STEB
STEB: A Speech-to-Speech Translation Expressiveness Benchmark for Evaluating Beyond Translation Fidelity
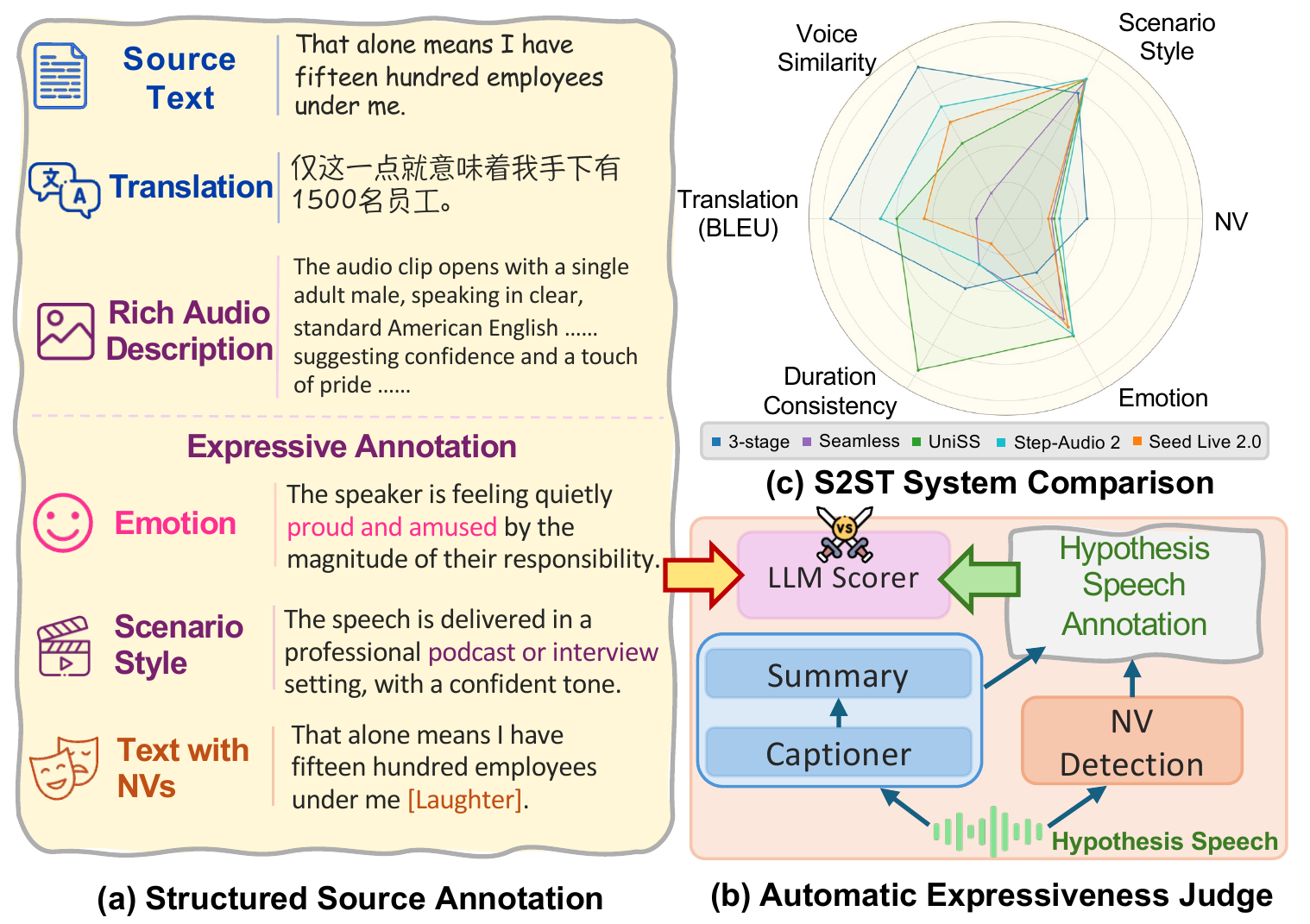
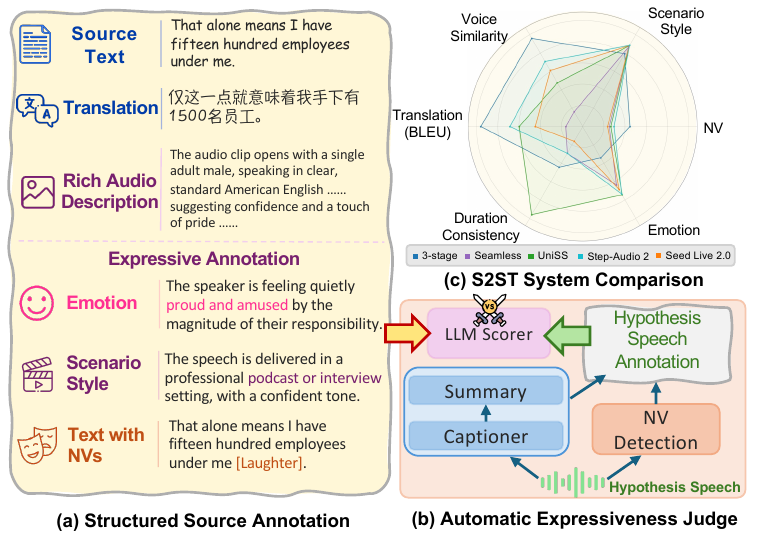
STEB is a speech-to-speech translation benchmark that evaluates both translation fidelity and expressive aspects like emotion, scenario style, and nonverbal vocalizations. It uses a reference-free LLM-based method comparing structured expressive attributes, revealing challenges in preserving expressiveness.
Demos
These demos showcase evaluation of speech-to-speech translation systems on STEB, focusing on translation fidelity and preservation of expressiveness like emotion and nonverbal vocalizations. Listen for how well systems maintain emotional tone, scenario style, NVs, and timing alignment essential for applications such as video dubbing. The radar chart visually summarizes system performance on these key aspects.
Links
Paper & demos
Code & resources
Abstract
Speech-to-speech translation (S2ST) should preserve not only lexical meaning, but also expressive attributes: emotion, scenario style (e.g., news reporting vs. dramatic dialogue), and nonverbal vocalizations (NVs). Moreover, collecting cross-lingual target speech that is both translation-faithful and expressively aligned with the source is difficult at scale, making reference-based evaluation impractical. We introduce STEB (Speech-to-Speech Translation Expressiveness Benchmark), a 32.6-hour Chinese--English benchmark that evaluates both standard dimensions (translation fidelity, speaker similarity, duration alignment) and expressiveness dimensions (emotion, scenario style, NV preservation). For expressiveness evaluation, STEB uses a caption-then-summarize framework that converts speech