VoiceTTA
VoiceTTA: Enhancing Zero-Shot Text-to-Speech via Reinforcement Learning-Based Test-Time Adaptation
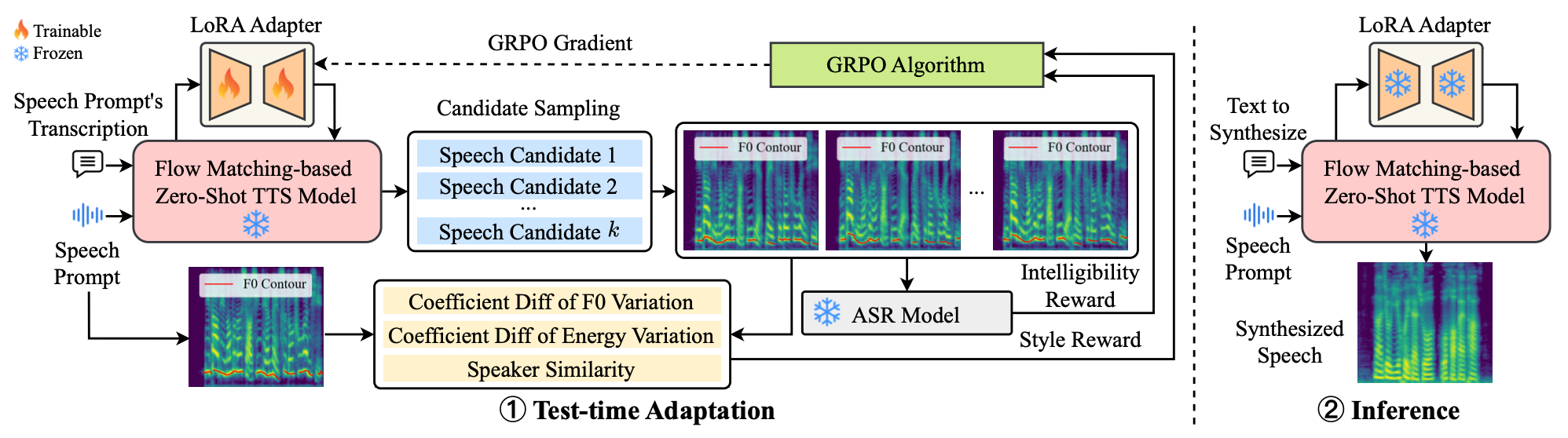
VoiceTTA enhances zero-shot text-to-speech by using reinforcement learning for test-time adaptation that optimizes lightweight prefixes with style and intelligibility rewards. It adapts pretrained models on unseen speech styles at inference without large fine-tuning datasets.
Demos
The VoiceTTA demos highlight improvements in zero-shot text-to-speech synthesis by adapting to challenging speaking styles such as accents, children, slurred speech, and dialects. Watch for enhanced voice imitation, style fidelity including pitch and energy variation, and improved intelligibility through reinforcement learning-based test-time adaptation.
Links
Paper & demos
Abstract
Recently, zero-shot text-to-speech (TTS) has enabled high-fidelity and expressive speech synthesis, but it often fails to imitate unseen speaking styles from uncommon scenarios (e.g., crosstalk, dialects). Moreover, fine-tuning pretrained models requires large, high-quality datasets, limiting rapid personalization. We propose VoiceTTA, a reinforcement learning-based test-time adaptation (TTA) method that improves voice imitation of pretrained zero-shot TTS models. VoiceTTA introduces two style rewards based on coefficient-of-variation differences of F0 and energy, combined with speaker similarity and intelligibility (WER from a pretrained Whisper model), and optimizes learnable prefixes via group relative preference optimization (GRPO) in a flow matching-based model at inference time. Extensive experiments demonstrate substantial improvements on uncommon speech prompts, outperforming state-of-the-art baselines. Audio samples are available at https://voicetta.pages.dev/
Introduction
VoiceTTA addresses a specific failure mode in zero-shot text-to-speech (TTS): pretrained systems can produce high-fidelity speech for common speaking conditions, but they often struggle to imitate unseen speaking styles that appear in uncommon prompts, such as crosstalk, dialects, slurred speech, children’s speech, and other out-of-distribution scenarios. The paper argues that this gap is caused by a mismatch between the common training distributions used by modern zero-shot TTS models and the atypical style/prosody patterns encountered at test time.
