FiCA
FiCA: Feed-forward instant Gaussian Codec Avatars from a Single Portrait Image

FiCA generates photorealistic, animatable 3D Gaussian Codec Avatars from a single portrait image using a feed-forward pipeline. It uniquely combines vision foundation models, diffusion-based completion, and UV refinement for real-time, identity-preserving avatars without offline tracking or optimization.
Demos
These demos showcase FiCA's capability to generate photorealistic, drivable 3D Gaussian Codec Avatars from a single portrait image in a feed-forward manner without test-time optimization. Evaluate avatar identity preservation, facial detail fidelity, and real-time animation quality versus competing methods. The pipeline and editing demos highlight efficient generation and future application potential.
Links
Paper & demos
Abstract
We introduce FiCA, a Feed-forward, instant Gaussian Codec Avatar generation pipeline that creates lifelike avatars from a single portrait image. Generating a photorealistic and drivable avatar from just a single image is significantly challenging due to the limited visual information available to accurately infer the 3D appearance and geometry of human heads. To address this, we develop a novel system that combines human-centric vision foundation models with a diffusion model. This system is designed to fully exploit partial visual observations to generate lifelike human avatars. Our proposed diffusion model learns a generative mapping from these partial observations to complete and authentic 3D mesh reconstruction. Additionally, we introduce a feed-forward mesh refinement network that enhances the fidelity and identity preservation of the generated avatars, eliminating the need for person-specific test-time optimization. By leveraging a universal prior model that decodes a generated mesh into a set of 3D Gaussians, we generate a photorealistic 3D Gaussian avatar, capable of being driven with novel expressions in real-time. Our experiments demonstrate that the avatars generated by our feed-forward approach faithfully represent diverse identities and surpass the visual quality of avatars produced by recent competing methods.
1. Problem Setting and Core Idea
FiCA addresses a difficult but practical avatar-generation setting: produce a photorealistic, identity-preserving, and drivable human head avatar from only a single portrait image. The paper frames this as an ill-posed reconstruction problem because a portrait contains only partial evidence about head geometry, hidden facial regions, texture beyond the visible view, and expression-dependent structure. Prior high-quality avatar pipelines often rely on multi-view capture, offline tracking, or per-subject optimization. FiCA’s central goal is to replace those expensive steps with a fully feed-forward pipeline that can synthesize a canonical avatar representation and then convert it into a real-time 3D Gaussian Codec Avatar.
The system combines three main ingredients: (1) human-centric vision foundation models that turn a portrait into partial UV-space observations; (2) a diffusion model that completes texture and geometry from those partial cues; and (3) a feed-forward refinement network that improves image-space alignment and identity fidelity. A universal prior model then decodes the generated mesh into 3D Gaussians, yielding a final avatar that can be driven by novel expressions and head/view signals in real time.
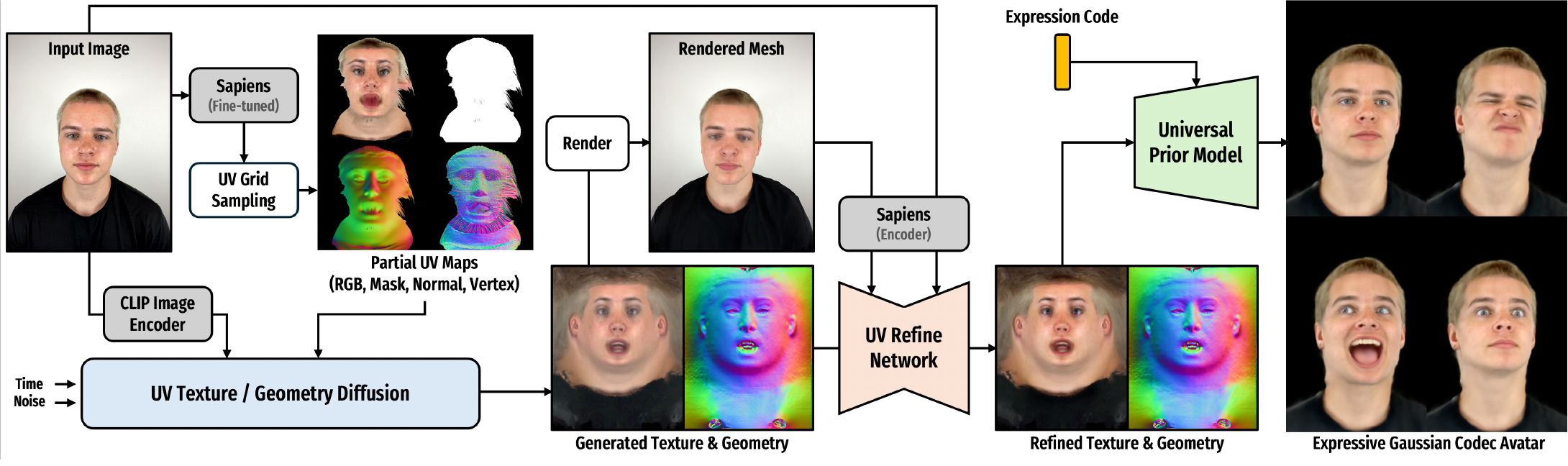