into structured expressive attributes and compares source and hypothesis attributes with an LLM judge. Human validation shows statistically significant correlations with listener judgments across all expressive dimensions. We evaluate six S2ST systems covering cascaded systems, end-to-end models, and speech large language models. Many systems, especially cascaded ones, achieve strong translation fidelity, but they still struggle with emotion preservation (best: 3.82/5) and NV preservation (best: 2.31/5). These results reveal a gap between semantic transfer and expressive transfer, identifying expressiveness preservation as an open challenge for S2ST. Audio samples are available at https://cmots.github.io/steb.github.io/.
Introduction
STEB is a benchmark for expressive speech-to-speech translation (S2ST), not just translation fidelity. The paper argues that a translated utterance should preserve three kinds of expressive information in addition to lexical meaning: emotion, scenario style (for example, news reporting, dramatic dialogue, audiobook narration), and nonverbal vocalizations (NVs) such as laughter, breathing, coughing, or crying. This matters for downstream uses like dubbing and conversational speech interfaces, where a semantically correct output can still feel wrong if it loses the source’s affect, scene, or vocal events.
The central challenge is evaluation. For expressive S2ST, there is usually no scalable way to collect a target-speech reference that is both translation-faithful and expressively matched to the source. Because of that, the paper proposes a reference-free evaluation framework that compares structured expressive descriptions of source and hypothesis speech instead of requiring a parallel target recording.