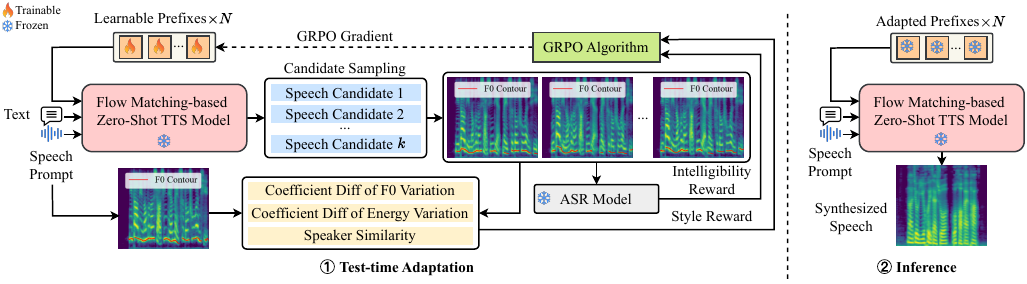
The central proposal is a test-time adaptation (TTA) method that modifies a pretrained zero-shot TTS model during inference using only a few seconds of user audio, rather than requiring conventional fine-tuning on a large target-speaker corpus. The adaptation is formulated as a reinforcement learning problem and implemented with group relative preference optimization (GRPO). Rather than updating the entire model, VoiceTTA learns a small set of prefixes that are prepended to the first layer of a flow matching-based TTS backbone. This makes the adaptation lightweight and suitable for repeated synthesis once a user has been adapted.
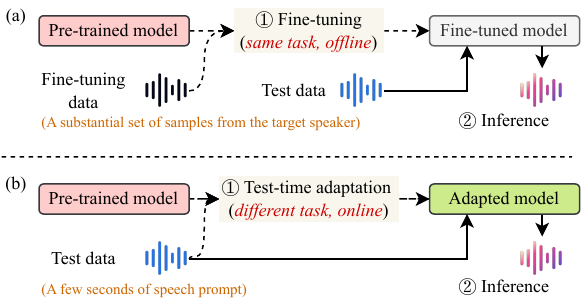
The authors position this as the first work to improve the voice imitation capability of pretrained zero-shot TTS models on unseen prompts via TTA. Their key design choice is to use auxiliary rewards that directly target style dynamics: pitch variation, energy variation, speaker similarity, and intelligibility.
Method
Problem formulation
Given a speech prompt $x$ and text content $p$, the goal is to synthesize speech $y = F_\theta(x,p)$ whose style closely matches the prompt. The paper writes this as minimizing an unknown distance function between the prompt and synthesized speech:
$$ \underset{\theta}{\text{minimize}}\; D\bigl(x, F_\theta(x,p)\bigr), $$
where $D$ measures similarity in speech characteristics. Because $D$ is not directly available, VoiceTTA estimates it through reward signals computed on multiple generated candidates.
Flow matching-based candidate generation
VoiceTTA is built on a flow matching-based TTS model. The model starts from a latent variable sampled from an isotropic Gaussian prior $\mathcal{N}(0, T^2 I)$ and progressively transforms it into a mel-spectrogram conditioned on encoded text and prompt information. A vocoder then converts the mel-spectrogram into waveform audio. The sampling temperature $T$ controls diversity: larger values produce more varied prosody and style, while smaller values are more stable but less diverse.
To compute rewards during adaptation, the method samples $k$ candidate utterances per step. In the implementation section, the paper uses $k = 4$ candidates and samples $T$ from a uniform distribution $U(0.5, 1.5)$ for candidate generation.