2. Method Overview
2.1 Conditioning from Human-Centric Foundation Models
The first stage extracts as much usable structure as possible from a single portrait image. FiCA uses a CLIP image encoder to capture semantic identity information, and fine-tuned Sapiens models to predict per-pixel UV coordinates, vertex coordinates, and normals. These predictions are unwrapped into partial UV maps:
$$\mathbf{UV}_{\text{partial}} = [\mathbf{UV}_{\text{RGB}}, \mathbf{UV}_{\text{mask}}, \mathbf{UV}_{\text{nrm}}, \mathbf{UV}_{\text{vtx}}].$$
The key design choice is that FiCA does not trust the partial observations as complete geometry or texture. Instead, it treats them as imperfect but informative evidence that should guide a generative model toward a full canonical mesh. This matters because single-image UV predictions can be noisy in self-occluded regions, around boundaries, or for hard-to-observe structures such as mouth interiors.
2.2 Diffusion-Based Texture and Geometry Completion
The core generative module is a latent diffusion model in a DiT-style architecture. It takes the CLIP embedding, the partial UV maps, a domain switcher, the diffusion timestep, and random noise, and predicts complete UV texture and geometry maps. The two output domains are handled with a single shared model but separated by a constant domain indicator that tells the network whether it should denoise the texture or geometry branch.
The paper emphasizes that this is more than simple inpainting. Because the UV predictions from Sapiens are partial and imperfect, FiCA trains the diffusion model to imagine the full avatar under identity constraints rather than only filling masked pixels. The training data consist of large-scale human-avatar assets captured from phone captures and high-end multi-view capture systems.
The flow-matching objective is written as:
$$ \mathcal{L}_{\text{diffusion}} = \left\| \mathbf{v}_{t}^{T} - \mathcal{F}_{\theta}(\mathbf{x}_{t}^{T}, \mathbf{f}_{\text{CLIP}}, \mathbf{UV}_{\text{partial}}, \mathbf{d}^{T}, t) \right\|_{2}^{2} + \left\| \mathbf{v}_{t}^{G} - \mathcal{F}_{\theta}(\mathbf{x}_{t}^{G}, \mathbf{f}_{\text{CLIP}}, \mathbf{UV}_{\text{partial}}, \mathbf{d}^{G}, t) \right\|_{2}^{2}. $$
Here, the superscripts $T$ and $G$ denote the texture and geometry domains, respectively; $\mathbf{x}_{t}^{*}$ are the noise-added latents at timestep $t$; $\mathbf{v}_{t}^{*}$ are the corresponding ground-truth flow fields from conditional flow matching; and $\mathbf{d}^{*}$ is the domain switcher.
Implementation-wise, the paper’s supplement states that the UV texture and geometry maps are compressed with a pre-trained SDXL VAE by $8\times$ to a latent size of $32 \times 32 \times 16$, patchified with patch size 2, and processed by 28 DiT+ControlMLP blocks. The diffusion model contains about 2B learnable parameters. The model is first image-only pre-trained on a large human-centric dataset, then fine-tuned on paired portrait-to-UV data.
2.3 Feed-Forward UV Refinement
The diffusion output already gives a plausible textured mesh, but FiCA adds a second learned stage to improve fidelity and identity preservation. This refinement network is explicitly motivated by image-level misalignment between the reference portrait and the rendered mesh. Instead of using person-specific test-time optimization, FiCA trains a feed-forward UV refinement network that edits both texture and geometry once, conditioned on the input portrait and a rendering of the generated mesh.
