Talkers Move and Speak Better
Today’s digest spans expressive talking heads, stylized co-speech gesture generation, and code-mixing speech tools for better downstream ASR. The common thread: tighter control over how synthetic voices, faces, and motions carry meaning.
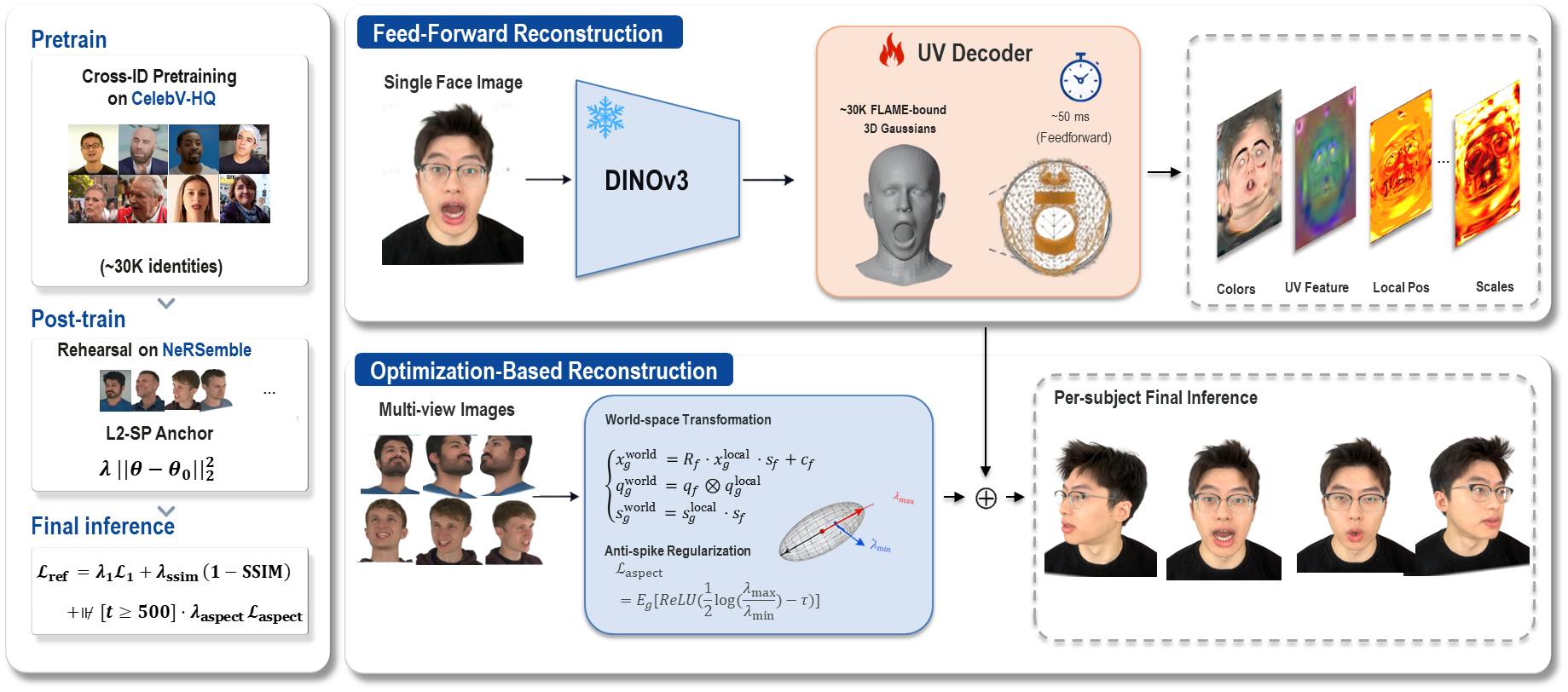
SpatialAvatar-0 method overview illustration. From SpatialAvatar-0.
