Avatars Voices And Edge Speech
Today’s digest spans real-time talking portraits, single-photo 3D face avatars, unified speech-singing synthesis, interpretable emotion control in TTS, and efficient neuromorphic speech recognition. It’s a strong mix of expressive generation and practical speech systems for interactive AI.

Teaser image demonstrating 3D Face Avatar generation from a single unconstrained photo using SplatShot. From SplatShot.
Talking Avatars & Digital Humans

Reference-Guided Deep Compression VAEs
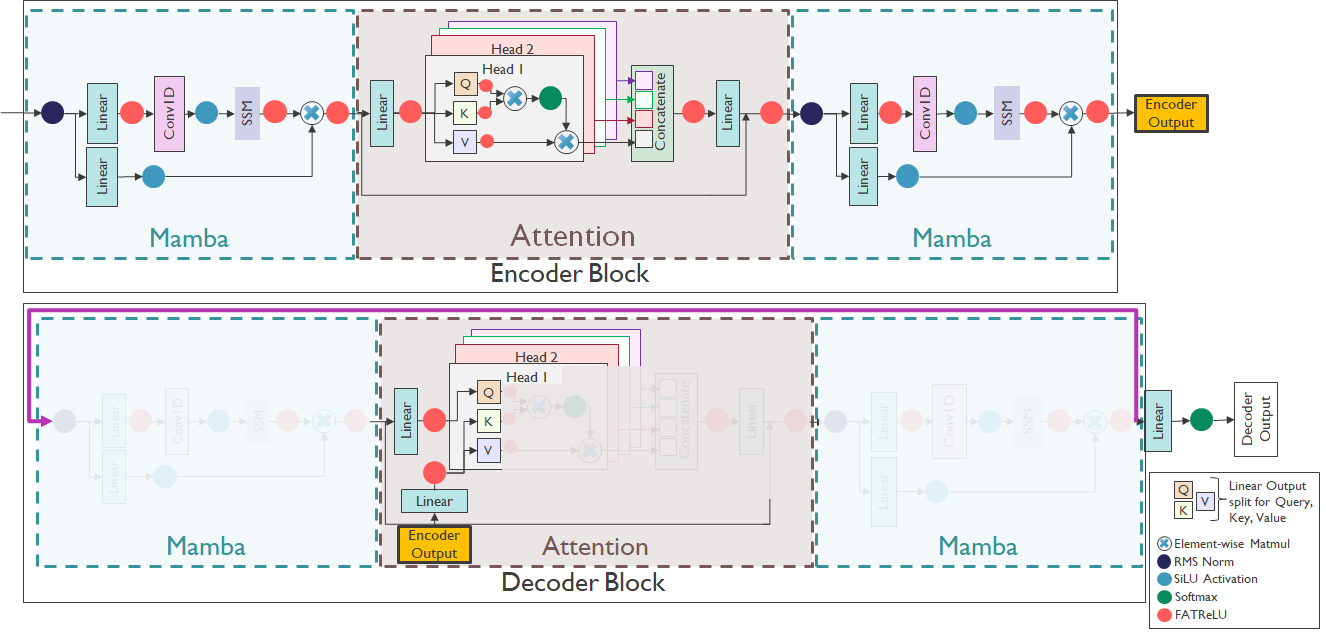
Real-Time Generation of Streamable Talking Portrait Video with Reference-Guided Deep Compression VAEs
A new framework for real-time, streamable talking portrait video generation using speech audio and reference images. It uses a reference-guided causal video VAE to compress dynamics efficiently, enabling high-quality, low-latency video suited for interactive AI communication.
SplatShot
Splatshot: 3D Face Avatar Generation from a Single Unconstrained Photo
SplatShot is a training-free method that combines 3D Gaussian Splatting with diffusion models to generate photorealistic 3D face avatars from a single photo. It uses 3D feedback during diffusion to ensure multi-view consistency and faithful identity without task-specific training.
