CrossAccent-TTS
CrossAccent-TTS: Cross-Lingual Accent-Intensity Controllable Text-to-Speech via Disentangled Speaker and Accent Representations
CrossAccent-TTS enables precise control of accent and accent intensity in cross-lingual TTS by disentangling speaker and accent features and conditioning synthesis on learned language embeddings. It preserves speaker identity while allowing smooth accent modulation, performing well on Indic and foreign English accents.
Links
Paper & demos
Abstract
Accent conversion and controllability remain fundamental challenges in cross-lingual text-to-speech (TTS), particularly for low-resource and phonetically diverse Indic languages. While recent large language model (LLM)-based TTS systems exhibit strong cross-lingual generalization, they provide limited explicit control over accent characteristics and intensity. In this paper, we propose CrossAccentTTS, a framework that enables both accent control and conversion while preserving speaker identity. Specifically, we introduce an Accent Intensity Controller (AIC) that injects weighted language embeddings into the accent subspace, allowing smooth interpolation between accents and fine-grained modulation of accent strength at inference time. Experiments on the Indic Multilingual and L2-arctic datasets shows that CrossAccent-TTS achieves precise control of accent intensity, outperforming strong baselines in accent similarity and controllability by maintaining speaker similarity and naturalness.
1. Problem Setting and Core Idea
CrossAccent-TTS addresses a specific gap in cross-lingual text-to-speech (TTS): most modern systems can synthesize speech across languages, but they offer limited explicit control over accent type and, more importantly, accent intensity. The paper frames accent as a property that is intertwined with speaker identity, phonetics, rhythm, and prosody, which makes it difficult to manipulate without damaging naturalness or speaker similarity. This is especially relevant for low-resource and phonetically diverse Indic languages, where controllable accent synthesis is underexplored.
The paper’s main claim is that accent can be controlled more precisely if the model separates speaker-related information from accent-related information and then exposes an explicit control path for accent strength at inference time. CrossAccent-TTS combines three ideas: (1) a neural codec tokenization pipeline, (2) a disentangling speaker/style pathway with adversarial suppression of accent cues, and (3) a learned language-embedding mechanism that can be linearly mixed to modulate accent intensity continuously.
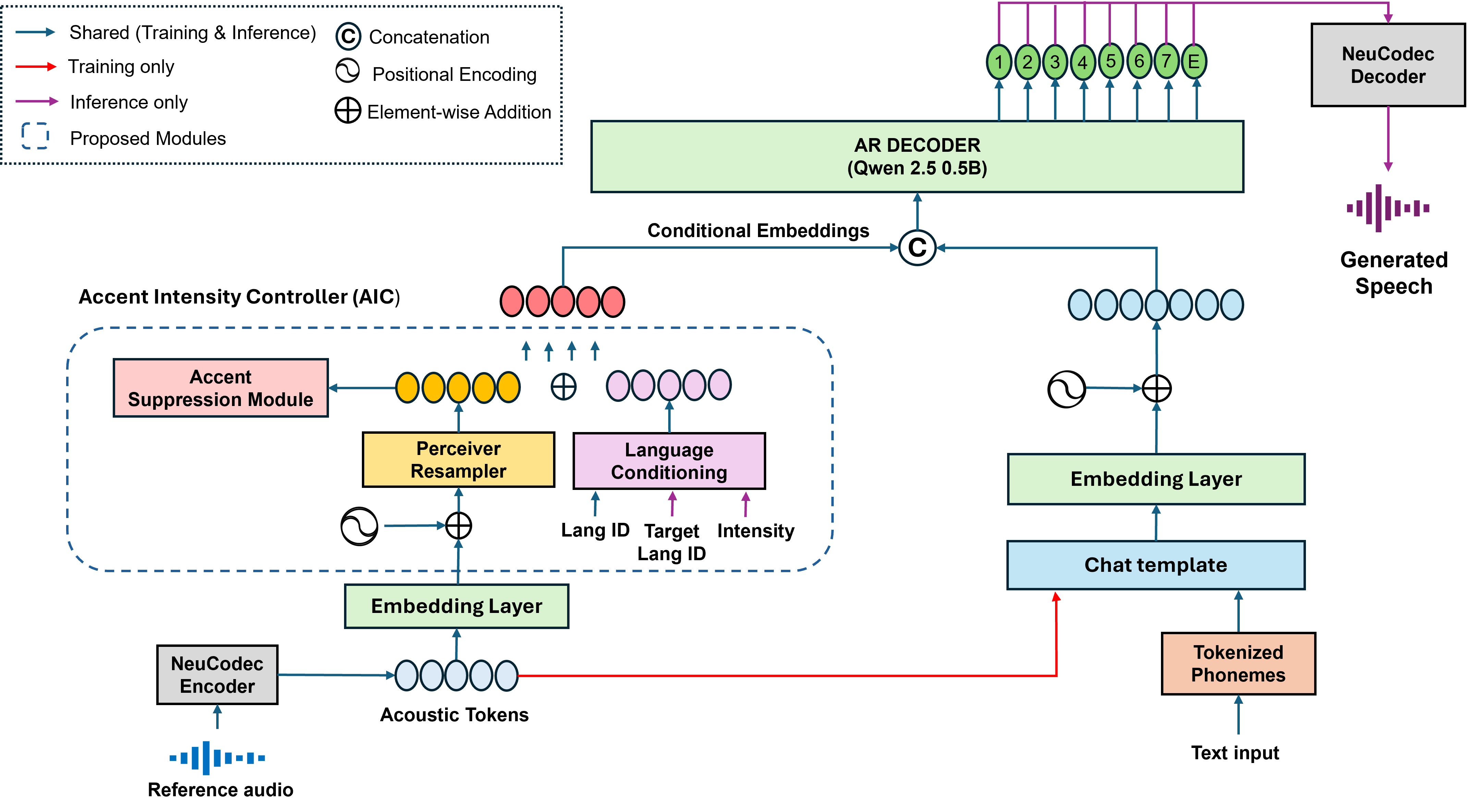
2. High-Level Architecture
