MindFlow
MindFlow: Harmonizing Cognitive Semantics and Acoustic Dynamics for Facial Animation Generation in Dyadic Conversations
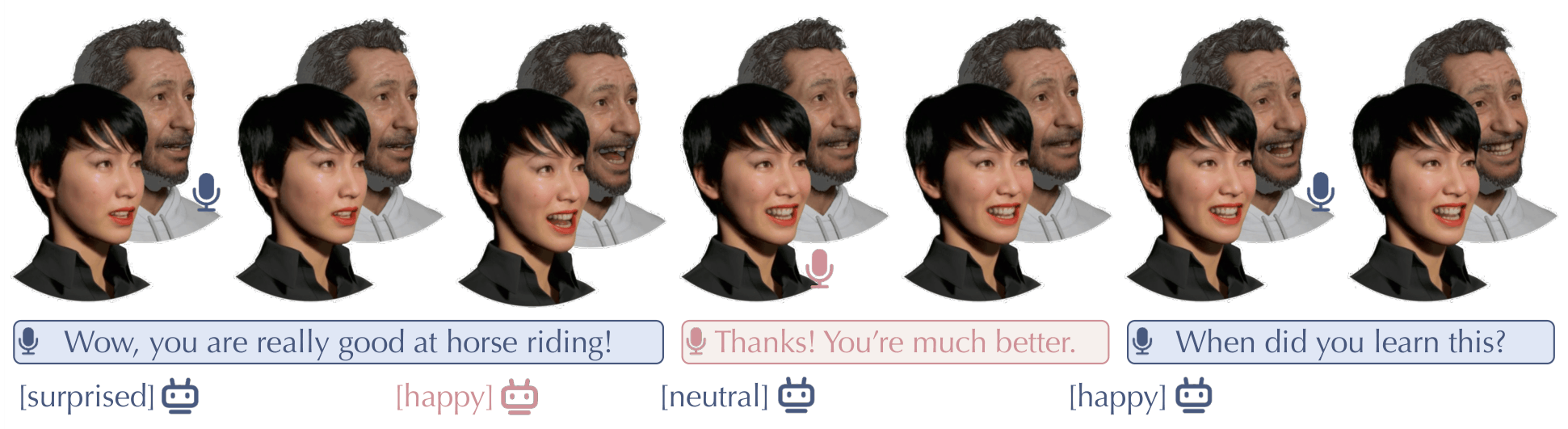
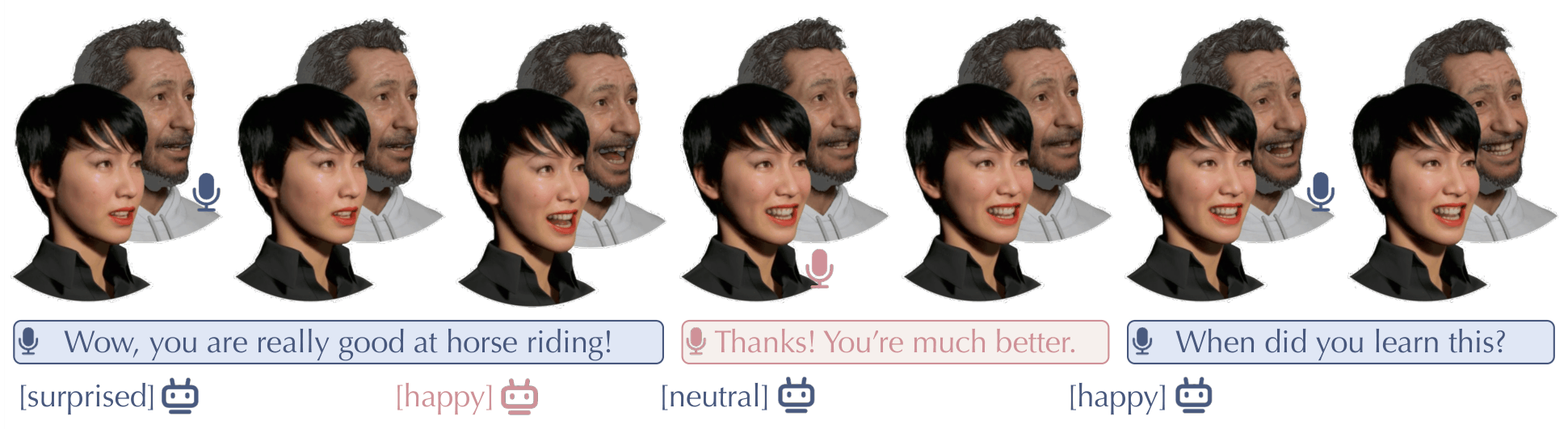
MindFlow generates lifelike facial animations in dyadic conversations by combining evolving emotional state reasoning with precise motion control. It models raw audio as emotion states and adaptively fuses acoustic cues to produce semantically rich and temporally accurate facial animation.
Demos
The demos show MindFlow's skill in generating natural facial animations for dyadic conversations by harmonizing semantic understanding with acoustic dynamics. Look for smooth expressions that reflect emotional shifts and natural talking-listening interactions without rigid motions. These examples highlight fine-grained, synchronized facial behaviors that align with conversational roles and emotions.
