lower layers do not yet carry a useful monotonic correspondence, and the top layers must convert a mostly unaligned representation into a nearly monotonic one within just a few layers. The paper argues that this is especially problematic for long utterances, where the mismatch between acoustic time steps and token length makes alignment learning brittle and training sensitive.
To address this, the paper introduces InterAligner, a progressive alignment training strategy for Aligner-Encoders. The core idea is to add an intermediate Aligner loss at an upper-intermediate encoder layer, using a longer and finer-grained target sequence, and to pair it with an intermediate CTC loss, called InterCTC, for optimization stability. Together, these objectives create a curriculum over alignment difficulty: early token-predictive supervision with CTC, then a finer intermediate alignment, then the final coarser output alignment at the top layer.
The paper reports that this approach improves recognition on LibriSpeech and Common Voice English, with the biggest gains on long utterances. It also includes attention visualizations that support the claim that alignment forms progressively across depth rather than all at once at the top of the network.
Background: Aligner-Encoder Formulation
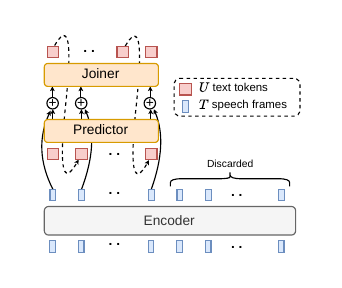
The paper follows the Aligner-Encoder formulation of Stooke et al. Let $ \mathbf{X} = (\mathbf{x}_1, \dots, \mathbf{x}_T)$ be the acoustic feature sequence and let $\mathbf{y} = (y_1, \dots, y_U)$ be the output token sequence, with an end-of-sequence token appended and included in $U$. After subsampling, the encoder produces a length-$T'$ sequence, and the model assumes $U \le T'$.
The encoder maps the input to acoustic embeddings
$$ \mathbf{H} = f_{\mathrm{enc}}(\mathbf{X}) = (\mathbf{h}_1, \dots, \mathbf{h}_{T'}) $$
A prediction network generates text-side hidden states autoregressively from the token history,
$$ \mathbf{g}_u = f_{\mathrm{pred}}(\mathbf{g}_{u-1}, y_{u-1}), \qquad u=1, \dots, U, $$
with $y_0 = \langle \mathrm{sos} \rangle$ and $\mathbf{g}_0$ initialized to zeros. In the implementation described in the paper, the predictor is a one-layer LSTM over token embeddings.
A feed-forward joiner combines the paired acoustic and text states:
$$ \tilde{\mathbf{z}}_u = \tanh(\mathbf{W}_h \mathbf{h}_u + \mathbf{W}_g \mathbf{g}_u + \mathbf{b}), \qquad \mathbf{z}_u = \mathbf{W}_o \tilde{\mathbf{z}}_u + \mathbf{b}_o, $$
followed by a softmax over the vocabulary to obtain $P(y_u \mid \mathbf{X}, y_{
Training with the final Aligner objective minimizes the negative log-likelihood
$$
\mathcal{L}_{\mathrm{final}}(\theta)
= -\sum_{u=1}^{U} \log P(y_u \mid \mathbf{X}, y_{
Because the loss is only applied up to $u = U$, the remaining encoder frames are ignored during training. This makes the encoder responsible for moving label-relevant information into its first $U$ output positions.
At inference time, decoding proceeds sequentially over encoder positions and emits one token per frame until $\langle \mathrm{eos} \rangle$ is produced; the paper states that greedy decoding or beam search can be used. The architecture figure below emphasizes this autoregressive frame-to-token process.
The main contribution is to make alignment emerge progressively across depth instead of only at the final layer. The method adds two auxiliary objectives to the baseline final Aligner loss: an intermediate CTC loss, InterCTC, and an intermediate Aligner loss, InterAligner.
Let $\mathbf{H}^{(\ell)} = (\mathbf{h}^{(\ell)}_1, \dots, \mathbf{h}^{(\ell)}_{T'})$ be the encoder output after layer $\ell$, with $\mathbf{H}^{(L)} = \mathbf{H}$ for the final layer $L$.
InterCTC places a CTC loss at an intermediate layer $\ell_{\mathrm{ctc}}$; in the main experiments the paper uses $\ell_{\mathrm{ctc}} = 12$. The purpose is to encourage token-predictive representations earlier in the encoder and to stabilize optimization.
InterAligner places a second Aligner head at layer $\ell_{\mathrm{int}}$; in the main experiments this is layer 15, while the final Aligner head remains at layer 17. The intermediate head uses a separate predictor and joiner, with no parameter sharing with the final head.
