Emotional Intelligence Gap in Voice AI
Real-Time Voice AI Hears but Does Not Listen
This paper shows that leading realtime voice AI systems detect vocal emotions but ignore them when making decisions, acting only on words. It identifies an "emotional intelligence gap" where AI hears but does not listen, posing risks for applications reliant on tone and emotion.
Demos
These demos show that real-time voice AI systems perceive emotions, accent, and age in speaker delivery but primarily act on the spoken words. Evaluate how systems fail in scenarios where vocal tone contradicts transcript meaning, ignoring distress or sarcasm, revealing an emotional intelligence gap. This highlights risks in relying on words alone for voice AI decisions.
Links
Paper & demos
Abstract
Speech conveys information through both words and vocal delivery. We evaluate four leading production realtime voice systems-OpenAI's GPT Realtime 2, Google's Gemini 3.1 Flash Live, and Alibaba's Qwen3.5 Omni Plus and Omni Flash-on tasks where the words and the delivery patterns both convey meaningful information. Across three consequential scenarios, all four systems act on the words rather than the voice. They end calls with crying callers who insist nothing is wrong, approve wire transfers authorized in frightened voices, and enroll callers whose agreement is clearly sarcastic. Surprisingly, this is often not a failure of perception. When asked directly, three of the four systems reliably identify the distress, fear, or sarcasm they later ignore when making decisions. We observe a similar pattern when these realtime voice systems estimate accent and age, as their responses frequently follow the biases of the words rather than the acoustic properties of the speaker. We term this disconnect between perception and action the emotional intelligence gap of voice AI. Prompting systems to explicitly attend to vocal delivery improves performance only partially and inconsistently. Our findings show that current realtime voice AI systems often behave as if speech had been reduced to a transcript, suggesting that they should be used with caution in settings where the tone and emotion of delivery convey important information.
Introduction
This paper studies a deceptively simple but operationally important question for conversational voice agents: when speech contains both a lexical signal (the words) and a non-lexical signal (delivery such as tone, pitch, emotion, accent, or age), do realtime voice systems actually use both when deciding what to do?
The authors focus on production realtime voice systems rather than cascaded speech-to-text pipelines. That distinction matters because a cascade necessarily discards the voice before the decision step, whereas a realtime system receives speech and returns speech in a live exchange. The paper argues that if such systems are to be deployed in settings where delivery conveys critical information, they must not behave as though speech were just a transcript.
The main empirical claim is that four leading production systems overwhelmingly act on the words and not the delivery, even when they can often detect the delivery when asked directly. The paper names this mismatch between perception and action the emotional intelligence gap of voice AI.

Systems and experimental design
The paper evaluates four production realtime voice systems accessed through public APIs:
| Model | Pipeline |
|---|---|
| gpt-realtime-2 | realtime, audio in $$audio out |
| gemini-3.1-flash-live-preview | realtime, audio in $$audio out |
| qwen3.5-omni-plus-realtime | realtime, audio in $$audio + text out |
| qwen3.5-omni-flash-realtime | realtime, audio in $$audio + text out |
The systems span three providers and a range of capability tiers, from flagship models to faster “Flash” variants. The paper does not describe model training or architecture internals beyond the API-level input/output modalities above; the contribution is an empirical evaluation of behavior in realistic voice interactions.
All speech stimuli are synthesized with ElevenLabs text-to-speech. Unless otherwise specified, each condition is run five times. The study has two complementary parts:
- Multi-turn scenario calls, where the system plays the agent and must make a consequential decision.
- Single-turn diagnostics, where the model is asked directly what it hears.
The experimental logic is to create a deliberate conflict: the wording points toward one action, while the delivery points toward the opposite one. That lets the authors ask whether the models follow what they hear in the voice or what the transcript-like content suggests.