The system is built around an autoregressive codec-token TTS model. Speech is first converted into discrete acoustic tokens using Neucodec, a finite scalar quantization (FSQ)-based neural speech codec. The model then learns to generate acoustic tokens conditioned on text and on a reference-speech-derived representation of the target speaker/style. A Perceiver Resampler compresses the reference acoustic tokens into a fixed number of latent slots, and an auxiliary adversarial classifier pushes those latents to become as accent- and language-invariant as possible. Accent conditioning is then reintroduced explicitly using learned language embeddings, which lets the model control accent at inference rather than baking it implicitly into the speaker vector.
In the implementation described in the paper, Neucodec operates at 50 tokens per second with 16 bits per token. It accepts 16 kHz input and reconstructs waveform output at 24 kHz. The autoregressive decoder is based on Qwen 2.5 (0.5B).
3. Speech Tokenization and Reference Representation
3.1 Neucodec tokenization
Ground-truth audio is encoded into a sequence of discrete acoustic tokens by Neucodec. These tokens preserve perceptual quality while making the synthesis problem sequence-based and compatible with the language-model decoder. The paper emphasizes that tokenization is not just used for generating speech; it is also used to extract reference information for speaker and style conditioning.
During training, the model samples a random chunk of acoustic tokens from each reference utterance. This is intended to reduce overfitting to utterance-specific linguistic content and encourage the reference encoder to focus on speaker characteristics rather than exact phonetic sequences.
3.2 Perceiver Resampler bottleneck
The sampled acoustic token embeddings are passed through a Perceiver Resampler, which maps a variable-length sequence to a fixed-size set of latent vectors using cross-attention followed by self-attention. The paper states that learnable positional encodings are added before the encoder to preserve temporal structure. The resulting latent bottleneck is described as a mechanism for forcing the model to retain compact speaker/style information while discarding linguistic detail.
The fixed-length representation has shape $(B, N_s, d)$, with $N_s = 32$ latent slots and embedding dimension $d = 768$. This compact latent is then used as conditioning for the autoregressive token decoder.
4. Accent Intensity Controller and Disentanglement
4.1 Accent Suppression Module with gradient reversal
To remove residual accent and language information from the reference-derived speaker/style embedding, the paper adds an Accent Suppression Module based on adversarial learning. A classifier is trained to predict language or accent labels from the latent representation. Through a gradient reversal layer (GRL), the classifier’s gradient is flipped when propagated into the encoder, so the encoder is trained to make those latents less predictive of accent or language.