The refinement module extracts dense features from the reference image and the rendered avatar image using a Sapiens ViT encoder. These features condition a U-Net with cross-attention so that UV-space updates can borrow cues from image space. In effect, the refinement stage learns to reconcile the mesh with the portrait while preserving the canonical structure learned by the diffusion model.
The training loss is a weighted combination of photometric, mask, keypoint, and regularization terms:
$$ \mathcal{L}_{\text{refine}} = \lambda_{\text{pho}}\mathcal{L}_{\text{pho}} + \lambda_{\text{mask}}\mathcal{L}_{\text{mask}} + \lambda_{\text{kpts}}\mathcal{L}_{\text{kpts}} + \lambda_{\text{reg}}\mathcal{L}_{\text{reg}}. $$
The individual terms are defined in the paper as $\mathcal{L}_{\text{pho}} = \| \mathbf{I}_{\text{ref}} - \mathbf{I}_{\text{rdr}} \|_{1}$, $\mathcal{L}_{\text{mask}} = \| \mathbf{m}_{\text{ref}} - \mathbf{m}_{\text{rdr}} \|_{1}$, $\mathcal{L}_{\text{kpts}} = \| \mathbf{k}_{\text{ref}} - \mathbf{k}_{\text{rdr}} \|_{1}$, and a UV regularizer that penalizes deviation of refined texture, Laplacian, and normal maps from the initial prediction. The supplement gives the weights $\lambda_{\text{pho}} = 2.0$, $\lambda_{\text{mask}} = 0.5$, $\lambda_{\text{kpts}} = 0.01$, and $\lambda_{\text{reg}} = 1.0$.
During training, the authors use ground-truth face pose and expression code to overlay the mesh and compute image-space supervision. At inference, they note that an off-the-shelf regressor such as EMOCA or SMIRK can estimate the pose/expression parameters if needed.

2.4 Universal Prior Model for 3D Gaussian Avatar Decoding
FiCA’s final avatar representation is a set of 3D Gaussians, chosen for efficiency and expressiveness. The canonical textured mesh produced by the previous stages acts as an identity-conditioning proxy for a universal prior model (UPM), which maps the mesh into a drivable 3D Gaussian Codec Avatar.
The UPM consists of an identity encoder and a Gaussian decoder. The identity encoder is a CNN-based hypernetwork that consumes the UV texture and geometry maps and outputs identity-specific bias maps. Those bias maps modulate the decoder, which takes expression code $\mathbf{e}$, view direction $\mathbf{v}$, and gaze direction $\mathbf{g}$ as driving signals. The decoder predicts Gaussian parameters including position offsets, color offsets, rotation, scale, and opacity:
$$ \Psi_{\text{id}} = \mathcal{E}_{\psi_{\text{id}}}(\mathbf{T}, \mathbf{G}), \qquad \{\delta \mathbf{x}, \delta \mathbf{c}, \mathbf{q}, \mathbf{s}, \mathbf{o}\} = \mathcal{D}_{\psi_{\text{dec}}}(\mathbf{e}, \mathbf{v}, \mathbf{g}, \Psi_{\text{id}}). $$
The paper’s main conceptual difference from earlier UPM-based avatar systems is that FiCA does not rely on offline face tracking or person-specific fine-tuning at test time to obtain the conditioning mesh. Instead, the mesh is generated directly from a single portrait image.
3. Training Data, Optimization, and Compute
FiCA uses multiple datasets for different stages. For diffusion training, the paper constructs paired samples of portrait images and UV texture/geometry maps from two heterogeneous sources: a multi-view dome-captured dataset and an iPhone-captured dataset. The dome dataset contains 1,948 identities total, split into 1,932 train IDs and 16 test IDs. The iPhone dataset contains 12,539 identities total, split into 12,439 train IDs and 100 test IDs.
The supplement also describes how the Sapiens models are fine-tuned. They start from Sapiens-1B and jointly fine-tune the encoder and task-specific decoders for UV coordinates, vertex coordinates, and normals. Training uses an internal iPhone capture dataset with about 12,000 identities of quarter-body videos, with per-frame importance sampling, random cropping/scaling, and photometric distortion. UV and vertex coordinates are supervised with $L_1$ loss, while normals use cosine similarity loss. Each Sapiens task is trained on 512 NVIDIA A100 GPUs for 12 hours.
