EMOSH
EMOSH: Expressive Motion and Shape Disentanglement for Human Animation

EMOSH presents a new Expressive Human Model that separates body shape from motion for high-fidelity human animation. It prevents shape leakage common in 2D pose methods while capturing detailed facial and gesture motions, enabling expressive, identity-consistent video generation with stable long-term performance.
Demos
The demos highlight EMOSH's strength in generating high-fidelity, expressive human animations with clear disentanglement of motion and body shape. Observe the natural facial expressions and intricate gestures in self-driven dance and cross-driven scenarios retaining identity consistency. The mesh visualization demo reveals the underlying EHM control and precise motion tracking, showcasing fine-grained control over motion and shape.

Links
Paper & demos
Abstract
High-fidelity and expressive controllable human animation is essential for content creation and digital avatar applications. However, existing methods face a dilemma between expressiveness and disentanglement. Mainstream 2D pose-conditioned approaches suffer from "motion-shape entanglement", leading to the leakage of the driving subject's body shape. Conversely, methods relying on 3D priors (e.g., SMPL) achieve geometric disentanglement but struggle to capture facial expressions and complex gestures, resulting in rigid animations. To this end, we propose EMOSH, a novel framework for high-fidelity controllable human video generation. First, an Expressive Human Model (EHM) is introduced as the core control representation. By explicitly disentangling shape and pose parameters, we fundamentally resolve the body shape leakage issue. Alongside this, a robust motion tracker is designed to accurately estimate EHM parameters from video. Second, we propose a Coarse-to-Fine Hybrid Motion Injection strategy, enabling more fine-grained control over expressions and gestures. Furthermore, we introduce a Spatially-Aligned Conditioning mechanism to bridge the domain gap between training and inference, improving identity consistency. Extensive experiments demonstrate that EMOSH outperforms previous methods in both self-driven and cross-driven scenarios, producing high-fidelity videos with vivid expressions while maintaining shape disentanglement.
1. Problem Setting and Core Idea
EMOSH addresses controllable human video generation from a reference image and a driving video. The paper targets the central trade-off in current human animation systems: methods based on 2D pose control often preserve motion detail but leak the driving subject's body shape, while methods built on 3D priors can disentangle geometry but tend to lose facial micro-expressions and complex hand gestures.
The proposed solution combines three ideas: (1) an Expressive Human Model (EHM) as a control representation that explicitly separates body shape from pose; (2) a confidence-aware motion tracker that estimates EHM parameters robustly from monocular video; and (3) a coarse-to-fine hybrid motion injection scheme plus spatially-aligned conditioning to improve motion fidelity, identity consistency, and long-video stability.

The paper positions EMOSH as a mesh-guided alternative that aims to keep the fine-grained expressiveness of pose-driven diffusion systems while removing their strongest failure mode: motion-shape entanglement. In the authors' framing, the goal is not only to reproduce the driving motion, but to do so while anchoring the generated body shape to the reference subject.
2. Related-Work Context and Motivation
The method is built against three families of prior work discussed in the paper. Early GAN and warping-based animation systems struggled with large motions and occlusions. Diffusion-model based methods improved synthesis quality and became the dominant paradigm. Within diffusion-based human animation, 2D pose-conditioned systems such as ControlNet-style approaches, Animate Anyone, UniAnimate, StableAnimator, MimicMotion, HyperMotion, and Wan-Animate improved controllability and realism, but typically encode the driving subject's pose in 2D skeletons, which implicitly leak body proportions.
The other direction uses 3D priors such as SMPL or mesh-based control to gain geometric disentanglement, but standard body models are too coarse for facial motion, gaze, and finger articulation. EMOSH extends this line by using EHM, which integrates a body model with face modeling so that facial expressions and body pose are available in a unified parameterization.
3. Method Overview
EMOSH is implemented on top of Wan2.1-I2V as the generation backbone. The paper describes Wan2.1-I2V as a DiT-based image-to-video model that uses a 3D causal VAE to compress video into spatiotemporal latents, then injects image and text semantics via cross-attention. EMOSH augments this backbone with motion features rendered from EHM and with conditioning strategies aimed at stable long-video generation.
The overall pipeline is: estimate EHM parameters from the driving video and reference image, retarget the driving motion to the reference identity, render the retargeted mesh into a hybrid conditioning map, encode that map into motion latents, and inject those motion latents into the DiT denoiser together with explicit reference-video conditioning.
