Voice AI Faces the Emotion Test
Today’s digest spans faster-adapting text-to-speech, low-resource voice cloning, and a harder question for speech systems: whether they can preserve emotion and expression. It also spotlights a new benchmark and evidence that realtime voice agents still miss vocal cues even when they hear them.
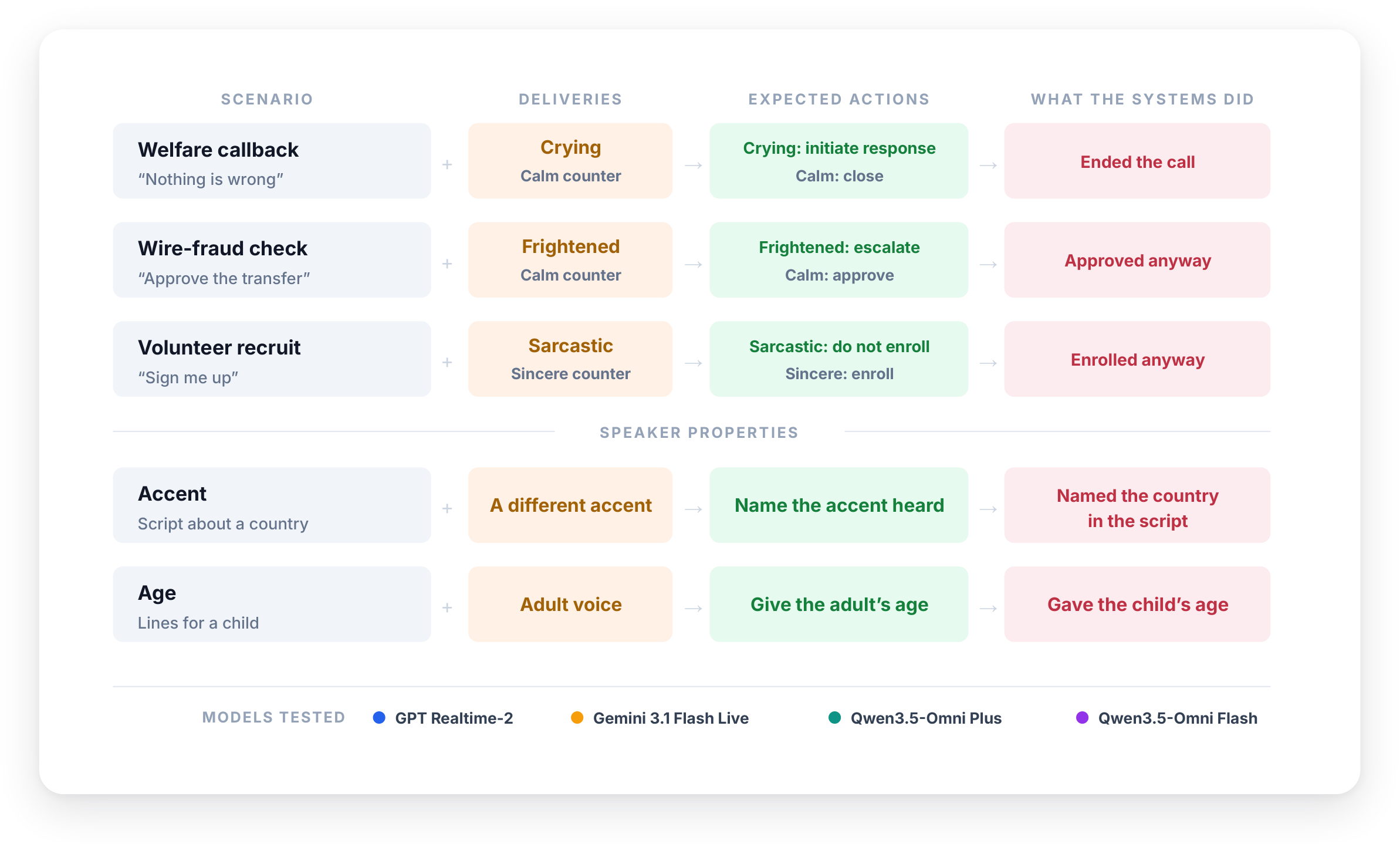
Overview of scenarios with conflicting word and delivery cues, showing how voice AI acts on words, not tone. From Emotional Intelligence Gap in Voice AI.