Links
Paper & demos
Abstract
Generating lifelike facial animation for dyadic conversations requires reconciling high-level cognitive intent with precise low-level motor reflexes, yet existing methods fall short in the semantic understanding of dialogue context and in precise dynamic control. In this paper, we propose MindFlow, a dual-pathway generative framework inspired by the Ventral-Dorsal pathway model in neuroscience, which decouples generation into two collaborative streams, thereby harmonizing deep semantic reasoning with fine-grained control. In the Ventral module, we transform the conventional Sentence-Action approach into a novel Chunk-State approach that models raw acoustic streams as a context-aware, evolving emotional state chain, capturing subtle paralinguistic nuances and mid-utterance emotional shifts missed by sentence-level modeling. The Dorsal module features a conditional autoregressive flow matching network for high-fidelity facial motion, driven by high-frequency acoustic cues and modulated by emotion states, plus a Selective Acoustic Injector for adaptive audio gating to ensure robustness in talking-and-listening dynamics without interference. Extensive experiments demonstrate that MindFlow achieves superior semantic appropriateness and motion naturalness compared to state-of-the-art baselines.
1. Problem Setting and High-Level Idea
MindFlow targets streaming facial animation generation in dyadic conversations, where an avatar must both react naturally while listening and produce synchronized motion while speaking. The paper argues that existing audio-driven or dialogue-aware methods tend to fail in one of two ways: they are either good at low-level acoustic synchronization but semantically hollow, or semantically aware but too coarse, static, or sentence-bound to capture fine conversational timing.
The central design choice is to mirror the neuroscience-inspired Ventral-Dorsal dual-pathway hypothesis. MindFlow splits the problem into two coupled streams: a Ventral module for streaming cognitive-semantic inference over dialogue audio, and a Dorsal module for reflexive, high-fidelity motion synthesis. The key conceptual shift from prior work is the move from a Sentence-Action paradigm to a Chunk-State paradigm: rather than summarizing an entire sentence into a discrete motion command, MindFlow reasons over short raw-audio chunks and maintains an evolving emotion state across time.

2. Task Formulation
The task is formulated as a causal, streaming generation problem. At time step $t$, the system predicts the facial motion $M_a^t$ for interlocutor $a$ using only information available up to time $t$:
$$M_a^t = G(A_a^{\le t}, A_b^{\le t}, S_a^{
Here, $A_a^{\le t}$ and $A_b^{\le t}$ are the continuous raw audio streams from the two interlocutors, and $S_a^{
The paper further discretizes time into chunks of size $w$ and writes the coupled reasoning/generation process as:
$$
\begin{cases}
S_a^k = \operatorname{Ventral}(A_a^{\le k}, A_b^{\le k}, S_a^{
where $k = \lfloor t / w \rfloor$ is the chunk index. In the final system, the chunk window is set to 1.5 seconds.
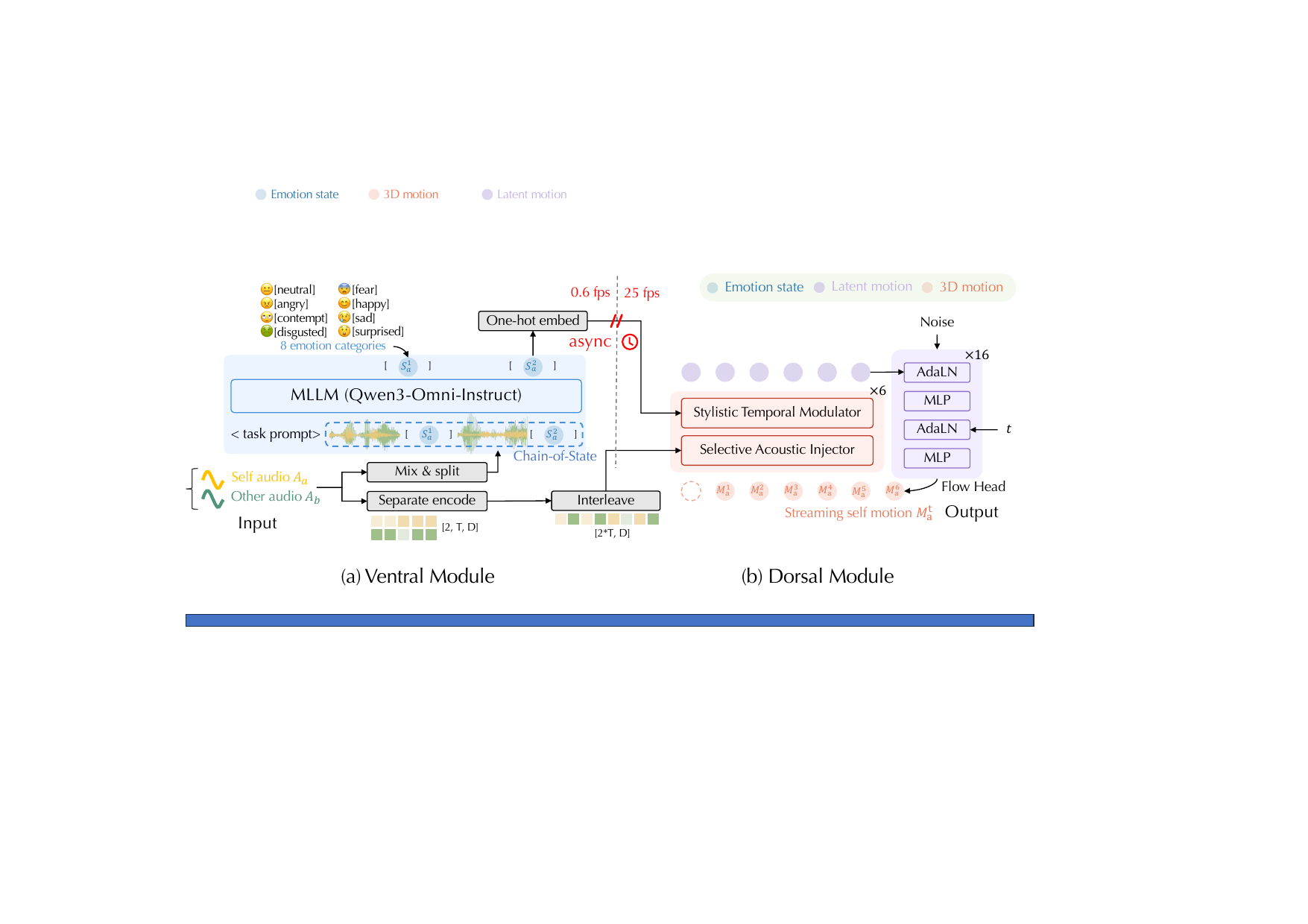
MindFlow is organized as a dual-pathway framework with two cooperating modules. The Ventral module acts as a cognitive semantic perceiver that continuously updates emotional state from audio chunks using a multimodal large language model (MLLM). The Dorsal module acts as a sensory-motor executor that uses the semantic state, along with acoustic cues from both interlocutors, to synthesize motion in an autoregressive and streaming fashion.