The total loss is written as:
$$L_{\text{total}} = L_{\text{decoder}} + \lambda_{\text{GRL}} L_{\text{GRL}}$$
where $L_{\text{decoder}}$ is the autoregressive acoustic-token prediction loss, $L_{\text{GRL}}$ is the auxiliary accent/language classification loss, and $\lambda_{\text{GRL}}$ controls the strength of adversarial suppression. The paper uses $\lambda_{\text{GRL}} = 0.1$ in all experiments.
4.2 Explicit accent control via learned language embeddings
The central novelty is the Accent Intensity Controller (AIC). Instead of relying only on disentanglement, the method explicitly conditions synthesis on learned language embeddings. A learnable embedding table produces a vector for each supported language or accent. This vector is expanded across the latent slots of the speaker/style representation and added to the bottleneck latents, yielding a combined representation used by the decoder.
At inference, the paper describes linear interpolation between two language embeddings to control accent strength:
$$\lambda e_{\text{lang}_1} + (1-\lambda)e_{\text{lang}_2}, \quad \lambda \in [0,1]$$
This lets the user smoothly trade off between accents rather than selecting only discrete accent labels. The paper positions this as a practical way to modulate accent intensity without training a separate accent-specific model for every setting.
5. Text and Acoustic Generation Pipeline
The decoder is an autoregressive model based on Qwen 2.5 (0.5B), conditioned on both text token embeddings and the combined speaker-language embedding. The paper says text is converted into IPA and tokenized using a shared tokenizer that maps speech tokens. The decoder predicts acoustic token sequences, which are then decoded back into waveform audio by Neucodec.
The paper’s formulation is intentionally modular: Neucodec provides a compact acoustic representation, the Perceiver Resampler creates a fixed conditioning bottleneck, GRL encourages disentanglement, and the explicit language embedding path restores controllable accent information. Together, these components aim to preserve speaker identity while allowing accent conversion and intensity control.
6. Training Setup
The model is trained end-to-end on paired text and speech. The paper reports a two-stage training schedule: the decoder is first trained on the full multilingual dataset for 5 epochs, then fine-tuned on L2 ARCTIC for 3 additional epochs with a reduced learning rate. The auxiliary accent/language classifier is trained jointly with the main model through the adversarial module.
The paper does not report a large hyperparameter sweep; instead, it fixes the main adversarial weight at $\lambda_{\text{GRL}} = 0.1$ and demonstrates performance through objective and subjective evaluation.
7. Datasets
7.1 Indic Multilingual dataset
The main multilingual training/evaluation setting is an Indic corpus covering Hindi, Telugu, Tamil, Bengali, Marathi, and English. The paper reports 636 hours of internal in-house Indic speech plus 350 hours of custom-split speech from the Emilia Yodas dataset, for a total of approximately 986 hours. Audio is resampled to 16 kHz for Neucodec encoding, and language labels are used both for explicit language conditioning and adversarial suppression.
7.2 L2 ARCTIC dataset
The second evaluation setting is L2 ARCTIC, which contains about 27 hours of non-native English speech from 24 speakers with six accent backgrounds. The dataset includes aligned text and speech plus native-language labels, making it suitable for measuring accent neutrality and accent rendering in second-language English synthesis.
8. Evaluation Metrics
The paper evaluates both objective and subjective aspects of accent-controllable TTS.
- Accent similarity: cosine similarity between accent embeddings of generated speech and target ground-truth speech; higher is better.
- Accent leakage: cosine similarity between reference-accent embeddings and generated speech embeddings; lower is better, because it indicates less leakage of the source accent when converting to a target accent.
- UTMOS: overall speech quality.
- Speaker similarity: speaker identity preservation using a pretrained speaker verification model (Resemblyzer).
- MOS listening tests: human accent-similarity judgments with 20 participants aged 23 to 35 and no known hearing impairments.
For accent embeddings, the paper uses the GenAID model from Accent Box for L2 English evaluation. For Indic languages, GenAID is fine-tuned on approximately 100k samples from 11 Indian languages and about 3,300 speakers from the Indic Voices dataset for two epochs.
9. Quantitative Results
The reported results are organized around two comparisons: Indic accent conversion and L2 English accent control. Across both settings, the proposed method improves accent controllability and reduces leakage while maintaining speaker similarity and naturalness.
