HPRO
HPRO: Hierarchical Progressive Reward Optimization via Preference Extraction for Emotional Text-to-Speech
HPRO improves emotional text-to-speech by separating content and style into distinct preference tokens and optimizing generation progressively at frame, word, and sentence levels, boosting naturalness and expressiveness while avoiding semantic-emotion conflicts.
Demos
These demos highlight HPRO's ability to generate emotionally expressive speech by separating content and style preferences to avoid conflicts in prosody. Evaluators should note how well emotions match prompts and assess stability across varied emotions. Key aspects include clear emotional expressiveness, semantic relevance, and hierarchical reward optimization at frame, word, and sentence levels.
Links
Paper & demos
Abstract
Recently, Large Language Model (LLM)-based Text-to-Speech (TTS) models have achieved remarkable naturalness. However, the standard Supervised Fine-Tuning paradigm often converges to statistically averaged prosody, limiting emotional expressiveness. While preference-driven optimization offers a promising alternative, existing approaches suffer from two structural mismatches: information conflict, where content and emotion in a shared latent space produce conflicting gradients, leading to reward hacking and semantic degradation; and scale gap, where sparse sentence-level rewards struggle to guide dense frame-level generation. To overcome these challenges, we propose HPRO, a hierarchical progressive reward optimization framework. Within HPRO, we introduce the HD-Emo codec as a novel differentiable reward model to resolve the information conflict. It extracts speech into distinct content and style preference tokens, structurally isolating emotional optimization from semantic content. Building upon this structured preference space, HPRO bridges the scale gap by progressively aligning frame-, word- and sentence-level objectives. Experiments demonstrate that HPRO significantly enhances emotional expressiveness, while effectively preserving linguistic intelligibility. The code and audio samples are publicly available at https://xxh333.github.io/hpro-demo/.