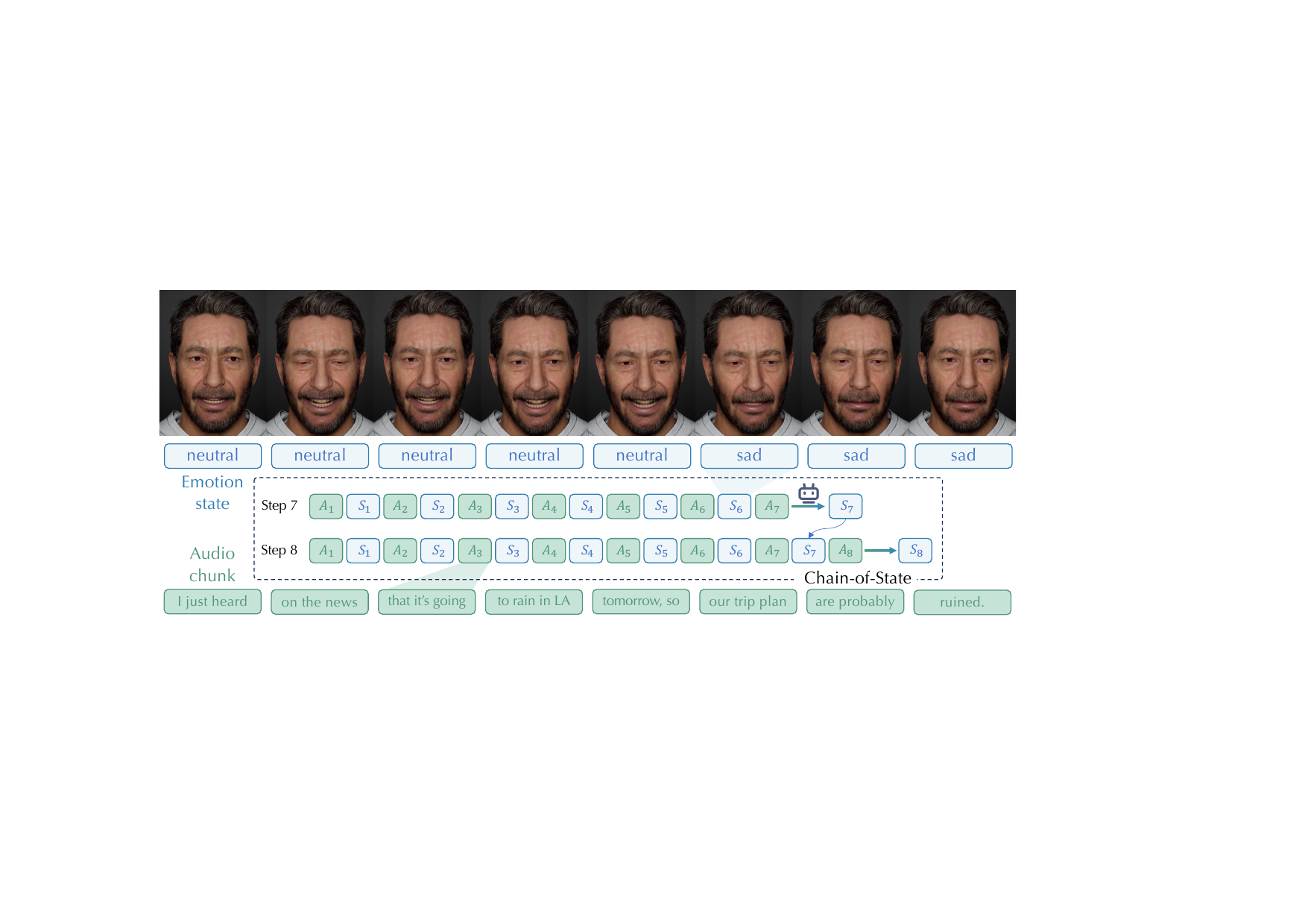
Prior dialogue-aware facial animation methods often use a Sentence-Action pipeline: an LLM reads text-level dialogue and emits a predefined motion instruction such as a nod, a gaze shift, or a smile. MindFlow argues that this has two structural flaws. First, text-only reasoning discards prosody and other paralinguistic cues that are present in the raw audio. Second, sentence boundaries are too coarse for conversational motion: real human expressions evolve within a sentence, not only at its end. Chunk-State addresses both issues by reasoning directly on fixed-window audio chunks and updating a state chain over time.
The supplementary prompt makes this design explicit: the MLLM is asked to infer one emotion label per chunk, jointly considering semantics and vocal prosody, while maintaining continuity with previous predictions. The label set is restricted to eight emotions: angry, contempt, disgusted, fear, happy, sad, surprised, and neutral.