9.1 Indic multilingual accent conversion
| Model | UTMOS ↑ | AccLeak ↓ | AccSim ↑ | SpkSim ↑ |
|---|---|---|---|---|
| IndicF5 | 2.817 | 0.312 | 0.312 | 0.843 |
| XTTS_v2 | 3.168 | 0.284 | 0.284 | 0.832 |
| CrossAccent-TTS | 3.181 | 0.203 | 0.371 | 0.842 |
On Indic data, CrossAccent-TTS achieves the lowest accent leakage and the highest accent similarity among the reported systems, while matching the best baseline on speaker similarity closely and slightly improving UTMOS over XTTS_v2. The paper interprets this as evidence that explicit language conditioning plus adversarial suppression can sharpen accent control without noticeably degrading speaker identity.
9.2 L2 ARCTIC English accent control
| Model | UTMOS ↑ | AccLeak ↓ | AccSim ↑ | SpkSim ↑ |
|---|---|---|---|---|
| CVAE-L | 2.810 | 0.487 | 0.612 | 0.677 |
| CVAE-NL | 2.714 | 0.530 | 0.491 | 0.673 |
| GST | 3.044 | 0.544 | 0.670 | 0.732 |
| CrossAccent-TTS | 4.001 | 0.439 | 0.686 | 0.693 |
On L2 ARCTIC, CrossAccent-TTS reports the best UTMOS, the lowest accent leakage, and the highest accent similarity. Speaker similarity is slightly below the GST baseline but still comparable overall. The paper uses this to argue that the model transfers well to foreign English accents and is not limited to Indic-language scenarios.
10. Subjective Evaluation
The subjective studies reinforce the objective metrics. The paper reports MOS-based accent similarity judgments for both Indic accents and foreign accents, and states that the proposed method is rated more similar to the target accent than the baselines in accent-controlled settings.