The diffusion model itself is trained for 50K steps with an effective batch size of 128 on 64 NVIDIA A100 GPUs, after image-only pre-training. According to the supplement, convergence takes about 2 days. Sampling uses 50 flow-estimation/update steps and takes about 4 seconds.
The refinement network is also trained for 50K steps with effective batch size 128 on 32 NVIDIA A100 GPUs, again taking about 2 days. The UPM is trained separately on a broadened corpus of 1,927 identities captured from 160 multi-view calibrated cameras, with 128 NVIDIA A100 GPUs for about 3 weeks. The supplement notes one additional change in UPM training: the photometric loss is moved to RGB space using a precomputed color correction matrix so that the UPM better matches FiCA’s RGB UV texture outputs.
End-to-end, the paper reports that FiCA generates an avatar in about 5 seconds in a purely feed-forward manner, enabling a much faster workflow than optimization-based baselines.
4. Experimental Evaluation
4.1 Qualitative Results
FiCA is evaluated on unseen test identities with diverse races, genders, ages, and hairstyles. The paper reports that the method faithfully reproduces visible details such as tattoos, necklaces, hood structures, and accessories. Because the diffusion module learns to complete the UV representation rather than just patching holes, it can also hallucinate unobserved facial regions such as mouth interiors and eye pupils in a plausible way.
The authors also claim robustness to input-image characteristics, including body coverage and camera position, because the conditioning stage relies on human-centric foundation models rather than raw pixel regression alone.


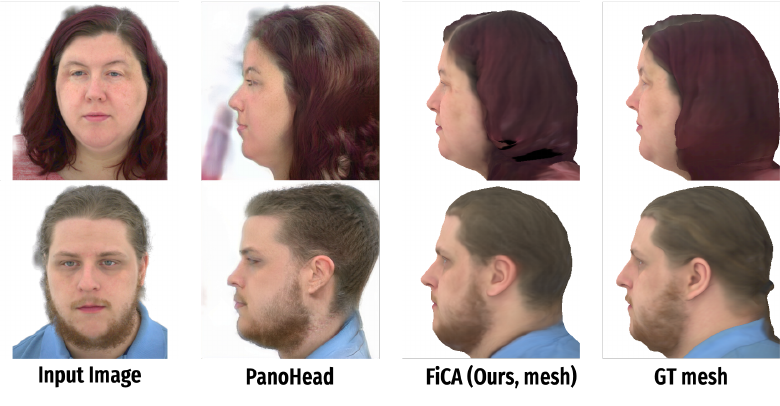
4.2 Static Avatar Comparison
For static reconstruction, FiCA is compared to PanoHead. The paper emphasizes two differences: first, PanoHead relies on per-image GAN inversion and takes about 80 seconds per image, whereas FiCA’s mesh generation takes about 5 seconds; second, PanoHead produces a static avatar that does not support free expression control, whereas FiCA’s mesh is later decoded into animatable 3D Gaussians.
Qualitatively, FiCA is reported to produce more complete and view-consistent head avatars, especially for side and back views, while PanoHead can show artifacts such as ghost faces and floaters.
4.3 Animated Avatar Comparison and Metrics
For animation, FiCA is compared against GPAvatar, VOODOO 3D, Portrait4D-v1, Portrait4D-v2, and GAGAvatar. The evaluation uses 16 held-out identities from the dome dataset, with approximately 1,500 frames in total. The paper drives each generated avatar using tracked per-frame expression codes from the same identity, enabling a zero-shot animation test. Metrics are computed on the face region only to reduce background influence.
The reported metrics are PSNR, SSIM, LPIPS, and ID-CSIM. ID-CSIM is the cosine similarity between ArcFace embeddings extracted from the source portrait image and the generated dynamic avatar frames, computed with the DeepFace implementation.