Introduction
This paper studies preference-driven optimization for emotional text-to-speech (TTS) in the setting of large-language-model-based speech generation. The core problem is that standard supervised fine-tuning (SFT) on next-token prediction tends to average over the training distribution, producing natural but emotionally flattened prosody. The authors argue that directly optimizing emotional preference signals is promising, but existing approaches suffer from two structural mismatches: information conflict, where content and emotion are entangled in a shared latent space and optimization for one can damage the other; and scale gap, where sparse sentence-level rewards are too coarse to supervise dense frame-level speech generation.
To address both issues, the paper proposes HPRO (Hierarchical Progressive Reward Optimization) and a differentiable reward model called the HD-Emo codec. The codec separates speech into content and style preference tokens, so that emotional optimization can be structurally isolated from semantic content. HPRO then applies rewards progressively at the frame, word, and sentence levels, building a gradient path from dense local alignment to global affective control.
The paper is positioned as a response to reward-hacking failure modes observed when global preference optimization is applied to monolithic speech representations. In the authors’ view, simply improving reward robustness is not enough; the optimization problem itself must be restructured so that semantics and style are separated and supervised at multiple granularities.
Method Overview
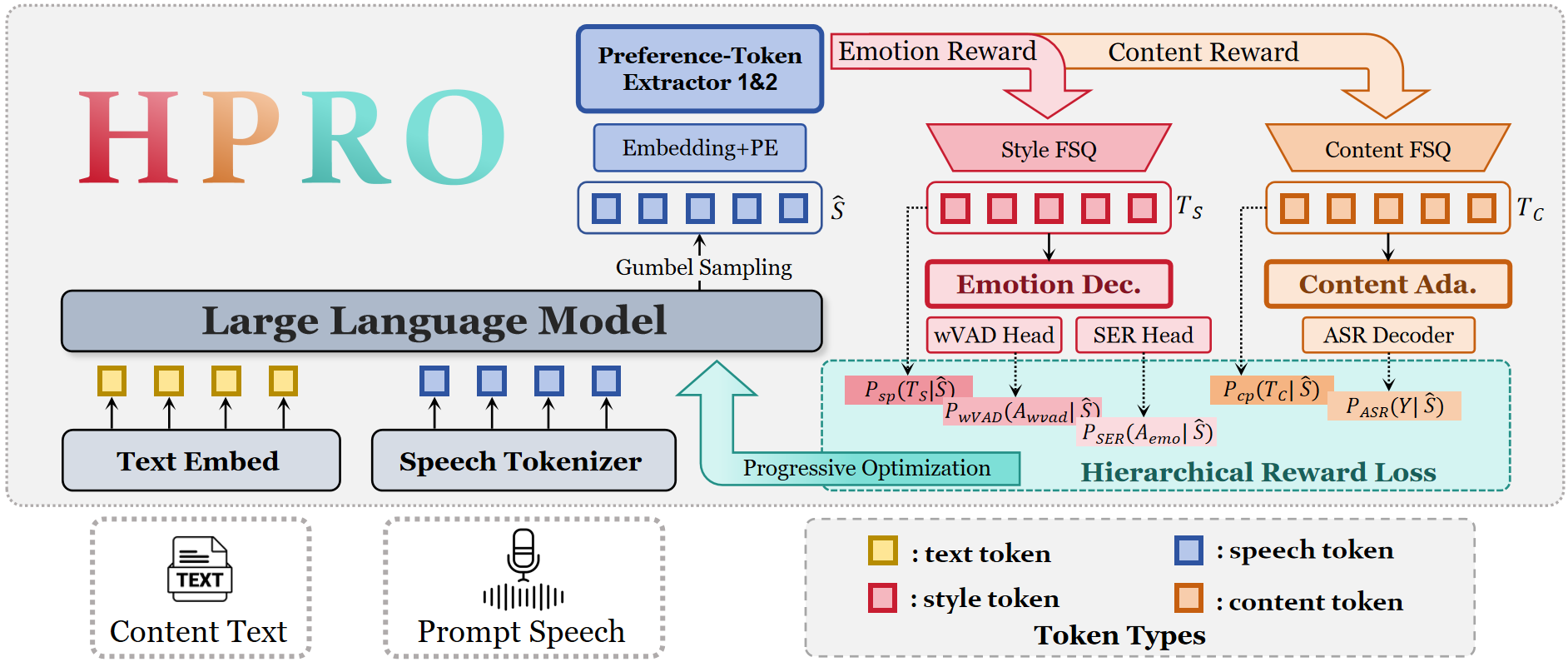
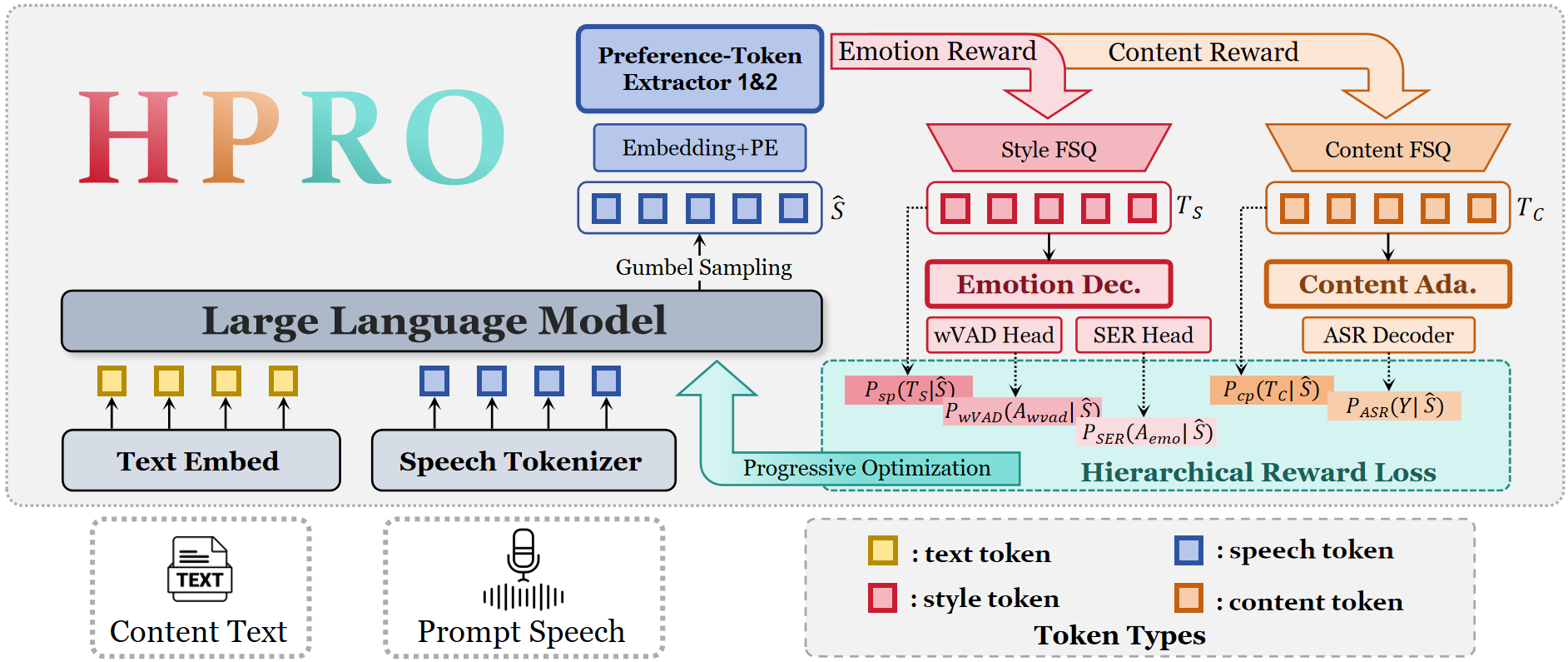
HPRO has two main parts. First, the HD-Emo codec acts as a differentiable reward interface that converts speech tokens into two structured preference spaces. Second, the HPRO training objective uses these preference spaces to supervise an LLM-based TTS model with hierarchical rewards.
