Avatars Get More Social
Today’s digest spans social digital humans, efficient 3D avatar creation, noise-robust spoken dialogue, and more controllable voice synthesis. From theory-of-mind avatars to stronger zero-shot TTS, the common thread is making conversational systems feel more natural and expressive.
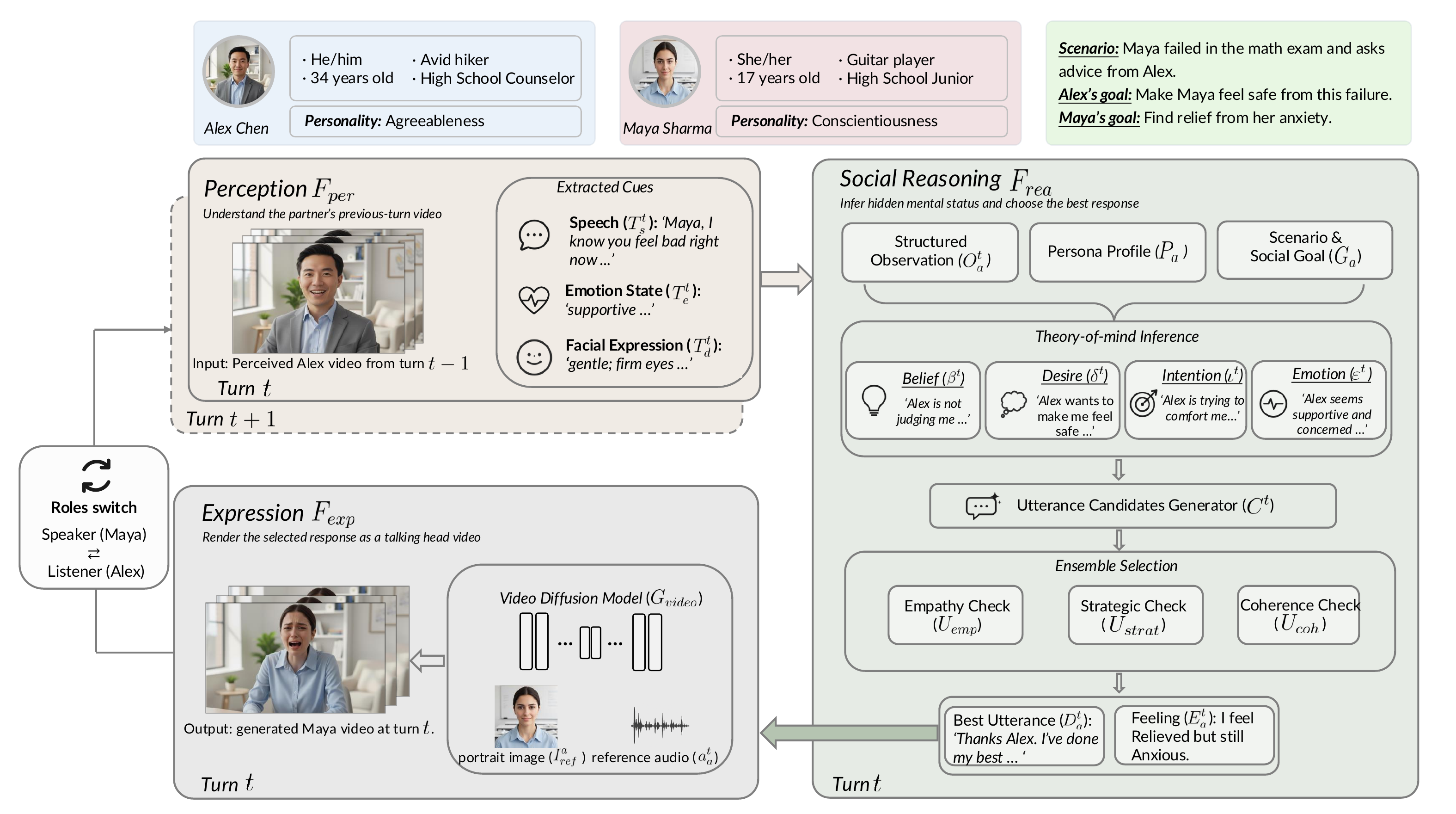
Diagram of the closed-loop framework overview for dual-agent interaction. From Resonant Minds.
