Joint Residual Reweighting
Joint Residual Reweighting for Classifier Free Guidance in Flow-Matching Zero-Shot TTS
The paper presents a new method for zero-shot TTS that separates classifier-free guidance into text, speaker, and joint residuals, allowing better control over speaker similarity and text correctness. This reduces the trade-off in prior methods by independently weighting speaker and joint terms during inference.
Links
Paper & demos
Abstract
Classifier-free guidance (CFG) is widely used in flow-matching-based zero-shot text-to-speech (TTS), where generation is typically controlled by two conditions: the target text and a prompt speech signal. Standard CFG strengthens these conditions jointly, while recent branch-selective guidance methods attempt to enhance text or speaker conditioning separately, often leading to a trade-off between text correctness and speaker similarity. In this paper, we revisit the CFG under independently masked text and speech-prompt conditions, and decompose the guidance field into text, speaker, and joint residuals. We show that conventional speaker-selective guidance entangles the speaker residual with the joint residual, which may disturb text-related generation. Based on this observation, we propose joint residual reweighting, which independently controls the speaker and joint residuals within the standard CFG framework. Experiments on F5-TTS and CosyVoice2 show that the proposed method improves speaker similarity while maintaining competitive text correctness, demonstrating the usefulness of the joint residual for balancing speaker fidelity and text accuracy in zero-shot TTS.
Introduction
This paper studies inference-time guidance for flow-matching zero-shot text-to-speech (TTS), where a model must satisfy two goals at once: reproduce the requested text accurately and preserve the voice characteristics of a short reference utterance. The setting is especially sensitive because the same guidance mechanism that improves speaker similarity can also damage text correctness, and vice versa.
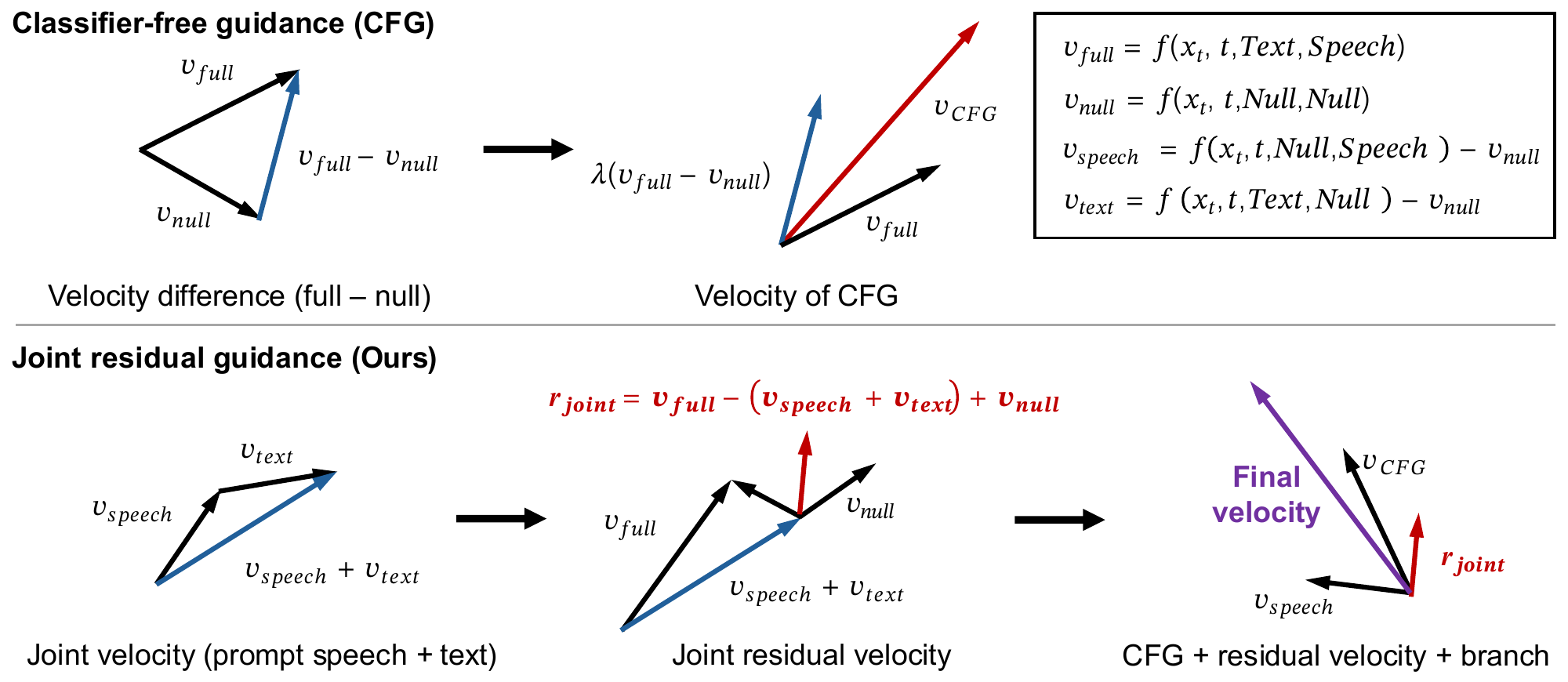
The paper starts from the observation that classifier-free guidance (CFG) is now a standard sampling tool for flow-matching TTS backbones such as F5-TTS and CosyVoice2, but the usual branch-difference view is too coarse for zero-shot TTS. Standard CFG compares a fully conditioned prediction with a null-conditioned prediction, so it boosts the combined effect of text and speaker conditioning together. Recent selective or branch-specific methods try to emphasize text or speaker information separately, but they still often behave as if each branch difference is a single direction. The authors argue that in zero-shot TTS there is a third component hiding inside the full conditional direction: a joint residual that only appears when text and speech-prompt conditions are provided together.
