Real-Time Voices, Agents, and Avatars
Today’s digest spans end-to-end interactive models, better speech and TTS synthesis, and instant 3D avatar generation. The common thread: more natural, controllable, low-latency conversational AI across voice and visual embodiment.

Qualitative Results. We show the animated results of our generated 3D Gaussian avatars for test IDs and novel expressions. Our ~generates authentic, ID-preserving avatars for diverse attributes, , races, genders, ages, hairstyles, and expressions, only from a single image. Also, the input image's visual details, such as tattoos or accessories, are faithfully reflected in the 3D Gaussian avatars. Note that ~can generate unseen observations from the input image, such as the mouth interior and eye pupil, aided by our diffusion model. Please refer to the supplementary video for the dynamic avatar animation results. From FiCA.
Digital Humans & 3D Avatars
SpeechLLMs & Voice Agents
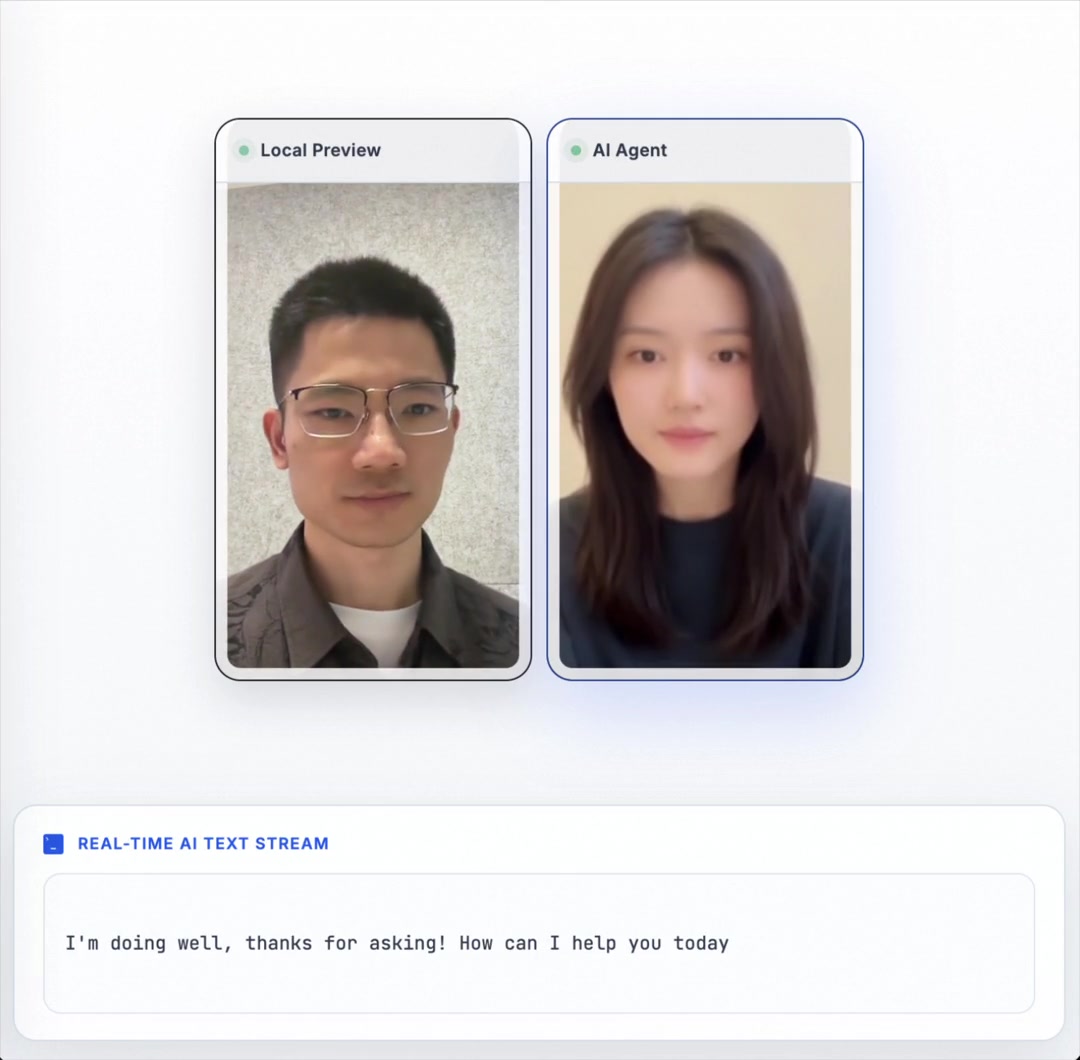
Wan-Streamer
Wan-Streamer v0.1: End-to-end Real-time Interactive Foundation Models
Wan-Streamer is an end-to-end interactive foundation model unifying text, audio, and video in a single Transformer for real-time full-duplex audio-visual interaction. It jointly learns perception and generation without separate modules, enabling sub-second latency streaming with synchronized multimodal responses.

