MARCUS-Avatar
Monocular Avatar Reconstruction via Cascaded Diffusion Priors and UV-Space Differentiable Shading
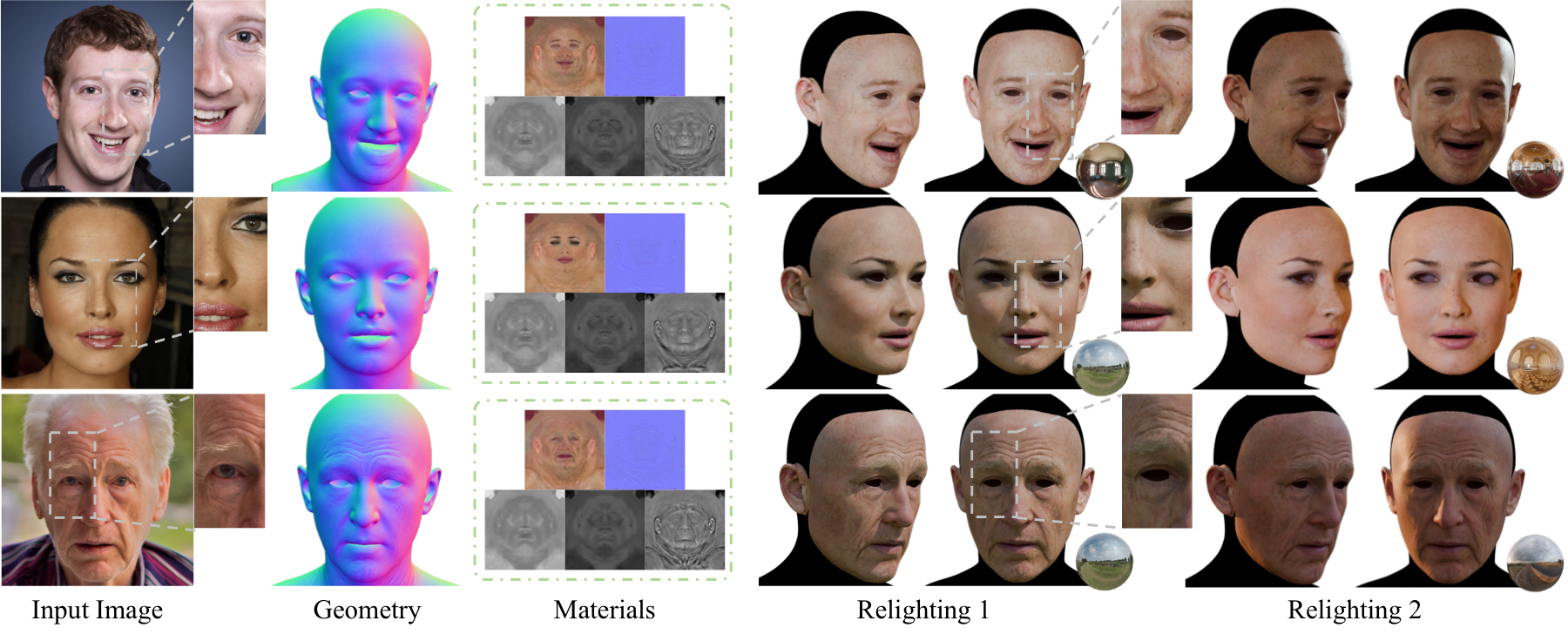
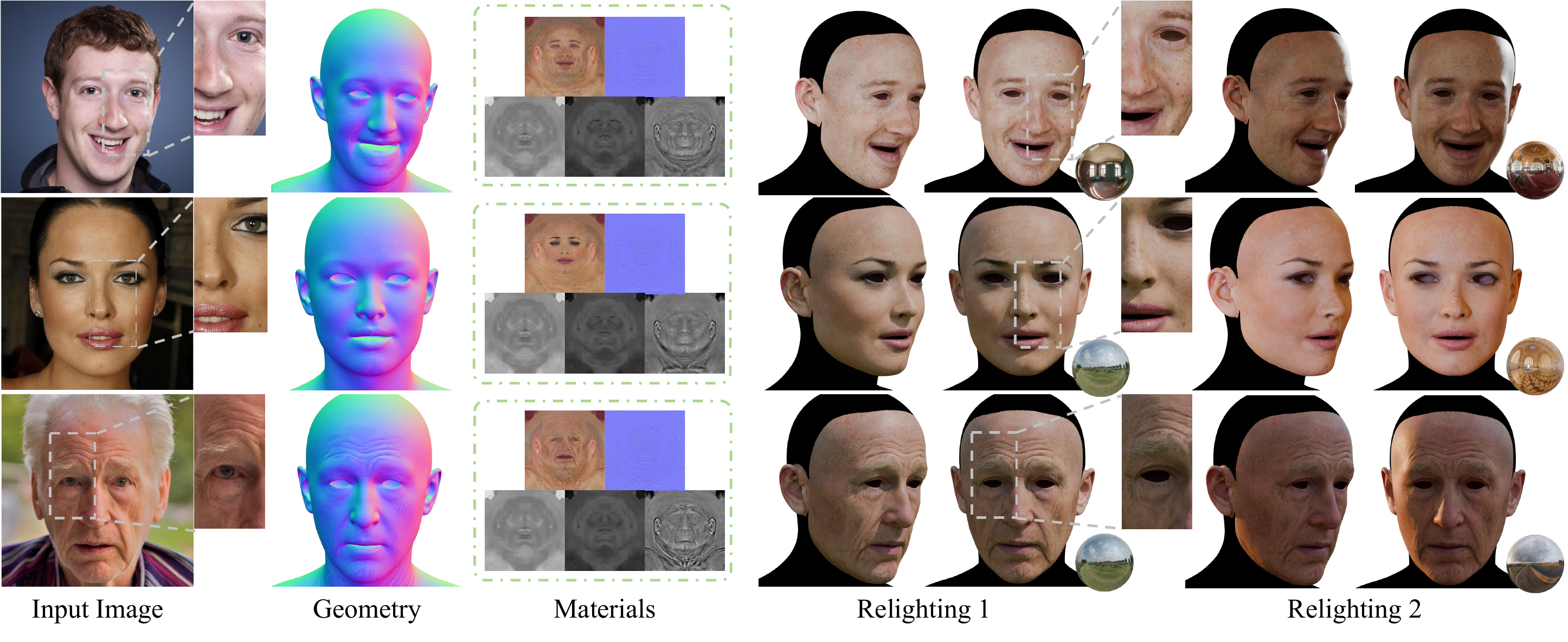
MARCUS-Avatar reconstructs high-quality, relightable 3D face avatars from a single image via cascaded diffusion priors in UV space. It integrates light normalization and differentiable shading to generate physically plausible PBR assets with detailed geometry and robust relighting, trained with limited real 3D scans.
Demos
These demos display MARCUS-Avatar's ability to build detailed, relightable 3D avatars from a single image. Key points to watch are the alignment between input and geometry, the fine geometric details, and realistic relighting results demonstrating intrinsic materials. The work uses cascaded diffusion priors and UV-space shading to yield high-fidelity avatars with detailed surface features and lighting effects.

Links
Paper & demos
Abstract
Reconstructing high-fidelity, relightable 3D avatars from a single in-the-wild image is a challenging ill-posed problem, primarily hindered by the scarcity of high-quality PBR data and the complexity of disentangling illumination from intrinsic materials. In this paper, we present a data-efficient framework that leverages the robust priors of a unified pre-trained diffusion backbone to sequentially address texture completion, delighting, and material decomposition. Unlike existing methods that rely on fragmented pipelines or extensive proprietary datasets, we utilize cascaded Low-Rank Adaptations (LoRAs) to adapt the strong generative prior of the diffusion model for each sub-task in UV space. Specifically, we first employ an Inpainting LoRA to complete missing UV textures caused by occlusion, leveraging the model's semantic understanding to generate semantically and photometrically coherent details. Subsequently, a Light-Homogenization LoRA and a novel Cross-Intrinsic Attention mechanism are introduced to remove baked-in lighting and collaboratively synthesize pixel-aligned PBR maps (Albedo, Normal, Roughness, Specular, and Displacement). To ensure physical plausibility, we impose a UV-space differentiable BRDF shading