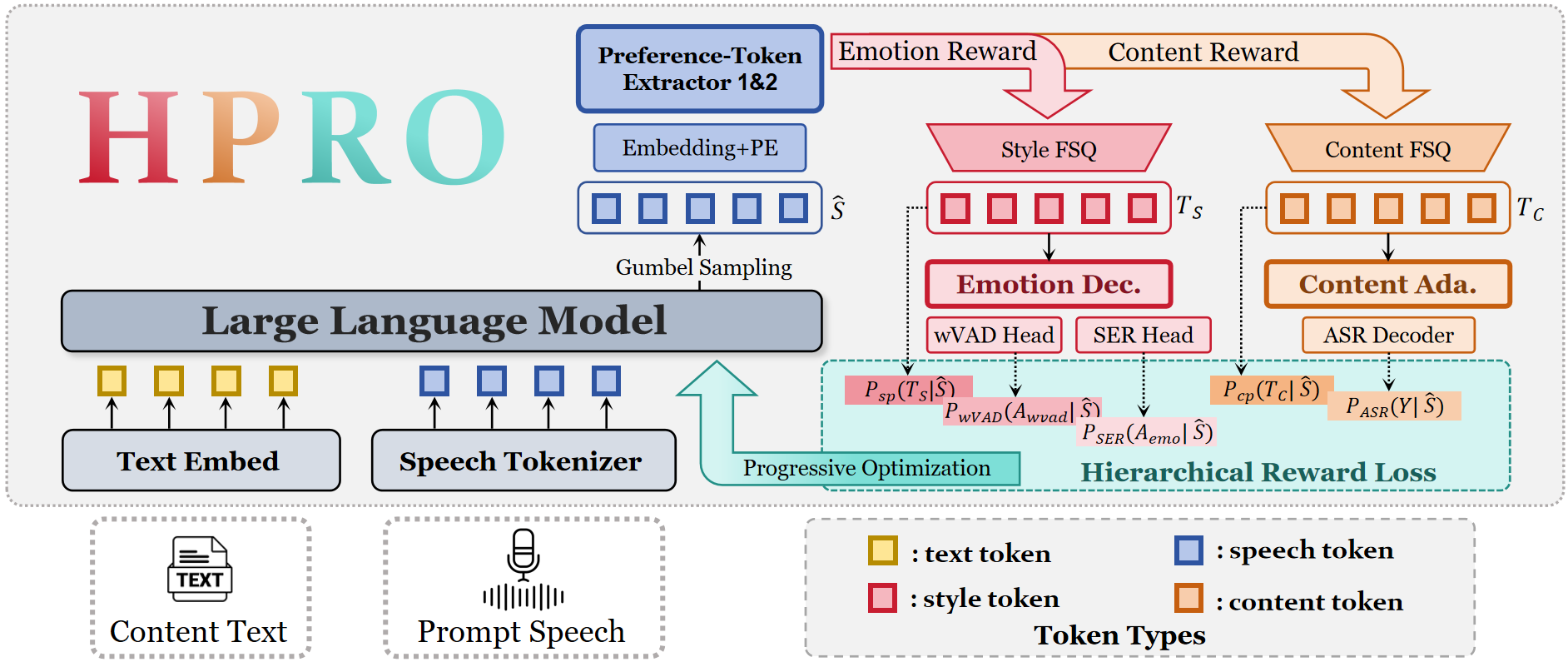
The LLM produces differentiable speech tokens using straight-through Gumbel-Softmax. These tokens are then passed through the frozen HD-Emo codec, which maps them into structured content and style preference tokens. Gradients can flow back into the LLM through the relaxed token representations, enabling direct optimization without conventional RL rollouts.
