GeoFace
GeoFace: Consistent Multi-View Face Generation with Geometry-Constrained Diffusion

GeoFace generates multi-view face images with consistent 3D geometry from a single input using a dual-stream diffusion model. Its unique geometry-guided attention ensures all views share a photorealistic, aligned underlying 3D face structure, surpassing prior methods without explicit 3D constraints.
Demos
These demos highlight GeoFace's ability to generate multi-view face images with consistent 3D geometry from a single input. Watch for geometric coherence across varied poses, evident in mesh overlays and focused cross-attention maps, as well as improvements in 3D face reconstruction quality. The in-the-wild results demonstrate robustness to challenging lighting, makeup, and stylized inputs, confirming strong geometry-appearance alignment.

Links
Paper & demos
Code & resources
Abstract
We present GeoFace, a geometry-constrained multi-view diffusion framework for consistent face generation from a single input. % While recent multi-view diffusion models achieve photorealistic synthesis at the per-view level, they lack an explicit mechanism to enforce a shared 3D structure across views, often leading to inconsistent geometry across viewpoints. To address this, GeoFace proposes a unified dual-stream framework for joint generation of multi-view RGB images and 3D face geometry, where the appearance and geometry streams interact through shared attention layers. To encourage the two streams to mutually constrain each other, we introduce a geometry-guided attention alignment loss that supervises the cross-attention between appearance and geometry tokens with 3D-consistent correspondences, enabling the appearance stream to correctly reference pose-invariant geometric cues for robust alignment across viewpoints. Geometry is represented as a canonical UV position map, derived from a FLAME mesh fitted to multi-view observations, serving as a view-invariant shared constraint across all generated views. Experiments on RenderMe-360 and NeRSemble demonstrate that GeoFace consistently outperforms existing methods in both visual quality and cross-view geometric consistency, facilitating more efficient 3D reconstruction.
1. Problem setting and core idea
GeoFace addresses a specific but important failure mode in single-image-to-multi-view face generation: modern diffusion models can synthesize photorealistic views, yet the generated views often disagree on the underlying 3D facial structure. This shows up most clearly under large yaw changes, where one view may imply a different nose shape, jawline, or forehead contour than another. The paper’s central claim is that better multi-view face generation requires not only appearance consistency, but an explicit shared geometric representation that is generated jointly with the RGB views.
The method therefore formulates face generation as a conditional joint diffusion problem over a set of target RGB views and a canonical 3D geometry representation. Given a reference image $I^{\text{ref}}$ and its camera $c^{\text{ref}}$, the model predicts target views $\mathbf{I}^{\text{tgt}} = \{ I_{(v)}^{\text{tgt}} \}$ together with a geometry latent $\mathcal{G}$ in FLAME canonical space:
$$P(\mathbf{I}^{\text{tgt}}, \mathcal{G} \mid I^{\text{ref}}, c^{\text{ref}}, \mathbf{C}^{\text{tgt}}).$$
The key design choice is to represent geometry as a canonical UV position map, where each texel stores the 3D coordinate of a surface point on a FLAME mesh. Because this representation is view-invariant and image-like, it can be denoised by the same kind of latent diffusion backbone used for RGB images, while remaining tightly coupled to the appearance synthesis process.

2. Method
2.1 Overview: a dual-stream multi-view diffusion model
GeoFace extends a CAT3D-style latent multi-view diffusion backbone. Instead of generating only a set of target RGB views, the backbone is expanded into a dual-stream system:
- Appearance stream: denoises target-view RGB latents conditioned on camera information encoded as Plücker ray embeddings.
- Geometry stream: denoises a latent UV position map that represents canonical FLAME-space geometry shared across all generated views.
Both streams are processed by shared attention layers in a single U-Net, so geometry is not a post-hoc constraint but part of the generative process itself. The paper’s motivation is that a shared 3D structure should emerge from the interaction of the two streams rather than from RGB synthesis alone.