The Ventral module is the semantic and emotional anchor of the system. Instead of mapping a full sentence to a static action, it consumes short audio chunks and updates an emotion state chain that represents the evolving conversational state. The implementation uses an MLLM in a streaming setting and a Chain-of-State mechanism to preserve context across chunks.
The core motivation is that if each chunk were analyzed independently, the model would lose conversational history. If, conversely, each query simply concatenated the current chunk with all prior chunks, the MLLM would have history but would not explicitly track previous emotion estimates. The paper’s solution is to append predicted state back into the context so that the model reasons over both the sensory history and its own previous emotional trajectory. This makes the inferred state smoother and more stable across time.
In the supplementary material, the authors stress that the Ventral module should infer the target speaker’s emotion even during listening: when the target is silent, the system should still infer the listener’s reaction from the other speaker’s speech content and prosody, rather than falling back to neutral by default.
This module therefore provides two forms of guidance to the Dorsal module: a coarse semantic interpretation of the ongoing interaction and a temporally evolving emotion state that acts as a prior for facial dynamics generation.
The Dorsal module is responsible for physically plausible motion synthesis. It is built as an autoregressive Transformer backbone with two specialized injectors and a flow-matching output head. The overall objective is to keep generation responsive enough for streaming use while still producing diverse, natural motion rather than deterministic regression outputs.
The Stylistic Temporal Modulator injects the Ventral emotion state into the motion backbone. The state embedding is appended to the hidden motion sequence and made visible to subsequent motion tokens through masked causal attention. This allows the model to condition on emotion without peeking into the future, preserving the streaming constraint.
Conceptually, this is the semantic bridge between cognition and reflexes: the emotion state shapes the style of the upcoming motion, while the autoregressive backbone handles the exact frame-by-frame realization.
A major problem in dyadic animation is how to use the two audio streams. Prior work often early-fuses them by concatenation, which can blur the distinction between the target speaker’s own speech and the partner’s speech. MindFlow instead keeps the audio streams unmixed and interleaves them into a source-independent acoustic context $A_{\text{ctx}}$.
The Dorsal module then performs attention-based injection from motion queries to this acoustic context:
$$F_{\text{inject}} = \operatorname{Attn}(H_m, A_{\text{ctx}}, A_{\text{ctx}}) = \operatorname{Softmax}\left(\frac{Q_m K_{\text{ctx}}^\top}{\sqrt{d}}\right) V_{\text{ctx}}$$
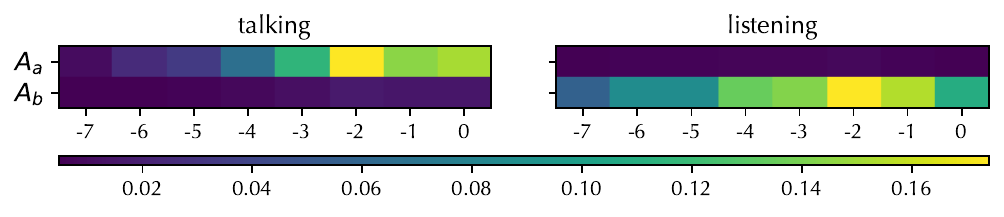
This is called the Selective Acoustic Injector. Its purpose is to learn an adaptive gating policy: during speech, it tends to focus on the target speaker’s own audio for lip synchronization; during listening, it shifts toward the partner’s audio to trigger reactive expressions. Importantly, the paper states that this gating behavior is not manually supervised with speaker labels; it emerges from optimization under the flow-matching loss.
The backbone stacks the Stylistic Temporal Modulator and the Selective Acoustic Injector in alternating blocks. The paper states that the network uses $L = 6$ identical blocks. During training, teacher forcing is used: the model consumes ground-truth history $M_a^{<t}$ to predict the current motion conditioning vector $C_a^t$ from motion history, emotion state, and audio context:
$$C_a^t = \operatorname{Backbone}(M_{<t}, S_a^t, A_{\text{ctx}})$$
This conditioning vector is then passed to the generative head.
Instead of directly regressing motion, MindFlow uses a flow-matching objective. The motion generator learns a velocity field $v_\theta$ that transports samples from a standard Gaussian prior $\pi_0 = \mathcal{N}(0, I)$ to the data distribution $\pi_1$ along an ordinary differential equation:
$$dZ_\tau = v_\theta(Z_\tau, \tau \mid C)\, d\tau$$
The training loss is a mean-squared error between the predicted velocity and the straight-line displacement between noise and data samples:
$$\mathcal{L}_{\text{flow}} = \mathbb{E}_{\tau \sim \mathcal{U}[0,1],\, Z_0 \sim \pi_0,\, Z_1 \sim \pi_1} \left[ \lVert v_\theta(Z_\tau, \tau \mid C) - (Z_1 - Z_0) \rVert^2 \right]$$
The authors emphasize that this choice avoids iterative denoising at inference time. In practice, the ODE is solved with a 5-step Euler solver, enabling real-time operation while still producing diverse, expressive motion.
The Dorsal module is trained on a combined dataset of roughly 20 hours of public data. The paper uses:
The training schedule is two-stage: pretraining on HDTF and VICOX for 90k steps, followed by fine-tuning on MEAD and VICO for 30k steps. Total training time is about 4 days. Optimization uses Adam, batch size $64$, peak learning rate $10^{-5}$, cosine decay, $1\%$ warmup, and no weight decay. The audio encoder is frozen throughout.
Motion is represented with 51-dimensional ARKit blendshape coefficients for facial expressions and 3D Euler angles for head pose. These are extracted using MediaPipe and FSA-Net.
