OscillaTTS
Adaptive Oscillatory Inductive Bias for Modeling Sharp Prosodic Dynamics in Diffusion-Based TTS
OscillaTTS enhances diffusion-based text-to-speech by introducing an adaptive oscillatory activation that improves modeling of sharp prosodic transitions and rapid pitch variations, enabling more expressive and stable speech synthesis compared to fixed periodic functions.
Demos
The demos showcase OscillaTTS's ability to generate expressive speech with sharp prosodic transitions and rapid pitch variations, outperforming baseline models like StyleTTS2 in capturing dynamic, expressive prosody. Listen for naturalness and precision in pitch contours, especially in emotional speech, highlighting OscillaTTS's improved modeling of prosodic dynamics with adaptive oscillatory inductive bias.
Links
Paper & demos
Abstract
Diffusion-based text-to-speech (TTS) models have achieved significant improvements in speech quality. However, modeling sharp prosodic transitions and rapid pitch variations in expressive speech remains challenging. Existing diffusion-based TTS decoders commonly utilize periodic nonlinearities such as Snake activation function to capture harmonic structures, but this activation funcation provides limited adaptability when modeling abrupt amplitude and frequency variations. In this paper, we investigate the role of oscillatory inductive bias in diffusion-based TTS decoders and introduce an adaptive oscillatory nonlinearity that enables controllable periodic modulation while maintaining signal stability through a linear bypass component. We refer the resulting TTS system as OscillaTTS. Experiments on the LJSpeech and Emotional Speech Dataset show consistent improvements across objective and subjective evaluations, indicating improved modeling of expressive prosodic dynamics.
Introduction
This INTERSPEECH 2026 paper studies whether an oscillatory inductive bias inside diffusion-based text-to-speech (TTS) decoders can improve the modeling of sharp prosodic transitions and rapid pitch variation in expressive speech. The starting point is a well-known limitation of modern diffusion-based TTS systems: they produce high-quality speech, but they can still struggle with abrupt changes in pitch, energy, and harmonic structure, especially in emotional or conversational speech where voiced-unvoiced boundaries and sudden prosodic shifts are common.
The paper’s core idea is simple but targeted: existing periodic activations such as Snake provide a useful harmonic prior, but their periodic behavior is relatively rigid. The authors therefore propose an adaptive oscillatory activation that keeps the useful periodic bias while adding a learnable modulation parameter and a linear bypass term for stability. They integrate this activation into the decoder side of a StyleTTS2-based system and call the resulting model OscillaTTS.
The paper evaluates the method on the single-speaker LJSpeech corpus and the English subset of the Emotional Speech Dataset (ESD) with the emotions Angry, Happy, and Sad. Across the reported tests, OscillaTTS improves subjective speech quality, spectral distortion, pitch modeling, prosody similarity, and intelligibility compared with the baselines considered in the paper.
Problem Setting and Main Idea
The paper frames TTS generation as a three-stage pipeline: linguistic feature extraction, acoustic modeling, and waveform reconstruction with a neural vocoder. In diffusion-based systems such as StyleTTS2, the decoder and vocoder are important not only for reconstructing audio but also for shaping how temporal dynamics are represented. The authors argue that activation functions inside these decoder blocks matter because they determine how well the network can represent periodic and aperiodic speech structure.
Speech contains strong quasi-periodic behavior due to vocal fold vibration, so periodic activations have been adopted in audio models. The paper specifically discusses Snake as a representative prior. However, Snake uses a fixed-frequency periodic form, and the authors argue that this can be limiting when prosody changes abruptly or when speaker/emotion conditions vary. Their proposed solution is an activation that preserves oscillatory behavior but makes it more adaptable.