The intermediate objective uses a finer tokenization derived from the same transcript:
$$
\mathbf{y}^{\mathrm{int}} = (y^{\mathrm{int}}_1, \dots, y^{\mathrm{int}}_{U_{\mathrm{int}}}),
$$
where typically $U_{\mathrm{int}} > U$. The paper requires $U_{\mathrm{int}} \le T'$ so that the one-to-one Aligner pairing remains well-defined.
Applying the same predictor-joiner factorization to $\mathbf{H}^{(\ell_{\mathrm{int}})}$ yields the intermediate Aligner loss
$$
\mathcal{L}_{\mathrm{int}}(\theta)
= -\sum_{u=1}^{U_{\mathrm{int}}} \log P_{\mathrm{int}}\!\left(y^{\mathrm{int}}_u \mid \mathbf{X}, y^{\mathrm{int}}_{<u}; \theta\right).
$$
The paper frames these losses as a staged curriculum: InterCTC first nudges the encoder toward token-discriminative features, InterAligner then forces a longer and finer-grained monotonic alignment at intermediate depth, and the final Aligner head refines that alignment to the shorter, coarser final tokenization.
The total training objective is
$$
\mathcal{L}(\theta)
= \lambda_{\mathrm{final}} \mathcal{L}_{\mathrm{final}}(\theta)
+ \lambda_{\mathrm{int}} \mathcal{L}_{\mathrm{int}}(\theta)
+ \lambda_{\mathrm{ctc}} \mathcal{L}_{\mathrm{ctc}}(\theta).
$$
The paper fixes $\lambda_{\mathrm{ctc}} = 0.1$ in all experiments and tunes the relative weights of the final and intermediate Aligner losses for the best-performing InterAligner configuration.
The paper evaluates on LibriSpeech 960h and reports word error rate (WER) on test-clean and test-other. It also evaluates on Common Voice 16.1 English, where punctuation is removed from both training and test text.
All systems use the same 17-layer Conformer-L encoder, with an overall model size of about 118M parameters. Unless otherwise noted, the final Aligner head is attached at layer 17, InterAligner at layer 15, and InterCTC at layer 12.
The paper uses a beam width of 6 for fair comparison with Stooke et al. On LibriSpeech, training runs for 100 epochs with model averaging over the 10 best checkpoints. On Common Voice, training runs for 50 epochs with the same 10-best averaging. The effective batch size is approximately 2 hours of audio in all settings.
Optimization uses standard Transformer warmup and decay with 20k warmup steps. The peak learning rate is set to 0.0020 for settings that do not use any target vocabulary size $\le 256$, and 0.0025 otherwise.
Tokenization uses BPE. By default, the final Aligner uses a vocabulary size of 1024, the intermediate Aligner uses 256, and InterCTC matches the tokenization used by the Aligner objective at the nearest higher layer. In the pure InterCTC setting that means 1024; in the full InterAligner setting the intermediate objectives use 256.
The paper explicitly notes that reproducing the final-only WER reported by Stooke et al. is difficult under the limited training budget, which motivates the addition of intermediate objectives to stabilize optimization.
The main result is that both auxiliary objectives help, and the combination helps most. On LibriSpeech, the final-only Aligner reproduced by the authors reaches 5.0/7.8 WER on test-clean/test-other. Adding InterCTC gives a large improvement to 3.4/6.0, and adding InterAligner further improves to 3.1/5.6.
The same trend holds on Common Voice English, where final-only Aligner reaches 12.4 WER, InterCTC improves to 11.2, and full InterAligner further reduces WER to 10.9.
The paper states that the improvements from InterCTC and from adding InterAligner are statistically significant at the 1% level.
A central claim of the paper is that progressive alignment supervision is especially beneficial when utterances are long. The authors therefore break down LibriSpeech WER by duration. The largest gains occur for utterances longer than 21 seconds, where final-only Aligner performance is poor and the intermediate objectives substantially reduce the error rate.
The paper highlights that InterAligner nearly preserves the gains from InterCTC on short and medium utterances, but produces especially large improvements on long utterances. For example, on test-clean segments longer than 21 seconds, WER drops from 17.0 with InterCTC to 11.6 with InterAligner; on test-other, it drops from 18.0 to 13.5. This supports the authors' interpretation that distributing alignment supervision across depth makes alignment formation more robust under long-range temporal mismatch.
One ablation asks whether the intermediate CTC target should match the InterAligner target, and how sensitive the system is to the relative weights of the final and intermediate Aligner objectives. The paper shows that matching the intermediate vocabularies is beneficial: using 256/256 for InterAligner and InterCTC outperforms a mismatched 256/1024 combination.
