Sculpting NeRF Geometry
Sculpting NeRF Geometry: Human-Preference Fine-Tuning of a 3D-Aware Face GAN

This paper fine-tunes a pretrained 3D-aware face GAN's geometry using a reward model trained on human preferences directly from the radiance field's density values. It uniquely improves 3D facial geometry without relying on text prompts, mesh priors, or explicit surface supervision, while preserving 2D appearance.
Demos
These demos show improvements in 3D face geometry generated by the EG3D model after fine-tuning with a human-preference reward model. The side-by-side comparison reveals fewer surface distortions and more plausible shapes in the fine-tuned meshes, while keeping the original RGB rendering quality and identity. Watch for enhancements in mesh realism and consistency.

Links
Paper & demos
Code & resources
Abstract
Reinforcement learning from human feedback (RLHF) for 3D generation is now established across a number of works, but most existing pipelines optimise explicit surface representations, often by converting radiance fields into meshes and training heavily on surface-supervised data. We instead fine-tune a pretrained 3D-aware generative model directly from a learned reward over radiance-field density ($σ$) values, with no externally supplied mesh or shape prior. The reward model requires no pretraining, trains easily on a small set of preference samples, and yields robust improvement in 3D geometry. Working on an unconditional 3D-aware face GAN (EG3D), our reward reads the continuous 3D density field of the neural radiance field (NeRF) directly and supplies a geometry-only learning signal, requiring neither text conditioning, mesh extraction, nor multi-view rendering. A density-consistency constraint keeps the 2D appearance qualitatively similar while the geometry is reshaped, at a measurable but bounded distributional cost (FID-50k rises from 4.09 to 6.66): the fine-tuned generator, trained from the preferences of a single annotator as a proof of concept, produces face geometries preferred by users in 74.4% of pairwise comparisons.
Introduction and problem setting
This paper studies whether human preferences can directly fine-tune the geometry of a pretrained 3D-aware face generator, without relying on text prompts, mesh priors, or explicit surface-supervised data. The target model is EG3D, an unconditional 3D-aware face GAN trained on FFHQ-style face images. The motivating observation is that the model can produce visually plausible 2D renders while still recovering implausible 3D structure: the same latent code can yield a realistic image but a mesh with grooves, bumps, or discontinuities on the nose and sides of the face.

The core idea is to learn a reward model over the generator’s implicit density field $\sigma$ and use that reward to improve 3D geometry during GAN fine-tuning. Unlike much of the recent 3D RLHF literature, which evaluates rendered multi-view images or mesh tokens and often depends on text conditioning, this method operates directly on the NeRF density volume and uses a prompt-free pairwise preference signal. The paper’s claim is not just that this is possible, but that it is practically useful: the resulting reward model is cheap to train, works with a small preference set, and improves perceived face geometry in user studies, though at a measurable cost in 2D image fidelity.

The paper positions itself relative to three strands of prior work: (1) 3D-aware generators from 2D image collections, especially EG3D-style triplane radiance-field models; (2) RLHF-style preference optimization for generative models; and (3) no-reference 3D quality assessment. Its novelty is the combination of all three in an unconditional setting where the reward is applied to the density volume itself. The authors emphasize that this avoids the prompt-conditioning failure modes of text-to-3D preference tuning and avoids the discretization and reconstruction issues of mesh-based post-processing.
- Input to the reward: a cropped $ \sigma_{XYZ}$ slab extracted from EG3D’s density volume.
- Supervision: pairwise human rankings from a small preference dataset.
- Optimization: a modified GAN-loop update that combines the original discriminator loss, the learned reward, and a consistency term on the density field.
- Main empirical result: users prefer the tuned geometries over the original EG3D outputs in $74.4\%$ of pairwise comparisons.
Method
Representing 3D shape from a NeRF
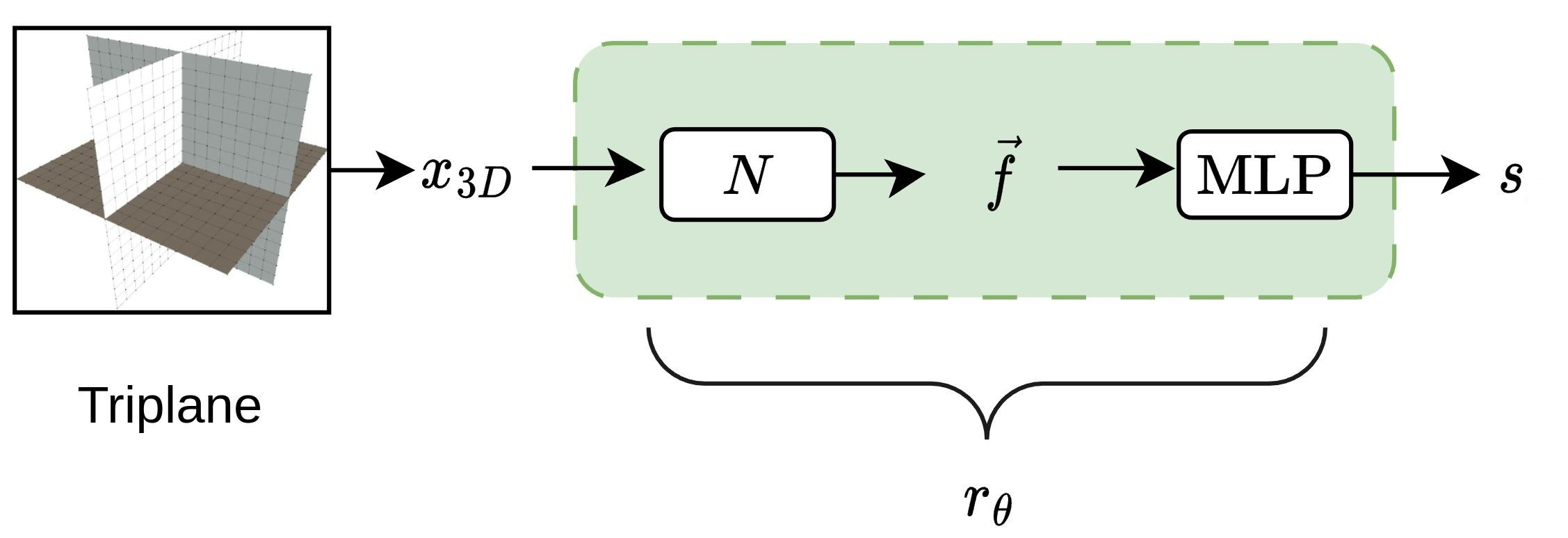
The generator is modeled as a NeRF-like field $$ F_{\Theta} : (x,y,z,\theta,\Phi) \rightarrow (R,G,B,\sigma), $$ where $(R,G,B)$ are view-dependent colors and $\sigma$ is the density. The paper makes a key design choice: geometry is learned from density, not from RGB. Since density carries the shape signal while color changes with viewpoint, the reward model is trained on shape-only features derived from $\sigma$ under a canonical view.
The authors compare three differentiable 3D representations extracted from the canonical-view field: a depth map, a point cloud, and the full sigma field. Depth maps are computed from the NeRF transmittance integral, $$ D(\mathbf{r}) = \int_{t_n}^{t_f} T(t)\,\sigma(\mathbf{r}(t))\,t\,dt, \qquad T(t) = \exp\!\left(-\int_0^t \sigma(\mathbf{r}(s))\,ds\right), $$ and point clouds are obtained by converting each depth pixel to a 3D coordinate along its ray. The best-performing representation is the full density field $\sigma_{XYZ}$, which is interpreted by a 3D U-Net-style backbone.