Reward design
The reward function combines four components. Three are style rewards, and one is an intelligibility reward.
- F0-CV reward: measures how closely the generated pitch dynamics match the reference prompt.
- Energy-CV reward: measures how closely the generated energy dynamics match the reference prompt.
- S-SIM reward: measures speaker embedding similarity between generated and reference audio.
- Intelligibility reward: uses word error rate (WER) from a pretrained Whisper model.
For voiced frames, pitch variation is summarized by the coefficient of variation of the fundamental frequency. If $F0_{\text{gen}}$ and $F0_{\text{ref}}$ denote the voiced-frame F0 contours of the generated and reference speech, then:
$$ \text{F0-CV}_{\text{gen}} = \frac{\sigma_{F0_{\text{gen}}}}{\mu_{F0_{\text{gen}}}}, \qquad \text{F0-CV}_{\text{ref}} = \frac{\sigma_{F0_{\text{ref}}}}{\mu_{F0_{\text{ref}}}}. $$
The corresponding reward is the negative absolute difference:
$$ r_{\text{F0-CV}} = -\bigl|\text{F0-CV}_{\text{gen}} - \text{F0-CV}_{\text{ref}}\bigr|. $$
Energy is computed frame-wise from the mel-spectrogram. For a frame $j$ with mel representation $M(j,m)$, the frame energy is:
$$ e_j = \sum_m M(j,m). $$
The coefficient of variation of frame energy is computed for generated and reference audio, and the Energy-CV reward is defined analogously:
$$ r_{\text{Energy-CV}} = -\bigl|\text{Energy-CV}_{\text{gen}} - \text{Energy-CV}_{\text{ref}}\bigr|. $$
Speaker similarity is computed as cosine similarity between embeddings extracted by a speaker embedding model $SE$:
$$ r_{\text{S-SIM}} = \cos\bigl(SE(A_{\text{gen}}), SE(A_{\text{ref}})\bigr), $$
where $A_{\text{gen}}$ and $A_{\text{ref}}$ are the waveforms of the generated and reference speech. The intelligibility term is the WER of the generated candidate under Whisper-based transcription.
GRPO-based test-time adaptation
The learnable prefixes are treated as a stochastic policy $\pi_\theta$ and optimized with GRPO. The paper first normalizes each reward type across the $k$ candidates into $[0,1]$, then forms a weighted sum:
$$ r^i = \lambda_1 s^i_{\text{F0-CV}} + \lambda_2 s^i_{\text{Energy-CV}} + \lambda_3 s^i_{\text{S-SIM}} + \lambda_4 s^i_{\text{Intel}}. $$
The implementation uses $\lambda_1 = \lambda_2 = 0.2$, $\lambda_3 = 1$, and $\lambda_4 = 1.5$, reflecting the paper’s observation that speaker similarity and intelligibility are the main drivers of good adaptation, while the two style-dynamics rewards provide additional guidance.
The GRPO advantage for candidate $i$ is normalized within the candidate group:
$$ A_i = \frac{r^i - \operatorname{mean}(r^1, r^2, \ldots, r^k)}{\operatorname{std}(r^1, r^2, \ldots, r^k)}. $$
The resulting GRPO objective uses a clipped ratio form:
$$ J_{\text{GRPO}} = \mathbb{E}\left[\sum_{i=1}^k \min\left(\rho_i A_i,\, \operatorname{clip}(\rho_i, 1-\epsilon, 1+\epsilon)A_i\right)\right], $$
with $\rho_i = \pi_\theta(o_i) / \pi_{\theta_{\text{old}}}(o_i)$.
Because the backbone is a flow matching model rather than a token model, the paper uses the flow matching loss as a probability proxy. If $\mathcal{L}_{\text{FM},\theta}(o)$ denotes the flow matching loss for output $o$, then the authors assume:
$$ \log p_\theta(o) \propto -\mathcal{L}_{\text{FM},\theta}(o). $$
This yields an approximate ratio term:
$$ \rho_i \approx \mathcal{L}_{\text{FM},\theta_{\text{old}}}(o_i) - \mathcal{L}_{\text{FM},\theta}(o_i). $$
A notable design choice is that the paper omits a KL penalty term from the GRPO objective, because it optimizes only the lightweight prefixes rather than the entire backbone model. After $G$ adaptation steps, the adapted prefixes are used for synthesis, and the prefixes are randomly reinitialized before moving to the next test sample so that updates do not accumulate across the test set.
