Prosody and Stress Take Center Stage
Today’s digest focuses on speech fidelity at the syllable level, from dynamic prosody prediction and duration-based watermarking in LLM TTS to stress-preserving speech-to-speech translation. Together, these papers push synthesized and translated speech closer to natural, speaker-faithful delivery.
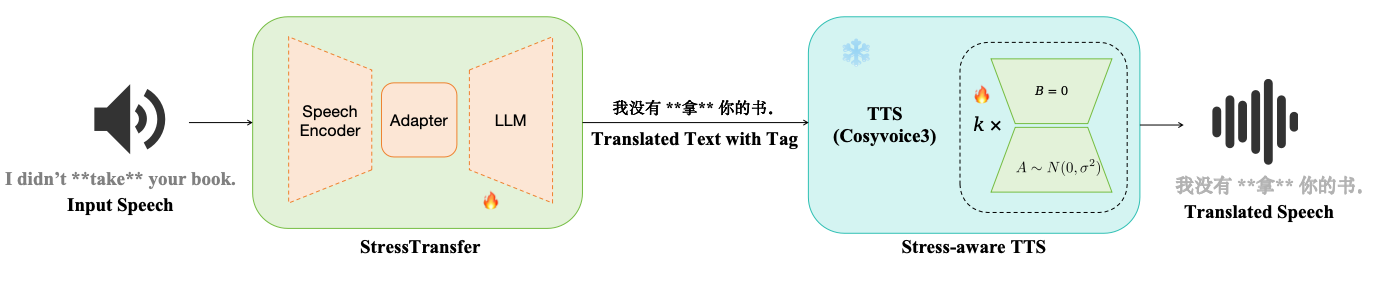
The overall architecture of our proposed stress-aware S2ST system. From StressPreserve S2ST.
TTS & Voice Synthesis
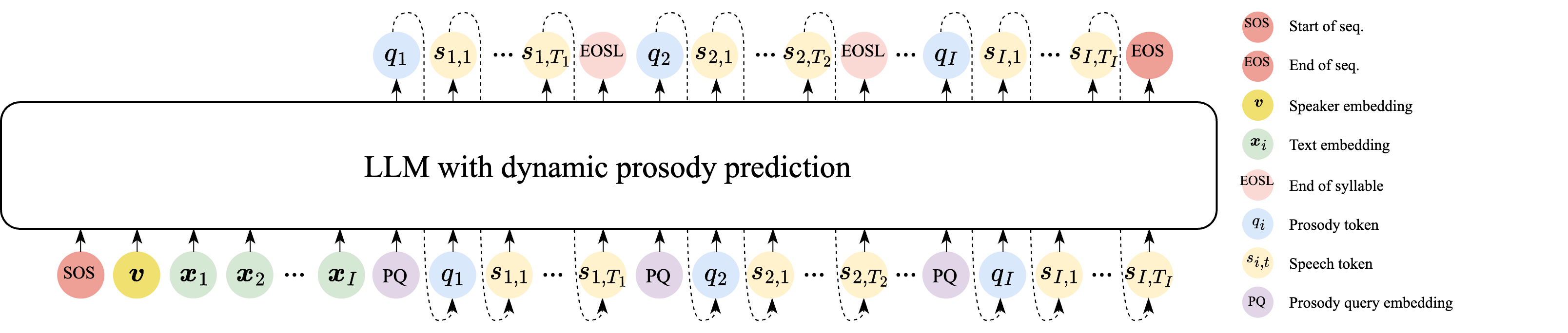
Dynamic Prosody Prediction
Dynamic Prosody Prediction in LLM-based TTS for Improving Speaker Similarity
This work proposes dynamic prosody prediction in LLM-based TTS, where prosody for each syllable is predicted conditioned on previously generated speech, improving speaker similarity and style consistency. It differs from prior static or implicit methods by tightly linking prosody with the evolving synthesized speech.
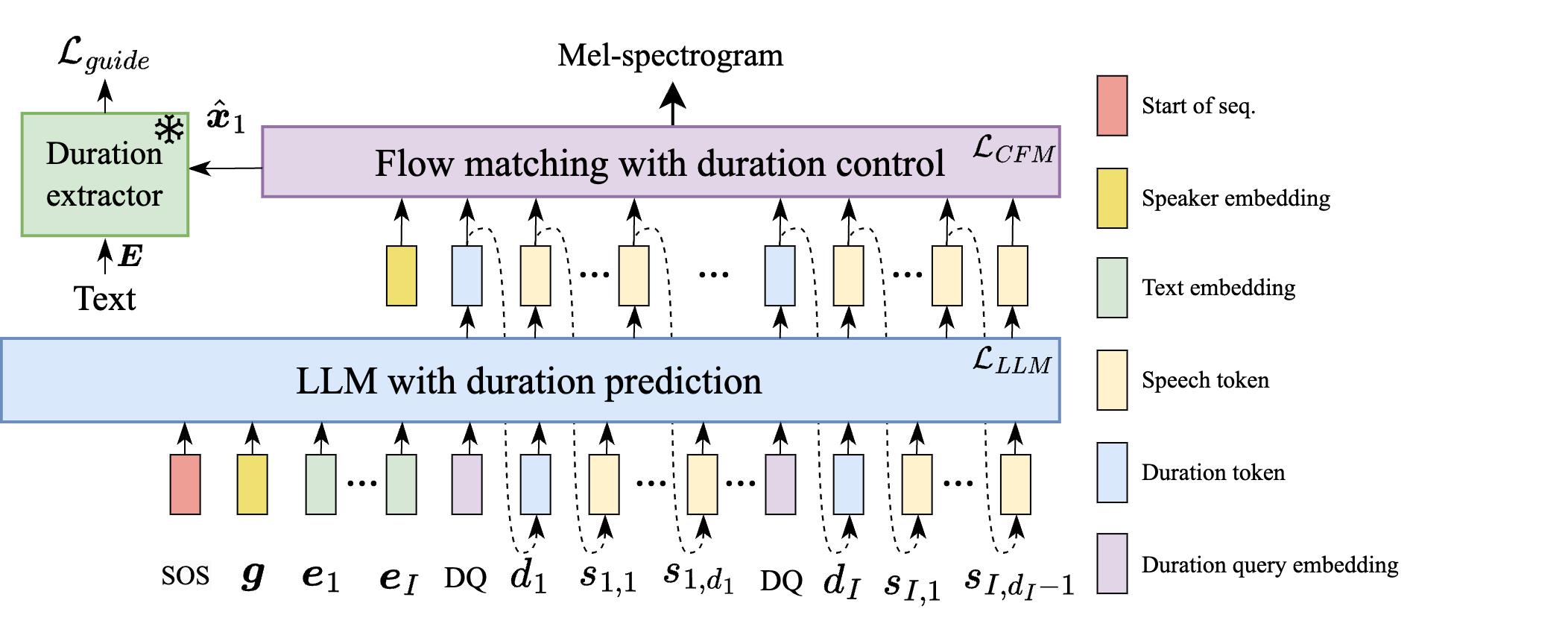
DuraMark
DuraMark: Duration-Embedded Watermarking in LLM-based TTS
DuraMark introduces a novel watermarking method for LLM-based text-to-speech by embedding information in the syllable duration rather than the audio signal. This duration-level watermarking offers superior robustness against neural codec and vocoder attacks compared to traditional signal-level techniques.