loss during the decomposition stage, forcing the generative process to adhere to the rendering equation without the artifacts typical of rasterization-based supervision. Extensive experiments demonstrate that our method, trained on fewer than 100 real 3D scans, generates comprehensive, 4K-resolution PBR assets with superior realism and generalization compared to state-of-the-art methods, and all training code and model weights will be released upon acceptance.
Introduction
This paper studies monocular reconstruction of relightable face/head avatars from a single in-the-wild image. The target output is not just a mesh or a colored UV texture, but a complete physically based rendering (PBR) asset: geometry plus intrinsic material maps that can be rendered under novel illumination. The core difficulty is the usual ill-posedness of single-view reconstruction, compounded by two practical constraints emphasized by the authors: high-quality PBR supervision is scarce, and existing methods often entangle illumination with intrinsic appearance, which makes the result unsuitable for relighting.
The paper's main idea is to use a shared pre-trained diffusion backbone as a strong generative prior, then adapt it with cascaded Low-Rank Adaptation (LoRA) modules for successive UV-space sub-tasks: (1) texture inpainting, (2) light homogenization, and (3) intrinsic material decomposition. The method is deliberately data-efficient: it is trained on fewer than 100 real 3D scans, plus large public in-the-wild face datasets and a Blender-based synthetic pipeline. The authors argue that this allows them to keep the base model's prior intact while still specializing it for avatar reconstruction.
A recurring design principle in the paper is to avoid direct screen-space rasterization supervision for material disentanglement. Instead, the authors perform the later stages entirely in UV space and introduce a UV-space differentiable GGX BRDF shader. This is used both as a physical constraint and as a training signal that ties predicted materials back to rendering, while reducing the tendency of 2D rasterization losses to bake occluders such as hair or glasses into the recovered texture.
