Speech synthesis, voice conversion, and interactive avatars push toward real-time realism
Today’s digest spans transcript-free text-to-speech, diffusion-guided speech generation, streaming voice conversion, and speech codecs built for cleaner identity control. It also features physically interactive 3D avatars that deform realistically under contact and motion.
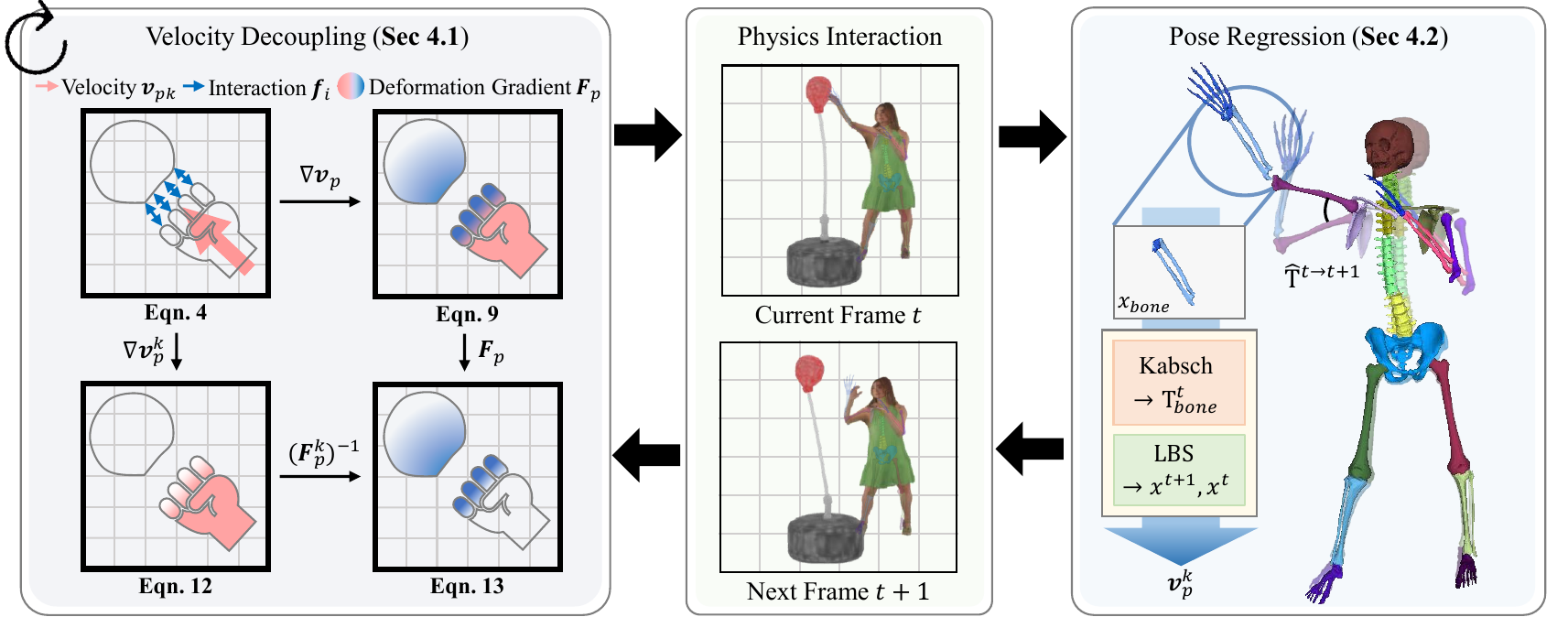
An illustration of our framework. (a) To faithfully reflect the user-defined motion, we decouple the kinematic velocity from the deformation gradient update (Sec.~). (b) By computing the velocity from the transformations of the embedded skeletal structure, our method preserves the pose consistency throughout the simulation (Sec.~). From PIAvatar.