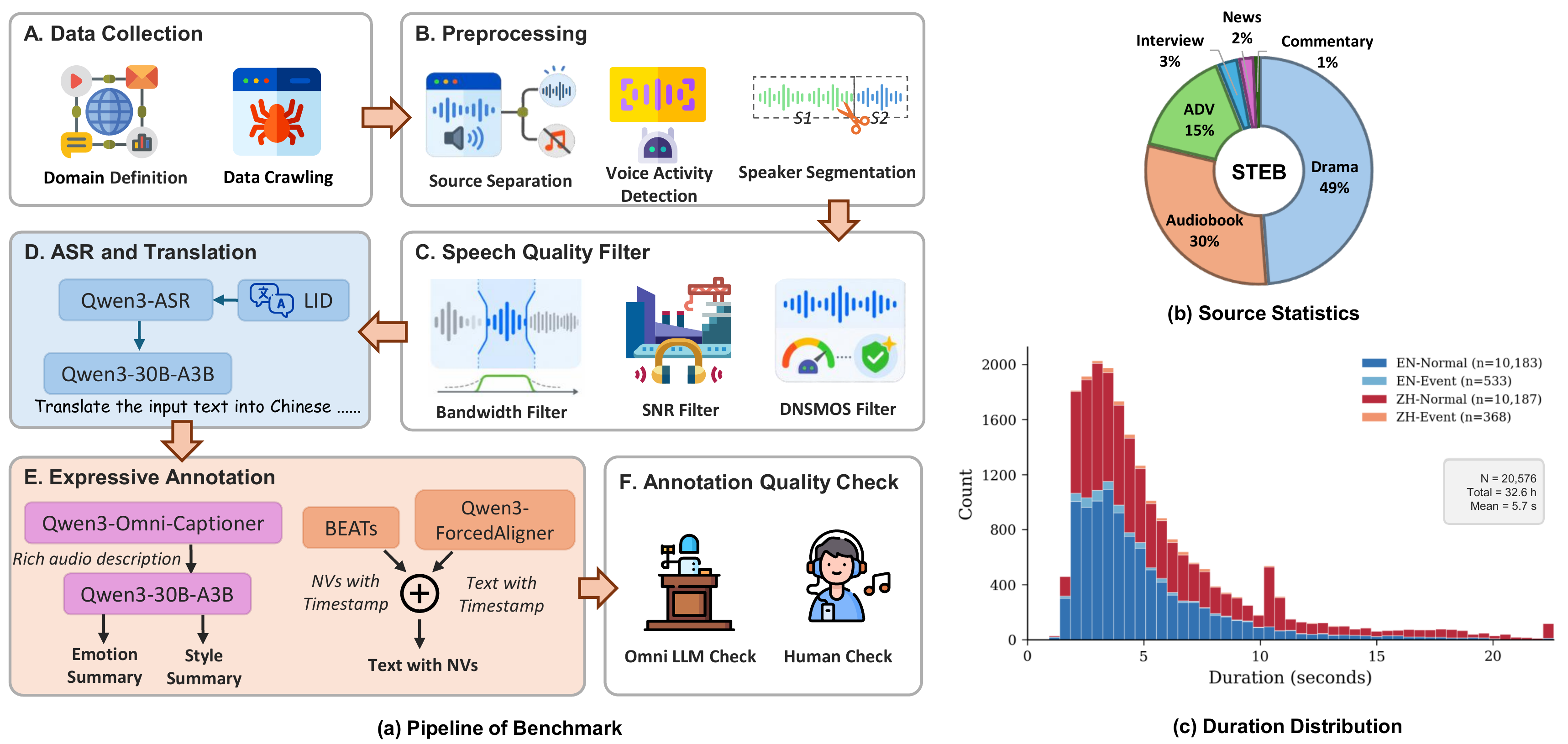
The benchmark covers Chinese$leftarrow$English translation in both directions, spans 32.6 hours of unique data, and is built from six real-world scenarios: drama, audiobooks, advertisements, interviews, news broadcasts, and commentary. The authors evaluate six S2ST systems covering cascaded pipelines, end-to-end models, and speech large language models. The core finding is that many systems do well on translation metrics, but expressiveness preservation remains weak, especially for emotion and NVs.
What STEB Contributes
- A new benchmark for evaluating beyond-fidelity S2ST, with explicit dimensions for emotion, scenario style, and NV preservation.
- A scalable curation pipeline that turns real-world audio into structured annotations using ASR, translation, NV tagging, audio captioning, summarization, and strict quality filtering.
- A reference-free LLM-as-a-judge evaluation method that scores expressive consistency on a 1--5 scale.
- A human validation study showing that the automatic expressiveness scorer correlates significantly with human judgments across all expressive dimensions.