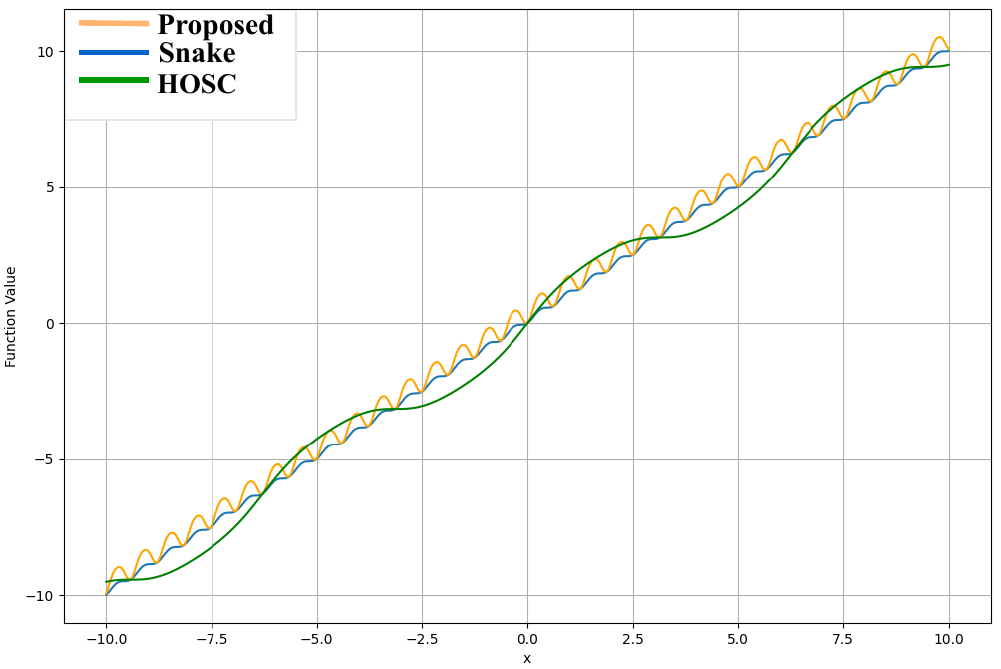
The proposed activation is
$$f_{\text{Oscilla}}(x) = x + \tanh\bigl(\alpha \sin^2(x)\bigr).$$
The linear bypass term $x$ is intended to preserve signal stability, while the periodic term $\sin^2(x)$ supplies oscillatory structure. The parameter $\alpha$ is learnable, so the strength of the nonlinear periodic modulation can adapt during training instead of being fixed a priori.
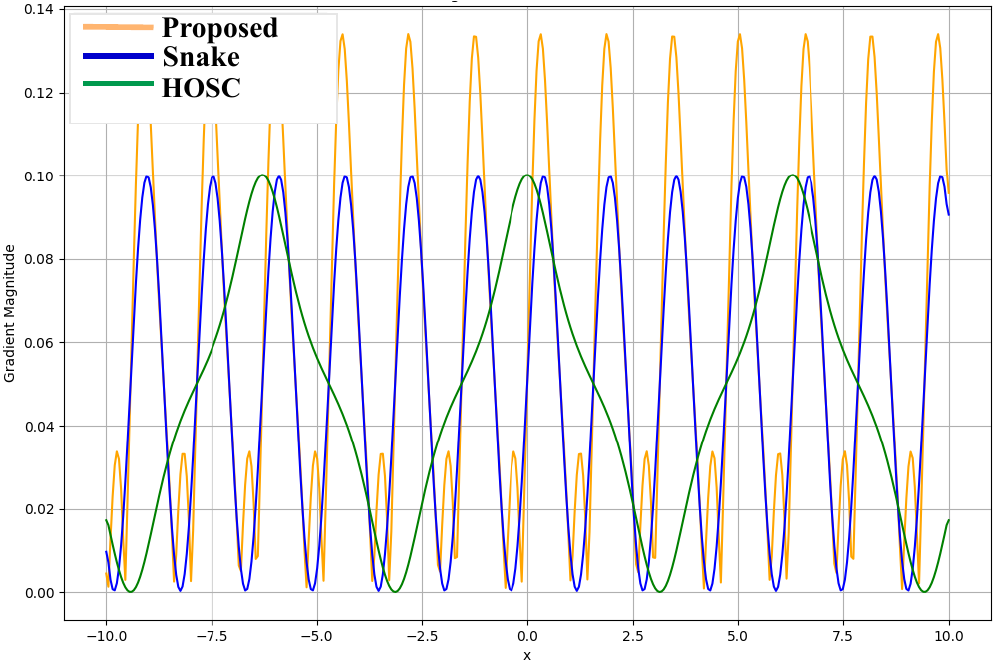
The authors also compare Oscilla conceptually to Snake and to HOSC, emphasizing that the learnable gating effect of $\tanh(\cdot)$ can suppress overly large oscillatory contributions when needed, while still allowing stronger oscillatory gradients when the input is in a smaller regime. Their argument is that this gives Oscilla a more controlled response to rapid prosodic changes than a purely periodic activation with fixed amplitude behavior.
