Reliable voice AI for multi-speaker dialogue and long-form synthesis
Today’s digest spans speech LLMs, voice agents, and TTS: from diarization-aware multi-speaker grounding and persona-driven speech role-play to more robust, faster, and longer-form speech generation. The common thread is making voice systems more controllable, consistent, and reliable.
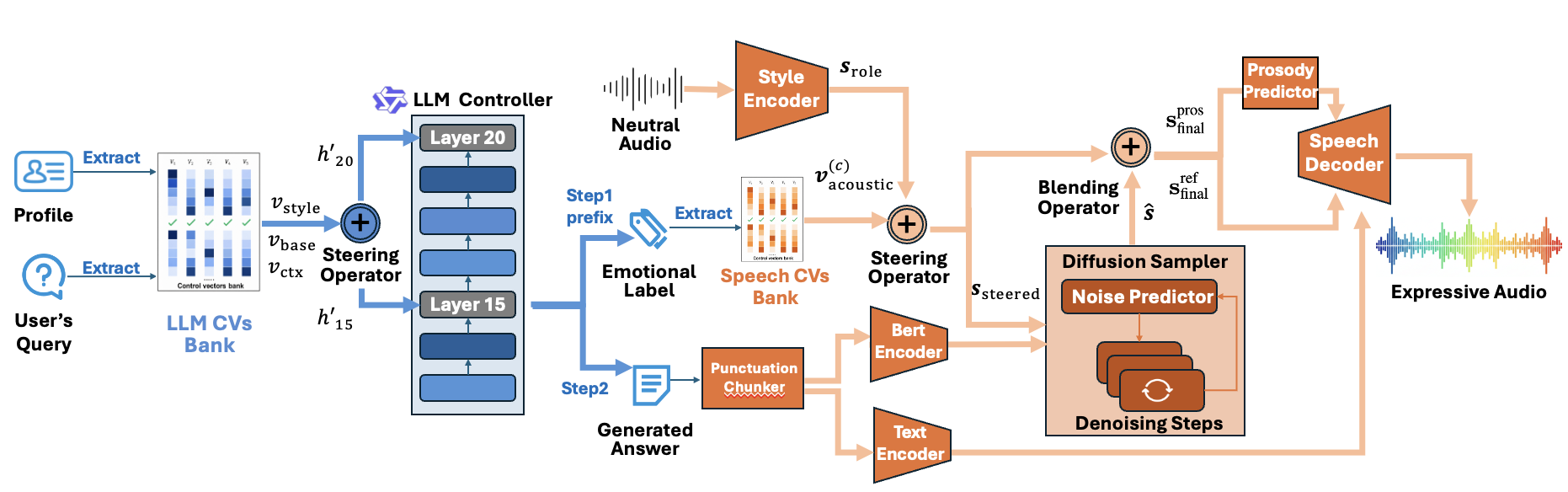
Proposed Decoupled Speech Role-Playing Agent (DeSRPA) framework. A Frozen LLM Controller (left) steers a Frozen StyleTTS~2~ (right) via Inference-Time Control Vectors, injecting personality and acoustic styles directly without parameter updates. From DeSRPA.
SpeechLLMs & Voice Agents
Dixtral
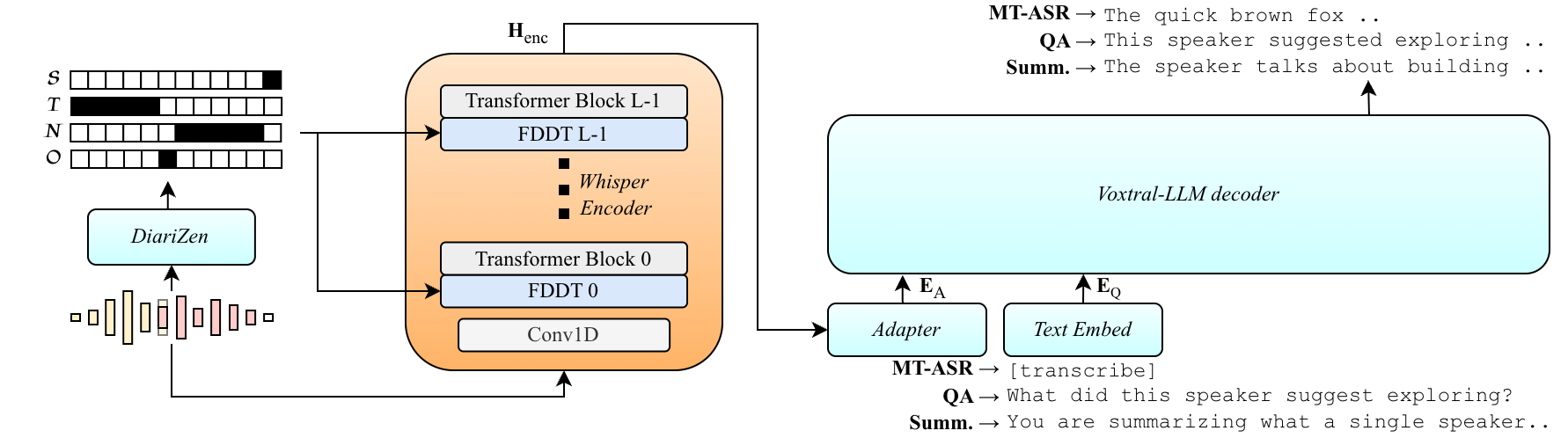
Grounding Spoken LLMs in Multi-Speaker Audio via Diarization Conditioning
Dixtral improves multi-speaker transcription by conditioning the acoustic encoder on diarization masks to isolate speakers, while keeping the language model decoder fixed. This preserves language reasoning and supports zero-shot multi-speaker QA without altering the decoder or output format.