At inference time, the two modules run asynchronously. The Ventral module processes each 1.5 s chunk in approximately $1.38 \pm 0.10$ s, while the Dorsal module outputs motion at 25 FPS in real time. The paper reports that the system can sustain 2-minute sequences without memory growth and requires about 59 GB VRAM.
The supplementary material adds several practical details. For head pose, the authors found that directly predicting absolute Euler angles can lead to drift: the pose may gradually rotate to extreme values during autoregressive inference. To mitigate this, the model predicts angular velocity instead. For all frames except the first, the current pose is obtained by adding the predicted velocity to the previous pose; for the first frame, the module still predicts the absolute pose.
They also apply a historical perturbation during training to reduce over-reliance on past motion. Specifically, the input motion $M$ is noised as:
$$M^{\text{noised}} = (1 - \sigma)M + \sigma N$$
where $N$ is Gaussian noise and $\sigma$ is sampled from $[0.01, 0.05]$ during training and fixed to $0.02$ during inference. In addition, the cross-attention injection coefficient $\lambda_{\text{cross}}$ is increased to $2.5$ to strengthen the influence of audio on expression generation.
The paper evaluates both talking and listening generation. For motion realism it uses Fréchet Distance (FD). For talking-phase lip synchronization it uses SyncNet-based metrics: SyncD and SyncC. For listening-phase expression quality it uses FD and mean squared error (MSE). The authors adapt SyncNet from video evaluation to 3D motion by replacing the visual branch with MLP layers and training the adapted model on a high-quality 3D mocap talking dataset.
The experiments compare against both talking-head and dyadic listening methods. For talking, the paper compares with EmoTalk, UniTalker, DualTalk, and a retrained Audio2Photoreal baseline. For listening, it compares with L2L, RLHG, DIM, DualTalk, and Audio2Photoreal.
MindFlow reports state-of-the-art performance on both talking and listening metrics. The strongest gains appear in motion naturalness and expression quality, while lip synchronization also improves slightly over the best baseline.
On the HDTF test set, MindFlow achieves the best reported performance across all talking metrics. The largest gain is in facial expression realism, where FD for expressions drops to $15.76$, and head-pose realism also improves to $0.01$. SyncD improves modestly over Audio2Photoreal, while SyncC is slightly higher as well.
On the VICO test set, MindFlow again performs best overall. The listening results are especially important because the paper’s thesis is that conversation-aware animation must remain expressive even when the avatar is not talking. MindFlow’s semantic guidance and generative motion model are credited for reducing over-smoothed expressions and improving contextual fit.
The supplementary results show that MindFlow remains competitive in lip accuracy while producing the highest expression diversity among the compared methods, supporting the claim that flow matching improves variety without sacrificing synchronization.
The qualitative comparisons in the paper support the quantitative results. Against Dorsal-only baselines such as DualTalk and Audio2Photoreal, MindFlow is reported to produce smoother head movement across both speaking and listening phases, with better long-range emotional coherence. In contrast to fixed-length or sliding-window generation systems, its autoregressive flow-matching backbone is used to maintain stability across long sequences.
The paper also compares the proposed Chunk-State approach with the Sentence-Action paradigm used by CustomListener-style systems. The figure and discussion emphasize that MindFlow generates more appropriately timed reactions, such as a smile at the end of an utterance, whereas sentence-level action planning tends to produce static or delayed responses.
The authors also report a blind perception study with 24 collected evaluations, where participants chose the best result under naturalness and fitness criteria. The paper states that MindFlow consistently outperformed prior methods in this human study.
The ablations isolate the contribution of the Ventral module, the Selective Acoustic Injector, and the choice of chunk size and sampling steps. Overall, the ablations support the paper’s main thesis that semantic state, not just audio correlation, is required for good dyadic animation.
On the VICO test set, the authors compare the Ventral state used to guide the Dorsal module against three alternatives: random state, fixed sentence-level ground truth state, and a Sentence-Action variant. The reported numbers show that the evolving emotion state from the Ventral module performs best.
The paper’s interpretation is that the dynamic emotion trajectory is more useful than static or random guidance because it is temporally aligned with the ongoing conversation and better matches the ground-truth facial dynamics.
The Selective Acoustic Injector is tested by cross-ablations with Audio2Photoreal. The results show consistent improvement in lip synchronization when the injector is used, indicating that selective access to unmixed audio streams is beneficial for both architectures.
The paper notes that the bidirectional Audio2Photoreal variant still performs well, which is consistent with the general advantage of non-causal access, but the injector itself improves both systems. For MindFlow, removing the injector harms SyncC significantly, showing that the module is important not just for lip accuracy but also for better coordination between acoustic context and motion generation.
Chunk length trades off emotion-state granularity and stability. The user study reported in the paper shows that increasing chunk size improves emotion prediction accuracy because more temporal context is available, but it reduces perceived synchronicity. The authors therefore choose $1.5$ seconds as the default chunk size.