| Method | PSNR ↑ | SSIM ↑ | LPIPS ↓ | ID-CSIM ↑ |
|---|---|---|---|---|
| GPAvatar | 19.565 | 0.7648 | 0.1915 | 0.3166 |
| VOODOO 3D | 19.321 | 0.6983 | 0.2756 | 0.4339 |
| Portrait4D-v1 | 15.006 | 0.3743 | 0.4138 | 0.2135 |
| Portrait4D-v2 | 15.704 | 0.3871 | 0.3765 | 0.2545 |
| GAGAvatar | 22.157 | 0.7513 | 0.1320 | 0.3522 |
| FiCA (Mesh) | 24.281 | 0.9625 | 0.1381 | 0.5233 |
| FiCA (3DGS) | 24.508 | 0.9637 | 0.1365 | 0.5867 |
The paper’s main quantitative takeaway is that FiCA achieves the best PSNR, SSIM, and ID-CSIM among the compared methods, with FiCA (3DGS) slightly outperforming FiCA (Mesh). For LPIPS, GAGAvatar remains the best among the listed methods, but FiCA is close. The authors interpret the strong PSNR/SSIM and identity metrics as evidence that the feed-forward pipeline preserves identity while improving photometric fidelity.
4.4 Ablation Study
The ablation study isolates three design choices: adding geometry cues beyond RGB texture, adding CLIP semantic conditioning, and adding the feed-forward refinement network. The trend is clear in both the visualization and the numbers: each component improves reconstruction quality and identity fidelity.
| Partial UV RGB | Normal + Vertex UV | CLIP | FF Refinement | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|---|---|---|
| ✓ | – | – | – | 19.504 | 0.8140 | 0.1806 |
| ✓ | ✓ | – | – | 19.644 | 0.8164 | 0.1667 |
| ✓ | ✓ | ✓ | – | 19.738 | 0.8431 | 0.1648 |
| ✓ | ✓ | ✓ | ✓ | 22.282 | 0.8804 | 0.1569 |
The qualitative ablation shows the same pattern. Using only partial RGB UV texture maps causes identity drift and geometry misalignment because RGB alone cannot resolve head structure. Adding normal and vertex UV cues improves geometry. Injecting CLIP helps recover semantic details such as a hood. Adding the UV refinement network yields the best skin tone, realism, and local detail consistency.

4.5 Supplementary Generalization Evidence
The supplementary material adds examples showing that FiCA generalizes beyond the training capture domains. The paper reports reasonable performance on in-the-wild internet portraits and on held-out NerSemble identities, including oblique head views. These results support the claim that the model learns a broad human prior rather than merely memorizing the capture setup.



5. What FiCA Contributes Relative to Prior Work
The novelty is not a single module but the way the modules are composed. Earlier monocular avatar systems often rely on either optimization-based priors, offline tracking, or a heavy amount of test-time adaptation. FiCA replaces those stages with a feed-forward completion model built on human-centric foundation features, then adds a refinement network to recover local fidelity, and finally leverages a universal prior model to map the canonical mesh into a real-time 3D Gaussian avatar.
Compared with optimization-heavy static methods such as PanoHead, FiCA is dramatically faster and yields more complete views. Compared with recent monocular animation systems such as GPAvatar, VOODOO 3D, Portrait4D, and GAGAvatar, FiCA more directly predicts a controllable 3D Gaussian avatar rather than depending on per-frame estimation or weaker renderer surrogates. The paper argues that this direct 3DGS target improves both visual quality and expression controllability.
6. Limitations, Future Work, and Broader Impact
The paper is explicit about several limitations. FiCA can be vulnerable to strong input artifacts such as extreme lighting or motion blur. The authors suggest that learned light normalization or blur correction inside the texture-generation stage could be useful future work. They also point to extending the method to jointly generate layered texture and geometry for accessories such as glasses as another promising direction.
On the broader-impact side, the authors frame the work as enabling more accessible telepresence and mixed-reality avatars, but they also acknowledge misuse risks. They recommend continued development of avatar fingerprinting and digital-media forensics to help detect synthetic media. The paper also states that the human datasets were collected in accordance with ethical guidelines and with informed consent.
A notable application highlighted in the conclusion is feed-forward avatar editing: a portrait can first be edited in 2D, and FiCA can then synthesize a stylized, drivable Gaussian avatar from the edited image without any heuristic 3D optimization.

7. Bottom Line
FiCA’s main contribution is a practical feed-forward pipeline for turning a single portrait into a photorealistic, identity-preserving, and real-time drivable Gaussian Codec Avatar. The paper’s technical recipe is: extract partial human-centric cues with foundation models, complete a canonical mesh with a conditional diffusion model, sharpen the result with feed-forward UV refinement, and decode the mesh into 3D Gaussians using a universal prior model. The reported results show strong gains over recent single-image and monocular avatar baselines, especially in reconstruction fidelity, identity preservation, and controllable animation quality.