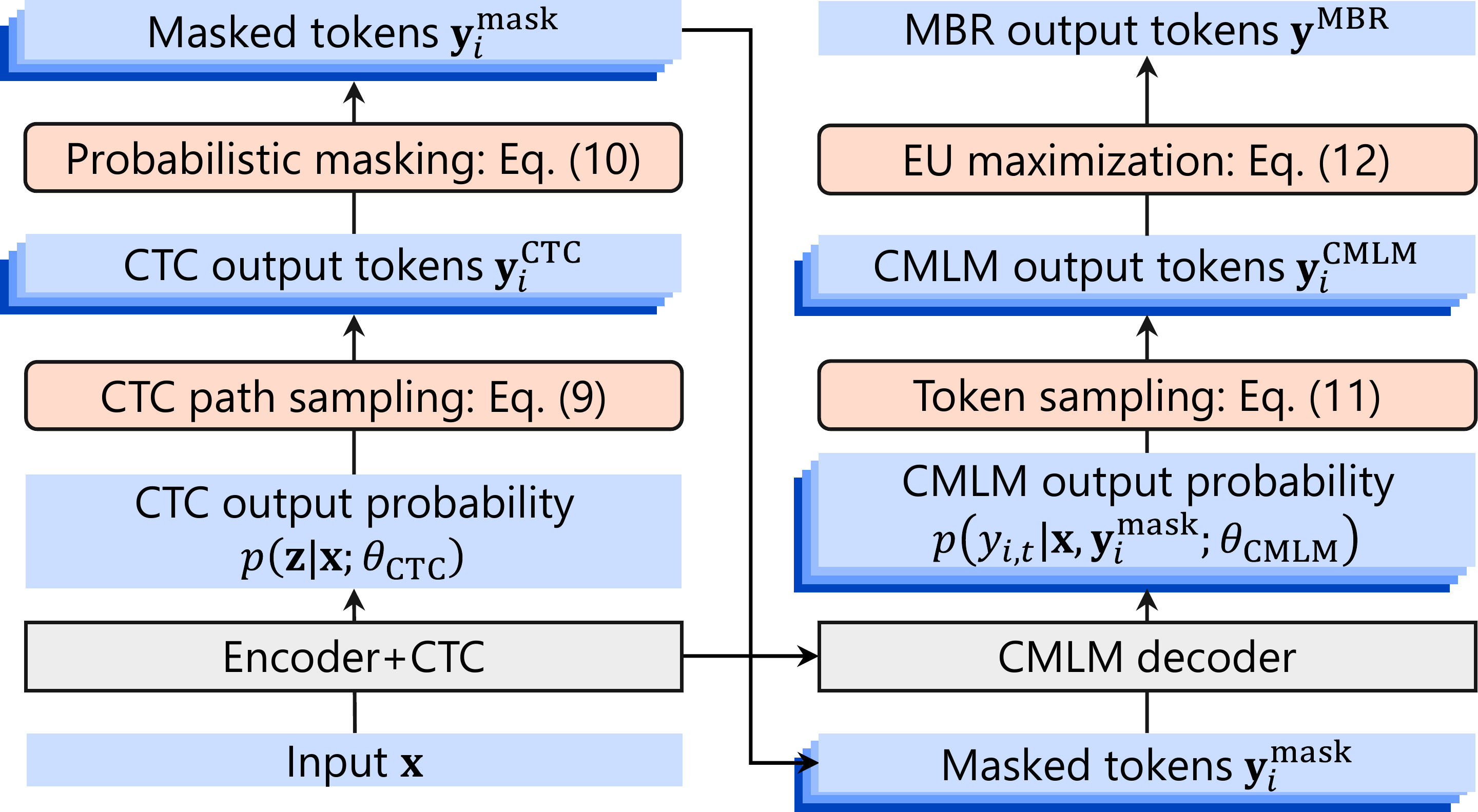
Speech systems tighten context, accents, and avatars
Today’s digest spans context-aware spoken dialogue, multilingual and accent-aware speech models, faster ASR decoding, and dynamic 3D head editing. Together, these papers push conversational systems toward more faithful, natural, and controllable interaction.