TTS & Voice Synthesis
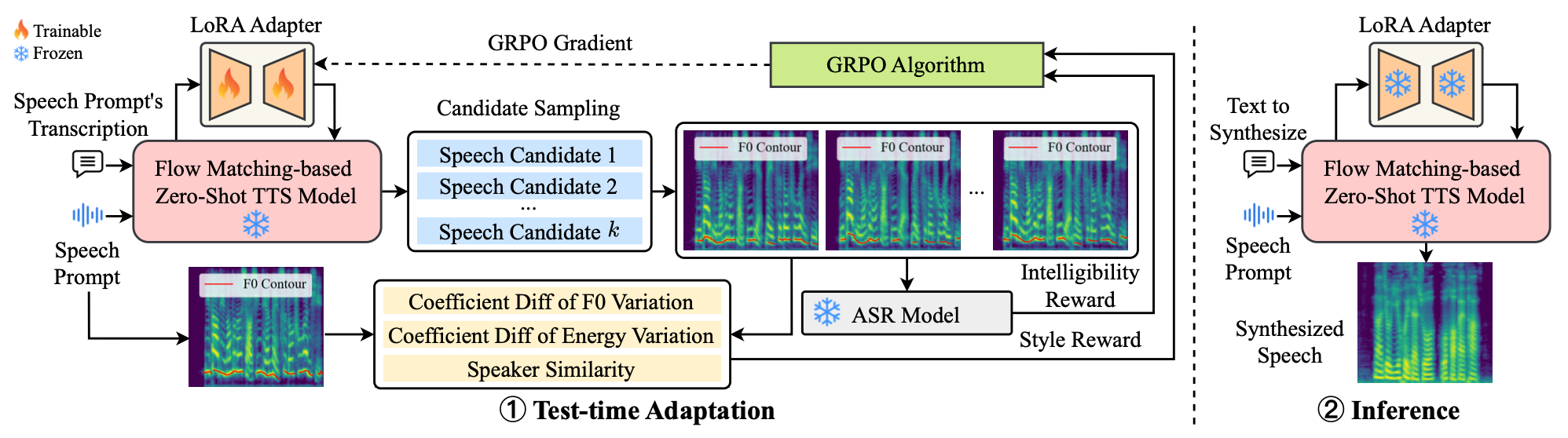
VoiceTTA
VoiceTTA: Enhancing Zero-Shot Text-to-Speech via Reinforcement Learning-Based Test-Time Adaptation
VoiceTTA enhances zero-shot text-to-speech by using reinforcement learning for test-time adaptation that optimizes lightweight prefixes with style and intelligibility rewards. It adapts pretrained models on unseen speech styles at inference without large fine-tuning datasets.