HD-Emo Codec: Structured Preference Extraction
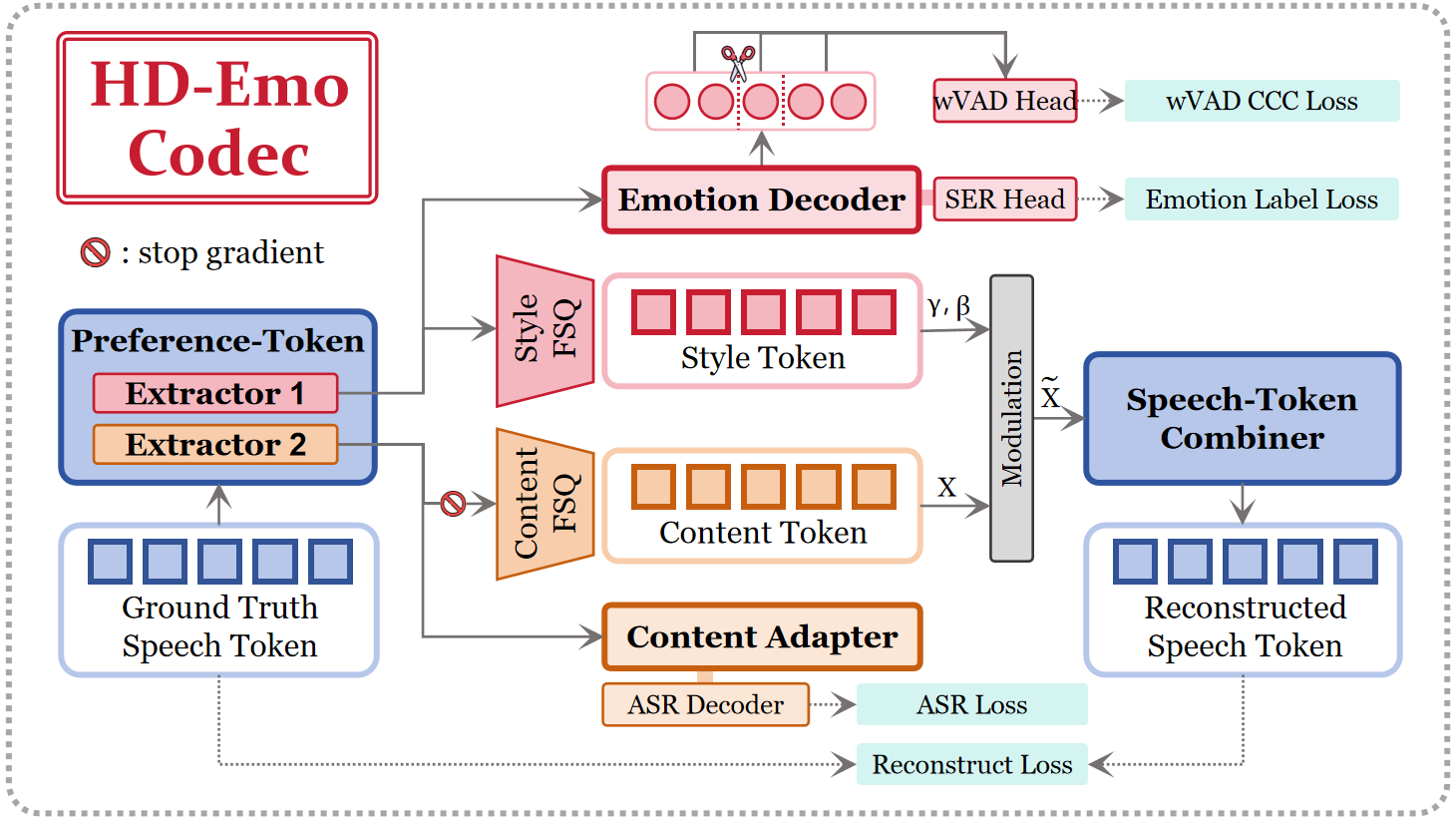
The codec receives discrete speech tokens extracted by the CosyVoice2 tokenizer and processes them with two preference token extractors that share architecture but not parameters. Both branches use finite scalar quantization (FSQ) to impose a hard information bottleneck and produce discrete latent tokens: content-preference tokens $T_c$ and style-preference tokens $T_s$.
The content branch is explicitly anchored to linguistic semantics. Before quantization, its latent representation is fed into a content adapter and an ASR decoder initialized from the pre-trained Whisper-medium decoder. Given a transcription $Y=(y_1,\dots,y_M)$, the ASR objective is:
$$\mathcal{L}_{\mathrm{ASR}}=-\sum_{j=1}^{M}\log P(y_j\mid y_{<j},T_c).$$
A key design choice is a stop-gradient path from the reconstruction stream to the content extractor. This prevents acoustic leakage, meaning the content branch cannot quietly absorb prosodic information just to improve reconstruction. As a result, the content tokens are updated only through ASR supervision, which enforces stricter semantic alignment.