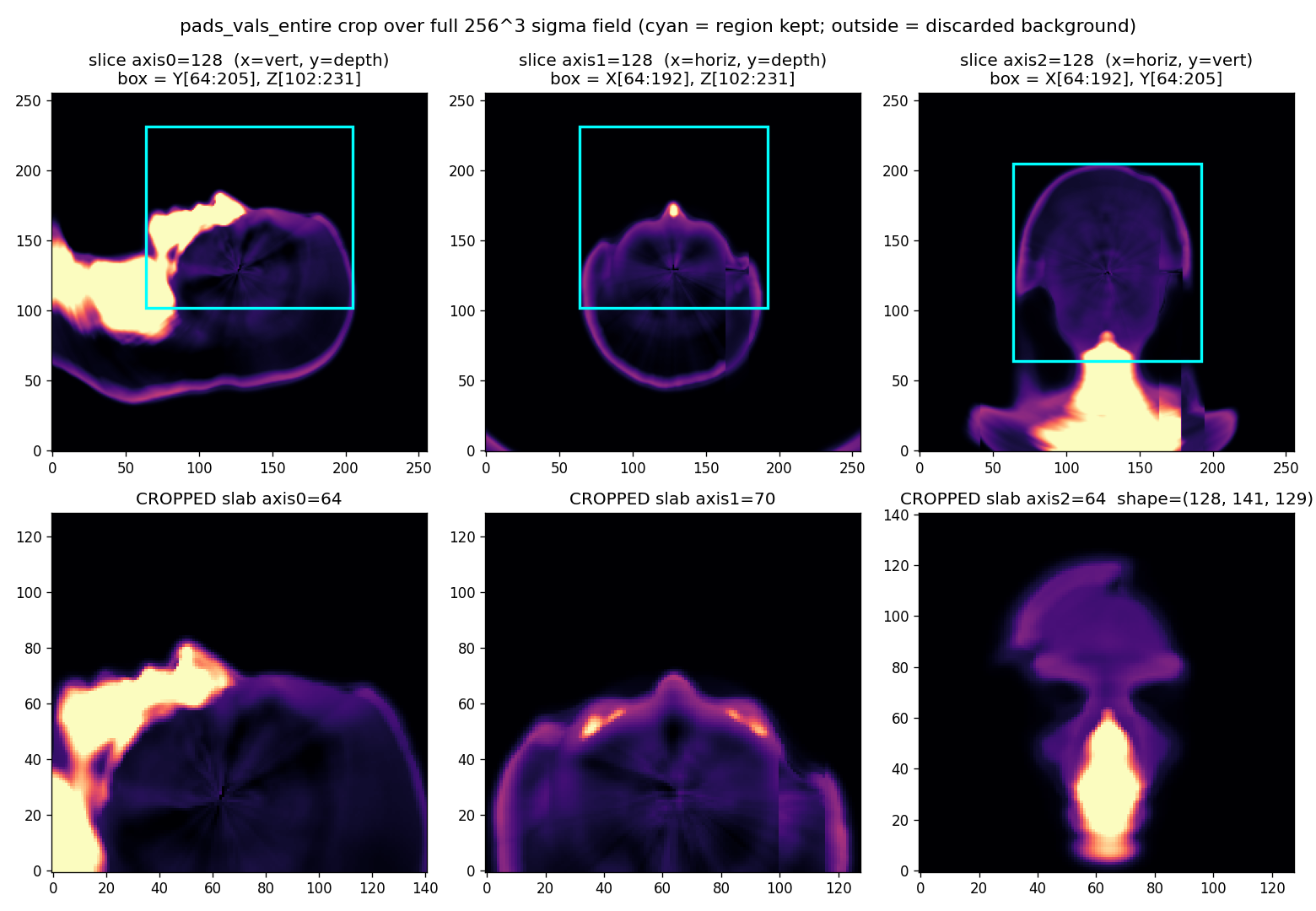
normalise_sigma_self.For the reward model, the full $256^3$ density cube is not used. Instead, the paper crops a frontal face slab inherited from the EG3D pipeline: $X[64:192]$, $Y[64:205]$, $Z[102:231]$, yielding a tensor of shape $128 \times 141 \times 129$. Each cropped slab is then min-max normalized to $[0,100]$. The motivation is practical: finer volumetric feedback helps geometry, but the full cube is too memory-intensive for the available GPU budget.
Preference data
Preference labels are collected by sampling latent codes from the pretrained EG3D generator, visualizing the resulting geometries with marching cubes, and asking a human annotator to rank the samples. The original data collection used batches of between two and six examples. For training, the paper reduces each ranked batch to a pair consisting of the highest-ranked example $x_w$ and the lowest-ranked example $x_l$, producing $4{,}346$ preference pairs in total.
To prevent the reward model from learning that low-quality features inside the winner are themselves good, each batch is augmented with a high-quality anchor sample $x_{HQ}$ drawn from the center of the latent space. The final training order becomes $x_{HQ} \succ x_w \succ x_l$. The full set of $4{,}346$ ranking batches is split $70\% / 15\% / 15\%$ into train/validation/test partitions, corresponding to $3{,}042 / 652 / 652$ batches.
Reward-model architecture and loss
The reward model is modular: a domain-specific encoder $N$ converts a 3D representation into a global feature vector, and an MLP maps that vector to a scalar reward. The paper sweeps several backbones. For depth maps it evaluates ResNet-50, VGGFace, and VGG-4096. For point clouds it evaluates PointNet, PointNet++, and CurveNet. For sigma fields it evaluates 3D U-Net variants, with a squeeze-and-excitation residual 3D U-Net performing best and used in the final method.
Training uses the pairwise preference loss adapted from InstructGPT-style reward modeling, but without prompt conditioning: $$ \mathcal{L}_w = -\frac{1}{\binom{K}{2}} \mathbb{E}_{(x_w,x_l) \sim D}\left[\log \sigma\big(r_\theta(x_w)-r_\theta(x_l)\big)\right], $$ where $\sigma(\cdot)$ denotes the logistic sigmoid. For the $\sigma_{XYZ}$ reward model, the authors also add an auxiliary reconstruction loss on the 3D U-Net output: the network reconstructs the input slab and an $L^1$ penalty with weight $10^{-2}$ is applied. This auxiliary term stabilizes volumetric learning, while the pairwise preference objective remains the primary supervision signal.
Optimization uses Adam with learning rate $10^{-5}$ and weight decay $10^{-4}$. Batch sizes differ by representation: $8$ for depth maps, $2$ for point clouds, and $1$ for $\sigma_{XYZ}$. Reward models train for at most $10$ epochs with early stopping if validation loss fails to improve for three epochs. The paper reports that both reward training and fine-tuning take roughly $5$--$10$ hours on a single RTX 4090 depending on the 3D representation.