Method
OscillaTTS follows the StyleTTS2 training structure. The paper keeps the overall pipeline close to the baseline and isolates the main change in the decoder activation. The system uses phoneme-level inputs $\mathbf{p}$ and mel-spectrogram targets $\mathbf{m}$.
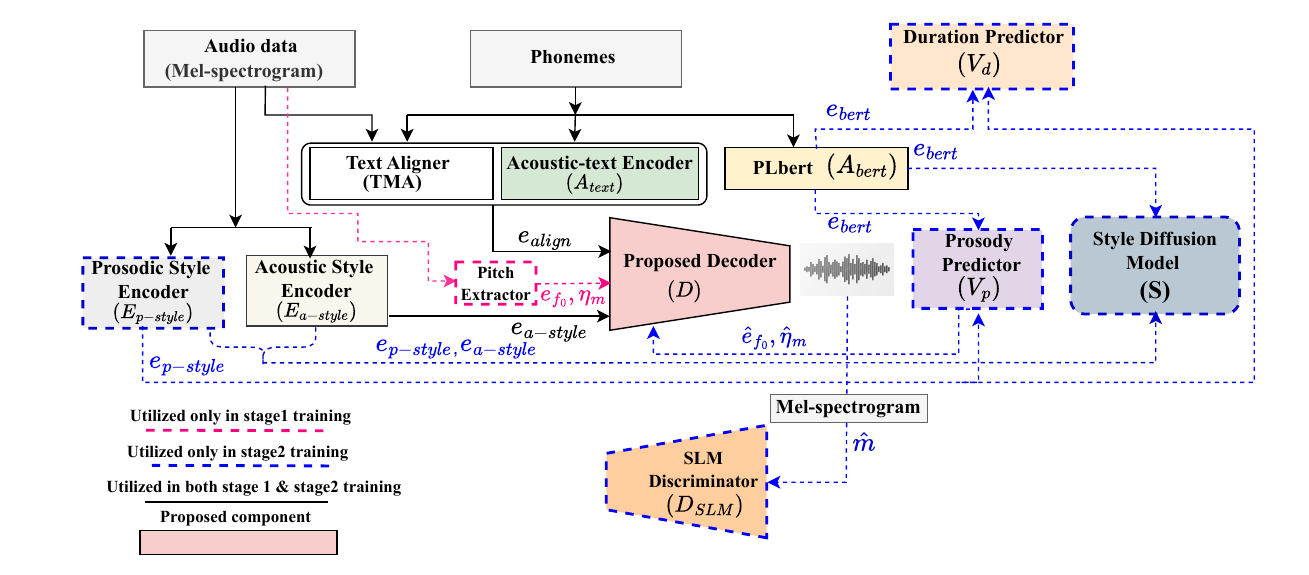
Architecture components
- A pre-trained acoustic text encoder $A_{\text{text}}$ based on a bidirectional LSTM extracts text-side acoustic features.
- A pre-trained prosodic text encoder $A_{\text{bert}}$ based on PLBert extracts prosodic/language-context features.