The loss weights matter as well. In the matched setting, emphasizing the intermediate Aligner objective with $(\lambda_{\mathrm{final}}, \lambda_{\mathrm{int}}) = (0.5, 1.0)$ is best. Reversing the emphasis to $(1.0, 0.5)$ worsens the intermediate head and slightly hurts the final head. Under the best weighting, the intermediate head slightly outperforms the final head, although the paper reports its main results using the final head for decoding.
Another ablation varies the target vocabulary sizes. Smaller intermediate vocabularies such as 256 or 64 perform well, while using the same large vocabulary as the final Aligner for the intermediate losses degrades performance. The paper interprets this as evidence that intermediate granularity changes the difficulty of the implicit alignment problem.
Importantly, the results also show that reducing vocabulary size by itself is not sufficient: a system that uses a 256-token final objective with CTC but no InterAligner performs substantially worse than the hierarchical configuration. This is one of the clearest pieces of evidence that the gains come from progressive supervision, not just from choosing a smaller token inventory.
The paper also studies the depth at which InterAligner should be attached. With $(\lambda_{\mathrm{final}}, \lambda_{\mathrm{int}}, \lambda_{\mathrm{ctc}}) = (0.5, 1.0, 0.1)$ and an intermediate vocabulary size of 256, the best placement is layer 15. Moving the intermediate head later to layer 16 hurts performance noticeably, while moving it earlier to layer 13 also degrades results.
The authors interpret this as evidence that at least two layers may be needed to convert the intermediate alignment into the final one, which is consistent with prior observations that alignment emerges across roughly two upper layers in Aligner-Encoders.
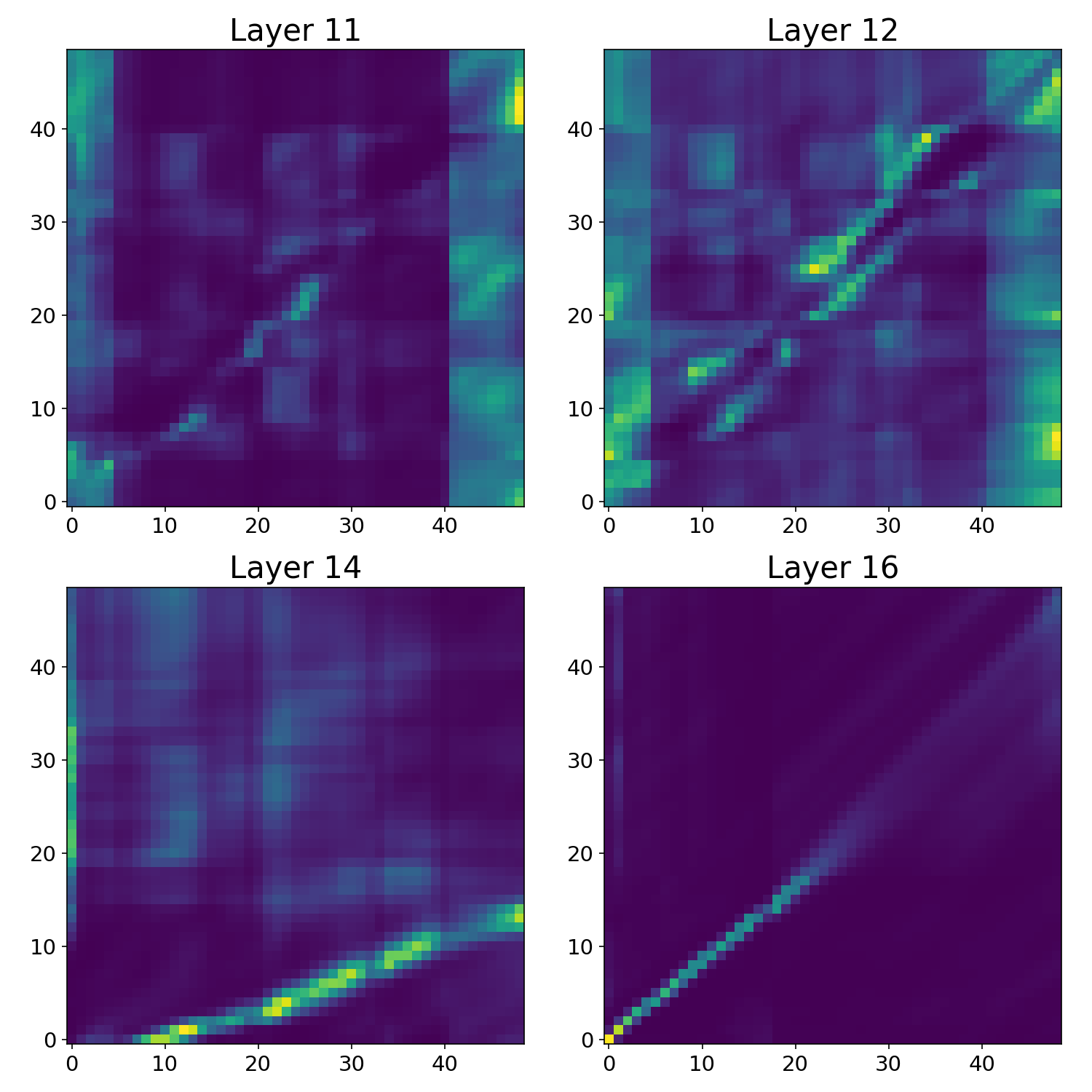
To support the progressive-alignment hypothesis, the paper visualizes averaged 8-head encoder self-attention maps for a representative LibriSpeech utterance with $U_{\mathrm{int}} = 11$ and $U = 9$. In the lower layers shown, alignment is not yet clearly formed. By layer 14, the attention concentrates into a sharp monotonic band consistent with $T' \rightarrow U_{\mathrm{int}}$ alignment. By layer 16, a second sharp diagonal pattern appears at the coarser final granularity, consistent with $U_{\mathrm{int}} \rightarrow U$ alignment.