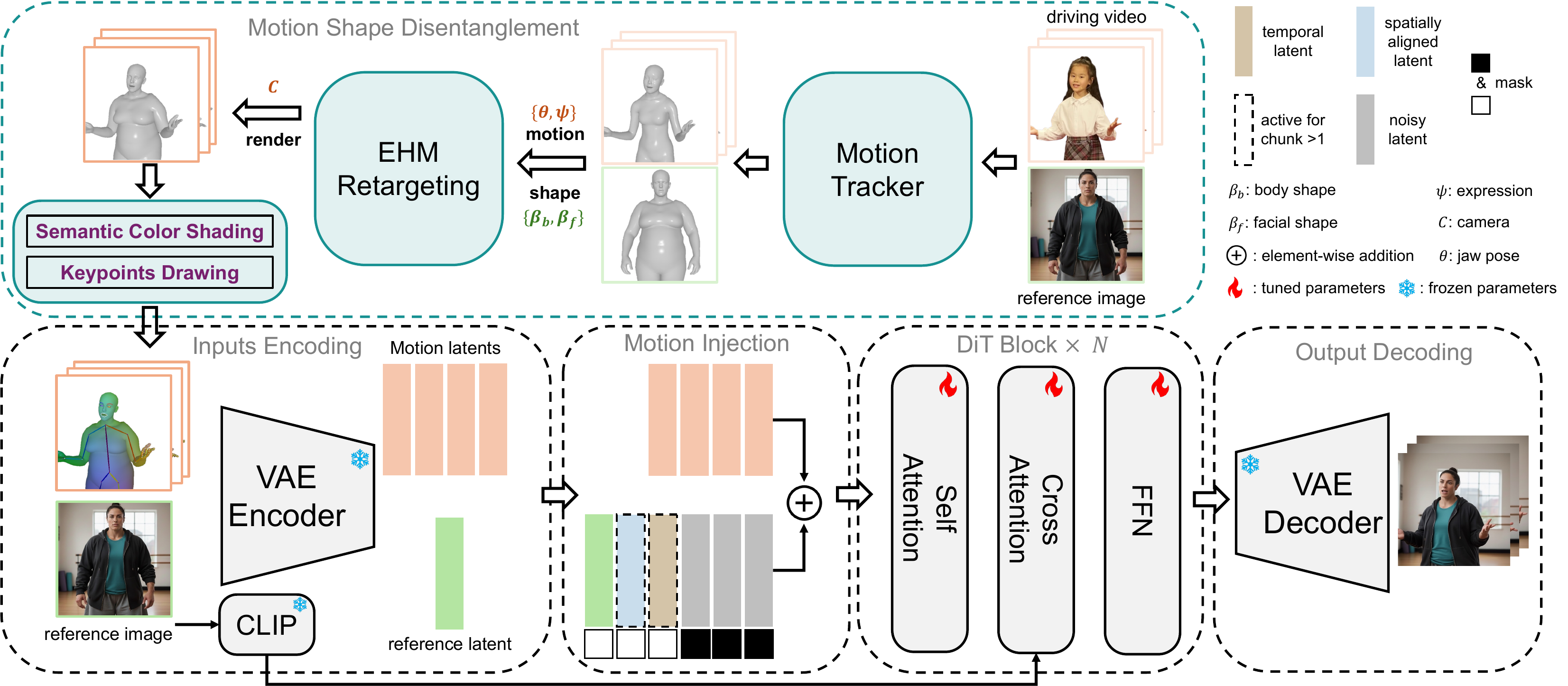
3.1 Expressive Human Model as the Control Representation
The paper's key representation is the Expressive Human Model (EHM), which is described as a mesh-based parametric model that combines SMPL-X with FLAME. Compared with standard SMPL-X, EHM explicitly separates body shape and head shape, and also carries expression parameters for facial dynamics.
In the notation used by the paper, EHM is parameterized by body shape $\beta_b$, head shape $\beta_f$, expression $\psi$, and pose $\theta$. The resulting mesh is written as $$V = M_{\text{ehm}}(\beta_b, \beta_f, \psi, \theta),$$ where $V$ is the deformed vertex set. This explicit factorization is the mechanism that enables shape-disentangled motion retargeting.
EMOSH uses the EHM to avoid inheriting the driving subject's physique. At inference time, the system retains the driver's pose and expression while replacing the shape parameters with those extracted from the reference image.
3.2 Confidence-Aware Motion Tracker
The motion tracker is a critical upstream module. The paper emphasizes that existing tracking pipelines are inefficient and brittle under side views, back views, and occlusions. EMOSH therefore proposes a unified joint optimization procedure rather than a cascaded body-then-face pipeline.