The style branch is supervised hierarchically. At the sentence level, a pre-trained emotion2vec model produces a soft emotion distribution $p$, and the style decoder predicts $\hat{p}$. The cross-entropy loss is:
$$\mathcal{L}_{\mathrm{SER}}=-\sum_{i=1}^{C}p_i\log \hat{p}_i,$$
where $C$ is the number of emotion categories. For word-level control, the paper uses Montreal Forced Aligner to align text and audio, then derives word-level valence-arousal-dominance trajectories with a pre-trained wav2vec2-ft emotion model. The comparison metric is concordance correlation coefficient (CCC):
$$\mathrm{CCC}(v,\hat{v})=\frac{2\sigma_{v\hat{v}}}{\sigma_v^2+\sigma_{\hat{v}}^2+(\mu_v-\mu_{\hat{v}})^2}.$$
The word-level objective sums the three affective dimensions:
$$\mathcal{L}_{\mathrm{word}}=\sum_{k\in\{V,A,D\}}\left(1-\mathrm{CCC}(v_k,\hat{v}_k)\right).$$
To reconstruct speech, the codec fuses the content representation $X$ and style factors through dynamic feature modulation inspired by Emo-FiLM:
$$\widetilde{X}=X\odot \gamma + \beta.$$
Here, $\gamma$ and $\beta$ are projected from the style stream. Reconstruction is trained with cross-entropy, so the codec remains generative while also providing structured internal supervision signals.
HPRO Training Objective and Progressive Optimization
HPRO uses the pretrained HD-Emo codec as a frozen reward model. The LLM generates a differentiable token sequence $\hat{S}$, which the codec maps into generated content and style preference tokens $\hat{T}_c$ and $\hat{T}_s$. The method defines rewards at three scales: frame, word, and sentence.
Frame-level reward. The model directly aligns the generated pre-quantization latent states $\hat{Z}_c$ and $\hat{Z}_s$ with the ground-truth discrete preference tokens $T_c$ and $T_s$ using $L_1$ regression:
$$\mathcal{L}_{cp}=\lVert \hat{Z}_c-T_c\rVert_1,\qquad \mathcal{L}_{sp}=\lVert \hat{Z}_s-T_s\rVert_1.$$
Word-level reward. Using forced-alignment boundaries, the training adds the word-level emotional trajectory loss $\mathcal{L}_{\mathrm{wVAD}}$ and the ASR loss $\mathcal{L}_{\mathrm{ASR}}$ to preserve lexical correctness while guiding local emotional variation.
Sentence-level reward. The sentence-level emotion distribution is matched to the target soft label with $\mathcal{L}_{\mathrm{SER}}$ to enforce global affective consistency.
The overall objective combines all components with weights $\lambda_i$:
$$\mathcal{L}_{\mathrm{total}}=\sum_i \lambda_i\mathcal{L}_i,\qquad i\in\{\mathrm{KL},cp,sp,\mathrm{wVAD},\mathrm{ASR},\mathrm{SER}\}.$$
A token-wise KL regularizer is also applied to the original speech-token distribution. The authors emphasize that the hierarchical structure is not only a collection of losses; it is an optimization schedule designed to avoid early-stage reward hacking.
Progressive training schedule
The training strategy proceeds in three stages:
- Stage I: Frame-level warm-up. Optimize $\mathcal{L}_{cp}$, $\mathcal{L}_{sp}$, and KL only. The weights are $\lambda_{\mathrm{KL}}=0.05$, $\lambda_{sp}=2$, $\lambda_{cp}=1$, with Gumbel temperature $\tau=2$.
- Stage II: Word-level refinement. Add $\mathcal{L}_{\mathrm{wVAD}}$ and $\mathcal{L}_{\mathrm{ASR}}$ with $\lambda_{\mathrm{KL}}=0.02$, $\lambda_{sp}=2$, $\lambda_{cp}=1$, $\lambda_{\mathrm{ASR}}=5$, $\lambda_{\mathrm{wVAD}}=1$, and anneal $\tau$ to $1$.
- Stage III: Sentence-level alignment. Introduce $\mathcal{L}_{\mathrm{SER}}$ with $\lambda_{\mathrm{SER}}=0.5$ and further anneal $\tau$ to $0.8$.
This schedule explicitly bridges the scale gap: dense local supervision stabilizes token generation first, then boundary-aware word-level control refines prosody, and finally global emotional alignment is added once the model has a stable acoustic basis.
Experimental Setup
Datasets
The paper evaluates on three datasets. LibriSpeech (960h) provides foundational ASR supervision for semantic extraction. LSSED (206h), a large-scale categorical SER dataset, and EmoVoice-DB (40h), a highly expressive emotional TTS corpus, are used for emotional modeling, TTS training, and evaluation. The test sets of LSSED and EmoVoice-DB are used in all experiments. The emotional datasets are also incorporated into ASR supervision during codec training to help the codec remain robust under expressive prosody.