The key contribution is therefore a four-branch residual decomposition and a guidance rule called joint residual reweighting. Instead of treating the full-minus-null direction as one vector, the method decomposes it into text, speaker, and joint residuals, then allows the speaker residual and the joint residual to be reweighted independently while keeping standard CFG as the base sampler. The paper reports that this improves speaker similarity while keeping text correctness competitive, and on CosyVoice2 it improves both speaker similarity and ASR error metrics over CFG baselines.
Problem setting and motivation
The paper considers a flow-matching TTS model with a velocity predictor $v = f(x_t,t,c_{\mathrm{text}},c_{\mathrm{spk}})$, where $x_t$ is the current sampling state, $t$ is the flow time, $c_{\mathrm{text}}$ is the text condition, and $c_{\mathrm{spk}}$ is the speech-prompt or speaker condition. Because both conditions can be independently masked at inference time, the same model can produce four branches:
$$v_n = f(x_t,t,\varnothing_{\mathrm{spk}},\varnothing_{\mathrm{text}}),\quad v_t = f(x_t,t,\varnothing_{\mathrm{spk}},c_{\mathrm{text}}),\quad v_s = f(x_t,t,c_{\mathrm{spk}},\varnothing_{\mathrm{text}}),\quad v_f = f(x_t,t,c_{\mathrm{spk}},c_{\mathrm{text}}).$$
Here $v_n$ is the null branch, $v_t$ is the text-only branch, $v_s$ is the speaker-only branch, and $v_f$ is the full text-speaker branch. The paper’s main thesis is that zero-shot TTS guidance should not treat $v_f - v_n$ as a single undifferentiated direction, because part of that difference is actually a text-only residual, part is a speaker-only residual, and part is a joint interaction term that exists only when both conditions are present together.
This perspective is used to reinterpret existing CFG variants. The authors specifically argue that speaker-selective guidance of the form $v_f + \beta (v_f - v_t)$ does not isolate speaker information cleanly: it also includes the joint residual. That entanglement can disturb text-related generation, which explains why many branch-level tricks exhibit a trade-off between speaker similarity and text correctness.
Methodology
Four-branch residual decomposition
The paper defines the single-condition residuals relative to the null branch as
$$\Delta v_t = v_t - v_n,\qquad \Delta v_s = v_s - v_n.$$
The full conditional direction is then decomposed as
$$v_f - v_n = \Delta v_t + \Delta v_s + r_j,$$
with the joint residual
$$r_j = v_f - v_t - v_s + v_n.$$
In words, $r_j$ is the part of the full conditional direction that remains after subtracting what text-only and speaker-only conditions already explain. This is the paper’s central analytical move: it turns standard CFG from a single branch-difference rule into a three-component residual view.
