Wan-Streamer
Wan-Streamer v0.1: End-to-end Real-time Interactive Foundation Models
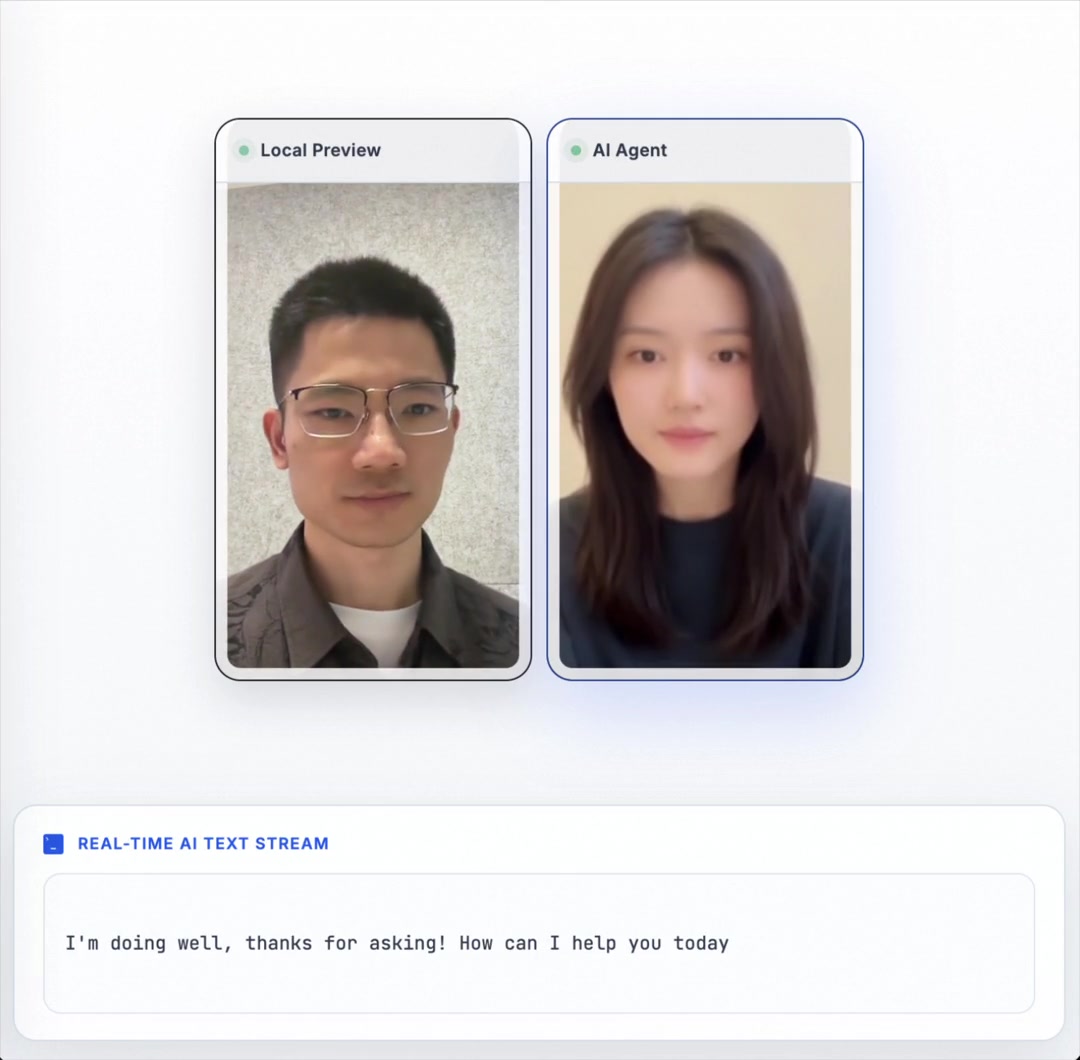
Wan-Streamer is an end-to-end interactive foundation model unifying text, audio, and video in a single Transformer for real-time full-duplex audio-visual interaction. It jointly learns perception and generation without separate modules, enabling sub-second latency streaming with synchronized multimodal responses.