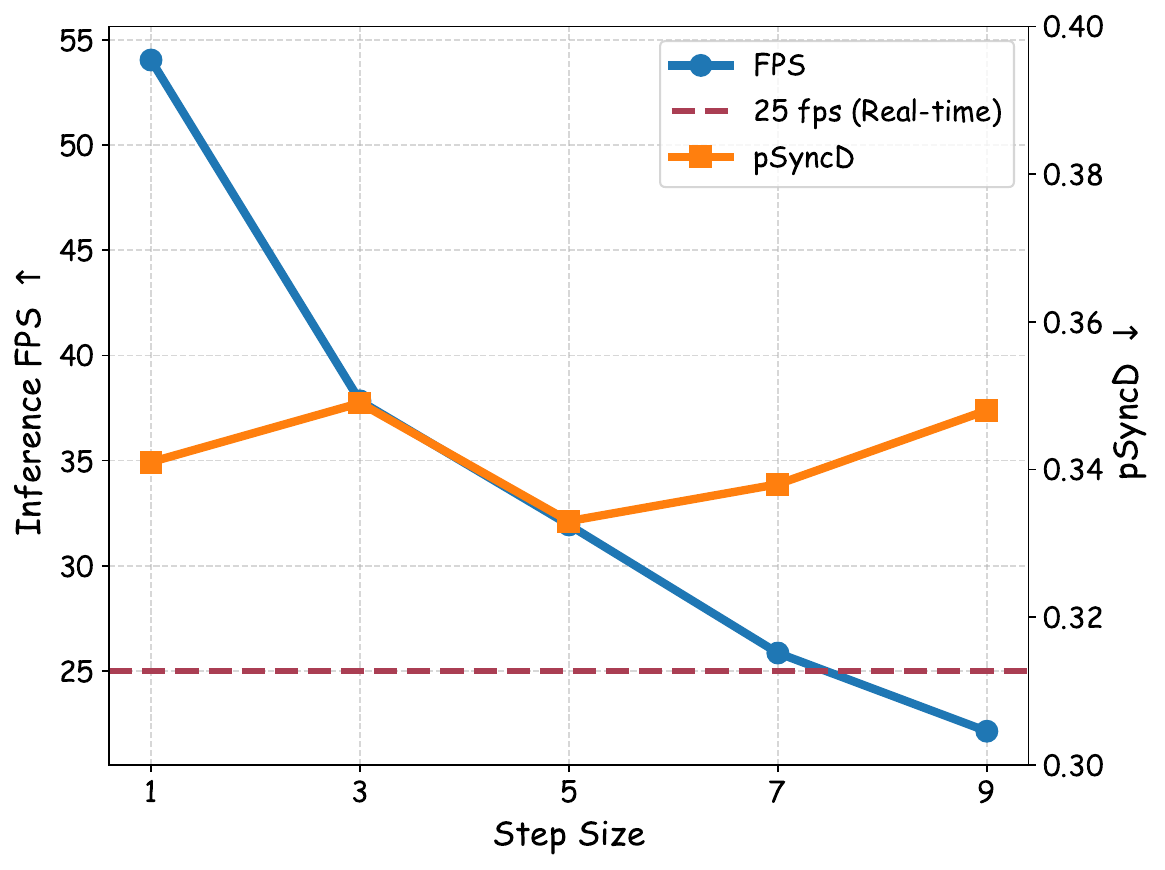
The authors also vary the number of ODE sampling steps for the flow-matching solver. The relationship between step count and lip synchronization is reported as non-monotonic. At low step counts, discretization error dominates; at higher step counts, accumulated prediction errors can introduce jitter and degrade SyncNet scores. The best trade-off is obtained at 5 steps, which is the setting adopted in the final system.
The main stated limitation is modality coverage. MindFlow currently relies only on audio to infer emotion and semantics. The authors explicitly note that natural face-to-face conversation also depends on visual cues such as eye contact, facial expression, and body language. As a result, audio-only inference may miss silent but meaningful non-verbal signals.
Their stated future direction is to extend the framework to multimodal sensory inputs, especially by integrating visual cues alongside raw audio so that the model can obtain a more holistic contextual understanding and generate more empathetic and accurate reactions.
MindFlow’s core contribution is a streaming, dual-pathway facial animation framework that separates semantic state tracking from reflexive motion generation. The Ventral module performs chunk-level emotional reasoning with a Chain-of-State memory, while the Dorsal module uses a Selective Acoustic Injector plus flow matching to produce high-fidelity motion in real time. The reported results support the paper’s claims that this design improves semantic appropriateness, motion naturalness, and temporal continuity over prior dyadic conversation baselines.