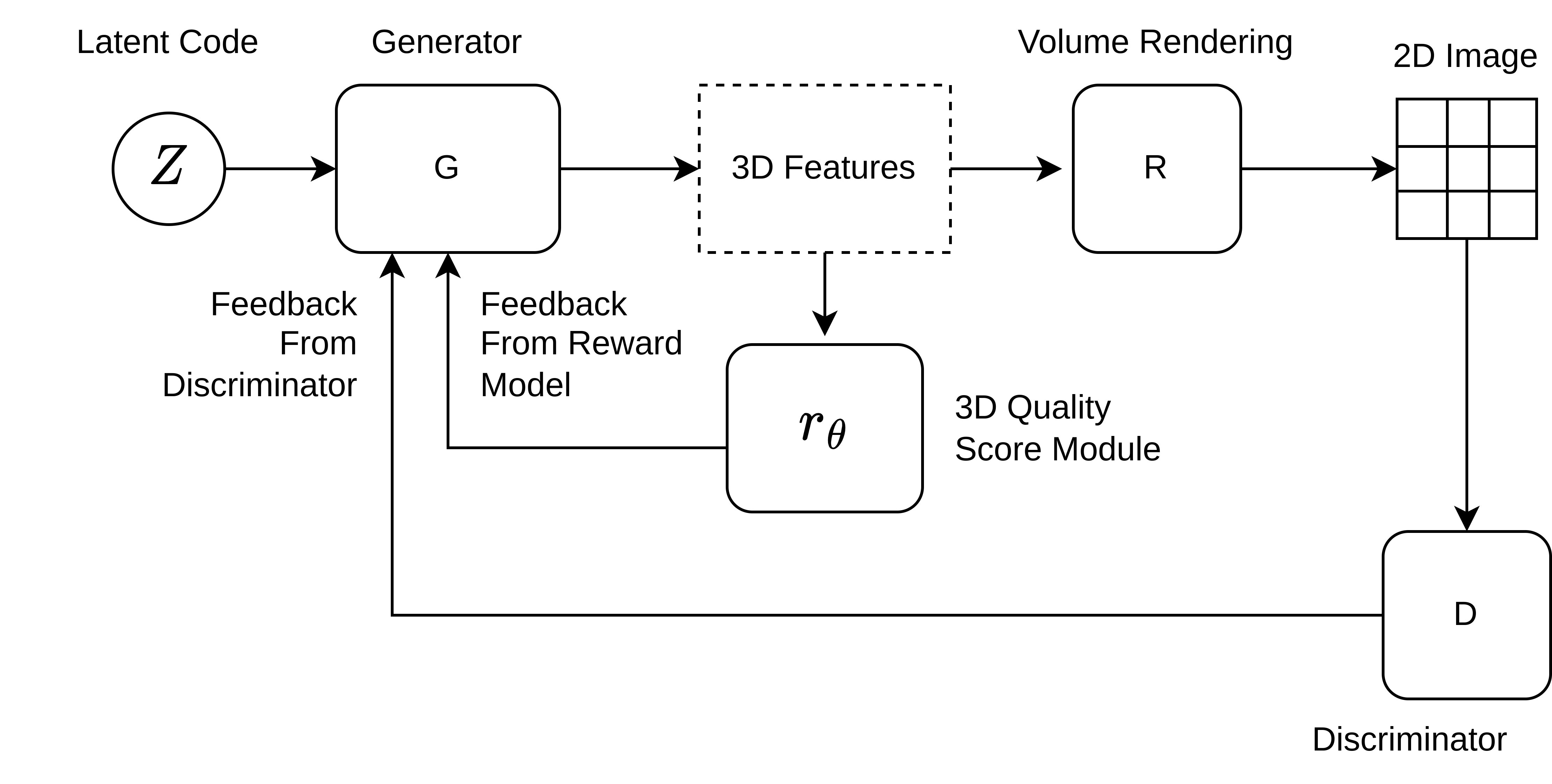
Fine-tuning EG3D geometry
Fine-tuning keeps the original GAN training structure rather than replacing it with PPO or score-distillation updates. The discriminator loss remains unchanged: $$ \mathcal{L}_D = -\frac{1}{2}\mathbb{E}_{x \sim p_s}\log D(x) - \frac{1}{2}\mathbb{E}_{z \sim p_z}\log\big(1-D(G(z))\big) + \gamma_{R_1} R_1. $$ The generator loss becomes $$ \mathcal{L}_G = -\frac{1}{2}\mathbb{E}_{z \sim p_z}\log D(G(z)) + \lambda_r \mathcal{L}_r + \lambda_c \mathcal{L}_c, $$ where $\mathcal{L}_r$ is the reward term and $\mathcal{L}_c$ is a density-consistency term.
The reward term is formed from the learned scalar score, clamped to the interval $[-10,10]$ for stability and then negated so that minimizing the generator loss maximizes reward. The clamp prevents runaway updates but also means high-scoring samples stop receiving reward gradient once they saturate. The consistency term is an $L^1$ distance between the new and old generator densities sampled on a $64^3$ grid: $$ \mathcal{L}_c = \mathbb{E}_{z \sim p_z} L^1\big[\sigma^{64} \circ G_{\text{new}}^z,\; \sigma^{64} \circ G_{\text{old}}^z\big]. $$
The main fine-tuning setting uses $\lambda_r = 10$ and $\lambda_c = 10^{-2}$. The batch size is reduced from $32$ to $16$, the discriminator R1 regularization coefficient is increased from $1$ to $20$, and the model is fine-tuned for $20$ kimg, i.e. roughly $20{,}000$ images. The paper also reports a matched control run with $\lambda_r = 0$ to isolate the effect of the reward signal.
Experiments and results
Reward-model selection and held-out accuracy
The first key result is that the $\sigma_{XYZ}$ representation is the best reward input. On the hard within-distribution test pairs, where the high-quality anchor is removed and only the regular-vs-regular comparisons remain, the sigma-field reward reaches $0.91$ accuracy. The best depth-map model, using three views, reaches $0.74$, while single-view depth maps and all point-cloud backbones hover near chance. Including the easy anchor pairs raises apparent accuracy, but the ranking remains the same.
| Representation | Backbone | All pairs | Regular only |
|---|---|---|---|
| Sigma field | ResNet-SE-3D-UNet ($256^3$ slab) | 0.97 | 0.91 |
| Depth map | ResNet-50 (single canonical view) | 0.83 | 0.50 |
| Depth map | ResNet-50 (triple view, $\pm 60^\circ$ yaw) | 0.91 | 0.74 |
| Point cloud | PointNet ($16{,}384 \rightarrow 2{,}048$ pts) | 0.83 | 0.50 |
| Point cloud | PointNet++ ($16{,}384 \rightarrow 2{,}048$ pts) | 0.50 | 0.50 |
| Point cloud | CurveNet ($16{,}384 \rightarrow 2{,}048$ pts) | 0.51 | 0.51 |
The paper interprets this as evidence that the density volume contains a usable geometry signal beyond what can be recovered from a single depth map or point cloud. The best 3D reward does not merely fit the training pairs; it also aligns with downstream fine-tuning behavior, where only the sigma-field reward consistently improves geometry without introducing the distortions seen with weaker backbones.
Fine-tuning EG3D
Fine-tuning is evaluated by comparing the pretrained generator, a no-reward control, and the reward-tuned model. The tuned model improves 3D geometry, but the improvement comes with a modest increase in FID-50k, showing the expected quality-versus-distribution-fidelity trade-off.
| Configuration | FID-50k |
|---|---|
| Pretrained EG3D (untuned) | 4.092 |
| $\lambda_r = 0$ (no-reward control) | 5.342 |
| $\lambda_r = 10$ (reward fine-tuning) | 6.657 |
Relative to the pretrained model, the matched control already increases FID by about $1.25$, and adding the reward increases it by a further $1.32$. However, only the reward-tuned model changes geometry in the intended direction. The control run shows essentially no observable 3D change, while the reward-tuned model smooths side-face artifacts, improves the nose region, and keeps the 2D appearance qualitatively similar.