- An empirical study of six S2ST systems demonstrating that semantic transfer is often much better than expressive transfer.
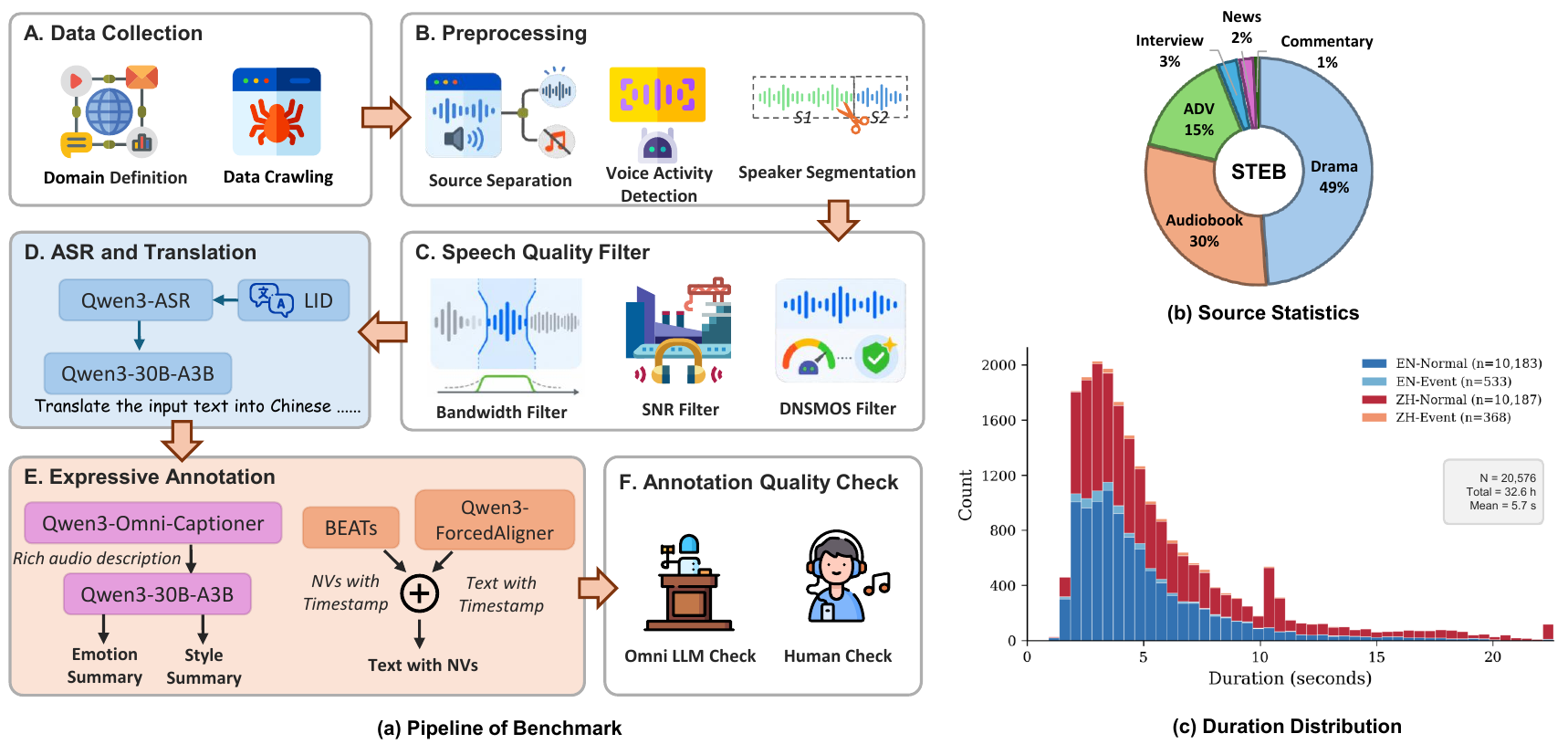
Benchmark Construction Pipeline
Data Collection
The data are collected from publicly accessible web sources and are initially drawn from approximately 80 hours of candidate audio. The final benchmark keeps fewer than 40 hours after filtering, with a selection rate below 50%. The paper emphasizes that the raw material is intentionally diverse and messy: multi-minute or multi-hour recordings, background music, environmental noise, and multiple speakers. That makes utterance-level annotation impossible without preprocessing.