Translation-Enhanced Speech Encoder
Does Translation-Enhanced Speech Encoder Pre-training Affect Speech LLMs?
This paper studies how adding translation objectives in speech encoder pre-training improves cross-lingual, language-agnostic representations for Speech LLMs. The bidirectional translation task aligns speech embeddings better with the LLM's shared semantic space, boosting downstream speech recognition and translation.
TTS & Voice Synthesis
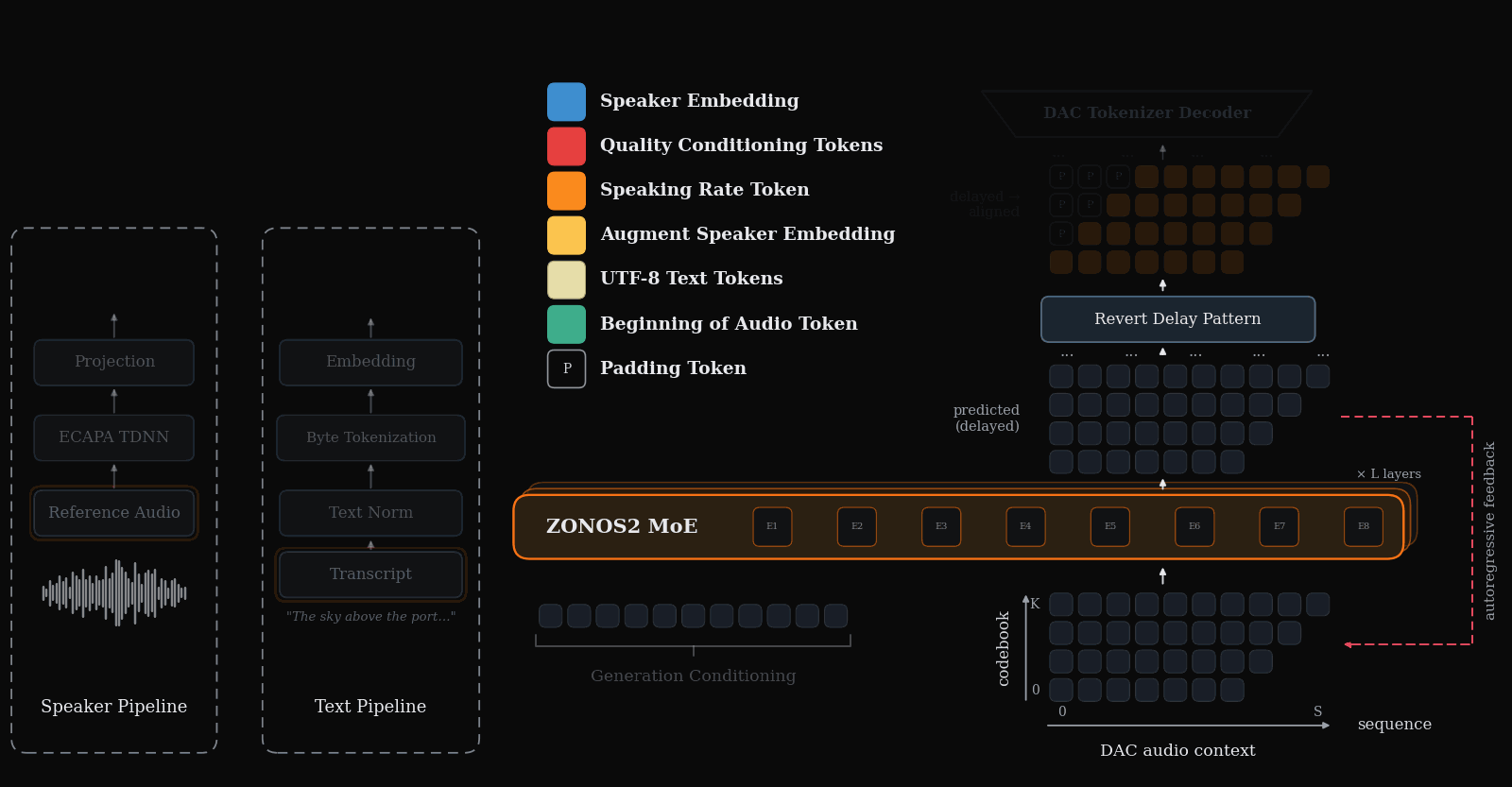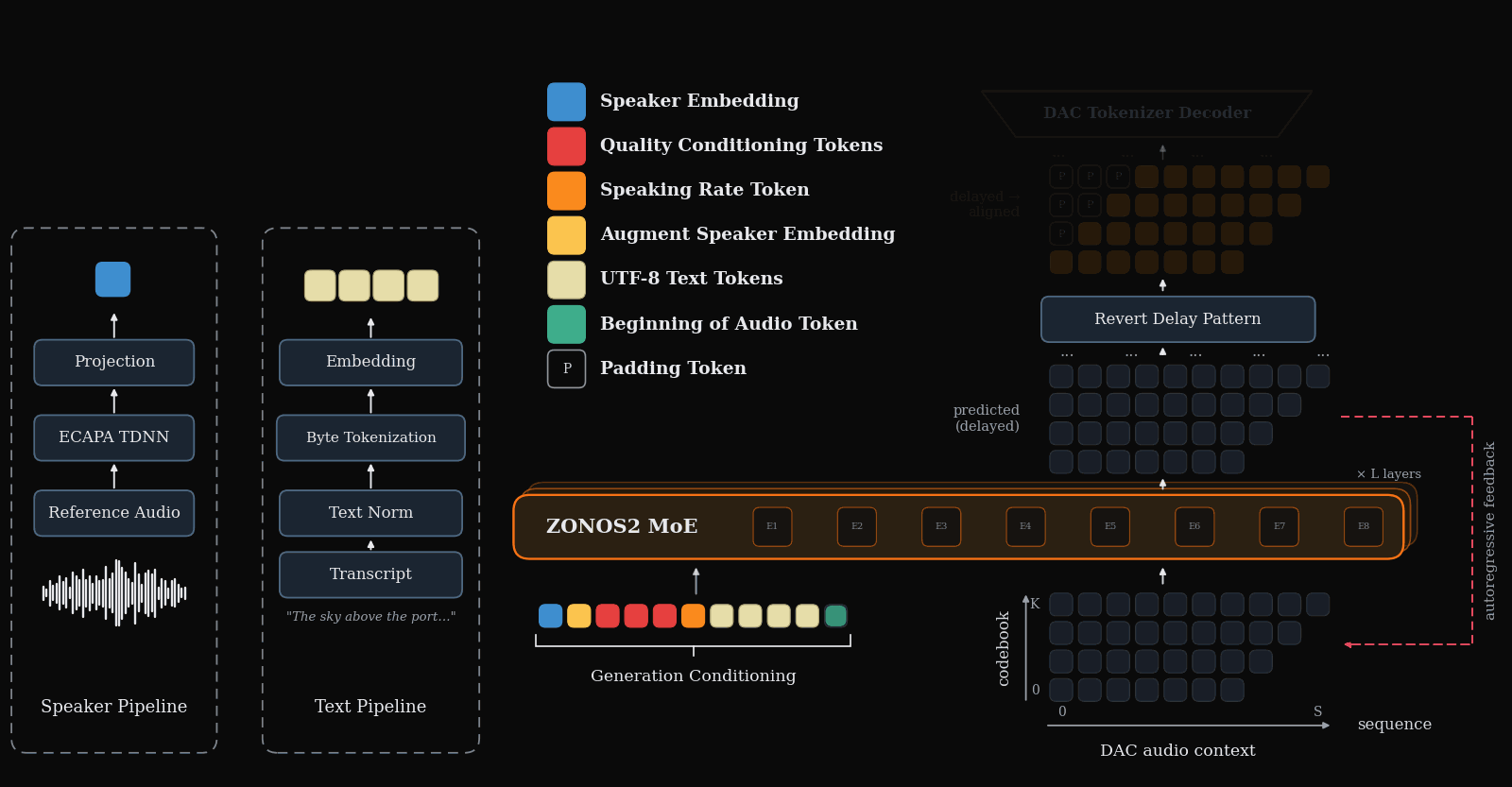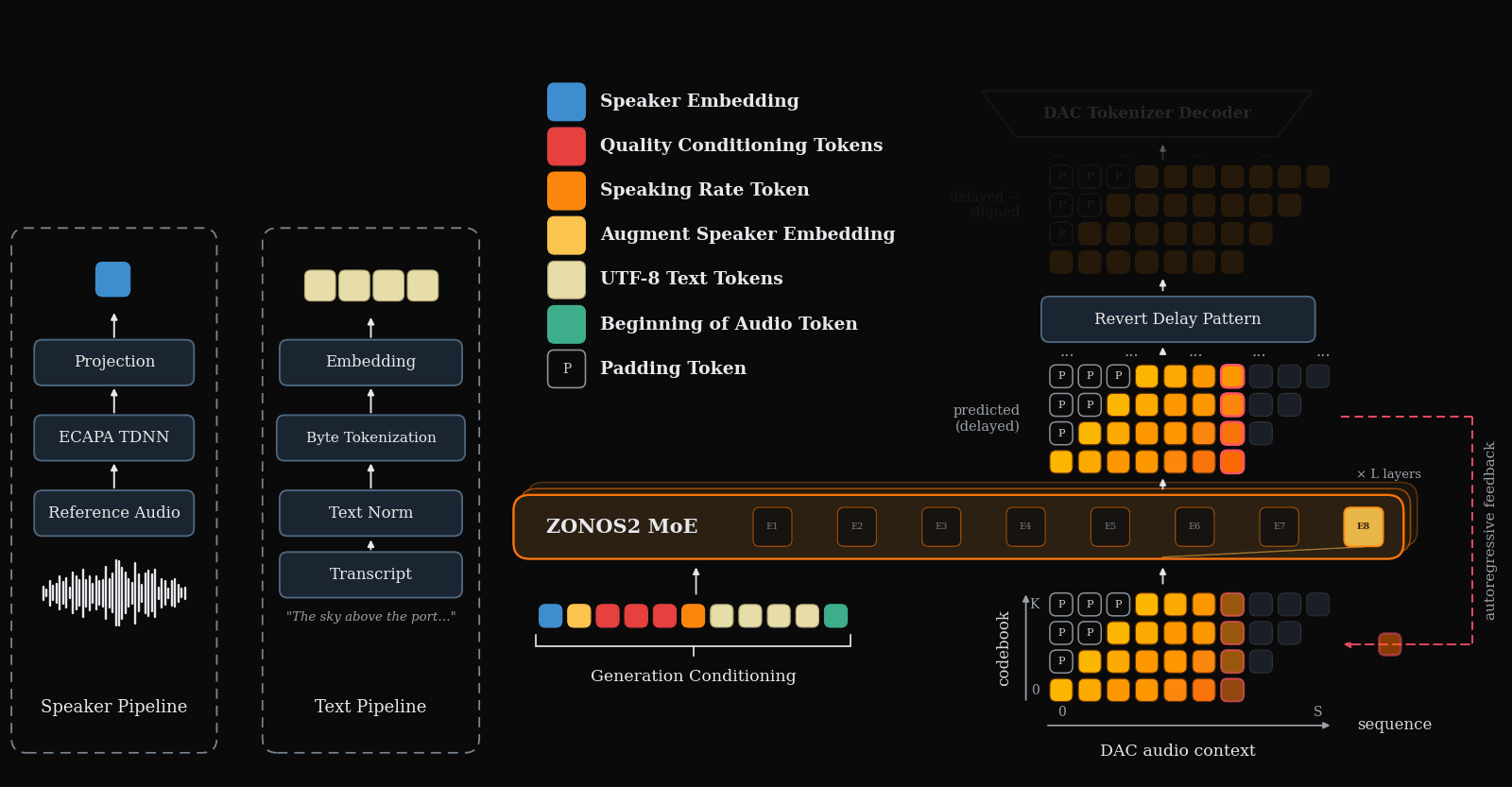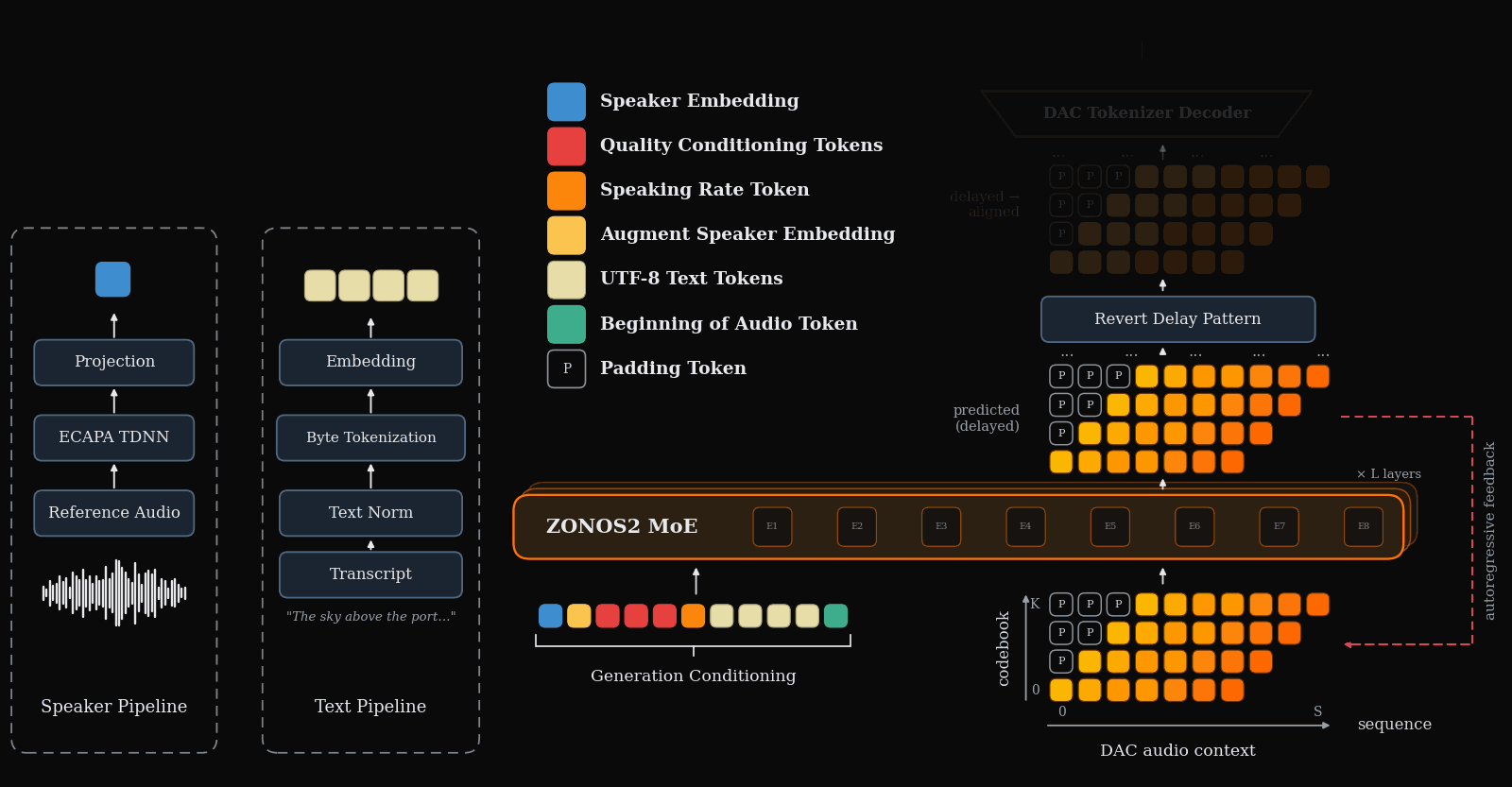
ZONOS2
ZONOS2 Technical Report
ZONOS2 is an advanced text-to-speech model that excels in naturalness, prosody, and zero-shot voice cloning across multiple languages. It uniquely combines a large-scale mixture-of-experts architecture with a massive multilingual training corpus and simplified conditioning for high-quality, low-latency streaming TTS.