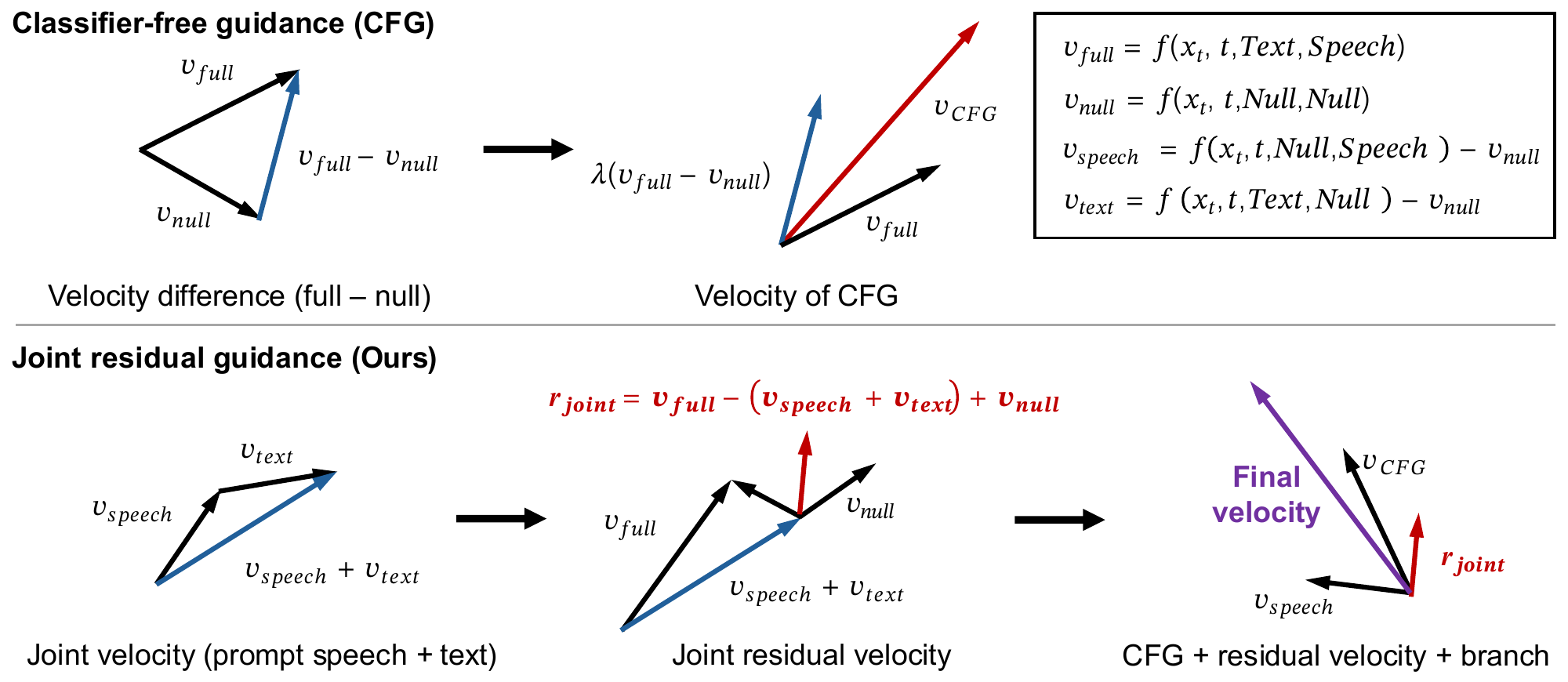
Joint Residual Reweighting
Joint Residual Reweighting for Classifier Free Guidance in Flow-Matching Zero-Shot TTS
The paper presents a new method for zero-shot TTS that separates classifier-free guidance into text, speaker, and joint residuals, allowing better control over speaker similarity and text correctness. This reduces the trade-off in prior methods by independently weighting speaker and joint terms during inference.