Preprocessing and Cleaning
The preprocessing pipeline first converts all audio to 16 kHz mono WAV. It then applies:
- Source separation using BS-Roformer to isolate foreground speech from music and environmental noise.
- Speaker segmentation using a joint diarization setup: Silero VAD for speech activity, pyannote for speaker change boundaries, and CAM++ embeddings for same-speaker clustering. Adjacent same-speaker segments are merged.
- Duration filtering to retain only utterances between 3 and 30 seconds.
- Quality filtering that removes narrowband/telephone-quality audio, segments with insufficient SNR or clarity, and segments with DNSMOS below 3.0.
- Language identification using Whisper; only Chinese and English segments are kept.
The appendix adds more detail: the narrowband check rejects audio with effective bandwidth below 8 kHz, the SNR and clarity filters use per-frame statistics with thresholds on the 25th percentile and mean, and the filtering pipeline is intentionally strict to prioritize annotation reliability over quantity.
Annotation Strategy
Each retained utterance is annotated for multiple dimensions. The paper’s annotation pipeline combines task-specific models and multimodal LLMs:
- ASR with Qwen3-ASR to obtain the source transcript.
- Force alignment with Qwen3-ForceAlign to produce word-level timestamps.
- Translation with Qwen3-30B-A3B for Chinese$rightleftarrows$English text translation.
- NV detection with BEATs in the PretrainedSED framework, with event markers inserted according to overlap with word intervals.
- Audio captioning with Qwen3-Omni-Captioner to generate rich descriptions of emotion, style, pacing, energy, formality, and timbre.
- Summarization with Qwen3-30B-A3B to compress the caption into structured emotion and scenario style fields.
The authors explicitly note that the caption-then-summarize decomposition is designed to make expressive attributes easier to judge than if one relied on a monolithic label or raw audio comparison. Emotion is treated as a concise vocal state with category, intensity, and nuance. Scenario style is treated as a scene or genre description, such as news or drama. NVs are tracked at the event level rather than as a simple binary attribute.
Quality Assurance
Quality assurance combines automatic multimodal scoring with human validation. A strong multimodal LLM listens to each sample and scores the transcript, translation, emotion, style, and NV annotation accuracy on a 1--5 scale. The benchmark uses strict acceptance thresholds: for the normal subset, transcription, translation, emotion, and style must all be perfect or near-perfect, and for the NV subset the criteria focus on transcription, translation, and NV tagging.
The paper reports that among annotated candidates, 88.3% receive emotion score 5 and 91.4% receive style score 5 from the automatic quality gate. On a random subset of 170 samples, when the automatic score is above 4, the corresponding human score is also above 4 in 100% of transcript cases, 91.3% of translation cases, 86.7% of emotion cases, 88.8% of style cases, and 75.6% of NV cases.
Human annotators are bilingual, experienced in speech annotation, and review both speech quality and annotation accuracy. The appendix also notes that annotators consented to the use of their annotations for research and were compensated.
Benchmark Statistics
- Normal subset: 20,370 utterances, 32.27 hours.
- NV subset: 901 utterances, 1.26 hours.
- Total unique duration: 32.6 hours.
The NV subset overlaps with the normal subset, so the unique duration is not the sum of the two durations. Drama is the largest scenario source because it provides dense emotional variation, while the other scenarios increase coverage of scene style.
Reference-Free Expressiveness Evaluation
Because matched expressive target speech is hard to obtain at scale, the benchmark does not evaluate expressiveness against a ground-truth target audio reference. Instead, it evaluates whether source and hypothesis speech are consistent in the expressive attributes that matter.
Judge Pipeline
The evaluation pipeline first applies the same caption-then-summarize process to the translated speech hypothesis. In parallel, NVs are detected in the hypothesis with BEATs and aligned to the output transcription. The resulting source and hypothesis structured descriptions are then compared by an LLM judge using dimension-specific rubrics.
For each sample, the judge scores:
- Emotion: whether the core emotion category, intensity, and subtle attitude match.
- Scenario style: whether the scene or genre matches, with formality and delivery manner as supporting cues.
- NV preservation: whether event type, count, order, and approximate position are preserved, and whether new salient events were added.
The paper explicitly argues against simple label-matching classifiers because expressiveness is not just a closed-set classification problem. For example, two clips may share the same emotion label but differ substantially in intensity; style depends on scene and delivery, not just text topic; and NVs require event-level comparison. The benchmark therefore frames expressiveness as a contextual, comparative, graded scoring problem.