Digital Humans & 3D Avatars
TTS & Voice Synthesis
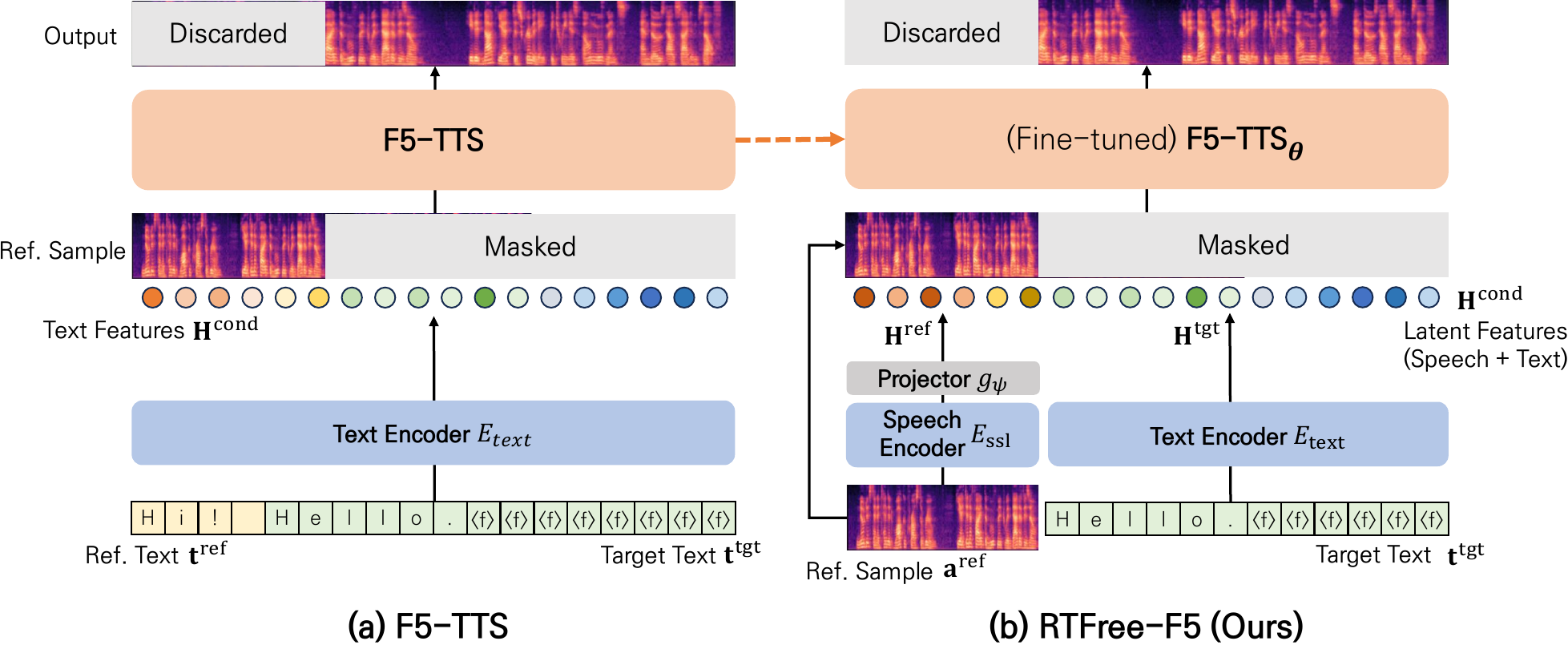
RTFree-F5
Transcript-Free Flow-Matching Text-to-Speech via Speech Feature Conditioning
RTFree-F5 innovates flow-matching zero-shot TTS by using self-supervised speech features instead of reference transcripts at inference. This improves robustness and speech quality for atypical speakers like those with dysarthria, while keeping competitive performance on typical voices.
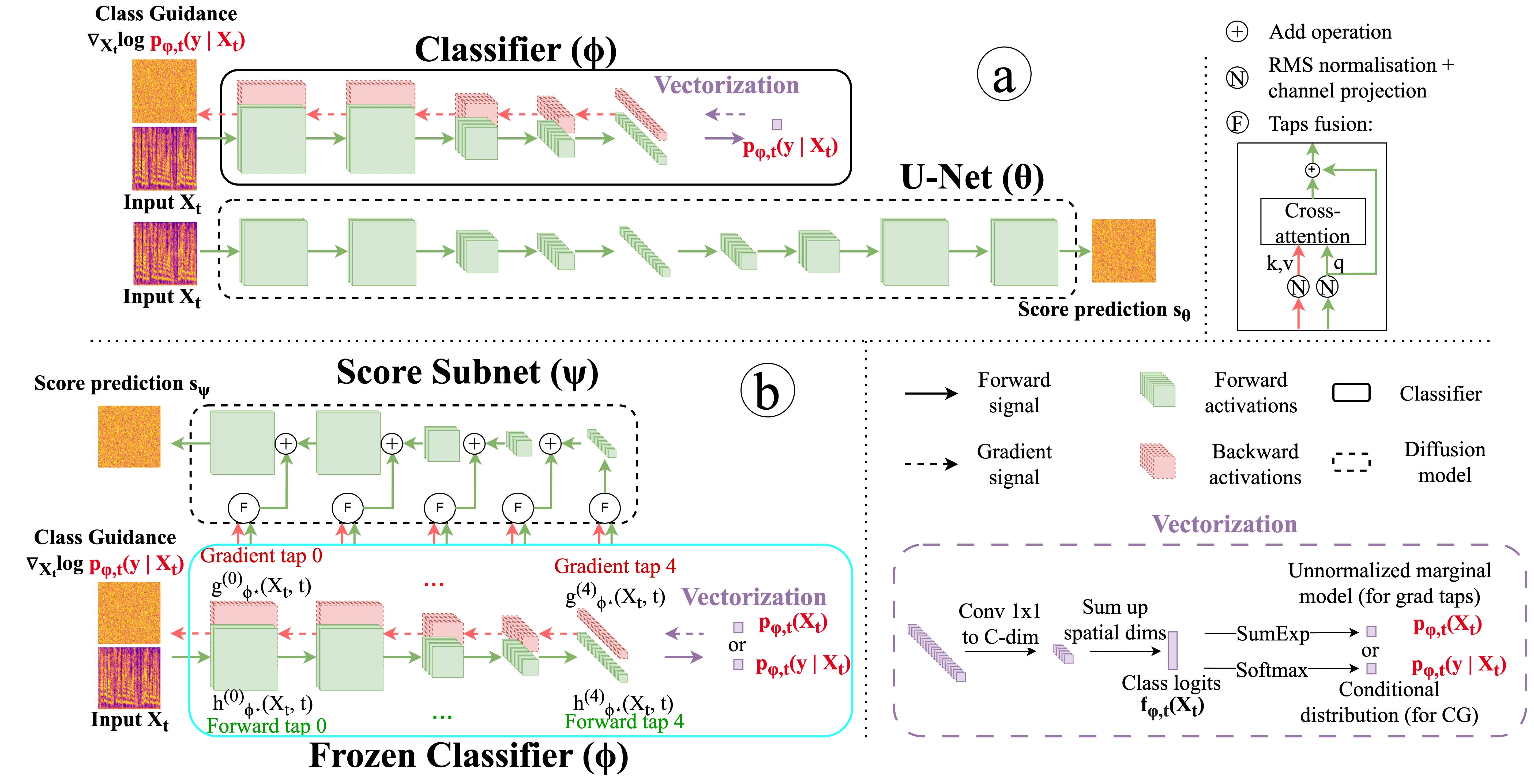
Score Subnet
Repurposing a Speech Classifier for Guided Diffusion-Based Speech Generation
Repurposes a pretrained noise-conditioned speech classifier for diffusion-based speech generation with a lightweight decoder. This unifies classifier guidance and score modeling in one backbone, cutting parameters and compute while delivering high-quality conditional speech synthesis.
