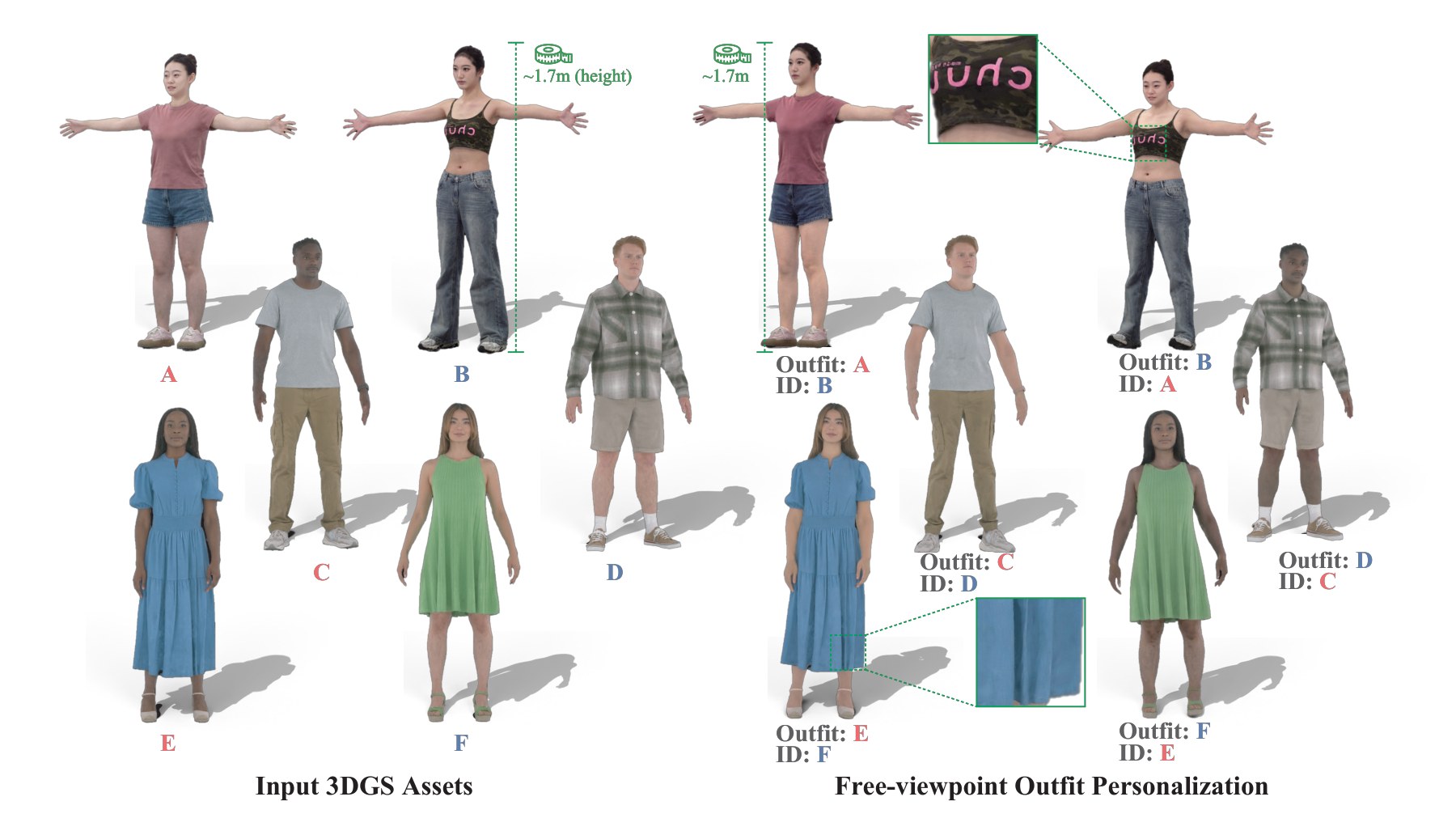
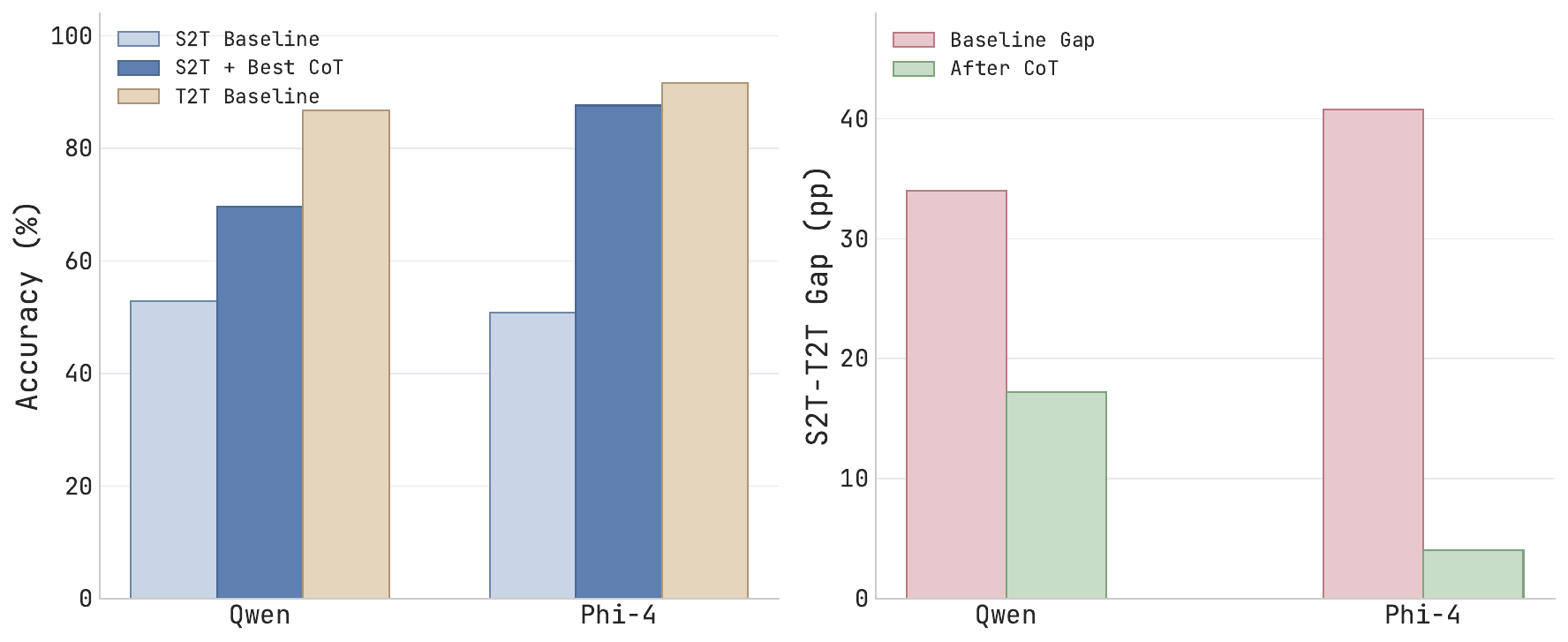
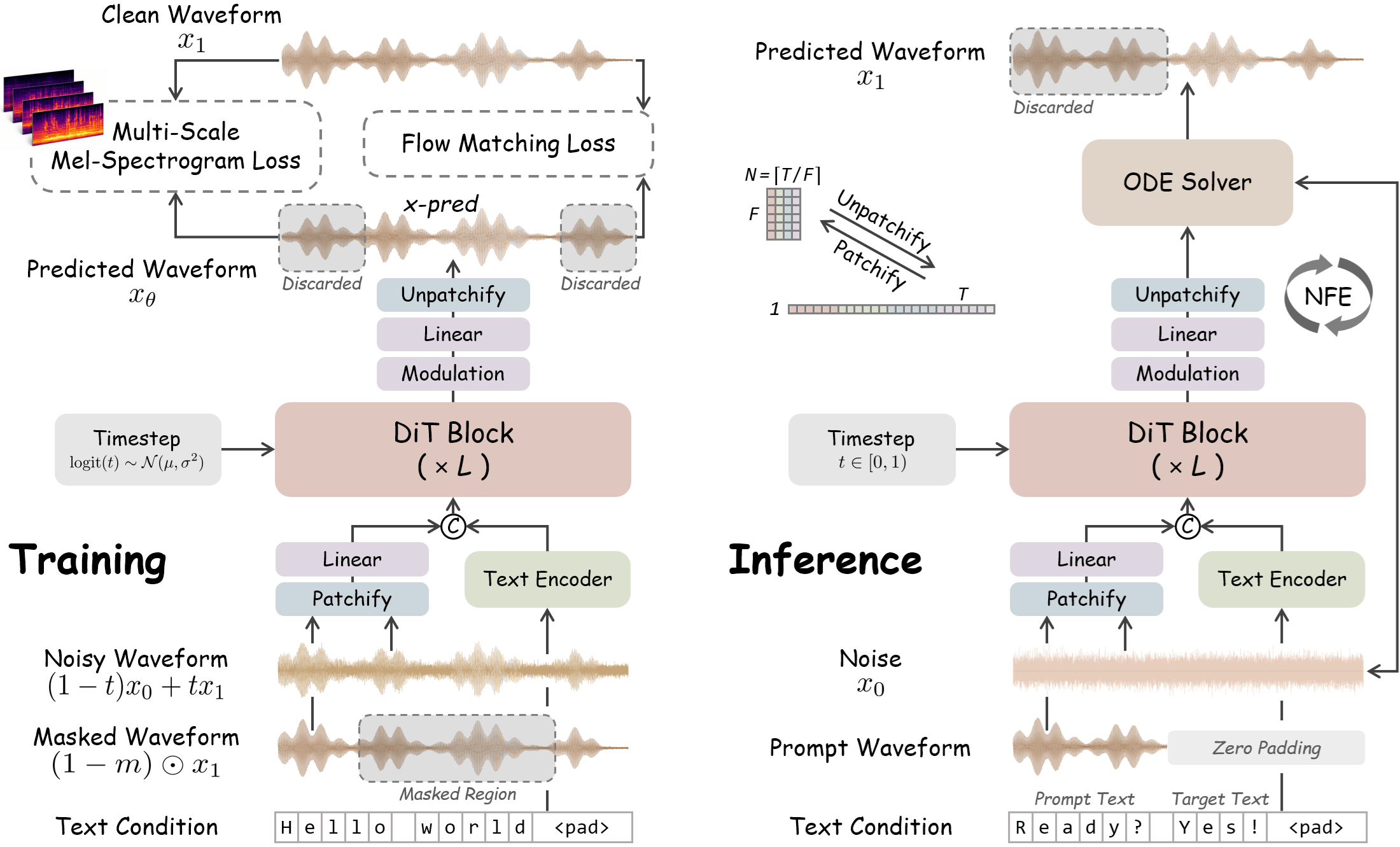
Talking Avatars Get Real
Today’s digest spans full-duplex speech-motion avatars, portrait animation, outfit-personalized 3D humans, speech-LLM reasoning fixes, and raw-waveform zero-shot TTS. A strong day for more natural voices, more expressive bodies, and better spoken reasoning.