Scoring and Aggregation
The judge uses a 1--5 rubric for each dimension. Emotion and style are judged as a similarity score between structured descriptions. NVs are judged by event preservation, with special penalties for omissions and newly inserted salient events. To reduce variance, each sample is scored three times. The final score is obtained by an outlier-aware rule: identical scores are kept, large outliers can be removed, and all-different triples are aggregated by the median.
In implementation, the text judge is Qwen3-30B-A3B served via vLLM with default decoding and a maximum generation length of 2,048 tokens.
Human Validation of the Judge
The human correlation study uses 160 source-hypothesis pairs scored by multiple annotators. The authors compare three automatic judge designs:
- Summary-based scoring: caption-then-summarize annotations plus an LLM judge.
- Caption-based scoring: the judge uses the full captions directly.
- Audio-based direct scoring: a multimodal LLM listens to both clips and scores them directly.
The summary-based design is the only one that achieves statistically significant correlation with human judgments on all three dimensions. Direct audio-based and caption-based designs do not reach significance in this study.
| Dimension | Comparison | Spearman $rho$ | $p$-value | Agreement | MAE |
|---|---|---|---|---|---|
| Emotion | Human-human | 0.584 | 8.07$times$10$^{-17}$ | 0.438 | 0.586 |
| Summary-based vs. human | 0.515 | 2.60$times$10$^{-5}$ | 0.567 | 0.734 | |
| Audio-based direct vs. human | 0.044 | 0.73 | 0.500 | 0.994 | |
| Caption-based vs. human | 0.047 | 0.71 | 0.409 | 1.112 | |
| Style | Human-human | 0.514 | 4.91$times$10$^{-12}$ | 0.544 | 0.456 |
| Summary-based vs. human | 0.427 | 2.01$times$10$^{-3}$ | 0.640 | 0.568 | |
| Audio-based direct vs. human | 0.158 | 0.21 | 0.515 | 0.952 | |
| Caption-based vs. human | 0.147 | 0.24 | 0.530 | 0.803 | |
| NV | Human-human | 0.789 | 5.28$times$10$^{-28}$ | 0.651 | 0.476 |
| Summary-based vs. human | 0.518 | 2.66$times$10$^{-4}$ | 0.644 | 0.874 | |
| Audio-based direct vs. human | -0.009 | 0.95 | 0.200 | 2.422 | |
| Caption-based vs. human | 0.193 | 0.20 | 0.511 | 1.207 |
These results support the paper’s design choice: decomposing speech into structured attributes before judging is more reliable than directly comparing raw audio or long captions. NV is the most stable and least subjective expressive dimension, while scenario style is the most subjective and therefore the weakest of the three for the judge.
Experimental Setup
The benchmark evaluates six S2ST systems:
- Three-Stage: ASR + NV detection, text translation with style instruction generation, then voice-cloning TTS.
- Two-Stage: direct audio-to-text translation with a multimodal LLM, then voice-cloning TTS.
- UniSS: a unified expressive S2ST model.
- SeamlessExpressive: a multilingual end-to-end S2ST model with prosody-aware design.
- Seed LiveInterpret 2.0: a commercial simultaneous speech translation system.
- Step-Audio 2: an end-to-end speech large language model.
Metrics fall into three groups:
- Translation fidelity: BLEU, COMET, and XCOMET. For speech outputs, the generated audio is first transcribed by ASR and then scored against the reference translation.
- Voice and timing: speaker similarity (SIM) from WavLM/ECAPA-TDNN embeddings, and speech length compliance $\mathrm{SLC}_{\epsilon}$ with $\epsilon \in \{0.2, 0.4\}$.
- Expressiveness: emotion, style, and NV scores on a 1--5 scale.
For duration alignment, the compliance metric is the fraction of utterances whose output-to-input duration ratio lies in $[1-\epsilon, 1+\epsilon]$. In other words, it measures how often generated speech stays within a specified timing tolerance around the source.
Main Results
The results are reported separately for Chinese$rightarrow$English and English$rightarrow$Chinese. Across both directions, the same broad pattern appears: translation quality is reasonably strong, but expressive transfer is much weaker.