DeSRPA
DeSRPA: Decoupled Speech Role-Playing Agent via Inference-Time Intervention
DeSRPA is a speech role-playing agent framework that decouples persona reasoning from speech rendering at inference. It uses frozen LLM and TTS models steered by control vectors, enabling scalable, training-free character adaptation with enhanced personality and emotional consistency.
TTS & Voice Synthesis
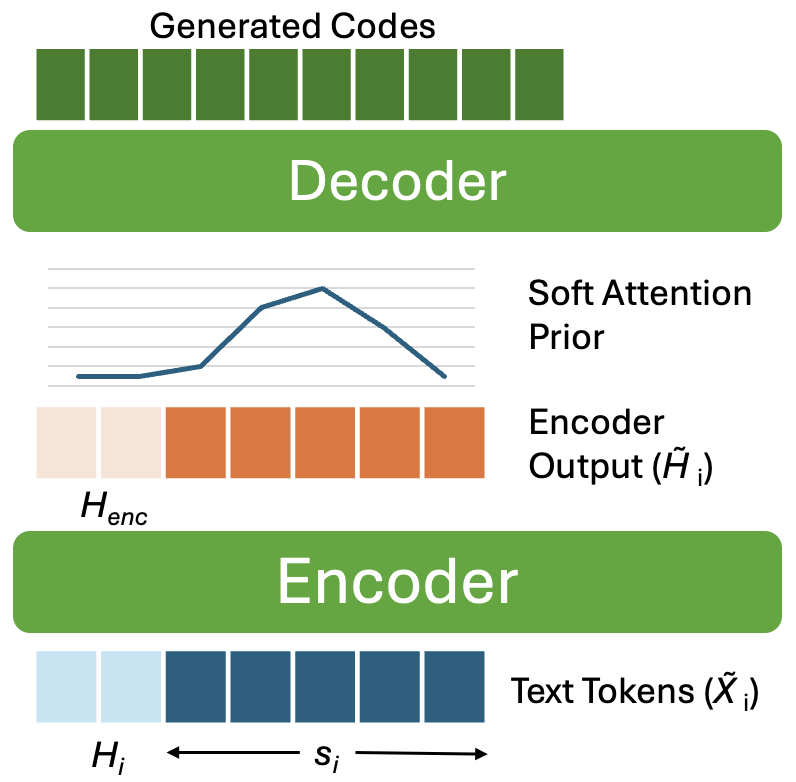
MagpieTTS-LF
MagpieTTS-LF: Inference-Time Long-Form Speech Generation Without Training on Long-Form data
MagpieTTS-LF improves long-form speech synthesis without retraining by maintaining context and guiding attention across sentence chunks. It combines stateful chunk generation, soft attention priors, and history-aware text encoding to enhance prosodic continuity, speaker consistency, and boundary smoothness.
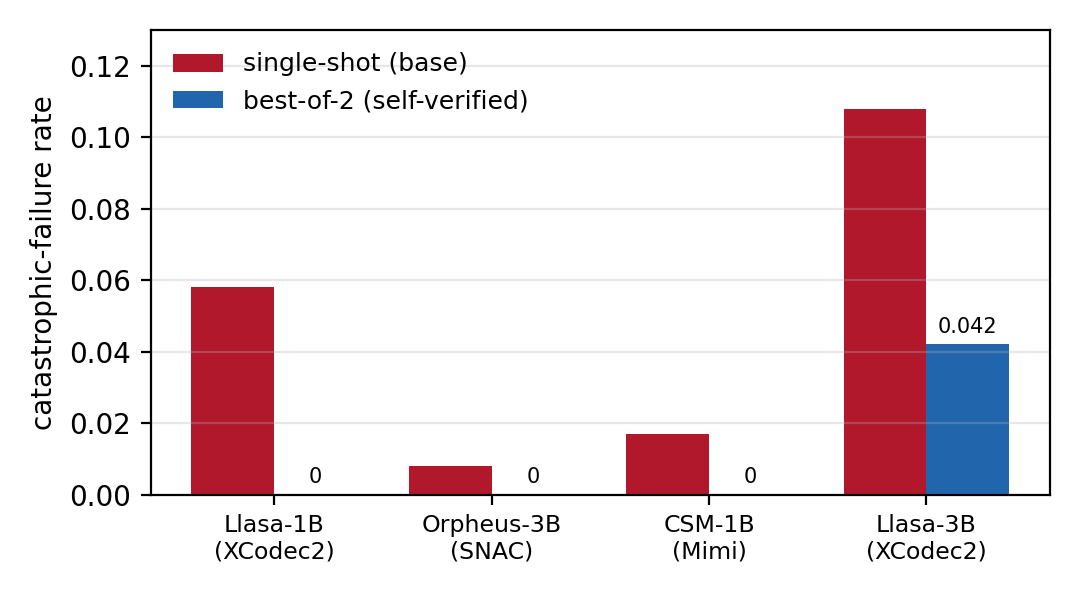
Reliable Neural-Codec TTS
Reliable Neural-Codec Text-to-Speech by ASR Self-Verification and Distillation: Near-Zero Catastrophic Failures Across Models and Codecs
Eliminates catastrophic failures in neural-codec text-to-speech by ASR self-verification and distillation, improving single-shot decoding robustness across models and codecs without added inference cost.
MeanFlow Token2Wav
One-Step Token-to-Waveform Generation with MeanFlow in Latent Space
This paper presents a one-step Token-to-Waveform synthesis using MeanFlow in latent space, greatly speeding up generation while keeping quality high. It replaces costly iterative decoding with a single latent prediction, plus novel refinements to improve output fidelity without slowing inference.