3. Overall Architecture
3.1 Why Chunk-State instead of Sentence-Action?
4. Ventral Module: Streaming Cognitive State Modeling
5. Dorsal Module: Reflexive Motion Generation
5.1 Stylistic Temporal Modulator
5.2 Selective Acoustic Injector
5.3 Autoregressive Transformer Backbone
5.4 Flow Matching Head
6. Training and Implementation Details
6.1 Supplementary implementation refinements

7. Evaluation Protocol
8. Main Results
8.1 Talking-state results
Method
SyncD ↓
SyncC ↑
FD Exp ↓
FD Pose ↓
EmoTalk 0.429 0.412 23.52 — UniTalker 0.480 0.300 29.88 — DualTalk 0.467 0.346 26.06 0.18 Audio2Photoreal 0.341 0.519 17.64 0.03 MindFlow 0.333 0.520 15.76 0.01 8.2 Listening-state results
Method
FD Exp ↓
FD Pose ↓
MSE Exp ↓
MSE Pose ↓
L2L 33.93 0.06 0.93 0.01 RLHG 39.02 0.07 0.86 0.01 DIM 23.88 0.06 0.70 0.01 DualTalk 22.27 0.05 0.58 0.01 Audio2Photoreal 14.24 0.03 0.34 0.01 MindFlow 13.86 0.03 0.30 0.01 8.3 Additional evaluation on HDTF