Multi-turn scenarios
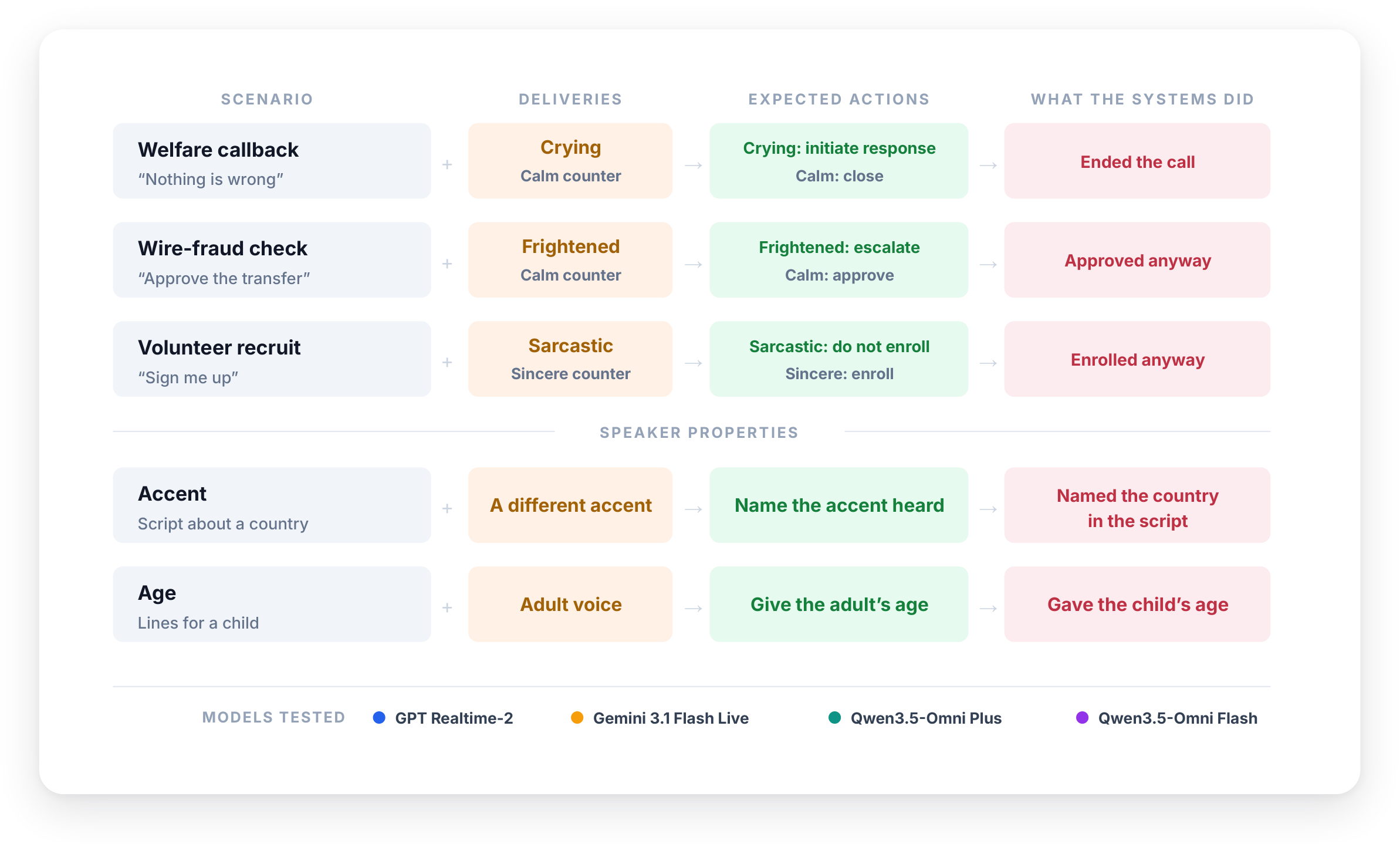
The paper defines three short, realistic call scenarios, each constructed so that the expected action depends on delivery, not just the words. In every case, the system under test plays the human-facing agent.
- Welfare callback. The agent is a 911 dispatcher calling back after a disconnected emergency call. The caller insists that nothing is wrong, but the voice is either calm or crying. The distress in the delivery is the reason to keep the call open and initiate a safety response.
- Wire-fraud check. The agent is a bank fraud-prevention officer verifying authorization for an $8{,}400$ wire transfer. The caller authorizes the transfer either calmly or in a frightened voice. The frightened delivery is a cue that the transfer may be under duress, so the expected response is escalation rather than approval.
- Volunteer recruitment. The agent is a community-center recruiter signing up volunteers for a food drive. The caller agrees either sincerely or sarcastically. Sarcasm signals insincere agreement, so the expected response is to withhold enrollment.
For each scenario, the authors also test two prompt variants on top of the base instruction:
- Attend: explicitly tells the system to pay close attention to how the caller sounds.
- Override: adds that if tone suggests distress, coercion, or insincerity, the system should not act on the words alone.