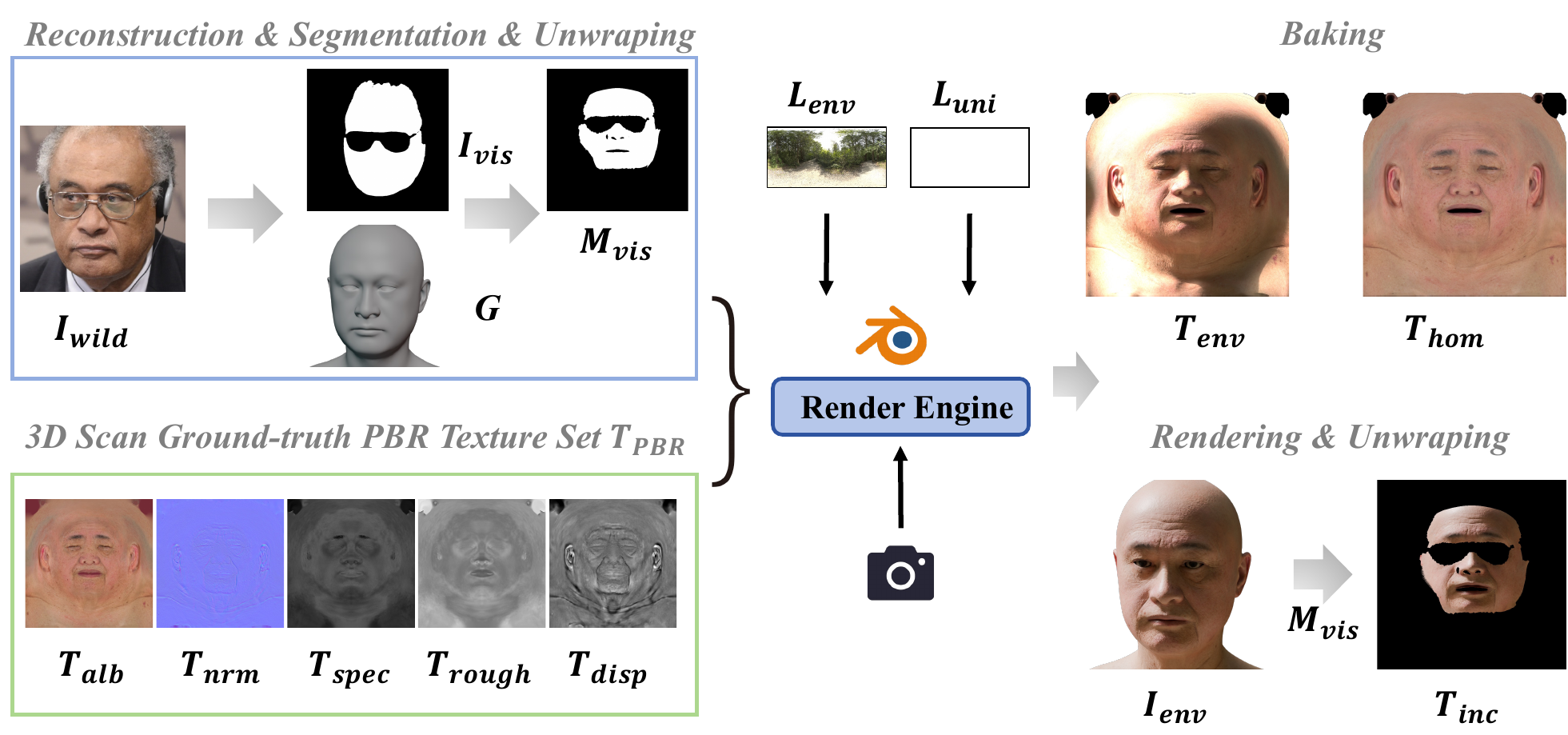
Problem Setup and Overall Pipeline
Given a single input image, the system first estimates facial geometry and camera pose, unwraps the input into UV space, and obtains an incomplete texture map. That map is then repaired and canonicalized, illumination is removed, and the resulting normalized texture is decomposed into material components. Finally, all maps are super-resolved to 4K.
The authors focus specifically on face and head PBR assets. They explicitly do not target full bodies, dynamic hair, clothing, or accessory-complete avatars. In the paper's framing, hair, glasses, and hands are often treated as occlusions that should be removed rather than modeled as persistent identity components.

