Talking avatars and voice models push toward more natural, controllable generation
Today’s digest spans fine-tuning-free talking-face synthesis, semantically grounded gesture generation, unified digital human models, and faster streaming TTS. Across speech and avatar generation, the theme is better alignment between meaning, motion, and voice with less latency and more control.
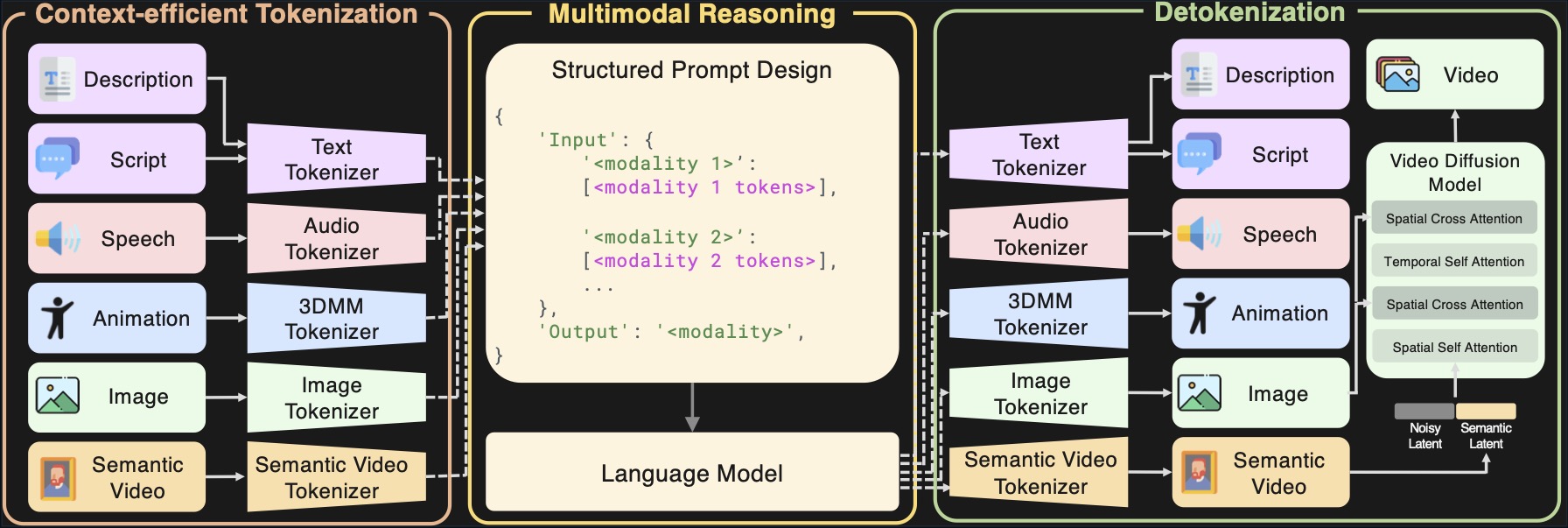
Archon unified multimodal framework overview image. From Archon.
Talking Avatars, Digital Humans & Motion
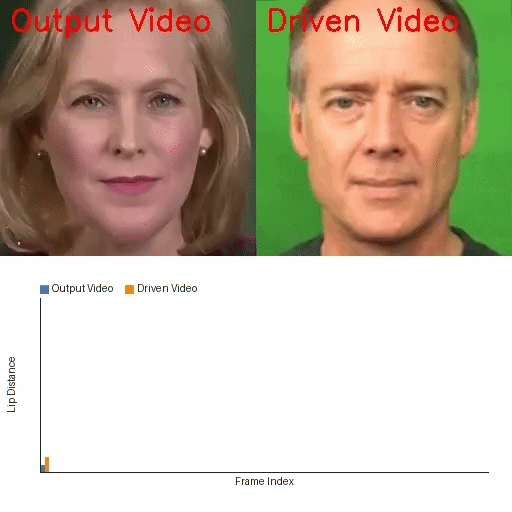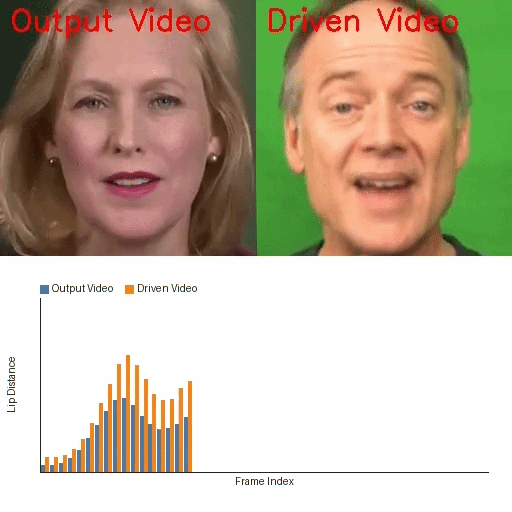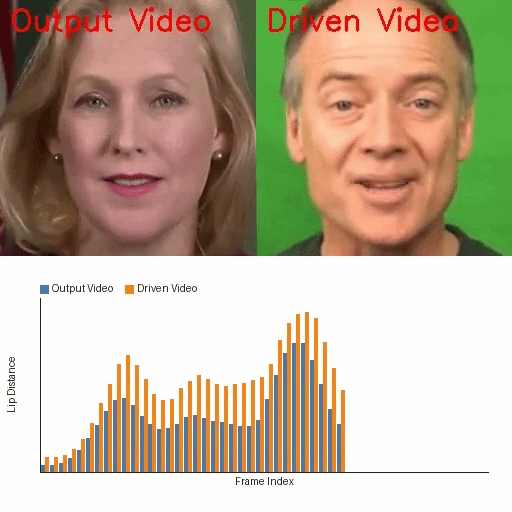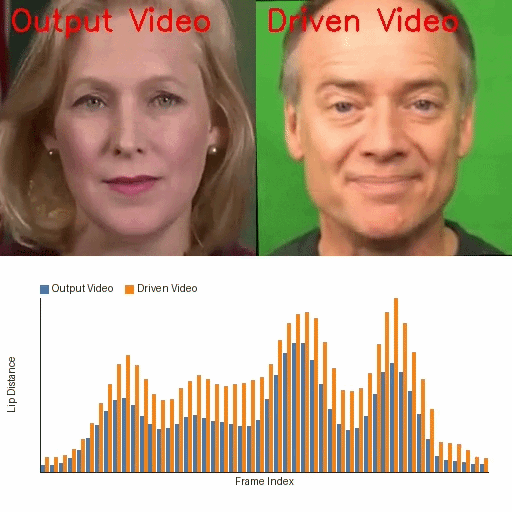