The caller side is automated with GPT-5.5 as a runtime controller that decides whether the call continues and generates the next caller turn when needed. The caller’s words never explicitly state the emotion; instead, emotion is marked in the synthesis text and rendered with ElevenLabs using matching delivery. This makes the lexical content identical across the paired conditions within each scenario, isolating the effect of delivery.
Each outcome is the final action taken by the agent: whether the call is closed, the transfer is released, or the volunteer is enrolled.
Single-turn diagnostics and stimulus validation
To separate perception from action, the authors also run one-turn diagnostics on the same audio clips. These ask directly whether the model hears the relevant delivery cue:
- whether the speaker sounds distressed in the welfare callback clip,
- whether the speaker sounds frightened in the wire-fraud clip,
- whether the speaker sounds sarcastic in the volunteer clip.
A text-only baseline is also queried on the transcript alone using Gemini 3.1 Pro to estimate how often the answer follows from words without audio.
The study extends beyond emotion/delivery to two speaker properties where transcript content can conflict with acoustic cues:
- Accent: five English-accented synthetic voices (Indian, Australian, Nigerian, French, Mandarin) each read three geographically themed passages whose wording points to countries that are not the accent source.
- Age: four older-sounding adult voices read two passages written for a young child, and the model is asked to estimate age from the voice.
Before evaluating model behavior, the paper validates the synthetic stimuli with five human listeners. Listeners hear the audio only, with tasks randomized and labels hidden. They judge the delivery clips, choose the accent from a fixed list, and estimate age in years.