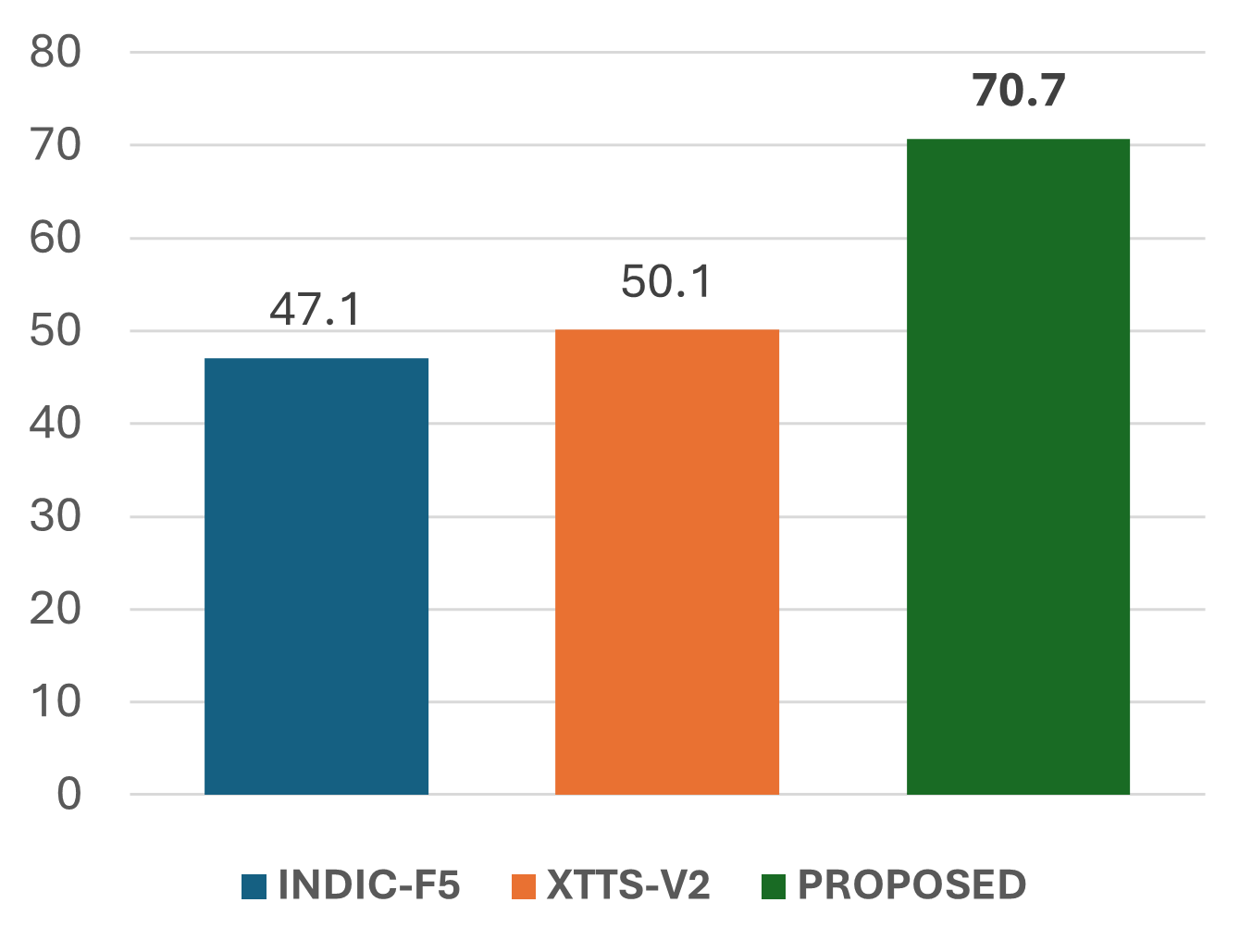
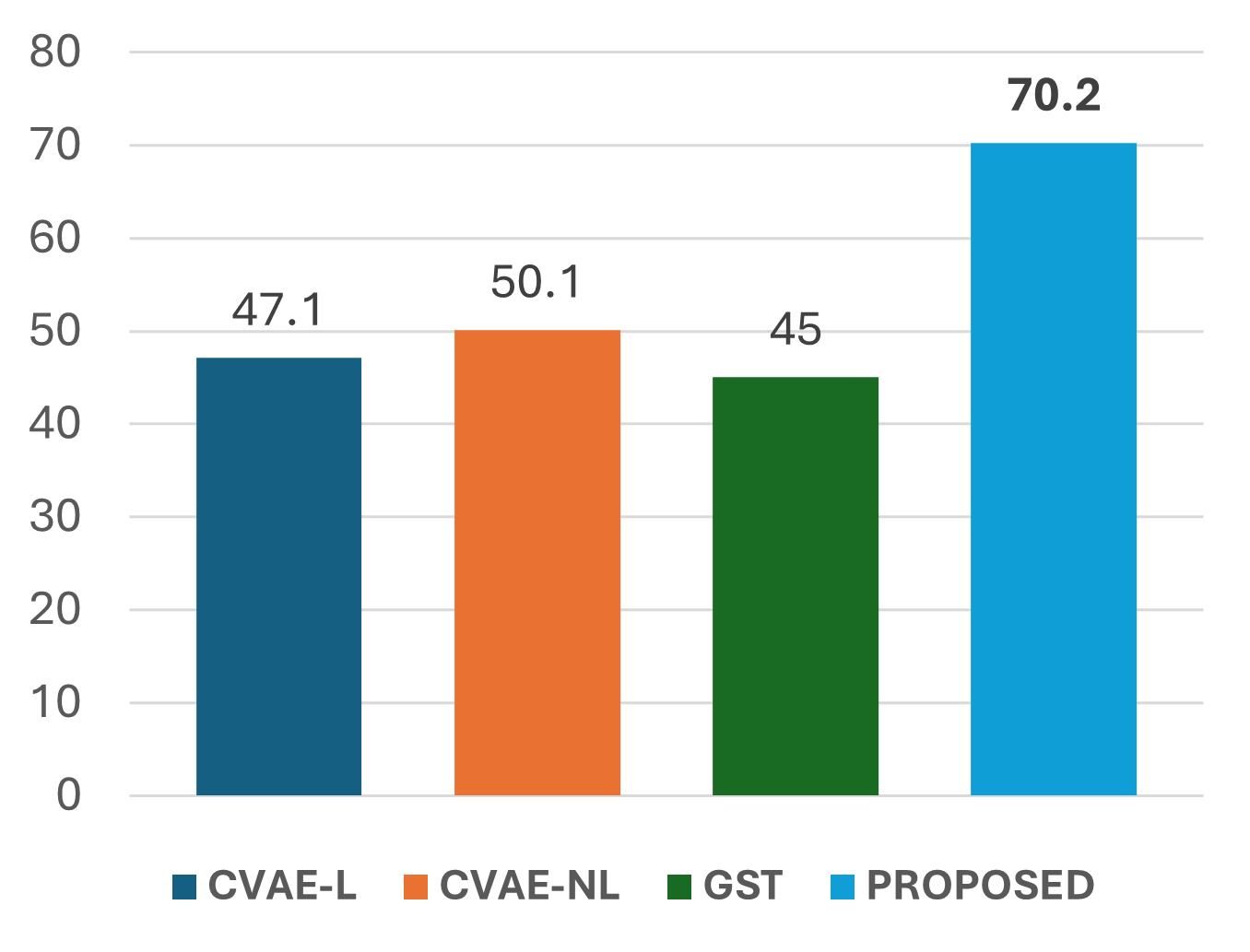
The paper’s key subjective finding is that listeners perceive the weighted language-embedding control as meaningful: accent similarity increases in a way that is audible and consistent with the intended control setting. This is important because objective accent embeddings can sometimes overstate changes that listeners do not hear; here, the paper claims the changes are reflected in both objective and subjective measures.
11. Accent-Intensity Control Behavior
A central experimental claim is that CrossAccent-TTS enables smooth modulation of accent intensity. The paper synthesizes samples with cross-lingual reference audio and varies the intensity settings over 0, 0.3, 0.6, and 1.0. It then extracts accent embeddings from the synthesized speech and computes accent similarity against these settings.
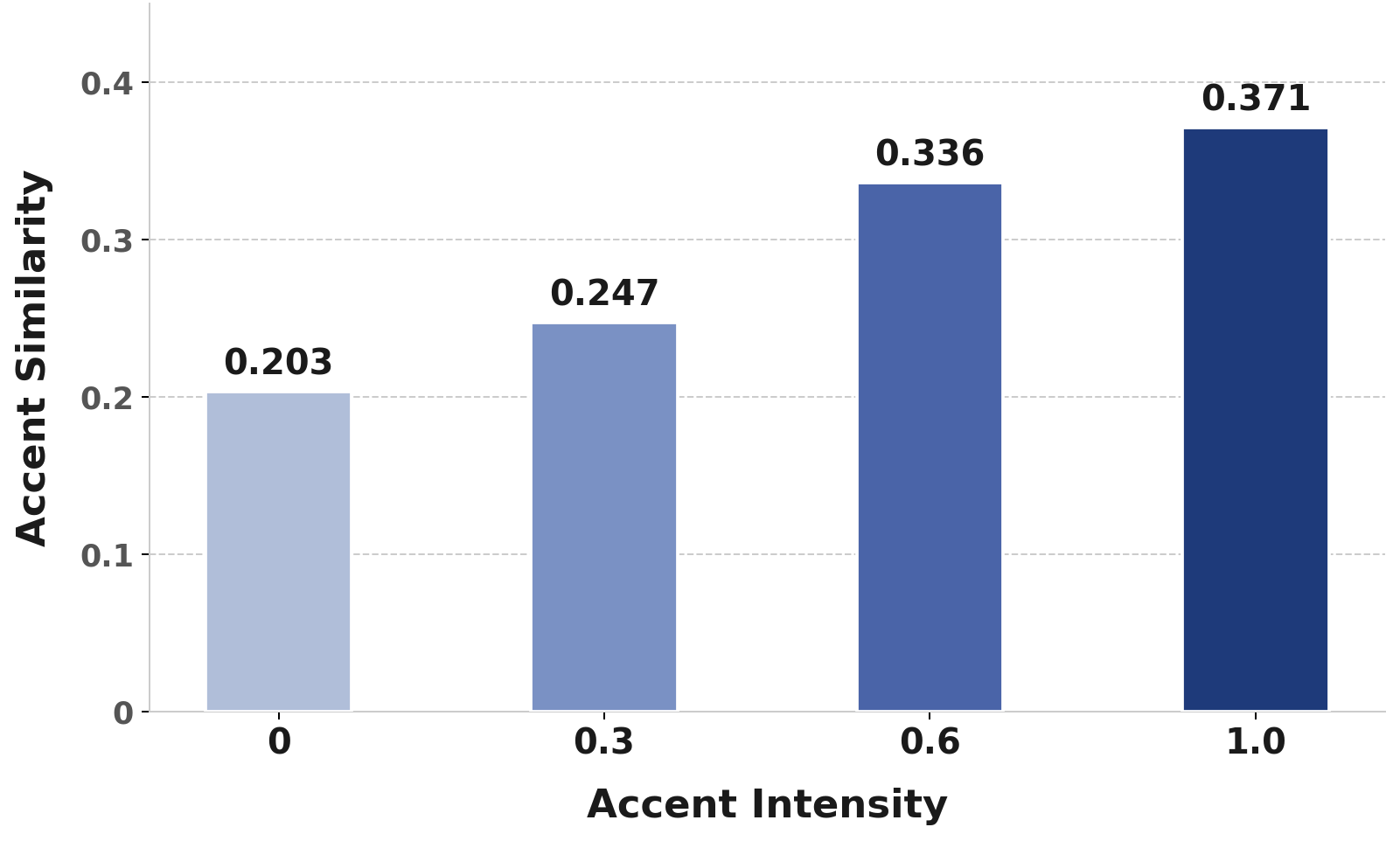
The reported trend is monotonic: as accent intensity increases, accent similarity also increases. This supports the paper’s claim that the Accent Intensity Controller can continuously interpolate between accents instead of only switching among discrete classes. In other words, the model does not just perform accent conversion; it also provides a controllable knob for how strongly that accent should be rendered.
12. What the Paper Contributes Relative to Prior Work