Standard CFG then becomes a special case that scales all three components together:
$$v_{\mathrm{CFG}} = v_f + \lambda (v_f - v_n).$$
Under the residual view, this means standard CFG amplifies the text, speaker, and joint residuals with the same strength. The paper argues that this is too blunt for zero-shot TTS, because the speaker and joint components may need different treatment to avoid sacrificing text accuracy.
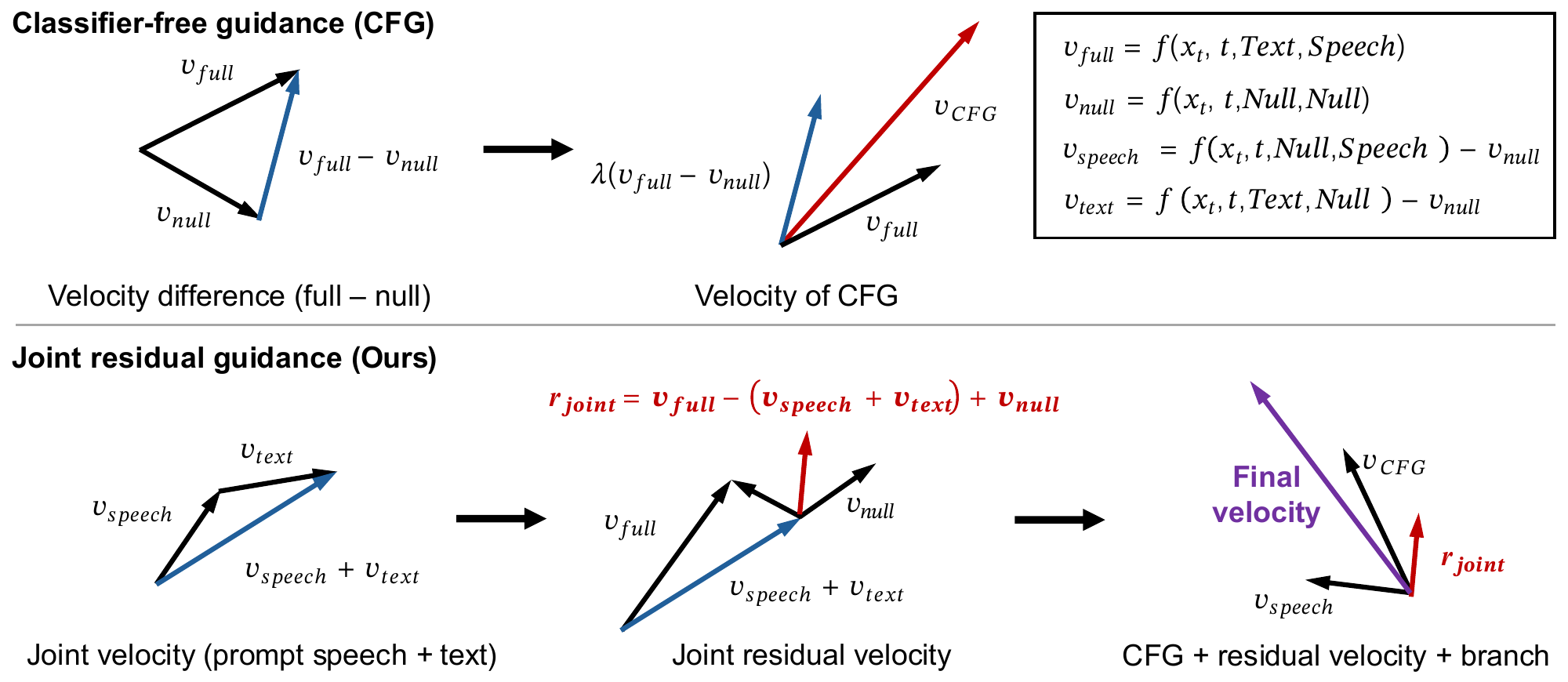
Joint residual reweighting
Building on the decomposition, the authors propose a sampler that keeps standard CFG as the base and adds extra weights on selected residual components. In full generality, they write
$$v = v_{\mathrm{CFG}} + \gamma_{\mathrm{text}} \Delta v_t + \gamma_{\mathrm{spk}} \Delta v_s + \gamma_{\mathrm{joint}} r_j.$$
They then focus on a speaker-oriented variant, which they report works best in their design-space exploration:
$$v = v_{\mathrm{CFG}} + \gamma_{\mathrm{spk}} \Delta v_s + \gamma_{\mathrm{joint}} r_j.$$
This is the practical method evaluated in the paper. Its effect is not just to increase the global CFG scale. Expanding the equation back into the four branches gives a different mixture of $v_f$, $v_t$, $v_s$, and $v_n$, so the sampler can independently tune the speaker residual and the joint residual rather than forcing both to move together.