Demos
These demos showcase Wan Streamer v0.1's real-time, end-to-end audio-visual interaction in a single Transformer. Watch for its low-latency, synchronized speech and video responses, natural full-duplex interaction, and coherent, expressive conversation across languages and scenarios. The real-time recording highlights simultaneous perception and response with low latency in a networked setting.

Links
Paper & demos
Abstract
We present Wan-Streamer, a native-streaming, end-to-end interactive foundation model designed from the ground up for real-time, low-latency, full-duplex audio-visual interaction. Wan-Streamer seamlessly models language, audio, and video as both input and output within a single Transformer, where the sequence is represented as interleaved visual, audio, and text input tokens together with visual, audio, and text output tokens, coordinated by block-causal attention for incremental streaming. Unlike cascaded interactive systems that rely on separate VAD, ASR, language, TTS, audio-driven animation, or video-generation modules, Wan-Streamer does not rely on external language, speech, avatar, or video-generation modules: perception, reasoning, generation, response timing, turn management, and cross-modal synchronization are learned jointly within one unified model, reducing pipeline latency and error accumulation. To support natural audio-visual responsiveness, we redesign the entire stack around streamability, including causal encoders, causal decoders, block-causal attention, and low-latency multimodal token scheduling, enabling streaming units as short as 160 ms at 25 fps. Wan-Streamer achieves approximately 200 ms model-side response latency and approximately 550 ms total interaction latency when combined with 350 ms bidirectional network latency, supporting sub-second duplex audio-visual communication. These results position Wan-Streamer as a unified, end-to-end, multimodal interactive foundation model for low-latency streaming interaction.
Introduction
Wan-Streamer v0.1 is presented as a native-streaming, end-to-end interactive foundation model for real-time, low-latency, full-duplex audio-visual interaction. The central design claim is that this setting should not be decomposed into separate perception, ASR, language, TTS, animation, and video-generation modules. Instead, the model treats language, audio, and video as both inputs and outputs in one causal sequence, so that perception, reasoning, response timing, turn management, and cross-modal synchronization are learned jointly.