Talking Avatars & Social Digital Humans
Digital Humans & 3D Avatars
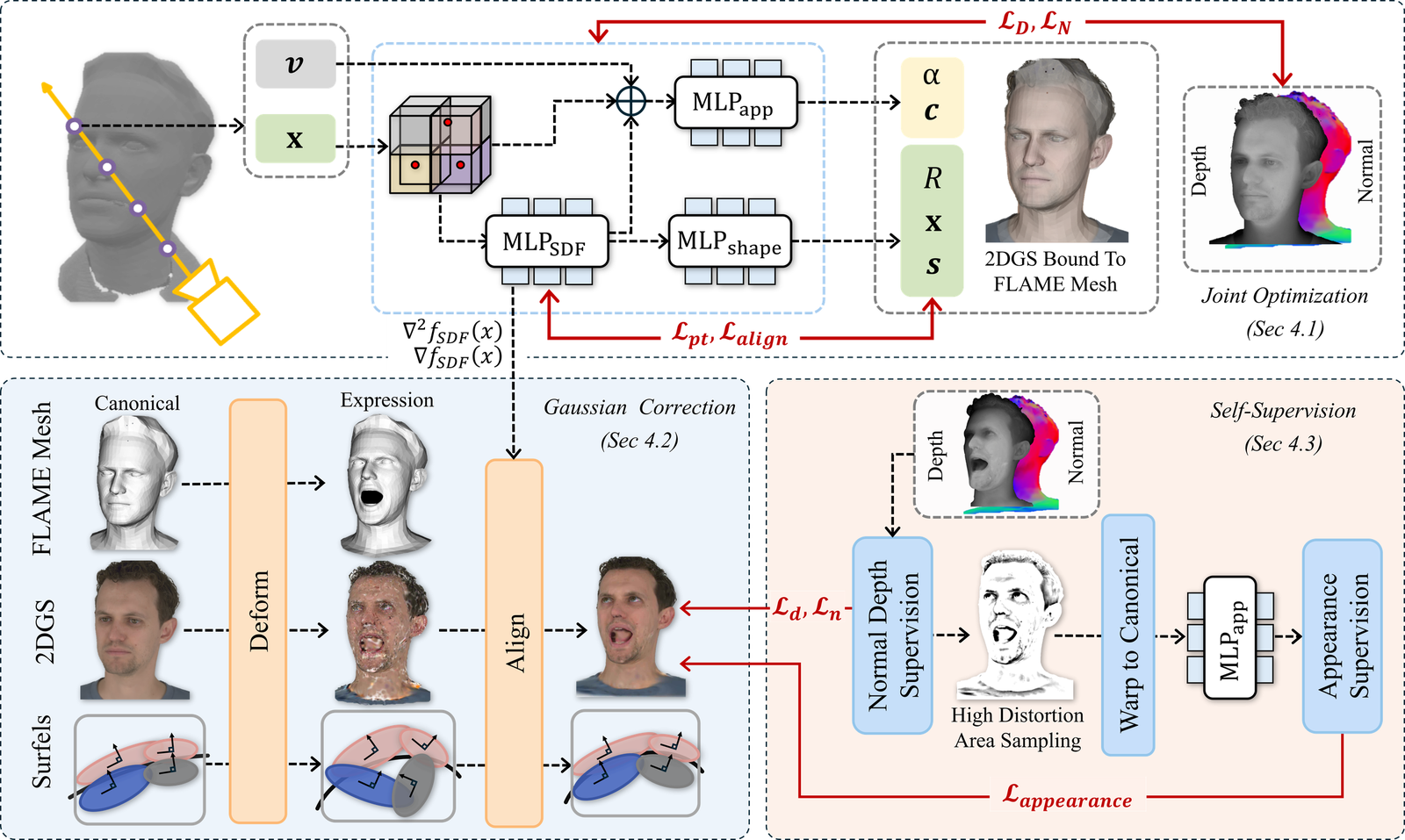
SAGE
Self-Learning Expression Deformations for Data-Efficient Gaussian Avatars
SAGE creates animatable 3D Gaussian avatars from minimal data by self-learning expression deformations using geometric and appearance consistency, eliminating the need for long expression data. It supports multiview, monocular, and one-shot inputs without pretraining, enabling efficient and accessible avatar creation.

