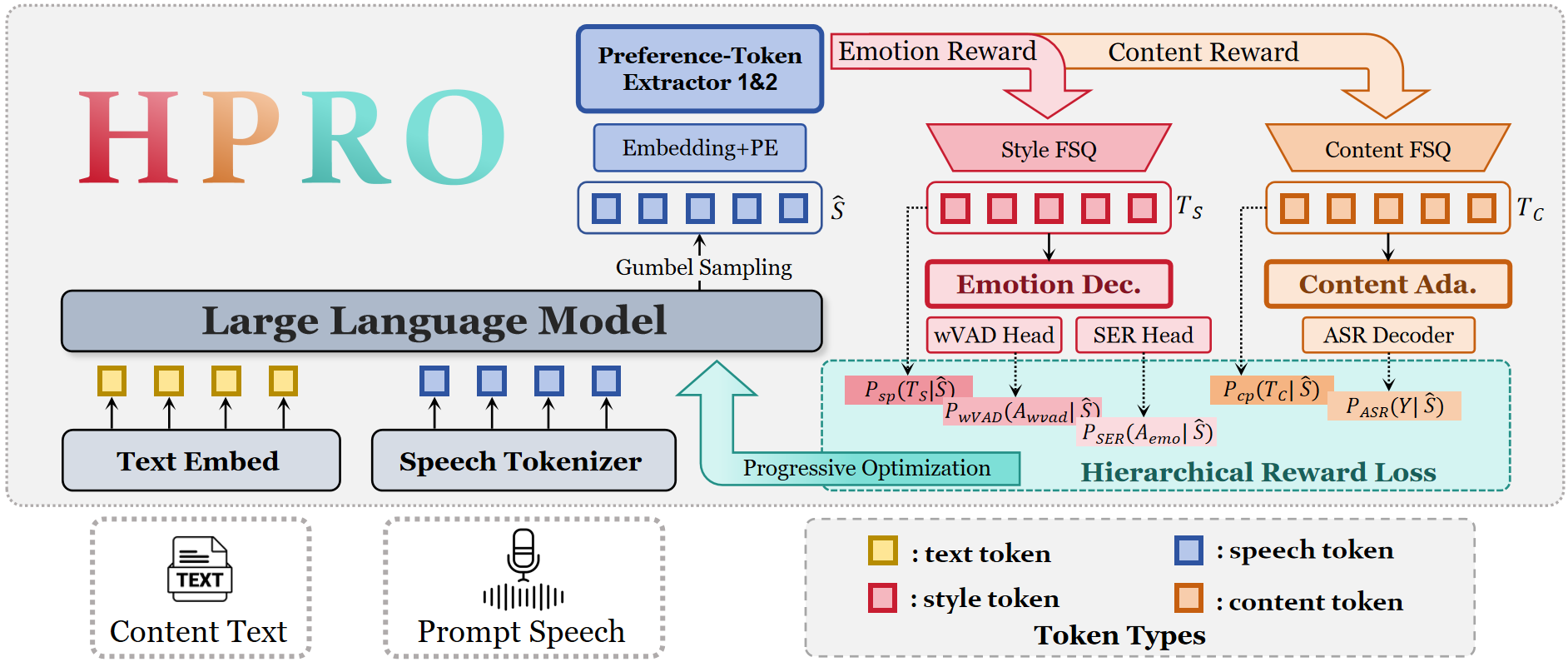
Expressive avatars and emotional speech
Today’s digest spans lifelike facial animation, monocular avatar reconstruction, expressive human motion, and emotional text-to-speech. The common thread: models that make speaking and moving digital humans feel more natural, controllable, and believable.
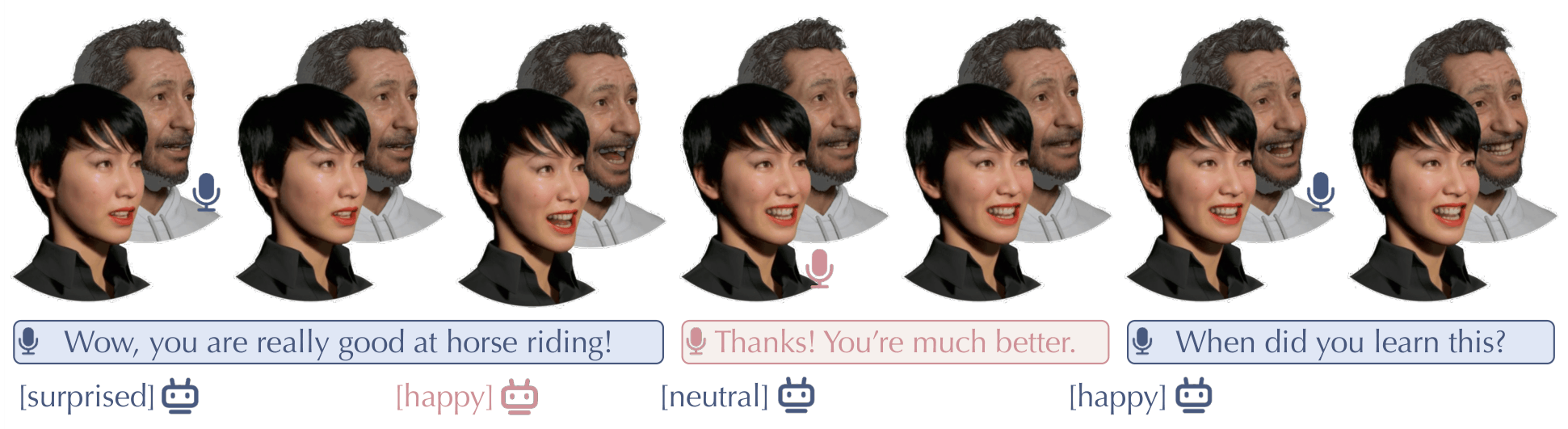
MindFlow teaser image illustrating harmonized cognitive semantics and acoustic dynamics in facial animation of dyadic conversations. From MindFlow.