Baselines
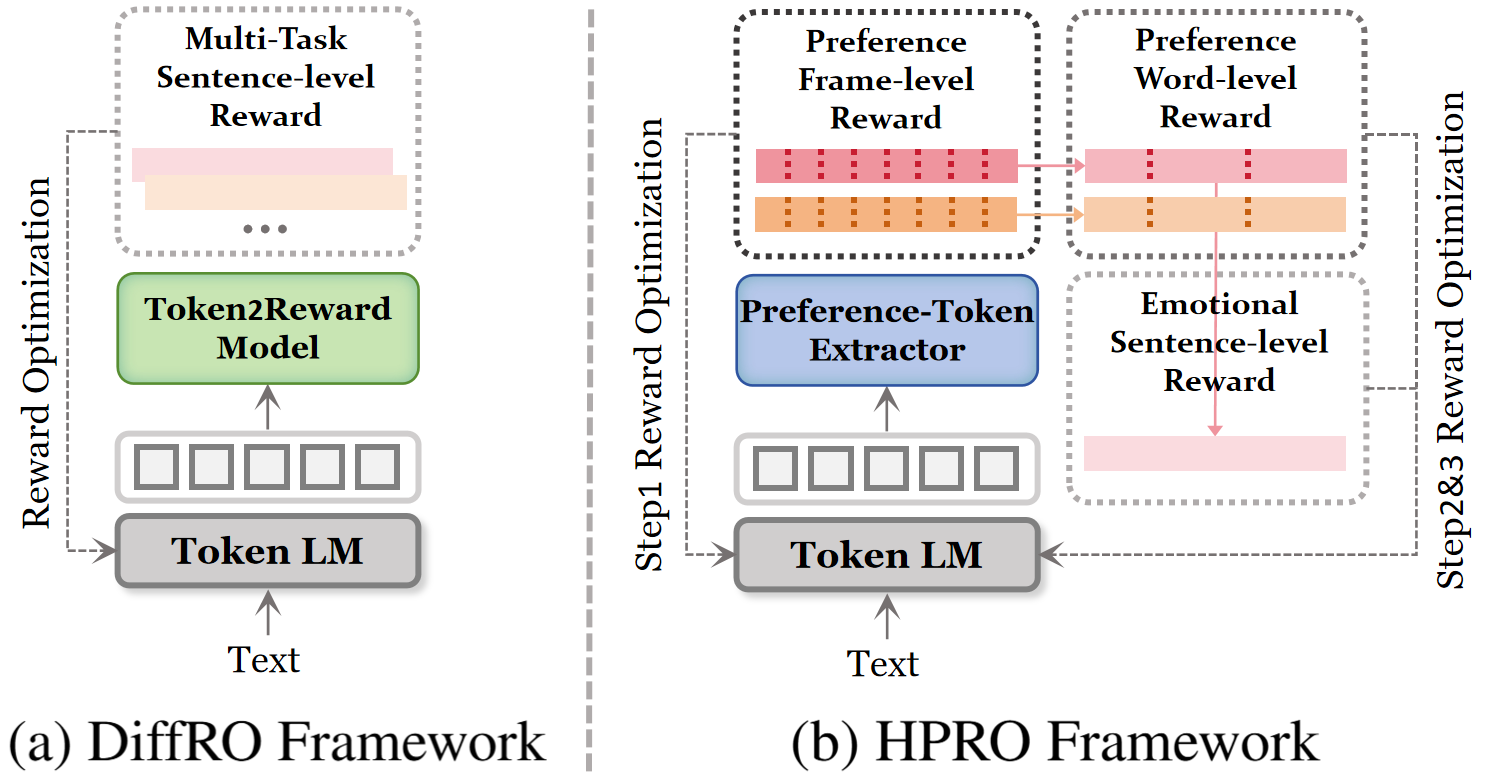
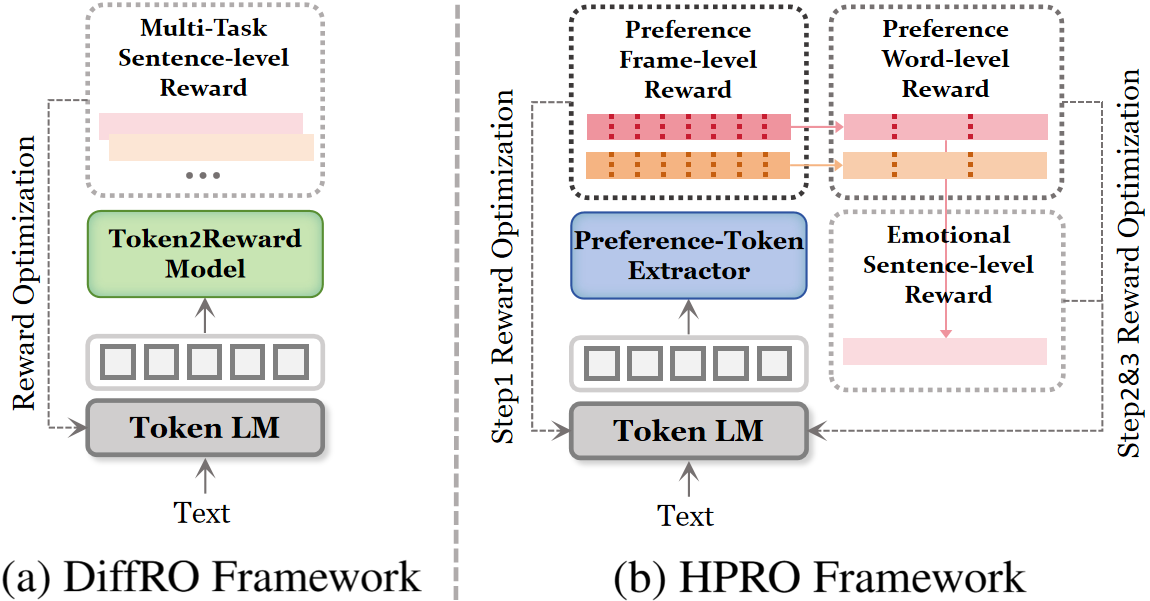
The main comparisons are against CosyVoice2, CosyVoice3, IndexTTS2, and HD-PPT. HPRO is implemented on top of the CosyVoice2 backbone. Because the official DiffRO implementation is not public, the authors simulate its single-scale reward optimization in their ablation study rather than comparing against a standalone released system. The HD-PPT baseline is adapted from its original instructional framework to the zero-shot TTS setting.
Implementation details
The HD-Emo codec uses an 8-layer conformer for the dual preference-token extractors and an 8-layer autoregressive transformer as the speech-token combiner. FSQ codebook sizes are 1296 for content tokens and 64 for style tokens. The codec is trained with Adam for 100 epochs on 8 NVIDIA RTX 4090 GPUs with learning rate $10^{-4}$.
The HPRO LLM backbone is based on Qwen2.5-0.5B and is optimized with Adam at learning rate $10^{-5}$. Training follows the three-stage progressive schedule described above.
Evaluation protocol
Evaluation is zero-shot: each test utterance is synthesized using a randomly selected reference from the same speaker. For subjective listening, the authors select 90 emotionally balanced utterances and recruit 18 participants to rate samples on a 5-point Likert scale. The subjective metrics are MOS-N for naturalness and MOS-E for consistency between emotion and semantic content.
Objective metrics are WER computed with whisper-large-v3, wVAD-CCC, EMO-SIM, and DNSMOS. The paper notes that although HPRO optimizes within the discrete preference-token space of the codec, all objective metrics are computed on final waveforms using external models, avoiding evaluation circularity.