The tracker operates in two stages. First, it performs coarse initialization using off-the-shelf estimators. Then it jointly refines body pose, hand pose, face pose/expression, shape, and camera parameters using differentiable rendering and keypoint supervision.
The coarse initialization uses DWPose for body keypoints, MediaPipe for dense facial landmarks, GVHMR for full-body pose and camera priors, HaMeR for hands, and TEASER for head/face initialization. The detailed optimization also uses a confidence-aware validity gating mechanism.
The optimization objective is written as $$\mathcal{L}_{\text{ehm}} = \lambda_{\text{kpt}}\mathcal{L}_{\text{kpt}} + \lambda_{3d}\mathcal{L}_{\text{hand}}^{3D} + \lambda_{\text{reg}}\mathcal{L}_{\text{reg}} + \lambda_{\text{smooth}}\mathcal{L}_{\text{smooth}}.$$ The individual terms combine 2D reprojection, 3D hand alignment, parameter regularization, and temporal smoothness.
The paper's confidence-aware logic matters because noisy 2D detections can destabilize optimization. For face tracking, the loss is masked when the head is rotated beyond a threshold or the face is effectively invisible. For hands, the method checks both detection confidence and whether the projected hand bounding box is meaningfully inside the image, then falls back to stronger 3D priors when the hand is invalid or occluded.
The 2D reprojection loss is based on perspective projection of 3D keypoints onto the image plane. For hands, the model adds a 3D vertex alignment loss with a much larger weight on the depth coordinate, using a factor of $\lambda_z = 10$ for the $z$ axis.
The regularization term keeps pose and shape in a biologically plausible range, including a truncation-style penalty on extreme expressions. The temporal smoothness loss penalizes frame-to-frame changes in camera, pose, vertex positions, and expression, which helps suppress jitter from framewise trackers.
3.3 Coarse-to-Fine Hybrid Motion Injection
After EHM tracking and retargeting, EMOSH builds a hybrid motion condition map. The first component is a semantic color rendering of the EHM mesh: canonical-t-pose vertex coordinates are mapped to fixed RGB values, then rendered with a differentiable renderer to create a dense 2D control image. This provides global, coarse geometric information.
Because pure mesh renderings are low-frequency and can miss subtle actions such as blinking or mouth closures, EMOSH adds sparse 2D keypoints on top of the rendered condition map. The resulting condition map is then encoded by a VAE and a lightweight embedding layer, and the extracted motion features are injected additively into the noisy video latent.
The paper frames this as a coarse-to-fine strategy: the mesh rendering gives spatial structure, while drawn keypoints recover high-frequency details in the face and hands. This combination is central to the claim that EMOSH can achieve mesh-based shape disentanglement without sacrificing expressiveness.
3.4 Identity Injection and Motion-Shape Disentanglement
EMOSH follows Wan2.1-I2V's explicit latent conditioning for appearance preservation. The reference image is VAE-encoded and temporally concatenated with the noisy target latents, with a binary mask indicating the reference-frame positions. This establishes the visual context that anchors the generated person identity.
For motion-shape disentanglement, EMOSH constructs a retargeted target mesh by preserving driving-video pose and expression while replacing the body and head shape parameters with those extracted from the reference image: $$M_{\text{ehm}}^{\text{target}} = M_{\text{ehm}}(\theta^d, \psi^d, \beta_b^r, \beta_f^r).$$ The driving camera is still used for rendering. This is the paper's direct response to body-shape leakage in 2D pose-conditioned systems.
The supplementary material adds one practical detail: when replacing shape parameters changes overall body length, the authors compensate by applying a global vertical offset so that the face stays properly framed under the original camera.
3.5 Spatially-Aligned Conditioning for Long Videos
A second major contribution is the Spatially-Aligned Conditioning mechanism. The paper argues that training and inference differ spatially: during training, reference and target frames come from the same video and are well aligned, but in cross-identity inference the reference image and driving motion are spatially misaligned. Without a remedy, autoregressive generation can over-trust temporally propagated latents and gradually drift in appearance.
EMOSH addresses this by keeping the latent of the first generated frame of the previous chunk and inserting it between the reference latent and the subsequent temporal latents for later chunks. This latent acts as a bridge between identity and the current scene layout. The paper also keeps the original reference latent as a visual anchor at the beginning of every chunk.