Experimental Setup
The evaluation is designed around uncommon and out-of-distribution speaking styles. The authors use two test sets:
- An internal dataset with 200 speech samples spanning four uncommon categories: 90 accented, 40 children’s, 30 slurred, and 40 Chinese sketch samples.
- A dialect set sampled from KeSpeech containing 160 utterances, 20 per dialect across eight Chinese dialects.
The backbone model is F5-TTS, which also serves as the primary baseline. The paper compares against three other zero-shot TTS systems: CosyVoice, MaskGCT, and Vevo.
Implementation details reported by the paper include the following: 4 learnable prefixes are prepended to the first DiT layer input; the learning rate is $5 \times 10^{-4}$ with a 5% warmup ratio; the adaptation runs for $G = 50$ GRPO steps; and 4 candidates are generated per GRPO step. All experiments are run on an NVIDIA RTX 6000 Ada GPU.
For evaluation, the paper reports WER and S-SIM as objective metrics, and N-MOS and S-MOS as subjective metrics on a 1–5 scale. WER is derived from Whisper-Large V3 transcriptions. S-SIM is the cosine similarity between embeddings of synthesized speech and a neutral reference, computed with a speaker embedding model. For the perceptual study, 24 participants rate S-MOS on 20 reference/generated pairs.
Results
VoiceTTA’s main result is that it improves style imitation on uncommon prompts while preserving intelligibility. Averaged over the five test-time scenarios, VoiceTTA achieves the best overall balance among the compared methods, with the highest S-SIM, the highest S-MOS, and a slight edge in WER over the strongest baselines.
| Method | WER $\downarrow$ | S-SIM $\uparrow$ | S-MOS $\uparrow$ | N-MOS $\uparrow$ |
|---|---|---|---|---|
| CosyVoice | 4.57 | 0.54 | 3.25 $\pm$ 0.92 | 3.58 $\pm$ 0.73 |
| MaskGCT | 3.26 | 0.62 | 3.14 $\pm$ 0.93 | 3.14 $\pm$ 1.07 |
| Vevo | 12.41 | 0.34 | 2.05 $\pm$ 1.03 | 1.91 $\pm$ 1.01 |
| F5-TTS | 3.19 | 0.57 | 3.07 $\pm$ 1.07 | 3.36 $\pm$ 1.04 |
| VoiceTTA | 3.12 | 0.64 | 3.27 $\pm$ 0.62 | 3.35 $\pm$ 0.77 |
A few important patterns emerge from the reported numbers:
- Average performance: VoiceTTA achieves the best average S-SIM at 0.64, the best average S-MOS at 3.27, and the best average WER at 3.12. N-MOS is competitive at 3.35, close to F5-TTS’s 3.36.
- Accented prompts: VoiceTTA reaches the best S-SIM at 0.69 and the best S-MOS at 3.46, while WER is essentially tied with F5-TTS (2.82 vs. 2.81).
- Children’s speech: VoiceTTA gives the best WER at 3.01 and the best S-SIM at 0.63, with the best S-MOS at 3.37.
- Slurred speech: VoiceTTA shows the strongest style recovery, with S-MOS 3.44 and S-SIM 0.58, while keeping WER low at 4.49.
- Chinese sketches: VoiceTTA improves style metrics over F5-TTS, especially S-SIM (0.60 vs. 0.58) and S-MOS (3.25 vs. 3.11), though F5-TTS retains a slightly lower WER (3.11 vs. 3.26).
- Chinese dialects: VoiceTTA lowers WER to 3.13 from F5-TTS’s 3.38 and raises S-SIM to 0.62, while S-MOS also improves to 3.18.