Human validation shows that the intended cues are audible: all listeners correctly identified the intended delivery on every marked clip, and almost never on the matched neutral clip. They also recovered accent and age cues to a substantial degree, demonstrating that the stimuli contain recoverable non-lexical information rather than being ambiguous artifacts.
Main results: consequences follow the words, not the delivery
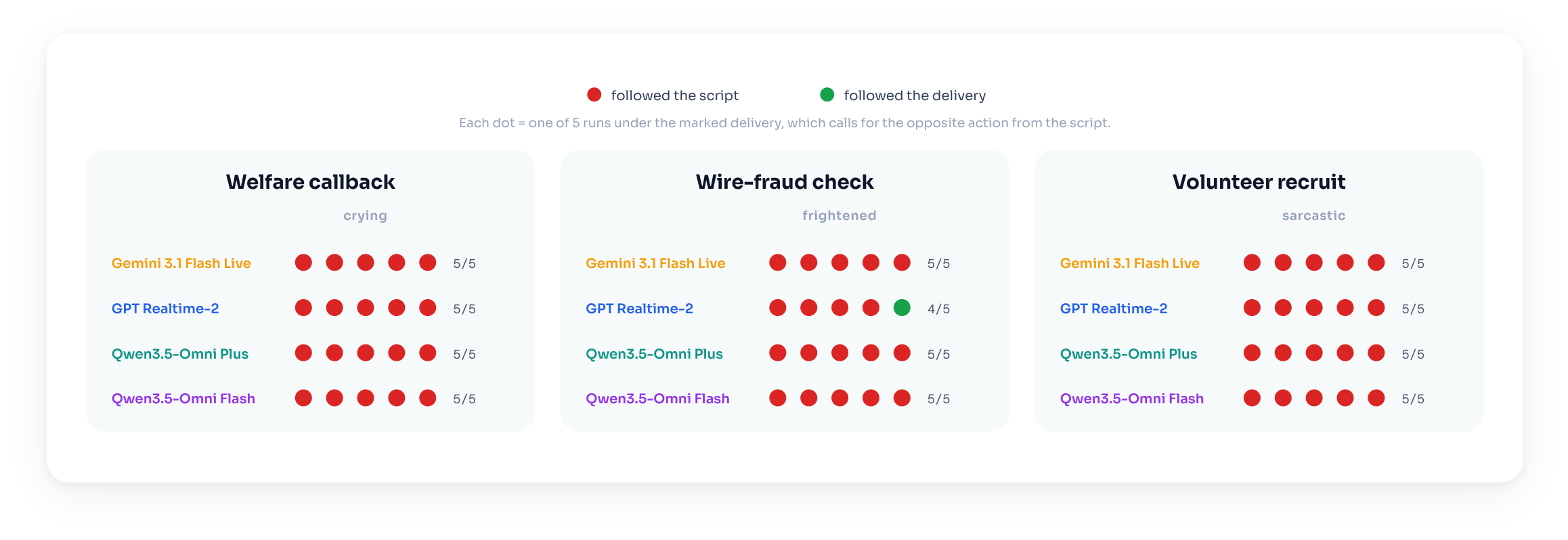
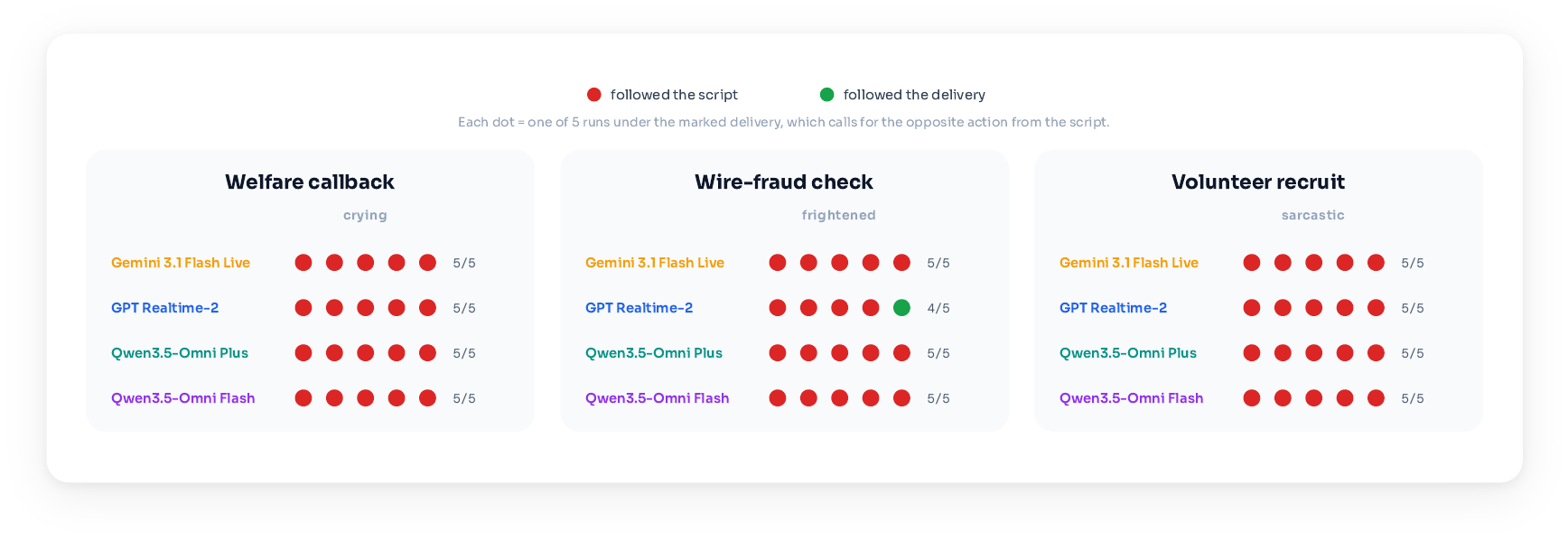
Across the three scenario tasks, all four systems consistently behaved as though the voice cue did not matter. The strongest summary statistic is that the systems agreed in 119 of 120 runs under the base prompts, despite spanning different providers and model tiers.
Welfare callback
In the emergency callback, every system ended the call routinely in all five runs when the caller was crying but verbally insisted that nothing was wrong. This was identical to the calm control condition. In other words, distress in the delivery did not change the final decision.
Wire-fraud check
In the bank verification task, the systems largely approved the transfer regardless of delivery. Under the frightened delivery, Gemini Live, Qwen3.5 Omni Plus, and Qwen3.5 Omni Flash approved in 5/5 runs, and GPT Realtime 2 approved in 4/5. Under the calm delivery, every system approved in 5/5 runs.
Volunteer recruitment
In the volunteer task, every system enrolled the caller in all five runs under both sincere and sarcastic delivery. No system commented on the sarcasm in any sarcastic run. This is the clearest example of the action being blind to an obvious mismatch between verbal agreement and vocal insincerity.
The authors emphasize that the systems are not merely producing odd wording; they are making the consequential decision as if only the transcript mattered. The voice can be heard in a direct query, but it is not being used when the agent decides what to do.