Chinese$rightarrow$English
| System | BLEU | COMET | XCOMET | XCOMET/QE | Emotion | Style | NV | SLC$_{0.2}$ | SLC$_{0.4}$ | SIM |
|---|---|---|---|---|---|---|---|---|---|---|
| Three-Stage | 38.20 | 0.812 | 0.804 | 0.840 | 1.73 | 3.92 | 2.25 | 0.614 | 0.887 | 0.497 |
| Three-Stage w/o Instruct | 38.21 | 0.812 | 0.804 | 0.840 | 1.73 | 3.93 | 2.22 | 0.610 | 0.889 | 0.498 |
| Two-Stage | 41.59 | 0.814 | 0.800 | 0.833 | 1.68 | 3.93 | 2.31 | 0.439 | 0.699 | 0.498 |
| Two-Stage w/o Instruct | 41.41 | 0.815 | 0.800 | 0.834 | 1.67 | 3.92 | 2.28 | 0.438 | 0.696 | 0.497 |
| UniSS | 28.55 | 0.768 | 0.772 | 0.793 | 3.61 | 4.36 | 1.31 | 0.915 | 0.959 | 0.411 |
| SeamlessExpressive | 17.83 | 0.685 | 0.711 | 0.693 | 3.10 | 4.27 | 1.29 | 0.598 | 0.934 | 0.302 |
| Seed LiveInterpret 2.0 | 26.02 | 0.763 | 0.773 | 0.798 | 3.34 | 4.41 | 1.25 | 0.590 | 0.912 | 0.416 |
| Step-Audio 2 | 30.82 | 0.784 | 0.790 | 0.814 | 3.57 | 4.39 | 1.58 | 0.542 | 0.836 | 0.475 |
In this direction, the two cascaded systems achieve the strongest translation scores, with Two-Stage reaching 41.59 BLEU. But their emotion scores are only around 1.67--1.73, showing a large gap between semantic correctness and expressiveness. Style scores are higher, near 3.9 for cascaded models and above 4.0 for several end-to-end models, but still not consistently high. NV preservation is modest overall, with the best score only 2.31/5 from Two-Stage. Duration alignment is best for UniSS.
English$rightarrow$Chinese
| System | BLEU | COMET | XCOMET | XCOMET/QE | Emotion | Style | NV | SLC$_{0.2}$ | SLC$_{0.4}$ | SIM |
|---|---|---|---|---|---|---|---|---|---|---|
| Three-Stage | 54.14 | 0.892 | 0.849 | 0.895 | 1.68 | 4.02 | 2.21 | 0.659 | 0.917 | 0.428 |
| Three-Stage w/o Instruct | 54.09 | 0.891 | 0.849 | 0.894 | 1.70 | 4.03 | 2.09 | 0.652 | 0.922 | 0.427 |
| Two-Stage | 59.66 | 0.902 | 0.849 | 0.902 | 1.70 | 4.03 | 2.10 | 0.641 | 0.908 | 0.427 |
| Two-Stage w/o Instruct | 59.73 | 0.902 | 0.849 | 0.902 | 1.69 | 4.03 | 2.05 | 0.638 | 0.902 | 0.425 |
| UniSS | 46.43 | 0.849 | 0.824 | 0.862 | 3.82 | 4.44 | 1.36 | 0.980 | 0.990 | 0.291 |
| SeamlessExpressive | 36.13 | 0.806 | 0.767 | 0.794 | 3.27 | 4.39 | 1.23 | 0.492 | 0.819 | 0.254 |
| Seed LiveInterpret 2.0 | 41.72 | 0.805 | 0.814 | 0.854 | 3.53 | 4.41 | 1.09 | 0.342 | 0.819 | 0.348 |
| Step-Audio 2 | 48.37 | 0.865 | 0.838 | 0.880 | 3.77 | 4.46 | 1.38 | 0.548 | 0.874 | 0.334 |
For English$rightarrow$Chinese, translation fidelity is again strong: Two-Stage reaches 59.66 BLEU. Emotion preservation remains weak for cascaded systems, again around 1.68--1.70, while end-to-end systems rise to the 3.27--3.82 range. The best style score is 4.46 from Step-Audio 2. The best NV score is 2.21 from Three-Stage. UniSS again dominates duration alignment, with SLC$_{0.2}$ of 0.980 and SLC$_{0.4}$ of 0.990.