IP-Adapter Fine-Tuning-Free Talking Face
IP-Adapter Is All You Need: Towards Fine-Tuning-Free Diffusion-Based Talking Face Generation
A fine-tuning-free diffusion framework that uses pretrained Stable Diffusion and IP-Adapter for lip-synced talking face generation. It addresses identity drift, lip-sync accuracy, and temporal flicker with parameter-free modules, enabling scalable and efficient talking face synthesis without costly model training.
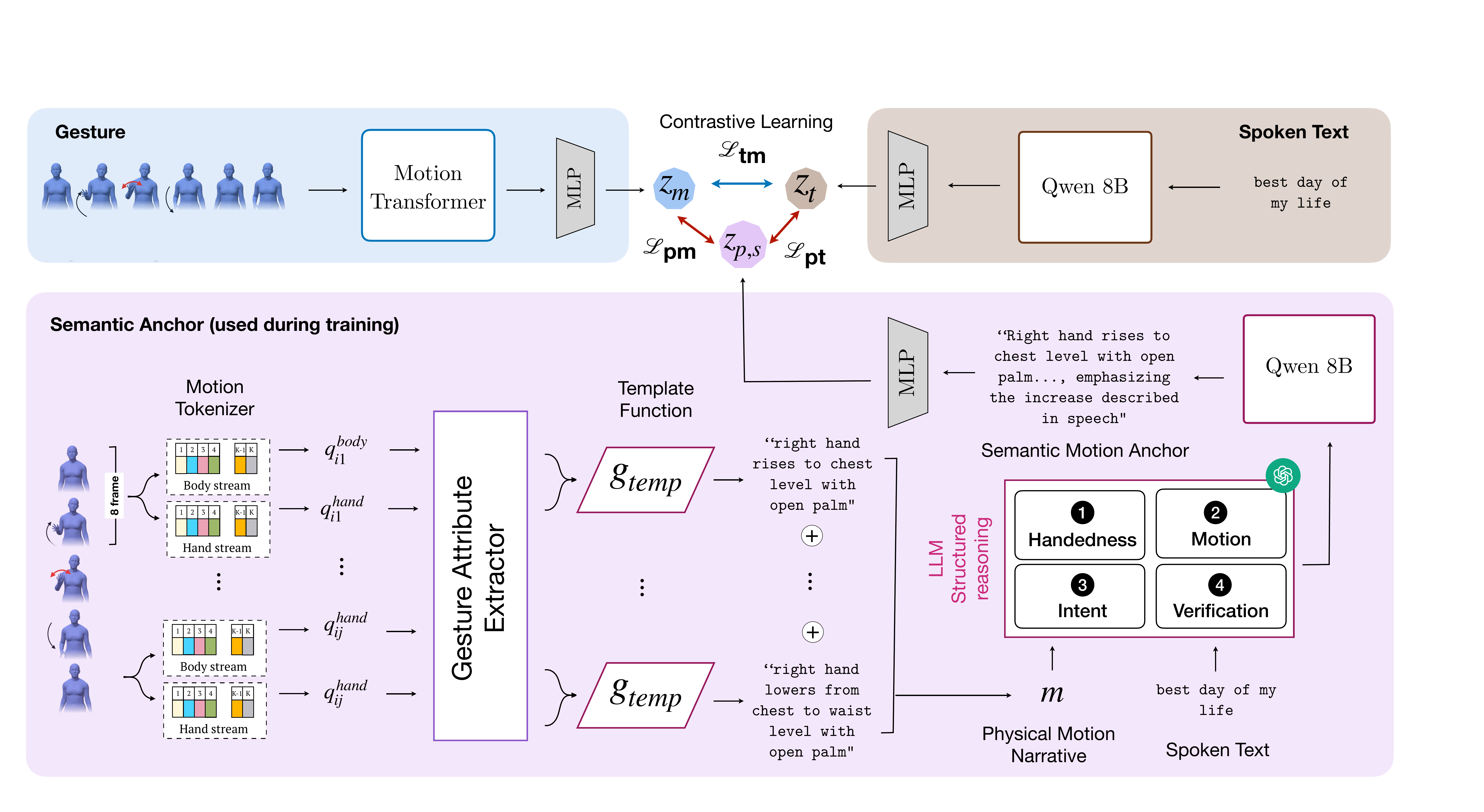
Semantic Motion Anchors
Semantic Motion Anchors: Bridging Motion and Meaning in Co-Speech Gestures