Talking Avatars & Facial Animation
Digital Humans & Avatar Reconstruction
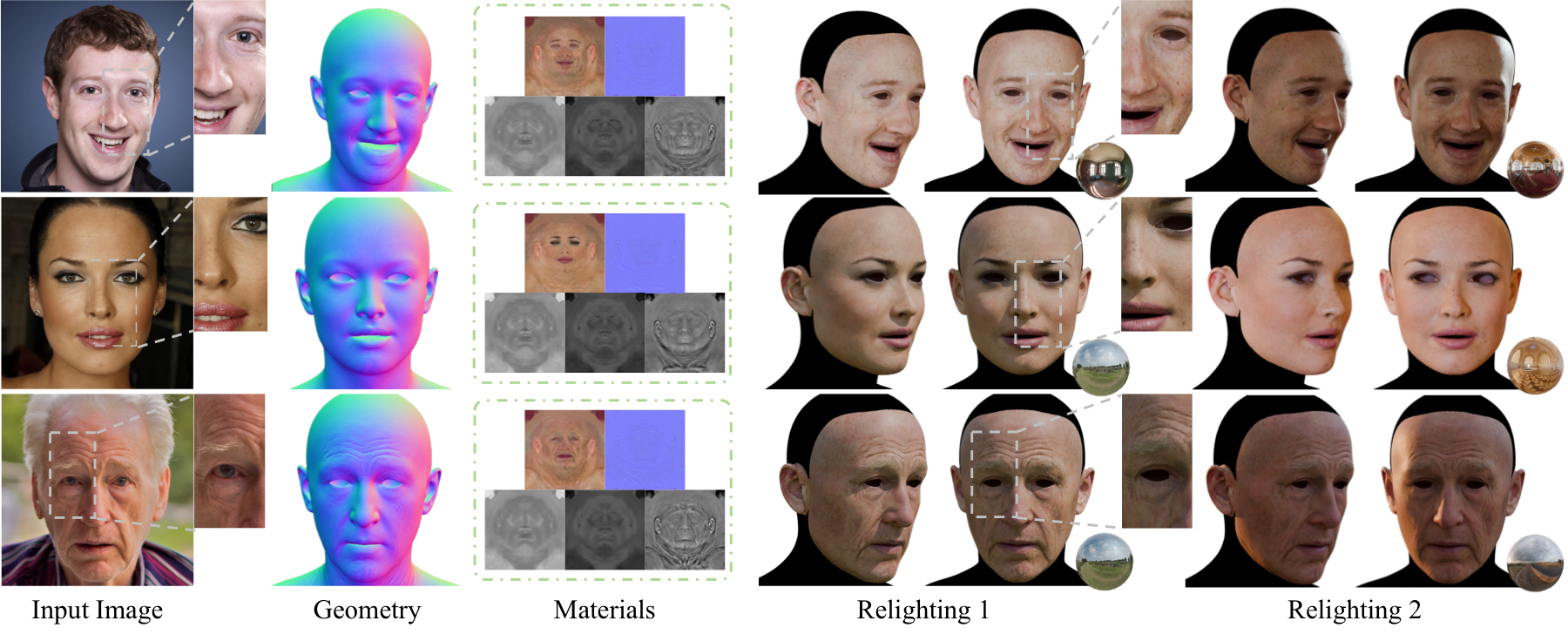
MARCUS-Avatar
Monocular Avatar Reconstruction via Cascaded Diffusion Priors and UV-Space Differentiable Shading
MARCUS-Avatar reconstructs high-quality, relightable 3D face avatars from a single image via cascaded diffusion priors in UV space. It integrates light normalization and differentiable shading to generate physically plausible PBR assets with detailed geometry and robust relighting, trained with limited real 3D scans.

EMOSH
EMOSH: Expressive Motion and Shape Disentanglement for Human Animation
EMOSH presents a new Expressive Human Model that separates body shape from motion for high-fidelity human animation. It prevents shape leakage common in 2D pose methods while capturing detailed facial and gesture motions, enabling expressive, identity-consistent video generation with stable long-term performance.