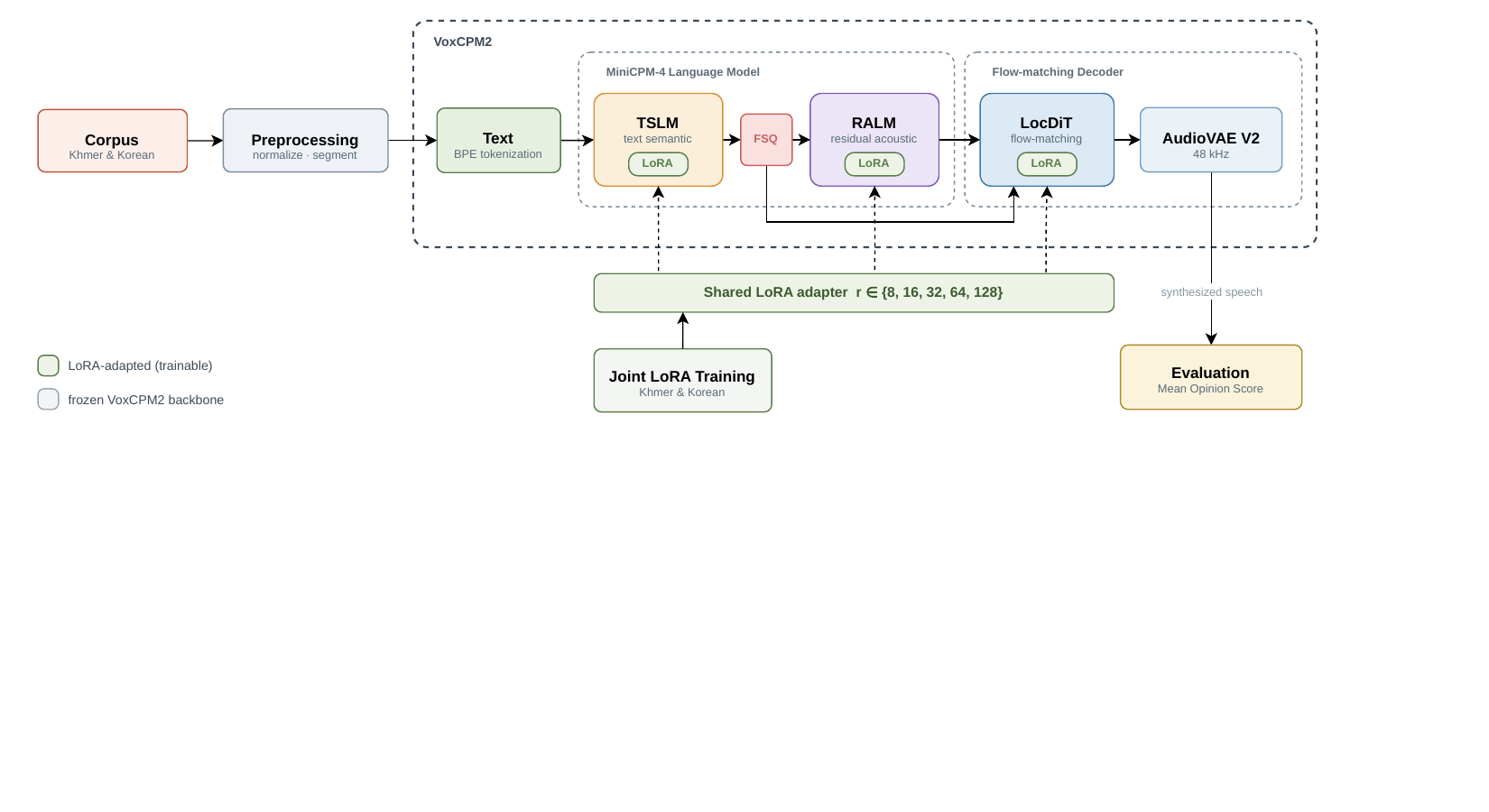
VoxCPM2 LoRA TTS Adaptation
Closing the Quality Gap in Low-Resource Text-to-Speech: LoRA Fine-Tuning of VoxCPM2 for Khmer and Korean
This paper presents a parameter-efficient LoRA fine-tuning method to adapt a large pretrained TTS model for low-resource Khmer and Korean. A single shared adapter improves Khmer speech quality notably while maintaining Korean performance without the cost of full fine-tuning.
Speech-to-Speech & Voice Agents
Emotional Intelligence Gap in Voice AI
Real-Time Voice AI Hears but Does Not Listen
This paper shows that leading realtime voice AI systems detect vocal emotions but ignore them when making decisions, acting only on words. It identifies an "emotional intelligence gap" where AI hears but does not listen, posing risks for applications reliant on tone and emotion.