RigPAPR
RigPAPR: Rig-Based Animation of Static Neural Point Clouds from a Fixed-Viewpoint Video
RigPAPR animates static neural point clouds to follow a fixed-viewpoint monocular video, recovering a rigged 3D asset. It avoids joint-boundary artifacts by using a shape-free proximity-attention renderer that naturally reforms surfaces under articulation, unlike prior Gaussian splat or mesh-based approaches.
SpeechLLMs & Voice Agents
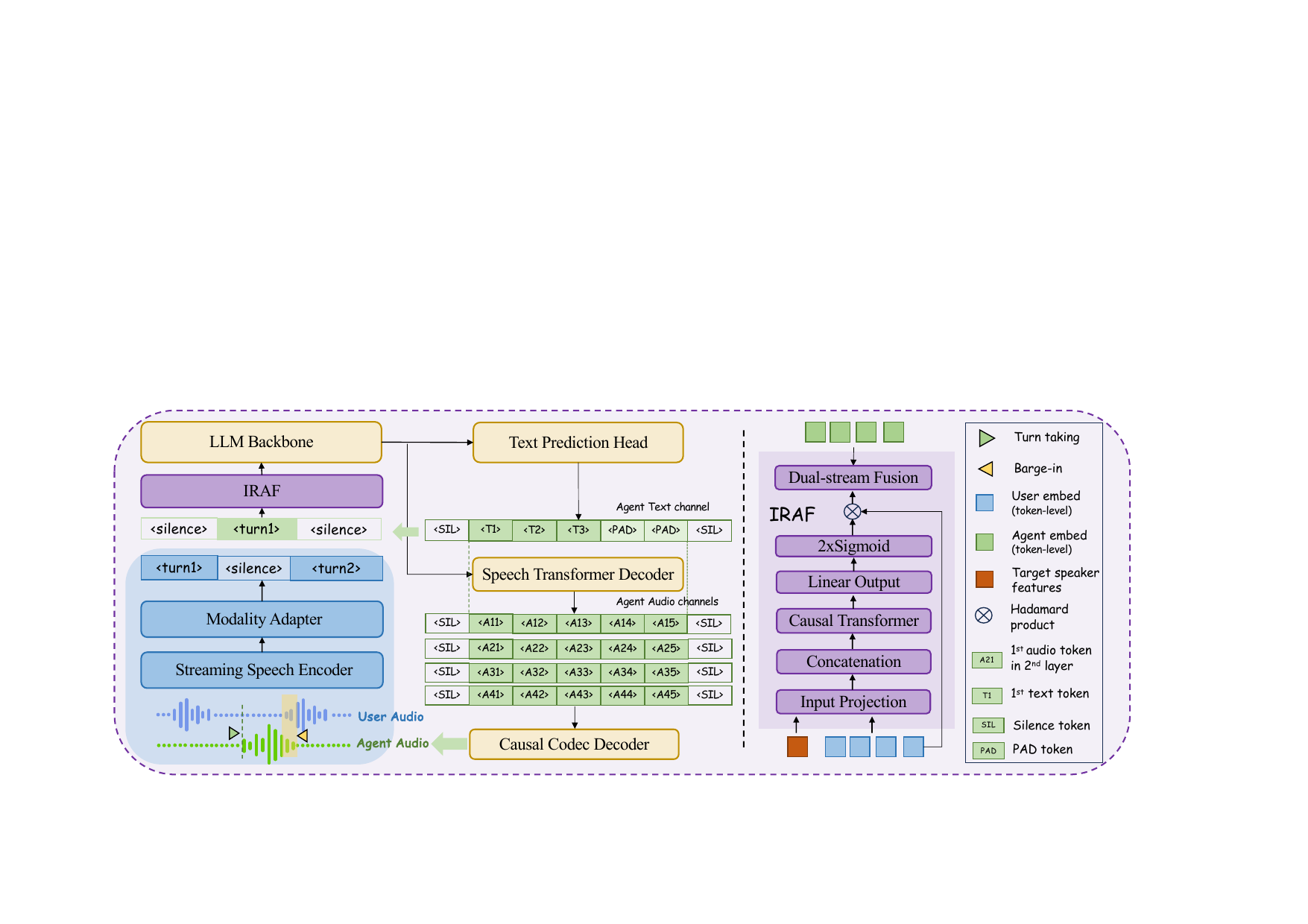
TTS & Voice Synthesis

VoxCPM2
VoxCPM2 Technical Report
VoxCPM2 is a 2B-parameter multilingual text-to-speech foundation model unifying voice design, zero-shot cloning, and high-fidelity super-resolution. It uses continuous-latent modeling for controllable and scalable speech generation without external discrete tokenizers.
