Voice AI Goes Real Time
Today’s digest spans streaming speech agents, emotional text-to-speech control, robust audio-visual recognition, and a new reference-free way to evaluate ASR. Together, these papers push conversational systems toward more responsive, expressive, and reliable voice interaction.
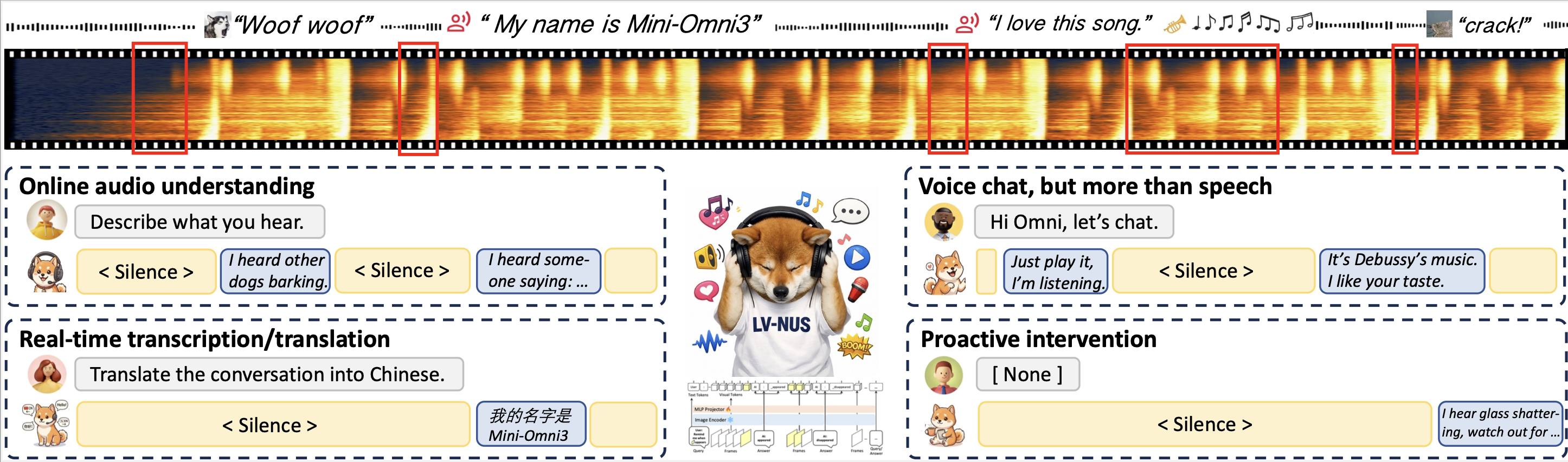
Audio-Interaction teaser showing the next-generation audio-language model concept with streaming brain for interaction. From Audio-Interaction.
SpeechLLMs & Voice Agents
TTS & Voice Synthesis
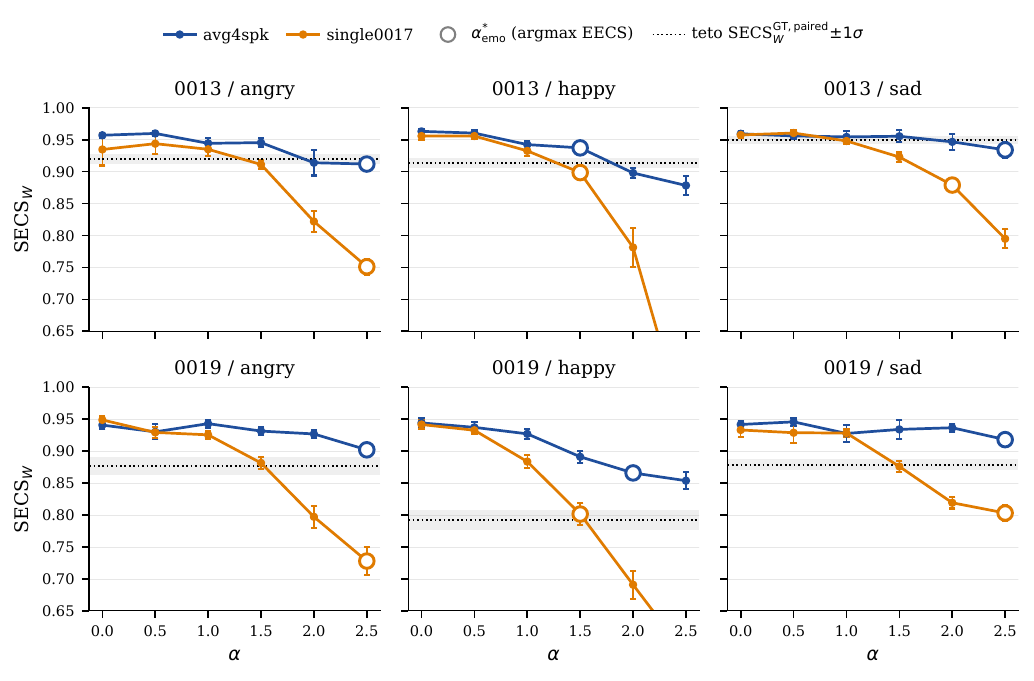
ASR & Audio-Visual Speech
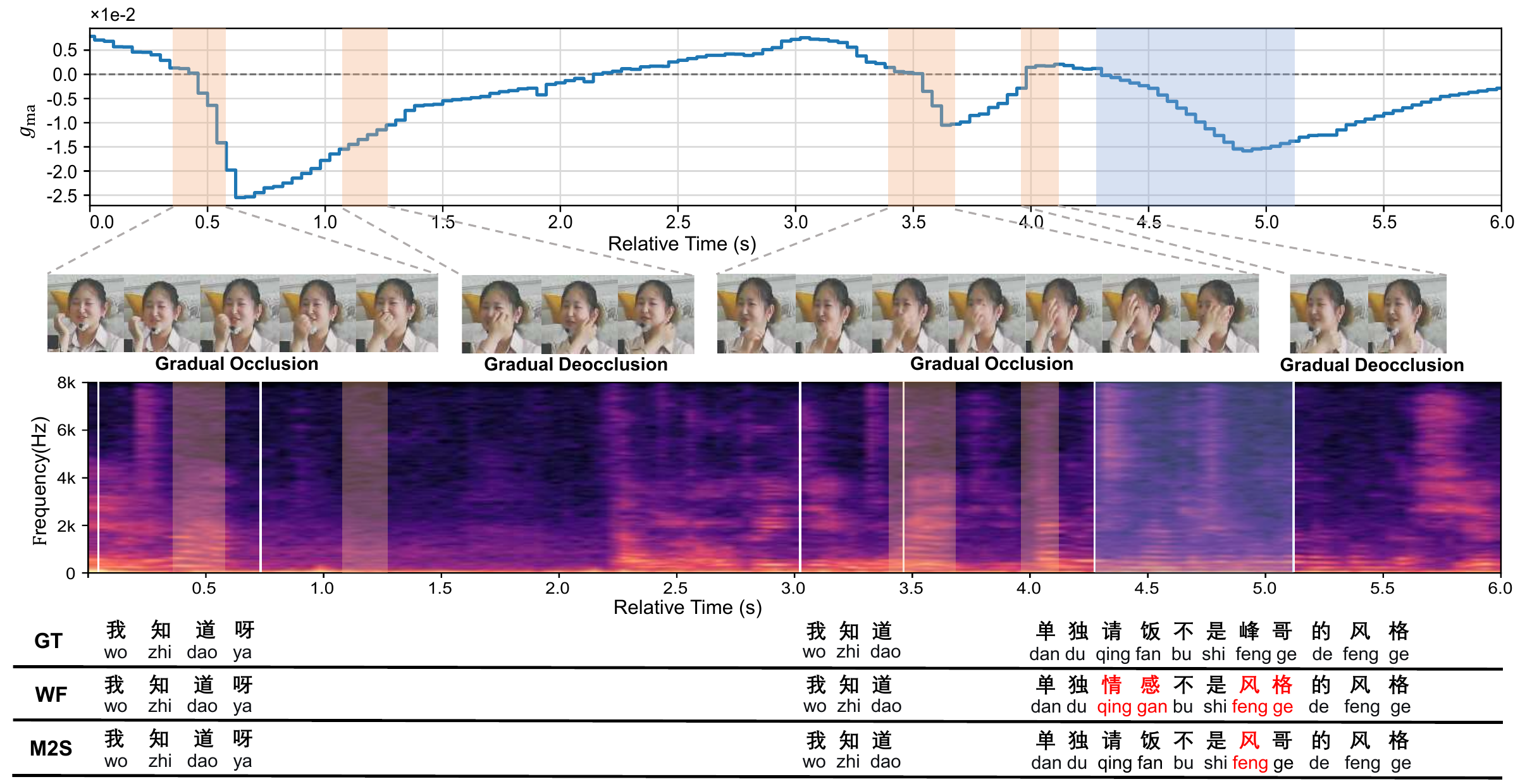
M2S-AVSR
M2S-AVSR: Modality-aware Multi-view Self-supervised Representation for Robust Audio-Visual Speech Recognition