Method
1. Geometry reconstruction with a multi-scale semantic encoder
Geometry is predicted with a standard parametric 3D face model, specifically the Hifi3D++ basis. The identity, expression, texture, lighting, and camera parameters are collected into $\chi = \{\boldsymbol{\alpha}, \boldsymbol{\delta}, \boldsymbol{\beta}, \boldsymbol{\gamma}, \boldsymbol{\phi}\}$, where identity has dimension 532, expression 45, texture 439, lighting 9, and pose is represented by the perspective camera parameters. The shape and texture are decoded as
$$ S(\boldsymbol{\alpha}, \boldsymbol{\delta}) = \bar{S} + \mathbf{B}_{id}\boldsymbol{\alpha} + \mathbf{B}_{exp}\boldsymbol{\delta}, \qquad T(\boldsymbol{\beta}) = \bar{T} + \mathbf{B}_{tex}\boldsymbol{\beta}. $$
A differentiable renderer then produces the reconstructed image. The key architectural contribution here is the Multi-Scale Space Fusion (MSSF) encoder, which combines a trainable ConvNeXt V2 backbone with a frozen DINOv3 branch. The ConvNeXt branch provides local, multi-scale detail, while DINOv3 injects strong semantic priors. The fusion is meant to improve geometry quality without abandoning the interpretability of the linear 3DMM decoder.
Training uses a self-supervised objective that combines photometric, landmark, perceptual, and regularization terms: $$ \mathcal{L} = \lambda_{pho}\mathcal{L}_{pho} + \lambda_{lan}\mathcal{L}_{lan} + \lambda_{per}\mathcal{L}_{per} + \lambda_{reg}\mathcal{L}_{reg}. $$ The photometric loss is weighted by a skin-attention mask to reduce the effect of occlusions. A particular detail the authors emphasize is their enhanced landmark loss: instead of a standard 68-point set, they use an 88-point hybrid configuration that mixes stable facial contour landmarks with robust mouth keypoints from MediaPipe, because they found the mouth region to be especially unstable under ordinary landmark detectors.
2. Texture inpainting and light homogenization in UV space
The texture pipeline operates on a shared pre-trained diffusion transformer that is adapted using task-specific LoRA modules. The backbone is frozen and only the LoRA parameters are optimized. This choice is important: the paper explicitly contrasts this with approaches that fully fine-tune diffusion models on small datasets and thereby lose the prior's generalization.
The first stage is texture inpainting. The incomplete UV texture is denoted $T_{inc}$. The model is trained using a flow-matching objective in latent space. For a noise level $\sigma \in (0,1)$,