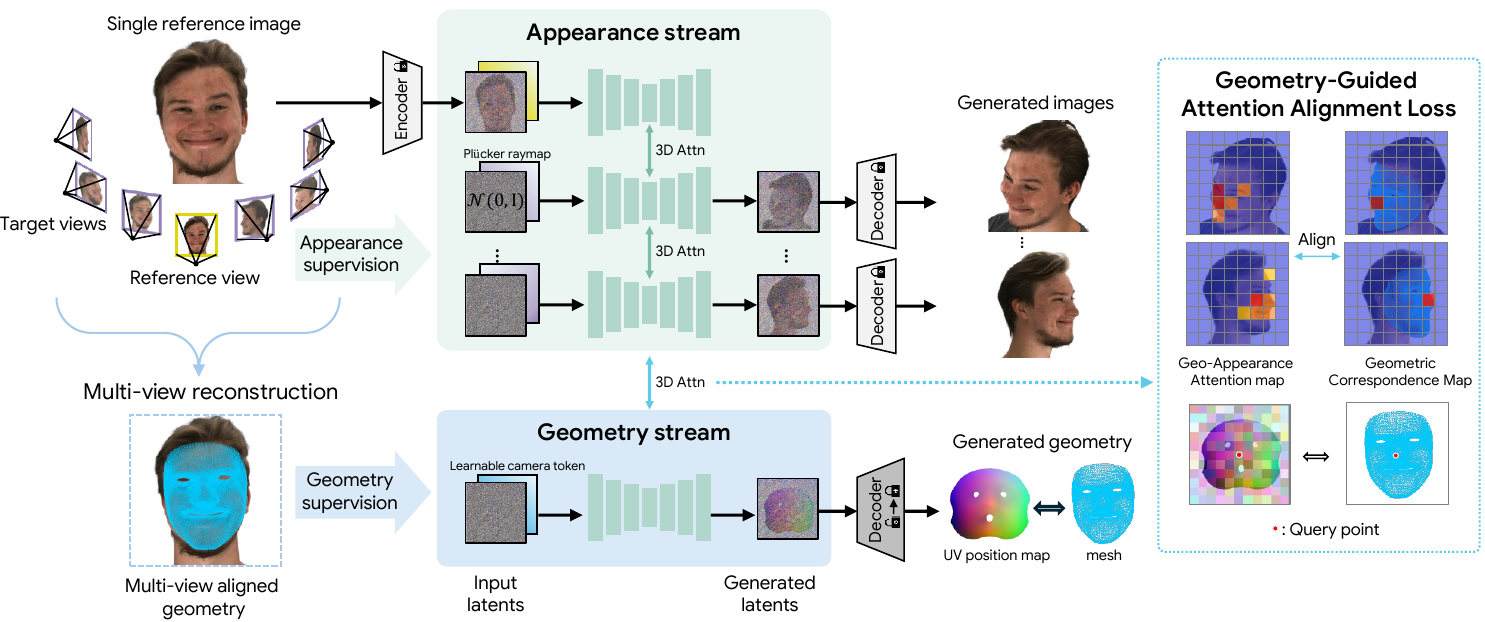
2.2 Conditioning and stream roles
The model uses a near-frontal reference image to stabilize identity and appearance conditioning. Target cameras are defined relative to the reference pose through yaw and pitch offsets, which makes the formulation agnostic to the world coordinate system and helps the model generalize across camera configurations. The paper also describes a stream-role conditioning mask, with values $0$, $1$, and $0.5$ used for the reference, target, and geometry streams, respectively.
The geometry stream cannot use a standard camera embedding, because the canonical UV position map is not associated with a real viewpoint. To avoid injecting a misleading viewpoint assumption, GeoFace replaces the Plücker embedding in the geometry stream with a learnable camera token $\mathbf{e}^{\text{geo}} \in \mathbb{R}^{6}$, optimized end-to-end as a view-agnostic positional code for canonical geometry.
2.3 Geometry representation and decoder handling
Geometry is represented as a canonical UV position map $\mathcal{G} \in \mathbb{R}^{H \times W \times 3}$. Each texel stores a dense 3D coordinate on the FLAME mesh in canonical space, which gives the representation two desirable properties: it is topology-aware and view-invariant. Since the representation is image-like, the authors can reuse a 2D convolutional diffusion backbone without architectural redesign.
A practical detail is that the pretrained Stable Diffusion VAE encoder is considered expressive enough for UV maps, so it is kept frozen; only the decoder is fine-tuned to better handle the distribution mismatch caused by sharp discontinuities at UV seam boundaries.
2.4 Geometry-guided attention alignment loss
The most distinctive technical contribution is the geometry-guided attention alignment loss. The geometry stream introduces cross-modal attention between UV tokens and appearance tokens, but this pathway is not naturally supervised during diffusion training. GeoFace therefore explicitly teaches these cross-attention maps to respect 3D correspondences derived from the canonical UV position map and calibrated camera poses.