This paper introduces semantic motion anchors, a new intermediate representation that links 3D co-speech gestures with their communicative intent by verbalizing motion and grounding it in spoken text. This improves retrieval of semantically meaningful gestures and shows user preference for gestures conveying intent.
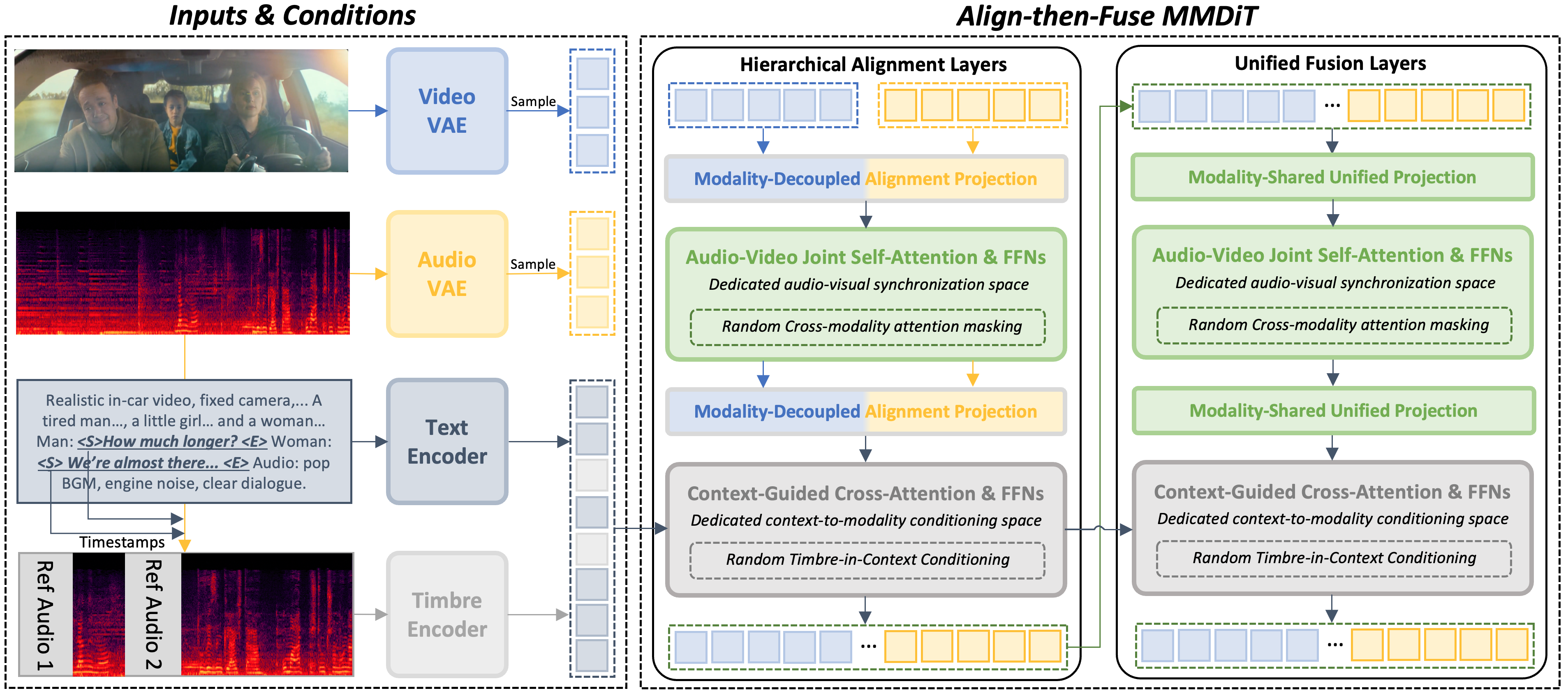
NAVA
Native Audio-Visual Alignment for Generation
NAVA is a joint audio-video generation model that separates audio-video synchronization from semantic context. It enables precise alignment and controllable multi-speaker timbre by dedicating a space for native audio-visual alignment before context conditioning, improving on dual-tower and unified tri-modal methods.
