From speech to face, code-switching, and pronunciation
Today's digest spans full-duplex talking avatars, stronger multilingual ASR for code-switching, and LLM-based grapheme-to-phoneme benchmarking for Japanese TTS. Together they point to voice systems that sound more natural, adapt more flexibly, and animate more convincingly.
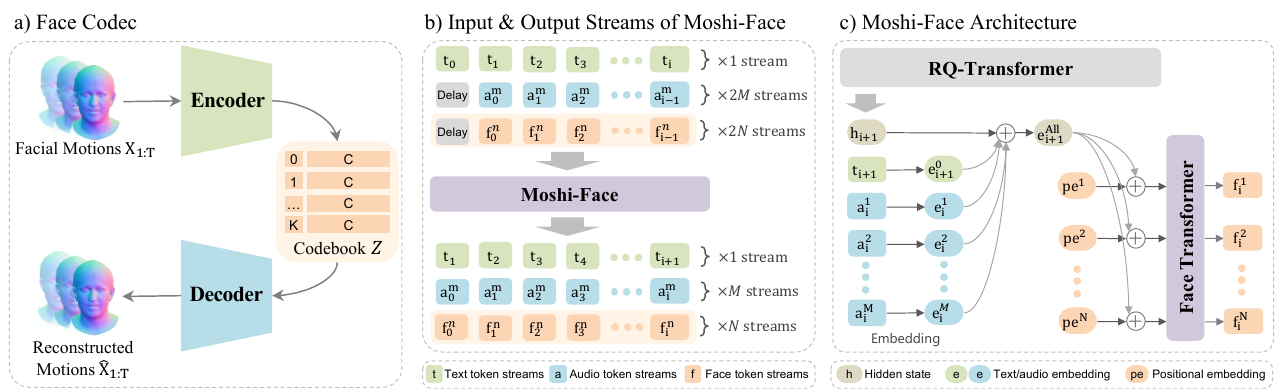
Overview of Moshi-Face. a)~Face codec encodes facial motion into $N$ discrete face tokens and decodes them back. b)~Moshi-Face appends $N$ face token streams to existing text and audio token streams. c)~Face Transformer generates $N$ face tokens from conditioning vector $ ^ _i+1$ that aggregates hidden state, text, and audio embeddings. From Moshi-Face.