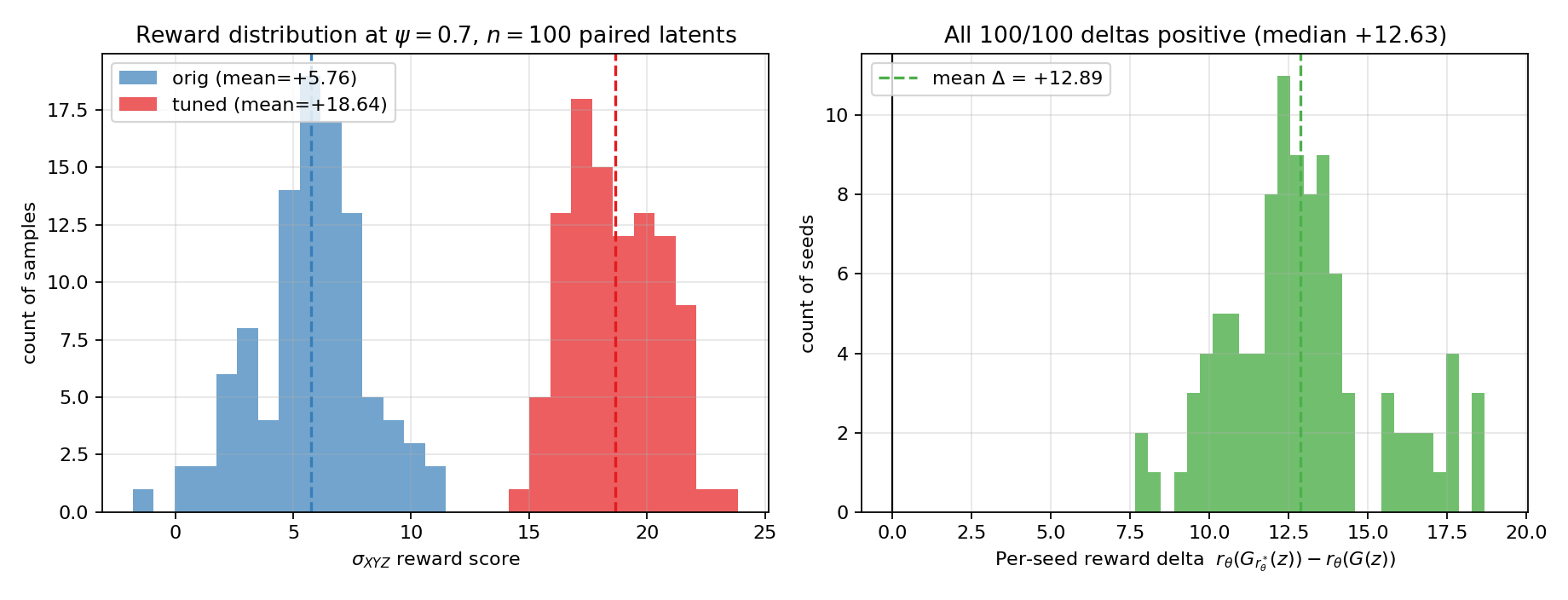
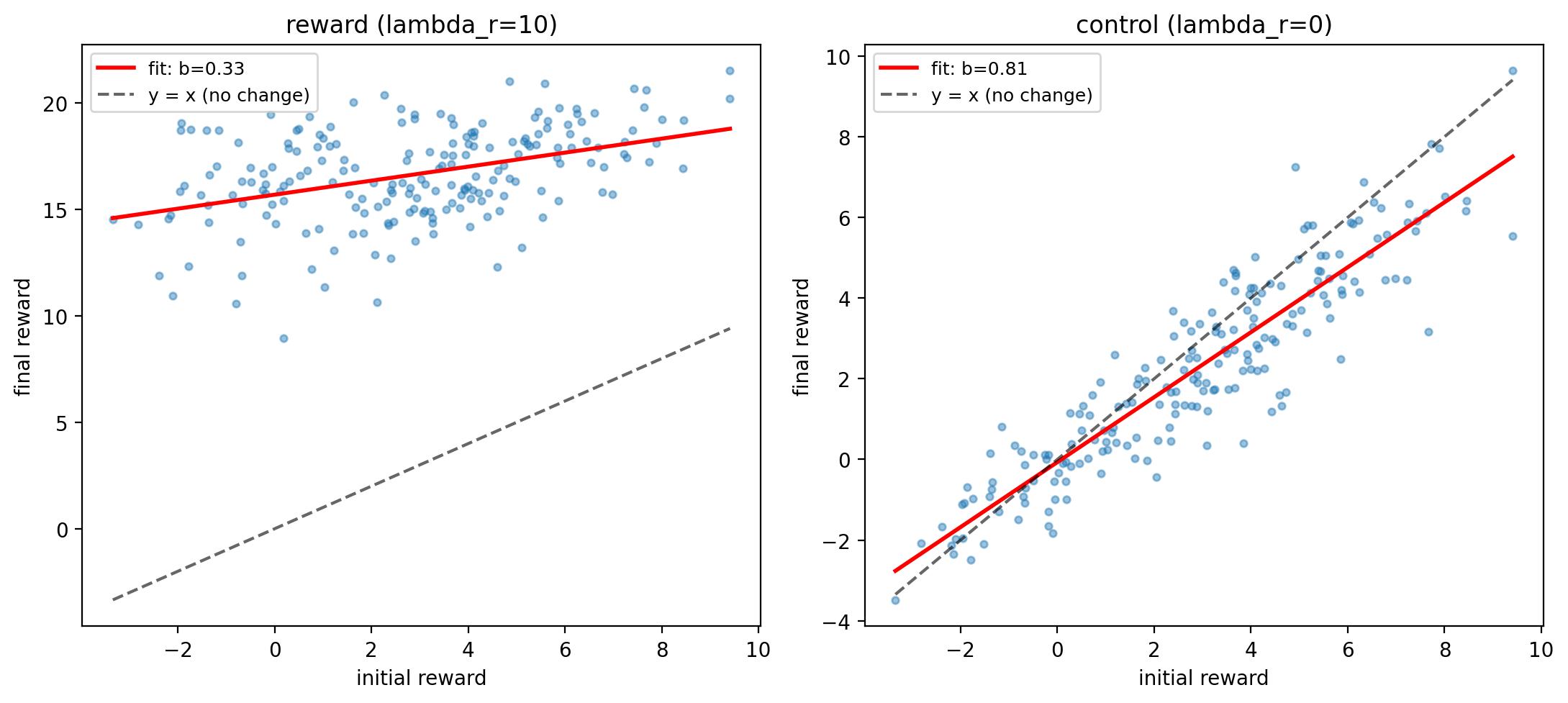
On $100$ fixed latent codes at truncation $\psi = 0.7$, the reward delta after fine-tuning is positive for every seed, with mean $+12.89$. On a larger set of $200$ codes, the final-vs-initial regression slope is $b = 0.33$ with a $95\%$ confidence interval of $[0.23, 0.43]$, strongly below $1$, which the authors interpret as compression toward a common high-quality level rather than mere reward amplification for already-good samples. The matched no-reward control remains close to the identity line with slope $0.81$.
Human preference evaluation
The tuned generator is evaluated with an external user study. Forty latent codes are rendered before and after fine-tuning, and $17$ respondents choose which geometry they prefer for each pair. Out of $680$ total judgments, $506$ favor the tuned output, $141$ favor the original, and the remainder are ties or no preference. The reported proportion in favor of the tuned model is $0.744$, with Cohen’s $h = 1.135$, which the paper describes as a large effect size.
| Outcome | Proportion |
|---|---|
| $x_{G_{r_\theta}} \succ x_G$ | 0.744 |
| $x_G \succ x_{G_{r_\theta}}$ | 0.207 |
| No preference | 0.049 |
The qualitative conclusion matches the quantitative metrics: users see the tuned models as better face geometries, even though the 2D image quality shifts slightly. The paper treats this as the main empirical validation of the approach.
What changes in the geometry?
The paper’s post-hoc analyses show that the reward primarily changes the parts of the face where humans notice shape quality most easily. In the sigma-field model, the reward is dominated by the nose, mouth, cheeks, jawline, brow, chin, and forehead. Eye regions contribute little, and only a small amount of reward mass leaks into the “front-of-camera” diagnostic band. This suggests the learned model is not simply detecting spurious density everywhere, but is instead sensitive to semantically meaningful facial structure.