The paper positions this as a modeling problem, not only a serving optimization problem. It argues that the agent must continuously consume user audio-visual observations while it is also producing its own speech and visual response, so the system must preserve a persistent interaction state across modalities and streaming units. The design target is sub-second duplex interaction rather than offline generation or turn-based dialogue.
Core Contributions
- A single-model formulation for full-duplex multimodal interaction, where text, audio, and video can all appear on both the input side and output side of the same causal stream.
- A fully causal multimodal stack built from strictly causal audio and video VAEs, causal audio-visual encoders and decoders, and a temporally causal Transformer with block-causal attention.
- A thinker-performer inference system that preserves a unified causal state while overlapping perception, decoding, and latent generation to reduce end-to-end latency.
- A training recipe that combines independent-task pretraining, end-to-end duplex interaction training, and distillation for low-latency streaming rollout.
Problem Formulation
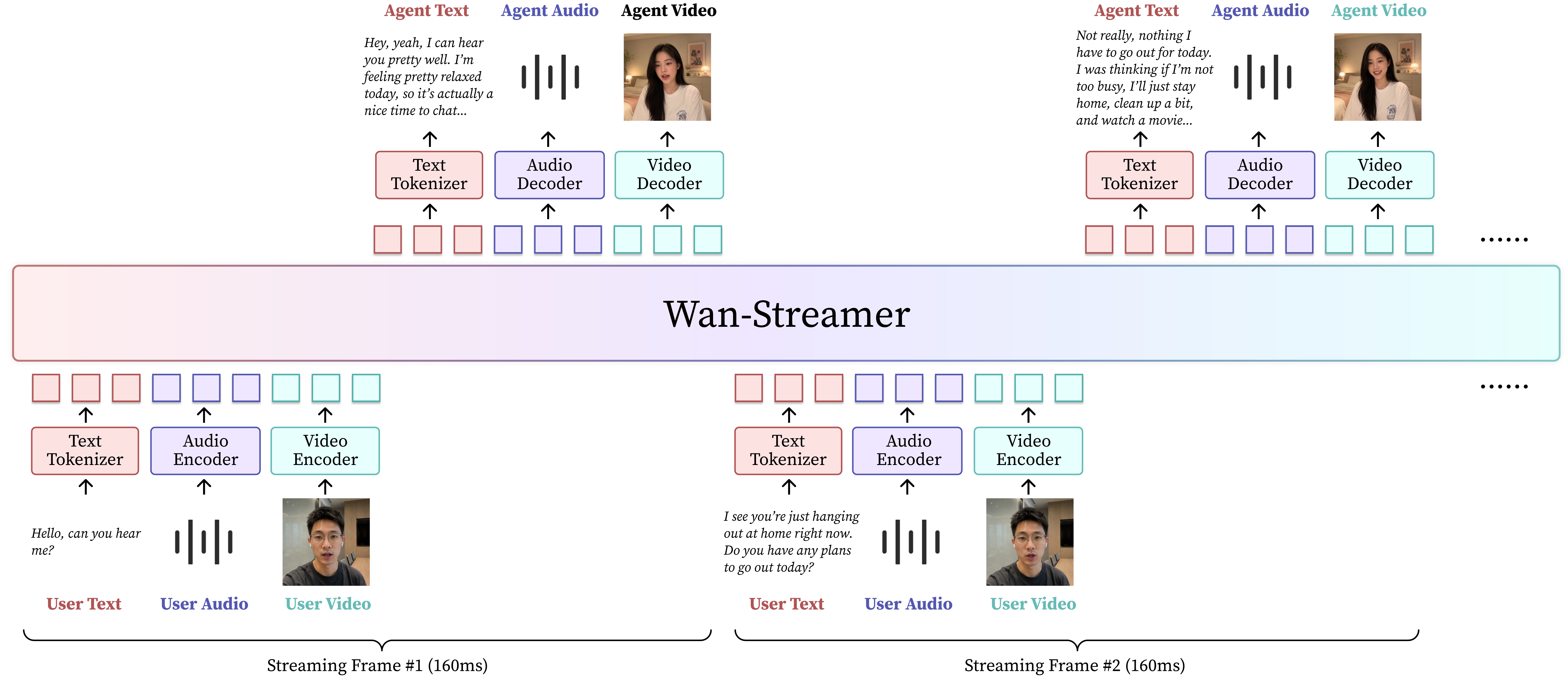
Wan-Streamer models the interaction as a causal stream indexed by streaming unit $k$. The user's observations are written as $u_k = (u_k^{\mathrm{t}}, u_k^{\mathrm{a}}, u_k^{\mathrm{v}})$ for text, audio, and video, and the agent response is written as $y_k = (y_k^{\mathrm{t}}, y_k^{\mathrm{a}}, y_k^{\mathrm{v}})$.
The response distribution factorizes over streaming units as
$$ p_\theta(y_{1:K}\mid u_{1:K}) = \prod_{k=1}^{K} p_\theta\!\left( y_k^{\mathrm{t}}, y_k^{\mathrm{a}}, y_k^{\mathrm{v}} \mid u_{\le k}^{\mathrm{t}}, u_{\le k}^{\mathrm{a}}, u_{\le k}^{\mathrm{v}}, y_{<k}^{\mathrm{t}}, y_{<k}^{\mathrm{a}}, y_{<k}^{\mathrm{v}} \right). $$
In words, the response at unit $k$ depends on all user observations that have arrived up to that point, plus all agent outputs that were previously committed to history. Once a response unit is generated, it is appended back into the interaction state and becomes context for future units. This is the mechanism that allows the model to maintain long-horizon consistency, identity, timing, and conversational continuity under streaming conditions.
Language, audio, and video objectives
The language side is represented as discrete tokens and optimized with next-token prediction. The audio and video sides are represented as continuous latents and generated with conditional flow matching. The paper therefore uses a hybrid objective: autoregressive token modeling for text and flow-based latent generation for speech and visual outputs.