For long-video inference, the system generates clips chunk by chunk using overlapping frames; the last five frames of the previous chunk are encoded and reused as temporal context for the next chunk. During training, the model is exposed to analogous conditions by randomly toggling temporal latents, applying geometric augmentations to the reference image, and sometimes injecting an auxiliary reference latent so the train-test behavior is less mismatched.
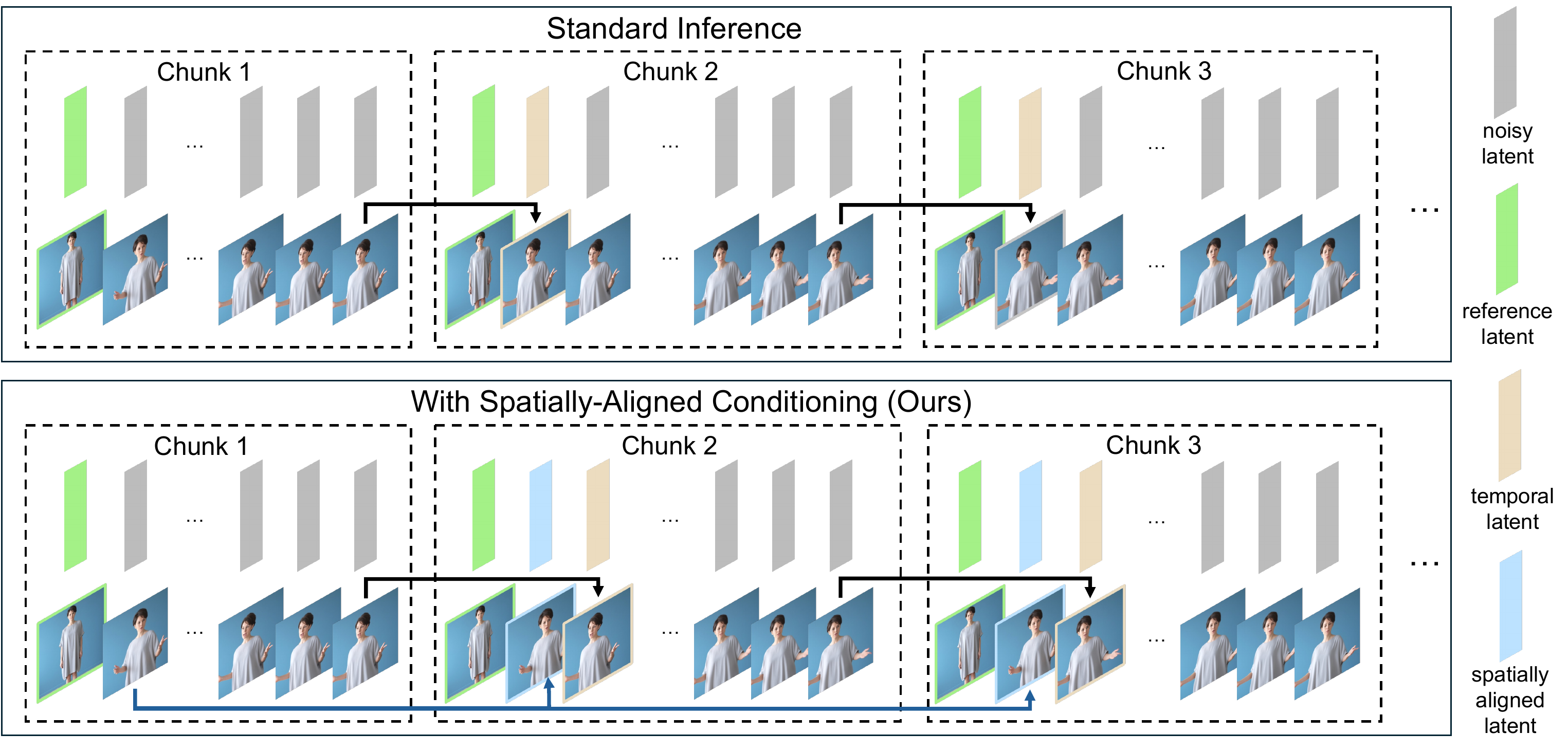
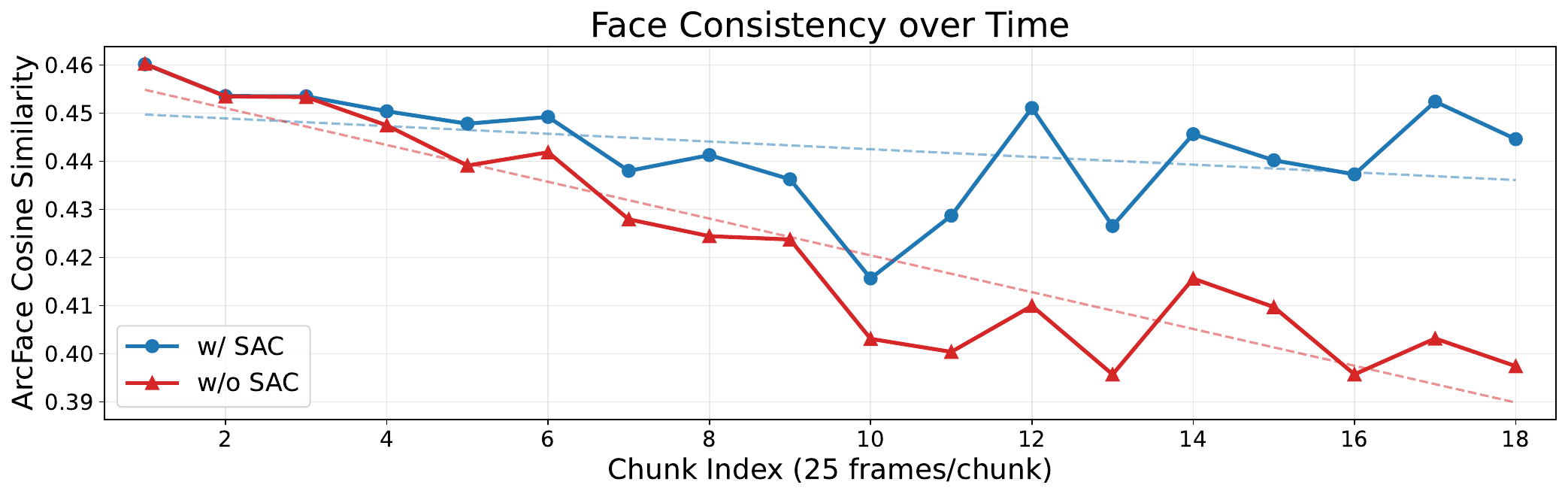
The supplementary experiments show that the gap between the full model and the version without SAC widens over time, supporting the claim that the spatially aligned latent helps suppress cumulative drift in long videos.
4. Training Objective and Implementation Details
EMOSH is trained using the Flow Matching formulation on the DiT latent space. The paper writes the latent evolution as an ODE: $$\frac{d z_t}{d t} = v(z_t, t, c),$$ where $c$ denotes conditioning information. Training uses an Optimal Transport path, linearly interpolating between data latent $z_0$ and Gaussian noise $z_1 \sim \mathcal{N}(0, I)$: $$z_t = (1 - t) z_0 + t z_1,$$ and regresses the predicted velocity to the target velocity $z_1 - z_0$ via a squared error objective.
Implementation-wise, the system is trained in PyTorch with Adam. The main paper reports training on 32 NVIDIA H20 GPUs with a global batch size of 32, about 100 hours of training, and roughly 6,500 iterations to convergence. Training clips are 77 frames long at resolution $512 \times 512$.
