VoxCPM2 LoRA TTS Adaptation
Closing the Quality Gap in Low-Resource Text-to-Speech: LoRA Fine-Tuning of VoxCPM2 for Khmer and Korean
This paper presents a parameter-efficient LoRA fine-tuning method to adapt a large pretrained TTS model for low-resource Khmer and Korean. A single shared adapter improves Khmer speech quality notably while maintaining Korean performance without the cost of full fine-tuning.
Links
Paper & demos
Code & resources
Abstract
Large pretrained text-to-speech (TTS) models sound almost human for well-resourced languages, but much worse for languages that are rare in their training data. We study this quality gap for Khmer and Korean using VoxCPM2, a 2.4B-parameter, tokenizer-free TTS model that joins a MiniCPM-4 language-model backbone with a flow-matching diffusion decoder. We build one shared, language-tagged corpus of about 26 hours and adapt VoxCPM2 with a single Low-Rank Adaptation (LoRA) adapter, trained on both languages at once and added to both the language model and the decoder. The adapter is zero-initialized, so training starts exactly at the original (zero-shot) model. In native-speaker listening tests, the Khmer Mean Opinion Score (MOS) rises from 3.85 to 4.23 with the best adapter (rank 64), a highly significant gain (paired Wilcoxon test, p<0.001), while training only 0.19 to 3.03 percent of the parameters. The automatic loss and the human ratings, however, disagree on the best rank: validation loss is lowest at rank 128, yet MOS peaks at rank 64. The same adapter brings no gain for Korean, a language the base model already handles well, and at a high rank it even degrades quality. Adaptation therefore helps mainly where the base model is genuinely weak.
Introduction
This paper studies whether parameter-efficient fine-tuning can close the quality gap that large pretrained text-to-speech (TTS) models still show on low-resource languages. The base system is VoxCPM2, a tokenizer-free TTS model with about $2.39 \times 10^9$ parameters that combines a MiniCPM-4 language-model backbone with a flow-matching diffusion decoder. The authors focus on Khmer and Korean because they represent two different regimes: Khmer is genuinely low-resource and poorly covered by the base model, while Korean is already handled comparatively well. This contrast is used to test whether adaptation helps only when the model is weak, or whether a shared adapter improves both languages uniformly.
The central claim is that a single shared LoRA adapter, trained jointly on both languages and inserted into both the language-model and decoder modules, can substantially improve Khmer quality while leaving Korean largely unchanged or even slightly degraded at high rank. The work is framed around a practical deployment question for conversational and talking-head systems: how much quality can be recovered from a frozen foundation TTS model without paying the cost of full fine-tuning?
Problem Setting and Motivation
The paper starts from a familiar observation in modern TTS: large pretrained systems can sound nearly human for well-resourced languages, but they still produce noticeably worse results for languages that were rare in pretraining. The authors emphasize typical failure modes such as mispronunciation, awkward stress and intonation, and residual synthetic quality. Their target is not general multilingual speech synthesis from scratch, but lightweight adaptation of an already strong base model to languages that remain under-served.
Khmer is the main low-resource case. The paper notes that Khmer orthography does not separate words with spaces, making it linguistically and tokenization-wise different from English or Korean. Korean serves as a control language: it is included in the same training setup, but the base VoxCPM2 already performs relatively well on it. This allows the authors to distinguish true adaptation from a universal gain that any language would enjoy.
Instead of full fine-tuning, the method uses Low-Rank Adaptation (LoRA). Only a small low-rank update is trained while the base model remains frozen, avoiding the storage and compute cost of separate multi-billion-parameter checkpoints. The paper’s more specific question is whether one shared adapter can serve multiple languages at once and still close the quality gap where it matters.
Related Technical Context
The related work positions the paper across four lines: classic neural TTS pipelines such as Tacotron 2 and FastSpeech 2, fully end-to-end systems such as VITS, modern generative TTS systems such as VALL-E, and adaptation methods such as AdaSpeech and PEFT methods including LoRA and QLoRA. VoxCPM2 is presented as a newer generation of tokenizer-free TTS, meaning it models continuous acoustic representations instead of discrete codec tokens. That matters because the authors are not adapting a codec-based synthesizer; they are adapting a model whose architecture already couples a language model and a diffusion-based acoustic decoder.