This visualization is important because it distinguishes the paper's claim from a simpler "smaller vocabulary helps" explanation. The observed pattern suggests that the model is not just learning a single early alignment, but is instead refining monotonic structure in stages across depth.
The paper's main technical message is that aligning only at the top layer makes Aligner-Encoders brittle, especially for long utterances, and that supervision should be distributed across depth. InterCTC improves optimization by encouraging token-discriminative intermediate representations, while InterAligner directly addresses the late-layer alignment bottleneck by supervising a finer-grained intermediate alignment before the final one.
The paper does not present a broad negative-results section, but its own ablations make a few practical constraints clear. Performance depends on the choice of intermediate vocabulary size, the balance between final and intermediate loss weights, and the layer at which the intermediate head is attached. In other words, the method is effective but not parameter-free; it requires selecting an appropriate progression schedule.
Another practical limitation is that, even with the proposed objectives, the strongest gains are concentrated on longer utterances, and the longest-duration subsets still have nontrivial error rates. The authors therefore frame the method as a training and alignment-stabilization improvement rather than a complete solution to long-form ASR.
The conclusion also points to future work on streaming and long-form recognition, as well as on integrating language models with progressive objectives.
InterAligner is a simple but effective extension of Aligner-Encoders: add an intermediate Aligner head, pair it with an intermediate CTC loss, and let alignment emerge progressively across depth. Across LibriSpeech and Common Voice English, this strategy consistently improves WER over a final-only Aligner and over InterCTC alone, with the largest benefit on long utterances. The ablations and attention visualizations together support the paper's central claim that progressive monotonic supervision is a better fit for Aligner-Encoder optimization than relying on a single late-layer alignment objective.
Method: Progressive Alignment Supervision
Experimental Setup
Main Results
System
test-clean
test-other
Final Aligner only (Stooke et al.) 4.8 6.5 Final Aligner only (ours) 5.0 7.8 + InterCTC 3.4 6.0 + InterAligner 3.1 5.6
System
test
Final Aligner only 12.4 + InterCTC 11.2 + InterAligner 10.9 Long-Utterance Behavior
Split
System
<17s
17--21s
>21s
All
clean Final Aligner only 3.2 5.7 23.4 5.0 + InterCTC 2.3 2.3 17.0 3.4 + InterAligner 2.4 2.9 11.6 3.1 other Final Aligner only 7.0 8.2 24.0 7.8 + InterCTC 5.4 5.3 18.0 6.0 + InterAligner 5.2 5.5 13.5 5.6 Ablations
Matching intermediate targets and tuning loss weights
Final BPE
Inter BPE
CTC BPE
$\lambda_{\mathrm{final}} / \lambda_{\mathrm{int}}$
final
inter
1024 256 256 0.5 / 1.0 3.1 / 5.6 3.0 / 5.5 1024 256 256 1.0 / 0.5 3.1 / 5.8 5.7 / 7.0 1024 256 1024 1.0 / 0.5 3.2 / 5.8 4.0 / 6.1 Tokenization choices alone are not enough
Final BPE
Inter BPE
CTC BPE
final
inter
1024 1024 1024 3.7 / 6.3 3.8 / 6.3 1024 256 256 3.1 / 5.8 5.7 / 7.0 1024 64 64 3.0 / 5.7 5.7 / 6.8 256 -- 256 5.0 / 6.4 -- Where to attach the intermediate Aligner
InterAligner layer
final
inter
16th 3.8 / 5.9 3.5 / 5.8 15th 3.1 / 5.6 3.0 / 5.5 13th 3.5 / 6.4 3.3 / 5.9 Attention Analysis
Interpretation and Limitations
Conclusion