TTS & Voice Synthesis
UniVocal
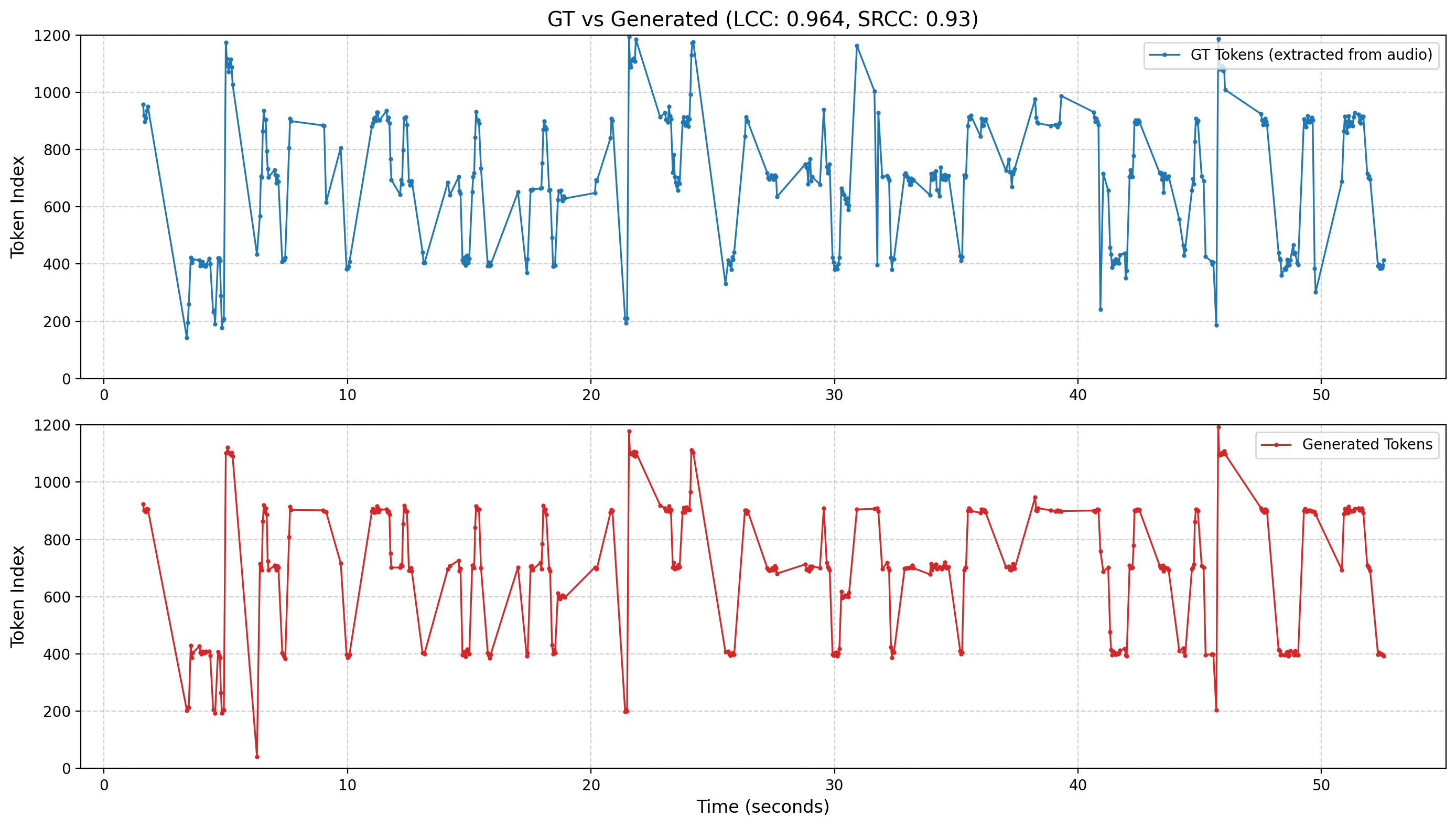
UniVocal: Unified Speech-Singing Code-Switching Synthesis
UniVocal unifies speech and singing synthesis into one model that switches automatically based on text cues, without explicit tags. Using a refined pitch token and a staged learning approach, it enables smooth speech-singing code-switching driven purely by textual semantics.
Sparse Autoencoders for Emotion Control
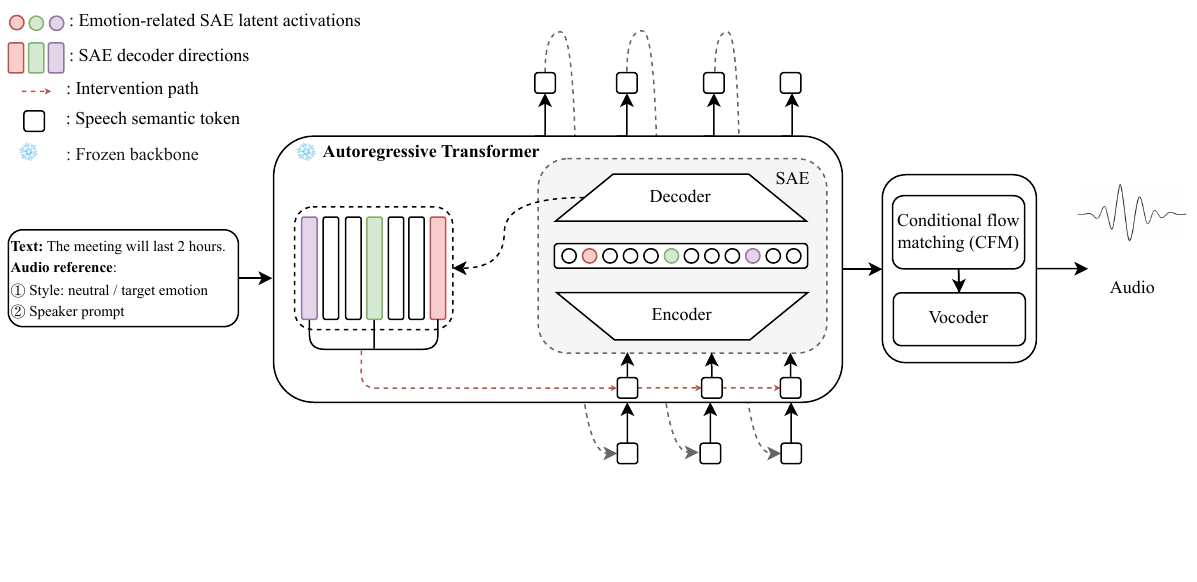
Sparse Autoencoders for Interpretable Emotion Control in Text-to-Speech
This paper introduces sparse autoencoders to identify and steer interpretable latent features related to emotion in LLM-based text-to-speech systems, enabling fine-grained bidirectional emotional control by intervening on a small subset of model internals rather than relying on global or external signals.