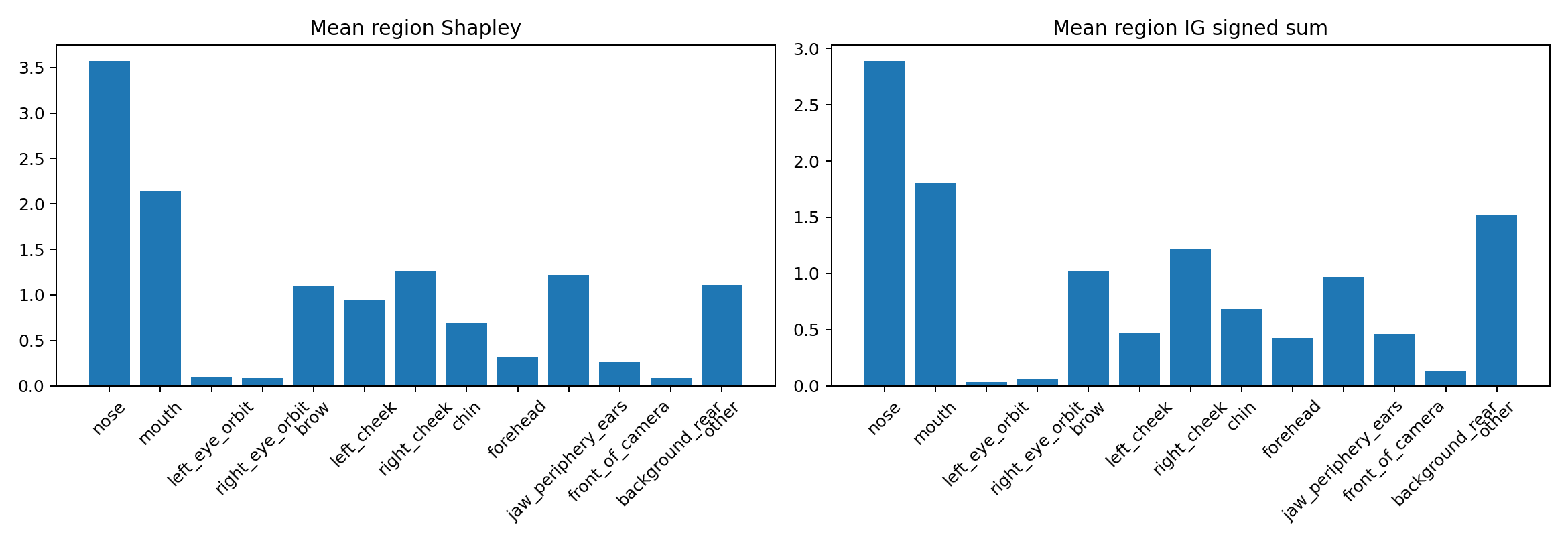
Quantitatively, the regional attributions are led by the nose, with mean Shapley value $3.57$ and top-ranked region in $82/100$ seeds. Mouth follows at $2.14$, then right cheek, left cheek, jaw periphery and ears, brow, chin, and forehead. Eye orbits have very small contributions. The paper reports that anatomically named regions account for $88.6\%$ of the mean reward delta, which supports the claim that the learned reward is genuinely face-geometry aware rather than merely detecting global density statistics.
The weaker depth-map and point-cloud rewards behave differently. Their SHAP attributions tend to emphasize side-of-face or edge regions rather than the semantically important center of the face. In the point-cloud case, the points that drive the global features often lie around the outer boundary of the cloud, and the highest-ranked geometries still include obvious defects such as over-sharp noses and irregular surfaces. This explains why those reward variants are much less effective during fine-tuning.
Reward trajectories and truncation analysis
The authors also test whether the tuned generator is simply collapsing toward the truncation mean face. Their answer is no. For $100$ shared latent codes, the tuned sample is closer to the original than to the truncation mean in $98\%$ of cases for the depth map representation and $93\%$ for $\sigma_{XYZ}$. The move induced by fine-tuning is mostly orthogonal to the truncation axis, with projection coefficients $0.22$ for depth and $0.33$ for sigma, and residual fractions around $0.9$.
The reward is monotonic in truncation for the pretrained EG3D generator, which shows that the reward model does in fact prefer lower-truncation, higher-quality samples. However, the tuned generator at $\psi = 0.7$ achieves a reward score of $18.64$, matching the truncation-$0$ mean face score, while still remaining geometrically closer to the original sample than to the mean face. In other words, fine-tuning finds a high-reward direction that is not just mean regression.
| EG3D-orig $\psi$ | Mean reward | Median | Std |
|---|---|---|---|
| $0.00$ (mean face) | +17.93 | +17.93 | ~0 |
| $0.25$ (HQ regime) | +14.70 | +14.93 | 1.50 |
| $0.50$ | +8.70 | +8.56 | 2.36 |
| $0.70$ (canonical) | +5.76 | +5.80 | 2.32 |
| $1.00$ (full diversity) | +2.78 | +2.89 | 2.40 |
| EG3D-tuned, $\psi = 0.7$ | +18.64 | +18.51 | 1.90 |
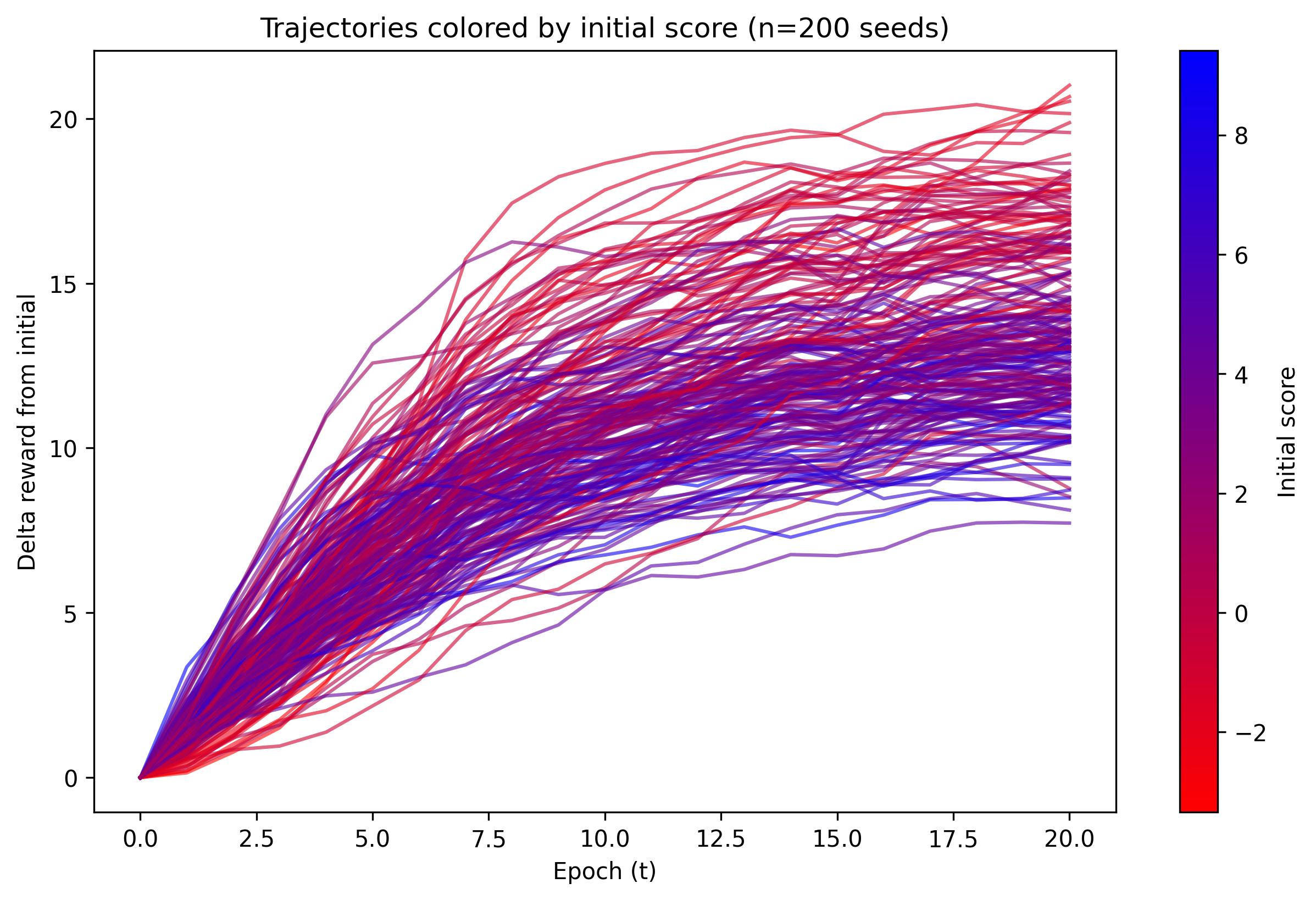
The reward trajectories make the mechanism especially clear: under the reward loss, nearly every seed climbs upward, while the control run stays flat. This is used to argue that the geometry changes are not an artifact of continued GAN optimization alone.