Main Results
The main comparison on LSSED and EmoVoice-DB shows that HPRO delivers the strongest overall balance between emotional expressiveness and intelligibility. It achieves the best MOS-N, the second-best MOS-E, the best WER, the best wVAD-CCC, and the best EMO-SIM among the reported TTS systems. DNSMOS remains slightly lower than the best baseline, but stays competitive.
| Model | MOS-N $\uparrow$ | MOS-E $\uparrow$ | WER $\downarrow$ | wVAD-CCC $\uparrow$ | EMO-SIM $\uparrow$ | DNSMOS $\uparrow$ |
|---|---|---|---|---|---|---|
| TokenRecon | - | - | 7.34% | 0.570 | 0.775 | 3.58 |
| CosyVoice2 | 4.094 ± 0.257 | 3.530 ± 0.402 | 5.45% | 0.307 | 0.613 | 3.76 |
| CosyVoice3 | 4.137 ± 0.285 | 3.538 ± 0.343 | 4.90% | 0.275 | 0.611 | 3.72 |
| IndexTTS2 | 4.026 ± 0.238 | 3.692 ± 0.213 | 6.74% | 0.293 | 0.526 | 3.53 |
| HD-PPT | 4.068 ± 0.248 | 3.547 ± 0.328 | 4.92% | 0.323 | 0.646 | 3.75 |
| HPRO | 4.171 ± 0.318 | 3.650 ± 0.347 | 4.02% | 0.339 | 0.672 | 3.73 |
The subjective results show that HPRO has the highest naturalness score while keeping emotional consistency near the top. The authors interpret the IndexTTS2 result as evidence that explicit text-to-emotion mapping can increase perceived emotional intensity, but at the cost of stereotyped, less natural speech. In contrast, HPRO better balances affect and naturalness. On the objective side, the strongest result is the lowest WER, which the paper uses to argue that the HD-Emo codec successfully resolves the information conflict between semantics and emotion. The best wVAD-CCC and EMO-SIM further support the claim that the hierarchical reward design captures fine-grained affective nuance.