Let $\hat{A}^{\text{uv}} \in \mathbb{R}^{hw \times F \cdot hw}$ denote geometry-to-appearance attention and $\hat{A}^{\text{face}} \in \mathbb{R}^{F \cdot hw \times hw}$ denote appearance-to-geometry attention. The supervision is bidirectional, using ground-truth correspondences for valid query tokens only:
$$ \mathcal{L}_{\text{align}} = -\sum_{i \in \mathcal{V}^{\text{uv}}} \sum_{v,j} \mathbf{g}^{\text{uv}}_{i,(v,j)} \log \hat{A}^{\text{uv}}_{i,(v,j)} -\sum_{(v,j) \in \mathcal{V}^{\text{face}}} \sum_{i} \mathbf{g}^{\text{face}}_{(v,j),i} \log \hat{A}^{\text{face}}_{(v,j),i}. $$
The correspondence targets are built from 3D positions associated with latent cells. For each UV token and face-view token, the paper averages world-space coordinates over the foreground texels inside the cell, then defines one-hot matches by nearest-neighbor $\ell_2$ distance, masking pairs whose distance exceeds a threshold $\tau$ to suppress spurious matches. The appearance-to-geometry target is approximated as the transpose of the geometry-to-appearance correspondence. The loss is applied only on the geometry-appearance pathway, because face-to-face attention is already relatively well aligned and would be expensive to supervise fully.
2.5 Training objective
Training combines RGB denoising, geometry denoising, and the alignment loss:
$$\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{rgb}} + \mathcal{L}_{\text{geo}} + \lambda_{\text{align}}\mathcal{L}_{\text{align}}.$$
Here $\mathcal{L}_{\text{rgb}}$ is the v-prediction loss for the appearance streams, $\mathcal{L}_{\text{geo}}$ is the v-prediction loss for the geometry stream, and $\lambda_{\text{align}}$ weights the correspondence supervision.

2.6 How geometry supervision is constructed
Existing face datasets do not directly provide canonicalized UV geometry supervision, so the paper constructs it from multi-view video collections. The authors sample frames with noticeable facial expressions to capture a range of geometry while preserving strict synchronization across views. They use RenderMe-360, which provides 27 synchronized viewpoints per identity, and Nersemble v2, which provides 16 viewpoints per identity.
Geometry is recovered using the VGGTFace pipeline: per-view point maps from VGGT and UV coordinate maps from Pixel3DMM are aggregated, refined by bundle adjustment, and converted into a consistent set of FLAME vertices. Since these vertices live in an arbitrary world coordinate frame, the paper applies a Sim(3) transformation estimated by Procrustes alignment to map them into shared FLAME canonical space. The canonicalized mesh is then rasterized into the UV domain to produce a UV position map for each frame.
3. Experimental setup
3.1 Implementation details
GeoFace is implemented on top of CAT3D, initialized from pretrained Stable Diffusion 2.1 weights. Because the official CAT3D implementation is unavailable, the authors reimplement the method using the MVGenMaster codebase. Training uses AdamW with learning rate $5 \times 10^{-5}$, per-GPU batch size 6, gradient clipping with max norm 1.0, and conditioning dropout probability 0.1 for classifier-free guidance.
The model is trained for 50k iterations on 2 NVIDIA A100 40GB GPUs at $512 \times 512$ resolution. At inference, they use classifier-free guidance scale 2.0 and a DDIM sampler with 50 steps. The geometry-guided attention alignment loss is applied at layer 10 of the U-Net decoder, following the layer choice in CAMEO, with $\lambda_{\text{align}} = 0.02$ and correspondence threshold $\tau = 0.035$.
3.2 Datasets and splits
The model is trained and evaluated on two multi-view face datasets: RenderMe-360 and Nersemble v2. For RenderMe-360, the paper uses 450 identities for training and 40 for testing, yielding over 5K training pairs and 480 test pairs. For Nersemble v2, it uses 450 identities for training and 30 for testing, and samples 15 view pairs per identity for a total of 9,750 training pairs and 450 test pairs.
On RenderMe-360 the viewpoints are restricted to the frontal hemisphere, within $\pm 90^\circ$ of the frontal direction, because the paper focuses on face-centric novel-view synthesis rather than full head-body coverage. For both datasets, the authors randomly select a representative frame per sequence to match the corresponding expression.
3.3 Baselines and metrics
The paper compares against two groups of baselines. Face-specific 3D-aware generators include PanoHead and SphereHead (NeRF-based), as well as DiffPortrait360 and CAP4D (diffusion-based). A general multi-view/video baseline, SEVA, is also evaluated. For CAP4D, the authors report results using only the morphable multi-view diffusion model stage to make the comparison focused on novel-view synthesis quality.