- The Transferable Monotonic Aligner (TMA) produces speech-phoneme alignment $\mathbf{s}_{\text{align}}$, which is used to obtain aligned text embeddings $\mathbf{e}_{\text{align}}$.
- A pre-trained JDC network extracts pitch information from the mel-spectrogram, denoted $\mathbf{e}_{f_0} = \operatorname{JDC}(\mathbf{m})$.
- Frame-level energy is represented by the logarithmic norm $\boldsymbol{\eta}_{m}$.
- Acoustic and prosodic style encoders, $E_{\text{a-style}}$ and $E_{\text{p-style}}$, produce style embeddings $\mathbf{e}_{\text{a-style}}$ and $\mathbf{e}_{\text{p-style}}$.
- A prosody predictor $V_p$ estimates pitch and energy features, while a duration predictor $V_d$ predicts phoneme durations conditioned on phoneme embeddings and prosodic style representations.
The decoder $D$ is implemented with the iSTFT-Net vocoder architecture, and the proposed Oscilla activation is inserted into the decoder layers. The reconstructed mel-spectrogram is
$$\hat{\mathbf{m}} = D\bigl(\mathbf{e}_{\text{align}}, \mathbf{e}_{\text{a-style}}, \mathbf{e}_{f_0}, \boldsymbol{\eta}_{m}\bigr).$$
Training objective
The paper uses the two-stage StyleTTS2 training recipe.
- Stage 1 pre-trains the decoder to reconstruct mel-spectrograms from aligned linguistic, style, pitch, and energy features.
- Stage 2 jointly trains the remaining components, except for the pitch extractor, and adds a speech language model discriminator $D_{\text{SLM}}$ as a critic to check whether the generated spectrogram preserves acoustic semantic information.
In stage 1, the objective is to fit decoder parameters $\boldsymbol{\theta}$ by maximizing the likelihood of the target mel-spectrogram, which the paper operationalizes with an $L_1$ reconstruction loss:
$$\mathcal{L}_{\text{rec}} = \mathbb{E}_{m,p}\left[\left\lVert \mathbf{m} - D_{\boldsymbol{\theta}}\bigl(\mathbf{e}_{\mathrm{align}}, \mathbf{e}_{\mathrm{a-style}}, \mathbf{e}_{f_0}, \boldsymbol{\eta}_{m}\bigr)\right\rVert_1\right].$$
The authors state that the remaining loss terms follow StyleTTS/StyleTTS2, but they do not redefine them in the paper body. The important methodological change is therefore localized: the decoder activation is replaced by Oscilla while the surrounding training framework remains largely unchanged.
During inference in stage 2, the model predicts $\hat{\mathbf{e}}_{\text{p-style}}$ and $\hat{\mathbf{e}}_{\text{a-style}}$ from the $\mathbf{e}_{\text{bert}}$ representation instead of using the style encoders directly, which the authors note reduces inference time.
Why the activation is claimed to help
The paper’s activation analysis compares Oscilla with Snake and HOSC in both forward shape and gradient behavior. The authors describe Snake as having a gradient term of the form $\sin(2 a x)$, where the amplitude is fixed and the frequency is controlled by $a$. Oscilla, in contrast, yields an oscillatory gradient of the form $\alpha \sin(2 x)$ that is additionally modulated by $\operatorname{sech}^2\!\bigl(\alpha \sin^2(x)\bigr)$. This acts like an implicit gate: larger values of $\alpha \sin^2(x)$ push the $\tanh$ term toward saturation and suppress the gradient contribution, while smaller values allow stronger oscillatory gradients.