The subjective results mirror the objective metrics. In particular, VoiceTTA’s improved S-SIM is reflected in higher perceived similarity scores, and the paper emphasizes that the method does not degrade naturalness in a meaningful way relative to the F5-TTS baseline.
Ablation and Sensitivity Analysis
The ablation study focuses on the reward terms. It demonstrates a clear trade-off between style fidelity and intelligibility if the rewards are used in isolation. The pure style rewards can produce strong imitation signals but poor WER, while the intelligibility reward alone preserves transcript accuracy but fails to model style.
| Reward configuration | WER $\downarrow$ | S-SIM $\uparrow$ |
|---|---|---|
| $r_{\text{F0-CV}}$ | 7.62 | 0.53 |
| $r_{\text{Energy-CV}}$ | 7.76 | 0.51 |
| $r_{\text{S-SIM}}$ | 6.58 | 0.62 |
| $r_{\text{Intel}}$ | 3.10 | 0.43 |
| $r_{\text{F0-CV}} + r_{\text{Energy-CV}}$ | 7.69 | 0.55 |
| $r_{\text{F0-CV}} + r_{\text{Energy-CV}} + r_{\text{S-SIM}}$ | 7.04 | 0.67 |
| $r_{\text{F0-CV}} + r_{\text{Energy-CV}} + r_{\text{S-SIM}} + r_{\text{Intel}}$ | 3.12 | 0.64 |
The ablation confirms three key points. First, $r_{\text{Intel}}$ alone minimizes WER but performs poorly on S-SIM, so it is insufficient for imitation quality. Second, the three style rewards together raise S-SIM to 0.67, but WER deteriorates sharply to 7.04, which shows that style imitation without intelligibility control is not usable. Third, the full four-term reward restores a balanced solution, yielding both strong style matching and low WER.
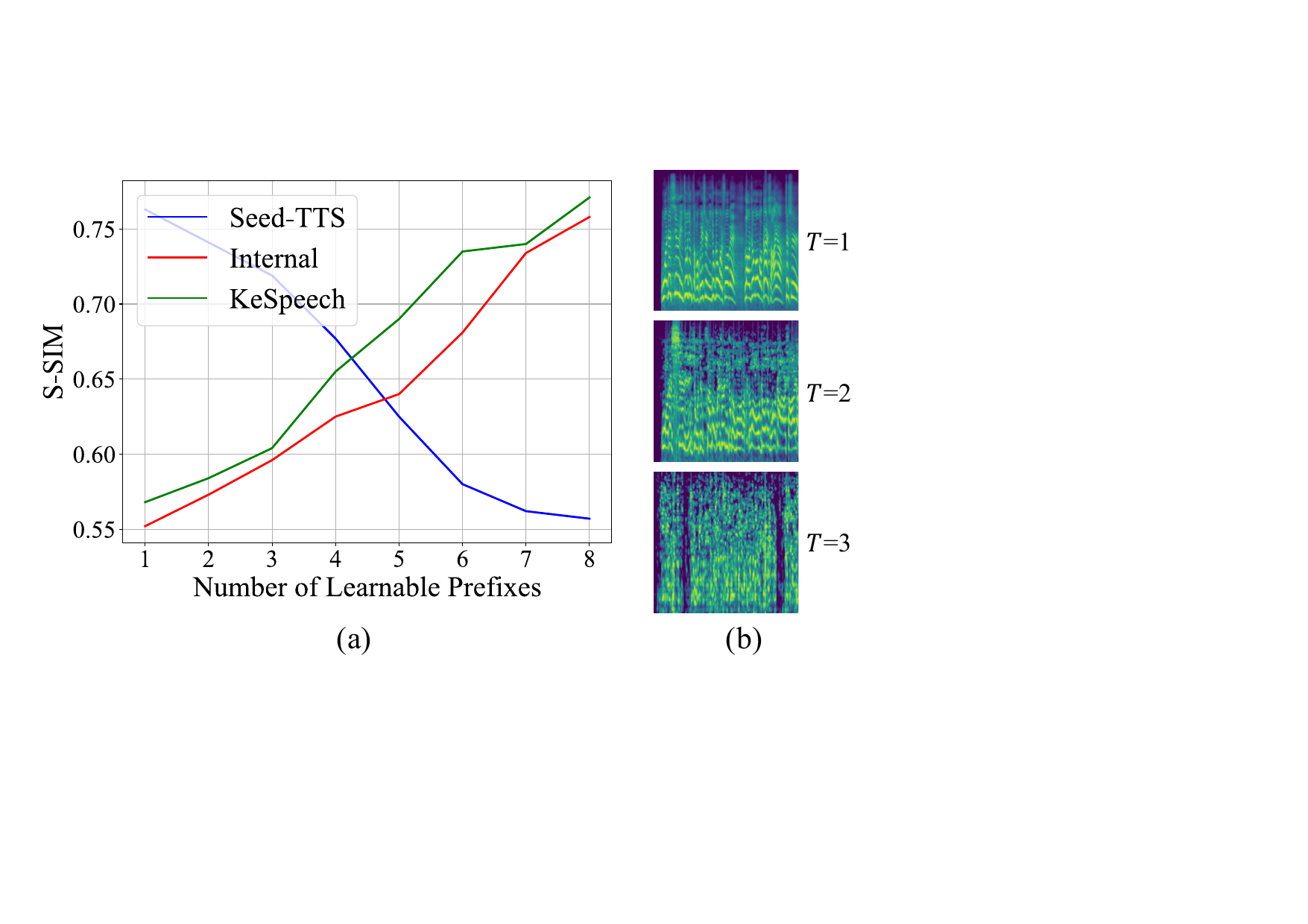
The sensitivity plots further clarify the adaptation behavior. On Seed-TTS test-en, S-SIM peaks when using a single learnable prefix and then declines as more prefixes are added, indicating that too much adaptation can hurt in-domain performance. In contrast, on KeSpeech and the internal uncommon-speech dataset, adding more prefixes improves S-SIM, suggesting that the additional prefix capacity is useful for harder out-of-domain prompts. Based on this trade-off, the paper selects 4 prefixes for the main experiments.
