ZONOS2
ZONOS2 Technical Report
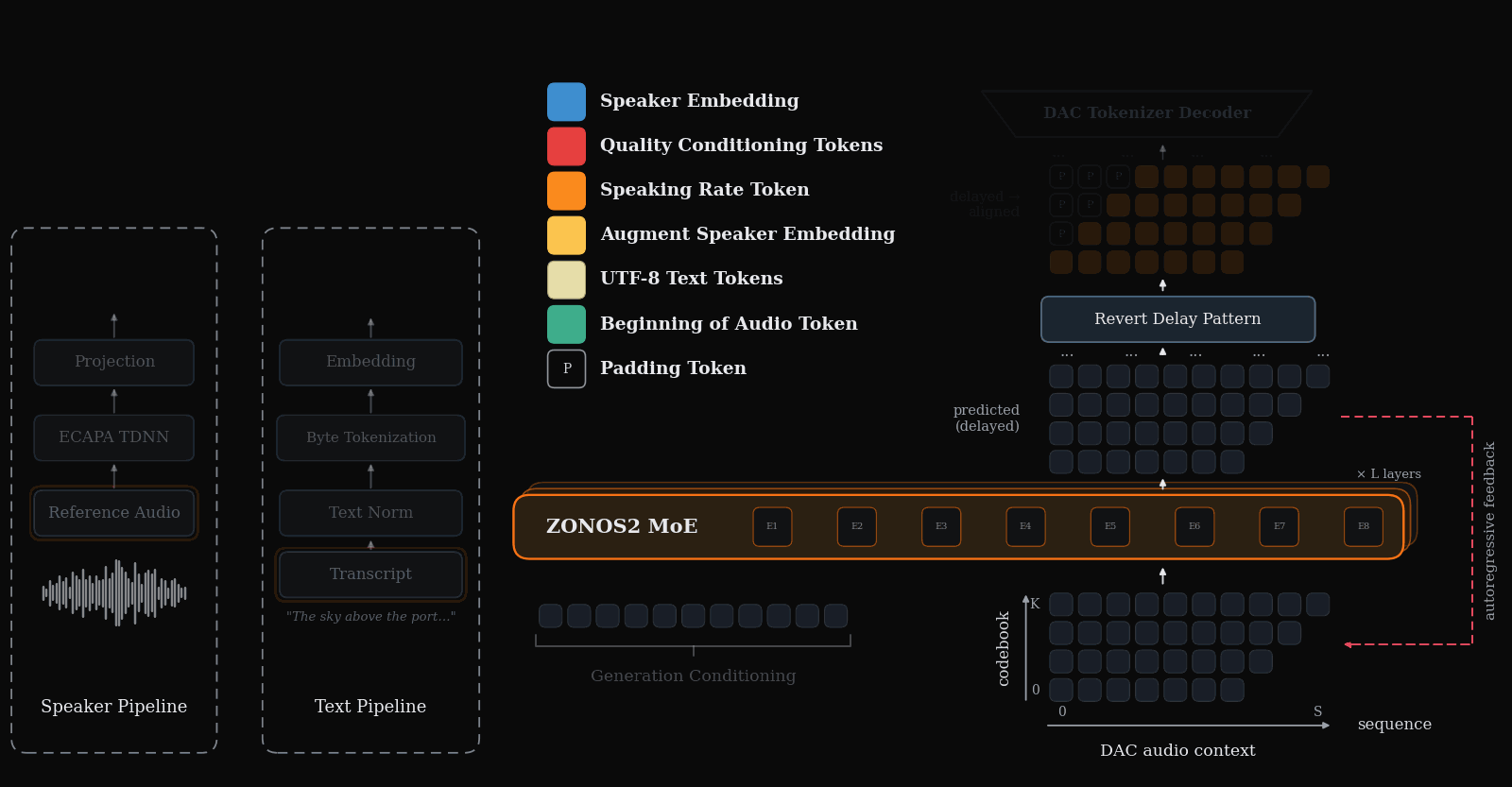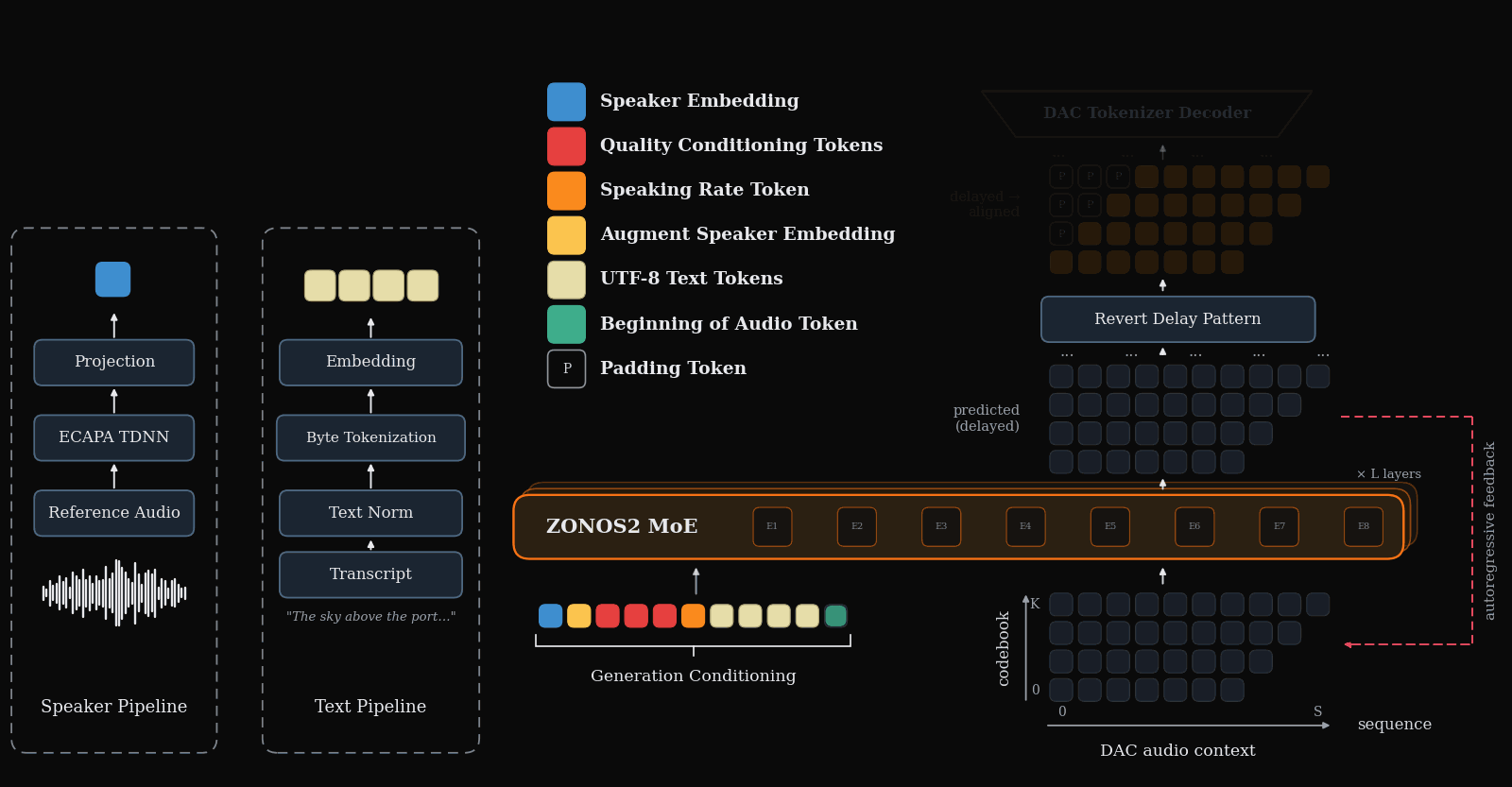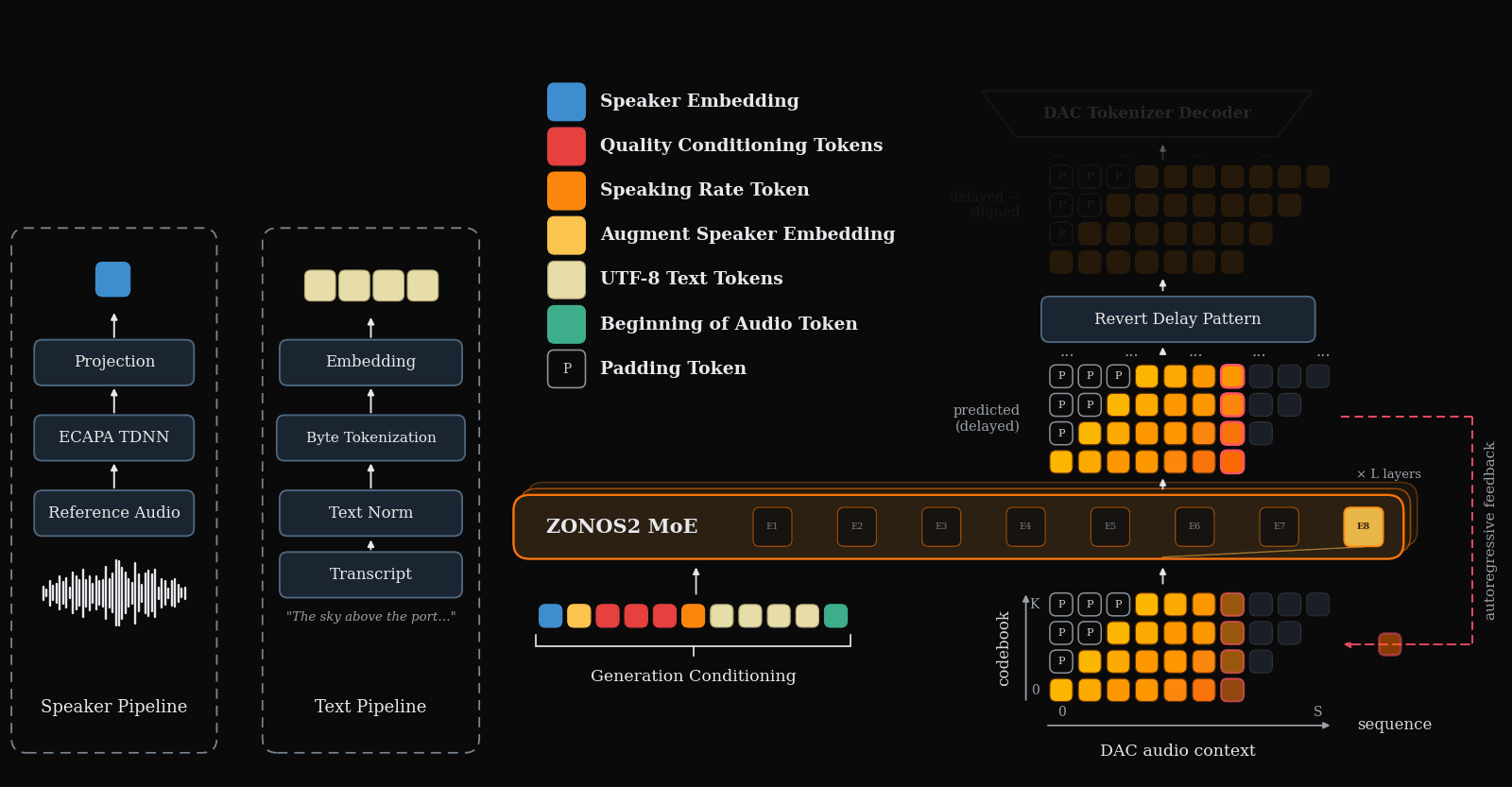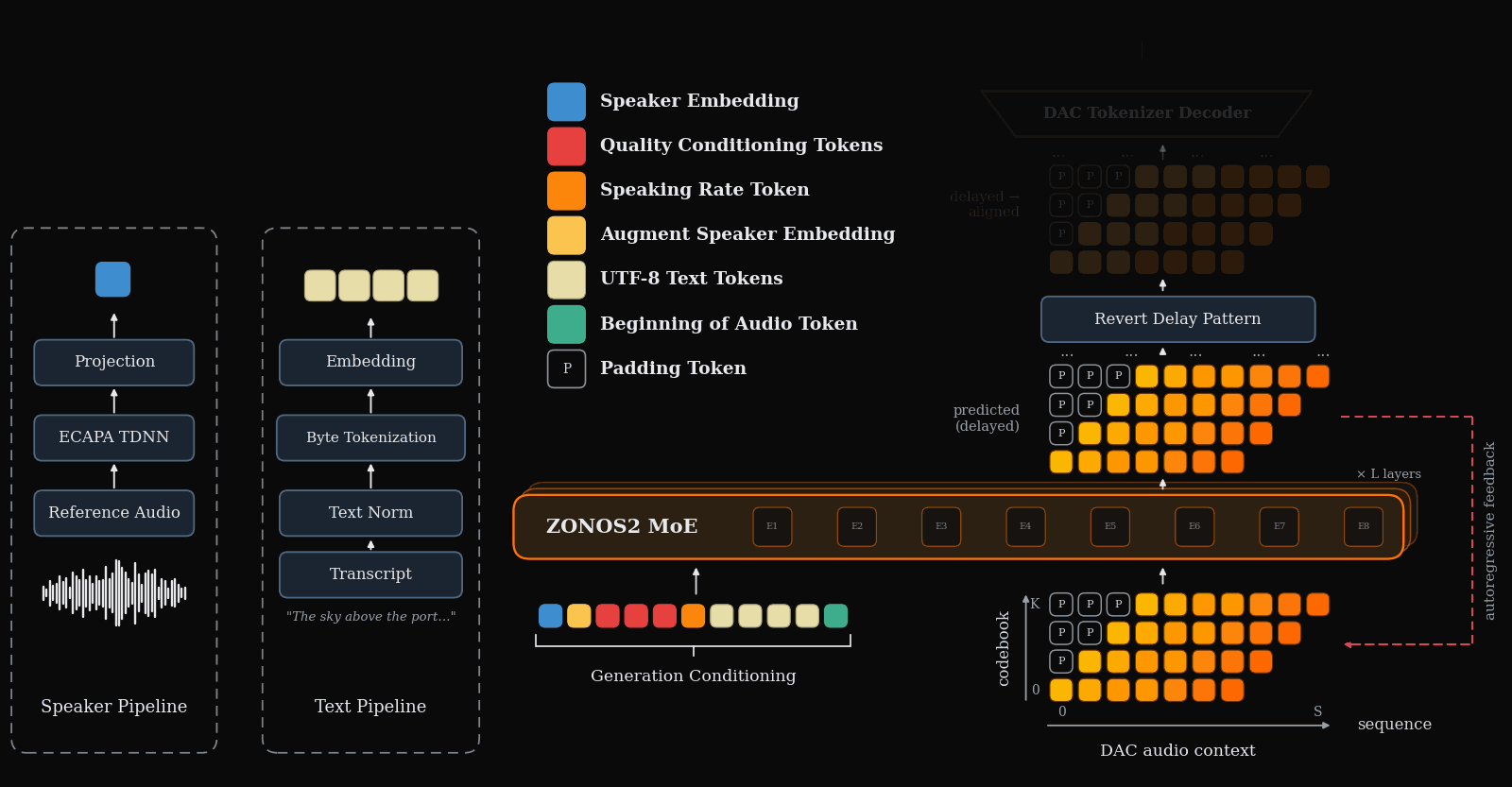
ZONOS2 is an advanced text-to-speech model that excels in naturalness, prosody, and zero-shot voice cloning across multiple languages. It uniquely combines a large-scale mixture-of-experts architecture with a massive multilingual training corpus and simplified conditioning for high-quality, low-latency streaming TTS.
Demos
The demos showcase ZONOS2, a multilingual text-to-speech MoE model excelling in expressiveness, naturalness, and voice cloning across many languages. Evaluate the synthesis quality by noting the high-fidelity voice reproduction, low latency, and naturalistic output. The animated GIF demo highlights these capabilities, showing strong audio-visual synergy and voice realism.

Links
Paper & demos
Code & resources
Abstract
We present ZONOS2 8B, our latest TTS model, which achieves state-of-the-art naturalness, prosody, and voice cloning fidelity. We improve upon Zonos-v0.1 across scale, data, and training recipe. We scale the model from 1.6B to 8B total parameters (900M active) with a novel mixture-of-experts (MoE) backbone, improving inference latency and throughput. We expand our training corpus from 200K to over 6M hours using a new data processing pipeline, and we simplify our post-training and conditioning recipes to improve naturalness and voice cloning fidelity. We evaluate ZONOS2 8B on quality, speaker similarity, WER, and ZTTS1-Eval, our novel TTS benchmark, where it performs competitively with state-of-the-art systems while maintaining good streaming latency. We release our model weights and example inference code under an Apache 2.0 license on GitHub and Hugging Face.
Introduction
ZONOS2 8B is presented as an open-source text-to-speech system targeted at the difficult combination of naturalness, prosody, voice cloning fidelity, multilingual robustness, and streaming efficiency. The paper’s central claim is that these goals can be improved simultaneously by scaling three things together: model capacity, training data scale and quality, and a simplified conditioning/post-training recipe.
The report positions ZONOS2 as a successor to Zonos-v0.1. Compared with the earlier system, it moves from 1.6B total parameters to 8B total parameters with 900M active parameters through a mixture-of-experts (MoE) decoder-only transformer backbone, expands the training corpus from roughly 200K hours to 6.2M hours, and replaces phoneme-based input text with byte-level tokenization. It also introduces a new benchmark, ZTTS1-Eval, designed to go beyond older read-speech English/Chinese evaluations by adding multilingual spontaneous speech plus prosody and diversity metrics.