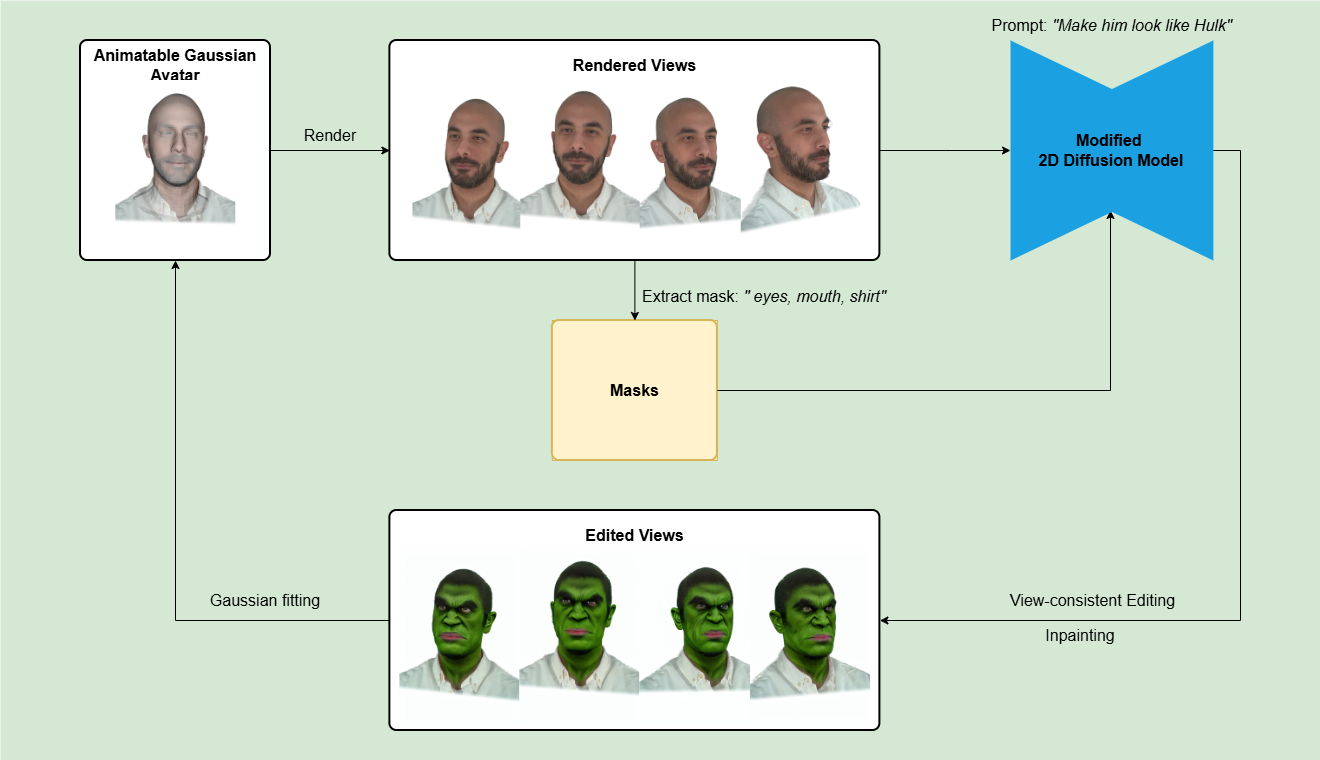
Overview of the proposed Edit3DGS framework. The core components are multi-view batch editing and mask-based refinement, which together ensure both spatial consistency across views and preservation of facial expressions. At each timestep, selected camera views are rendered and edited using instruction-guided diffusion. The edited results across multiple timesteps are then aggregated to update the original Gaussian model through 3D fitting. After several iterations, the refined 3D avatar can be reprocessed through 2D editing to propagate changes to previously unseen timesteps. From Edit3DGS.