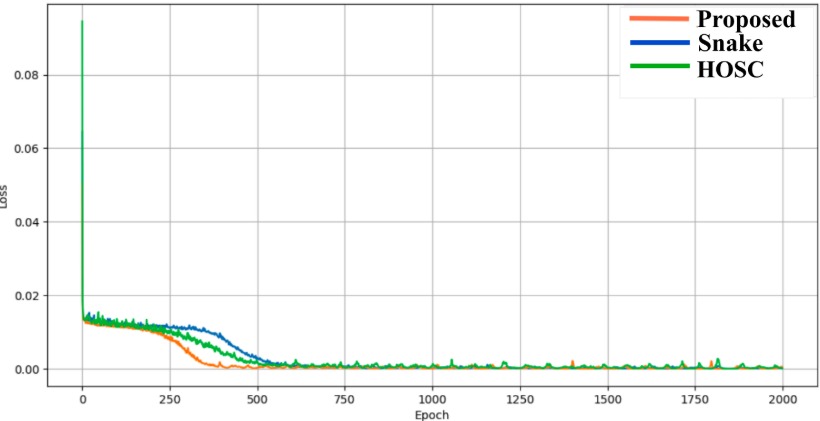
The paper also reports a toy convergence study on a four-layer regression model trained on mixed periodic and aperiodic data. In that illustrative setting, Oscilla converges stably and maintains the same asymptotic computational complexity as Snake1D, namely $O(n)$ with respect to the input dimensionality $n$.
Experimental Setup
The paper evaluates OscillaTTS on two datasets. LJSpeech is used for standard single-speaker English TTS evaluation and contains approximately 24 hours of high-quality recordings from one female speaker. To test expressive synthesis and sharp prosodic variation, the authors also use the English subset of the Emotional Speech Dataset (ESD), focusing on the three emotions Angry, Happy, and Sad.
Both datasets are split into training, validation, and test sets with an 80/10/10 ratio. Audio is resampled to 24 kHz. Training follows the StyleTTS2 two-stage schedule: stage 1 for 200 epochs and stage 2 for 120 epochs. Optimization uses AdamW with $\beta_1 = 0$, $\beta_2 = 0.99$, weight decay $\lambda = 10^{-4}$, learning rate $\gamma = 10^{-4}$, and batch size 8. All experiments are run on a single NVIDIA A100 GPU.
| Setting | Value |
|---|---|
| Dataset split | 80% train / 10% validation / 10% test |
| Audio sampling rate | 24 kHz |
| Stage 1 epochs | 200 |
| Stage 2 epochs | 120 |
| Optimizer | AdamW |
| $\beta_1$ | 0 |
| $\beta_2$ | 0.99 |
| Weight decay | $10^{-4}$ |
| Learning rate | $10^{-4}$ |
| Batch size | 8 |
| Hardware | Single NVIDIA A100 GPU |
Results
The paper reports both subjective and objective evaluation. Subjective quality is measured using MUSHRA-style listening tests. A total of 25 participants, aged 22 to 36 with no reported hearing impairment, evaluated 150 samples per system on a $0$ to $100$ scale, with $100$ indicating the best quality.
LJSpeech: general TTS quality and intelligibility
On LJSpeech, OscillaTTS improves perceptual quality and reduces spectral and pitch error relative to StyleTTS2 and the other TTS baselines included in the paper.
| Model | Speech quality $\uparrow$ | MCD $\downarrow$ | $F_0$-RMSE $\downarrow$ |
|---|---|---|---|
| StyleTTS2 | 81.48 $\pm$ 2.53 | 6.64 $\pm$ 0.01 | 0.41 $\pm$ 0.003 |
| OscillaTTS | 86.67 $\pm$ 1.49 | 6.59 $\pm$ 0.01 | 0.35 $\pm$ 0.003 |
| GlowTTS | 75.79 $\pm$ 2.27 | 6.85 $\pm$ 0.02 | 0.40 $\pm$ 0.003 |
| Grad-TTS | 83.78 $\pm$ 1.99 | 6.90 $\pm$ 0.02 | 0.35 $\pm$ 0.003 |
| FastSpeech2 | 76.00 $\pm$ 2.77 | 6.62 $\pm$ 0.01 | 0.35 $\pm$ 0.003 |
The reported subjective score improves from 81.48 to 86.67, while MCD drops from 6.64 to 6.59 and $F_0$-RMSE drops from 0.41 to 0.35. The paper interprets this as evidence that Oscilla helps the decoder better preserve both spectral detail and pitch dynamics.