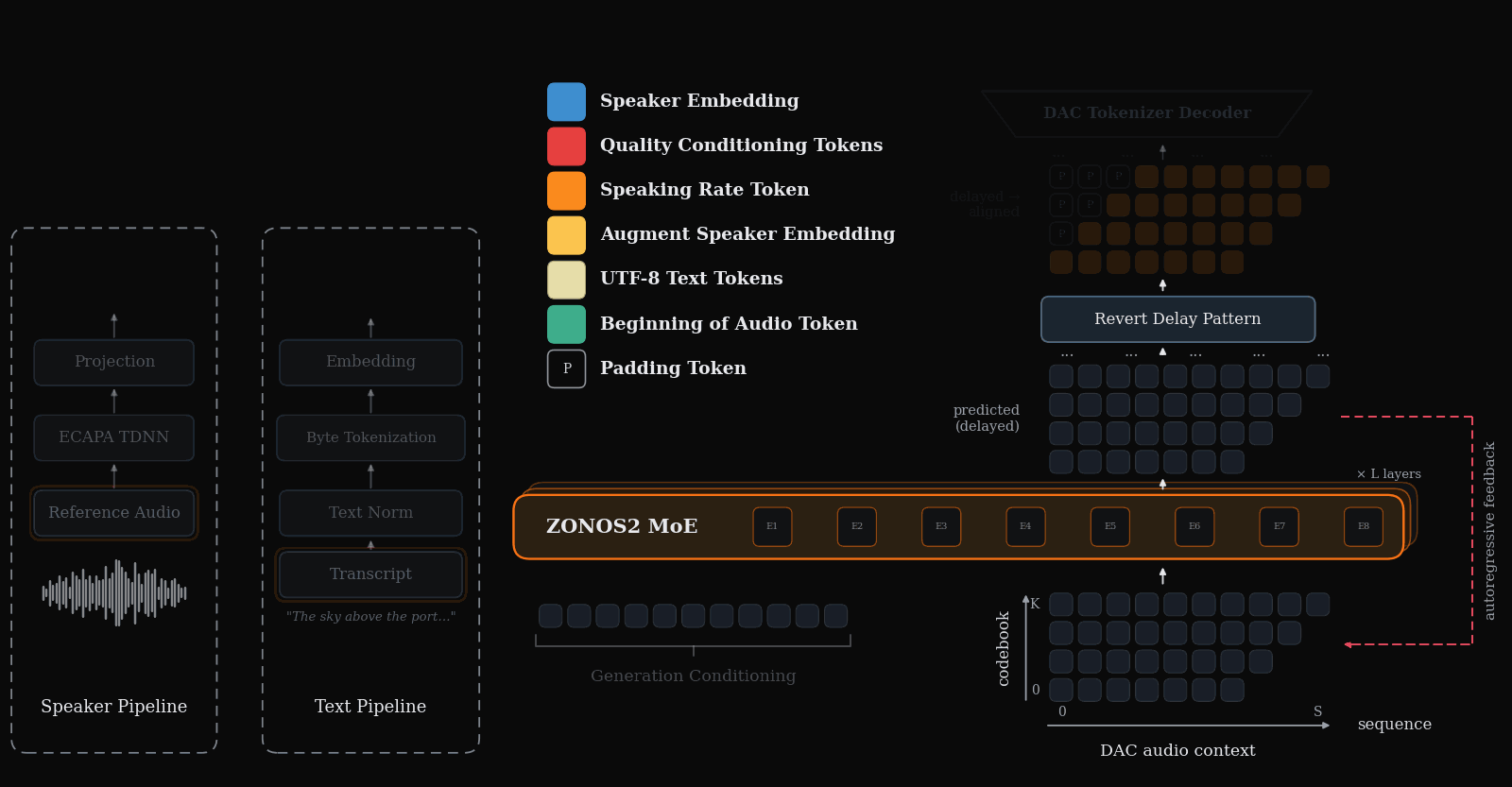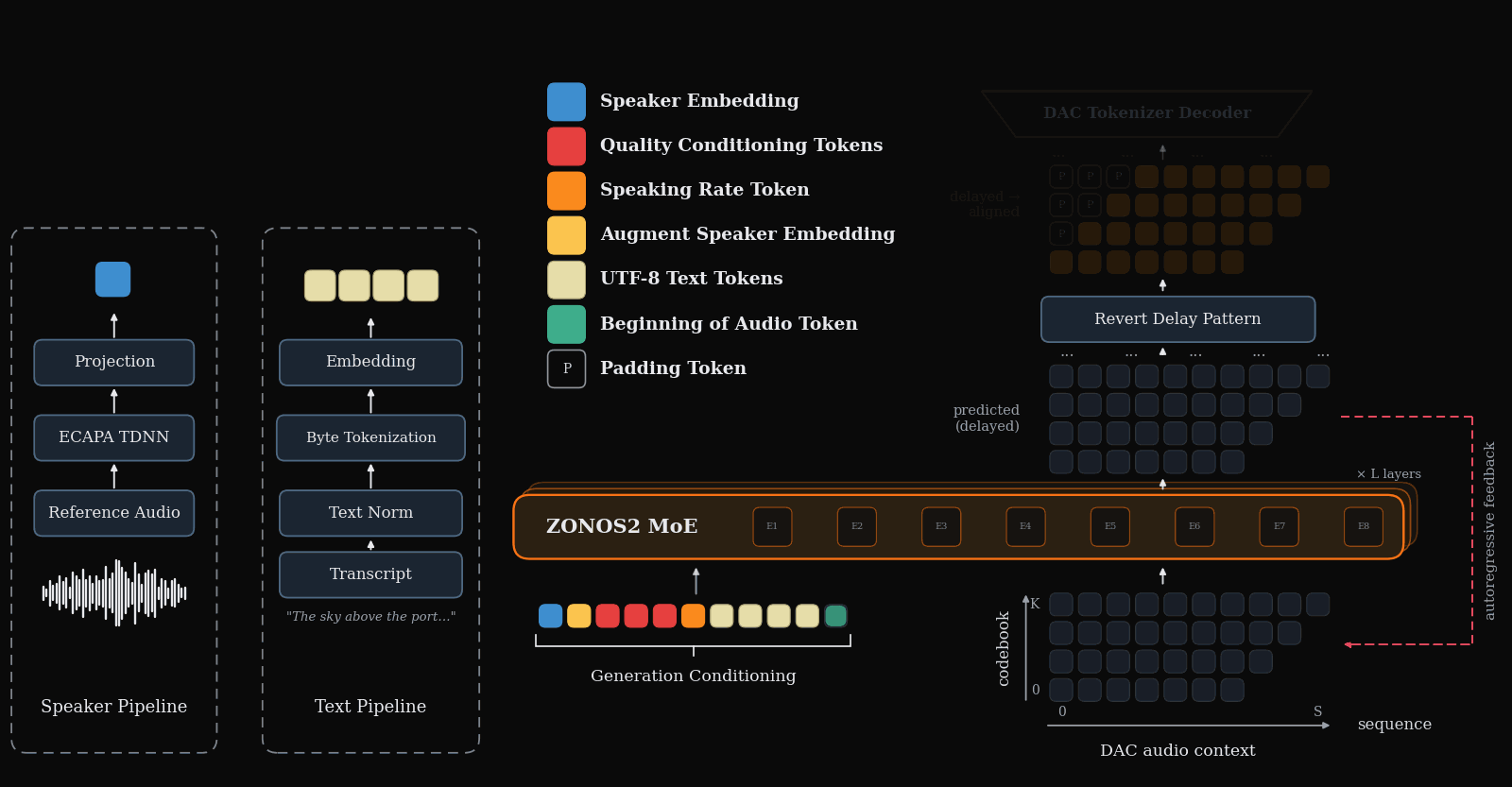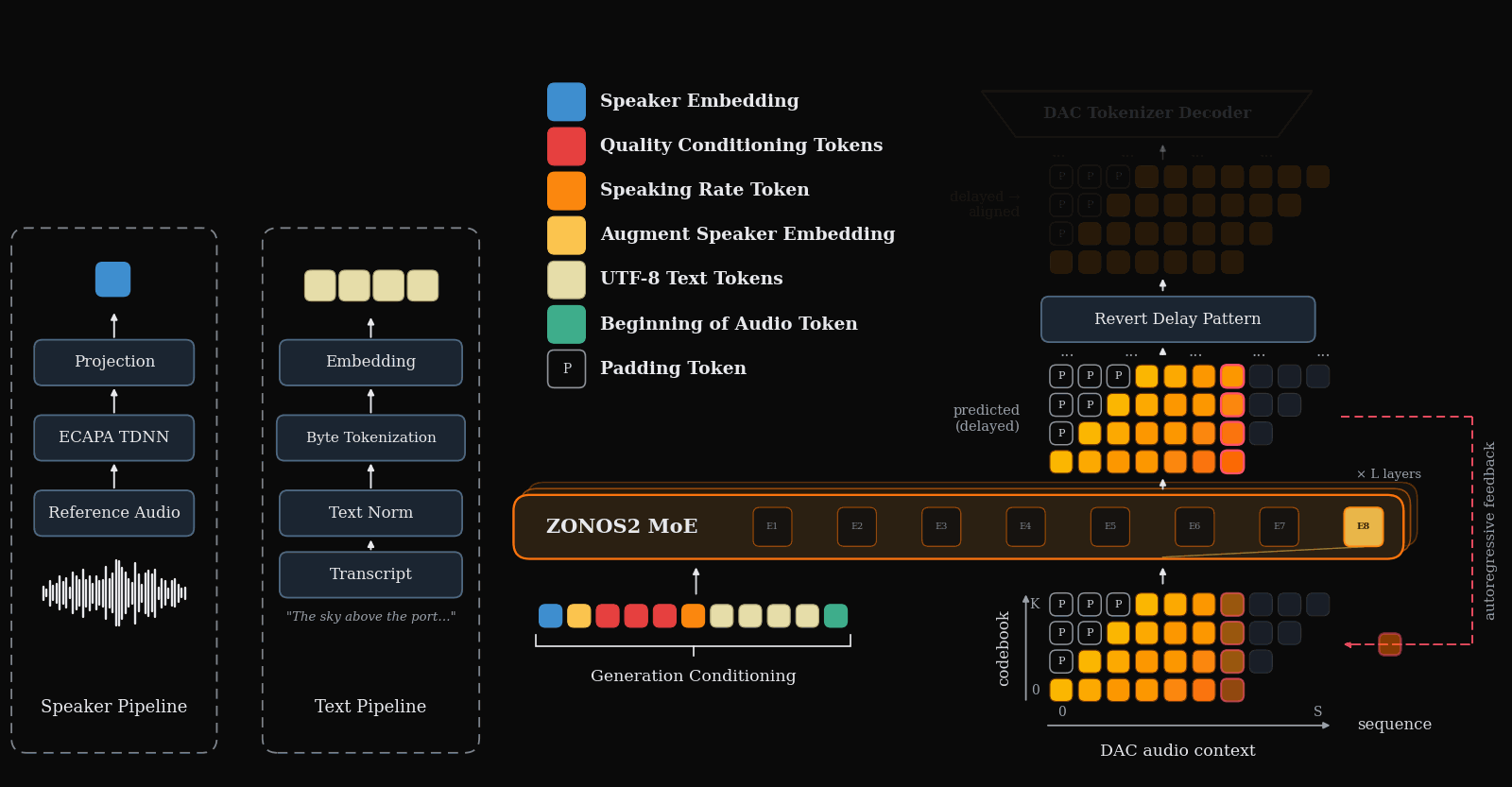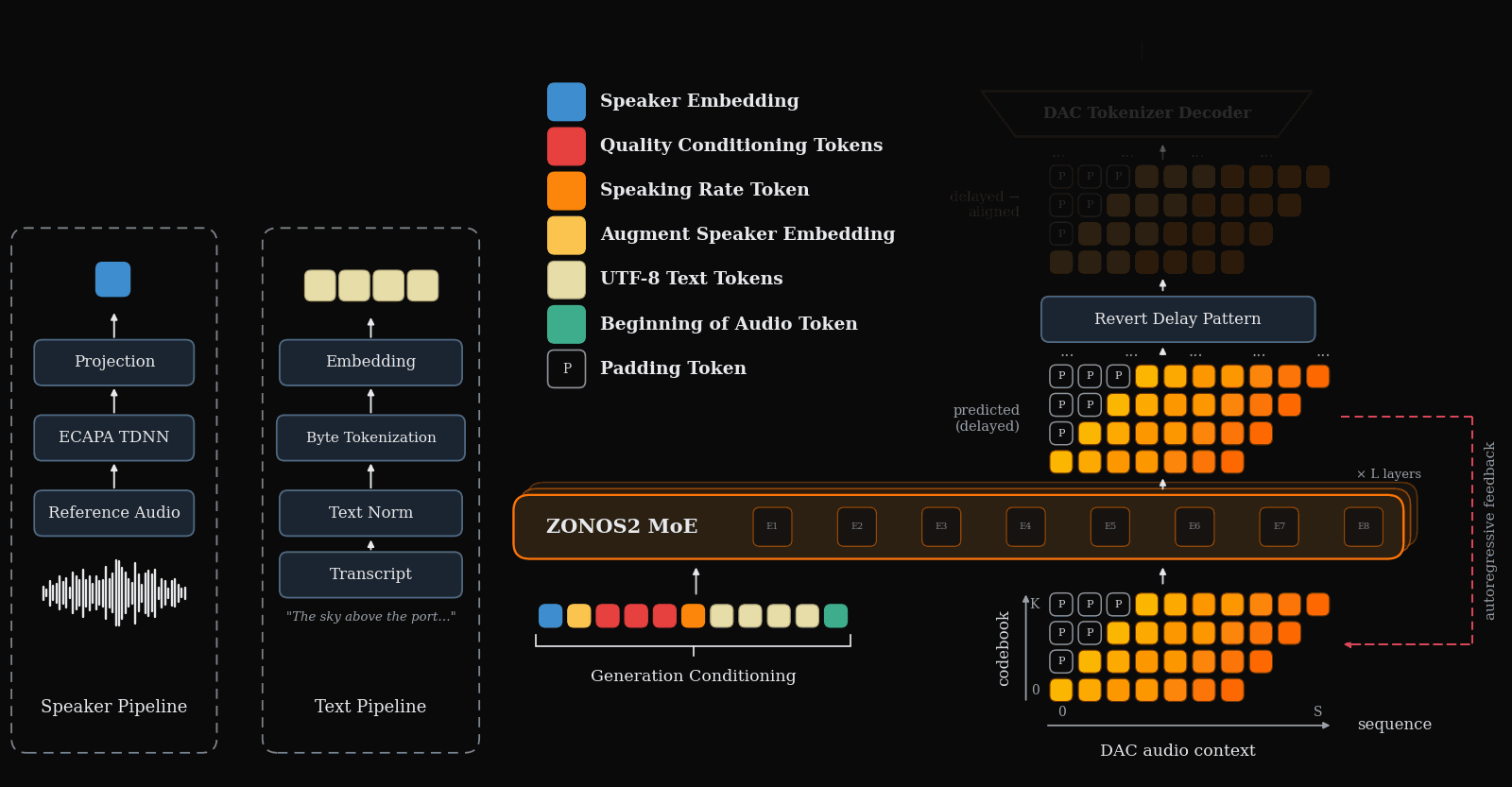
Figure 1 gives the end-to-end inference picture: text, optional speaker conditioning, and other control tokens are packed together with delayed audio-codec tokens, then decoded autoregressively into speech.
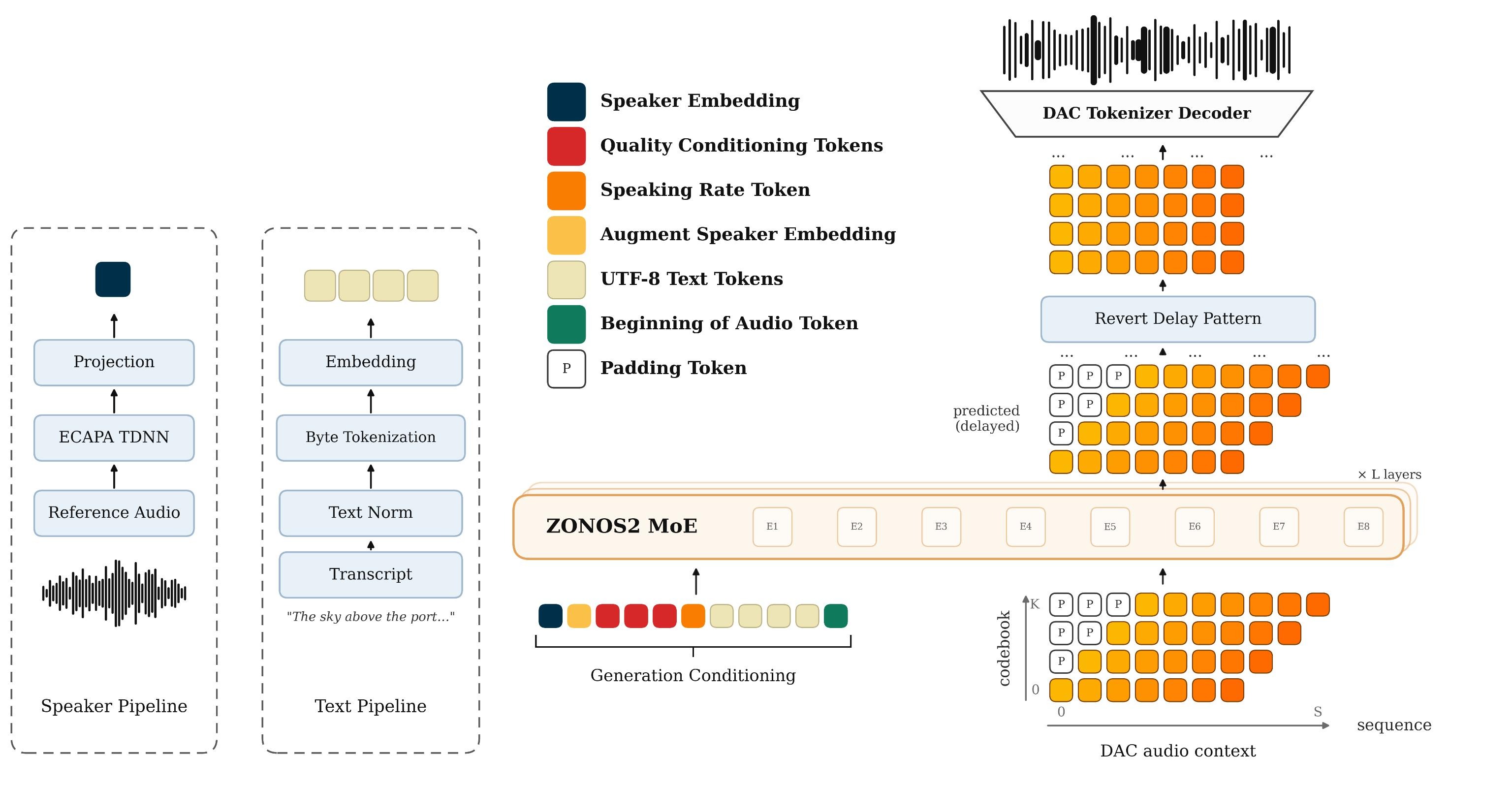
Model overview
ZONOS2 is an autoregressive conditional language model over Discrete Audio Codec (DAC) tokens. Audio is first quantized with a residual vector quantization codec, and the transformer predicts the next delayed codebook frame given the preceding text and audio context. The model is deliberately built around a streaming-friendly “delay pattern” representation that turns within-frame codebook dependencies into a causal sequence the decoder can model.