Digital Humans & 3D Faces
SpeechLLMs & Spoken Dialogue
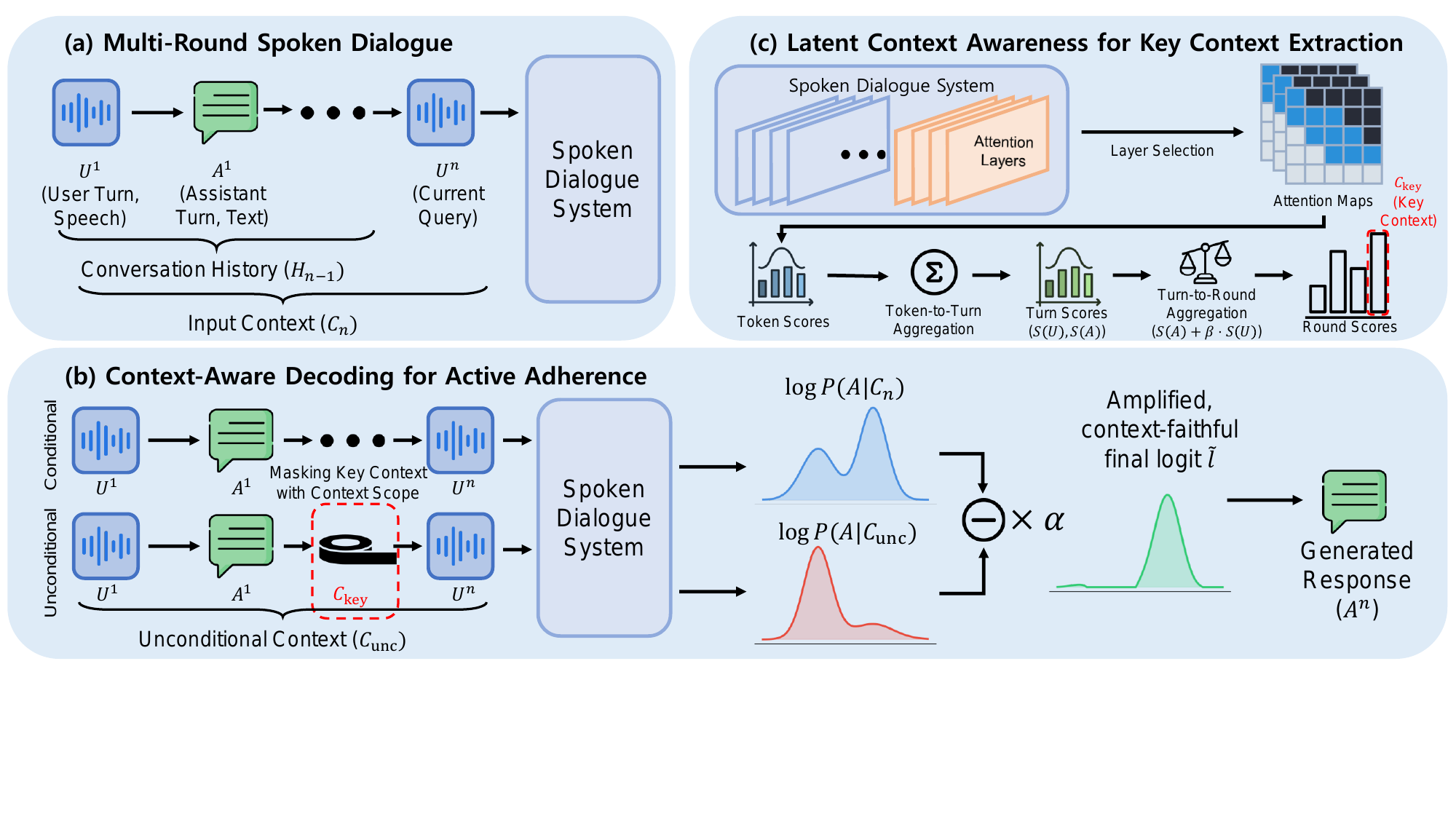
Context-Aware Decoding (CAD)
From Awareness to Adherence: Bridging the Context Gap in Spoken Dialogue Systems via Context-Aware Decoding
Introduces an inference-only method that boosts multi-round spoken dialogue systems by amplifying relevant context during response generation. It bridges the gap between internal context awareness and active adherence, improving context fidelity without retraining or extra modules.

Spoken Language Adherence in Multimodal LLMs
Are you speaking my languages? On spoken language adherence in multimodal LLMs
Addresses language misidentification by multimodal ASR models through a soft prompting approach, a new adherence metric, and compares three mitigation strategies to improve transcription fidelity in multilingual and code-switching speech.