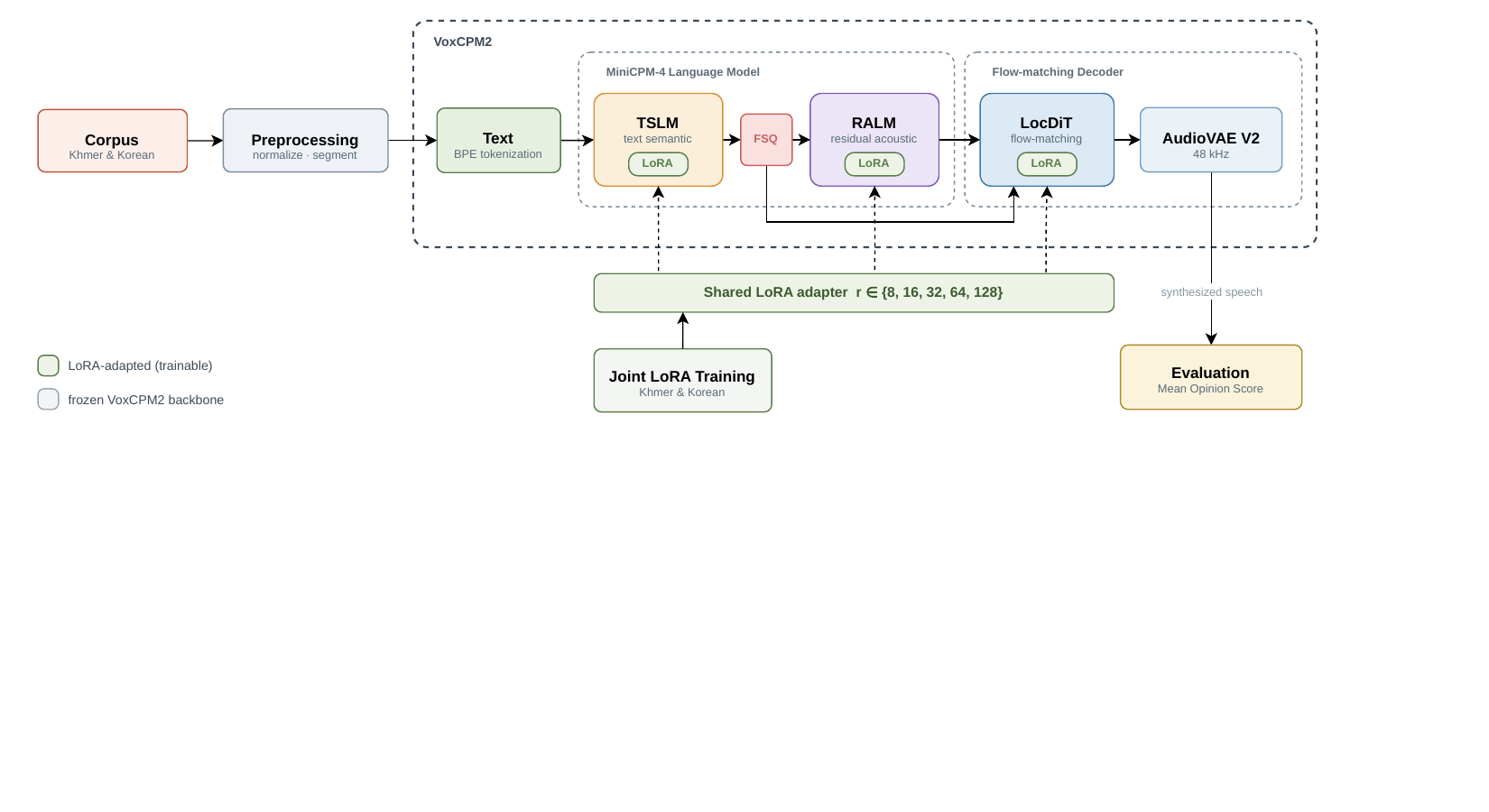
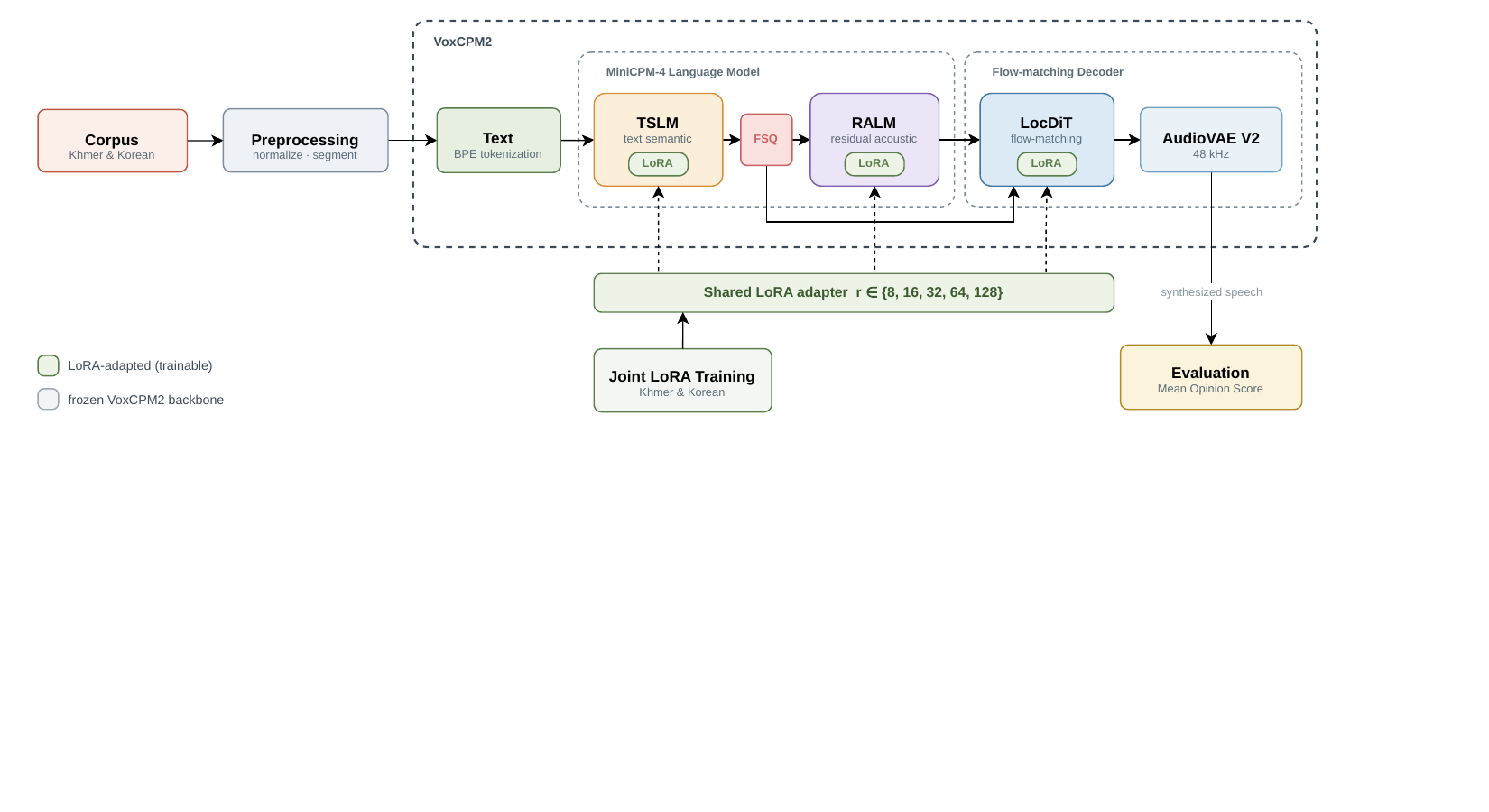
Base Model Architecture
The paper describes VoxCPM2 as having two main parts:
- A MiniCPM-4 language-model backbone with hidden size $2048$, $28$ transformer layers plus $8$ residual layers, $16$ attention heads with $2$ key/value heads, and a vocabulary size of $73{,}440$.
- A flow-matching diffusion transformer decoder (DiT), described as a local DiT followed by an AudioVAE V2 vocoder, which generates continuous acoustic features of dimension $64$ with patch size $4$ and renders audio at $48$ kHz.
The input pipeline normalizes and segments text, then BPE-tokenizes it before feeding it to the model. The model contains a text-semantic stage, a finite scalar quantization stage, and a residual-acoustic stage in the language-model portion. The key architectural distinction highlighted by the paper is that VoxCPM2 predicts continuous features directly, avoiding the quantization artifacts associated with discrete-codec approaches.