Evaluation uses PSNR and SSIM for fidelity, LPIPS for perceptual similarity, and ArcFace cosine similarity (CSIM) for identity consistency. For geometric consistency, the paper also reports MEt3R in the analysis section and vertex-to-vertex error (V2V) in the ablation study.
4. Main results
4.1 Quantitative comparison on RenderMe-360
GeoFace substantially outperforms all baselines on RenderMe-360, with especially large gains in the profile-view regime, where geometry ambiguity is highest. The paper highlights that the benefit of explicit geometry supervision becomes more pronounced under large pose variation.
| Method | Frontal-to-mid PSNR | Frontal-to-mid SSIM | Frontal-to-mid LPIPS | Frontal-to-mid CSIM | Profile PSNR | Profile SSIM | Profile LPIPS | Profile CSIM |
|---|---|---|---|---|---|---|---|---|
| PanoHead | 11.78 | 0.6404 | 0.3957 | 0.5330 | 10.71 | 0.5985 | 0.4622 | 0.3754 |
| SphereHead | 12.24 | 0.6528 | 0.3883 | 0.5219 | 11.29 | 0.6252 | 0.4471 | 0.3601 |
| SEVA | 12.39 | 0.6706 | 0.3568 | 0.5895 | 10.26 | 0.6228 | 0.4650 | 0.4848 |
| DiffPortrait360 | 10.59 | 0.5915 | 0.4534 | 0.4697 | 8.11 | 0.4804 | 0.6005 | 0.2513 |
| CAP4D | 12.82 | 0.6782 | 0.3235 | 0.6526 | 12.10 | 0.6676 | 0.3738 | 0.5388 |
| GeoFace | 17.34 | 0.7780 | 0.1795 | 0.8084 | 15.30 | 0.7562 | 0.2440 | 0.7001 |
4.2 Quantitative comparison on Nersemble v2
The same pattern holds on Nersemble v2. GeoFace is the best method across all metrics and both viewpoint ranges, with the strongest improvements again appearing on profile views.
| Method | Frontal-to-mid PSNR | Frontal-to-mid SSIM | Frontal-to-mid LPIPS | Frontal-to-mid CSIM | Profile PSNR | Profile SSIM | Profile LPIPS | Profile CSIM |
|---|---|---|---|---|---|---|---|---|
| PanoHead | 13.54 | 0.6613 | 0.3528 | 0.5983 | 11.80 | 0.6310 | 0.4358 | 0.5088 |
| SphereHead | 13.44 | 0.6650 | 0.3556 | 0.6157 | 11.35 | 0.6263 | 0.4433 | 0.5206 |