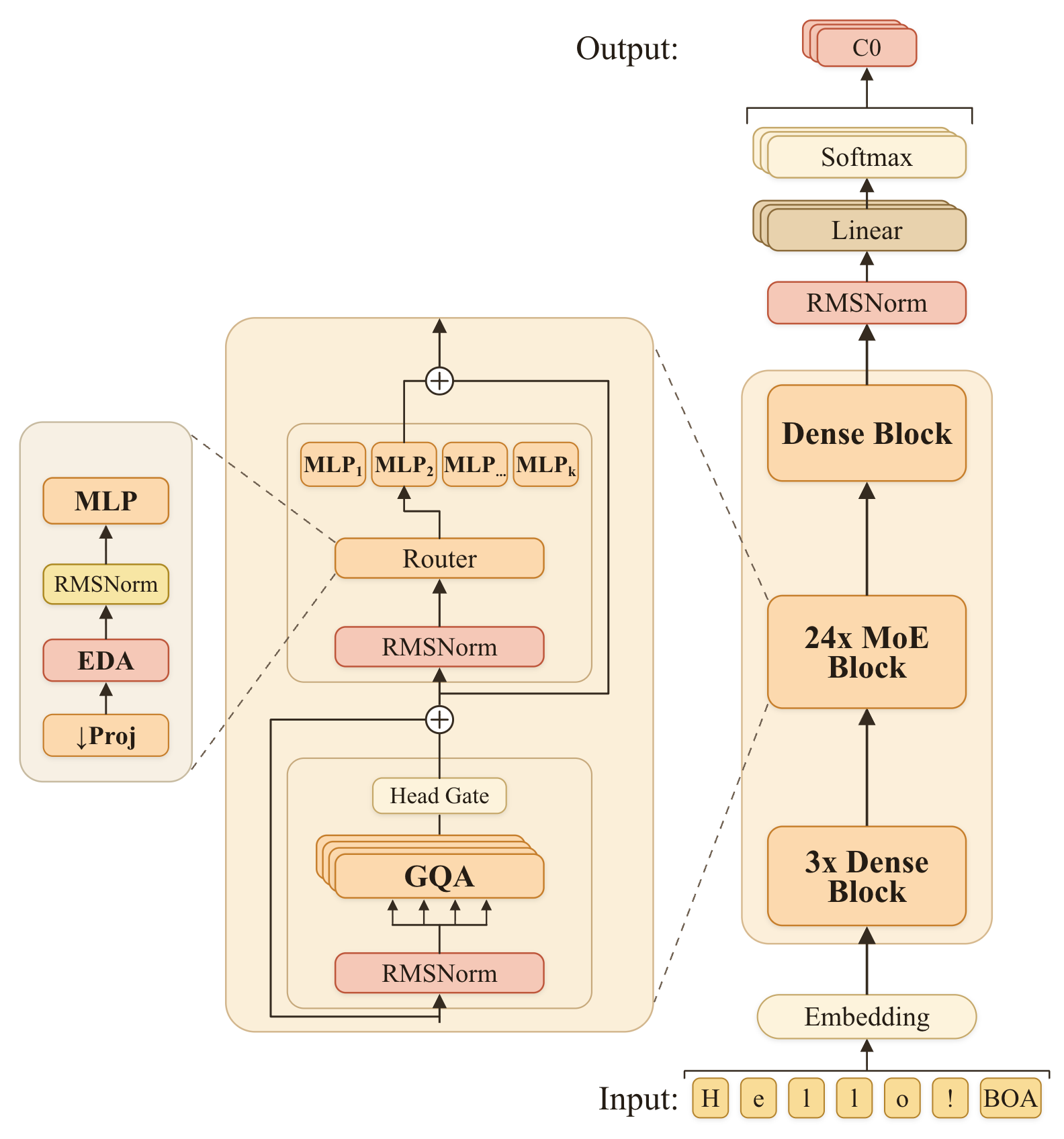
At a high level, the backbone is a 28-layer decoder-only MoE transformer with a 2048-dimensional hidden state. Attention uses grouped query attention (GQA) with headwise gating, and the feed-forward blocks are either dense SwiGLU blocks or routed MoE MLPs. The architecture details are summarized below.
| Property | ZONOS2 8B configuration |
|---|---|
| Architecture | Decoder-only MoE transformer |
| Total parameters | 8B |
| Active parameters | 900M |
| Transformer layers | 28 |
| Hidden dimension | 2048 |
| Query heads | 16 |
| KV heads | 4 |
| Head dimension | 128 |
| Experts per MoE layer | 16 |
| Routing | Top-1 in MoE layers, top-2 in the final MoE layer |
| Expert FFN width | 3072 |
| Router latent dimension | 128 |
| Router configuration | Exponential depth averaging (EDA) |
| Positional embeddings | RoPE |
| Tokenizer | Byte-level UTF-8 |
Audio tokenization and the delay pattern
ZONOS2 uses a residual-vector-quantized audio codec with $N=9$ codebooks. If $X[t,j]$ denotes the aligned token for audio frame $t$ and codebook $j$, the delay pattern shears the codebooks in time:
$$ Y[t,j] = \begin{cases} X[t-j,j] & \text{if } t \ge j, \\ p & \text{otherwise}, \end{cases} $$
where $p$ is a padding token. This makes codebook generation autoregressive across sequence positions rather than conditionally independent within a frame. Before decoding, the shear is inverted by
$$\hat{X}[t,j] = Y[t+j,j].$$
The practical consequence is streaming with a lookahead of $N-1$ generated frames before all codebooks for an aligned frame are available for DAC decoding. This is one of the paper’s key latency/quality compromises: it preserves codebook dependency structure while remaining streamable.
Text tokenization
Unlike Zonos-v0.1, which used phonemes, ZONOS2 tokenizes text at the byte level. Each input string is encoded as UTF-8 bytes, giving a language-agnostic representation that avoids language-specific grapheme-to-phoneme front ends and out-of-vocabulary handling. The paper argues that phonemization’s inductive bias becomes less valuable as scale increases, while its failure modes become increasingly harmful for code-switched text, rare words, technical vocabulary, and lower-resource languages.
The paper gives representative silent failures in the G2P pipeline, including code-switching corruption, false substring matches such as alpharetrovirus becoming retroretrovirus, and pronunciation loss in names like Satoshi when forced through a language-specific phoneme inventory. Byte tokenization is chosen as the simplest representation that remains fully general across languages.
Speaker embeddings and zero-shot cloning
For zero-shot speaker cloning, ZONOS2 conditions on a 2048-dimensional ECAPA-TDNN speaker embedding extracted from a reference utterance. The embedding is not fed as waveform or token sequence; it is inserted as a single prefix position, keeping context cost negligible even if the reference audio is long. The paper emphasizes that this allows cloning without requiring a transcription of the prompt audio at inference time.
Because the raw embedding also carries nuisance factors such as duration, recording conditions, lexical content, and pause structure, the model projects it through linear discriminant analysis (LDA) to a 1024-dimensional vector and then applies a learned projection:
$$h_{\mathrm{spk}} = W_{\mathrm{spk}}\hat{\mathbf{e}}_x + b_{\mathrm{spk}}.$$
The authors report that this LDA step is essential: without it, the model overfits to shortcut cues from the prompt embedding before it can learn robust cloning behavior.
Speaking-rate and quality conditioning
ZONOS2 adds two other user-facing controls. Speaking rate is computed by stripping symbols, annotations, whitespace, and punctuation from the transcript, then dividing the remaining UTF-8 byte count by utterance duration. The resulting rate is bucketed and prepended as a token. Quality conditioning adds tokens for acoustic properties such as bandwidth, loudness, silence frames, and estimated signal-to-noise ratio, and the paper also introduces a dedicated Quality Mode token that biases toward intelligibility and acoustic cleanliness at the cost of some cloning fidelity.
The conditioning recipe also includes audio augmentations during training: background noise or music mixing, codec compression, and reverberation. These are used to make the model less sensitive to poor-quality clone prompts.
Training objective and optimization
The model is trained as a standard causal language model over packed sequences containing optional control tokens, byte-tokenized text, and delayed audio-codec frames. The logits are soft-capped before the softmax for stability:
$$\tilde{\ell}_{t,j} = \tau \tanh\!\left(\frac{\ell_{t,j}}{\tau}\right), \qquad \tau = 15.$$
The main objective is masked negative log-likelihood over non-padding audio targets:
$$
\mathcal{L}_{\mathrm{NLL}} = -\frac{1}{M_{\mathrm{aud}}} \sum_{t,j} m_{t,j} \log p_\theta(Y[t+1,j] \mid s_{ where the mask excludes padded audio positions. A separate MoE balancing term encourages uniform expert utilization: $$
\mathcal{L}_{\mathrm{bal}} = \sum_{\ell \in \mathcal{M}} b_\ell^\top \operatorname{sg}(u_\ell - \bar{u}),
\qquad
\mathcal{L} = \mathcal{L}_{\mathrm{NLL}} + \mathcal{L}_{\mathrm{bal}}.