For a modality $m \in \{\mathrm{a}, \mathrm{v}\}$, a clean target latent is denoted $z_0^m$ and Gaussian noise is denoted $\epsilon^m \sim \mathcal{N}(0, I)$. The interpolation path is defined as
$$ z_\tau^m = (1-\tau) z_0^m + \tau \epsilon^m, \qquad \frac{\partial z_\tau^m}{\partial \tau} = \epsilon^m - z_0^m. $$
With clean streaming context $c_k = \{u_{\le k}^{\mathrm{t}}, u_{\le k}^{\mathrm{a}}, u_{\le k}^{\mathrm{v}}, y_{<k}^{\mathrm{t}}, y_{<k}^{\mathrm{a}}, y_{<k}^{\mathrm{v}}\}$, the unified diffusion transformer learns to predict the velocity fields for the noisy audio and video latents:
$$ \mathcal{L}_{\mathrm{FM}}^m = \mathbb{E}_{\epsilon^m} \left\| f_\theta\!\left(z_\tau^{\mathrm{a}}, z_\tau^{\mathrm{v}}, c_k, \tau\right) - \frac{\partial z_\tau^m}{\partial \tau} \right\|_2^2. $$
The key point is that the same clean context conditions both audio and video denoising, so speech, motion, appearance, and scene evolution are optimized as a coupled response rather than as independent streams.
Architecture
The model is explicitly designed around streamability. The paper states that the full stack uses strictly causal audio and video VAEs for latent coding, causal audio-visual encoders, causal audio and video decoders, and a causal Transformer with block-causal attention. The result is a single sequence model that can ingest current user signals, update the interaction state, and generate synchronized output without relying on external modules for language, speech, avatar animation, or video generation.
The sequence representation interleaves visual, audio, and text input tokens with visual, audio, and text output tokens. The paper emphasizes that this is not a hidden cascade with text as an intermediate representation; instead, the modalities are treated as first-class tokens in one unified causal stream.
Because the model is unified, generated audio and visual latents are not repaired post hoc. They are predicted in a shared causal context before decoding, then committed back into the history state so that future generation can use them as part of the conversation and scene memory. This commitment step is important for maintaining identity, speaking rhythm, and cross-modal synchronization over long sessions.
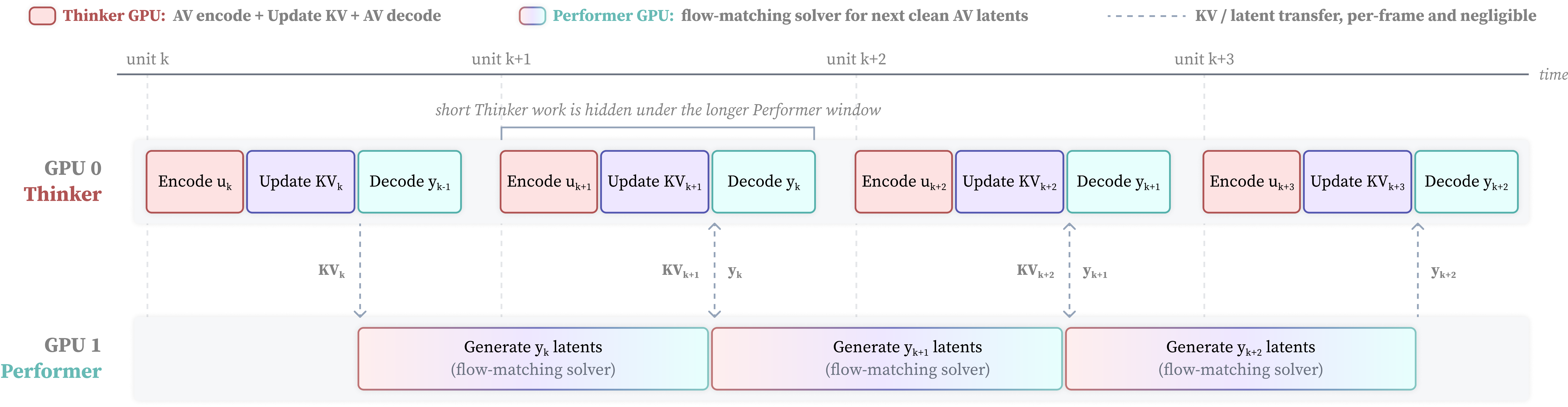
Thinker-performer serving pipeline
Although Wan-Streamer is trained as one end-to-end model, inference is deployed as a separated thinker-performer pipeline to maximize overlap and hardware utilization. The thinker handles the causal encoders, language/state update, KV-cache construction, and causal decoders. The performer handles only the latent-generation path.