$$ z_{\sigma} = (1-\sigma) z_0 + \sigma \epsilon, \qquad \epsilon \sim \mathcal{N}(0, \mathbf{I}), $$
and the loss is $$ \mathcal{L}_{FM} = \mathbb{E}_{\sigma,\epsilon}\left[\left\|f_{inp}(z_{\sigma}, T_{inc}, \sigma) - (\epsilon - z_0)\right\|_2^2\right]. $$ The incomplete texture is used as conditioning so that the network can fill in occluded UV regions while preserving visible identity cues.
The second stage is light homogenization. Here the same diffusion backbone is conditioned on the shaded UV texture $T_{env}$ and supervised by a uniformly illuminated target $T_{hom}$. The purpose is to move from a scene-dependent shaded representation into a canonical lighting domain before material decomposition. The authors repeatedly stress that this normalization is not optional: without it, the inverse problem becomes much harder and the material estimator tends to entangle albedo, shading, and geometry.
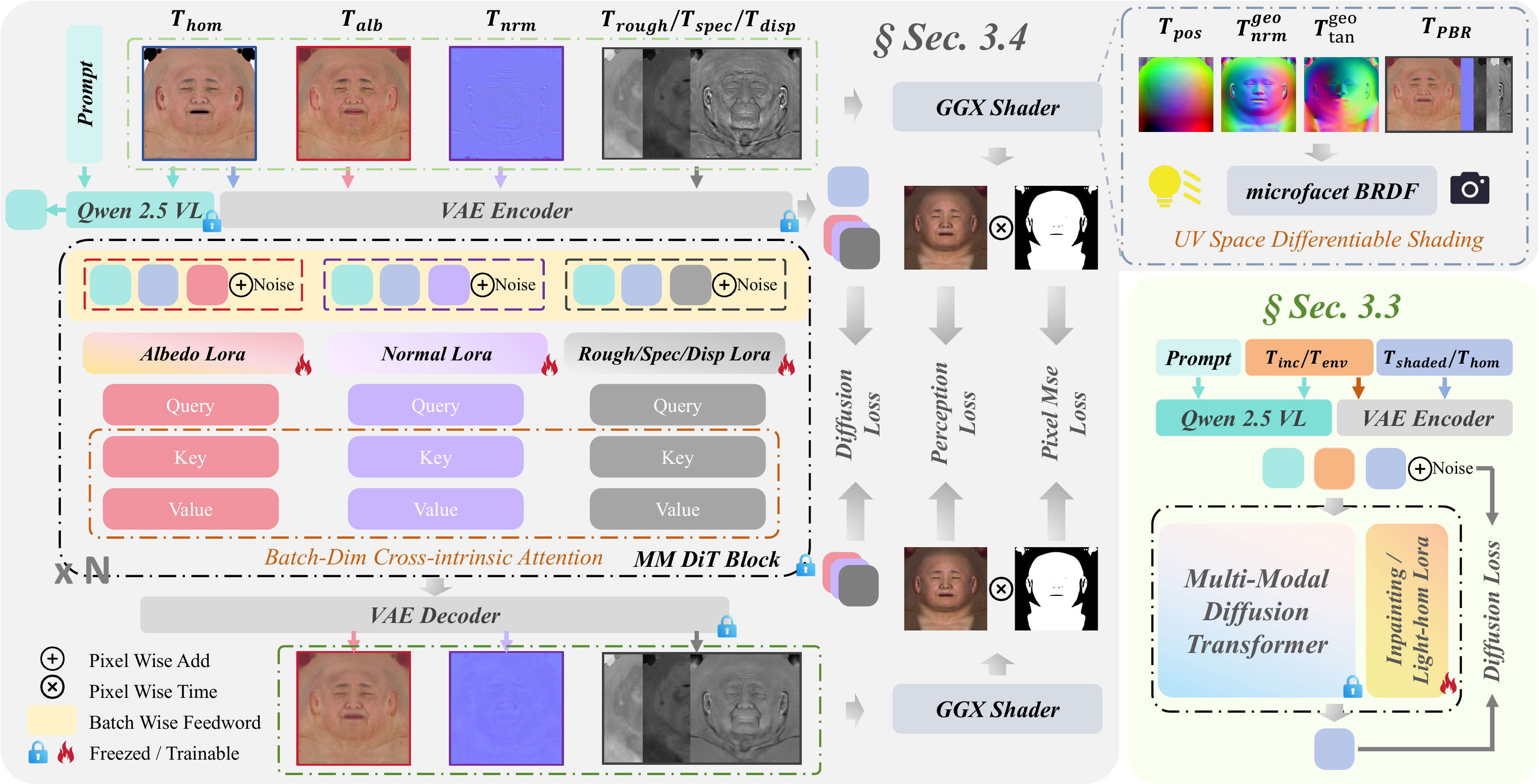
3. Physically based material estimation with cross-intrinsic attention
After homogenization, the model estimates intrinsic material properties in UV space. The paper distinguishes between three branches: albedo, normal, and a compact reflectance branch $T_{rsd}$ that packs roughness, specular, and displacement. The authors say a naive strategy with independent diffusion adapters per attribute gives visually plausible maps, but often produces physically inconsistent results: texture detail is overfit as geometry, and branch outputs become spatially fragmented.
To address this, they train the material stage with three task-specific LoRA adapters and a cross-intrinsic attention mechanism. Queries are computed per modality, while keys and values are concatenated across modalities, enabling explicit information exchange among albedo, normal, and reflectance-related branches:
$$ \mathbf{h}_i = \operatorname{Attn}(\mathbf{q}_i, \mathbf{K}, \mathbf{V}), \qquad \operatorname{Attn}(\mathbf{q}, \mathbf{K}, \mathbf{V}) = \operatorname{softmax}\!\left(\frac{\mathbf{q}\mathbf{K}^{\mathsf{T}}}{\sqrt{d}}\right)\mathbf{V}. $$
This design is intended to let each branch borrow complementary cues from the others while still maintaining branch-specific adaptation through separate LoRA weights.
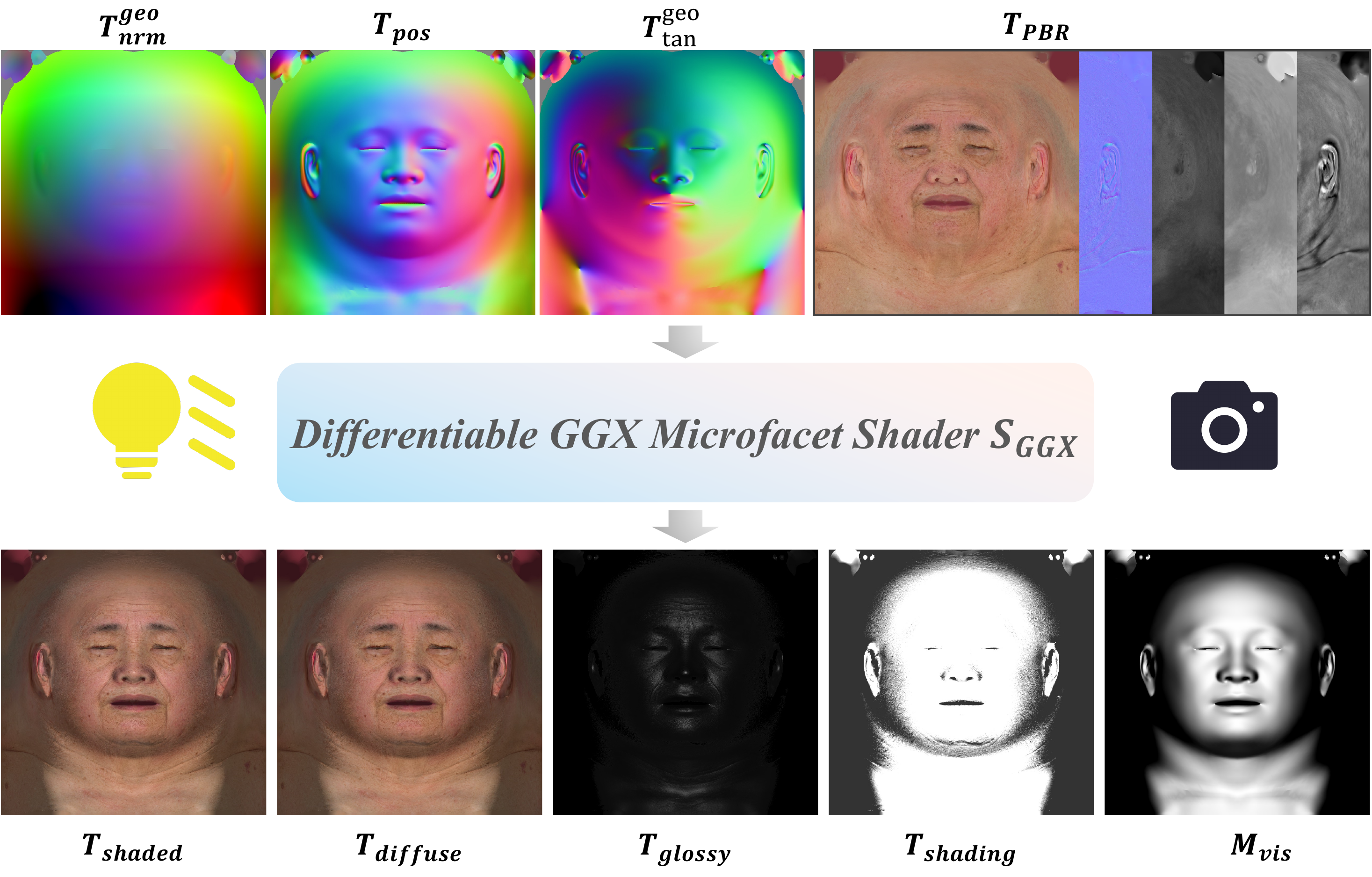