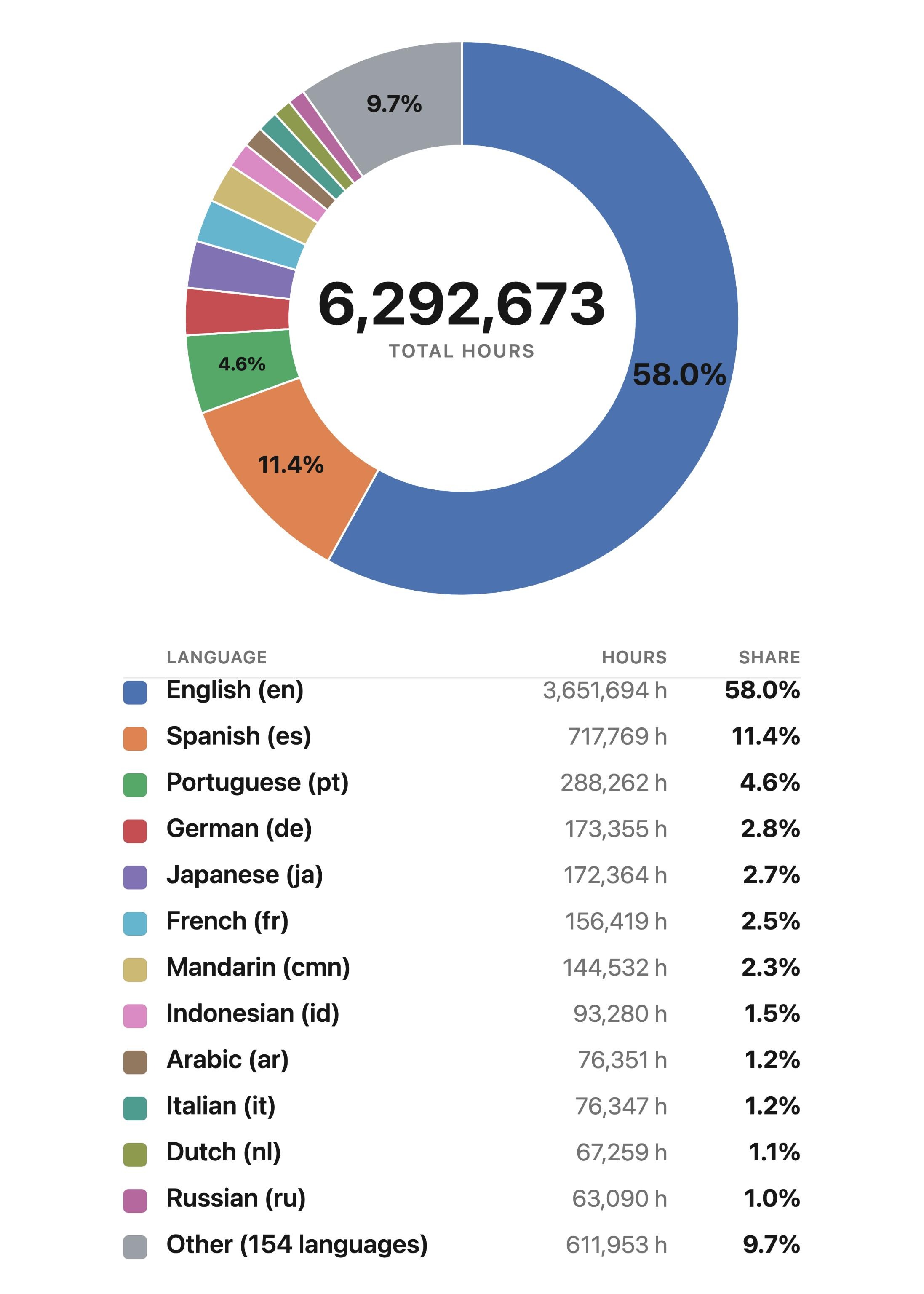
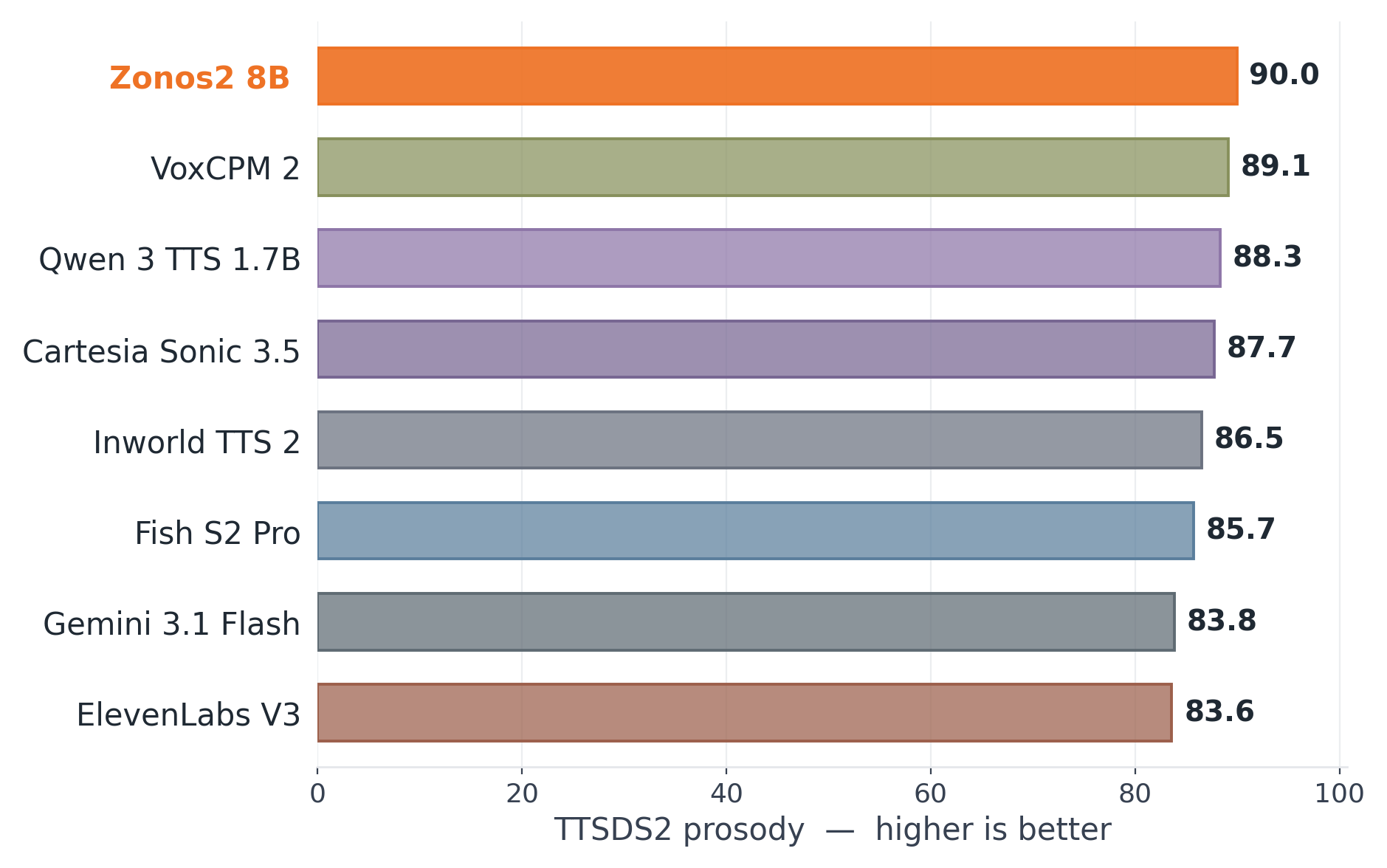
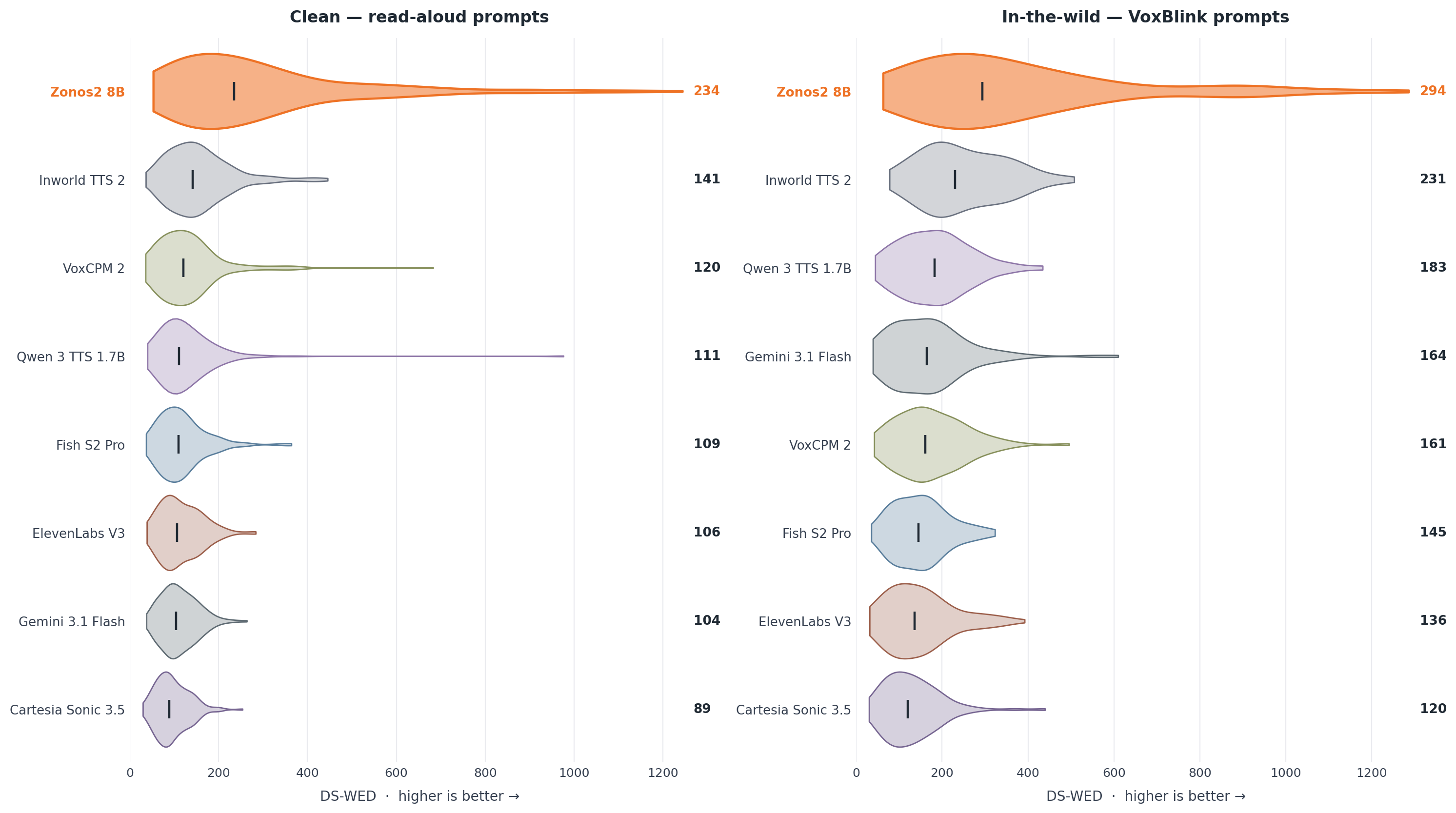
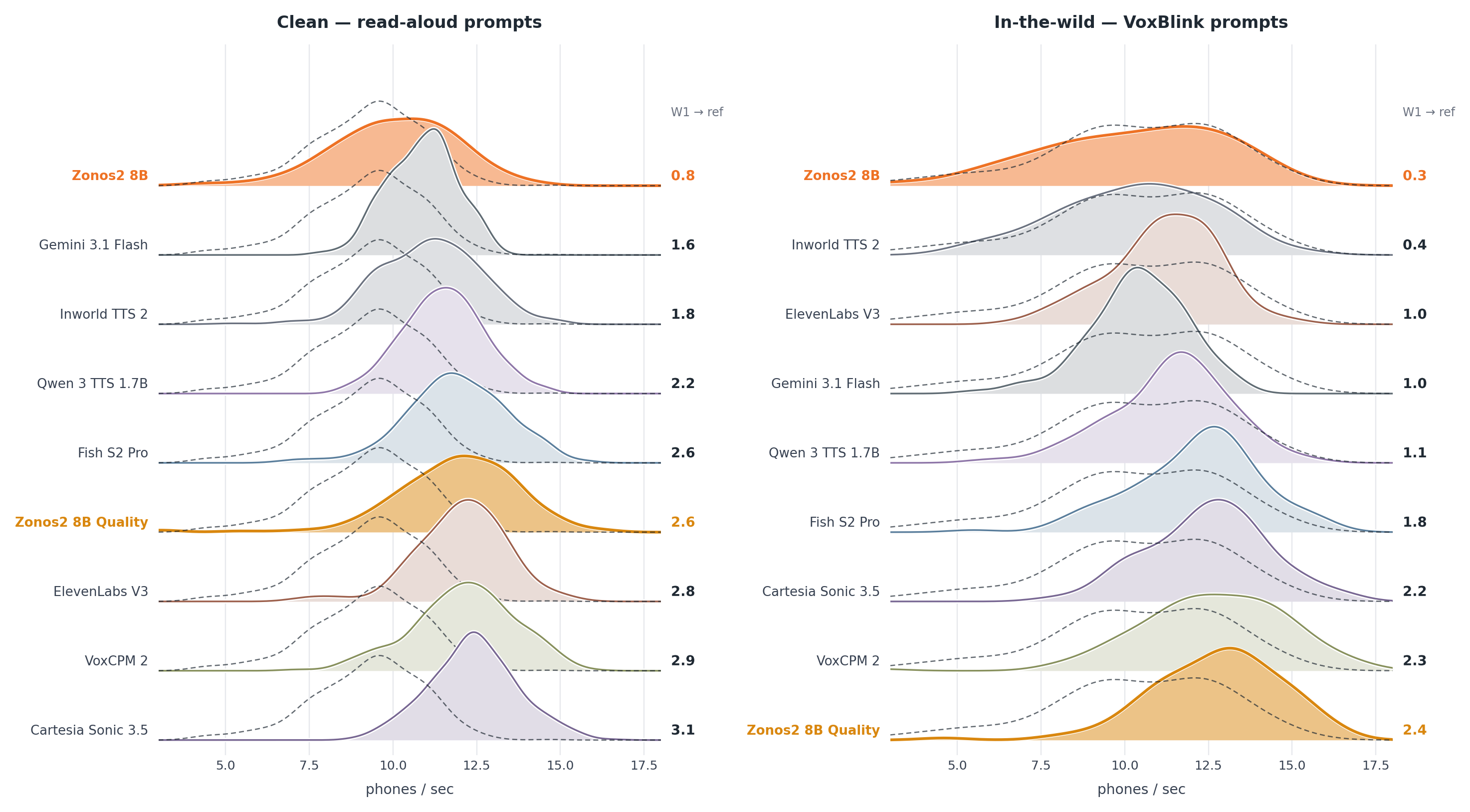
$$ The paper notes that balancing on delayed audio tokens is substantially harder than on text and required manual intervention during training. Within each transformer layer, the paper uses a pre-norm residual pattern with RMSNorm, GQA, RoPE, query-key normalization, and FlashAttention. The attention output is modulated by a headwise gate, following the Qwen-style gating idea the authors say worked best in their ablations. For the feed-forward block, the dense version is a SwiGLU MLP; routed layers use 16 experts, top-1 routing in most layers, and top-2 routing in the last MoE block. The authors also report several stability fixes discovered during training. The first three layers and the final layer are kept dense; the final routed layer uses top-2 routing; and balancing/router learning rates were adjusted manually in response to expert collapse. The paper explicitly says MoE balancing on audio is harder than on text and suggests the delayed codec-token structure may be one reason. ZONOS2 is trained on a web-scale speech corpus totaling 6.2 million hours. The dataset spans public speech corpora, podcasts, public-domain audiobooks, conversational data, multilingual web speech, and expressive or character-driven datasets. The paper emphasizes that the final model benefits from broad language coverage while also preserving high-quality expressive and dialogue-style audio through dataset-specific sampling weights. The data-processing pipeline is two-stage. First, a voice-activity detector segments raw audio into utterance-level clips. Second, multiple ASR systems independently transcribe each utterance. The training set is filtered by inter-ASR agreement, measured with pairwise WER between the ASR outputs. Utterances with low agreement are removed, and the threshold is adjusted by training stage: lower during pre-training to preserve diversity, higher during annealing to sharpen the final model. This ensemble transcription setup is also used to reduce overfitting to a single transcription style by allowing different transcripts to be sampled for the same utterance over the course of training. The language pie chart shows that English dominates the corpus, but the authors stress that the model generalizes well across languages that make up only a small fraction of the data, helped by byte tokenization and the multilingual data pipeline. Alongside the model, the paper introduces ZTTS1-Eval, a new benchmark for expressive, zero-shot, voice-cloning TTS. The benchmark is explicitly designed to address limitations the authors identify in Seed-TTS-Eval and related datasets: limited language coverage, dated scorers, and a lack of spontaneous speech and prosody/diversity measurement. ZTTS1-Eval has two subsets. The Clean set contains 500 utterances per language from FLEURS-R for 9 languages: English, Chinese, German, Spanish, French, Italian, Japanese, Korean, and Russian. It totals about 13 hours and is intended to represent prepared read-aloud speech, with “hard” subsets for difficult English and Chinese utterances. The in-the-wild set contains 1,618 utterances from VoxBlink2 across 17 languages, totaling about 2.86 hours. These clips are conversational and spontaneous, providing a better test of real-world cloning and prosodic robustness. The ITW language breakdown is balanced across languages such as English, Mandarin, German, Spanish, French, Italian, Japanese, Korean, Russian, Portuguese, Arabic, Hindi, Indonesian, Turkish, Tagalog, Polish, and Thai. Evaluation uses multilingual Qwen3-ASR for WER, ReDimNet for speaker similarity, MSR-UTMOS for audio quality, TTSDS2 for prosody, and DS-WED for generation diversity. The paper emphasizes that ZONOS2 is not trained on any ZTTS1-Eval audio. The main tables report zero-shot results on both Clean and ITW subsets, with and without the Quality Mode token. The authors compare ZONOS2 