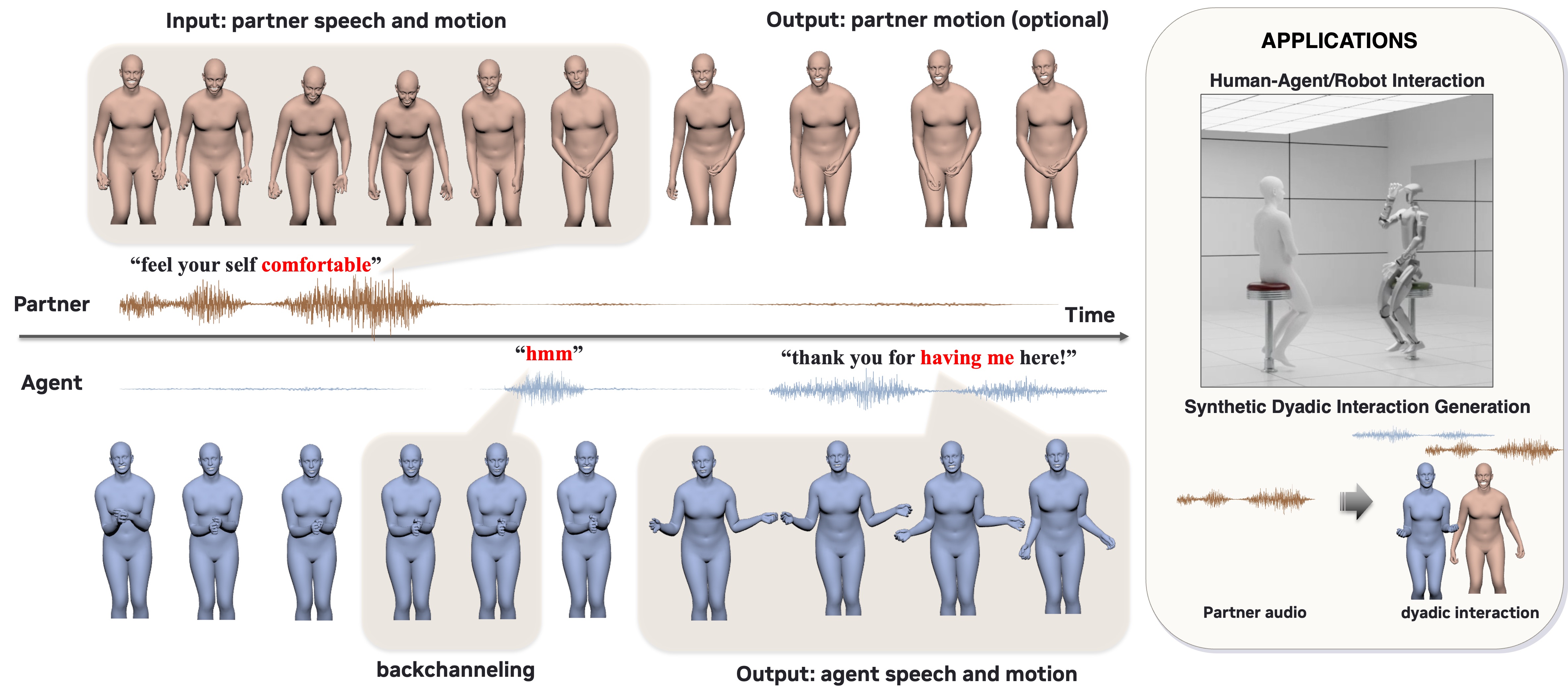
DyaPlex overview: partner speech and motion as input; the agent listens, backchannels, and responds with synchronized speech and motion; application scenarios for human-agent/robot interaction and synthetic dyadic interaction generation. From DyaPlex.
Talking Avatars & Embodied Interaction
DyaPlex
DyaPlex: Full-Duplex Speech-Motion Model for Dyadic Interaction
DyaPlex is a streaming full-duplex model that generates synchronized speech and full-body motion for dyadic interactions. It perceives and responds to both partners' speech and motion in real time, enabling natural continuous communication with improved multi-modal coherence for conversational AI agents.

Mamba-Enhanced Implicit Motion
Mamba-Enhanced Implicit Motion Learning for Audio-Driven Portrait Animation
A two-stage implicit motion learning framework for audio-driven portrait animation. It predicts detailed motion features without explicit landmarks using Mamba-enhanced diffusion, delivering high-quality, coherent talking-head and gesture animations from a single image and audio.