Intermediate representations and interpretability
The learned sigma reward embedding is analyzed to see whether it organizes samples by geometry quality more cleanly than the raw density feature. The paper reports that the compressed feature vector separates regimes more strongly than the raw 3D U-Net activations, and that original versus tuned samples become increasingly separable in the learned embedding. A UMAP projection shows this visually.
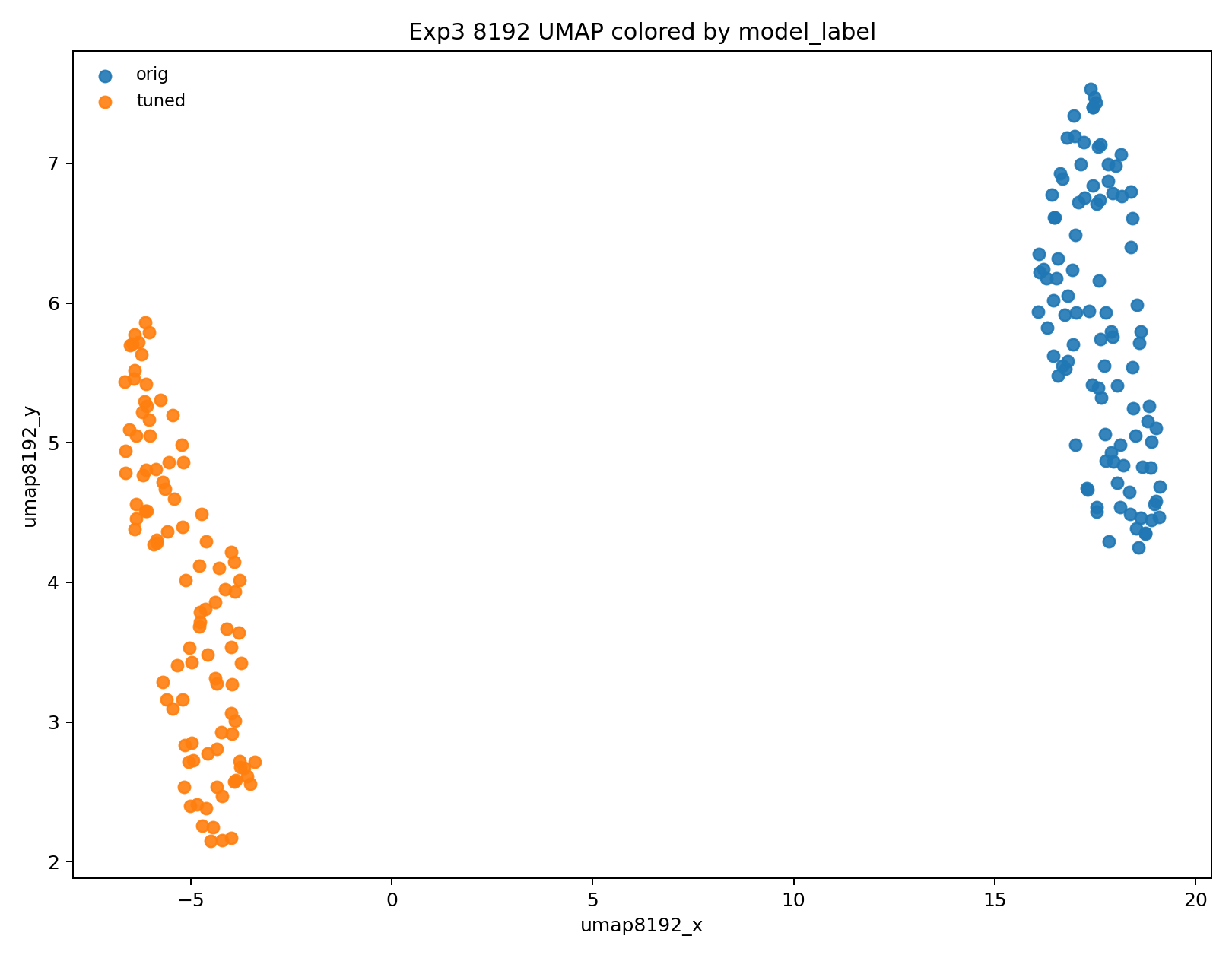
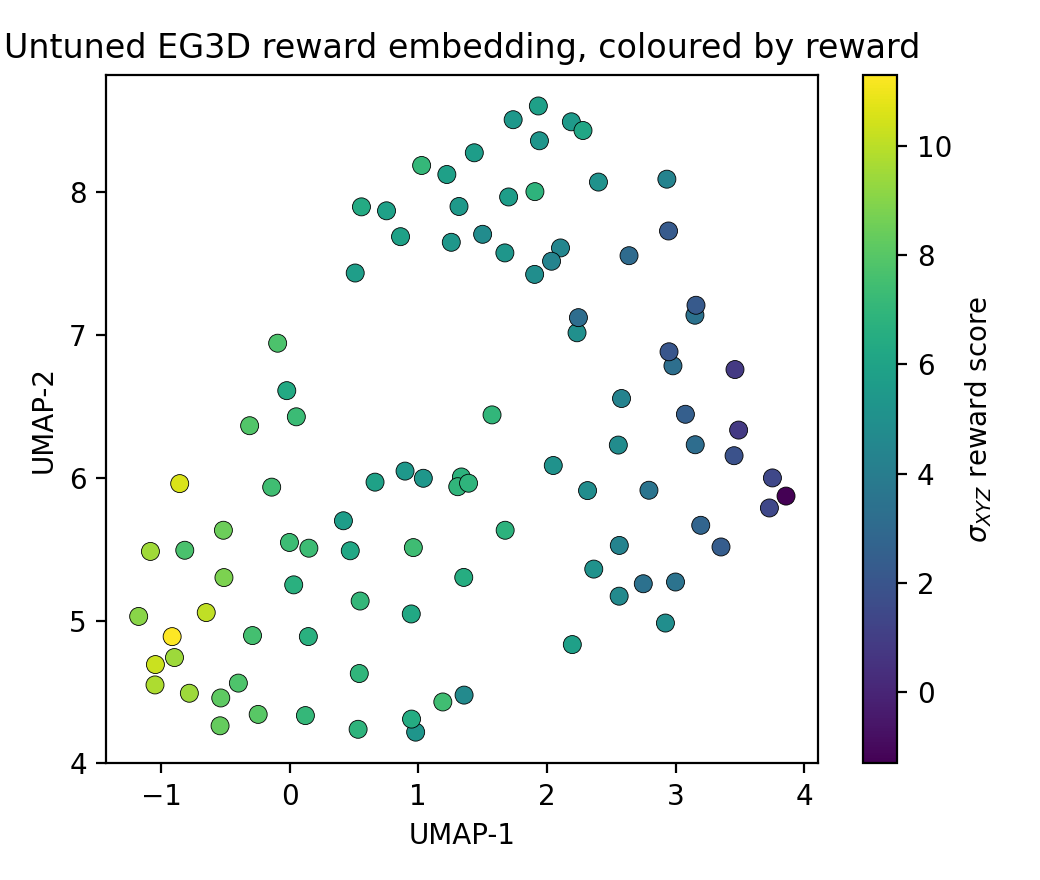
The broader interpretability story is that the sigma reward seems to learn a meaningful latent notion of face-quality improvement, not a trivial binary detector. On the original generator, reward varies smoothly across the embedding; on paired before/after samples, the tuned set forms a distinct cluster. This is one reason the reward can be used as a training signal rather than just as a post-hoc evaluator.