The backbone is a DiT architecture aligned with Wan2.1-I2V, and the model initializes its DiT module from Wan-Animate weights to leverage a strong human-video prior. In the supplementary details, the authors state that only the DiT module is updated using LoRA with rank 32 and learning rate $10^{-4}$, while a dedicated motion embedding layer projects the 16-dimensional VAE motion features to the DiT's 5120-dimensional input space.
The training dataset is a composite of about 900k clips: 37.8% internet-crawled human motion videos, 60.6% from Speaker-Vid, and 1.6% from VFHQ. The dataset is filtered to remove clips with undetected faces, insufficient face scale, low hand visibility, or static subjects.
Additional training details from the supplement: temporal latents are used in 50% of iterations, the reference image is geometrically augmented with 50% probability, and an auxiliary reference latent is injected with 10% probability when temporal reference latents are enabled. Reference latents are excluded from the loss, and motion information is only injected into latents after the reference frame.
5. Experimental Setup
The paper evaluates EMOSH in two settings:
- Self-driven: the reference image comes from the same video as the driving source, so the model is tested as a reconstruction-style animator. The evaluation uses EchoMimicV2, TikTok, and a self-collected test set of 150 videos, totaling about 55k frames. Metrics are PSNR, L1, SSIM, and LPIPS.