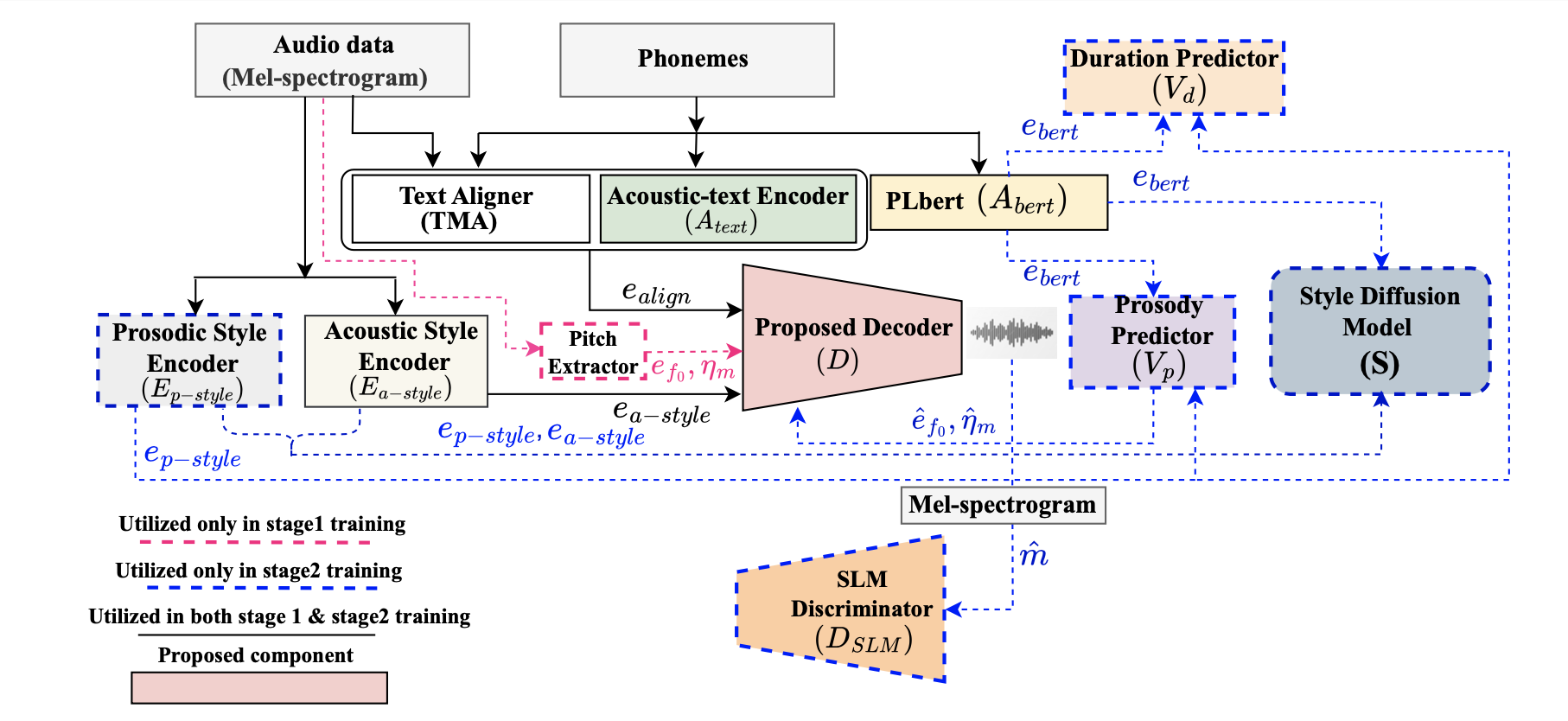
OscillaTTS
Adaptive Oscillatory Inductive Bias for Modeling Sharp Prosodic Dynamics in Diffusion-Based TTS
OscillaTTS enhances diffusion-based text-to-speech by introducing an adaptive oscillatory activation that improves modeling of sharp prosodic transitions and rapid pitch variations, enabling more expressive and stable speech synthesis compared to fixed periodic functions.