Data and Corpus Construction
The authors construct a single shared corpus for Khmer and Korean from public and in-house sources. The corpus includes:
- a Khmer corpus from the Institute of Digital Research and Innovation (IDRI), Cambodia,
- the Korean Single Speaker (KSS) corpus,
- Korean data from Common Voice and FLEURS.
The preparation pipeline has four explicit stages:
- Aggregation: each clip is paired with its transcript and duration is measured.
- Cleaning: clips shorter than $0.5$ s or longer than $20$ s are removed, and audio-text matching is checked.
- Tokenization: each transcript is prefixed with a language tag, either
[km]or[ko], then encoded with the VoxCPM2 tokenizer. Clips with more than $256$ text tokens are dropped, leaving $3{,}717$ Khmer and $15{,}658$ Korean clips before balancing. - Manifest construction: the data are split $90/10$ into train and validation within each language; Khmer training clips are then upsampled until Khmer contributes $40\%$ of the training mix.
The final corpus statistics reported in the paper are:
| Language | Utterances | Hours |
|---|---|---|
| Khmer | 4,000 | 3.96 |
| Korean | 15,769 | 22.21 |
| Total | 19,769 | 26.17 |
The training manifest contains $23{,}487$ clips total, with $9{,}395$ Khmer and $14{,}092$ Korean training clips. The validation set contains $1{,}938$ clips total, with $372$ Khmer and $1{,}566$ Korean validation clips. The authors explicitly keep the validation split at the natural ratio so that validation loss is measured fairly rather than on an artificially rebalanced set.
LoRA Adaptation Method
The adaptation strategy is the core methodological contribution. For a pretrained weight matrix $W_0 \in \mathbb{R}^{d \times k}$, LoRA replaces the full update with a low-rank decomposition:
$$W = W_0 + \Delta W = W_0 + \frac{\alpha}{r} BA,$$
where $A \in \mathbb{R}^{r \times k}$ is initialized with Kaiming-uniform initialization, $B \in \mathbb{R}^{d \times r}$ is zero-initialized, and $r$ is the rank. Because $B$ starts at zero, the update is initially $\Delta W = 0$, so training begins exactly from the original zero-shot model. This zero-initialized design is important: the adapter can be interpreted as learning only the residual correction needed to move away from the base model.
The paper applies LoRA to the query, key, value, and output projections of attention layers in both the language-model backbone and the diffusion decoder. The feed-forward layers and the audio VAE remain frozen. The scaling factor is set to $\alpha = 2r$, and the authors sweep the rank over $r \in \{8,16,32,64,128\}$. Depending on rank, the adapter contains from $0.19\%$ to $3.03\%$ of the base model’s parameters, corresponding to about $4.5$ million to $72.4$ million trainable parameters.
A key novelty is that they train one shared adapter on both languages simultaneously. Language tags make it possible to keep the scripts distinct while sharing the same low-rank matrices. The paper explicitly claims this as a first parameter-efficient adaptation of a foundation TTS model for Khmer.
Training Configuration
All experiments use the AdamW optimizer with $\beta_1 = 0.9$, $\beta_2 = 0.999$, and weight decay $0.01$. The learning rate peaks at $10^{-4}$, with a $200$-step linear warmup followed by cosine decay to zero. The effective batch size is $16$ using micro-batch size $4$ and gradient accumulation $4$. Gradients are clipped at $1.0$, and the training uses bfloat16 mixed precision, while the audio VAE remains in float32.
Each run lasts $10{,}000$ steps and validation is performed every $500$ steps. The experiments run on a single NVIDIA H200 GPU, and each rank takes roughly $2.6$ hours, or about $1.07$ steps per second. These details matter because they show that the improvement is achieved with a relatively small compute budget compared with full fine-tuning of a $2.39$ billion-parameter model.
Evaluation Protocol
The main automatic metric is the validation flow-matching loss ($\texttt{loss\_diff}$) on the held-out split. The authors also track the stop-token loss ($\texttt{loss\_stop}$), but the diffusion objective is the principal optimization target and the one that is compared against perceptual quality. Since the adapter starts at zero, the initial loss matches the zero-shot base model, and the amount of loss reduction indicates how much of the gap the adapter has closed.