Generalization and failure modes
Comparison with image-based rewards
To probe whether the learned geometry signal is redundant with existing image-based 3D reward models, the paper scores the same $100$ identity-paired seeds with two external rewards based on rendered views. One is Reward3D from DreamReward, which consumes multi-view images and a fixed prompt. The other is MVReward, which consumes a canonical view and off-canonical views without text at inference. The resulting deltas are much weaker and only partially correlated with the sigma reward.
| Reward | Mean $\Delta r$ | Frac. positive | Std | Spearman vs $\sigma_{XYZ}$ |
|---|---|---|---|---|
| $\sigma_{XYZ}$ (ours) | +12.89 | 1.00 | 2.38 | — |
| Reward3D | +0.10 | 0.77 | 0.18 | +0.25 |
| MVReward | -0.03 | 0.39 | 0.09 | -0.05 |
The interpretation is nuanced. Reward3D is weakly aligned with the sigma reward and agrees that the tuned generator is better on most seeds, but MVReward is essentially uncorrelated and appears out of distribution for FFHQ-domain face renders. This supports the paper’s claim that density-field geometry is not captured by all 2D image-based rewards, even when they are designed for 3D generation.
Cross-generator transfer and out-of-distribution behavior
The paper then asks whether a reward trained on EG3D’s sigma distribution transfers to other 3D face generators. The answer is mixed: the reward retains a positive within-generator rank signal on other models, but its dynamic range becomes compressed and its absolute scores shift sharply. This is shown most clearly by comparing PanoHead, SphereHead, and HyPlaneHead to the original EG3D distribution.
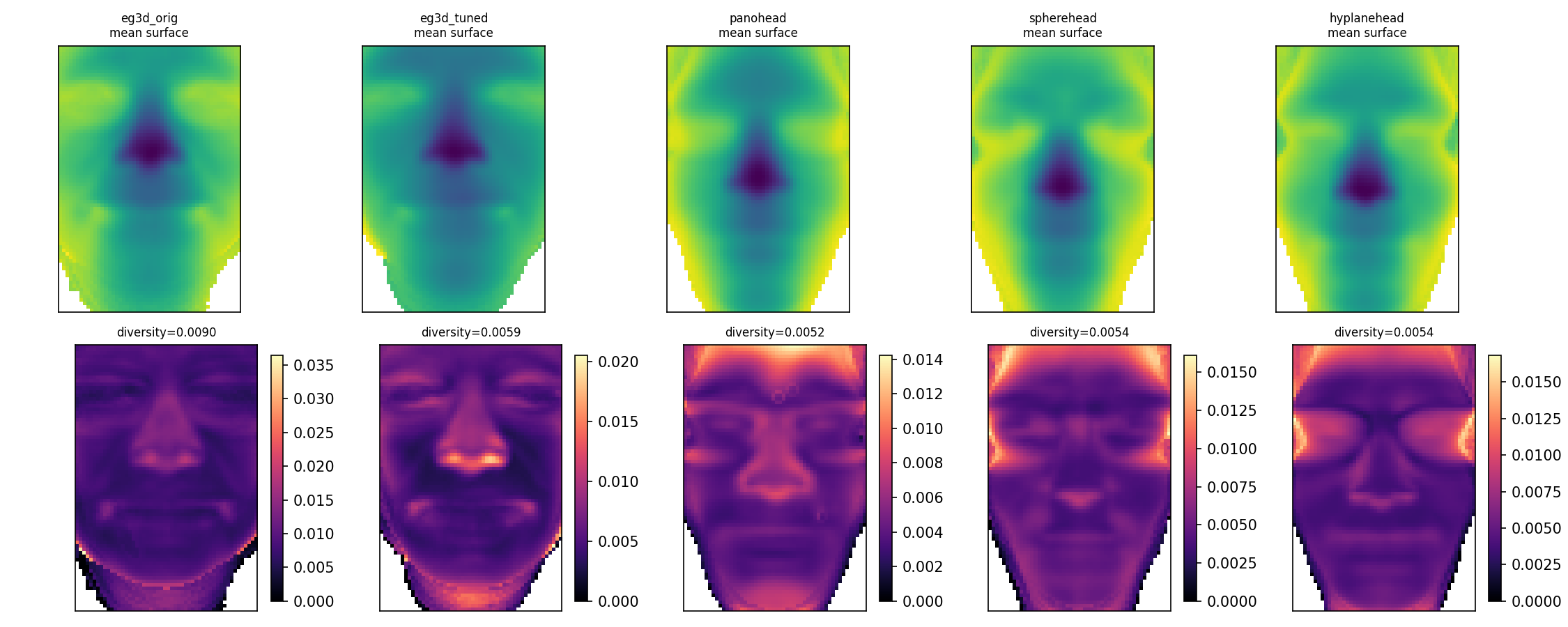
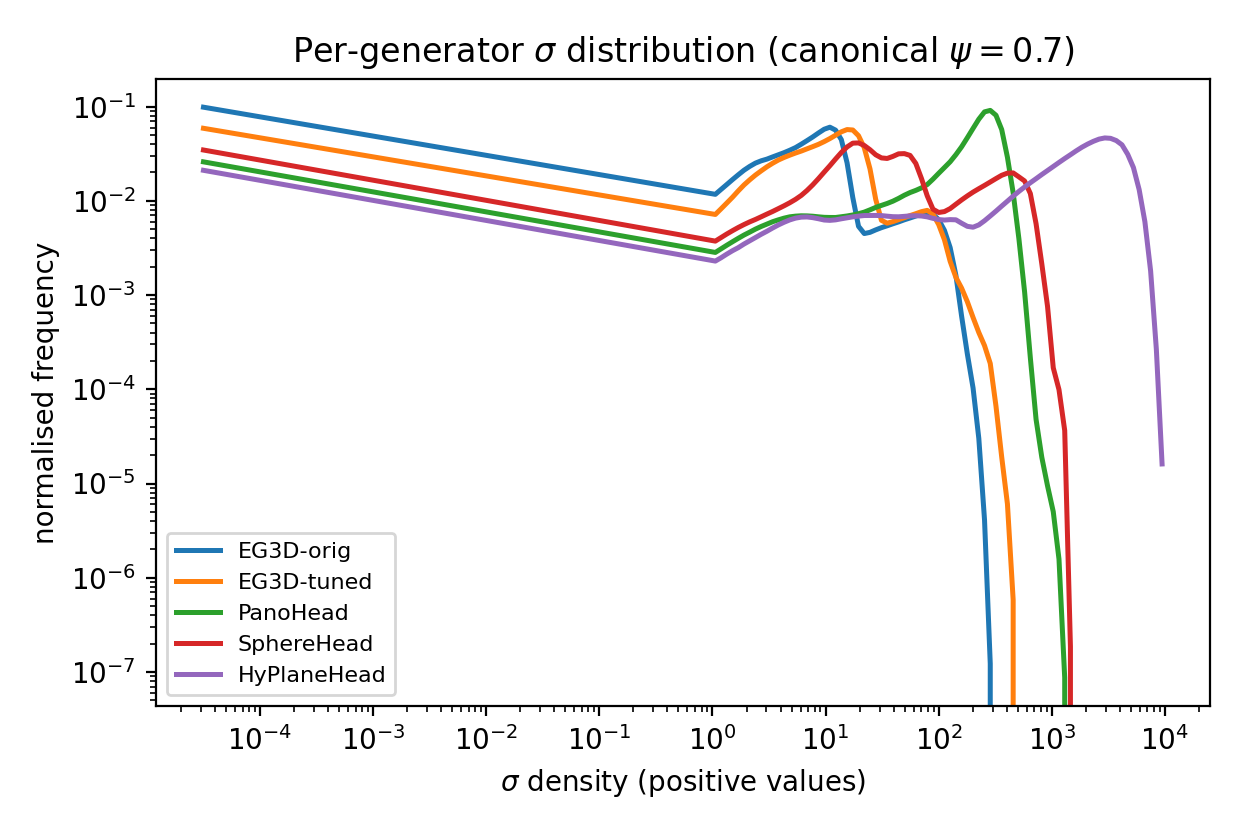
At canonical truncation $\psi = 0.7$, the mean sigma reward is $+5.76$ for EG3D-orig, but $-1.33$ for HyPlaneHead, $-3.13$ for SphereHead, and $-5.40$ for PanoHead. The paper argues that this is not purely a failure of the reward model: those generators also occupy different numerical regimes in density space, with peak sigma values varying by more than an order of magnitude. As a result, an EG3D-trained reward is evaluated out of distribution on the newer architectures.