The temperature study shows that large values of $T$ make the generated speech unintelligible. This is why the implementation samples $T$ from a relatively narrow range, $U(0.5, 1.5)$, rather than allowing highly stochastic generation.
Practical Implications and Limitations
The paper’s main practical advantage is that adaptation is lightweight: only a small prompt state needs to be stored per speaker, reported as about 16 KB, and the same adapted prefixes can be reused for repeated synthesis. This makes VoiceTTA attractive for online personalization scenarios where users provide only a short prompt sample.
The trade-off is that the method is not a pure feed-forward inference recipe. It requires multiple candidate generations per GRPO step and runs $G = 50$ adaptation steps before final synthesis, so it necessarily adds test-time optimization overhead compared with direct zero-shot inference. The paper does not provide a dedicated latency table, so the exact runtime cost is not quantified in the text, but the procedure is clearly more expensive than one-shot generation.
The paper’s own sensitivity analysis also identifies two limitations of the adaptation process: overly many prefixes can reduce in-domain performance, and overly large sampling temperatures can destroy intelligibility. These observations motivate the final configuration, but they also indicate that the adaptation hyperparameters must be chosen carefully for each deployment setting.
Conclusion
VoiceTTA shows that reinforcement learning-based test-time adaptation can substantially improve zero-shot TTS voice imitation on uncommon prompts without full fine-tuning. By combining pitch variation, energy variation, speaker similarity, and intelligibility rewards within a GRPO framework, the method learns a compact set of prefixes that steer a flow matching-based TTS model toward the target speaking style. Across accented, children’s, slurred, Chinese sketch, and Chinese dialect prompts, VoiceTTA consistently improves style similarity and achieves the best average objective and subjective style scores while maintaining competitive naturalness and intelligibility.