For perceptual evaluation, the authors synthesize the same Khmer and Korean sentences at $48$ kHz for the base model and all LoRA ranks. They run native-speaker MOS tests separately for each language. Five native speakers rate $20$ sentences per system on a $5$-point scale along three axes: naturalness, prosody, and pronunciation. The overall MOS is the mean of the three axis-level means:
$$\mathrm{MOS}_s = \frac{1}{3} \sum_a \bar{m}_{s,a},$$
where $\bar{m}_{s,a}$ is the average score for system $s$ on axis $a$. The authors use a paired Wilcoxon signed-rank test against the zero-shot base, bootstrap confidence intervals from $10{,}000$ resamples, and Krippendorff’s $\alpha$ for inter-rater agreement. Importantly, the two languages use different rater panels, so the paper only makes within-language comparisons.
Quantitative Results
The results show a clear rank-dependent pattern: validation loss improves for every LoRA rank, but perceptual quality only improves strongly for Khmer, not Korean.
| System | Trainable % of base | Adapter size | Validation loss |
|---|---|---|---|
| LoRA $r=8$ | 0.19 | 18 MB | 0.7243 |
| LoRA $r=16$ | 0.38 | 35 MB | 0.7334 |
| LoRA $r=32$ | 0.76 | 70 MB | 0.7344 |
| LoRA $r=64$ | 1.51 | 139 MB | 0.7266 |
| LoRA $r=128$ | 3.03 | 277 MB | 0.7094 |
The baseline validation loss is reported as approximately $0.83$, and all LoRA ranks bring it down to the range $0.71$ to $0.73$. The best loss is at rank $128$, but that is not the perceptual optimum.
Khmer MOS
Khmer is where the adapter clearly helps. The zero-shot base achieves overall MOS $3.85 \pm 0.77$. Quality rises with rank up to $64$ and then falls slightly at $128$.
| System | Naturalness | Prosody | Pronunciation | Overall MOS | $p$ vs. base |
|---|---|---|---|---|---|
| Zero-shot base | 4.00 | 3.76 | 3.78 | 3.85 $\pm$ 0.77 | --- |
| LoRA $r=8$ | 3.97 | 3.98 | 3.78 | 3.91 $\pm$ 0.65 | 0.19 |
| LoRA $r=16$ | 4.07 | 3.93 | 3.82 | 3.94 $\pm$ 0.66 | 0.07 |
| LoRA $r=32$ | 4.12 | 4.01 | 3.97 | 4.03 $\pm$ 0.67 | 0.001 |
| LoRA $r=64$ | 4.25 | 4.36 | 4.07 | 4.23 $\pm$ 0.58 | < 0.001 |
| LoRA $r=128$ | 4.19 | 4.15 | 3.91 | 4.08 $\pm$ 0.63 | 0.001 |
The best Khmer result is rank $64$, with an overall MOS increase from $3.85$ to $4.23$, a gain of $0.38$ points that is highly significant ($p < 0.001$). Ranks $32$ and $128$ are also significant ($p = 0.001$), while ranks $8$ and $16$ are not. The largest axis-level improvement is in prosody, which rises from $3.76$ to $4.36$ at rank $64$, suggesting that the base model’s Khmer weakness is especially strong in rhythm and intonation. This is one of the paper’s main empirical findings: the adapter corrects not only pronunciation but also the temporal and prosodic properties that make speech sound natural.
Korean MOS
Korean behaves very differently. The base already scores $3.65 \pm 0.76$ overall, and none of the LoRA ranks gives a statistically significant improvement. The best mean is rank $32$ at $3.76$, but the test result is not significant ($p = 0.49$). Rank $64$ is actually worse than the base, with a significant decrease.
| System | Naturalness | Prosody | Pronunciation | Overall MOS | $p$ vs. base |
|---|---|---|---|---|---|
| Zero-shot base | 3.67 | 3.64 | 3.64 | 3.65 $\pm$ 0.76 | --- |
| LoRA $r=8$ | 3.59 | 3.64 | 3.95 | 3.73 $\pm$ 0.72 | 0.60 |
| LoRA $r=16$ | 3.65 | 3.53 | 3.94 | 3.71 $\pm$ 0.79 | 0.80 |
| LoRA $r=32$ | 3.61 | 3.63 | 4.03 | 3.76 $\pm$ 0.75 | 0.49 |
| LoRA $r=64$ | 3.23 | 3.49 | 3.72 | 3.48 $\pm$ 0.81 | 0.02 |
| LoRA $r=128$ | 3.27 | 3.45 | 3.91 | 3.54 $\pm$ 0.80 | 0.10 |
The only significant Korean change is negative: rank $64$ drops overall MOS to $3.48$ and significantly degrades naturalness. Pronunciation can improve locally, reaching $4.03$ at rank $32$, but this is not enough to move the overall score significantly. The authors interpret this as evidence that the base model already covers Korean reasonably well, leaving little room for improvement and making larger adapters more likely to overfit the small training set.