| SEVA | 12.73 | 0.2169 | 0.4692 | 0.5436 | 11.18 | 0.2073 | 0.4849 | 0.4839 |
| DiffPortrait360 | 12.31 | 0.6250 | 0.4064 | 0.5823 | 10.67 | 0.5803 | 0.4927 | 0.4795 |
| CAP4D | 12.41 | 0.6428 | 0.4059 | 0.6090 | 10.68 | 0.6006 | 0.5099 | 0.4606 |
| GeoFace | 21.33 | 0.7858 | 0.1460 | 0.8365 | 18.16 | 0.7384 | 0.2055 | 0.7782 |
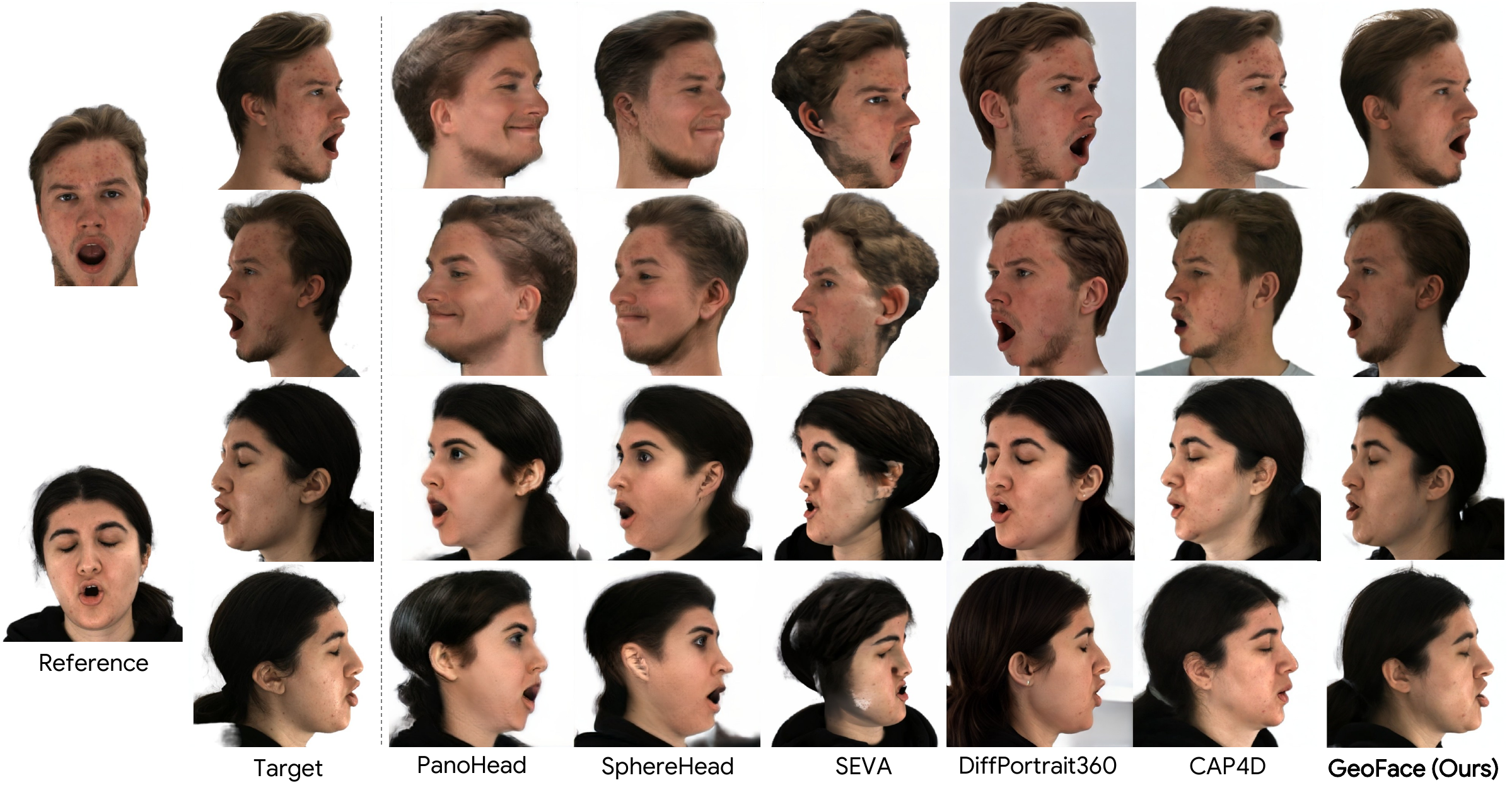

4.3 Qualitative behavior
The qualitative comparisons reinforce the quantitative story. The paper reports that NeRF-based methods such as PanoHead and SphereHead struggle to synthesize realistic faces under large pose changes, likely due to the limited diversity of large-pose training data. SEVA, which is not face-specific, often distorts the head shape and facial structure. DiffPortrait360 gives visually appealing outputs but still exhibits geometric inconsistencies around the nose and jaw. CAP4D improves consistency via FLAME-based guidance, but its output can degrade when the FLAME fitting fails to capture fine-grained expression or geometry.
GeoFace is described as especially strong on self-occluded regions such as the jaw and nasal bridge, where appearance-only methods have insufficient information to resolve depth ambiguity. The paper’s interpretation is that the geometry stream supplies the missing structural prior directly into the diffusion process.

4.4 In-the-wild generalization and downstream reconstruction
The paper includes an in-the-wild qualitative figure showing inputs outside the controlled capture setting, including portraits with difficult lighting, heavily made-up faces, 3D-rendered characters, and stylized illustrations. GeoFace is reported to preserve identity while producing geometrically coherent novel views, suggesting that the geometry stream learns a structural prior that transfers beyond the training distribution.
