Avatars Speak and See Clearly
Today’s digest spans photorealistic 3D human avatars, identity-preserving video generation, and a unified audio-language model for speech, sounds, and music. Together they point to richer multimodal agents that can see, hear, and render people more naturally.
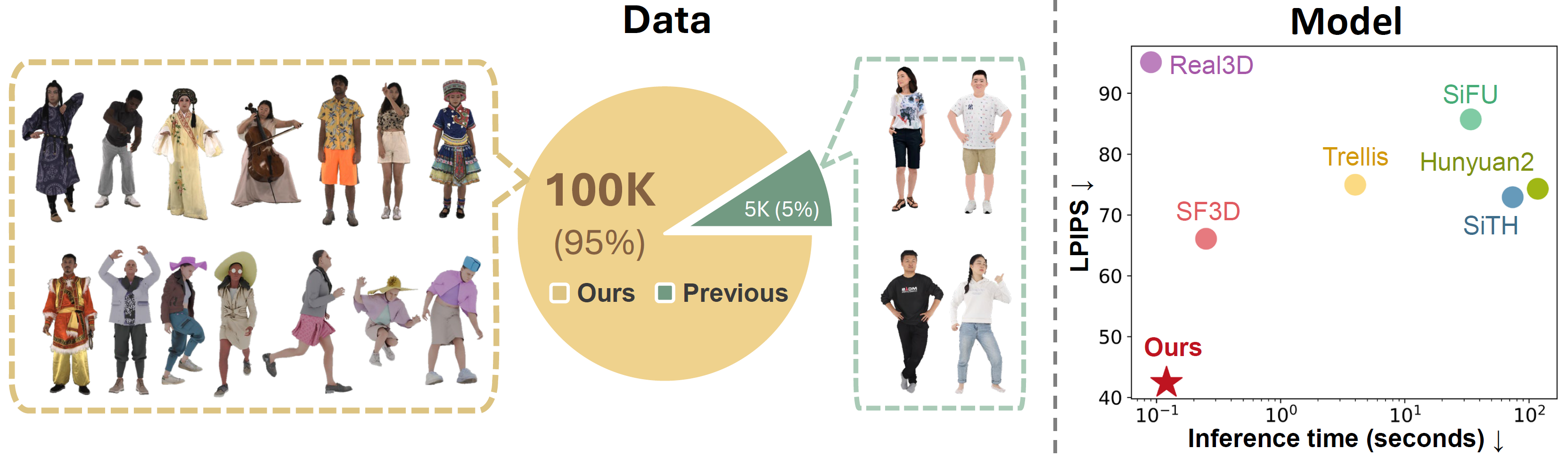
HumanNOVA teaser figure illustrating photorealistic, universal, and rapid 3D human avatar modeling from a single image. From HumanNOVA.
Digital Humans & 3D Avatars
HumanNOVA
HumanNOVA: Photorealistic, Universal and Rapid 3D Human Avatar Modeling from a Single Image
HumanNOVA is a photorealistic, universal, and rapid method for creating 3D human avatars from a single image without test-time optimization. It uses large-scale synthetic and real training data plus token-conditioned feed-forward modeling, enabling fast and robust 3D human reconstructions in diverse conditions.

ST-DRC
Spatial-Temporal Decoupled Reference Conditioning for Identity-Preserving Text-to-Video Generation
ST-DRC is a spatial-temporal decoupled reference conditioning method for identity-preserving text-to-video generation. It encodes the reference as latent memory and separates spatial-temporal cues to balance text adherence with facial identity preservation, avoiding common copy-paste artifacts.