The paper also reports AutoPCP and word error rate (WER) on LJSpeech. AutoPCP is used as an utterance-level prosody similarity measure, while WER is computed with a Whisper-based recognizer.
| Model | AutoPCP $\uparrow$ | WER $\downarrow$ |
|---|---|---|
| StyleTTS2 | 3.92 | 2.86 |
| OscillaTTS | 4.05 | 1.85 |
| FastSpeech2 | 3.94 | 4.57 |
| GlowTTS | 3.67 | 6.22 |
| Grad-TTS | 3.91 | 3.89 |
Here, OscillaTTS has the best reported AutoPCP and the lowest WER among the listed TTS systems.
The paper also compares OscillaTTS to BigVGAN, a vocoder system that also uses periodic activations. In that comparison, OscillaTTS again shows better AutoPCP and MCD, matches the reported $F_0$-RMSE, and substantially lowers WER.
| Model | AutoPCP $\uparrow$ | MCD $\downarrow$ | $F_0$-RMSE $\downarrow$ | WER $\downarrow$ |
|---|---|---|---|---|
| BigVGAN | 3.87 | 7.56 | 0.35 | 7.10 |
| OscillaTTS | 4.05 | 6.59 | 0.35 | 1.85 |
Expressive synthesis on ESD
The ESD experiments are the paper’s main test of whether Oscilla helps with sharp prosodic dynamics. The authors analyze three emotions and report both subjective emotion similarity (ES MOS) and objective metrics.

| Emotion | Model | ES MOS $\uparrow$ | MCD $\downarrow$ | $F_0$-RMSE $\downarrow$ |
|---|---|---|---|---|
| Angry | StyleTTS2 | 68.80 $\pm$ 2.43 | 4.68 $\pm$ 0.03 | 0.67 $\pm$ 0.003 |
| OscillaTTS | 70.71 $\pm$ 1.73 | 4.42 $\pm$ 0.03 | 0.67 $\pm$ 0.003 | |
| Happy | StyleTTS2 | 65.80 $\pm$ 2.52 | 6.45 $\pm$ 0.03 | 0.76 $\pm$ 0.003 |
| OscillaTTS | 68.30 $\pm$ 1.93 | 6.29 $\pm$ 0.03 | 0.77 $\pm$ 0.003 | |
| Sad | StyleTTS2 | 67.34 $\pm$ 2.22 | 5.40 $\pm$ 0.03 | 0.50 $\pm$ 0.003 |
| OscillaTTS | 68.32 $\pm$ 1.56 | 5.27 $\pm$ 0.03 | 0.49 $\pm$ 0.004 |
The pattern on ESD is nuanced: OscillaTTS improves ES MOS and MCD for all three emotions, matches the baseline $F_0$-RMSE on Angry, slightly worsens $F_0$-RMSE on Happy, and improves $F_0$-RMSE on Sad. The paper’s main claim is therefore not that every metric improves everywhere, but that the model more consistently captures the expressive prosodic patterns that matter for emotional synthesis.
To further quantify prosody and intelligibility on ESD, the paper reports AutoPCP and WER for each emotion.
| Metric | Model | Angry | Happy | Sad |
|---|---|---|---|---|
| AutoPCP $\uparrow$ | StyleTTS2 | 3.03 | 3.17 | 2.97 |
| OscillaTTS | 3.23 | 3.21 | 3.00 | |
| WER $\downarrow$ | StyleTTS2 | 9.21 | 13.30 | 9.72 |
| OscillaTTS | 4.05 | 7.93 | 7.89 |
These results show improved prosody similarity and a clear drop in recognition error across all three emotions, which the authors interpret as evidence that the oscillatory bias better preserves both expressive style and intelligibility.