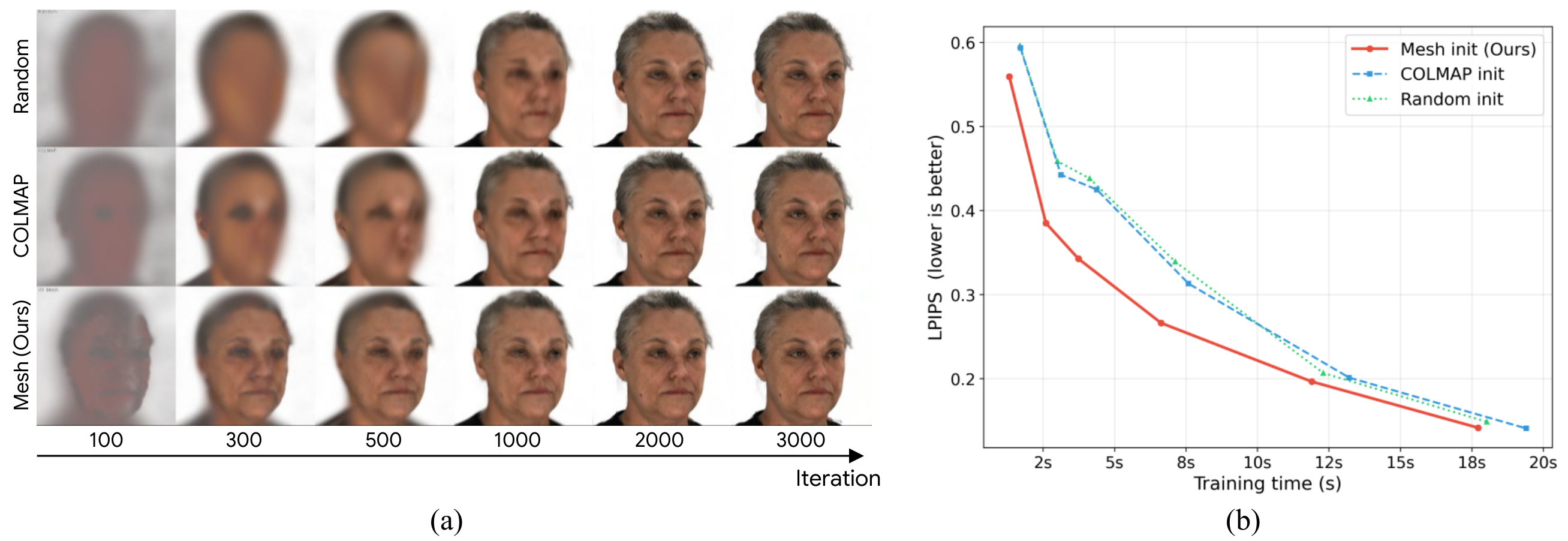
A downstream experiment evaluates GeoFace as an initialization source for 3D Gaussian Splatting. The authors generate 24 multi-view images from a single reference image, then reconstruct a Gaussian scene using three initialization strategies: random initialization, COLMAP-based initialization, and mesh-based initialization from the jointly generated FLAME mesh averaged across multiple generations. The mesh-based strategy gives denser and more uniform coverage of the facial surface than sparse feature-based COLMAP initialization.
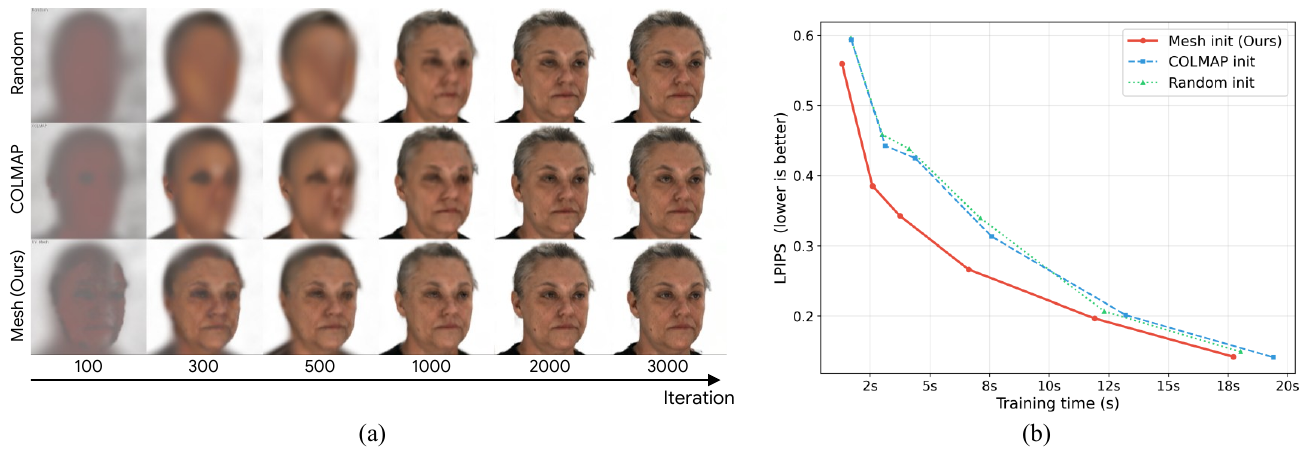
The reported outcome is that mesh-based initialization yields noticeably sharper early reconstructions and faster convergence, with consistently lower LPIPS than both random and COLMAP-based baselines. This supports the paper’s claim that jointly generated geometry is useful not only for image synthesis but also as a structural prior for 3D reconstruction.