Interpretation of the Rank Sweep
The rank sweep is one of the paper’s central ablations. The authors compare ranks $8$, $16$, $32$, $64$, and $128$ and find a consistent but nuanced story:
- Loss keeps improving with more capacity. The best validation loss is at rank $128$.
- Perceptual quality does not track loss monotonically. Khmer MOS peaks at rank $64$, not at the lowest-loss rank.
- Small adapters already recover much of the benefit. Rank $8$ captures a noticeable share of the Khmer improvement while using only $0.19\%$ of the base parameters.
- High capacity can hurt when the language is already well covered. Korean is the clearest example: rank $64$ reduces quality.
This leads to a key conclusion: validation loss is an imperfect proxy for perceived speech quality. The authors argue that adapter rank should be selected with listening tests, not only with automatic loss curves. They also suggest that the useful adapter size depends on how far the target language is from what the base model already knows.
Qualitative Findings
The paper includes side-by-side synthesized speech for the base model and all LoRA ranks. The authors report that the adapted models pronounce Khmer subscript consonant clusters more reliably and handle Korean sound boundaries more cleanly, with steadier rhythm overall. These observations are said to match the lower validation loss and the MOS results, especially the large prosody gain in Khmer. The paper does not present a separate objective intelligibility metric; the qualitative claims are grounded in listening and in the released audio artifacts.
Contributions and Claimed Novelty
The paper makes four explicit contributions:
- One shared adapter for two languages and two modules. A single LoRA adapter is trained jointly on Khmer and Korean and inserted into both the language model and decoder, avoiding separate per-language checkpoints.
- Adaptation helps only where the base model is weak. Khmer improves strongly and significantly, while Korean does not improve overall.
- Training loss and MOS disagree on the best rank. The best validation loss occurs at rank $128$, but the best MOS occurs at rank $64$.
- Adaptation as a probe of model knowledge. Because the adapter starts from the exact zero-shot model, its effect reveals how much the base model already knows about each language.
The authors also explicitly claim that this is the first parameter-efficient adaptation of a foundation TTS model for Khmer.
Limitations
The paper is unusually direct about its limitations. Several are important for interpreting the results:
- No full fine-tuning upper bound. The authors do not compare against a fully fine-tuned VoxCPM2 model, so the maximum achievable gain remains unknown.
- No direct test of sharing versus separate adapters. They do not isolate whether one shared adapter is better than separate per-language adapters at the same parameter budget.
- Low inter-rater agreement. Krippendorff’s $\alpha$ is $0.31$ for Khmer and $0.26$ for Korean, making the listening results noisy, especially for Korean.
- Small evaluation panels. Each language uses only five raters and twenty sentences per system.
- Cross-language comparisons are not controlled. The two languages use different rater panels, so only within-language comparisons are valid.
- Small and partly upsampled corpus. The training corpus is about $26$ hours, and Khmer gains partly come from upsampling rather than from more unique data.
- Confounded language/data differences. Khmer and Korean differ not only in how well VoxCPM2 pretraining covers them, but also in the source and quality of the fine-tuning data. Khmer uses a private in-house corpus, while Korean uses public corpora such as KSS and Common Voice/FLEURS, so the exact source of the gap is not fully isolated.
These limitations mean that the strongest claims are modest but well supported: the adapter clearly helps Khmer in this setup, does not help Korean overall, and rank selection should not rely on validation loss alone.
Takeaway
The paper shows that a small, zero-initialized LoRA adapter can substantially improve a strong pretrained TTS model on a genuinely low-resource language without retraining the full network. For Khmer, the best rank $64$ adapter raises MOS from $3.85$ to $4.23$ with only a tiny fraction of trainable parameters. For Korean, which the base model already handles well, the same strategy provides no overall gain and can even degrade quality at higher rank. The main technical lesson is that adaptation capacity should match the gap between the base model and the target language, and that perceptual evaluation is necessary because lower loss does not always mean better speech.