Voice Conversion & Streaming Speech
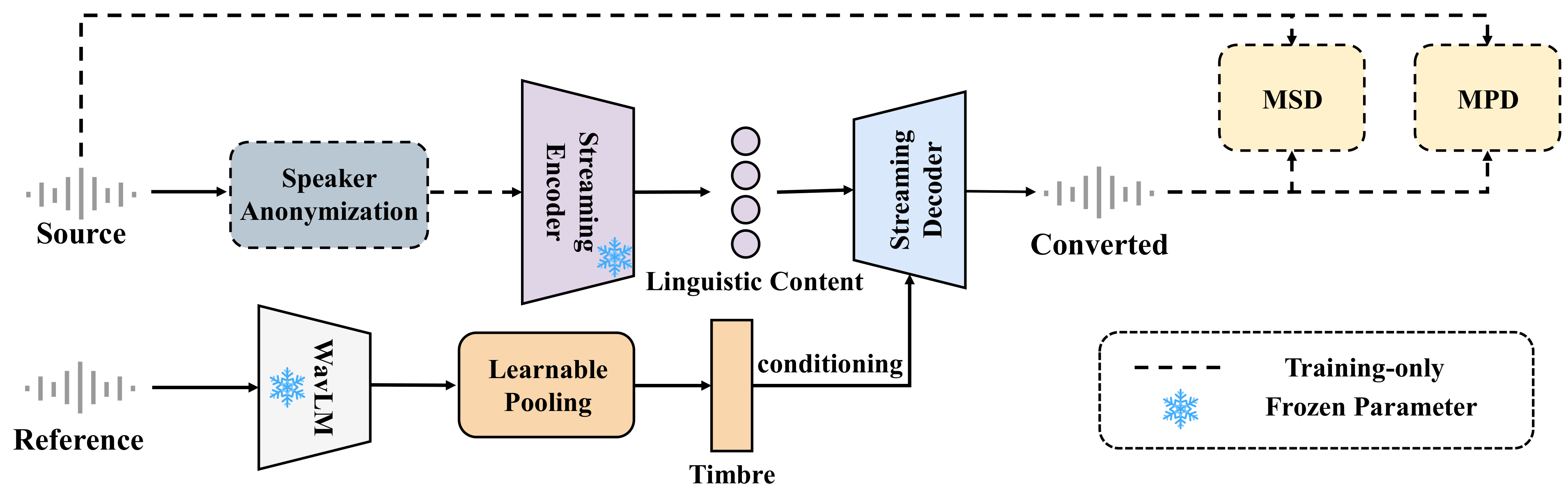
Zero-VC
Zero-VC: Zero-Lookahead Streaming Voice Conversion via Speaker Anonymization
Zero-VC uses speaker anonymization to enable zero-lookahead streaming voice conversion that minimizes timbre leakage while preserving prosody. This real-time approach better balances identity hiding and utility, allowing low-latency conversion to unseen speakers without buffering future audio frames.

SDP-Codec
SDP-Codec: A Speaker-Decoupled Speech Codec with Pitch Injection for Low-Bitrate Coding and Zero-Shot Voice Conversion
SDP-Codec is a low-bitrate speech codec that separates speaker identity from content and prosody to enable high-quality speech reconstruction and zero-shot voice conversion. It uses a single-stage training method with pitch injection to reduce speaker leakage and improve voice conversion accuracy.