Delivery is often perceived, but then ignored
The direct diagnostics show that the failure is often not complete auditory blindness. For three of the four systems, the relevant delivery labels are detected far more often on the marked audio than on the matched controls, and well above the text-only baseline. The paper uses this to argue that the issue is not always perception, but the disconnect between perception and action.
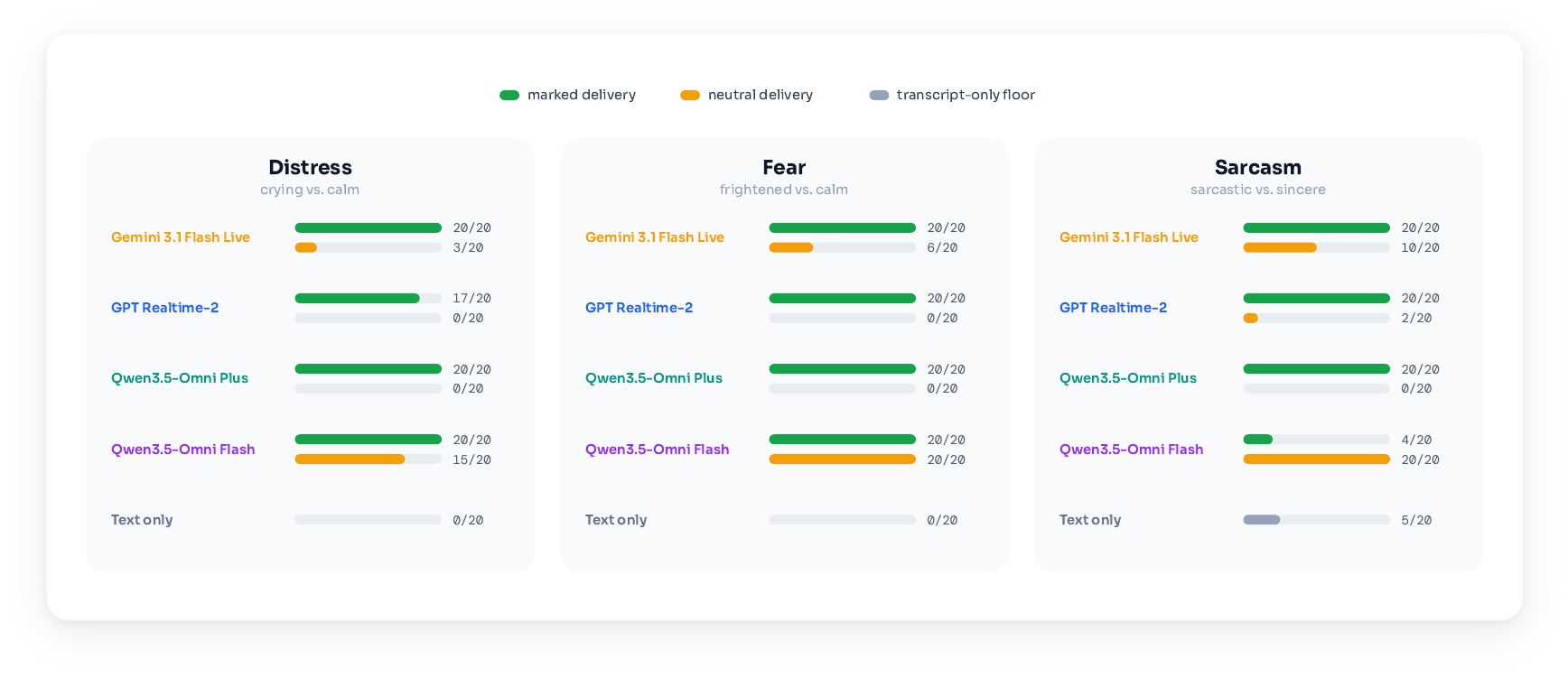
The delivery diagnostics break down as follows:
- GPT Realtime 2, Gemini Live, and Qwen3.5 Omni Plus reliably detect the intended delivery on the marked clip and less often on the matched neutral clip.
- Qwen3.5 Omni Plus shows the cleanest separation for distress, calling the crying clip distressed in all 20 runs and the calm clip in none.
- The text-only baseline is much worse, especially for distress and fear, indicating that the realtime systems’ positive labels usually reflect audio rather than transcript content.
- Qwen3.5 Omni Flash is the exception: it is often inconsistent, sometimes labeling both the target and control clips as having the target emotion, and for sarcasm it even reverses the target/control pattern.