TTS & Voice Synthesis
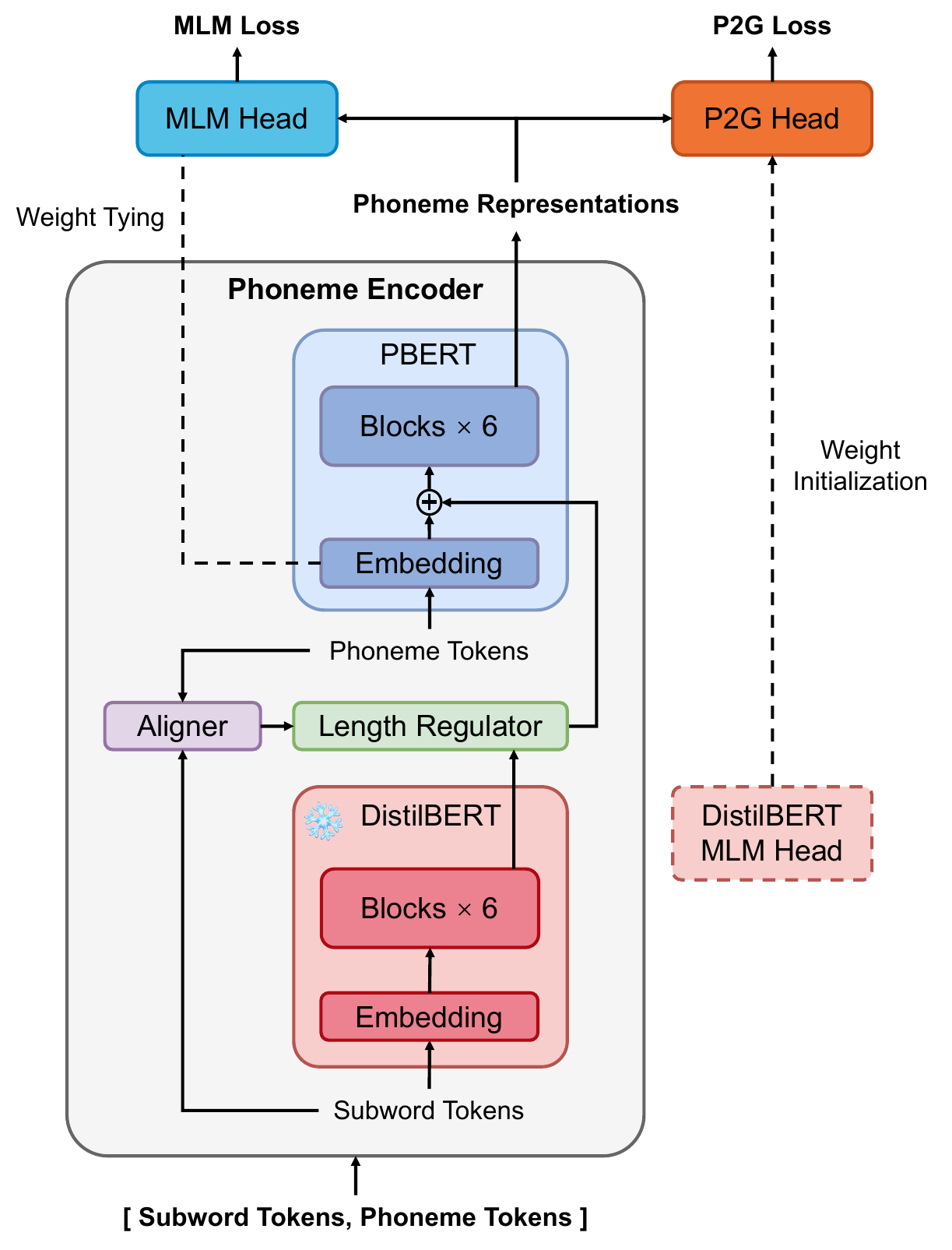
CraBERT
CraBERT: Efficient Phoneme Encoder Pre-Training via Cascade Fusion of Subword Representations for Text-to-Speech
CraBERT is an efficient pre-trained phoneme encoder for text-to-speech that leverages a frozen pre-trained subword BERT to infuse word- and sentence-level context into phoneme-level representations, enabling significantly faster pre-training with comparable perceived speech quality to longer-trained baselines.