to a set of open-source and closed-source baselines. Across both subsets, the paper’s headline message is that ZONOS2 is highly competitive, especially for speaker similarity and prosody, while preserving good streaming behavior. However, it is not uniformly the best on WER or UTMOS; some baselines, especially Qwen 3 TTS 1.7B and several closed-source systems, outperform it on intelligibility/quality on many languages. On the Clean subset, the paper highlights that ZONOS2 achieves the best open-source and second-best overall speaker similarity for English. Quality Mode has a mixed effect on WER: it improves Mandarin substantially, but worsens English WER while still raising UTMOS. In other words, Quality Mode is a real tradeoff knob rather than a free win. Against the baselines, the paper reports that Qwen 3 TTS 1.7B generally leads on WER and UTMOS across many Clean languages, while closed-source systems such as Cartesia Sonic 3.5 and Gemini 3.1 Flash often have the strongest speaker similarity among the zero-shot-capable comparisons. ZONOS2 remains competitive despite being open-source and focuses on balanced quality plus cloning fidelity. On the ITW set, Quality Mode is more consistently beneficial: it improves WER and UTMOS across languages, though speaker similarity usually drops. The paper interprets this as the expected intelligibility-versus-identity tradeoff. ZONOS2 remains strong on both WER and similarity, and the authors emphasize that it maintains good streaming latency. For the English portions of ZTTS1-Eval, the paper also studies prosody directly. Mean TTSDS2 prosody is competitive on the Clean set and best on the ITW set, while DS-WED violin plots show ZONOS2 producing substantially more prosodic variation than the compared systems. The Allosaurus SR distribution plot further suggests that the generated prosody distribution is closer to the source-clone distribution than the baselines. The paper also reports additional benchmark checks in the appendix. On CosyVoice 3 Eval, ZONOS2 records, for example, speaker similarity of 49.66 on English zero-shot, 56.93 on Chinese, and 58.75 on Korean, with the corresponding WERs of 4.48, 12.08, and 6.03. On Seed-TTS-Eval, ZONOS2 reports 47.60 speaker similarity and 2.05 WER on Test-EN, 58.20 speaker similarity and 2.55 WER on Test-ZH, and 56.2 speaker similarity with 11.15 WER on Test-ZH-Hard. These appendix results reinforce that the system is broadly competitive on older benchmark families as well. The discussion section is especially useful because it documents what the authors tried and what turned out to matter most. These observations matter because they define the practical limits of the architecture. The model’s gains are not just a consequence of scale; they depend on training recipes that reduce information leakage, stabilize expert routing, and control the mismatch between prompt audio and target generation. The paper is unusually explicit about limitations. First, routing on audio is harder to balance than routing on text, so the final MoE design is partly a stability compromise. Second, GQA is chosen for speed despite MHA looking better in ablation. Third, speaker-embedding conditioning still carries nuisance information even after LDA, so cloning quality remains sensitive to prompt choice and conditioning mode. The authors also suggest that alternative audio codecs may reduce instability and improve generation robustness and efficiency. They similarly flag further work on backbone design and post-training strategy as promising directions. In short, ZONOS2 is presented not as a solved endpoint but as a strong open-source baseline that demonstrates MoE TTS scaling is viable. ZONOS2 8B is a technically ambitious open-source TTS system that combines a large MoE transformer, byte-level multilingual text input, DAC-based audio tokenization, and carefully engineered conditioning for voice cloning and controllable generation. Its main empirical strengths are cloning fidelity, prosody, multilingual robustness, and