At streaming step $k$, the thinker consumes the current user observations, updates the KV cache, decodes the previous response latents for immediate emission, and sends the newly formed KV slice to the performer. The performer appends that KV slice to its own full-history state and runs the flow-matching solver only for the next audio-visual latent unit. Those generated latents are then returned to the thinker at the next step.
The paper frames this as an overlap schedule: current-frame perception and state update, previous-frame decoding, KV/latent communication, and next-frame latent denoising are pipelined across adjacent streaming units. The system is intended to preserve the semantics of one unified model while distributing the expensive generation work so that the real-time budget is easier to meet.
Data and Training
The provided LaTeX describes the training data at the category level rather than enumerating specific datasets. Wan-Streamer is trained on a broad mixture of three types of supervision:
- Understanding-oriented data: image, audio, and video understanding; text dialogue; ASR; TTS; audio dialogue; and related language-audio-visual supervision.
- Generation-oriented data: image generation, audio generation, video generation, and joint audio-visual generation tasks, covering both single-modality and cross-modality conditions.
- End-to-end duplex interaction data: text, audio, and video can appear on both the input and the output side, exposing the model to the target setting of simultaneous perception and expression.
| Training stage | Goal | Mechanism reported in the paper |
|---|---|---|
| 1. Independent-task pretraining | Align multimodal understanding and generation in one sequence model | Initialize the unified Transformer from a language model backbone and train the multimodal interface on the mixed understanding/generation data |
| 2. End-to-end interaction training | Learn duplex turn behavior, response timing, and synchronization | Train on interleaved user input and agent output streams in the same causal format used at inference time |
| 3. Distillation for low-latency streaming | Reduce solver steps and absorb classifier-free guidance behavior into the student | Distill a stronger teacher into an efficient student; use rolling distillation with self-forcing and distribution matching to reduce train-test mismatch |
A noteworthy detail is that the paper does not spell out the exact combined loss weights in the excerpted body. It states the separate next-token and flow-matching objectives, and it describes the three-stage training recipe, but the precise weighting between the language and latent-generation losses is not given in the supplied source text.
Inference, Latency, and Runtime
The paper reports a two-GPU thinker-performer serving path. A streaming unit is 160 ms at 25 fps, and the system is evaluated on the signal-to-signal path from a user unit becoming available to the corresponding audio-video response unit being decoded for emission. Under that protocol, Wan-Streamer reaches about 200 ms model-side latency.
When the paper adds a 350 ms bidirectional network budget, the total interaction latency is about 550 ms. This is the headline system-level claim: the model can support sub-second duplex audio-visual communication for a remote user.
| Metric | Reported value | Interpretation in the paper |
|---|---|---|
| Streaming unit duration | 160 ms at 25 fps | The per-step real-time budget that the thinker-performer pipeline must fit into |
| Model-side response latency | About 200 ms | From receiving a 160 ms user unit to decoding the corresponding response unit for emission |
| Total interaction latency | About 550 ms | Model-side latency plus a 350 ms bidirectional network budget |
| Output resolution in the reported proof of concept | 192p | The current v0.1 validation setting; higher resolutions are left for future work |
The paper also notes that implementation tactics such as CUDA graph capture, compilation, optimized kernels, and KV-cache exchange are used to improve throughput. It distinguishes between model-side response latency and the broader user-visible interaction latency, which is important because public systems often report incomparable metrics such as first-packet delay, first-token delay, API time-to-first-byte, or product-specific benchmark times.
Qualitative interaction behavior
Beyond speed, the paper claims that the model produces more natural interaction behavior because it keeps emitting visible signals while the agent is idle or listening. In the idle state, the agent is described as maintaining identity, gaze, posture, breathing, and subtle facial motion rather than collapsing into a frozen portrait. In the listening state, it can generate non-verbal feedback such as gaze shifts, nods, micro-expressions, and posture changes that are temporally coupled with the user's speech and visual cues.
The paper also emphasizes interruption and proactive speaking. Because user inputs and agent outputs are interleaved on the same causal timeline, the model can keep consuming user audio-visual observations while it is generating its own response, which allows it to stop, shorten, or redirect speech when interrupted. It can also proactively comment on salient visual events or user actions rather than waiting for an explicit spoken request.