The material stage is further constrained by a UV-space differentiable BRDF shading loss. The clean latent estimate is reconstructed as $$ \hat{\mathbf{z}}_0 = \mathbf{z}_{\sigma} - \sigma\,\hat{\mathbf{v}}_{\theta}(\mathbf{z}_{\sigma}, \sigma, \mathbf{c}), $$ then decoded to predicted material maps. The shading loss is evaluated using a fixed template face whose position, geometric normal, and geometric tangent maps are precomputed. The BRDF is based on a GGX microfacet model. The final shaded texture is written as $$ \hat{T}_{shaded}(\mathbf{u}) = M(\mathbf{u})\bigg[\sum_{k=1}^{K} L_k(\mathbf{l}_k)(\mathbf{n}\cdot\mathbf{l}_k)^+\big(f_d(\mathbf{u}) + f_s(\mathbf{u},\mathbf{v},\mathbf{l}_k)\big) + I_{amb}\,\hat{T}_{alb}(\mathbf{u})\bigg], $$ with ambient intensity sampled from $\mathcal{U}(0.15, 0.3)$ during training. The overall material objective is $$ \mathcal{L} = \mathcal{L}_{diff} + \lambda_{img}\|\hat{T}_{shaded} - T_{shaded}\|_2^2 + \lambda_{lpips}\,\operatorname{LPIPS}(\hat{T}_{shaded}, T_{shaded}). $$ In the reported experiments, the authors set $\lambda_{img}=0.5$ and $\lambda_{lpips}=0.1$.
A useful implementation detail from the appendix is that the shader operates fully in UV space and uses fixed geometric priors rather than rasterization. The predicted displacement map is applied along the geometric normal with a small scale factor $s_{disp}=0.01$. The local tangent frame is re-orthogonalized via Gram-Schmidt to keep the shading basis consistent with the perturbed normal. The appendix also notes that their GGX proxy is simplified for numerical stability and is not strictly energy conserving.
4. Super-resolution
As a final step, the predicted maps are upscaled from 1K to 4K using a fine-tuned Real-ESRGAN model. The paper treats this as post-processing rather than part of the main generative pipeline.
Data Preparation
The training data are assembled from two very different sources. For geometry and occlusion priors, the authors use FFHQ and CelebAMask-HQ, which together contain nearly 100,000 in-the-wild face images with variation in ethnicity, age, expression, pose, illumination, and occlusion. For material learning, they use a compact professional scan set from 3dscanstore containing fewer than 100 face scans, each with complete PBR maps up to 8K resolution: albedo, normal, specular, roughness, and displacement.
The key scaling step is a synthetic data pipeline. The geometry reconstruction network is used to fit face geometry to in-the-wild images, then high-quality PBR textures are randomly assigned to these geometries, producing 100,000 synthetic instances. To simulate realistic incompleteness, the authors use a segmentation model to extract visible skin regions and build UV-space visibility masks that encode both self-occlusion and external occlusion from hair, glasses, and accessories.