- Explicit intensity control: Unlike many accent-aware TTS systems that only condition on a discrete accent label, CrossAccent-TTS introduces a continuous control mechanism based on weighted language embeddings.
- Speaker-accent disentanglement: The speaker/style pathway is forced toward accent invariance through random token chunking, a fixed Perceiver bottleneck, and adversarial suppression with GRL.
- Codec-token foundation: The method builds on a neural codec representation and an LLM-style autoregressive decoder, consistent with recent codec-based TTS trends but specialized for accent control.
- Cross-dataset validation: The paper evaluates on both Indic multilingual speech and L2 ARCTIC, showing that the approach is not tied to a single accent family or language setting.
13. Interpretation of the Results
The reported numbers suggest a useful tradeoff has been achieved: accent similarity rises while source-accent leakage falls, and speech quality remains competitive or improves. On the Indic task, CrossAccent-TTS improves accent leakage from 0.284 with XTTS_v2 to 0.203 while increasing accent similarity from 0.284 to 0.371. On L2 ARCTIC, it improves UTMOS to 4.001 and accent similarity to 0.686, while lowering accent leakage to 0.439.
The speaker-similarity numbers are also important to interpret: the method preserves speaker identity closely, though not always as the top performer on speaker similarity. The paper’s framing is that the proposed adversarial suppression is sufficient to reduce accent leakage without causing a major collapse in identity preservation.
14. Limitations and Scope Boundaries Reported by the Paper
The paper does not present a separate, detailed limitations section, and it does not report extensive failure analysis, robustness tests, or ablations over all architectural choices. Based on the reported experiments, its evidence is concentrated on two datasets, a single adversarial weight setting, and a small set of intensity values. The summary of claims is therefore strongest for the tested multilingual Indic and L2 English conditions described in the paper.
Another scope boundary is that the method is described and evaluated in the context of the datasets and accents reported in the paper; the text does not provide broader multilingual generalization results beyond those settings, nor does it include a detailed study of out-of-domain accent transfer. These are not stated as failures, but they are not covered in the reported experiments.
15. Bottom Line
CrossAccent-TTS is a codec-token, LLM-based TTS framework designed for cross-lingual accent conversion and continuous accent-intensity control. Its technical novelty lies in combining an adversarially disentangled speaker/style bottleneck with explicit language-embedding interpolation. Within the reported experiments, that combination yields strong accent control, low accent leakage, and competitive speech quality while keeping speaker similarity close to strong baselines. For a conversational-AI or dubbing pipeline, the paper’s main takeaway is that accent can be treated as a controllable continuous attribute rather than a fixed categorical label.