The paper emphasizes that the method does not change the number of sampling steps or the integration schedule. It is an inference-time guidance modification. The cost is that computing $r_j$ requires four branch evaluations instead of two, although the four branches share the same $x_t$ and $t$ and can therefore be evaluated in parallel or in a single batched forward pass if memory allows.
How the method relates to existing guidance rules
The residual view is used to unify several existing CFG families. Standard CFG scales all residuals together. Separated-condition CFG adjusts text and speaker residuals relative to the null branch but leaves the joint residual fixed. Speaker-selective CFG amplifies the speaker residual and the joint residual with the same coefficient, which is exactly the entanglement problem the paper wants to fix. The proposed method keeps the standard CFG text side intact while giving separate control over the speaker and joint terms.
| Rule | Guidance rule | Branch weights $(v_f,v_t,v_s,v_n)$ | Residual weights $(\Delta v_t,\Delta v_s,r_j)$ |
|---|---|---|---|
| CFG | $v_f + \lambda (v_f - v_n)$ | $(1+\lambda, 0, 0, -\lambda)$ | $(1+\lambda, 1+\lambda, 1+\lambda)$ |
| Separated CFG | $v_f + \alpha_t (v_t - v_n) + \alpha_s (v_s - v_n)$ | $(1, \alpha_t, \alpha_s, -\alpha_t-\alpha_s)$ | $(1+\alpha_t, 1+\alpha_s, 1)$ |
| Speaker-selective CFG | $v_f + \beta (v_f - v_t)$ | $(1+\beta, -\beta, 0, 0)$ | $(1, 1+\beta, 1+\beta)$ |
| Ours | $v_{\mathrm{CFG}} + \gamma_s \Delta v_s + \gamma_j r_j$ | $(1+\lambda+\gamma_j, -\gamma_j, \gamma_s-\gamma_j, -\lambda-\gamma_s+\gamma_j)$ | $(1+\lambda, 1+\lambda+\gamma_s, 1+\lambda+\gamma_j)$ |
Experimental setup
The paper evaluates the method on two representative flow-matching zero-shot TTS backbones: F5-TTS and CosyVoice2. Both are selected because their inference-time conditions can be independently disabled, which makes the four-branch decomposition feasible without changing the underlying model weights.
The evaluation datasets are LibriSpeech-test, SEED-EN, and SEED-ZH. For English text correctness, the paper reports WER using Faster-Whisper Large-v3. For Chinese, it reports CER using Paraformer-zh. For speaker similarity, it uses a WavLM-large-based speaker verification model and computes cosine similarity between synthesized and ground-truth speech embeddings.
The paper reports the following inference settings:
- F5-TTS: 32 sampling steps, original CFG strength $2.0$, and the selected residual setting adds $1.0S$ and $2.5I$ on top of the CFG velocity, where $S$ denotes the speaker residual and $I$ denotes the joint interaction residual.
- CosyVoice2: official CFG baseline strength $0.7$, 10 sampling steps, and the selected residual setting adds $0.5S$ and $0.25I$.
The paper also clarifies that in CosyVoice2 the text condition corresponds to the flow encoder condition $\mu$, while the speaker side combines the global speaker embedding and the prompt acoustic condition.
Importantly, the paper does not introduce a new training objective or retrain the backbones. The contribution is an inference-time guidance rule and an analysis of how the branch components interact.