- Cross-driven: 12 reference images and 10 driving videos are cross-paired to form 120 samples, about 51k frames. Since there is no ground truth, the paper reports human evaluation and an Identity Preservation Score (IPS) based on ArcFace cosine similarity.
The baseline set includes Moore-AA, StableAnimator, MimicMotion, UniAnimate, UniAnimate-DiT, HyperMotion, Wan-Animate, and Champ. For fair comparison, all methods are evaluated on a unified square resolution, with padding and cropping used to normalize outputs from different native aspect ratios.
5.1 Self-Driven Quantitative Results
EMOSH achieves the best numbers on all three self-driven datasets, indicating that the method preserves both appearance and motion more accurately than the baselines. The strongest pose-based competitor in this table is often Wan-Animate or HyperMotion, but EMOSH still improves on both reconstruction quality and perceptual similarity.
| Method | EchoMimicV2 | TikTok | Self-collected | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR ↑ | L1 ↓ | SSIM ↑ | LPIPS ↓ | PSNR ↑ | L1 ↓ | SSIM ↑ | LPIPS ↓ | PSNR ↑ | L1 ↓ | SSIM ↑ | LPIPS ↓ | |
| Moore-AA | 20.39 | 0.0513 | 0.7388 | 0.2059 | 16.23 | 0.1022 | 0.6742 | 0.3263 | 18.11 | 0.0762 | 0.6464 | 0.2788 |
| StableAnimator | 16.76 | 0.0796 | 0.6724 | 0.2836 | 11.76 | 0.1845 | 0.5732 | 0.4437 | 15.97 | 0.1024 | 0.6179 | 0.3285 |
| MimicMotion | 19.52 | 0.0622 | 0.7211 | 0.2450 | 14.17 | 0.1335 | 0.3876 | 0.6316 | 16.00 | 0.1057 | 0.6179 | 0.3552 |
| UniAnimate | 16.39 | 0.1045 | 0.6933 | 0.2678 | 11.73 | 0.1939 | 0.6096 | 0.4320 | 14.69 | 0.1286 | 0.6048 | 0.3543 |
| UniAnimate-DiT | 17.90 | 0.0678 | 0.7266 | 0.2533 | 12.79 | 0.1571 | 0.6151 | 0.4213 | 14.76 | 0.1302 | 0.5778 | 0.3688 |
| HyperMotion | 22.32 | 0.0391 | 0.7975 | 0.1800 | 15.48 | 0.1154 | 0.6529 | 0.3536 | 19.48 | 0.0660 | 0.7082 | 0.2512 |
| Wan-Animate | 22.86 | 0.0379 | 0.7750 | 0.1802 | 17.18 | 0.0932 | 0.6808 | 0.3209 | 20.72 | 0.0555 | 0.7281 | 0.2229 |
| Champ | 17.40 | 0.0756 | 0.6502 | 0.2911 | 13.34 | 0.1482 | 0.5902 | 0.4156 | 14.85 | 0.1159 | 0.5602 | 0.3727 |
| EMOSH | 23.66 | 0.0308 | 0.8240 | 0.1428 | 17.80 | 0.0831 | 0.7400 | 0.2933 | 21.18 | 0.0522 | 0.7510 | 0.2066 |
5.2 Cross-Driven Identity Preservation
Under cross-identity driving, EMOSH reports the best IPS among all compared methods, indicating stronger facial identity preservation. This is especially notable because cross-driven settings are where shape leakage and appearance drift are typically most visible.
| Method | Moore-AA | Champ | StableAnimator | MimicMotion | UniAnimate | UniAnimate-DiT | HyperMotion | Wan-Animate | EMOSH |
|---|---|---|---|---|---|---|---|---|---|
| IPS ↑ | 0.2174 | 0.2619 | 0.0935 | 0.0744 | 0.1618 | 0.3130 | 0.2872 | 0.3802 | 0.4445 |
The human study uses the GSB protocol on pairwise comparisons with 20 participants and reports a strong preference for EMOSH over Wan-Animate, HyperMotion, and UniAnimate-DiT.