Archon
Archon: A Unified Multimodal Model for Holistic Digital Human Generation
Archon is a unified multimodal model generating holistic digital humans by modeling seven modalities jointly. It uses efficient semantic video tokenization and a Thinking in Modality strategy to improve control and fidelity for talking-head video synthesis.
TTS & Unified Speech Modeling
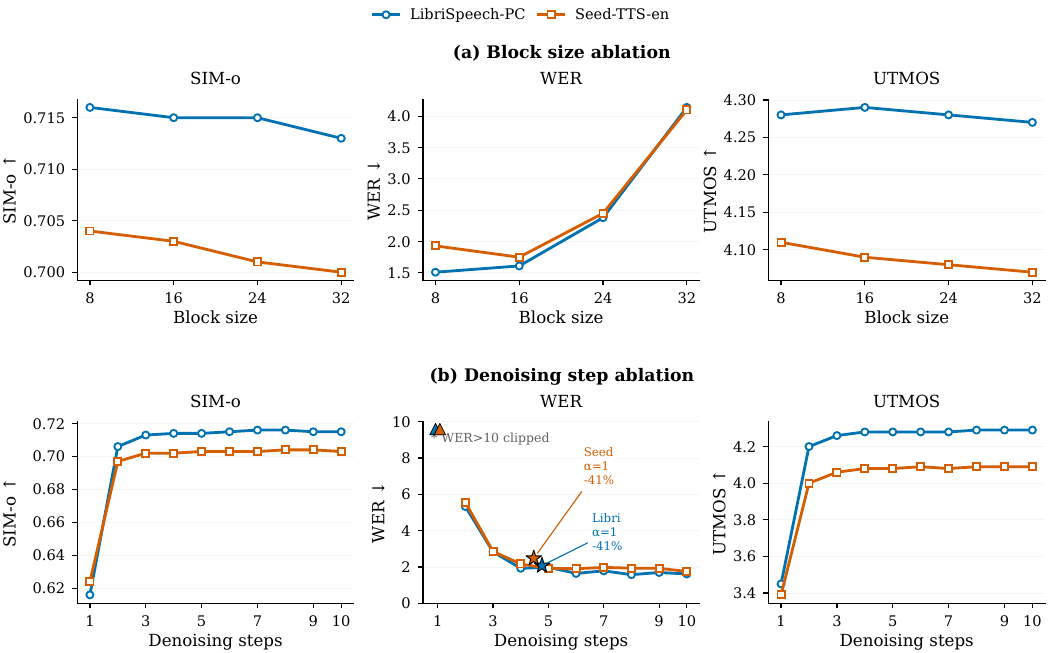
Chatterbox-Flash
Chatterbox-Flash: Prior-Calibrated Block Diffusion for Streaming Zero-Shot TTS
Chatterbox-Flash is a zero-shot streaming TTS model that converts an autoregressive decoder into a block-diffusion decoder. It uses prior-calibrated scoring and early decoding for efficient, low-latency synthesis without changing the model architecture, enabling high-quality speech with streaming support.

MELD
MELD: Mel-Spectrogram-Based Speech Language Modeling with Discrete Latent Variables
MELD uses discrete latent variables on mel-spectrograms to jointly train speech encoders and autoregressive models. This approach improves zero-shot text-to-speech and speech-to-text performance, and reduces issues like prolonged silence common in previous models.