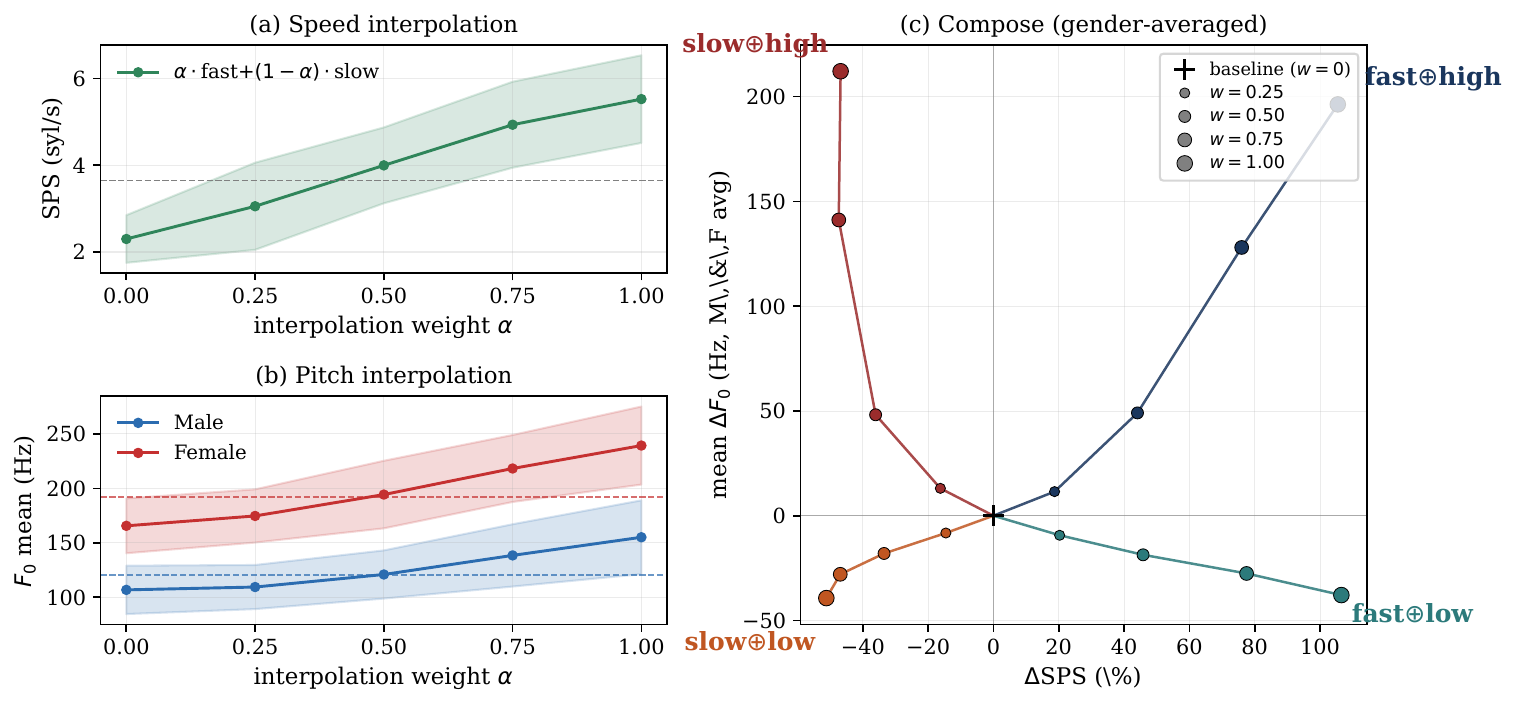
GLASS
GLASS: GRPO-Trained LoRA for Acoustic Style Steering in Zero-Shot Text-to-Speech
GLASS is a zero-shot TTS framework that controls speaking rate and pitch via LoRA adapters trained from post-generation rewards, not style labels. This modular approach enables smooth style edits and multi-axis composition without changing speaker prompts, preserving speaker identity and naturalness.