| Comparison | Ours win | Same | Competitor win |
|---|---|---|---|
| Ours vs Wan-Animate | 89.21% | 3.96% | 6.83% |
| Ours vs HyperMotion | 98.42% | 0.75% | 0.83% |
| Ours vs UniAnimate-DiT | 95.62% | 1.80% | 2.58% |
5.3 Qualitative Findings
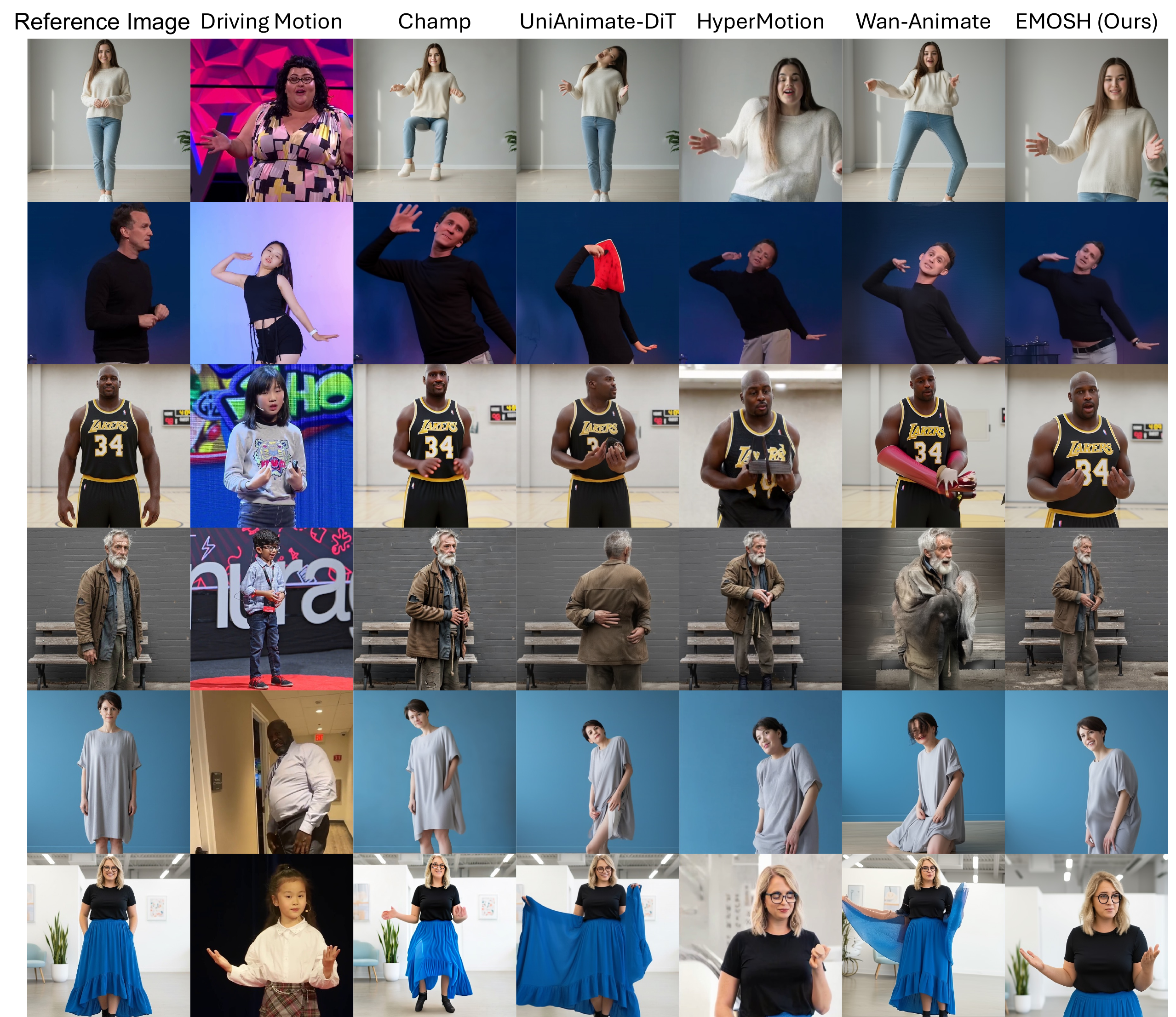
In the self-driven comparisons, the paper emphasizes that many baselines can keep rough identity but struggle with fingers, mouth shapes, and subtle facial motion. Mesh-only methods such as Champ are limited in fine-grained expression control, while 2D-pose methods can produce blurry or merged finger artifacts or fail on complex gestures. EMOSH is reported to achieve more accurate facial expression transfer and hand motion while keeping higher visual fidelity.

In cross-driven settings, the paper highlights that some baselines distort body proportions, over-thin or over-widen the reference subject, or keep an unnatural fixed body scale despite camera changes. EMOSH is reported to preserve body shape while following pose, expression, and camera framing more faithfully.