The spectrogram visualizations support the numerical results: the paper claims that OscillaTTS produces more accurate harmonic structure and more stable pitch trajectories, particularly in regions where the prosody changes rapidly.
Ablation Study
The ablation study replaces Oscilla with several alternatives inside the same architecture to isolate the contribution of the activation. The compared variants are Snake1D, ReLU, $\tanh$, $x + \sin(x)$, $\tanh(\sin(x))$, and a fixed-parameter Oscilla setting with $\alpha = 1$. All ablations are run on LJSpeech with the rest of the configuration unchanged.
| Activation function | MCD $\downarrow$ | $F_0$-RMSE $\downarrow$ |
|---|---|---|
| Oscilla (learnable $\alpha$) | 6.59 $\pm$ 0.01 | 0.35 $\pm$ 0.003 |
| Oscilla (fixed $\alpha = 1$) | 6.63 $\pm$ 0.01 | 0.39 $\pm$ 0.003 |
| Snake1D | 6.64 $\pm$ 0.01 | 0.41 $\pm$ 0.003 |
| ReLU | 8.14 $\pm$ 0.02 | 0.44 $\pm$ 0.003 |
| $\tanh$ | 7.87 $\pm$ 0.02 | 0.68 $\pm$ 0.003 |
| $x + \sin(x)$ | 12.63 $\pm$ 0.03 | 0.80 $\pm$ 0.003 |
| $\tanh(\sin(x))$ | 8.14 $\pm$ 0.02 | 2.56 $\pm$ 0.004 |
The ablation is important because it separates three effects: periodicity itself, the linear bypass, and learnability of $\alpha$. The fixed-$\alpha$ variant already improves on Snake1D slightly, but the learnable-$\alpha$ version is best, indicating that adaptation rather than periodicity alone is what gives the strongest gains. The non-oscillatory alternatives perform noticeably worse, especially $x + \sin(x)$ and $\tanh(\sin(x))$.
Interpretation of the Results
The paper’s evidence points to a consistent theme: making the decoder’s nonlinearity more adaptable helps the model better preserve expressive speech cues. The gains are strongest where sharp changes matter most, namely in the emotional-speech setting and in pitch-related metrics such as $F_0$-RMSE, AutoPCP, and WER. The activation study also suggests that the improvement is not simply because the model is more nonlinear, but because the oscillatory response can be gated and modulated during learning.
Another practical advantage reported in the paper is that the activation does not introduce a new asymptotic computational burden. The authors explicitly note that Oscilla and Snake1D both have $O(n)$ complexity, so the proposed change is intended as a drop-in architectural modification rather than a heavier model redesign.
Limitations and Scope
The paper does not present a formal limitations section, but its reported scope is clear. The evaluation is limited to LJSpeech and the English subset of ESD, so the evidence is strongest for single-speaker English TTS and a small set of emotional conditions. The conclusion explicitly identifies multi-speaker expressive TTS and singing voice synthesis as future work, which is the main indication of where the method has not yet been tested.
The paper also does not report a detailed latency or parameter-count analysis beyond noting that the activation remains computationally light. In addition, the ESD pitch results are not uniformly improved across every emotion, which suggests that the proposed bias helps most when the synthesis target strongly benefits from adaptive oscillatory modeling, but it is not a guaranteed win for all pitch-error cases.
Conclusion
OscillaTTS is a targeted architectural modification to StyleTTS2-style diffusion TTS: it replaces a standard periodic decoder activation with an adaptive oscillatory function $x + \tanh(\alpha \sin^2(x))$ and keeps the rest of the training recipe largely intact. The reported experiments show improvements on both ordinary TTS and expressive emotional synthesis, including better subjective quality, lower MCD, improved prosody similarity, and lower WER in the evaluated settings.
The main technical message of the paper is that periodic inductive bias helps, but adaptive periodicity helps more when the goal is to model sharp prosodic dynamics. Within the constraints of the paper’s evaluation scope, the proposed activation appears to be a useful, low-cost way to improve decoder behavior in diffusion-based TTS systems.