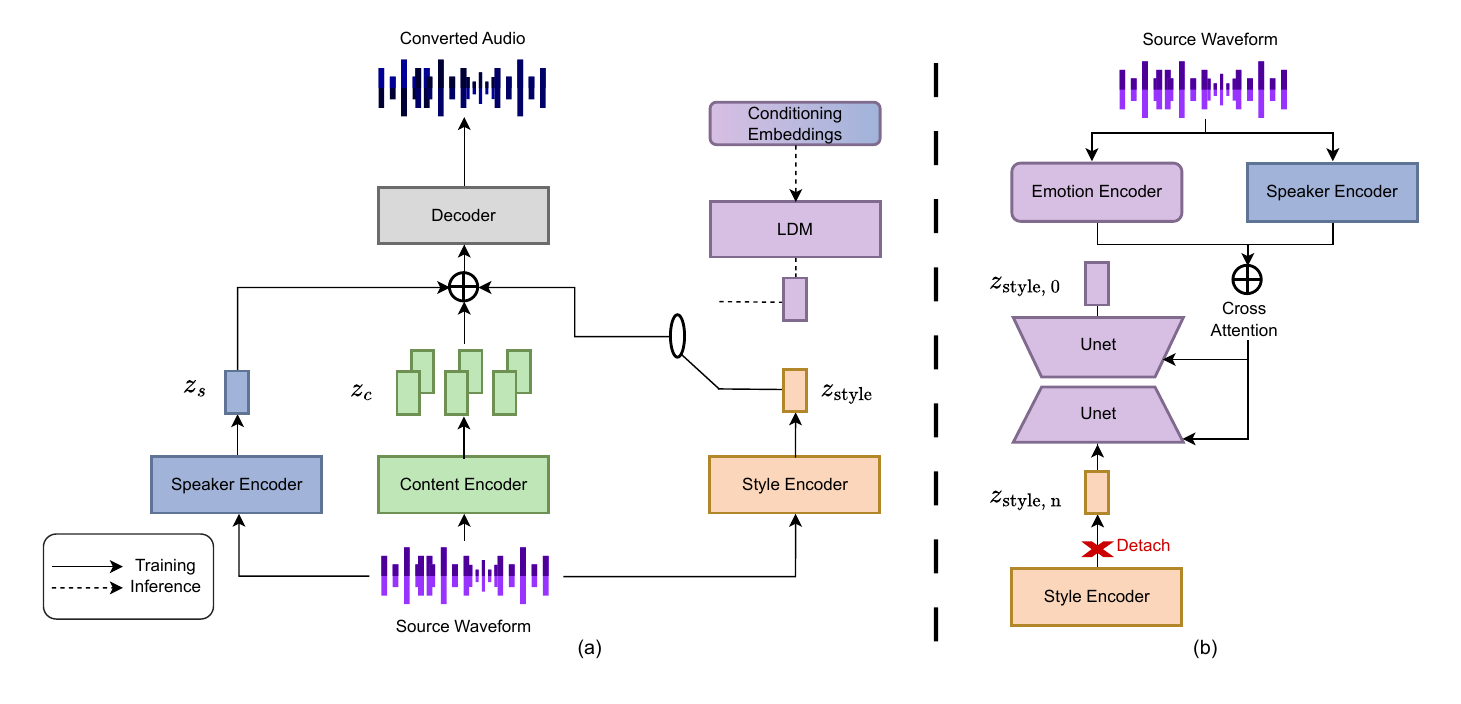
Smarter Voices, Fewer Errors
Today’s digest spotlights more expressive speech synthesis, emotion conversion, and better ASR reliability for voice agents. From image-based TTS and continuous latent speech models to hallucination steering in Whisper, the focus is on making spoken AI sound better and fail less.
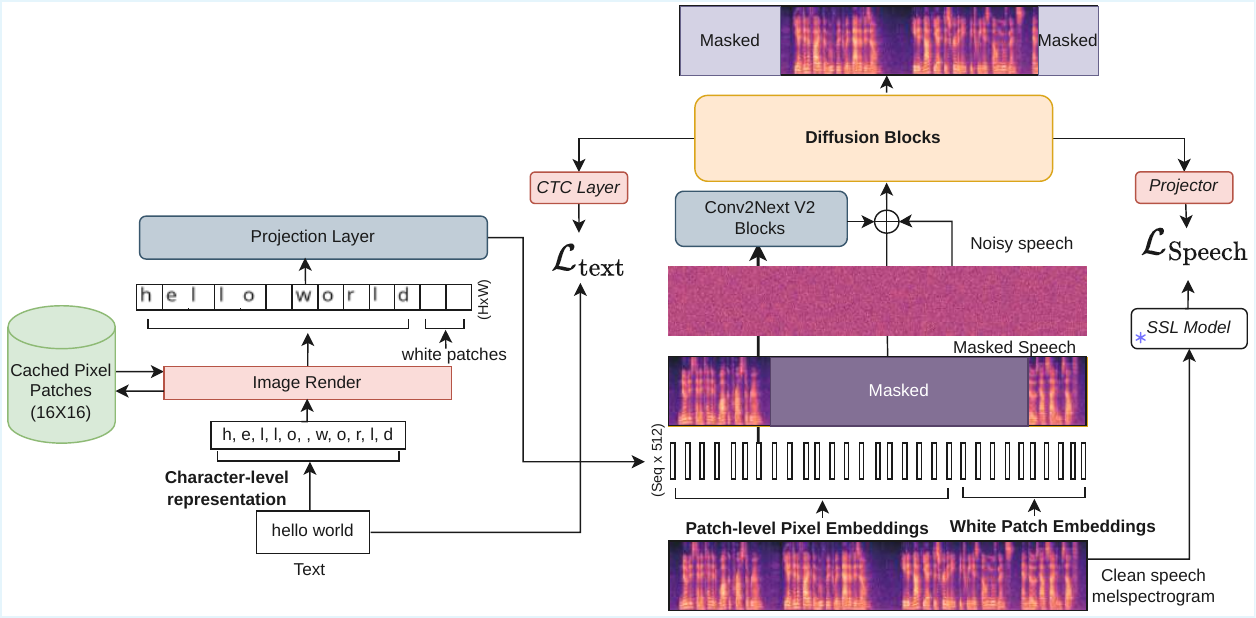
Overview of the proposed method. From Pixel-TTS.