5. Ablation studies
5.1 Geometry stream, learnable token, and alignment loss
The main ablation study is run on RenderMe-360 and reports image metrics as well as V2V error for the generated UV position map. The ablations isolate three design choices: adding the geometry stream, using a learnable camera token rather than a fixed reference-view token, and adding the geometry-guided attention alignment loss.
| Variant | Geometry stream | Learnable token | Alignment loss | PSNR | SSIM | LPIPS | CSIM | V2V error |
|---|---|---|---|---|---|---|---|---|
| (a) CAT3D baseline | No | No | No | 15.12 | 0.7499 | 0.2495 | 0.7020 | - |
| (b) | Yes | No | No | 15.33 | 0.7507 | 0.2474 | 0.7069 | 15.26 |
| (c) | Yes | Yes | No | 15.61 | 0.7597 | 0.2359 | 0.7161 | 13.12 |
| (d) | Yes | No | Yes | 15.50 | 0.7520 | 0.2424 | 0.7137 | 15.00 |
| (e) GeoFace | Yes | Yes | Yes | 15.71 | 0.7595 | 0.2300 | 0.7226 | 12.65 |
The ablation shows that adding the geometry stream improves all metrics over the CAT3D baseline, confirming that jointly denoising a canonical UV position map regularizes cross-view appearance generation. Introducing the learnable token further improves performance and reduces geometry error, which the authors interpret as evidence that a view-agnostic conditioning code is better aligned with FLAME canonical space than a fixed reference-view assumption. Adding the alignment loss brings the best overall model, especially improving LPIPS, CSIM, and V2V error.
One subtle point is that the full model’s SSIM is very close to, but slightly below, the variant with the learnable token but no alignment loss. The paper still selects the full model because the overall tradeoff favors better perceptual quality, identity preservation, and geometry accuracy.

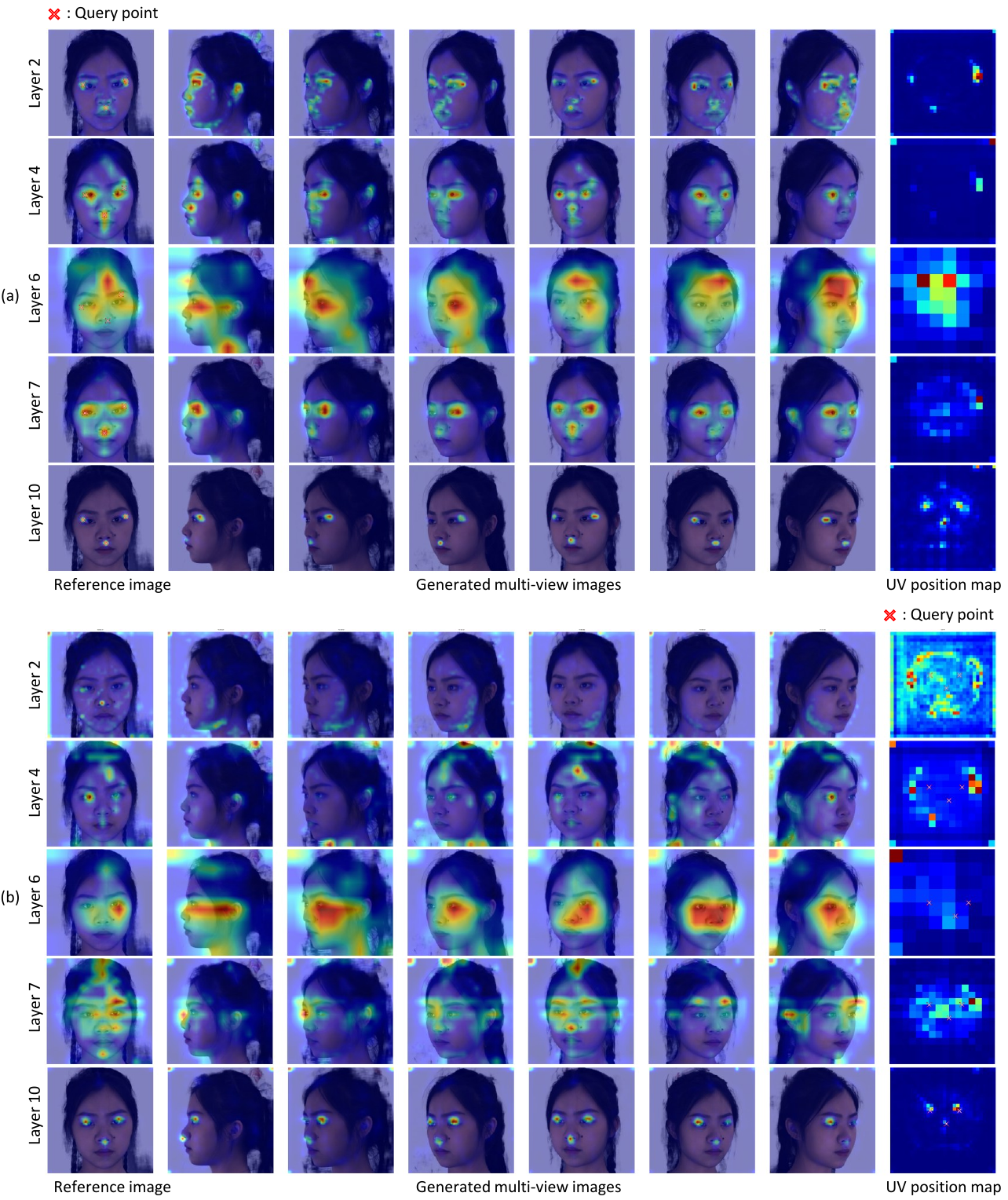
The layer-wise attention visualization shows why supervision is placed at decoder layer 10: this layer yields the most spatially localized correspondences in both directions. Earlier or later layers are less sharply aligned, so layer 10 is chosen as the best tradeoff for correspondence learning.
5.2 Cross-view feature consistency analysis
To quantify the benefit of the geometry stream beyond standard image metrics, the paper reports MEt3R on RenderMe-360. The variant without geometry obtains a score of $0.3304$, GeoFace improves it to $0.3198$, and the ground truth reference is $0.3157$. Since lower is better, this shows that the geometry stream measurably improves cross-view consistency, though there remains a gap to the real data distribution.