For the inpainting stage, synthetic faces are rendered in Blender Cycles under 2,041 HDRI environment maps plus rotation augmentation. The shaded renders are baked back into UV space to provide complete shaded targets $T_{env}$. The incomplete input $T_{inc}$ is formed by re-unwrapping the rendered image and multiplying by the visibility mask. For light homogenization, the same instance is rendered under a uniform white ambient lighting setup to obtain $T_{hom}$. For material estimation, the homogenized texture is supervised by the ground-truth PBR textures. For super-resolution, 8K textures are downsampled to 4K ground truth.
Implementation Details
Geometry reconstruction is trained with a ConvNeXt V2 Base backbone plus frozen DINOv3 for 50 epochs with batch size 128. The diffusion backbone for texture generation is LongCat-Image-Edit, used as the unified DiT. LoRA rank is 32, injected into attention and feedforward projections. Each adapter contains approximately 91M parameters, which the authors state is about 0.7% of the backbone.
Training uses JoyCaption captions for the ground-truth data at each stage, with fixed templates plus input-image captions at inference for intermediate tasks. All models are trained on 8 NVIDIA H100 80GB GPUs using BF16 and AdamW with learning rate $10^{-4}$. Inpainting and light-homogenization LoRAs are trained for 20k steps with batch size 64. The intrinsic material stage uses a two-stage schedule: 10k steps of independent training followed by 10k steps of joint training, with batch size 8.
The appendix also reports inference settings: 30 sampling steps and guidance scale 2.0 for all diffusion-based modules. This leads to a multi-stage runtime of about 4 minutes per 1K input on a single H100.
Experiments
The experimental section evaluates three different things: geometry reconstruction, texture reconstruction, and full-avatar relighting / qualitative realism. The paper also includes a user study and runtime accounting. The overall message is that the proposed system is not always numerically best on geometry alone, but it is consistently strong on texture fidelity, relighting, and visual realism, especially under occlusion and varied lighting.
Geometry reconstruction on REALY
Geometry is evaluated on the REALY benchmark using Normalized Mean Squared Error (NMSE) in millimeters over four regions: nose, mouth, forehead, and cheeks. The authors report that their method achieves an overall NMSE of 1.490, which they describe as the third-best overall result. Numerically, it is slightly behind 3DDFA-V3 and HiFace, but the paper argues that its qualitative behavior is more stable and less prone to overfitting artifacts.
The qualitative claim is that the use of predicted normal and displacement maps helps recover high-frequency details such as wrinkles, crow's feet, eye-region creases, and smile lines, while avoiding the warped bumps and over-smoothing seen in some alternatives.

| Method | Nose | Mouth | Forehead | Cheeks | All |
|---|---|---|---|---|---|
| DECA | 1.697 ± 0.355 | 2.516 ± 0.839 | 2.394 ± 0.576 | 1.479 ± 0.535 | 2.010 |
| Deep3D | 1.719 ± 0.354 | 1.368 ± 0.439 | 2.015 ± 0.449 | 1.528 ± 0.501 | 1.657 |
| HRN | 1.722 ± 0.330 | 1.357 ± 0.523 | 1.995 ± 0.476 | 1.072 ± 0.333 | 1.537 |
| HiFace (w/o syn) | 1.227 ± 0.407 | 1.787 ± 0.439 | 1.454 ± 0.382 | 1.762 ± 0.436 | 1.558 |
| MoSAR | 1.499 ± 0.366 | 1.424 ± 0.462 | 1.950 ± 0.559 | 1.128 ± 0.303 | 1.500 |
| 3DDFA-V3 | 1.584 ± 0.308 | 1.237 ± 0.375 | 1.809 ± 0.394 | 1.110 ± 0.328 | 1.435 |
| HiFace | 1.036 ± 0.280 | 1.450 ± 0.413 | 1.324 ± 0.334 | 1.291 ± 0.362 | 1.275 |
| Ours | 1.619 ± 0.381 | 1.376 ± 0.477 | 1.784 ± 0.464 | 1.181 ± 0.402 | 1.490 |
| w/o Enhanced $\mathcal{L}_{lan}$ | 1.457 ± 0.341 | 1.670 ± 0.529 | 1.803 ± 0.453 | 1.140 ± 0.405 | 1.518 |
| w/o MSSF | 1.728 ± 0.441 | 1.785 ± 0.514 | 2.179 ± 0.610 | 1.530 ± 0.548 | 1.806 |
| Baseline | 2.592 ± 0.510 | 2.664 ± 0.528 | 2.273 ± 0.563 | 2.524 ± 0.474 | 2.514 |
The main ablation finding here is that the MSSF encoder matters more than the landmark tweak in aggregate: removing MSSF degrades all regions substantially, while the enhanced landmark loss mostly helps the mouth region. The authors interpret this as evidence that DINOv3 semantic priors are important for the overall shape of the reconstruction.