Talking Avatars & Digital Humans
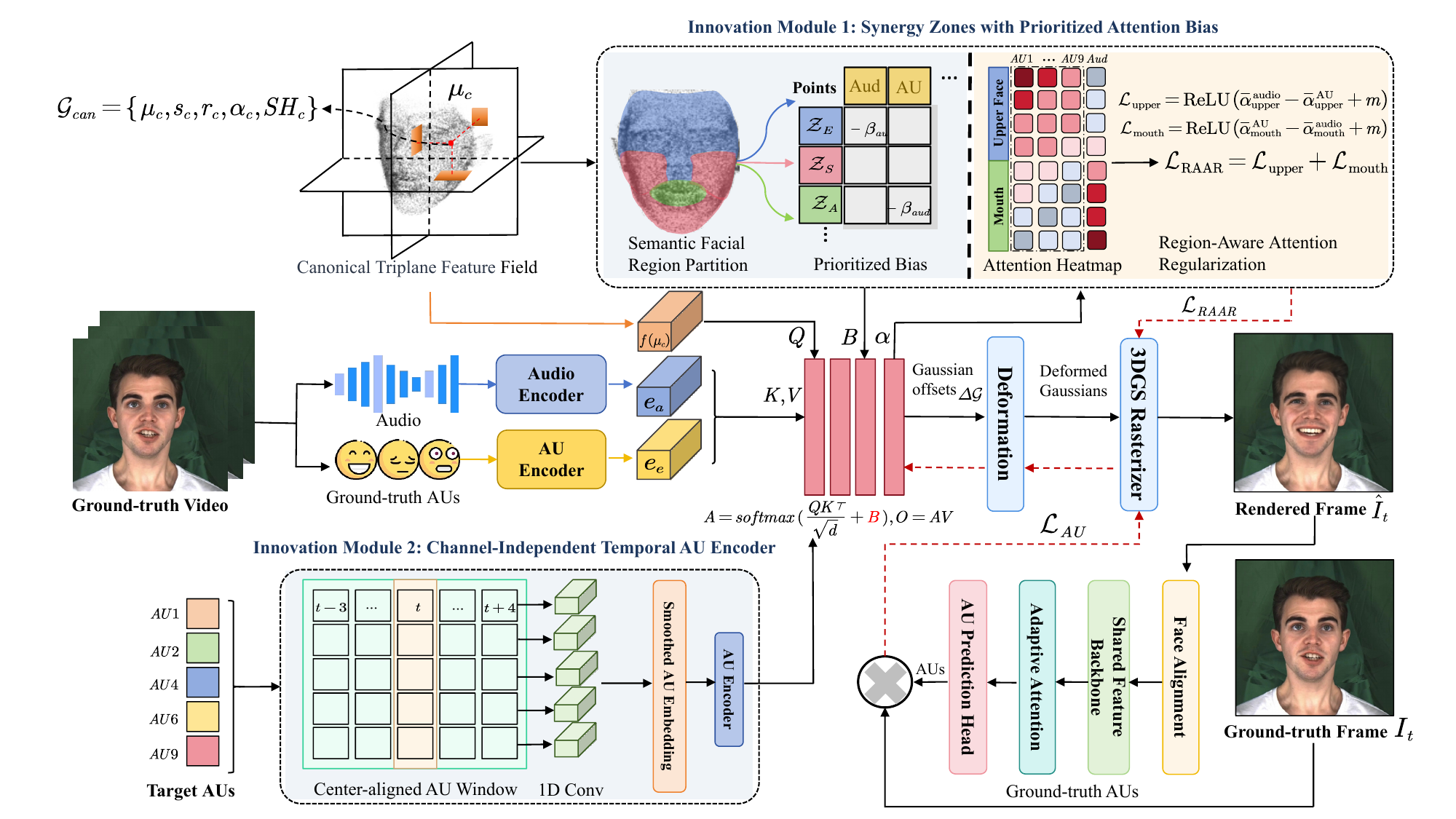
EmoZone-Talker
EmoZone-Talker: Regional Semantic Control of Audio-Driven 3DGS Talking Heads via Facial Action Units
EmoZone-Talker enables fine-grained, anatomically interpretable control of facial expressions in audio-driven 3D Gaussian Splatting talking heads by disentangling spatial and temporal interactions of speech and facial Action Units, improving expression realism, controllability, and lip-sync accuracy.
SpatialAvatar-0
SpatialAvatar-0: High-Quality 4D Head Avatar with Multi-Stage Reconstruction
SpatialAvatar-0 creates high-quality 4D head avatars from few portraits by unifying feed-forward prediction and per-subject refinement on a shared Gaussian-splat FLAME-mesh representation. It enables strong zero-shot generalization and faster refinement by preserving spatial layout and Gaussian count throughout.