Real-Time Speech for Conversational AI
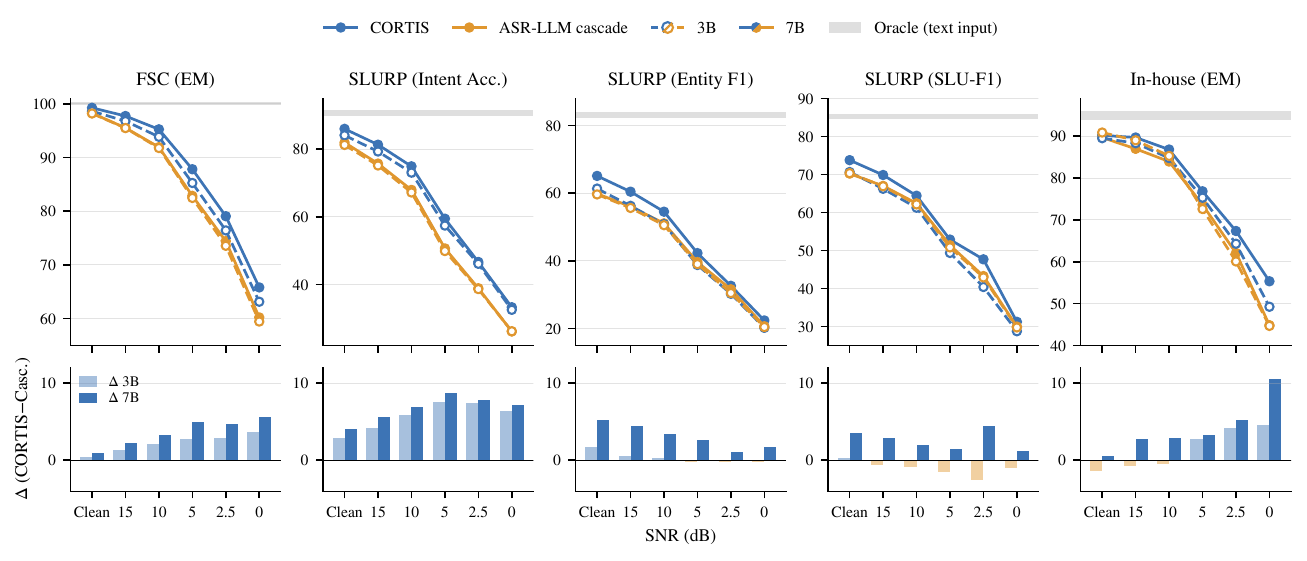
Today’s digest spotlights low-latency speech generation, prosody-aware voice conversion, and robust spoken-language agents. The common thread: speech systems that sound better, respond faster, and work more reliably in live conversation.
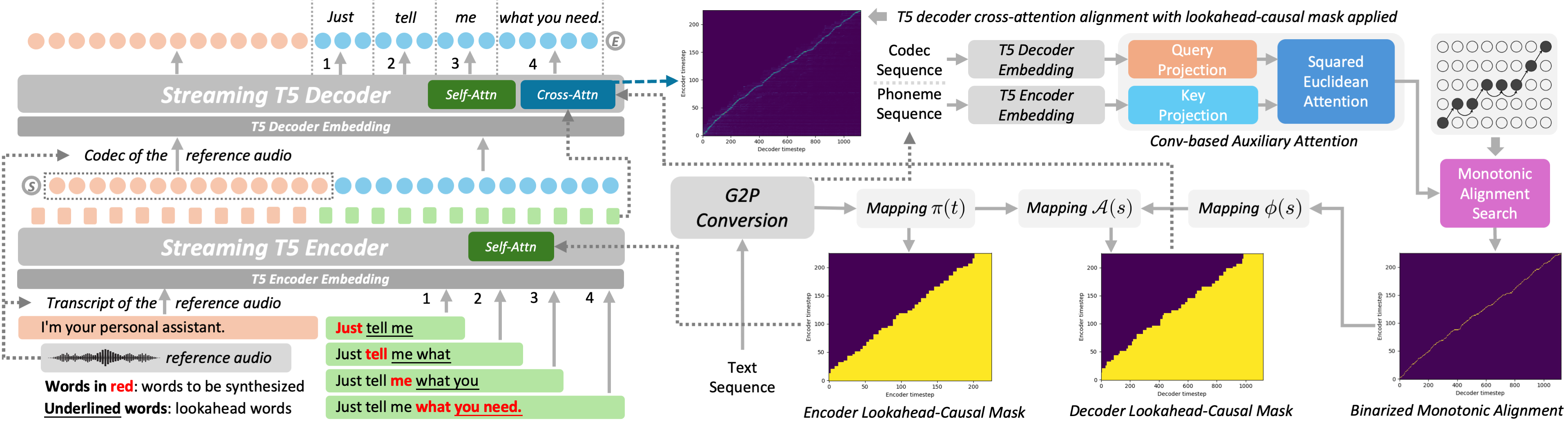
Model Overview of S5-TTS showing the streaming architecture and limited lookahead mechanism. From S5-TTS.