| Generator | Mean | Median | Std | Gap vs EG3D-orig |
|---|---|---|---|---|
| EG3D-orig | +5.76 | +5.80 | 2.32 | — |
| HyPlaneHead | -1.33 | -1.40 | 0.38 | 3.1$\sigma$ |
| SphereHead | -3.13 | -3.08 | 0.55 | 3.8$\sigma$ |
| PanoHead | -5.40 | -5.58 | 1.12 | 4.8$\sigma$ |
Despite the OOD shift, the reward is not arbitrary inside each generator. The paper measures within-generator rank consistency by correlating scores at $\psi = 0.7$ and $\psi = 0.25$ on the same $100$ latent codes. All five generators show positive Spearman correlation, but the strength varies: EG3D-tuned is most stable, EG3D-orig and PanoHead are intermediate, and HyPlaneHead and SphereHead are weaker. The rank stability tracks how much the score distribution compresses under truncation.
| Generator | $\rho$ | Top-10 at $0.7$ in top-50 at $0.25$ | Bottom-10 at $0.7$ in bottom-50 at $0.25$ | Std ratio ($0.7 / 0.25$) |
|---|---|---|---|---|
| EG3D-orig | +0.37 | 80% | 70% | 1.5$\times$ |
| EG3D-tuned | +0.75 | 100% | 80% | 1.9$\times$ |
| PanoHead | +0.52 | 100% | 100% | 3.1$\times$ |
| HyPlaneHead | +0.18 | 60% | 80% | 5.0$\times$ |
| SphereHead | +0.22 | 60% | 80% | 4.6$\times$ |
The paper further tests a direct reward-guided inversion on SphereHead. Increasing the guidance weight improves the reward but worsens image reconstruction and visibly distorts the mesh. The conclusion is that the EG3D-trained reward does not transfer cleanly to SphereHead under this setup.

| Reward weight $w$ | MSE | Perceptual | Reward |
|---|---|---|---|
| 0 (baseline) | 0.027 | 0.091 | — |
| 0.01 | 0.032 | 0.099 | 6.69 |
| 0.1 | 0.038 | 0.124 | 7.32 |
| 1.0 | 0.055 | 0.162 | 7.23 |
| 10.0 | 0.069 | 0.186 | 8.56 |
Discussion and limitations
The main empirical message is that a simple preference model over density fields can improve 3D face geometry in a pretrained 3D-aware GAN, even when trained from a small and weakly supervised dataset. The reward is especially sensitive to the nose, face sides, and adjacent regions, which aligns well with human judgments of geometry quality. The paper also argues that the method is compute-efficient and practical: it uses a single annotator, a small number of preference pairs, and a standard GAN-loop update rather than a more complex RL pipeline.
The paper is equally explicit about the costs. First, the reward is tied to the generator distribution it was trained on: it does not transfer cleanly to other face generators with different density statistics. Second, the tuning objective improves geometry but slightly degrades 2D distributional fidelity, reflected in the FID increase from $4.092$ to $6.657$. Third, the preference data come from a single annotator, after an initial multi-annotator triplet-ranking attempt failed to converge to a stable preference. The study is therefore best read as a proof of concept, not a general model of population-level preference.
Another limitation concerns representation choice. Depth-map and point-cloud rewards can fit the preference pairs to some extent, but they often attend to face edges rather than semantically important regions and can produce distorted geometry when used aggressively. The sigma-field reward is the only one that consistently drives the intended geometric corrections while keeping the RGB appearance qualitatively stable.
The authors suggest several extensions: retraining the reward on other generator families to restore dynamic range, using multiple annotators to test consensus, and exploring mesh-based or image-based reward inputs under the same GAN-loop framework. They also note that a full replacement of the reward with other 3D or multi-view rewards would help disentangle whether the benefit comes from the reward representation, the fine-tuning loop, or both.
Conclusion
In summary, the paper demonstrates that human preferences can be used to fine-tune the geometry of an unconditional 3D-aware face GAN directly in density space. A small preference dataset is enough to train a reward model over $\sigma_{XYZ}$, and that reward can reshape EG3D’s geometry so that external users prefer the results, while preserving identity and 2D appearance reasonably well. The method is not universal — it is tied to the training distribution of the generator — but within that regime it offers a clean and practical route to RLHF-style 3D geometry improvement without meshes or text prompts.
Code & Implementation
This repository implements the human-preference fine-tuning pipeline for 3D-aware face GAN geometry improvement as described in the paper "Sculpting NeRF Geometry: Human-Preference Fine-Tuning of a 3D-Aware Face GAN".
The core of the code is structured around three main components:
- EG3D Fork and Fine-Tuning Loop: Located in the
eg3d/directory, this contains a PyTorch-based fork of the EG3D 3D-aware GAN, with the critical fine-tuning loop implemented in thetrain_rlhf.pyscript. This module handles generator fine-tuning guided by the learned reward model to improve geometry quality directly in the neural radiance field's density representation. - Reward Model Training Framework: Found in
reward_model_training/, this uses Hydra and PyTorch Lightning to train geometry-aware reward models on a dataset of human preference rankings. The reward model reads cropped 3D sigma-density fields from the generator's output and produces preference logits used as supervision signals for fine-tuning. - Supporting Utilities and Analyses: Additional scripts for dataset preprocessing, mesh export, post-hoc analysis, and ranked preference metadata are available under
dataset_preprocessing/,paper_artifacts/, andpaper_result_analyses/.
The repository uses Hydra configurations for running experiments, enabling reproducible training of reward models and EG3D fine-tuning. Released pre-trained checkpoints include the reward model and the fine-tuned EG3D generator, which are used in analysis and figure generation.
Overall, this modular design reflects the paper's methodology: sampling and ranking geometry from EG3D, training a differentiable reward over 3D density fields, and fine-tuning the generator towards human-preferred geometry improvements.