6. Stated contributions and novelty
- The paper proposes a unified dual-stream diffusion framework for joint generation of multi-view RGB images and 3D face geometry.
- It introduces a geometry-guided attention alignment loss that explicitly supervises cross-attention with 3D-consistent correspondences.
- It uses a canonical UV position map in FLAME space as a view-invariant geometry representation that can be denoised with standard latent diffusion machinery.
- It demonstrates that the geometry stream improves both novel-view synthesis quality and downstream 3D reconstruction initialization.
7. Limitations and future directions
The paper’s main limitation is also straightforward: the geometry backbone is still FLAME-based, so the method may not fully represent regions outside the facial surface such as hair, ears, and teeth. This can reduce geometry completeness for subjects with complex hairstyles or accessories. The authors also note that broader validation on in-the-wild data remains an open direction, even though they show some promising qualitative examples.
In other words, GeoFace improves face-centric multi-view consistency substantially, but it is not yet a complete human-head geometry solution. Extending the geometric representation beyond the FLAME face manifold is the natural next step.
8. Bottom line
GeoFace is a strong and carefully motivated step toward geometry-aware multi-view face diffusion. Its main contribution is not simply adding a geometry branch, but making geometry a first-class generative target and explicitly aligning appearance-geometry attention through 3D correspondences. The result is better identity preservation, better profile-view fidelity, cleaner cross-view geometry, and a useful geometric prior for downstream reconstruction.
Code & Implementation
This repository is currently a placeholder for the "GeoFace: Consistent Multi-View Face Generation with Geometry-Constrained Diffusion" paper. According to the README, the code release is pending, and no source code files are available at this time.
As such, there are no implementation details or runnable scripts included yet. Future updates are expected to provide the official code to reproduce the method, which involves geometry-constrained multi-view diffusion for consistent face generation as described in the paper.