M2S-AVSR improves audio-visual speech recognition by learning view-invariant visual features and adaptively gating visual input based on quality and timing. It boosts robustness against viewpoint changes, occlusion, and asynchrony, and introduces a real-world multi-view AV dataset for challenging environments.
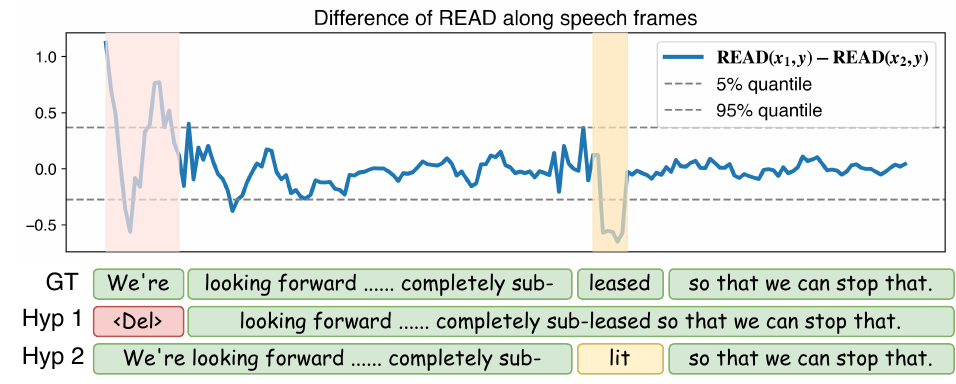
READ
Read What You Hear: Reference-Free Hypotheses Evaluation with Acoustic Discrepancy
READ is a reference-free metric that evaluates ASR hypotheses by measuring acoustic discrepancy between speech and text using a pretrained autoregressive TTS model. It uniquely grounds evaluation in the speech signal, enabling effective hypothesis refinement and error localization without extra training.