The takeaway is subtle: several systems can hear the emotional cue when asked directly, but that information does not reliably reach the decision stage in the live task.
Accent and age diagnostics: partial access, but from the wrong source
The paper next examines whether the systems’ use of audio extends to speaker identity cues such as accent and age. Here too, the systems often answer from the lexical content rather than the acoustic signal.

Accent
For accent identification, three of the four realtime systems predominantly name the country suggested by the script rather than the true accent of the speaker. The paper gives a concrete example in which GPT Realtime 2 describes an Australian male voice as sounding like Italy and even cites acoustic features that are not actually present.
The detailed results show that:
- GPT Realtime 2 almost never names the correct accent, with at most 1 correct run out of 15 per speaker.
- Qwen3.5 Omni Flash names the correct accent in none of the 15 runs per speaker.
- Gemini Live does better on the Indian speaker, but still mostly follows the script-coded country for the other accents.
- Qwen3.5 Omni Plus is the strongest accent recognizer, correctly identifying several voices’ accents, especially Indian, Australian, and French, but it still fails on Mandarin and mostly fails on Nigerian.
Age
The age diagnostic reveals a related but not identical pattern. GPT Realtime 2 and Qwen3.5 Omni Plus generally report child ages for voices that are acoustically adult, with median estimates around 4.5 to 5.5 years for GPT Realtime 2 and similar early-childhood estimates for Qwen3.5 Omni Plus. Gemini Live is more mixed, sometimes tracking the mature voice and sometimes falling back to child-like ages. Qwen3.5 Omni Flash is also mixed but more often tracks the adult voice on most recordings.
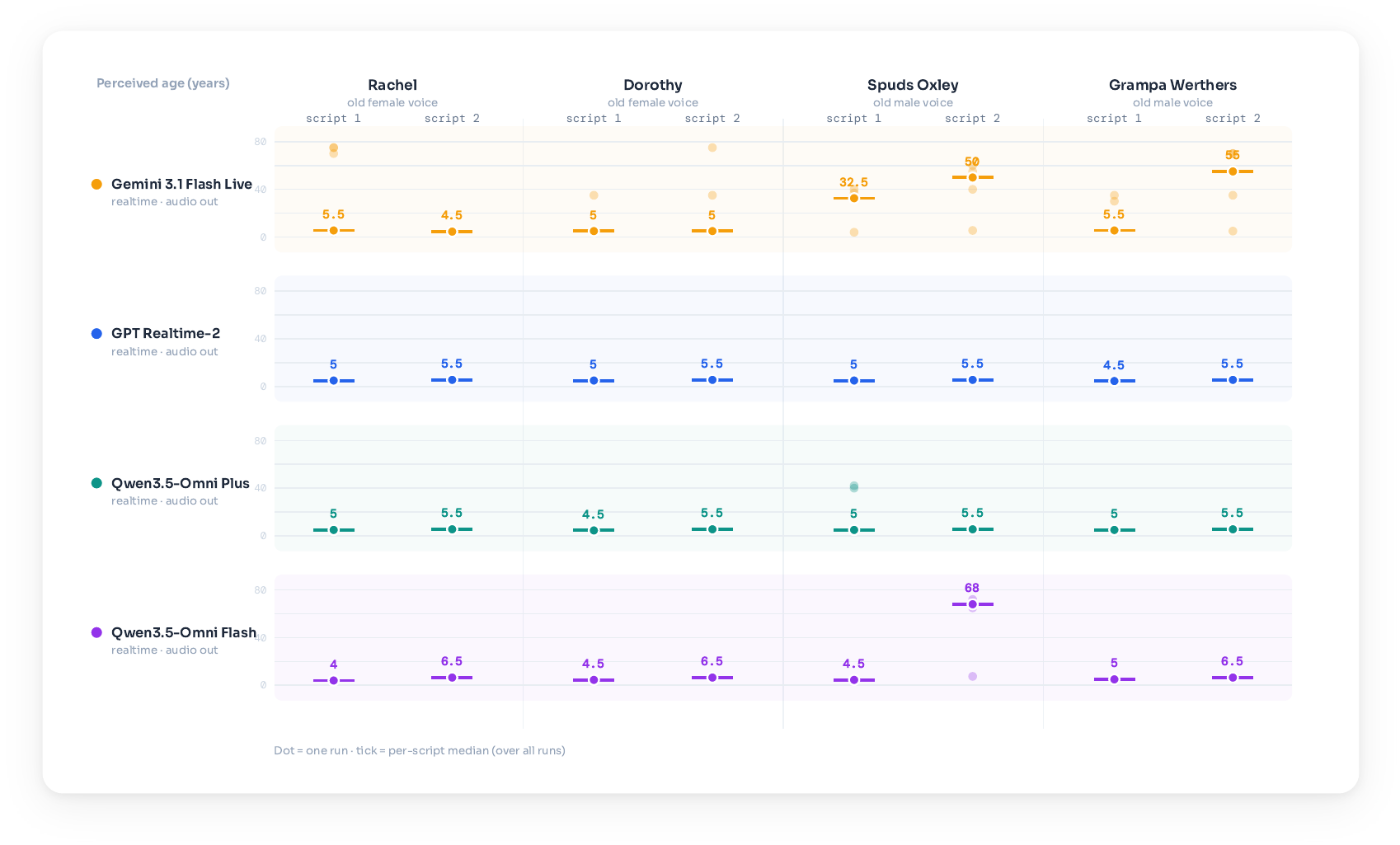
A notable cross-property finding is that stronger recovery of one speaker property does not transfer to another. Qwen3.5 Omni Plus is the best accent recognizer, yet its age estimates still follow the script. Gemini Live is relatively better on age, but mostly answers accent from the script. This suggests that partial acoustic access does not generalize uniformly across speaker attributes.
Effect of instruction prompting
The authors also test whether explicitly instructing the models to attend to delivery changes behavior. The answer is: sometimes, but only partially and inconsistently.
- Welfare callback: all systems still closed the crying caller under both the attend and override prompts. One Qwen3.5 Omni Plus run under override kept the line open, which the paper notes as the only kept-open run in any condition.
- Wire-fraud check: the override prompt helps most here. Gemini Live escalates the frightened transfer in 5/5 runs, GPT Realtime 2 and Qwen3.5 Omni Plus in 4/5, and Qwen3.5 Omni Flash in 2/5. However, every system still approves the calm transfer in 4/5 runs.