6. Ablations
The ablation study isolates the core contributions: the motion tracker, the hybrid motion injection, the motion-shape disentanglement step, and spatially aligned conditioning. The reported results show that each component contributes measurably to the final performance.
| Variant | EchoMimicV2 | Self-collected | ||||||
|---|---|---|---|---|---|---|---|---|
| PSNR ↑ | L1 ↓ | SSIM ↑ | LPIPS ↓ | PSNR ↑ | L1 ↓ | SSIM ↑ | LPIPS ↓ | |
| w/o Tracker | 20.51 | 0.0434 | 0.7789 | 0.1909 | 16.48 | 0.0959 | 0.7095 | 0.3300 |
| w/o Hybrid Motion | 22.90 | 0.0345 | 0.8127 | 0.1492 | 17.55 | 0.0850 | 0.7330 | 0.2973 |
| Full (Ours) | 23.66 | 0.0308 | 0.8240 | 0.1428 | 17.80 | 0.0831 | 0.7400 | 0.2933 |
| Variant | IPS ↑ |
|---|---|
| w/o Disentanglement | 0.4258 |
| w/o SAC | 0.4237 |
| Full (Ours) | 0.4445 |
The qualitative ablations reinforce the same conclusion: removing the tracker weakens facial and hand control; removing hybrid motion reduces the model's ability to handle blinking and fine gestures; removing disentanglement causes body-shape leakage; and removing SAC introduces artifacts and worsens identity preservation.


7. Supplementary Results
The supplementary material adds several technically relevant observations. First, it reports a body-shape consistency evaluation using GVHMR-derived shape parameters from the reference image and generated video. EMOSH obtains a higher shape consistency score than the non-disentangled ablation and Wan-Animate.
| Method | Shape Consistency Score ↑ |
|---|---|
| EMOSH | 0.4483 |
| w/o Disentanglement | 0.3968 |
| Wan-Animate | 0.3560 |
Second, the paper compares tracker efficiency on a 436-frame video. EMOSH's tracker takes 223 seconds at 1.96 FPS, whereas the GUAVA tracker takes 424 seconds at 1.03 FPS, giving roughly a $1.9\times$ speedup.
Third, EMOSH demonstrates a zero-shot ability to follow simple zoom-in and zoom-out camera motions by changing the rendering camera distance, although it is not explicitly trained on dynamic camera trajectories. The authors note a key limitation here: the model does not reliably separate camera rotation from subject rotation when only mesh conditioning is used.


The supplementary also reports FID and FVD on EchoMimicV2, where EMOSH is best on both metrics among the compared methods.
| Metric | EMOSH | Wan-Animate | HyperMotion | UniAnimate-DiT |
|---|---|---|---|---|
| FID ↓ | 25.86 | 27.91 | 33.94 | 112.02 |
| FVD ↓ | 32.07 | 34.49 | 33.90 | 35.33 |
8. Limitations and Ethical Notes
The paper is explicit about several limitations. First, the current system is trained only at low resolution because of dataset quality constraints, which limits deployment for high-definition production. Second, inference is computationally expensive and can take several minutes for a short clip. Third, mesh-only conditioning cannot fully disentangle camera motion from human motion, especially for rotational trajectories.
The supplement adds two more technical limitations: different body proportions can make identical joint rotations correspond to slightly different end-effector positions, sometimes confusing gestures such as clapping versus crossed hands; and the generation quality is highly dependent on the accuracy of the upstream tracker, with mesh interpenetration or jitter propagating into the final video.
The authors also include an ethical warning: because the method can generate highly realistic cross-driven human videos with detailed expressions and gestures, it has clear dual-use risk for deepfakes, identity theft, fraud, and misinformation. They recommend informed consent, data-protection compliance, and future integration of watermarking and provenance tools.
9. Bottom-Line Technical Takeaway
EMOSH's main technical contribution is not a new diffusion backbone, but a better control representation and control pipeline for human animation. By combining EHM-based disentanglement, confidence-aware tracking, hybrid mesh-plus-keypoint motion injection, and spatially aligned long-video conditioning, the system aims to occupy the middle ground between rigid 3D-prior methods and expressive but shape-entangled 2D pose methods.
The reported results support that trade-off: EMOSH improves self-driven reconstruction metrics, achieves the best cross-driven IPS, and receives strong human preference, while the ablations and supplementary analyses tie these gains to the tracker, the hybrid motion representation, the disentanglement step, and SAC.