Main results
The main results show a consistent pattern: on both backbones, the proposed residual reweighting improves speaker similarity, and on CosyVoice2 it also improves the ASR error metrics across all three test sets compared with the CFG baselines. The strongest interpretation in the paper is that the joint residual provides a useful extra degree of freedom for balancing voice fidelity and text correctness.
| Backbone | Method | Branches | LibriSpeech-test SIM | LibriSpeech-test WER | SEED-EN SIM | SEED-EN WER | SEED-ZH SIM | SEED-ZH CER |
|---|---|---|---|---|---|---|---|---|
| F5-TTS | CFG (strength = 1.5) | 2 | 0.6644 | 0.0210 | 0.6768 | 0.0146 | 0.7609 | 0.0157 |
| CFG (strength = 2.0) | 2 | 0.6745 | 0.0197 | 0.6811 | 0.0136 | 0.7636 | 0.0158 | |
| Ours | 4 | 0.6819 | 0.0196 | 0.6875 | 0.0146 | 0.7630 | 0.0153 | |
| CosyVoice2 | CFG (strength = 0.7) | 2 | 0.6561 | 0.0212 | 0.6586 | 0.0205 | 0.7531 | 0.0153 |
| CFG (strength = 1.0) | 2 | 0.6585 | 0.0219 | 0.6620 | 0.0198 | 0.7547 | 0.0144 | |
| Ours | 4 | 0.6690 | 0.0211 | 0.6706 | 0.0194 | 0.7631 | 0.0139 |
Two points stand out from the table. First, on CosyVoice2 the method improves both similarity and recognition quality over the CFG baselines on every reported test set: SIM rises from $0.6561$ to $0.6690$ on LibriSpeech-test, from $0.6586$ to $0.6706$ on SEED-EN, and from $0.7531$ to $0.7631$ on SEED-ZH, while WER or CER also decreases. Second, on F5-TTS the method improves speaker similarity on the English sets and keeps text accuracy competitive: it increases SIM to $0.6819$ on LibriSpeech-test and $0.6875$ on SEED-EN, while matching or slightly improving the error rate relative to the stronger CFG baseline. On SEED-ZH, it slightly lowers CER to $0.0153$ with nearly unchanged SIM.
The paper also includes quoted numbers from Selective CFG as a reference. Those numbers suggest the usual trade-off of branch-level guidance: the method can achieve strong similarity, but it may do so at the cost of higher WER/CER. The proposed residual reweighting is presented as a way to reduce that trade-off by exposing the joint residual separately.
Ablation on residual components
The ablation study is on F5-TTS and focuses on LibriSpeech-PC. All variants use CFG strength $2.0$ as the base sampler, and the paper uses $S$ for the speaker residual, $I$ for the joint interaction residual, and $T$ for a text residual control. The goal is to test whether the joint residual really matters, rather than simply adding more guidance directions indiscriminately.
| Method | Formula | SIM | WER |
|---|---|---|---|
| CFG baseline | $v_{\mathrm{CFG}}$ | 0.6745 | 0.0197 |
| Speaker + joint | $v_{\mathrm{CFG}} + (S + I)$ | 0.6788 | 0.0196 |
| Speaker + stronger joint | $v_{\mathrm{CFG}} + (S + 2.5I)$ | 0.6819 | 0.0196 |
| $S + T$ control | $v_{\mathrm{CFG}} + (S + T)$ | 0.6621 | 0.0180 |
The ablation supports the paper’s interpretation of the residuals. Adding the speaker and joint residuals improves speaker similarity over CFG with essentially unchanged WER. Increasing the joint residual weight further boosts SIM, which suggests that the joint term carries useful speaker-related information beyond the single speaker residual. By contrast, the $S + T$ control reduces WER but significantly hurts SIM, reinforcing the authors’ claim that the residual components should not be mixed arbitrarily.