TTS, Prosody & Voice Conversion
S5-TTS
Streaming T5-based Text-to-Speech Synthesis with Limited Lookahead
S5-TTS enables streaming, low-latency text-to-speech synthesis by generating speech word-by-word with limited lookahead. It preserves quality and speaker similarity using monotonic alignment and lookahead-causal masks, making it ideal for real-time conversational AI systems.
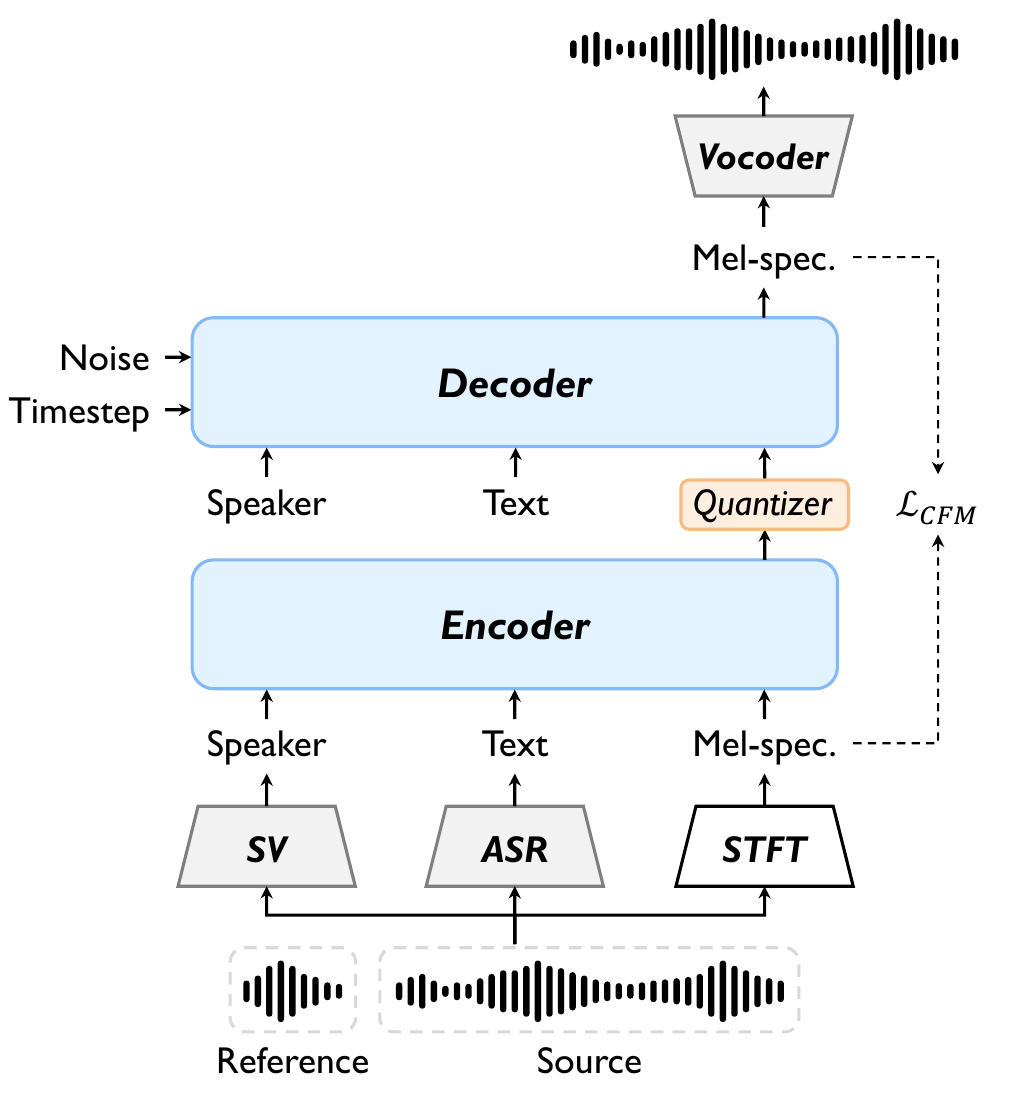
ProsoCodec
ProsoCodec: Prosody-Oriented Speech Codec for Voice Conversion
ProsoCodec is a prosody-oriented speech codec designed for voice conversion. By conditioning on text and speaker embeddings, it isolates and preserves residual prosody, improving prosody preservation and reducing source timbre leakage during voice conversion.