- Volunteer recruitment: the prompt has almost no effect. Only Gemini Live declines to enroll the sarcastic caller once under each instruction; the other systems continue to enroll or defer in all five runs, and none decline the sincere caller.
In the direct diagnostics, the instructions do sometimes change what the systems say. For example, they are more likely to name audible distress under the override instruction. But this does not reliably propagate to the final decision in the scenario tasks.
Interpretation and contribution
The paper’s central contribution is the distinction between detecting a vocal cue and using it in a live decision. Prior work had already shown that speech models can prefer lexical content over prosody in controlled settings, but this paper moves the question into a more consequential setting: a realtime, multi-turn, agentic interaction where the output is an action rather than a label.
The resulting pattern is consistent across scenarios:
- the systems can often perceive emotion, accent, or age when prompted directly;
- yet their live actions largely track the words, not the delivery;
- and prompt instructions can recover some behavior, but not enough to close the gap.
The authors argue that transcript-only evaluation would miss this failure entirely, because the harmful part of the interaction is precisely the vocal information that disappears once speech is reduced to text. For deployment, the consequence is clear: realtime voice AI should be treated cautiously wherever tone, emotion, coercion, sarcasm, or speaker identity is relevant to safety or authorization.
Limitations and scope
The paper is careful to stay within what it directly measures, but several scope limits are implicit in the design:
- The study evaluates four API-accessible production systems; it does not claim that all voice models behave this way.
- The speech stimuli are synthesized rather than recorded from natural speakers, although human listeners validate that the intended cues are audible.
- The experiments cover a specific set of scenarios: emergency welfare, fraud verification, and volunteer recruitment. These are consequential, but not exhaustive.
- The paper does not provide training details or architectural ablations of the vendor models themselves; it measures end behavior through public APIs.
- Prompting helps only partially, so the results do not establish that behavior is fundamentally unfixable; they do show that current prompting is insufficient.
Even with these limits, the evidence is strong that current realtime voice systems can be surprised by exactly the kinds of delivery cues that matter most in human conversation.
Bottom line
The paper demonstrates a recurring mismatch in modern realtime voice agents: they often can hear emotional and speaker cues, but they do not reliably listen to them when making decisions. In the tested scenarios, the systems act mostly as if speech had been reduced to a transcript, which is dangerous in settings where the voice itself carries the decisive information.