competitive overall quality on a new benchmark that better reflects modern use cases than older read-speech-only evaluations. The core technical takeaways are: scaling helps, but only when paired with a stable MoE routing recipe; byte-level text avoids G2P brittleness; prompt-embedding leakage must be actively suppressed; and the right benchmark needs to measure not just WER and speaker similarity, but also prosodic behavior and diversity. The paper’s release of the model weights, example inference code, and ZTTS1-Eval under an Apache 2.0 license is positioned as a contribution to the open TTS ecosystem. This repository contains the implementation and model weights for the ZONOS2 8B text-to-speech (TTS) system described in the paper. It includes the core TTS model using a mixture-of-experts (MoE) backbone designed for efficient and expressive speech synthesis, trained on over 6 million hours of multilingual speech data. The main codebase is organized under the The README provides concise usage instructions for launching the inference server and using the Python API with example code snippets, supporting streaming audio generation and fine-tuning inference parameters such as speaking rate and sampling temperature. Overall, the codebase directly supports the methods and evaluation protocols presented in the paper, providing both the model and interface for reproducing synthesis results.Training schedule
Stage
Steps / tokens
Key setup
Pre-training
77,500 steps; 2.9T tokens
No speaker or quality conditioning; max length 6144 frames; global batch of 37.7M DAC frames, or about 121.8 hours of audio; Muon optimizer with base LR $5\times10^{-4}$, Muon LR $5\times10^{-3}$, weight decay 0.1, gradient clipping 0.5, 100-step warmup, cosine decay.
Mid-training
15,000 steps; about 560B tokens
Same core objective, but with stricter transcript-agreement filtering and more selective data weighting.
Annealing stage 1
10,000 steps
Introduces speaker embeddings, speaking-rate tokens, and quality conditioning; speaker embedding is computed from a cropped target segment and the loss on that crop is masked to reduce causal leakage; acoustic augmentation is applied with probability $\alpha_{\mathrm{AUG}}$; speaking-rate and quality tokens are independently dropped with probabilities 0.4 and 0.25.
Annealing stage 2
10,000 steps
Speaker embedding now covers the full target segment; loss masking on the embedded region is removed; the dedicated Quality Mode token is introduced on the highest-quality subset.
Data pipeline
ZTTS1-Eval benchmark
Benchmark
Languages
Audio
Duration
Prosody / diversity
Scorers
Seed-TTS-Eval
2
Read speech
3 h
None
Whisper-L / Paraformer for WER, WavLM for speaker similarity
CV3-Eval
9
Read and expressive
14 h
Task-specific
Whisper-L / Paraformer, ERes2Net, DNSMOS
MiniMax-ML
24
Read speech
Not specified in the paper
None
Seed-TTS-Eval protocol
ZTTS1-Eval
Up to 17
Read and in-the-wild spontaneous speech
16 h
TTSDS2 + DS-WED
Qwen3-ASR, ReDimNet, MSR-UTMOS
Experimental results
Representative Clean-set findings
Language
Setting
Speaker similarity
WER
UTMOS
English Base 78.6 2.76 3.40 English Quality Mode 74.4 3.99 3.47 Mandarin Base 73.3 15.62 3.10 Mandarin Quality Mode 81.1 6.73 3.21 Spanish Base 79.4 4.78 2.96 Spanish Quality Mode 79.0 3.25 2.94 Representative ITW findings
Language
Setting
Speaker similarity
WER
UTMOS
English Base 67.0 4.70 2.44 English Quality Mode 56.9 2.21 2.99 Mandarin Base 74.3 3.19 2.43 Mandarin Quality Mode 70.6 2.77 2.68 Hindi Base 66.3 15.50 2.47 Hindi Quality Mode 62.3 9.04 2.73 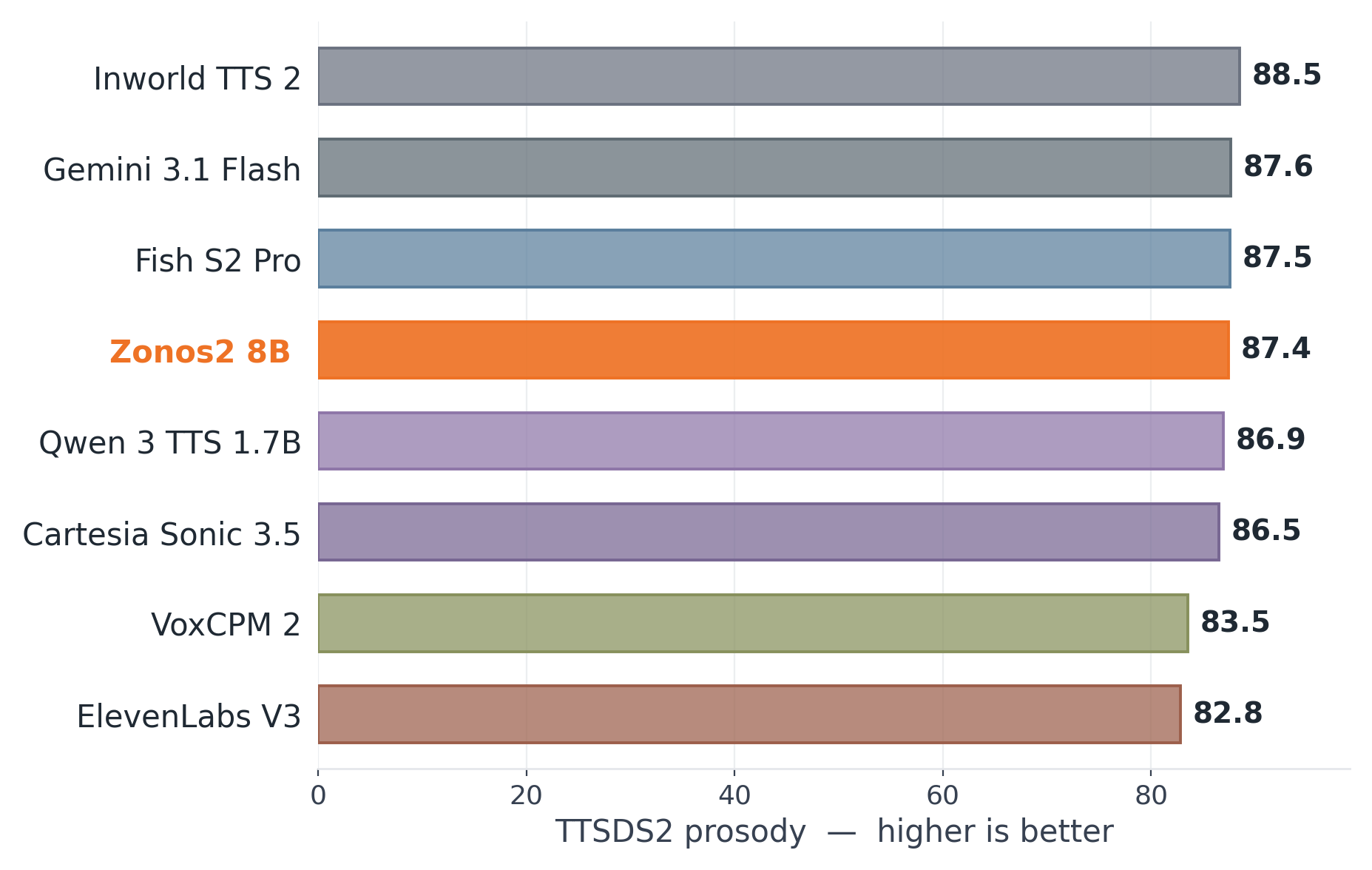
Ablations and discussion
Limitations and future work
Conclusion
Code & Implementation
python/zonos2/ directory and entry points for inference are accessible through a Python API and a high-performance TTS server built on Mini-SGLang, as detailed in the README. The model accepts normalized UTF-8 byte inputs with ECAPA-TDNN speaker embeddings and outputs discrete audio codec (DAC) tokens, aligning with the paper's described inference pipeline.