Ablation Studies
Progressive optimization ablation
The first ablation adds hierarchical constraints incrementally on top of a CosyVoice2-SFT baseline. The results show a clear progression: frame-level supervision provides a strong acoustic foundation, word-level supervision produces the best WER and wVAD-CCC, and sentence-level supervision gives the best global emotion score and DNSMOS.
| Model | WER $\downarrow$ | wVAD-CCC $\uparrow$ | EMO-SIM $\uparrow$ | DNSMOS $\uparrow$ |
|---|---|---|---|---|
| CosyVoice2-SFT | 5.42% | 0.297 | 0.641 | 3.63 |
| + Frame | 4.85% | 0.332 | 0.650 | 3.71 |
| + Word | 3.99% | 0.350 | 0.653 | 3.70 |
| + Sentence | 4.02% | 0.339 | 0.672 | 3.73 |
This ablation reveals the intended optimization behavior. Frame-level supervision reduces the risk of losing core speech structure. Word-level supervision is especially effective for local temporal alignment and lexical accuracy, giving the best WER and wVAD-CCC. Adding sentence-level supervision increases global emotion consistency, though it slightly softens local word-level prosody and WER relative to the word-only stage. The paper explicitly describes this as an expected multi-scale tension rather than a failure.
Reward-design ablation
The second ablation is trained in a non-progressive manner to isolate individual reward terms. The authors note that the variant w/o frame&wvad simulates a single-scale global-reward paradigm similar to DiffRO.
| Model | WER $\downarrow$ | wVAD-CCC $\uparrow$ | EMO-SIM $\uparrow$ | DNSMOS $\uparrow$ |
|---|---|---|---|---|
| w/o content | 13.61% | 0.285 | 0.584 | 3.59 |
| w/o emotion | 3.80% | 0.295 | 0.637 | 3.78 |
| w/o frame | 4.97% | 0.333 | 0.608 | 3.68 |
| w/o wvad | 4.10% | 0.310 | 0.659 | 3.75 |
| w/o frame&wvad (DiffRO) | 4.35% | 0.315 | 0.662 | 3.73 |
| HPRO | 4.02% | 0.339 | 0.672 | 3.73 |
This ablation is the paper’s strongest evidence for the two structural mismatches. Removing content supervision causes severe semantic collapse, with WER rising to 13.61%. Removing emotion supervision yields the best WER and DNSMOS but clearly undercuts affective expressiveness. The frame-level and word-level terms both contribute measurably: omitting either degrades the multi-scale balance, and omitting both leaves a single-scale global reward system that is noticeably weaker than the full hierarchical design. In particular, the DiffRO-style setting keeps decent EMO-SIM but performs worse on WER and wVAD-CCC, reinforcing the authors’ claim that monolithic rewards alone are insufficient for emotional TTS.
Interpretation and Limitations
The paper’s central takeaway is that emotional TTS benefits from structural separation and progressive supervision. The HD-Emo codec reduces conflict by disentangling content from style, while HPRO reduces the scale mismatch by moving from local preference alignment to word- and sentence-level affective objectives. The ablations show that both ingredients matter: if content supervision is removed, semantics collapse; if frame-level or word-level guidance is removed, emotional control becomes less precise; and if only a single global reward is used, the model cannot balance the two objectives as well as the full hierarchy.
The most evident limitation reported in the results is the trade-off between local and global objectives. When sentence-level emotion alignment is added, EMO-SIM improves, but WER and wVAD-CCC can slightly drift relative to the word-only stage. The main table also shows that HPRO does not achieve the best DNSMOS among all systems, even though it wins on the semantic and emotional alignment metrics. In other words, the method is strong at balancing intelligibility and expressiveness, but the different metrics do not all peak simultaneously.
Another practical limitation is the need for multiple external components: forced alignment with Montreal Forced Aligner, a pre-trained SER model, a pre-trained emotion trajectory regressor, and a Whisper-based ASR decoder. The paper uses these components deliberately to construct its hierarchical reward signal, but that also means the approach depends on a fairly elaborate supervision stack. The authors’ own future-work statement suggests extending the word-level mechanism beyond affective attributes and turning these intermediate signals into learned representations for broader controllable TTS and spoken dialogue models.
Conclusion
HPRO is presented as a hierarchical optimization framework for emotional TTS that explicitly targets two failure modes of preference-driven training: information conflict and scale gap. Its key technical contribution is the HD-Emo codec, which extracts separated content and style preference tokens under ASR, SER, and word-level valence-arousal-dominance supervision. Its key optimization contribution is a three-stage progressive reward schedule that starts with frame-level token alignment, adds word-level refinement, and ends with sentence-level emotion alignment. On LSSED and EmoVoice-DB, the method improves emotional expressiveness while preserving linguistic intelligibility, and the ablations support the claim that both the structured preference space and the hierarchical optimization schedule are necessary.