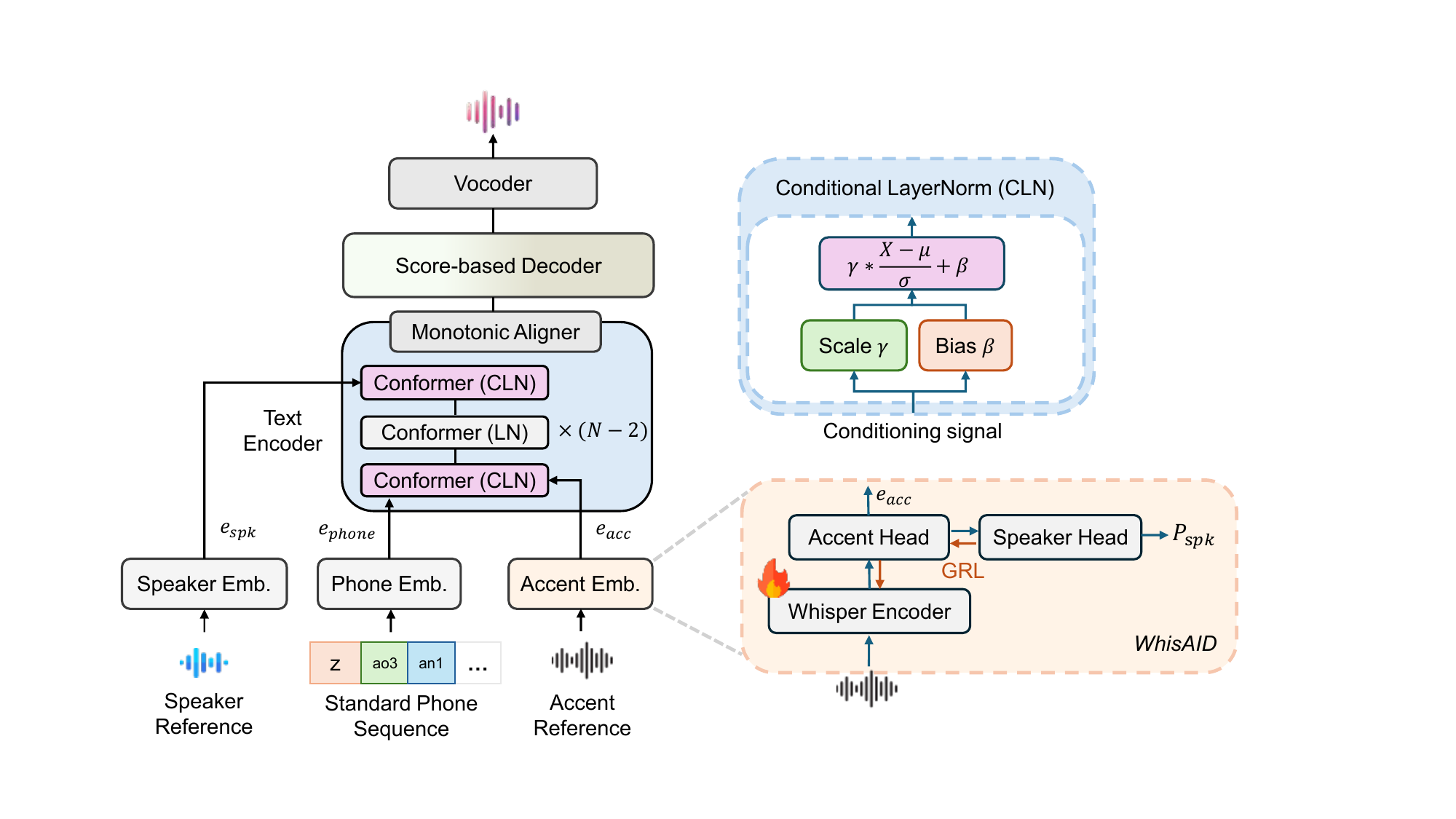
Joycent
Joycent: Diffusion-based Accent TTS without Accented Phone Prediction
Joycent is a diffusion-based TTS model that synthesizes accented speech from standard phones and speech references, bypassing accented phone prediction. It integrates accent and speaker cues using conditional layer normalization, enhancing accentedness while preserving speaker identity without paired accent data.