Texture inpainting and light homogenization
The texture experiments compare against UV-IDM and HRN for inpainting, and against FFHQ-UV for light homogenization. The main takeaways are that the proposed method better removes baked-in occlusion and retains identity cues, while also producing a more uniformly lit texture suitable for downstream intrinsic decomposition.

| Method | PSNR | SSIM | LPIPS | CSIM |
|---|---|---|---|---|
| UV-IDM | 19.39 | 0.6149 | 0.1674 | 0.269 |
| HRN | 15.70 | 0.6193 | 0.2982 | 0.441 |
| Ours | 22.44 | 0.8003 | 0.0621 | 0.540 |
| Method | CSIM | BS |
|---|---|---|
| FFHQ-UV | 0.1340 | 5.738 |
| Ours | 0.4667 | 3.963 |
The paper's qualitative explanation is that HRN tends to bake occluders into UV textures because it lacks explicit occlusion handling, while UV-IDM preserves structure better but can lose high-frequency identity detail. In the homogenization comparison, FFHQ-UV still carries visible illumination artifacts such as forehead highlights and shadows, whereas the proposed method suppresses scene lighting while keeping skin details, eyebrow structure, makeup, redness, and beard information.

Across these comparisons, the paper argues that the main qualitative advantage is better disentanglement: the model separates lighting from intrinsic color and separates surface detail from spurious image artifacts such as hair, hats, and shadows. In the relighting examples, MoSAR is described as waxy and over-smoothed, while FitMe and Relightify are said to suffer from poor albedo and texture baking. The authors claim their system produces more faithful skin tone, richer micro-structure, and more complete material maps.
Ablations on light homogenization and joint material prediction
The paper includes two ablation themes. First, if light homogenization is removed, the inverse problem becomes ill-posed: the model must simultaneously infer materials and unknown lighting from a single shaded texture. In the authors' visualization, the model then misreads shadows as dark albedo and injects geometric noise into normals and displacement. Second, if the material branches are trained separately, they overfit high-frequency appearance and produce noisy or fragmented geometry-like artifacts. The joint strategy with cross-intrinsic attention and the differentiable BRDF constraint is what restores coherence.

| Method | Geometric Details | Texture Realism | Relighting Quality |
|---|---|---|---|
| vs. MoSAR | 60.0% | 83.3% | 80.0% |
| vs. FitMe | 96.7% | 93.3% | 93.3% |
| vs. Relightify | 100.0% | 100.0% | 100.0% |
The paper also reports a user study with 30 participants and 20 reconstruction sets. Participants preferred the proposed method over MoSAR, FitMe, and Relightify across geometric precision, texture realism, and relighting quality. The most striking result is the 100% preference over Relightify in all three categories, and 96.7% / 93.3% over FitMe for geometry and relighting.
Runtime
Runtime is a major practical caveat. The system is explicitly an offline-quality pipeline rather than a real-time regressor. The latency breakdown reported in the appendix is:
| Stage | Backbone | Time |
|---|---|---|
| Geometry reconstruction | ConvNeXt V2 + DINOv3 | < 0.5 s |
| Texture inpainting | Flow matching DiT + LoRA | 30 s |
| Light homogenization | Flow matching DiT + LoRA | 30 s |
| Intrinsic material estimation | Joint diffusion with cross attention | 3 min |
| Super-resolution | RealESRGAN (1K → 4K) | ~ 2 s |
| Total | ~ 4 min |

Additional visual results reinforce the same theme: the geometry stage recovers micro-structures such as crow's feet and wrinkles; the inpainting stage removes occlusions while keeping identity; and the light homogenization stage strips away scene-dependent lighting while retaining appearance cues. The appendix also shows robustness on in-the-wild images spanning different ages, ethnicities, and genders, and on difficult cases with large pose changes and strong cast shadows.

Limitations
The paper is unusually explicit about limitations. First, while the system is robust to common occluders like hair, it struggles with semi-transparent occlusions such as eyeglasses. In those cases, the restored region may be over-smoothed because the missing high-frequency evidence is simply not observable in the incomplete texture. Second, the geometry stage still relies on a linear Hifi3D++ basis, so extreme expressions or highly non-rigid deformations can cause geometric misalignment or loss of identity-specific detail. Third, the pipeline is slow, which makes it better suited to offline asset creation than interactive use. Finally, LoRA fine-tuning on a small professional scan set can degrade the base diffusion model's open-domain text editing/editability, so balancing physical accuracy and editability remains an open issue.

Conclusion
The paper's overall contribution is a data-efficient, UV-space, diffusion-prior-based avatar reconstruction pipeline that couples a strong generative backbone with physically based shading constraints. The method's main novelty is not any single component in isolation, but the combination of: a semantic geometry encoder, cascaded LoRA adaptation for separate reconstruction subtasks, cross-intrinsic attention for coordinated material prediction, and a differentiable GGX shader used directly as supervision. The reported results suggest that this combination is effective for producing high-resolution, relightable face avatars from a single image with strong generalization to in-the-wild inputs.