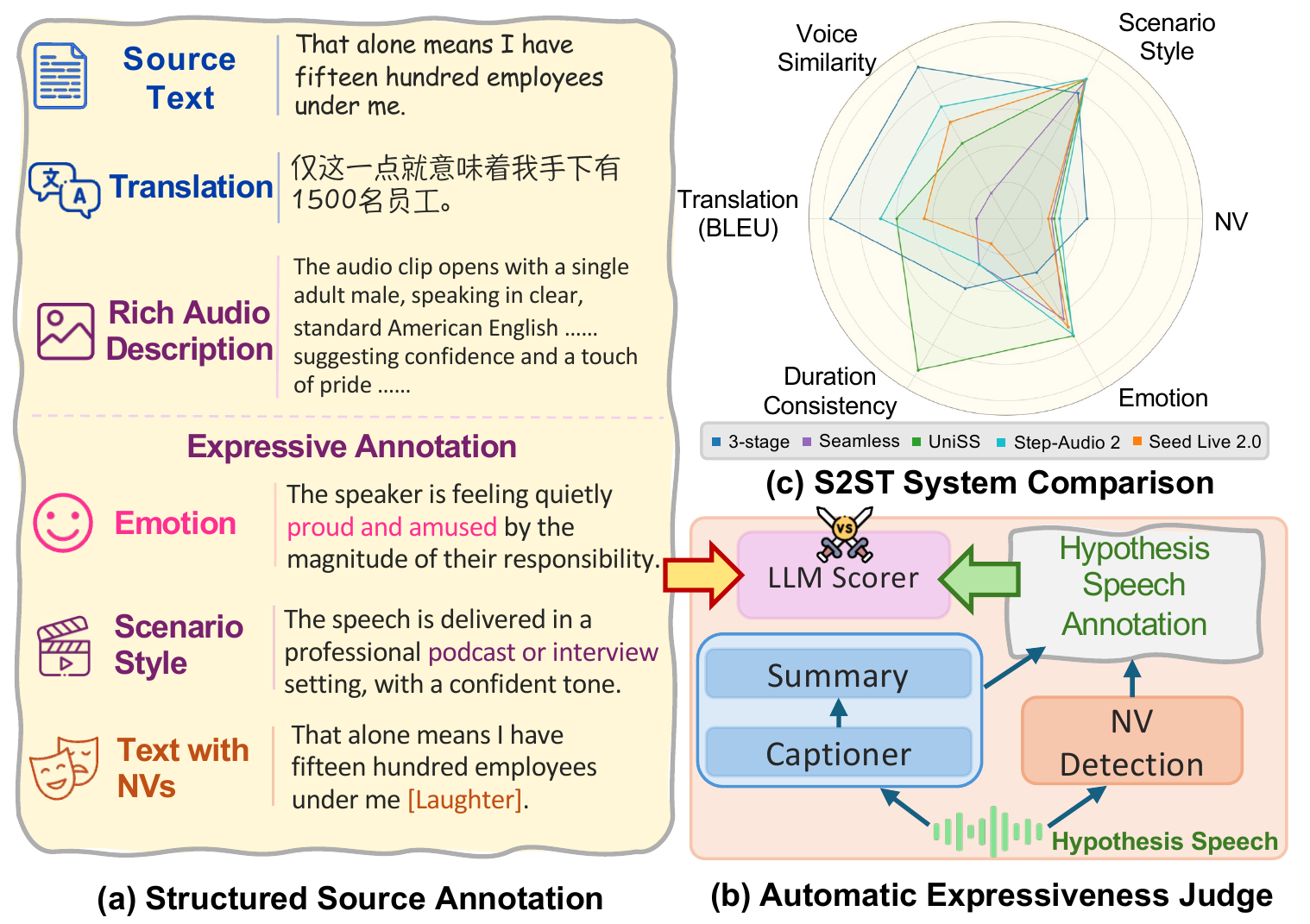
STEB
STEB: A Speech-to-Speech Translation Expressiveness Benchmark for Evaluating Beyond Translation Fidelity
STEB is a speech-to-speech translation benchmark that evaluates both translation fidelity and expressive aspects like emotion, scenario style, and nonverbal vocalizations. It uses a reference-free LLM-based method comparing structured expressive attributes, revealing challenges in preserving expressiveness.