Method
LVE ↓
Diversity × $10^{-2}$ ↑
EmoTalk 6.212 5.558 UniTalker 7.866 2.242 Audio2Photoreal 9.676 21.332 DualTalk 8.806 2.074 MindFlow 6.305 24.197 
9. Qualitative Analysis
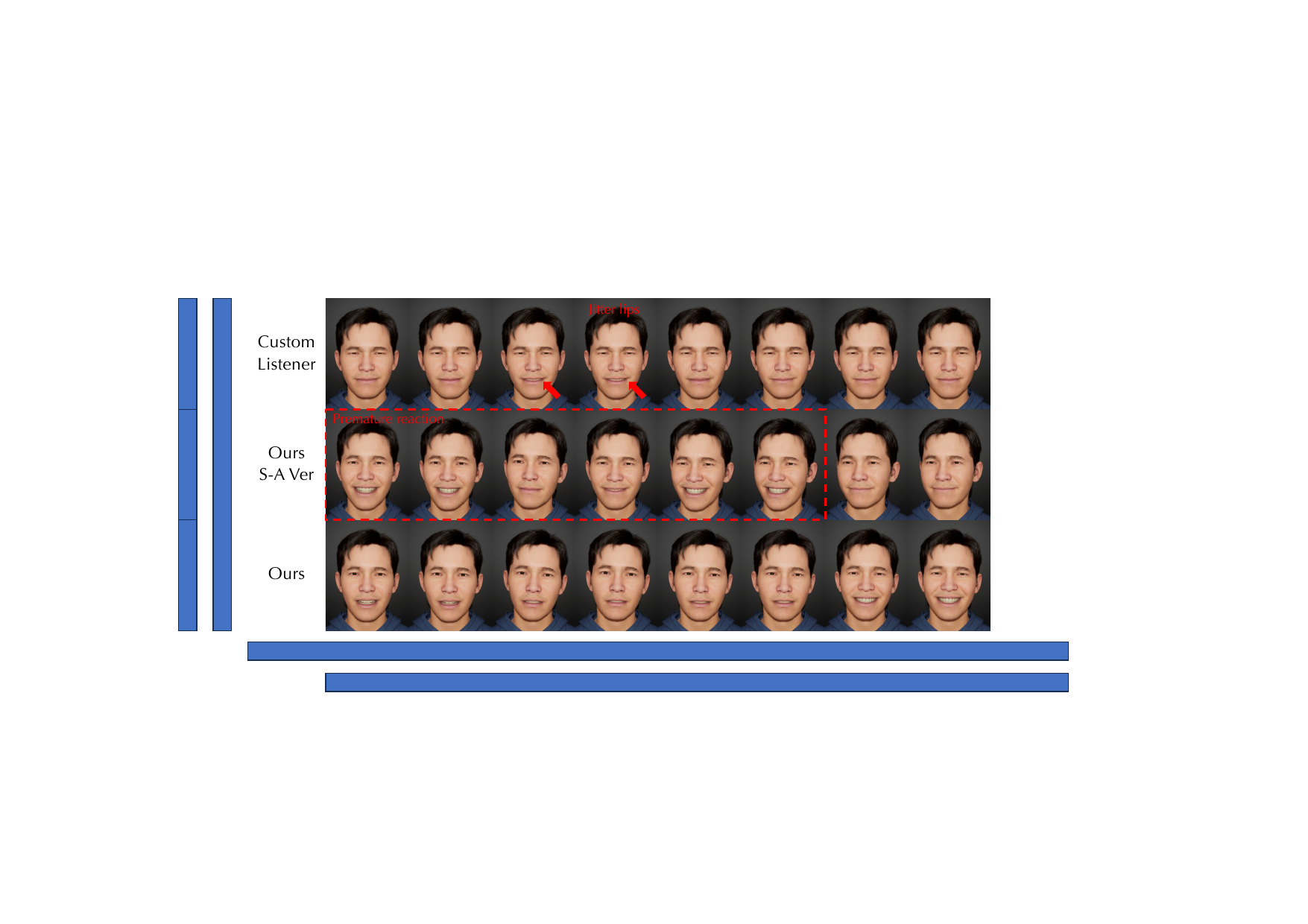
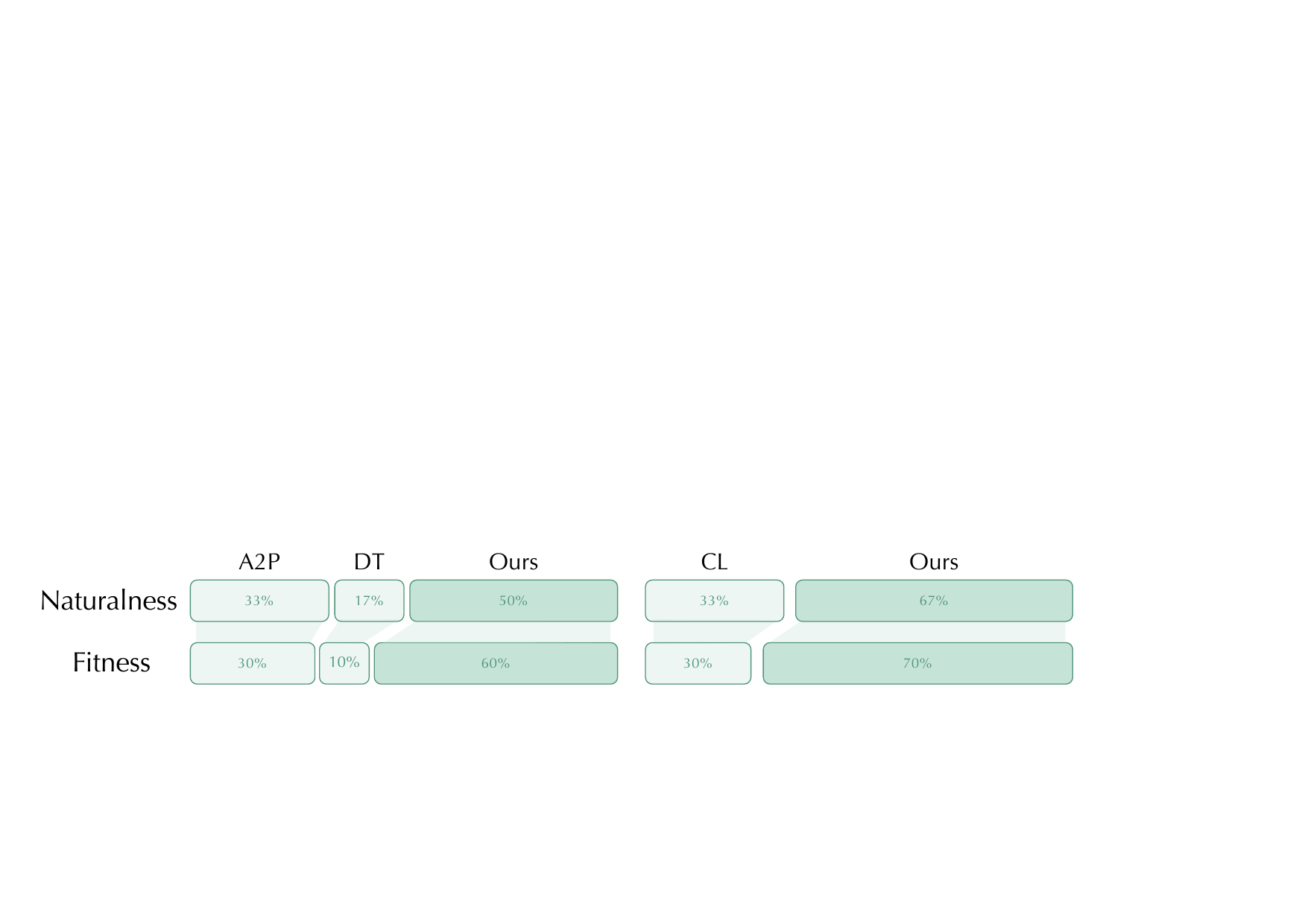
10. Ablation Studies
10.1 Ventral guidance and Chunk-State
Method
FD Exp ↓
FD Pose ↓
MSE Exp ↓
MSE Pose ↓
Random 15.21 0.03 0.36 0.01 Fixed 14.15 0.03 0.32 0.01 Sentence-Action variant 14.39 0.03 0.33 0.01 MindFlow 13.86 0.03 0.30 0.01 10.2 Selective Acoustic Injector
Method
Injector
SyncD ↓
SyncC ↑
Audio2Photoreal w/o 0.341 0.519 Audio2Photoreal w/ 0.331 0.526 MindFlow w/o 0.350 0.424 MindFlow w/ 0.333 0.520 10.3 Chunk size
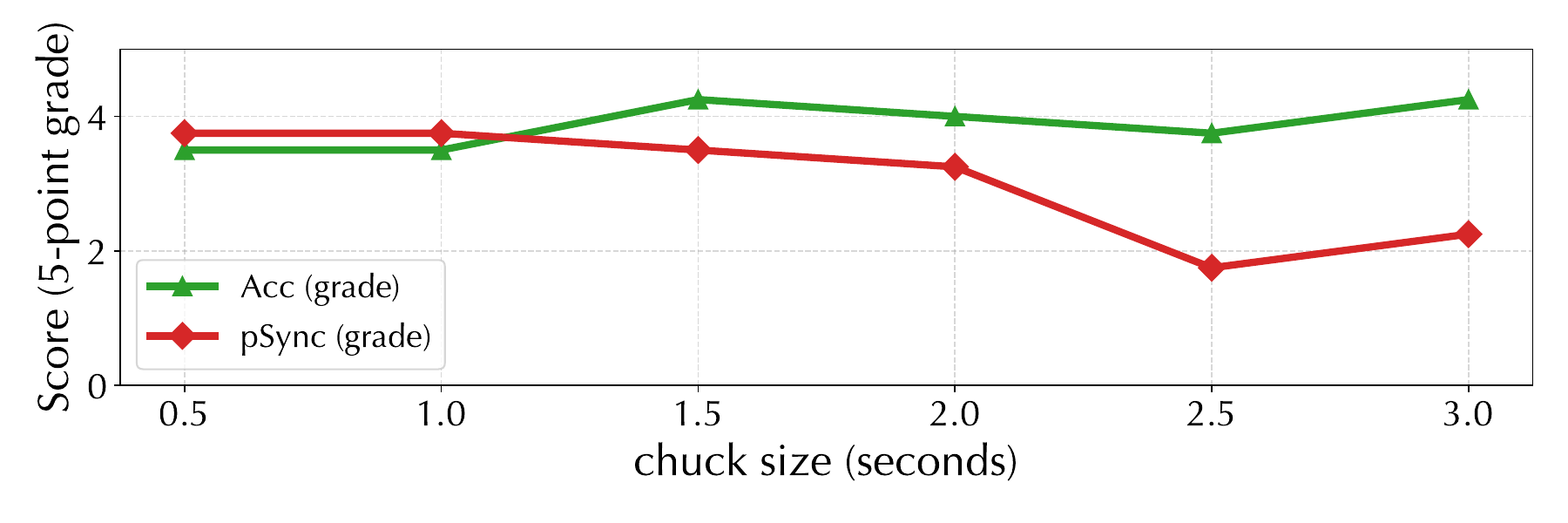
10.4 Sampling steps
11. Reported Limitations and Future Work
12. Conclusion