Qualitative discussion
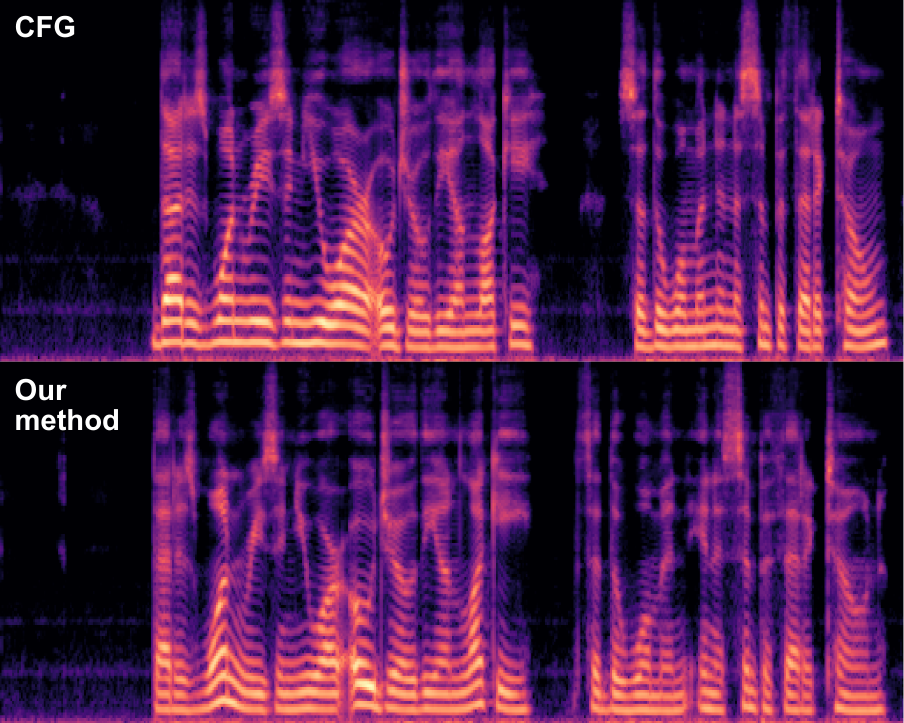
The paper includes a case study with CosyVoice2 on a LibriSpeech utterance. The target text is correctly synthesized by both the default CFG sampler and the residual-reweighted sampler, and both outputs have zero WER. This makes the example useful for isolating speaker and acoustic differences rather than text realization.
Under the same text-correctness outcome, the speaker similarity increases from $0.57$ with default CFG to $0.71$ with the proposed method. The paper also reports a more expressive spectrogram pattern with clearer local energy variation, which is consistent with the quantitative SIM gains. The qualitative takeaway is that the method is not just strengthening all conditions uniformly; it is changing the balance among conditional components in a way that can improve speaker fidelity after text has already been generated correctly.
Discussion and limitations
The most important limitation is inference cost. Standard CFG requires two branches per step, while the explicit joint-residual formulation needs four branch evaluations to compute $v_f$, $v_t$, $v_s$, and $v_n$. The number of integration steps does not change, and the paper notes that the branches can be computed in a batched pass because they share the same $x_t$ and $t$, but the method is still more expensive than plain CFG.
A second limitation is that the exact masking semantics are backbone dependent. In F5-TTS, the conditions are naturally described as text and speech prompt. In CosyVoice2, the text side is represented by the flow encoder condition $\mu$, while the speaker side combines a global speaker embedding and the prompt acoustic condition. The algebra is shared, but faithful implementation requires care in defining what counts as each branch.
The authors also frame the method as a design-space and analysis tool rather than a production acceleration technique. Future work directions mentioned in the paper include applying joint-residual reweighting only at selected sampling intervals, learning an adaptive residual schedule, or distilling the four-branch sampler into a cheaper student sampler.
Conclusion
The paper’s main contribution is a four-branch residual analysis of classifier-free guidance for flow-matching zero-shot TTS, together with a practical speaker-oriented reweighting rule. By decomposing the full conditional direction into text, speaker, and joint residuals, the method explains why speaker-selective guidance can interfere with text-related generation, and it provides a cleaner way to tune the speaker-text balance at inference time. Across F5-TTS and CosyVoice2, the proposed method consistently improves speaker similarity and, on CosyVoice2, also improves WER/CER. The overall message is that the joint residual is a useful control degree of freedom for balancing voice fidelity and text accuracy in zero-shot TTS.