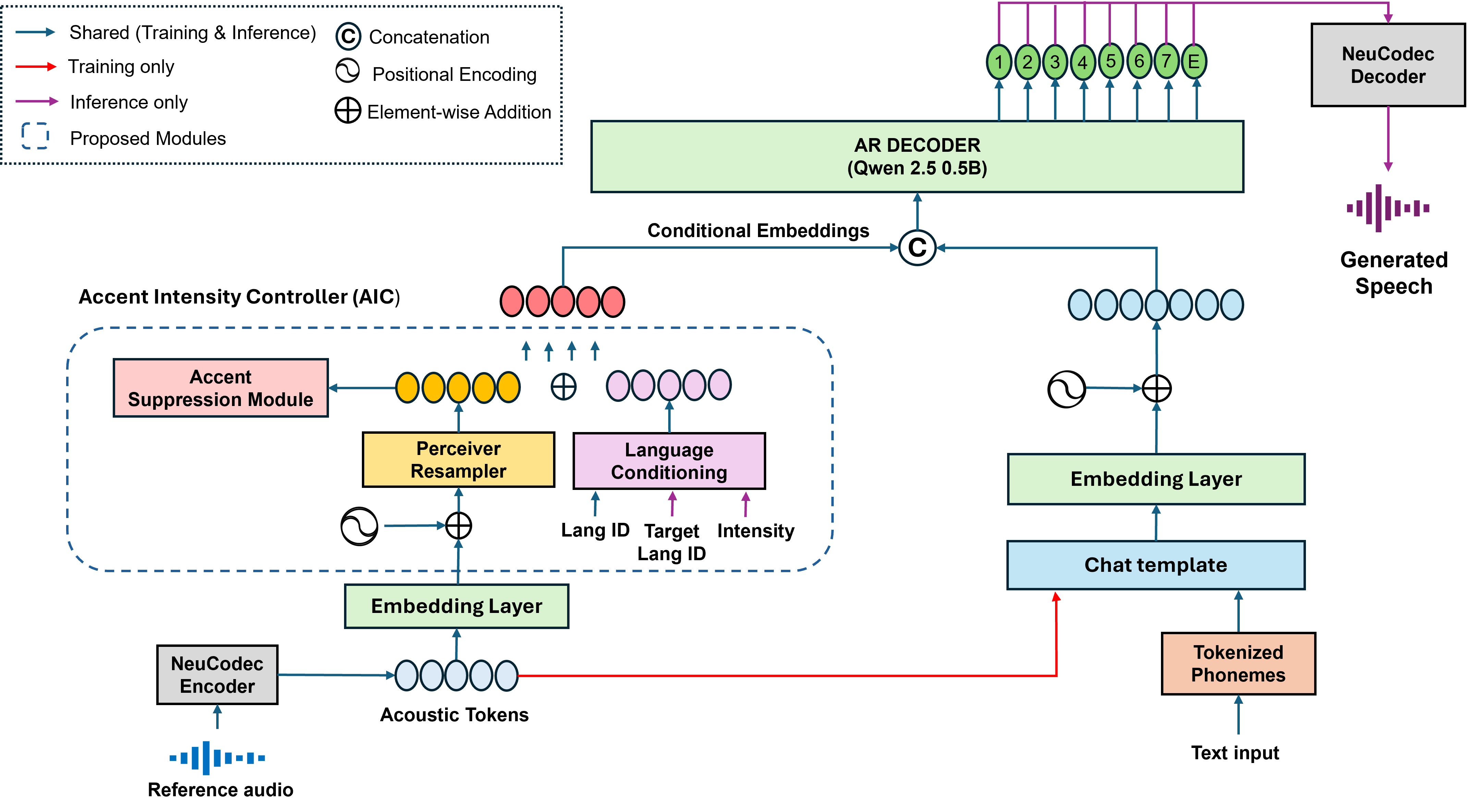
CrossAccent-TTS
CrossAccent-TTS: Cross-Lingual Accent-Intensity Controllable Text-to-Speech via Disentangled Speaker and Accent Representations
CrossAccent-TTS enables precise control of accent and accent intensity in cross-lingual TTS by disentangling speaker and accent features and conditioning synthesis on learned language embeddings. It preserves speaker identity while allowing smooth accent modulation, performing well on Indic and foreign English accents.