TTS & Voice Synthesis
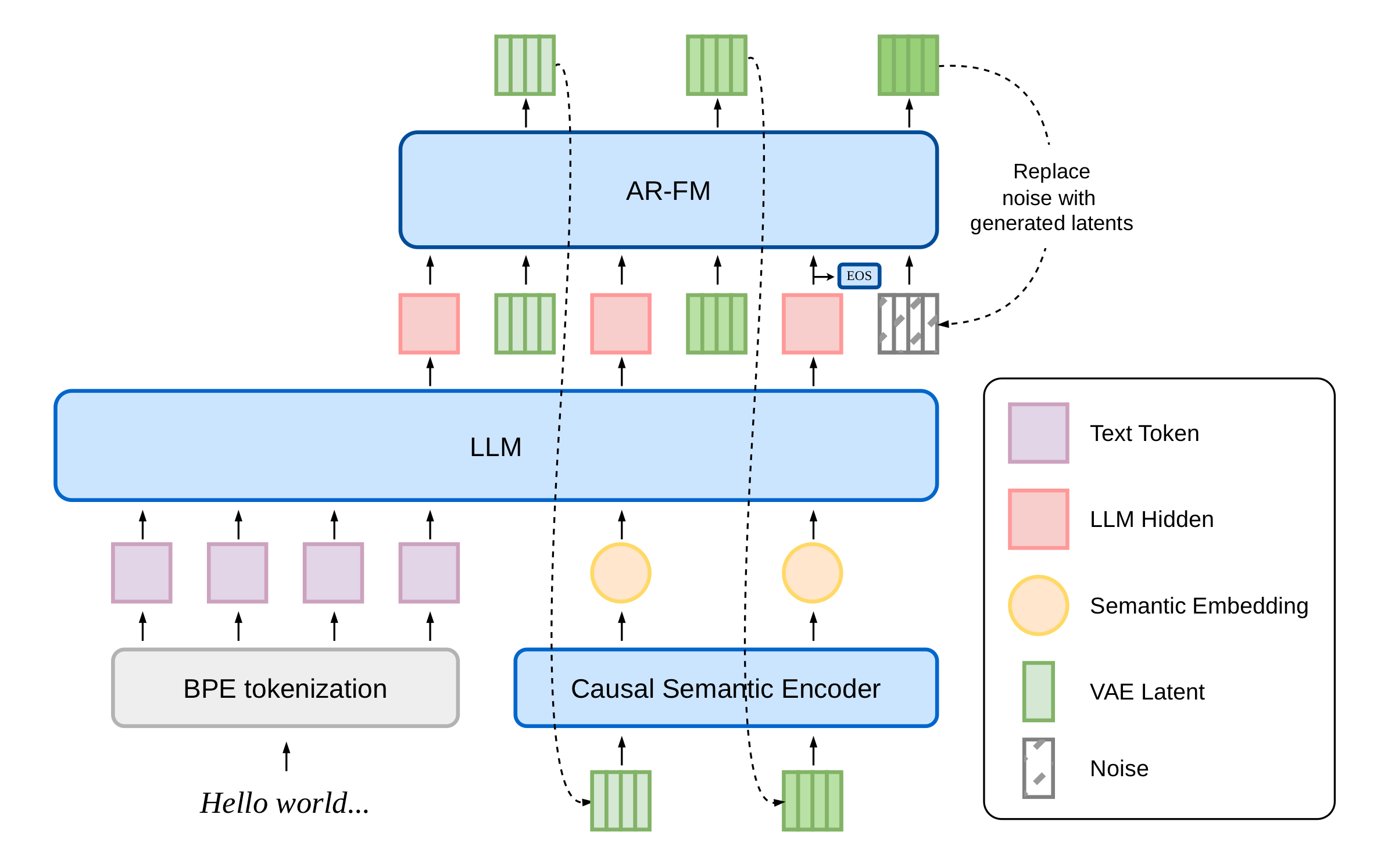
dots.tts
dots.tts Technical Report
dots.tts is a 2B-parameter continuous autoregressive text-to-speech model that generates speech in a semantically structured continuous latent space. Innovations include full-history conditioning and self-corrective post-training for robust, expressive, and low-latency multilingual speech.
Pixel-TTS
Pixel-TTS: Image based Text Rendering for Robust Text-to-Speech
Pixel-TTS innovates text-to-speech by rendering text as images, enabling robust and visually grounded embeddings that improve synthesis quality, accelerate training, and enhance zero-shot multilingual generalization without needing embedding matrix expansion.