Experimental Positioning and Reported Comparisons
The experiments in the provided source focus primarily on latency and runtime comparisons. The paper is careful to separate metrics that are not directly comparable, because public systems report different boundaries: some numbers are model-only, some are first-packet or first-token, and some are product or API measurements that include endpoint detection or network delay. The authors explicitly argue that response-latency comparisons should be read by the measurement boundary, not by the smallest raw number.
The paper compares Wan-Streamer against speech-only full-duplex systems and against audio-visual or avatar systems that often rely on external dialogue, ASR, TTS, or rendering modules. The takeaway is not that every competitor is slower in a directly apples-to-apples sense, but that many of them do not close the loop with synchronized visual output and do not report the same end-to-end interaction boundary.
- For speech-only systems, the paper cites examples such as Doubao Realtime Voice, Moshi, GPT-4o / Realtime API, Hume EVI 3, Gemini Live API, Sesame, and Seeduplex, but stresses that these systems often report different latency definitions and do not produce synchronized visual agent output.
- For multimodal or avatar systems, the paper cites Qwen3/3.5-Omni, MiniCPM-o 4.5, VASA-1, TalkingMachines, StreamAvatar, LiveTalk, Hallo-Live, OmniForcing, Body of Her, MIDAS, U-Mind, X-Streamer, LPM 1.0, MAViD, and M.I.O, again emphasizing that many of these are module-based systems or component-level renderers rather than one unified causal dialogue model.
The reported distinction is therefore architectural as much as it is numerical: Wan-Streamer combines text I/O, audio, and synchronized visual response in one causal stream and reports the full remote audio-visual response path, not only a component-level runtime.
Related Work Positioning
The paper organizes prior work into three clusters. First are full-duplex spoken dialogue models such as Moshi, OmniFlatten, SALM-Duplex, DuplexSLA, and commercial systems like Seeduplex. These establish that real-time dialogue should not be formulated as a simple ASR-LLM-TTS alternation, but they remain speech or speech-text systems and do not include a visual agent or streaming video perception.
The second cluster covers interactive digital humans and audio-visual avatars, including VASA-1, TalkingMachines, StreamAvatar, LiveTalk, Hallo-Live, OmniForcing, MIDAS, MAViD, M.I.O, U-Mind, LPM, and X-Streamer. These systems improve visual realism and runtime, but the paper argues that they usually assemble separate modules for reasoning, speech, and visual rendering rather than learning full-duplex behavior end to end.
The third cluster contains the smaller set of end-to-end audio-visual interaction efforts, especially Body of Her. Wan-Streamer is positioned as extending this direction to a stricter setting in which language, audio, and video all appear on both input and output sides and are served with fully causal encoders, decoders, and full-history streaming inference.
Limitations and Scope of the Reported v0.1 System
- The paper explicitly says that the current v0.1 results are validated at a preliminary 192p output resolution. Scaling to higher resolutions is described as straightforward but left to future work.
- The provided LaTeX excerpt does not include detailed benchmark scores for standard understanding or generation tasks, nor does it provide dataset names or dataset sizes beyond the modality/task categories described above.
- The excerpt also does not present a dedicated ablation table. The main evidence shown in the body is the latency and runtime analysis, plus qualitative discussion of naturalness, listening behavior, interruption handling, and proactive speaking.
- Several comparisons in the paper are necessarily coarse because public systems report different latency boundaries and different output scopes, making direct numerical comparison imperfect.
Conclusion
Wan-Streamer v0.1 is a unified streaming architecture for real-time, full-duplex multimodal interaction. Its main technical idea is to treat language, audio, and video as a single causal stream, train a shared Transformer with both autoregressive and flow-matching objectives, and serve it with a thinker-performer pipeline that overlaps perception and generation. The paper's key empirical claim is a roughly 200 ms model-side response latency and roughly 550 ms end-to-end interaction latency with network delay included, alongside a 25 fps visual output path. The most important broader message is that low-latency conversational agents with visual presence should be designed from the ground up as native full-duplex systems rather than assembled from post-hoc modules.