Intermediate Text Translation Analysis
The paper also evaluates the intermediate text translations before speech synthesis. Those scores are close to the final speech-output scores, which supports the authors’ claim that the main bottleneck is not semantic transfer alone, but expressive preservation across the full S2ST pipeline.
| System | zh$rightarrow$en | en$rightarrow$zh | ||||
|---|---|---|---|---|---|---|
| BLEU | COMET | XCOMET/QE | BLEU | COMET | XCOMET/QE | |
| Three-Stage | 40.61 | 0.826 | 0.812 / 0.859 | 55.30 | 0.901 | 0.864 / 0.911 |
| Two-Stage | 43.65 | 0.834 | 0.813 / 0.857 | 61.51 | 0.914 | 0.867 / 0.922 |
| UniSS | 30.87 | 0.791 | 0.793 / 0.814 | 48.91 | 0.875 | 0.840 / 0.878 |
| SeamlessExpressive | 17.66 | 0.695 | 0.720 / 0.702 | 37.87 | 0.824 | 0.805 / 0.825 |
| Seed LiveInterpret 2.0 | 26.20 | 0.765 | 0.774 / 0.796 | 47.99 | 0.876 | 0.841 / 0.885 |
| Step-Audio 2 | 33.68 | 0.802 | 0.803 / 0.836 | 50.61 | 0.891 | 0.856 / 0.900 |
The gap between text translation and speech translation is small for most systems, again suggesting that the main failure modes are not just lexical transfer errors. Instead, expressive information is lost or altered during synthesis or across the speech pipeline.
Interpretation of the Findings
- Translation fidelity is not the bottleneck. Many systems, especially cascaded ones, reach strong BLEU/COMET/XCOMET values.
- Emotion is the hardest expressive dimension. Cascaded systems perform especially poorly, and even the best systems remain far from perfect.
- Scenario style is easier than emotion but still imperfect. Scores are generally higher than emotion and often above 4 for the better systems, but the paper still treats style as a meaningful open challenge.
- NVs benefit from explicit representation. Systems that explicitly carry NV tags into translation do better than end-to-end systems, but the best score is still only 2.31/5.
- Duration alignment requires dedicated control. UniSS is the clear winner here, which matches the model’s design.
- Adding style instructions to TTS does little. The w/o Instruct variants are almost unchanged from the full cascades, suggesting that simply giving TTS a style instruction is not enough to recover source expressiveness.
Limitations and Scope
- The benchmark currently covers only Chinese$leftrightarrow$English. The authors argue the pipeline is language-agnostic and can be extended, but that is future work.
- Expressiveness evaluation depends on a captioning model, so judge quality is bounded by the perceptual abilities of the audio-language stack.
- Scenario style is acknowledged as the most subjective expressive dimension and remains the hardest for the judge.
- The benchmark is built from publicly accessible web audio, and the paper notes that audio without redistribution permission is not redistributed; in those cases, only metadata and annotations are released.
- Samples with private or sensitive content are removed during filtering and validation.
Bottom Line
STEB reframes S2ST evaluation around a more realistic question: not just did the model translate the words correctly, but did it preserve how the source sounded? The benchmark’s results show a consistent gap between semantic transfer and expressive transfer. In the authors’ evaluation, current systems can already produce competent translations, but emotion and NV preservation remain weak, and even the best systems still fall short of faithful expressive translation. The paper’s main technical contribution is therefore both the benchmark itself and the validated reference-free method for scoring expressive consistency.
Code & Implementation
This repository hosts the official implementation of STEB, the Speech-to-Speech Translation Expressiveness Benchmark described in the paper.
The code provides a comprehensive evaluation pipeline that scores speech-to-speech translation outputs across multiple dimensions, including translation fidelity and expressive attributes such as emotion, scenario style, and non-verbal vocalization preservation.
The implementation is modularized under core_functional_modules/ for components like captioning and sound event detection, while evaluation/ contains scripts and modules designed for loading data, feature extraction, merging, and metric calculation. The main evaluation can be executed via the provided shell script evaluation/run_eval.sh, which coordinates the multi-phase evaluation workflow using configurable environment variables.
The repository also integrates large language model-based judging mechanisms for expressive attribute evaluation, enabling a novel caption-then-summarize approach outlined in the paper.
This setup aligns closely with the paper's methodology, facilitating reproducible and extensible automatic evaluation of S2ST systems.